

推论统计学基础
置信区间
先来介绍一下置信区间的预备知识:
对于正态分布而言,有3σ原则,也就是数值分布在(μ-σ,μ+σ)中的概率为0.6827;数值分布在(μ-2σ,μ+2σ)中的概率为0.9544;数值分布在(μ-3σ,μ+3σ)中的概率为0.9974。
其中μ为样本均值,σ为样本标准差。
而2σ时概率分布已经达到95%以上的水平,事件不发生的概率只有5%,可以说是极有可能发生了。所以在讨论某个情况的置信区间时通常我们都用95%。
下面具体介绍一下置信区间:
置信区间从字面上可以理解为,某一事件发生在某一个概率区间内可能的概率。这个概率被称为置信水平。举例来说,如果在一次大选中某人的支持率为55%,而置信水平0.95以上的置信区间是(50%,60%),那么他的真实支持率有百分之九十五的机率落在百分之五十和百分之六十之间,因此他的真实支持率不足一半的可能性小于百分之5。
如例子中一样,置信水平一般用百分比表示,因此置信水平0.95上的置信空间也可以表达为:95%置信区间。置信区间的两端被称为置信极限。对一个给定情形的估计来说,置信水平越高,所对应的置信区间就会越大。
我们由于有公式
SE=σn‾√
se是样本标准差, σ
是总体标准差
所以95%的置信区间公式为:
x¯−2σn‾√<μB<x¯+2σn‾√
其中μB
为要估计的数,x¯
为样本均值
点估计
点估计(point estimation)是用样本统计量来估计总体参数,因为样本统计量为数轴上某一点值,估计的结果也以一个点的数值表示,所以称为点估计。
由样本数据估计总体分布所含未知参数的真值,所得到的值,称为估计值。点估计的精确程度用置信区间表示。
区间估计
区间估计顾名思义就是某事件发生在某概率区间之内可能的概率情况。比如估计一种药品所含杂质的比率在1~2%之间;估计一种合金的断裂强度在1000~1200千克之间,等等。
区间估计(interval estimation)是从点估计值和抽样标准误出发,按给定的概率值建立包含待估计参数的区间。其中这个给定的概率值称为置信度或置信水平(confidence level),这个建立起
来的包含待估计参数的区间称为置信区间(confidence interval),指总体参数值落在样本统计值某一区内的概率;
划定置信区间的两个数值分别称为置信下限(lower confidence limit,lcl)和置信上限(upper confidence limit,ucl)
样本量越大,置信区间的范围就会越小,因为样本量越大,标准误差就会越小,这样对于总成参数的估计就会越精确。
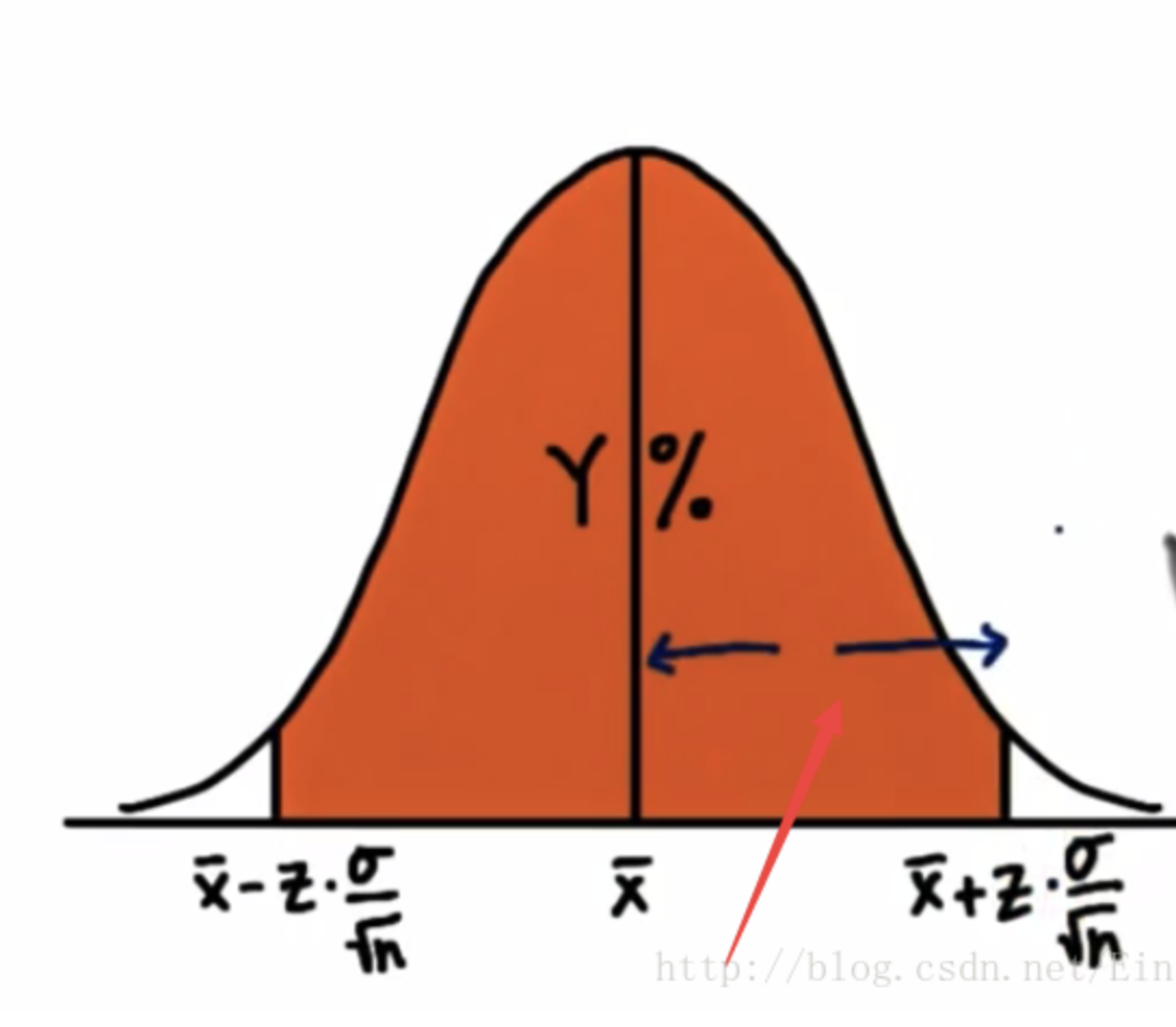
下面是区间估计的计算公式:
(x¯−z∗σn‾√,x¯+z∗σn‾√)
其中z为置信度,比如说95%所对应的标准正态分布的z是1.96,98%所对应的标准正态分布的z是2.33,99%所对应的标准正态分布的z是2.576
x¯
是样本均值
区间估计的计算公式为什么会是这样呢?
对于区间估计,因为根据中心极限定理,抽样分布的平均值是会符合正态分布的,因此我们可以根据正态分布来求95%的置信区间。因为标准误差的定义就是抽样分布的“平均值的标准差”,因此使用中心值±
1.96*标准误差就可以求出平均值的置信区间。
假设检验
判断某件事是否有效果,我们称之为假设检验
距离x¯
两侧的距离称之为误差界限(margin of error)
其值等于
z∗σn‾√
也就是一半的置信宽度

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步