李宏毅机器学习-学习笔记
function set就是model

机器学习3大步骤:
1. 定义模型(function)集合
2. 指定模型(function)好坏的评价指标
3. 通过算法选择到最佳的模型(function)
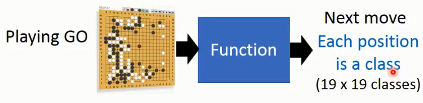
alphago下棋模型抽象为棋局向下一步的分类问题:
减少拥有label的data用量的方法:
1. semi-supervised learning:使用部分核心拥有label的data以及大量没有label的data
2.transfer learing
structure learning:
结构化学习输出的是有结构内容的东西,比如机器翻译,语音识别,物体框检测
reinforcement learning:
强化学习。learning from critics。比如,alphago, 下了500步后却败北了,机器只知道这个结果,自己去总结。
我们知道supervised learning中会告诉机器哪个是对的(learning from teacher),而强化学习不会告诉做的对错,
terms术语

注意:包含2次或者高次的多项式模型也属于线性model,因为参数对model的输出是线性关系。$y=\omega _1x+ \omega_2x^2+b$
学习率自适应adam算法


hidden factor存在的象征
选择模型function,喂以data时评估结果是一般机器学习的流程。但是我们很有可能对数据本身的特征研究不够,遗漏掉重要特征,那么自然效果不佳。这时domain knowledge就显得很重要了。

error误差来自于何处?
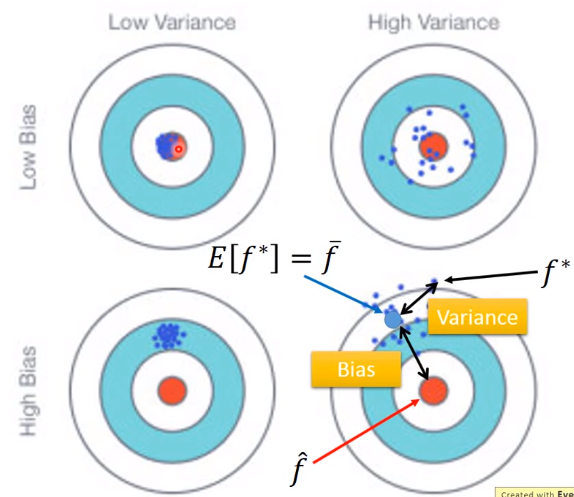
bias and variance of estimator
假设一个随机变量x的期望为$\mu$,方差为$\sigma ^2$,我们通过样本来估计其期望和方差。
$\bar X = \frac {1}{N} \sum_{n=1}^{N}x^{(n)}$ 是总体期望的无偏(non-biased)估计,原因是:
$E(\bar X) = \frac {1}{N} \sum_{n=1}^{N}E(x^{(n)})=\frac {1}{N}\cdot N \mu = \mu$
而其样本方差$s^2 = \frac {1}{N} \sum_{n=1}^{N}(x^{(n)}-\bar X)^2$却是biased有偏估计:
原因是:
$E(s^2) = \frac {1}{N} \sum_{n=1}^{N}E((x^{(n)}-\bar X)^2)= \frac {N-1}{N}\sigma ^2 \neq \sigma ^2$
机器学习中模型选择时本质上是针对样本数据做参数估计,而一组样本对应一个参数估计,对应一个最优模型;但是用统计的视角来看,当我们取另外一组样本时,参数估计必然不同,也就是最优模型就会不同。模型也可以看着是一个随机变量$X$的函数,它也是一个随机变量,我们记着$F$,每次实验获取样本数据训练出来的模型$f$都是$F$期望最佳目标的一个value,这就存在bias或者variance.
什么时候bias大?
什么时候variance大?
针对bias大的情况,如何处理:增加更多的输入feature,使用更加复杂的模型
针对variance大的情况: 增加更多的data, regularization正则处罚

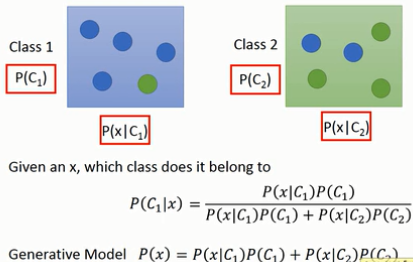
generative model
从training data中首先计算出来各自类别下出现某特定$x$的概率,随后使用贝叶斯公式,我们可以计算给定$x$,其属于某个类别的概率$p$。另一方面,根据全概率公式,经由手上的数据data分布,我们又可以计算出$P(x)$的概率分布模型,这样我们就可以人为在该概率分布模型下采样获取相应数据$x$,因此,我们称这类基于贝叶斯,全概率等公式定义的model为生成式模型。
deep learning
Given network structure, define a function set.
对于深度学习来说,由于feature engineering可以由网络自己来学习和处理,那么问题的难度由机器学习中的特征工程转换为神经网络网络结构的架构设计,比如需要多少层次,每一层需要多少个单元。。。
微分两种类型链式法则

x_train,y_train数据的堆叠
水平轴为sample number,纵轴为feature个数
为什么需要deep?
有理论证明只需要一层网络就能表示出任何的函数,那么为什么我们还需要deep network呢?有以下几个原因:
同样函数表示单层网络所需要的神经元数量远远大于多层级联网络,这个类似于使用单层的逻辑门电路造电脑一样,理论上是可行的,但是实际上由于所需逻辑门电路太过庞大,无法实现;
单层网络由于神经元数量更多,则意味着需要更多的data才能达到比较满意的结果。
deep learning调试技术
当training data上的结果不理想时:
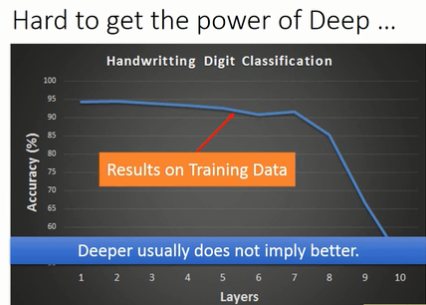
网络并不是越深效果越好,比如看下图,随着网络深度的提高而导致即使在training data上学习效果也非常差,因此并不是由于网络复杂度的增加而导致的overfitting,我们必须调查其根本原因。
产生该问题可能的一个原因是sigmoid激活函数导致的梯度消失问题。vanishing gradient problem.
梯度消失问题vanishing gradient problem
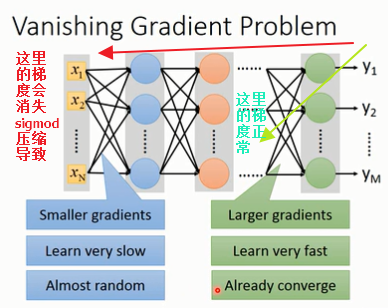
梯度消失问题可以这样理解:由于sigmoid激活函数具有压缩输入到很小的-1到+1之间的功能,我们在网络的前几层,即使权重$\omega$的变化值$\Delta \omega$很大,经过后续sigmoid函数的层层压缩到最后影响到的loss函数变化极其微小,也就是$\frac {\partial L}{\partial \omega}$几乎为0非常小,出现了梯度消失。
为此我们需要更换激活函数,保持梯度不会消失,网络可以正常学习训练。
relu激活函数解决了梯度消失问题

有max操作时其微分如何计算????
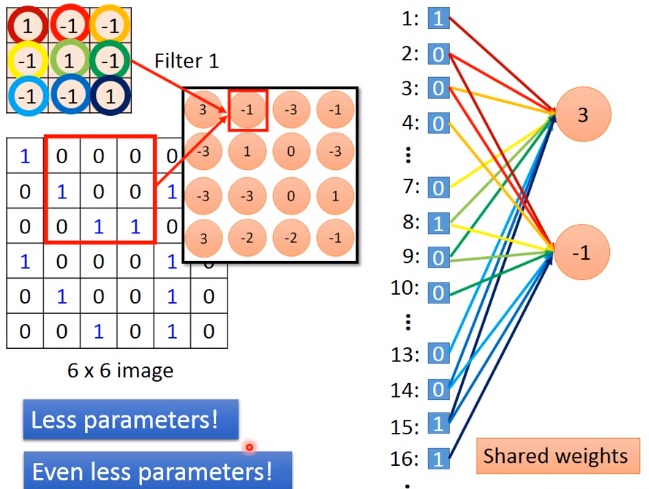
CNN的特性
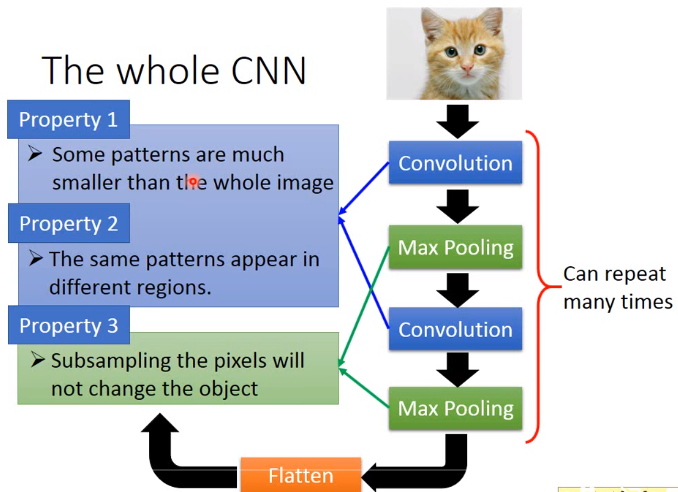
卷积filter可以视为全连接层的子集,一个filter的每个神经元其权重相同,根据stride滑窗大小分别连接着不同的输入像素点,
大大减少了参数数量,而一个卷积层neuro的个数决定本层输出个数
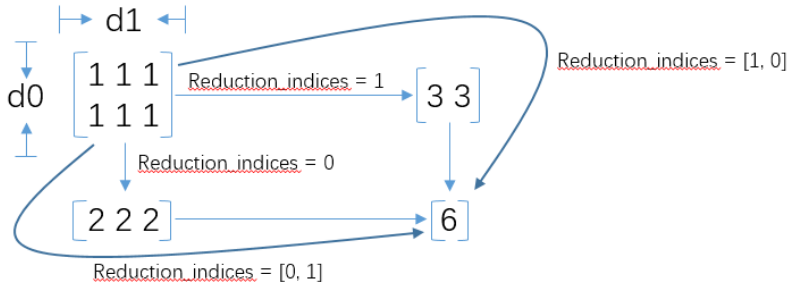
tf.reduce_mean,reduce_sum等