

python常见问题
1.列表list和元组tuple有什么区别?
(1)是否可变
列表是可变的,创建后可以对其进行修改。
元组是不可变的,元组一旦创建,就不能对其进行更改。
(2)元素数据类型是否一样
列表中的元素可以是不同的数据类型。
元组表示的是结构,可以用来存储不同数据类型的元素。
(3)是否可以通过索引来访问
列表和元组均可以通过索引来访问。
2.is和“”
“is”用来检查对象的表示id(),而“”用来检查两个对象是否相等。
我们将通过一个例子说明。创建一些列表并将其分配给不同的名字。请注意,下面的b指向与a相同的对象。
a = [1,2,3]b = ac = [1,2,3]
下面来检查是否相等,你会注意到结果显示它们都是相等的。
print(a == b)print(a == c)#=> True#=> True
但是它们具有相同的标识(id)吗?答案是不。
print(a is b)print(a is c)#=> True#=> False
我们可以通过打印他们的对象标识(id)来验证这一点。
print(id(a))print(id(b))print(id(c))#=> 4369567560#=> 4369567560#=> 4369567624
你可以看到:c和a和b具有不同的标识(id)。
3.什么是装饰器(decorator)
装饰器允许通过将现有函数传递给装饰器,从而向现有函数添加一些额外的功能,该装饰器将执行现有函数的功能和添加的额外功能。
最近有人问我装饰器是什么,我就跟他说,其实就是装饰器就是类似于女孩子的发卡。你喜欢的一个女孩子,她可以有很多个发卡,而当她戴上不同的发卡,她的头顶上就是装饰了不同的发卡。但是你喜欢的女孩子还是你喜欢的女孩子。如果还觉得不理解的话,装饰器就是咱们的手机壳,你尽管套上了手机壳,但并不影响你的手机功能,可你的手机还是该可以给你玩,该打电话打电话,该玩游戏玩游戏。而你的手机就变成了带手机壳的手机。
3.1 什么是装饰器
装饰器是给现有的模块增添的小功能,可以对原函数进行功能扩展,而且还不需要修改原函数的内容,也不需要修改原函数的调用。
装饰器的使用符合了面向对象编程的开放封闭原则。
开放封闭原则主要体现在两个方面:
(1)对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。
(2)对修改封闭,意味着类一旦设计完成,就可以独立其工作,而不要对类进行任何修改。
3.2 为什么要使用装饰器
使用装饰器之前,我们要知道,其实python里是万物皆可对象,也就是万物都可以传参。
函数也可以作为函数的参数进行传递的。
通过下面这个简单的例子可以直观知道函数名是如何直接作为参数进行传递的。
点击查看代码
def baiyu():
print("我是攻城狮白玉")
def blog(name):
print('进入blog函数')
name()
print('我的博客是 https://blog.csdn.net/zhh763984017')
if __name__ == '__main__':
func = baiyu # 这里是把baiyu这个函数名赋值给变量func
func() # 执行func函数
print('------------')
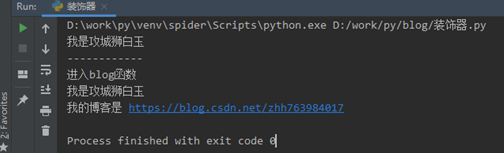
blog(baiyu) # 把baiyu这个函数作为参数传递给blog函数
执行结果如下所示:
接下来,我想知道这baiyu和blog两个函数分别的执行时间是多少,我就把代码修改如下:
点击查看代码
import time
def baiyu():
t1 = time.time()
print("我是攻城狮白玉")
time.sleep(2)
print("执行时间为:", time.time() - t1)
def blog(name):
t1 = time.time()
print('进入blog函数')
name()
print('我的博客是 https://blog.csdn.net/zhh763984017')
print("执行时间为:", time.time() - t1)
if __name__ == '__main__':
func = baiyu # 这里是把baiyu这个函数名赋值给变量func
func() # 执行func函数
print('------------')
blog(baiyu) # 把baiyu这个函数作为参数传递给blog函数
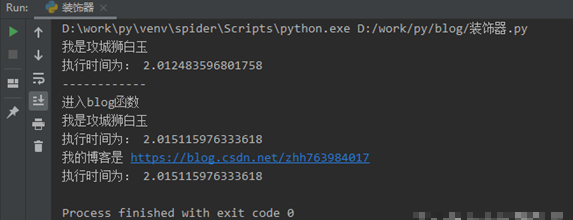
3.3 简单的装饰器
基于上面的函数执行时间的需求,我们写一个简单的装饰器进行实现。
点击查看代码
import time
def baiyu():
print("我是攻城狮白玉")
time.sleep(2)
def count_time(func):
def wrapper():
t1 = time.time()
func()
print("执行时间为:", time.time() - t1)
return wrapper
if __name__ == '__main__':
baiyu = count_time(baiyu) # 因为装饰器 count_time(baiyu) 返回的时函数对象 wrapper,这条语句相当于 baiyu = wrapper
baiyu() # 执行baiyu()就相当于执行wrapper()
这里的count_time是一个装饰器,装饰器函数里面定义一个wrapper函数,把func这个函数当作参数传入,函数实现的功能是把func包裹起来,并且返回wrapper函数。wrapper函数体就是要实现装饰器的内容。
当然,这里的wrapper函数名是可以自定义的,只要你定义的函数名,跟return的函数名是相同的就好了。
3.4 装饰器的语法糖@
看过其他python项目里面的代码,难免会看到@符号,这个@符号就是装饰器的语法糖。
因此上面简单的装饰器还是可以通过语法糖来实现的,这样就可以省去
baiyu=count_time(baiyu)
这一句代码,而直接调用baiyu()这个函数
换句话说,其实默认传入的参数就是被装饰的函数。
`import time
def count_time(func):
def wrapper():
t1 = time.time()
func()
print("执行时间为:", time.time() - t1)
return wrapper
@count_time
def baiyu():
print("我是攻城狮白玉")
time.sleep(2)
if name == 'main':
# baiyu = count_time(baiyu) # 因为装饰器 count_time(baiyu) 返回的时函数对象 wrapper,这条语句相当于 baiyu = wrapper
# baiyu() # 执行baiyu()就相当于执行wrapper()
baiyu() # 用语法糖之后,就可以直接调用该函数了`
3.5 装饰器传参
当我们被装饰的函数是带参数的,此时要怎么写装饰器呢?
上面我们有定义了一个blog函数是带参数的
def blog(name): print('进入blog函数') name() print('我的博客是 https://blog.csdn.net/zhh763984017')
此时我们的装饰器函数要优化一下下,修改成为可以接受任意参数的装饰器
`def count_time(func):
def wrapper(args,**kwargs):
t1 = time.time()
func(args,**kwargs)
print("执行时间为:", time.time() - t1)
return wrapper`
此处,我们的wrapper函数的参数为*args和**kwargs,表示可以接受任意参数。
这时我们就可以调用我们的装饰器了。
`import time
def count_time(func):
def wrapper(args, **kwargs):
t1 = time.time()
func(args, **kwargs)
print("执行时间为:", time.time() - t1)
return wrapper
@count_time
def blog(name):
print('进入blog函数')
name()
print('我的博客是 https://blog.csdn.net/zhh763984017')
if name == 'main':
# baiyu = count_time(baiyu) # 因为装饰器 count_time(baiyu) 返回的时函数对象 wrapper,这条语句相当于 baiyu = wrapper
# baiyu() # 执行baiyu()就相当于执行wrapper()
# baiyu() # 用语法糖之后,就可以直接调用该函数了
blog(baiyu)`
3.6 带参数的装饰器
前面咱们知道,装饰器函数也是函数,既然是函数,那么就可以进行参数传递,咱们怎么写一个带参数的装饰器呢?
前面咱们的装饰器只是实现了一个计数,那么我想在使用该装饰器的时候,传入一些备注的msg信息,怎么办呢?
`import time
def count_time_args(msg=None):
def count_time(func):
def wrapper(args, **kwargs):
t1 = time.time()
func(args, **kwargs)
print(f"[{msg}]执行时间为:", time.time() - t1)
return wrapper
return count_time
@count_time_args(msg="baiyu")
def fun_one():
time.sleep(1)
@count_time_args(msg="zhh")
def fun_two():
time.sleep(1)
@count_time_args(msg="mylove")
def fun_three():
time.sleep(1)
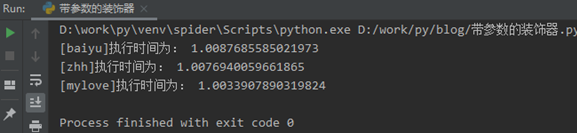
if name == 'main':
fun_one()
fun_two()
fun_three()`
咱们基于原来的count_time函数外部再报一层用于接收参数的count_time_args,接收回来的参数就可以直接在内部的函数里面调用了。
3.7 类装饰器
上面咱们一起学习了怎么写装饰器函数,在python中,其实也可以同类来实现装饰器的功能,称之为类装饰器。
类装饰器的实现是调用了类里面的__call__函数。类装饰器的写法比我们装饰器函数的写法更加简单。
当我们将类作为一个装饰器,工作流程:
通过__init__()方法初始化类
通过__call__()方法调用真正的装饰方法
`import time
class BaiyuDecorator:
def init(self, func):
self.func = func
print("执行类的__init__方法")
def __call__(self, *args, **kwargs):
print('进入__call__函数')
t1 = time.time()
self.func(*args, **kwargs)
print("执行时间为:", time.time() - t1)
@BaiyuDecorator
def baiyu():
print("我是攻城狮白玉")
time.sleep(2)
def python_blog_list():
time.sleep(5)
print('''【Python】爬虫实战,零基础初试爬虫下载图片(附源码和分析过程)
https://blog.csdn.net/zhh763984017/article/details/119063252 ''')
print('''【Python】除了多线程和多进程,你还要会协程
https://blog.csdn.net/zhh763984017/article/details/118958668 ''')
print('''【Python】爬虫提速小技巧,多线程与多进程(附源码示例)
https://blog.csdn.net/zhh763984017/article/details/118773313 ''')
print('''【Python】爬虫解析利器Xpath,由浅入深快速掌握(附源码例子)
https://blog.csdn.net/zhh763984017/article/details/118634945 ''')
@BaiyuDecorator
def blog(name):
print('进入blog函数')
name()
print('我的博客是 https://blog.csdn.net/zhh763984017')
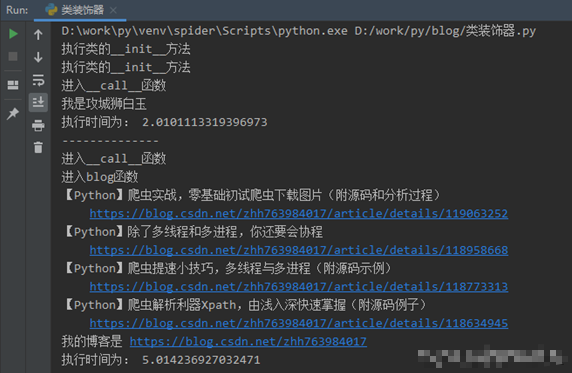
if name == 'main':
baiyu()
print('--------------')
blog(python_blog_list)`
3.8 带参数的类装饰器
当装饰器有参数的时候,init() 函数就不能传入func(func代表要装饰的函数)了,而func是在__call__函数调用的时候传入的。
`class BaiyuDecorator:
def init(self, arg1, arg2): # init()方法里面的参数都是装饰器的参数
print('执行类Decorator的__init__()方法')
self.arg1 = arg1
self.arg2 = arg2
def __call__(self, func): # 因为装饰器带了参数,所以接收传入函数变量的位置是这里
print('执行类Decorator的__call__()方法')
def baiyu_warp(*args): # 这里装饰器的函数名字可以随便命名,只要跟return的函数名相同即可
print('执行wrap()')
print('装饰器参数:', self.arg1, self.arg2)
print('执行' + func.__name__ + '()')
func(*args)
print(func.__name__ + '()执行完毕')
return baiyu_warp
@BaiyuDecorator('Hello', 'Baiyu')
def example(a1, a2, a3):
print('传入example()的参数:', a1, a2, a3)
if name == 'main':
print('准备调用example()')
example('Baiyu', 'Happy', 'Coder')
print('测试代码执行完毕')`
3.9 装饰器的执行顺序
一个函数可以被多个装饰器进行装饰,那么装饰器的执行顺序是怎么样的呢?咱们执行一下下面的代码就清楚了。
`def BaiyuDecorator_1(func):
def wrapper(args, **kwargs):
func(args, **kwargs)
print('我是装饰器1')
return wrapper
def BaiyuDecorator_2(func):
def wrapper(args, **kwargs):
func(args, **kwargs)
print('我是装饰器2')
return wrapper
def BaiyuDecorator_3(func):
def wrapper(args, **kwargs):
func(args, **kwargs)
print('我是装饰器3')
return wrapper
@BaiyuDecorator_1
@BaiyuDecorator_2
@BaiyuDecorator_3
def baiyu():
print("我是攻城狮白玉")
if name == 'main':
baiyu()由输出结果可知,在装饰器修饰完的函数,在执行的时候先执行原函数的功能,然后再由里到外依次执行装饰器的内容。 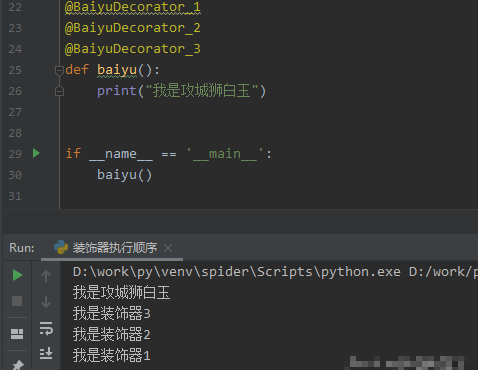 我们带三个装饰器的函数的代码如下:@BaiyuDecorator_1
@BaiyuDecorator_2
@BaiyuDecorator_3
def baiyu():
print("我是攻城狮白玉")上述的代码可以看作如下代码,就能理解为何是由里到外执行了baiyu = BaiyuDecorator_1 (BaiyuDecorator_2 (BaiyuDecorator_3(baiyu)))`
- Python中的实例方法、静态方法和类方法有什么区别?
5.类中的“self”指的是什么?
“self”引用类本身的实例。这就是我们赋予方法访问权限并且能够更新方法所属对象的能力。
6.浅拷贝和深拷贝之间有什么区别?
我们将在一个可变对象(列表)的上下文中讨论这个问题,对于不可变的对象,浅拷贝和深拷贝的区别并不重要。
简单的说:
(1)copy.copy浅拷贝:只拷贝父对象,不会拷贝对象的内部的子对象
(2)copy.deepcopy深拷贝:拷贝对象及其子对象
用一个简单的例子说明如下:
点击查看代码
>>>import copy
>>>a = [1, 2, 3, 4, ['a', 'b', 'c']]
>>> b = a
>>> c = copy.copy(a)
>>> d = copy.deepcopy(a)
第4行是浅拷贝,第五行是深拷贝,通过id(c)和id(d)可以发现他们不相同,且与id(a)都不相同:
点击查看代码
>>> id(a)
19276104
>>> id(b)
19276104
>>> id(c)
19113304
>>> id(d)
19286976
点击查看代码
>>> a.append(5) #操作1
>>> a[4].append('hello') #操作2
点击查看代码
>>> a
[1, 2, 0, 4, ['a', 'b', 'c', 'hello'], 5]
>>> b
[1, 2, 0, 4, ['a', 'b', 'c', 'hello'], 5]
>>> c
[1, 2, 3, 4, ['a', 'b', 'c', 'hello']]
>>> d
[1, 2, 3, 4, ['a', 'b', 'c']]
点击查看代码
aList=[[1, 2], 3, 4]
bList = aList[:] #利用切片完成一次浅拷贝
id(aList)
3084416588L
id(bList)
3084418156L
aList[0][0] = 5
aList
[[5, 2], 3, 4]
bList
[[5, 2], 3, 4]
但是有点需要特别提醒的,如果对象本身是不可变的,那么浅拷贝时也会产生两个值
点击查看代码
这个顺便回顾下Python标准类型的分类:
可变类型: 列表,字典
不可变类型:数字,字符串,元组
理解了浅拷贝,深拷贝是什么自然就很清楚了。
python中有一个模块copy,deepcopy函数用于深拷贝,copy函数用于浅拷贝。
最后,对象的赋值是深拷贝还是浅拷贝?
对象赋值实际上是简单的对象引用
实例
点击查看代码
#!/usr/bin/python
# -*-coding:utf-8 -*-
import copy
a = [1, 2, 3, 4, ['a', 'b']] #原始对象
b = a #赋值,传对象的引用
c = copy.copy(a) #对象拷贝,浅拷贝
d = copy.deepcopy(a) #对象拷贝,深拷贝
a.append(5) #修改对象a
a[4].append('c') #修改对象a中的['a', 'b']数组对象
print( 'a = ', a )
print( 'b = ', b )
print( 'c = ', c )
print( 'd = ', d )
以上实例执行输出结果为:
点击查看代码
('a = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])
('b = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])
('c = ', [1, 2, 3, 4, ['a', 'b', 'c']])
('d = ', [1, 2, 3, 4, ['a', 'b']])
7.列表list和数组array相同点和不同点
(1)定义
列表是由一系列按特定顺序排列的元素组成,可以将任何东西加入列表中,其中的元素之间没有任何关系。
python中的列表list用于顺序存储结构。它可以方便、高效的添加和删除元素,并且列表中的元素可以是多种类型。
数组也就是同一类型的数据的有限集合。
(2)相同点
都可以根据索引来取其中的元素。
(3)不同点
a. 列表list中的元素的数据类型可以不一样;数组array里的元素的数据类型必须一样
b. 列表list不可以进行数学四则运算,数组array可以进行数学四则运算
c. 相对于array,列表会使用更多的存储空间
点击查看代码
import numpy as np
lis1=[1,2,3,4] #lis1是列表类型
a = np.array([1,2,3,4]) #a是数组类型
#从下面print可以看出 list和array都可以根据索引来操作;
print("list",lis1,lis1[0],'\n','array',a,a[0])
#从下面print可以看出list的加法运算是列表长度的增删,与数学计算无关;
#而array的+法运算是真正的数学四则运算;
print("list+list",lis1+lis1,'\n','array+array',a+a)
点击查看代码
list [1, 2, 3, 4] 1
array [1 2 3 4] 1
list+list [1, 2, 3, 4, 1, 2, 3, 4]
array+array [2 4 6 8]
8.举几个可变和不可变对象的例子
不可变意味着创建后不能修改状态。例如:int、float、bool、string和tuple
可变意味着创建后可以修改状态。例如:列表(list)、字典(dict)和集合(set)
9.四舍五入和求绝对值
四舍五入:round()
求绝对值:abs()
四舍五入:
点击查看代码
#!/usr/bin/python
print "round(80.23456, 2) : ", round(80.23456, 2)
print "round(100.000056, 3) : ", round(100.000056, 3)
print "round(-100.000056, 3) : ", round(-100.000056, 3)
结果:
点击查看代码
round(80.23456, 2) : 80.23
round(100.000056, 3) : 100.0
round(-100.000056, 3) : -100.0
求绝对值:
点击查看代码
#!/usr/bin/python3
print ("abs(-40) : ", abs(-40))
print ("abs(100.10) : ", abs(100.10))
结果:
点击查看代码
abs(-40) : 40
abs(100.10) : 100.1
10.字典和列表的查找速度哪个更快?
在列表中查找一个值需要O(n)时间,因为需要遍历整个列表,直到找到值为止。
在字典中查找一个值只需要O(1)时间,因为它是一个哈希表。
如果有很多值,这会造成很大的时间差异,因此通常建议使用字典来提高速度。但字典也有其他限制,比如需要唯一键。
//什么是哈希表?
根据关键码值 (Key value)而直接进行访问的 数据结构
11.模块(module)和包(package)有什么区别?
模块是可以一起导入的文件(或文件集合)。
import sklearn
包是模块的目录。
from sklearn import cross_validation
12.如何从列表中删除重复的元素
可以通过将一个列表先转化为集合,然后再转化回列表来完成。
点击查看代码
a = [1,1,2,2,2,3]
a = list(set(a))
print(a)
点击查看代码
[1,2,3]
13.如何检查一个值是不是在列表中存在
'a' in ['a', 'b', 'c']
True
- 如何按字母顺序对字典进行排序?
你不能对字典进行排序,因为字典没有顺序,但是你可以返回一个已排序的元组列表,其中包含字典中的键和值。
d = {'c':3, 'd':4, 'b':2, 'a':1}
sorted(d.items)#=> [('a', 1), ('b', 2), ('c', 3), ('d', 4)]
15.删除字符串中的所有空白
点击查看代码
In [1]: sentence = ' hello apple \n \r \t '
In [2]: "".join(sentence.split())
Out[3]: 'helloapple'
16.remove、del和pop有什么区别?
remove 删除第一个匹配的值。
li = ['a','b','c','d']
li.remove('b')
['a', 'c', 'd']
del按索引删除元素
li = ['a','b','c','d']
del li[0]
['b', 'c', 'd']
pop 按索引删除一个元素并返回该元素。
li = ['a','b','c','d']
li.pop(2)#=> 'c'
['a', 'b', 'd']


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具
2019-02-15 python中addict模块,设置和读取嵌套字典
2019-02-15 python+json
2019-02-15 Python + excel
2019-02-15 PyCharm撤消/恢复
2019-02-15 python安装第三方库的步骤