

统计模型机器学习模型领域相关知识,指标概念及问题点积累
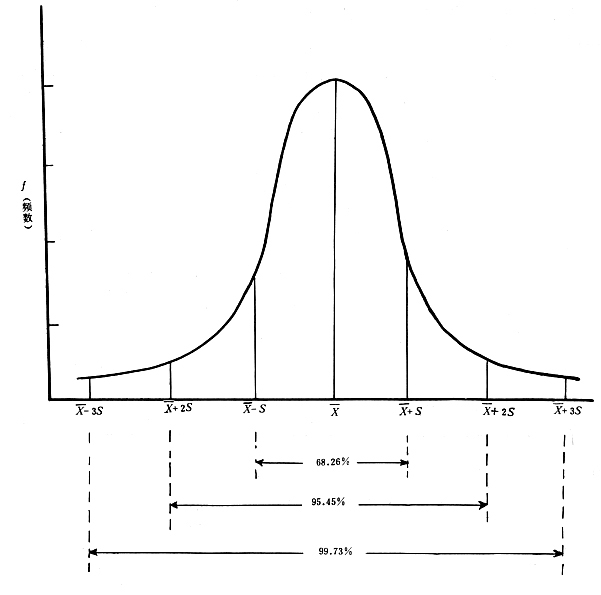
3 σ法则
在正态分布中σ代表标准差,μ代表均值x=μ即为图像的对称轴.三σ原则即为
数值分布在(μ—σ,μ+σ)中的概率为0.6526
数值分布在(μ—2σ,μ+2σ)中的概率为0.9544
数值分布在(μ—3σ,μ+3σ)中的概率为0.9974
z-score
z分数(z-score),也叫标准分数(standard score)是一个数与平均数的差再除以标准差。
z-score可以回答以下问题:一个给定的观测值距离平均数多少个标准差?在平均数之上的分数会得到一个正的标准分数,在平均数之下的分数会得到一个负的标准分数。 z分数是一种可以看出某分数在分布中相对位置的方法。
总体的z-score: 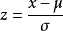 ,通常总体的均值和方差未知,我们可以使用样本的均值和样本方差来估计,得到样本的z-score:
,通常总体的均值和方差未知,我们可以使用样本的均值和样本方差来估计,得到样本的z-score: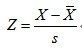
TSS=ESS+RSS

证明过程参考:https://stats.stackexchange.com/questions/248397/total-sum-of-squarestss-is-not-equal-ess-rss-when-the-model-doesnt-include

需要注意的是上式成立的条件是必须有一个非0的截距参数β0,否则没有代数残差之和为0的结论,因此TSS就不等于RSS+ESS!!

https://blog.csdn.net/strwolf/article/details/72621692
其中的核心点是 ∑(Yi−^Yi)=0 这是OLS这个模型求解最有问题时,令目标函数对系数的导数为0得到的必然结果,而不是任何假设!
nd-array/scipy sparse matrices/pandas dataframe
sparse matrice是scipy包定义的一种紧凑稀疏矩阵数据组织方式,特别适合于有大量0值的稀疏矩阵,因为会大大降低内存空间的占用。
pandas dataframe基于numpy的nd-array
https://docs.scipy.org/doc/scipy/reference/sparse.html
ndarray axis
对于大于1维的numpy数组,我们就定义了数轴的概念。一个2维数组有两个轴, axis 0是垂直方向,作为第一个轴向下延伸跨过相应的行, 而axis 1则是水平方向,定义为跨过不同的列。很多数学操作都能够指定在哪个轴上进行。比如,我们可以计算每一行的sum,这时我们sum要执行的是对column的计算,也就是axis 1:

>>> x = np.arange(12).reshape((3,4)) >>> x array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>> x.sum(axis=1) array([ 6, 22, 38])
feature extraction:特征提取
所有的机器学习算法的输入就是一堆行列构成的数字集合,那么问题来了一般性问题的输入可能并非数字,比如nlp自然语言处理,得到的语料都是文本,使用之前必须做特征提取的工作,将自然语言编码变换为对计算机有意义的数据。还有一种情况是降维时的特征提取
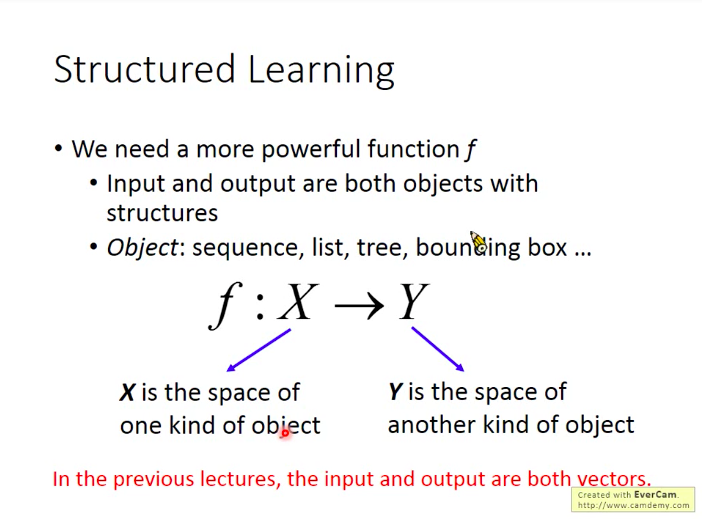
structured learning/unstructured learning
https://pystruct.github.io/intro.html
结构化学习预测是经典监督式学习:分类和回归范例的一个泛化。分类算法也好,回归算法也好都可以更加抽象为以下本质的过程:
寻找到一个针对训练数据集能够最小化损失函数L值的函数F,所不同的是算法函数F以及损失函数样式L.比如,针对分类问题,目标为离散的标签类别,而loss通常就是0-1 loss,即:计数分类错误总数。而在回归问题中,目标是实数值,loss通常用MSE均方差.
机器学习的本质实际上可以简化为寻找一个函数F,使得输入data到F能够映射为对应的输出:

而在结构化学习范畴中,target和loss都或多或少可能是任意的。这意味着我们的目标不再是预测一个分类标签或者一个数值,而可能是更加复杂的对象:比如一个序列或者一副图片。

https://blog.csdn.net/qq_32690999/article/details/78840312
http://yoferzhang.com/post/20170326ML01Introduction/
结构化学习统一框架:
找到一个函数F->评估F(x,y)对象x和y有多么匹配。
imbalanced dataset
http://contrib.scikit-learn.org/imbalanced-learn/stable/introduction.html
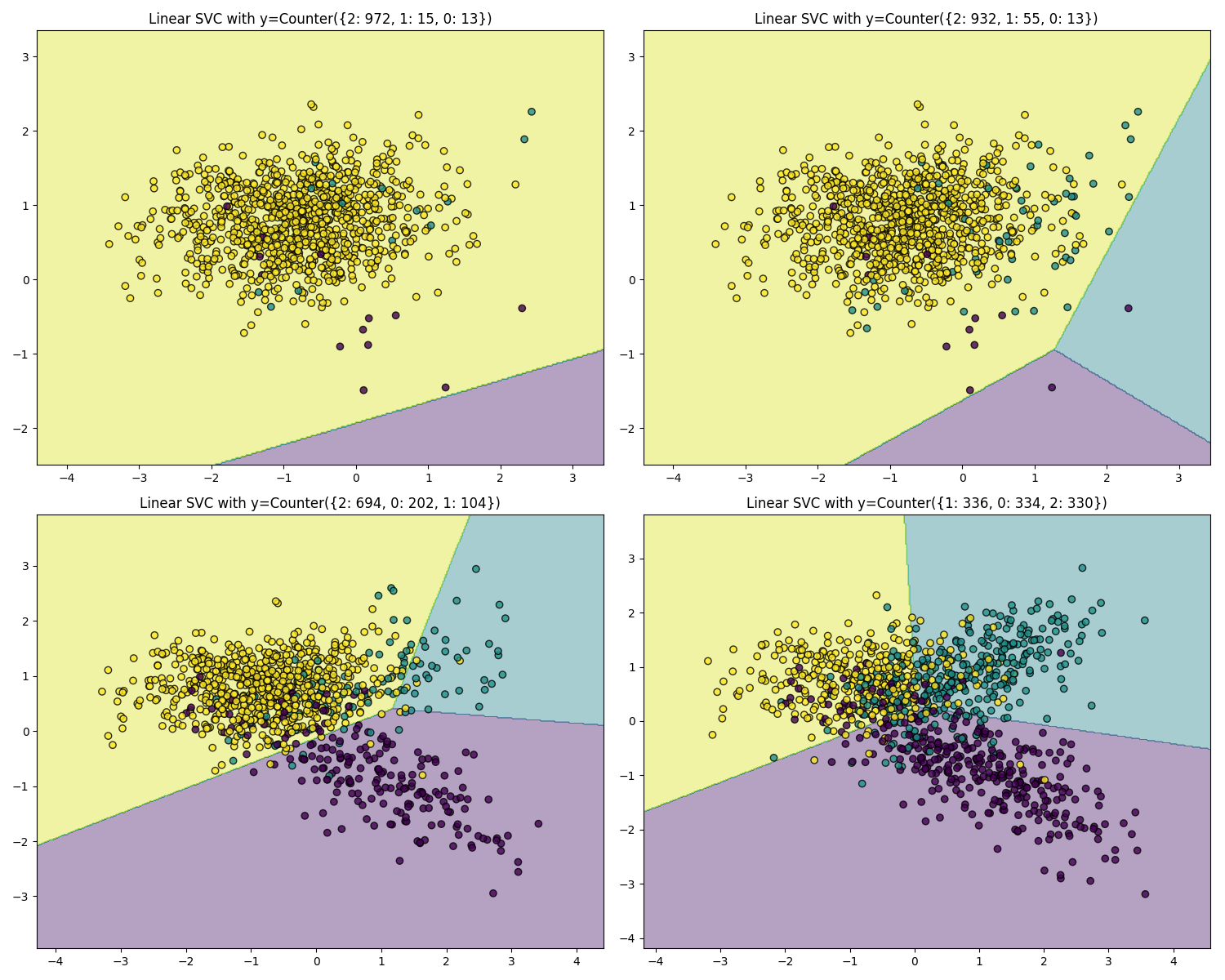
problem setting:
机器学习实际问题解决时,第一步我们需要对问题进行分类:比如是监督式学习还是无监督学习,分类还是回归。。这个流程称为problem setting
sklearn estimator
在sklearn中,一个estimator是一个python的object,这个对象实现了fit(X,y)方法以及predict(T)方法,分别用于训练集的学习和预测集的预测。例如sklearn.svm.SVC类就实现了支持向量学习机分类器算法。
sklearn通用流程:
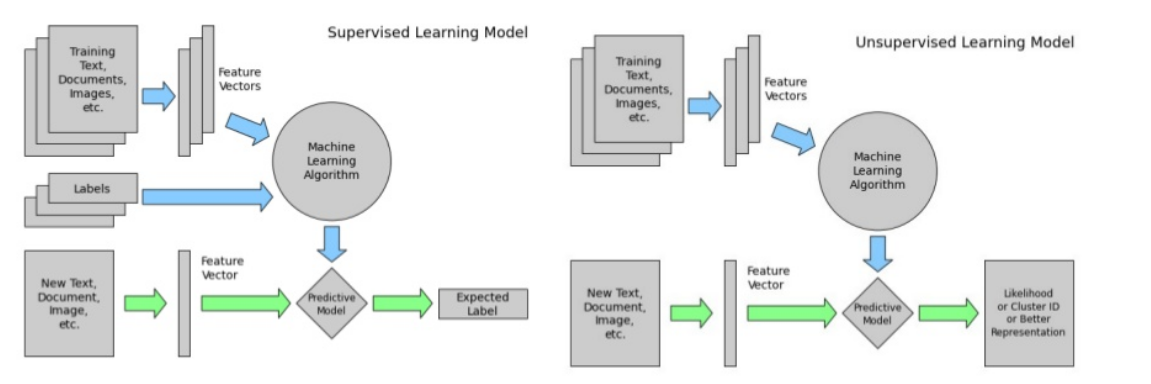
1d/2d array
1d array就是一个numpy一维数组,其.shape值为1,是一个向量
2d array就是一个numpy的二维数组,其.shape属性的值为2,通常代表一个矩阵
array-like
在sklearn的estimator或者函数的输入数据一般是array-like的数据。只要numpy.asarray调用后能够产生一个适当shape的array(通常是1维或者2维的)的数据,都是array-like的数据。比如:
- numpy array
- list of numbers
- list of length-k lists
- pandas.DataFrame
- pandas.Series
注意不是array-like的有: sparse matrix, an iterator, a generator
model persistence
模型训练完毕后,我们可能希望保存训练的结果,下次可以直接使用即可。可以使用的模块有:python内置的pickle或者第三方库joblib
sklearn estimator
estimator是任何能夠从数据中学习pattern的对象,他可以是一个分类器,回归算法,或者聚类,或者是一个从原始数据中提取有用特征的transformer
所有的estimator都有一个fit方法,该方法通常接收一个2d数组。当estimator完成fit后,相应参数的估计值就从数据中学习出来。所有估计的参数都作为estimator以 _ 结尾的属性存在,比如estimator.estimated_param_
维数诅咒(The curse of dimensionality)
https://blog.csdn.net/u010182633/article/details/45895493
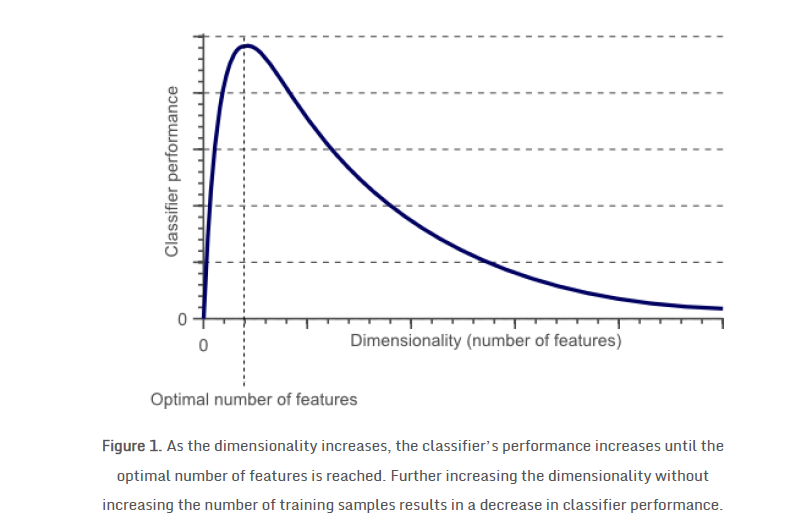
要训练一个泛化能力高的分类器,特征的维数非常重要,太高的维数非常容易导致过拟合,结果就是虽然训练结果非常好,但是未见过的数据预测效果极差。要训练得到更好的效果,所需要的数据样本呈现指数级别的提高。
jacobian矩阵和hessian矩阵
http://jacoxu.com/jacobian%E7%9F%A9%E9%98%B5%E5%92%8Chessian%E7%9F%A9%E9%98%B5/
jacobian矩阵和hessian矩阵主要用于优化算法中,提供梯度(导数)的数值矩阵。
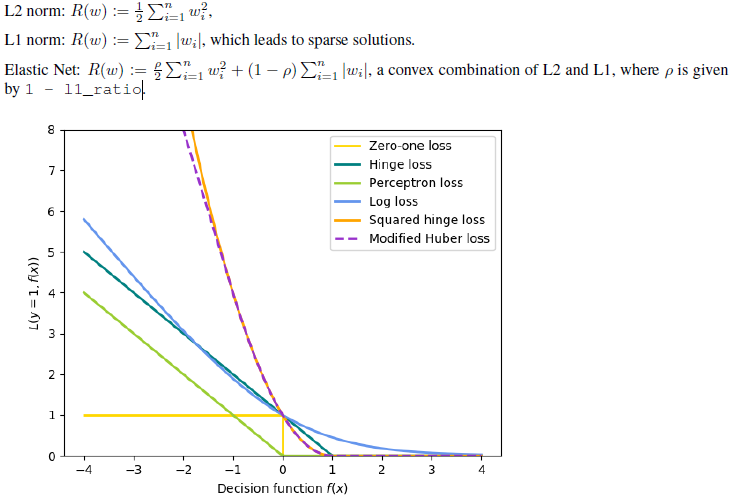
L2 Norm/L1 Norm/Elastic Net
优化目标函数时我们往往会增加一个惩罚项以免模型过于复杂出现过拟合。常见的惩罚项有
ensemble算法
集成算法(ensemble)的目标是将多个使用给定学习算法学习出来的base estimator的预测输出结合起来,总体决策用于提高模型泛化能力及健壮性。
有两种思路:
averaging(bagging)
首先独立地构建多个estimator,然后将他们的输出预测值做平均,这样总的来说,比一个单独的estimator效果要更好。原因是降低了variance of a base estimator,比如:bagging method,forest of randomized trees.
boosting
多个base estimator顺序构建,后建的estimator用于减少最终模型的bias.比如AdaBoost, Gradient Tree Boosting,XGBoost
Bagging methods come in many flavours but mostly differ from each other by the way they draw random subsets of
the training set:
• When random subsets of the dataset are drawn as random subsets of the samples, then this algorithm is known
as Pasting [B1999].
• When samples are drawn with replacement, then the method is known as Bagging [B1996].
• When random subsets of the dataset are drawn as random subsets of the features, then the method is known as
Random Subspaces [H1998].
• Finally, when base estimators are built on subsets of both samples and features, then the method is known as
Random Patches [LG2012].
voting:
同一个问题使用不同类型的模型分别预测,得到的结果做voting得到最终的结果。。
变量相关性的卡方检验 vs 线性相关检验的相关系数
在搭建模型时,自变量数据不能是线性相关的,以及自变量和因变量是必须紧密相关的这两点都非常重要。如果模型中的输入变量本身具有线性相关性,那么会导致"多重共线性"问题;如果模型中某个输入的特征和因变量根本不相关(独立的)(无论是线性的还是非线性的),那么我们就不应该在建模时引入该变量,因为这将突然增加模型复杂度。同时,如果输入自变量太多,会很容易导致模型过拟合,因此有必要降维处理,这时我们就需要将输入变量和因变量之间的相关程度来做一下排序。
因此,如何检验线性相关性以及独立性就非常重要了。一般来说,线性相关性的检测可以通过相关系数来检查,而独立性可以通过卡方检验来完成。

其中A为实际值,也就是第一个四格表里的4个数据,T为理论值,也就是理论值四格表里的4个数据。
x2用于衡量实际值与理论值的差异程度(也就是卡方检验的核心思想),有了卡方值查表看看是否满足95%置信
下面是一个卡方检验的链接:
https://blog.csdn.net/snowdroptulip/article/details/78770088
嵌入式系统中使用的机器学习C库 libsvm
https://www.csie.ntu.edu.tw/~cjlin/libsvm/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)