
机器学习知识积累
数据科学两大门派:统计学派.vs.机器学习学派
机器学习学派预测效果好,但是解释性不强,人们很难说明为什么就是工作的,为什么就是不工作的。。在图像识别(语音识别。。)领域机器学习(深度学习)虽然解释性差,但是确实有惊艳的表现;
统计学派往往使用线性模型或各种预设的分布假设去研究数据,解释性好,但是泛化预测能力差。。
机器学习的分类
是否需要人的监督和参与: supervised, unsupervised, semisupervised,reinforcement learning
是否能够渐进持续学习(learn incrementally on the fly): online .vs. batch learning
是否通过简单地比较新数据和已知数据还是洞察训练集中的pattern并且构建一个预测模型(就像科学家一样类似地工作):instance-based .vs. model based learning
这些分类的标准本身并不互相排斥,我们可以任意组合。比如一个好的spam邮件过滤系统可以使用由已知训练集训练过的一个深度神经网络持续on the fly学习。这构成一个online的model-based的监督式学习系统。
supervised learning(predictive model):
K nearest neighbours,线性回归,逻辑回归,SVM,决策树和随机森林,神经网络
典型监督式学习:垃圾邮件过滤器
unsupervised learning(descriptive model):
clustering聚类: K-means, Hierarchical Cluster Analysis(HCA),Expectation maximization
visualization and dimensionality reduction:PCA,Kernel PCA, Locally linear embedding(LLE),t-distributed stochastic neighbor embedding(t-SNE)
association rule learning: apriori, eclat
典型的非监督学习例子:访客画像,特征提取(比如汽车里程和年龄可以组合为汽车损耗系数新特征既实现了降维又实现了新特征的提取和替换),信用卡异常监测, association rule learning:超市中买了尿不湿的很大可能会买奶粉,那么我们将这两样物品摆放在比较近的位置。
semisupervised learning
一部分算法场景可能是数据有小部分具有标签,但是绝大部分是没有标签的。比如百度图片:每个头像分别在哪些照片中出现这个过程是clustering,属于无监督学习,随后我们指定一张照片中的头像是谁,那么就能知道哪个人在哪些照片中出现了,这属于监督式学习。
再比如,DBN(Deep belief network)是基于被称为restricted boltzmann machine(RBMs)的无监督组件一个个叠加起来。RBMs依次以无监督模式训练,然后整个系统使用监督学习算法更好的调整
Reinforcement learning:
在这里,学习系统被称为一个agent,可以观察环境,选择并执行对应动作,并且给到相应反馈(鼓励还是惩罚)。随后该算法应该学习到最佳的策略(术语policy). 一个policy定义了在给定场景下,agent应该选择什么行动。
比如很多机器人都会实现Reinforcement学习算法来学习如何走路。alphaGo也使用该算法,alphaGo通过分析上百万的游戏学习到赢的policy是什么样子。在alphaGo正式比赛的时候关闭学习过程,而只是将这些Policy应用到实战中。
Batch .vs. online learning
在batch learning下,系统无法"渐进"学习:必须使用全部的数据来做训练。这将会需要很长的时间和计算资源,因此基本上都是离线训练。部署模式为:学习获得trained model部署上线应用,但是不再学习!"offline learning".这种情况下,如果希望系统能够识别新的数据(比如能够识别新类型的垃圾邮件),必须使用新的数据训练出一个全新的模型。幸运的是我们可以比较容易实现自动化,即便我们无法实现真正online learning,也可以通过更新数据周期性地训练新模型来实现模型更替。然而,这样可以工作的前提是你必须有足够的计算和存储资源,但这并不总是满足的,比如在移动应用上,我们的计算资源是很有限的。因此我们必须寻找新的解决方案---online learning
model-based泛化机器学习基本流程:
1. 学习数据EDA
2. 根据数据学习选择一个合适的model
3. 训练model
4. 部署该model做泛化
5. 部署人工性能评估工具(monitoring tool),周期性地监控Model性能并分析原因,重新训练和部署
争取将常规的model训练选择部署自动化
机器学习的主要挑战:
既然机器学习的主要任务是选择一个合适的算法使用已知的数据来做训练,那么重要的挑战也就有两条:1.错误的模型假设;2.错误的输入数据
心法:数据决定了机器学习的上限,学习算法只能无限逼近这个上限
非常重要的一点是:你必须使用能够代表你需要泛化到的case的数据来做训练,否则模型效果不可能优秀。优良的数据须解决两个问题:采样噪声(sample noise),以及采样偏差(sampling bias)\
特征工程:
1. feature selection:选择哪些最有用的特征;
2. feature extraction:组合现有的特征产生一个更加有用的特征(比如降维PCA算法)
3. creating new feature:搜集新的数据获取新的更加关注的特征
算法带来问题:
过拟合(over fitting)
regularization是缓解过拟合的有效手段,其原理是,比如对于线性回归,我们允许修改$\theta_1$但是强制它必须比较小,那么算法会生成一个介于1到2之间自由度的模型!折中了!
机器学习dataset资源:
http://archive.ics.uci.edu/ml/index.php
https://www.kaggle.com/datasets
http://aws.amazon.com/fr/datasets/
—http://dataportals.org/
—http://opendatamonitor.eu/
—http://quandl.com/
—Wikipedia’s list of Machine Learning datasets
—Quora.com question
—Datasets subreddit
数据集train/test切分注意事项:
最好不要纯粹做随机抽样8、2分成,因为很有可能我们取得的数据是skewed的,需要确保train/test的数据分布和总体是一致的。一个可行的方案是:拿出最重要的feature,然后根据样本总体中随该feature的分布比例照样随机抽取,确保train/test数据的分布和总体是一致的。
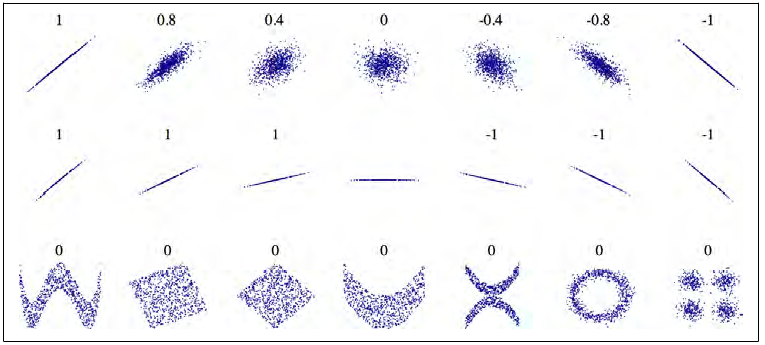
特征相关性指标相关系数corelation coefficient(Pearson'r)矩阵
注意Pearson'r参数仅能表征两个变量之间的线性相关程度,对于非线性关系则无法描述。比如最后一行的图中虽然相关系数为0,但实际上他们明显存在非线性的关系
图形化库matplotlib
什么是matplotlib的backend?
https://matplotlib.org/tutorials/introductory/usage.html#what-is-a-backend
matplotlib可以被多种不同的场景并支持不同的输出格式。很多人从python shell中交互模式地使用matplotlib,当他们敲出相关命令时会弹出绘图窗口。而又有很多人将matplotlib嵌入到富交互应用的图形用户接口中,比如wxpython, pygtk。还有一些人在batch script中使用matplotlib以便从一些数字仿真中产生postscript image.还有一些人则将matplotlib作为web app专门用于serve图表。为了支持这些use case,matplotlib可以target这些不同的输出类型和场景,每种这类能力都被称为一个“backend”;而frontend指用户直接面对的代码,比如:plotting code,而backend则在幕后执行所有产生图片的繁重工作。总的来说,有两种类型的backend: user interface bakcends(用在pygtk,wxpython,tkinter,qt4,或者macosx中),也往往被称为"interactive backends"以及hardcopy backends来生成image文件(PNG, SVG,PDF,PS),这种类型也被称为non-interactive backends.
判别模型(discriminative) vs生成模型(generative)

逻辑回归算法简单,对特征工程的要求就非常高。必须做特征归一化,否则各特征重要程度不一。
http://www.cnblogs.com/maybe2030/p/6336896.html
特征正规化
from sklearn import preprocessing df['normized'] = preprocessing.scale(df['non-normalized'])
L1 Distance/L1-Norm .vs. L2 Distance/L2-Norm
L1 = sum(abs(t1_i-t2_i))
L1-norm = |A|+|B_1|+... + |b_n|
L2 = sqrt(sum(t1_i-t2_i)^2)
bias .vs. variance
http://ogrisel.github.io/scikit-learn.org/sklearn-tutorial/tutorial/astronomy/practical.html
low bias: 对数据符合一个model(比如我们假设数据符合线性模型)没有强假设(没有假设一定要用线性模型),会将数据本身被model拟合看得更加重要,对model本身参数(比如线性模型的a,b两个参数)重要性看得更轻一些。往往会产生更加复杂的模型(比如产生多项式拟合的模型),过拟合风险加大, overfit
high bias:有对数据分布的model强假设,比如假设数据分布为线性关系,会认为数据遵循model更加重要,而对数据本身是否能够完全拟合并不是非常关心,这往往导致model过于简单.under fit
Regression就是典型的high bias算法
Decision Tree, 深度神经网络就是high variance的典型

我们再来看使用交叉验证的场景下,过拟合欠拟合的特征:
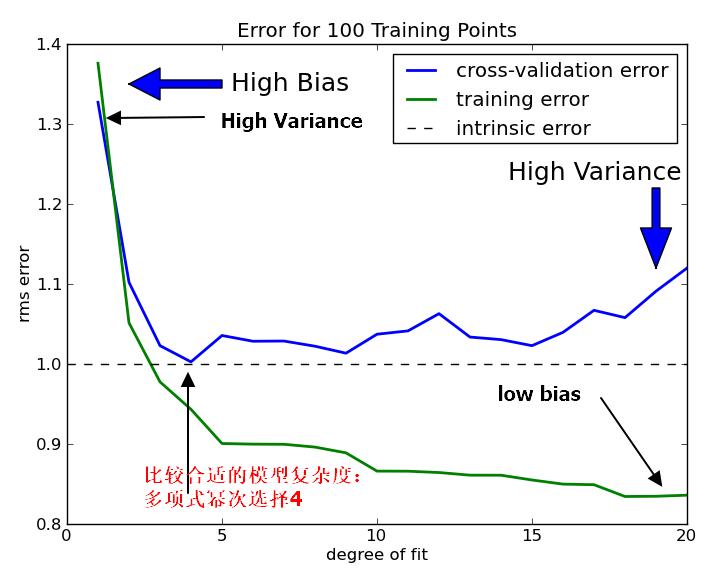
学习曲线是判断模型是否overfit还是underfit的一个重要依据
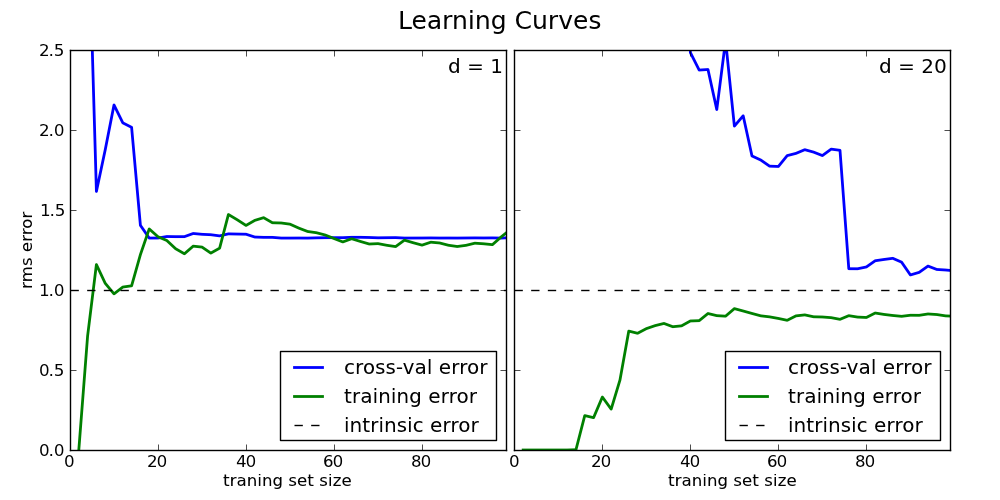
上图我们分别对high-bias和high variance的两种模型分别调整train set数量来看在不同训练集样本数的情况下,其训练误差及测试误差的变化情况。左边的图是high-bias(underfit)的典型图例:traing error和test error都很高,这种情况下,即使增加再多的测试数据集也不会有多大帮助,两条线都渐进收敛域一个相对高的error值;
右面的图则是一个high-variance的模型(过拟合):训练错误远远小于验证集错误。随着我们增加更多的数据到训练中,训练错误持续攀升,而test error会持续下降,直到趋于中值。
处理overfit的几种手段:
cross-validation
regularization
Lasso Regression:使用L1-Norm$Loss = \sqrt {(y-y^{predict})^2}+\alpha(|A|^2+|B|^2)$
Ridge Regression:使用L2-Norm作为正则惩罚项($Loss = \sqrt {(y-y^{predict})^2}+\alpha(|A|+|B|)$)
drop off(神经网络)
机器学习知识小结
模型融合和集成学习是不同的哦。
比如集成学习: 弱学习机(往往算法类型单一元学习机)-》组合形成一个强学习机
模型融合:强学习机(多个)强强结合形成一个更强的模型
voting, averaging, bagging, boosting, stacking:
比如
SVM(y1)+
GBGT(y2)+
LR(y3)
通过voting,众人智慧. averaging:往往用于回归问题
特征选择:
1. 去掉方差特别小的特征
2. 相关性:特征之间最好无相关性,特征与目标有强相关性。基于统计学的方法,相关性或者协方差为1,则正相关
1.coding的数据结构,算法设计是要求用python吗?
用伪代码都行。。
2.怎么判断特征与目标的相关性?
统计学Pirson,
3.请问在人工智能的公司中有哪些岗位分别是什么角色及其工作是什么?
推荐算法增加CTR,
数据挖掘,
数据分析:分析先有的业务数据
人脸识别指纹解码
机器学习的一般步骤
业务问题抽象,比如从log中发现一些有用的特征:
数据获取,比如log: kafe,hbare,hdfs
特征工程
模型训练,调优,
模型验证,误差分析,误差小的
模型融合
模型上线
多参数调参方法: grid search:可以调整步长,逐步细分范围
XGBoost算法主要参数及其作用,高纬稀疏不适合用XGBoost,可能需要深度学习算法
所谓并行计算:样本(数据)纬度和特征纬度的并行。 比如特征和特征之间可以并行,再比如样本和样本之间可以并行计算
L1正则为何产生稀疏解: 黄色为约束区域,蓝色的为可行解区域。 结构风险最小化:参数越简单
数据不均衡问题的解决方案:
1. 训练集随机欠(多的减少)的采样和过采样(少的倍增)
2. 设计适合不均衡数据集的模型
3. 聚类丰富类, 比如100万 vs 100的数据 先用kmeans k=100做训练,生成100个中心,这100个中心外加100个数据作为新的样本集做训练
集成学习大部分都是基于决策树,决策树容易过拟合,但是集成的决策树不容易产生过拟合
SVM曾经是算法一哥,结构风险最小化,泛化错误率低,只能解决小样本,只能处理小数据集,大数据集计算开销太大
CNN适合解决具备相关性的问题,RNN适合解决时序性问题,企业界都不用
LR不单用,一般联合使用 GBDT+LR , wdie & deep最后交给LR来做
adaboost是boost界元老
大规模机器学习
spark mllib:容错能力强,但是性能不强
mpi: 分布式高性能计算,没有容错,但是效率会高一些,小规模数据比较好
PS: 参数服务器,在比spark规模更大的机器学习平台
以上三种都是适合于用于批量训练(基于全体的训练集训练)
但是也可以使用增量式学习,在线学习来解决批量式学习,或者SGD:随机选择一部分样本来学习,对参数调整,
从最大似然估计到EM算法
https://blog.csdn.net/zouxy09/article/details/8537620
ensemble模型训练到部署到设备桥梁利器: treelite
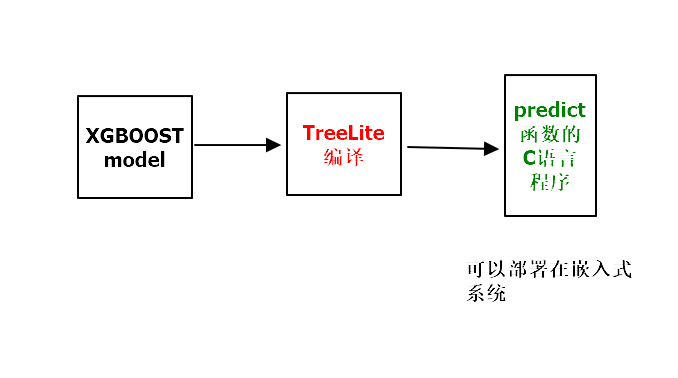
https://treelite.readthedocs.io/en/latest/tutorials/first.html

