
机器学习数学知识积累之数理统计
数理统计
概率论是从已知分布出发,来研究随机变量$X$的性质,规律和数字特征等
数理统计以概率论为理论基础,研究怎样用有效的方法去收集整理,分析带随机影响的数据,以便对所研究的问题给出估计和推断。数理统计研究对象$X$的分布并不知道,或者不完全知道,我们通过观察它的取值(采集数据),通过分析数据来推断$X$服从什么概率分布。
在数理统计中,最基本的研究问题的方法是:“以部分数据信息来推断整体相关信息”
数理统计可以分为两类:
- 描述统计学:对随机现象进行观测,试验以便取得有代表性的观测值(统计量)
- 推断统计学:对已经取得的观测值进行整理,分析,做出推断和决策,从而找出所研究对象的规律性.
概率论/数理统计/统计学
已知一个数据产生过程(随机分布,随机过程,...)对观测数据作出推测的是概率论研究的内容。
已知观测数据(样本)对数据产生过程作出推测的是统计学。
数理统计可以理解为统计里的数学部分,即是统计学的理论基础,但是同时也是概率论的应用领域。
从数学的逻辑严密程度上来说,或者说更数学的程度看:(由小到大排序)
统计学< 数理统计 < 概率论
概率论和数理统计的关系
概率论是数理统计的理论基础,数理统计是概率论的重要应用
重要概念
总体:
研究对象的全体
总体可能是有限的,也可能是无限的。比如某大学3000名大一学生的身高,体重。。共3000名大学生,因此是有限的总体
也可能是无限的,比如测量一个湖泊任意点的深度,这时点是无穷多的
个体:
总体中的某个成员。比如一名大学生,湖泊的一个测量点
在数理统计中,人们往往关心的是总体中的每个个体的一项或多项指标(feature)和该指标在总体中的分布情况。
由于人们往往关心总体的某项数量指标,我们把该指标记为$X$,其不同的个体取值不同。我们往往用$X$来等同总体。总体就可以用随机变量$X$及其分布来描述
样本:
按一定的规则从总体中抽取的一部分个体
样本容量
样本中所包含的个体的数量就叫做样本容量。比如3个人的样本
抽样:
从总体中抽取样本的过程就是抽样。由于抽样的随机性,样本也具有随机性,容量为n的样本用随机变量$X_1,X_2,...,X_n$来表示
简单随机样本:
若样本中的个体$X_1,X_2,..,X_n$是相互独立的(独立性)且与总体X有相同的分布(代表性),则称$X_1,X_2,..,X_n$为来自总体$X$的一个容量为$n$的简单随机样本,简称为X的一个样本
样本值:
样本($X_1,X_2,..,X_n$)的每一个观测值($x_1,x_2,...,x_n$)称为样本值,或者样本的一次实现。想象一下我们研究骰子厂10000个产品(总体)的质地均匀情况,我们抽取100个作为样本,分别投掷一次,记录其点数,则每一次投掷取得的100个点数集合就是样本值,是这组100个骰子样本的一次实现,每一个样本的点数$X_1,X_2,X_n$组成了独立同分布的随机变量序列
样本空间:
样本值的集合被成为样本空间
由于总体分布决定了样本取值的概率规律,因而可以用样本值去推断总体。
数理统计的重要任务就是研究如何根据样本去推断总体。
样本分布(联合分布)
如果总体$X$的分布函数为$F(x)$, $X_1,X_2,..,X_n$为来自$X$的一个样本,则样本($X_1,X_2,..,X_n$)的联合分布函数就为:
$$F(x_1,x_2,...,xn)= \prod_{i=1}^{n}F(x_i)$$
样本,个体,特征(feature),观测值
$$ \begin{matrix}Sample&&X&Y&Z\\1&\rightarrow &X_1(x_{1})&Y_1(y_{1})&Z_1(z_{1})\\2&\rightarrow &X_2(x_{2})&Y_2(y_{2})&Z_2(z_{2})\\3&\rightarrow &X_3(x_{3})&Y_3(y_{3})&Z_3(z_{3})\\n&\rightarrow &X_n(x_{n})&Y_n(y_{n})&Z_n(z_{n})\end{matrix} $$
$X,Y$是要考察的个体的feature(随机变量),$Z$为每个个体随特征变量决定的输出值(比如收入是否大于50k,是否购买,是否点击广告...)。每行为一个个体的所有feature记录,每一列$x_1,y_2$都对应着随机变量$X_1,Y_2$的一个观测值。注意:$X_1,Y_2$可以理解为$X_i,Y_i$随机变量序列中的一个随机变量。而$x_1,y_2$可以理解为该随机变量的观测值。$X_1,Y_2$虽然代表了一个独立的样本,一旦采样就确定了,没有随机性,但是由于抽样具有随机性,因此可以理解为$X_1,Y_2$也是一个随机变量,因为下一次再采样的话,其观测值就会不同,因此可以将$X_1,X_2,..,X_n$视为独立同分布随机变量序列。
使用统计学方法就是要研究各feature的观测值去推断整体,并且建模研究输出$Z$这些feature之间的关系

数理统计的理论基础
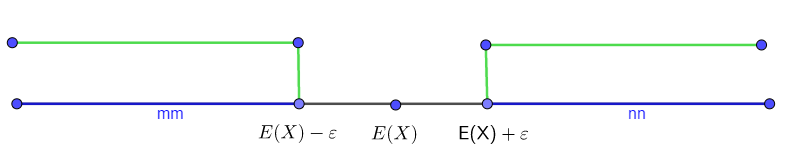
切比雪夫不等式-概率区间估计
对于任意随机变量$X$,如果其方差$D(X)$存在,则对任意$\varepsilon > 0$,有
$$P(|X-E(X)| \geq \varepsilon)\leq \frac{D(X)}{\varepsilon ^2}$$
或:
$$P(|X-E(X)| < \varepsilon)\geq 1-\frac{D(X)}{\varepsilon ^2}$$
该定理常用于概率的粗略估计,其几何意义如下:
伯努利大数定理:
在n重伯努利实验中,$Y_n$是事件A发生的次数,p是事件A的概率,那么对于任意$\varepsilon$
$$\lim_{n->\infty }P(|\frac{Y_n}{n}-p|< \varepsilon ) = 1, $$
伯努利大数定理为使用频率来确定概率的理论依据。也就是说可以利用有限的data来研究无限的空间
独立同分布随机变量序列:
若随机变量序列$X_1,X2,....X_n$相互独立,对$n\geq 2$, $X_1,X_2,...X_n$独立,且有相同的分布函数,则称$X_1,X_2,...X_n$是独立同分布的随机变量序列,比较形象的例子是:做实验掷骰子记录出现各点的点数,共有${1,2,3,4,5,6}$个样本,如果将两个骰子一把扔出去,记录其点数之和,则样本$2,3,4,...,12$,两个骰子的取得的点数分别记为$X_1,X_2$则他们互相独立并且同分布,同理,同时扔3个骰子,则形成三个独立同分布随机变量$X_1,X_2,X_3$,他们也是独立同分布骰子数量足够大时,考察$X_1+X_2+...+X_n$的分布,会发现近似于满足正态分布。
一般的,我们可以将机器学习中的feature列作为随机变量$X_1,X_2...$,如果他们独立同分布,则也有以下中心极限定理。
http://www.muelaner.com/uncertainty-of-measurement/
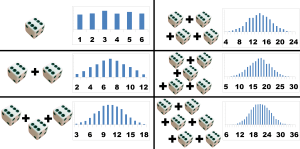
独立同分布下的中心极限定理:
$$\sum_{i=1}^{n} X_i \sim N(n\mu,n\sigma^2)$$
切比雪夫大数定理(辛钦大数定律)
设$X_1,X_2,...X_n$是独立同分布的随机变量序列,且$E(X_i) = \mu ,(i=1,2,3,...)$,则对$\forall \varepsilon > 0$
$$\forall \varepsilon, \lim_{n->\infty }P(|\frac{1}{n}\sum X_i-\mu|< \varepsilon ) = 1$$
该定律给出了随机变量序列的统计量:算数平均值(依概率收敛于)稳定于数学期望的理论基础,反过来,我们可以使用均值当作数学期望
样本矩的大数定理
$$\widehat{a_k} = A_k = \frac{1}{n} \sum_{i=1}^{n} X_i^k \xrightarrow[n-> \infty]{P} a_k = E(X^k), k = 1,2,...,m$$
$$\widehat{\theta} = h(A_1,A_2,...,A_m) \xrightarrow[n-> \infty]{P} \theta = h(a_1,a_2,...a_m)$$
样本的k阶原点矩以概率收敛于总体的k阶原点矩,样本的矩函数以概率收敛于总体的矩函数
大数定律的意义
给出了频率稳定性的严格数学解释;
提供了通过试验来确定事件概率的方法;
是数理统计中参数估计的重要理论依据之一;
是Monte Carlo方法的主要数学理论基础
Monte Carlo方法利用大数定律模拟解决不规则图形的面积求解

隶莫佛-拉普拉斯定理
如果随机变量$Y_n$服从参数n,p的二项分布,则对充分大的n,有$$Y_n \sim N(np,npq) , q=1-p$$,近似有以下近似公式:
$$P(a<Y_n\leq b)\approx \phi (\frac{b-np}{\sqrt{npq}}) - \phi (\frac{a-np}{\sqrt{npq}})$$
统计量
数理统计由样本推断总体,我们需要对样本值进行"加工",这就要构造一些样本的函数(统计量),它把样本中所含的某一方面信息集中起来,用于对总体进行推断和把握。
统计量依赖且只依赖于样本x1,x2,…xn;它不含总体分布的任何未知参数。从样本推断总体(见统计推断)通常是通过统计量进行的。例如X1,X2,…,Xn是从正态总体N(μ,1)(见正态分布)中抽出的简单随机样本,其中总体均值(见数学期望)μ是未知的,为了对μ作出推断,计算样本均值。可以证明,在一定意义下,包含样本中有关μ的全部信息,因而能对μ作出良好的推断。这里只依赖于样本X1,X2,…,Xn,是一个统计量。注意:统计量由于是样本这些n个随机变量的n元函数,因此统计量也是一个随机变量。具体的统计量的一次观测值就是利用样本计算出来的统计量的值。我们也需要研究统计量的数字特征和概率分布,以便使用这些统计量去推断总体。确定统计量的分布是概率统计的基本问题之一。
期望($E[X]$)和均值
均值是一个统计学概念,是后验数据,是对统计得到的样本取均值;
期望是概率与数理统计的概念,是先验数据,是根据经验的概率分布“预测"的样本均值,是随机变量总体的一个数字特征
如果我们的概率分布是正确的假设的话,那么当实验次数足够大时,样本的均值就趋向于期望。
数学期望的计算性质
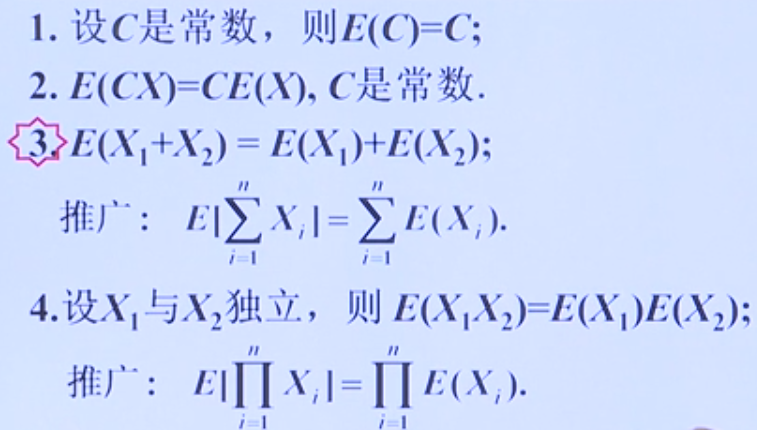
离散型随机变量的期望:
$$E[X]=\sum p_ix_i$$
如果说概率是频率随样本趋于无穷的极限,那么期望就是平均数随样本趋于无穷的极限
常用分布的数学期望和方差:

连续型随机变量的期望:
$$E(X) = \int_{-\infty }^{+\infty}x \cdot f(x)dx$$
可以看到实际上就是用x代替离散型定义的$x_i$,用$f(x)dx$代替离散型定义的$p_i$,其中$f(x)$是随机变量x的概率密度函数
随机变量函数的期望
设$Y = g(x)$,则:
1. 如果x是离散型变量:
$$E(Y)=E[g(X)]=\sum g(x_i)p_i$$
2. 如果x是连续型变量:
$$E(Y) = E(g(x)) = \int_{-\infty }^{+\infty}g(x) \cdot f(x)dx$$
方差$D(X)$
定义:$D(X) = E[X-E(X)]^{2} $ 也就是说方差是$[X-E(X)]^{2}$的数学期望(均值)
常用计算公式 $D(X) = E(X^{2}) - (E(X))^{2}$
方差$D(X)$的性质
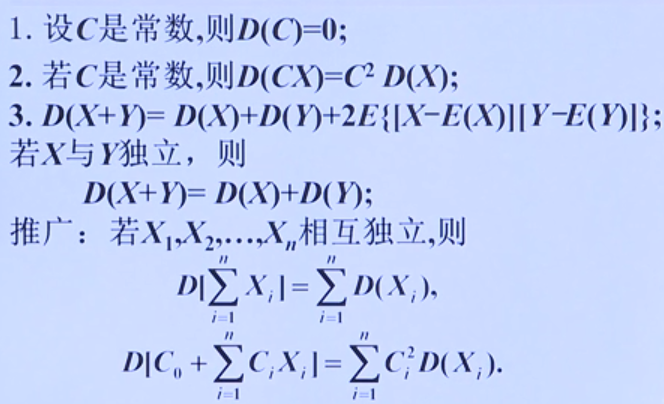
协方差及相关系数
先假设有两个随机变量$X,Y及其均值分别为\bar X, \bar Y$,这两个随机变量容量为n的样本,我们由$X,Y$构造两个向量(可以这么认为,对于随机变量组成的向量,其均值才是原点):
$\vec{x} = (X_1-\bar X, X_2-\bar X,..,X_i - \bar X,..X_n-\bar X); \vec{y} = (Y_1-\bar Y, Y_2-\bar Y,..,Y_i - \bar Y,..Y_n-\bar Y)$
样本方差
$S_X^{2} = \frac{1}{n-1}\sum_{i=1}^{n}(X_i-\bar X)^2 = \frac{\vec{x} \cdot \vec{x}}{n-1}$
$S_Y^{2} = \frac{1}{n-1}\sum_{i=1}^{n}(Y_i-\bar Y)^2 = \frac{\vec{y} \cdot \vec{y}}{n-1}$
样本协方差:
样本计算式:$S_{XY} = \frac{1}{n-1}\sum_{i=1}^{n}(X_i-\bar X)(Y_i-\bar Y) = \frac{\vec{x} \cdot \vec{y}}{n-1}$
理论定义式:$Cov(X,Y) = E([X-E(X)][Y-E(Y)]) = E(XY) - E(X)E(Y)$
若X,Y互相独立,则$S_{XY},Cov(X,Y) = 0$ ,协方差为0;$S_{XY},Cov(X,Y) > 0 $ 则称X,Y是正相关;若$ S_{XY},Cov(X,Y) < 0 $ 则称X,Y是负相关
若协方差为0,不能推出$X,Y$独立,也就是说虽然线性无关,但是有可能非线性方式相关。独立是一个强条件,是没有任何关系
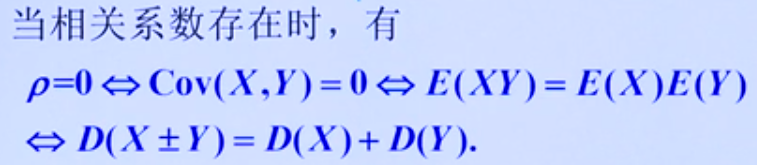
特征工程中,如果两个变量的协方差绝对值比较大的话,则说明X,Y是线性相关的,那么就应该剔除掉一个,否则出现"多重共线性"
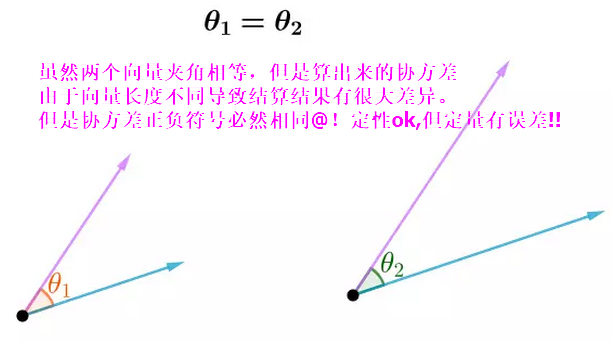
一般来说通过协方差就能描述两个向量之间的关系了,但是由于协方差的值会受到向量长度本身的影响,因此很难判断其相关的程度,为解决该问题,我们引入相关系数这个概念以消除向量长度的影响。
给定一个特征向量$(X_1,X_2,...,X_n)$两两计算其协方差会形成一个nxn的协方差矩阵,这个矩阵在PCA降纬时使用.

$$C= \begin{bmatrix} c_{11} & c_{12} & ... & c_{1n}\\ c_{21} & c_{22} & ... & c_{2n}\\ ... & ... & ... & ...\\ c_{n1} & c_{n2} & ... & c_{nn} \end{bmatrix}$$
相关系数:
样本计算式:$r = \frac{\vec{x}\cdot \vec{y}}{|\vec{x}|\times |\vec{y}|}=cos(\theta)$
从这个定义中我们看出,相关系数实际上是描述$X,Y$分别相均值平移后的向量夹角的余弦值,范围为$(-1,+1)$,如果为0表示向量正交垂直,说明两向量无关,如果为1,则线性正相关,如果为-1则线性负相关。
理论定义式:$\rho _{XY} = \frac{Cov(X,Y)}{\sqrt{D(X)}\sqrt {D(Y)}}$
当$\rho _{XY}$ 为1时,说明完全线性相关,如果比较小,则说明线性相关程度越低
散点图和相关系数值的直观映射

互信息$I(X,Y)$
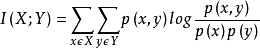
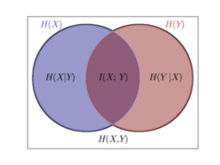
https://baike.baidu.com/item/%E4%BA%92%E4%BF%A1%E6%81%AF
http://www.cnblogs.com/liugl7/p/5385061.html
决定系数(coefficient of Determination)和相关系数(correlation of Coefficient)
https://blog.csdn.net/danmeng8068/article/details/80143306
先看以下几个定义:
a. Sum of Squares Due to Error

b. total sum of squares

c. sum of squares due to regression

以上三者之间存在以下关系:

决定系数用于判断回归方程的拟合程度,也就是通过model得出的因变量的变化有百分之多少可以由自变量来解释,从而判断拟合的程度。在Y的总平方和中,由X引起的平方和所占的比例,记为$R^{2}$ (R的平方). 当$R^{2}$接近于1时,表示模型参考价值越高,

相关系数:测试因变量自变量之间的线性关系的,也就是说自变量发生变化时,因变量的变化情况如何


似然函数,损失函数和最大似然估计
https://www.cnblogs.com/hejunlin1992/p/7976119.html
似然函数是关于统计模型中的参数函数,表示模型参数的似然性。往往通过求解当似然函数最大时的参数作为最优参数
损失函数则是机器学习中用于度量模型效果的函数,他是模型参数的函数,给定数据集,只和模型参数有关。
常用统计量(统计量不允许有任何未知参数,只和样本数据本身有关)
样本均值$\bar X = \frac{1}{n}\sum_{i=1}^{n}X_i$
用途:当总体均值$E(X)=\mu$未知时(基本上都是未知的!),我们使用样本的均值$\bar X$来估计总体均值$\mu$.
注意这样做的理论基础是切比雪夫大数定理
样本方差
$$S^{2} = \frac{1}{n-1}\sum_{i=1}^{n}(X_i-\bar X)^2 = \frac{1}{n-1}(\sum_{i=1}^{n}X_i^2 - n {\bar X}^2)$$
样本标准差
将方差开根号
用途:用样本的标准差$S^2$去估计总体方差$\sigma ^2$
矩
$E(X^k)$ : k阶原点矩
$E[(X-E(X))^k]$ : k阶中心矩
$E(X^kY^l)$ :(k,l)阶联合原点矩
$E[(X-E(X))^k(Y-E(Y))^l]$ : (k,l)阶联合中心矩
期望是一阶原点矩,方差是二阶中心矩,协方差是(1,1)阶联合中心矩
样本k阶原点矩
$$A_k = \frac{1}{n}\sum_{i=1}^{n}X_i^k, k = 1,2,..$$
$$\bar X = A_1 = \frac{1}{n} \sum_{i=1}^{n} X_i$$
用途,当总体的k阶原点矩 $E(X^k) = a_k$未知时,使用该值估计总体
样本k阶中心原点矩
$$B_k = \frac{1}{n}\sum_{i=1}^{n}(X_i-\bar X)^k, k = 1,2,..$$
用途:以样本去评估总体
样本的2阶中心矩$S^{*2}$ 或者记为$S_n^2$
$$S^{*2} = B_2 = \frac{1}{n}\sum_{i=1}^{n}(X_i-\bar X)^2 = \frac{1}{n}\sum_{i=1}^{n} X_i^2 - {\bar X}^2$$
我们可以使用该参数来估计总体方差$D(X)$.
注意样本方差$S^2$与样本2阶中心矩$S^{*2}$的关系:
$$S^{*2} = B_2 = \frac{1}{n}\sum_{i=1}^{n}(X_i-\bar X)^2 = \frac{(n-1)S^2}{n}$$
顺序统计量:
将样本($x_1,x_2,...,x_n$)从小到大排序,并且变换下标$x_{(1)},x_{(2)},...,x_{(n)}$,
$X_{(1)}$为最小顺序量, $X_{(n)}$为最大顺序量
样本中位数(median)
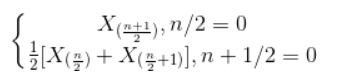
样本极差
$$R=X_{(n)} - X_{(1)}$$
样本几何均数
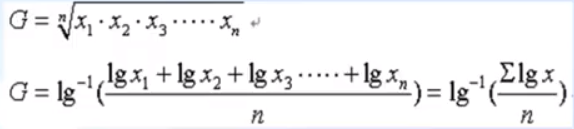
变异系数(标注差率)(coefficient of variation, CV)
主要用于描述数据的相对离散程度,特别是对于多个指标的变异程度进行比较时,如果数据本身的量纲或者均值不同时,将会由于数据的绝对大小的不同而失去横向比较的意义,因此使用下式剔除相关量纲的影响:(否则,如果量纲及均值都相同时,也可以直接用标准差去度量和比较两个变量的变异程度)
$$CV = \frac{S}{\bar X }\times 100 \% $$
分类变量的统计描述:统计量
相对数
比(Ratio)
又称为相对比,表示两个有关联的指标之比。
比如:
性别比(Sex Ratio) = 男性人口数/女性人口数 X 100
体质指数(BMI) = 体重(kg)/身高平方
比例(Proportion)(小于等于100%)
指事物内部各部分所占的比重(又称为构成百分比).
比如高血压患病率
率(Rate)
表示单位时间内某时间发生的频率
统计量的几个性质
设总体$X$指标$E(X) = \mu$,方差$D(X) = \sigma ^2$, $(X_1,X_2,...,X_n)$为取自该总体的一个样本,那么该样本的统计量随机变量
$\bar X, S^2, S_n^2$其期望及方差有以下性质:
1)$E(\bar X) = \mu, D(\bar X) = \frac{\sigma ^2}{n}$
2)$E(S^2) = \sigma ^2, E(S_n^2) = \frac{n-1}{n}\sigma ^2, n\geq 2$
统计推断
由样本到总体的推理就称为统计推断。常用的统计推断有三种基本形式:
抽样(样本函数)分布,参数估计和假设检验
抽样(样本函数)分布
当用统计量推断总体时,须知道统计量(随机变量)的分布,统计量的分布属于样本函数的分布,人们把样本函数的分布统称为“抽样分布”
数理统计中常用做置信估计的概率分布模型:卡方分布,t分布, F分布
需要注意的是统计学中的卡方分布,t分布,f分布与概率论中对随机变量分布定义的区别。在概率论中:我们一般给出符合某种概率分布律或密度分布特征的分布分别称呼为泊松分布,指数分布,正态分布,几何分布等等。但是在统计学(数理统计)中,我们却并未给出统计量(随机变量)的密度函数给大家,原因是在统计中,是以数据为基础对总体的推断,面向的是样本,需要强调的是样本来源于哪里,经过整理后得到的结果是什么样子的,这个样子的统计量就符合什么分布。比如卡方分布,我们得到一批来自正态总体的一个样本$X_1,X_2,..,X_n$,随后凡是整理成$X_1^2+X_2^2+...+X_n^2$这个样子的统计量就符合卡方分布.而卡方分布的密度函数需要n重积分,一般不要求证明。同时其密度函数一般也没有解析表达式,往往通过数值方法预先给出然后查表取得概率值
卡方分布
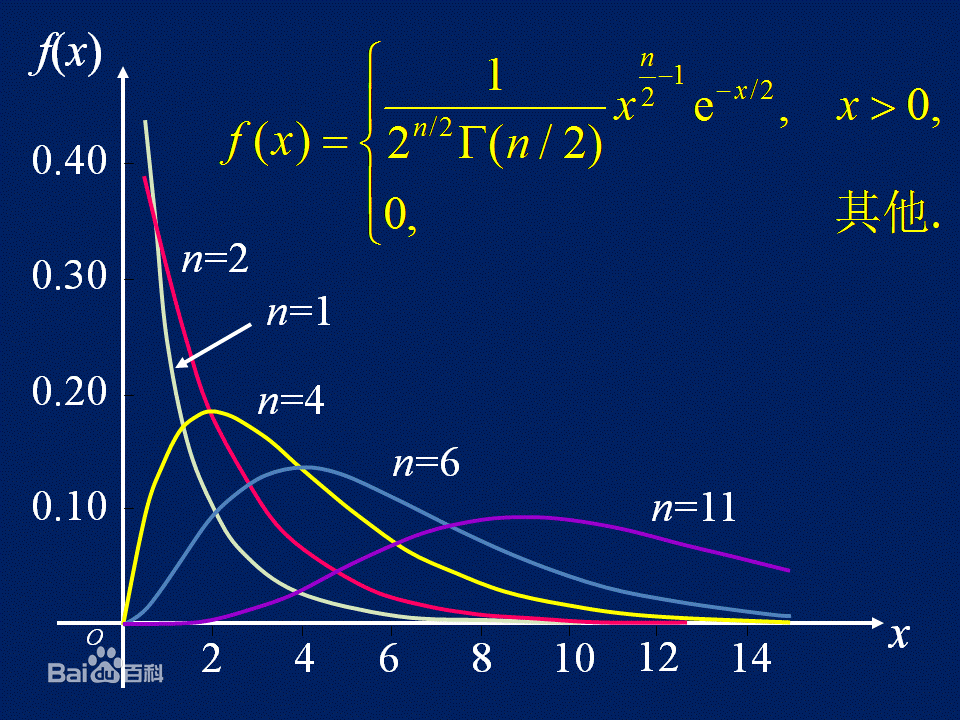
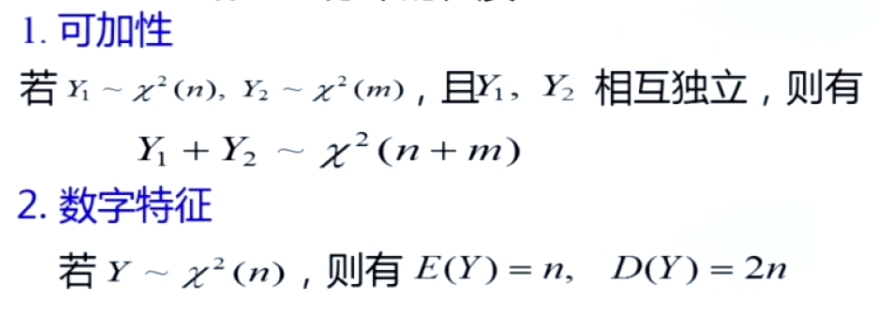
t分布
如果一个随机变量是由一个服从正态分布的随机变量除以一个服从卡方分布的变量组成的,则该变量服从t分布,t分布是正态分布的小样本形态。
比如对于正态分布样本的均值变换为$t = \frac{\bar X - \mu}{S_{\bar X}} = \frac{\bar X - \mu}{S/ \sqrt n}$后就服从自由度为n-1的t分布
t分布是于自由度$v$有关的一组曲线,随着$v$的增大接近标准正态分布
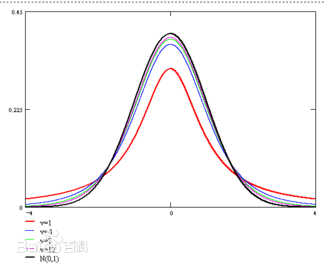
F分布
设$X,Y$是两个相互独立的遵循卡方分布的随机变量$X \sim \chi ^2(n_1),Y \sim \chi ^2(n_2)$,则
$F = \frac{X/n_1}{Y/n_2} = \frac {n2}{n1} \cdot \frac {X}{Y} \sim F(n_1,n_2)$服从自由度为n1,n2的F分布

单个正态总体统计量抽样分布
由于抽样分布(统计量的分布)是一个n维随机变量函数的联合分布,一般来说非常复杂,我们只研究与正态总体相关的抽样分布:卡方分布,t-分布, F-分布.
如果$X_1,X_2,...,X_n$是总体$N(\mu,\sigma^2)$的一个样本,其样本均值$\bar X = \frac{1}{n} \sum_{i=1}^{n} X_i$, 服从$ \bar X \sim N(\mu, \frac{\sigma ^2}{n})$
其他性质:


上面的定理1.属于基本结论,定理2常用于单个正态整体均值推断,区间估计,精度分析,假设检验
两个正态整体统计量分布

定理3用于比较两个正态整体方差,精度,稳定性比较的推断

定理4用于两个正态整体均值差的统计推断问题,注意定理4要求两个样本方差一样,方差齐性
均数的抽样误差
在抽样研究中,由于抽样造成的样本均数与总体均数之间的差异或者样本均数之间的差异,称为均数的抽样误差。(sampling error)抽样误差是不可避免的,造成抽样误差的根本原因是个体变异的客观存在。
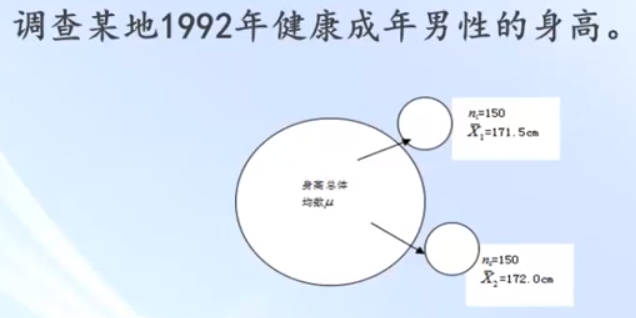
抽样误差的计算-标准误

不同样本之间均值差异的来源
1. 如果来自同一总体,则差异仅由抽样误差造成;
2. 如果两个样本来自不同总体,则差异可能由两个总体之间的不同造成的。比如男生身高的样本均值可能不同,这又有可能两个样本本身就不是来自同一总体,
比如:一个样本取自北方的男性,而另一个样本来自南方的男性,一般来说北方的均值要高于南方。。而如果样本来自同一整体,也就是说既考虑了南方,又考虑了北方的男性,那么样本均值不同就是抽样误差造成的了。而抽样误差本身是不可避免的!我们只能结合置信区间的参数估计去做有信息的估值。
3. 系统误差:比如测量方法的不同,测量仪器的不同,测量仪器本身就不准确,具有系统误差,这时计量数据就带有系统误差,系统误差是可以解决的
分位点及在标准正态分布,卡方,t分布,F分布中分位点查表方法(注意小于0.5时可能需要用到性质)

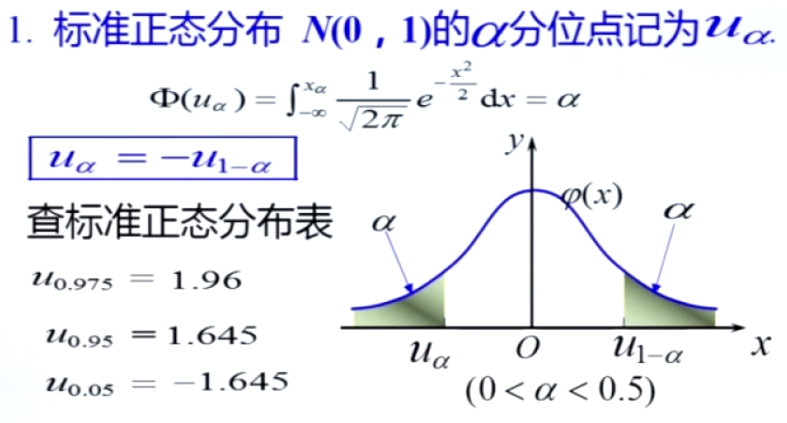

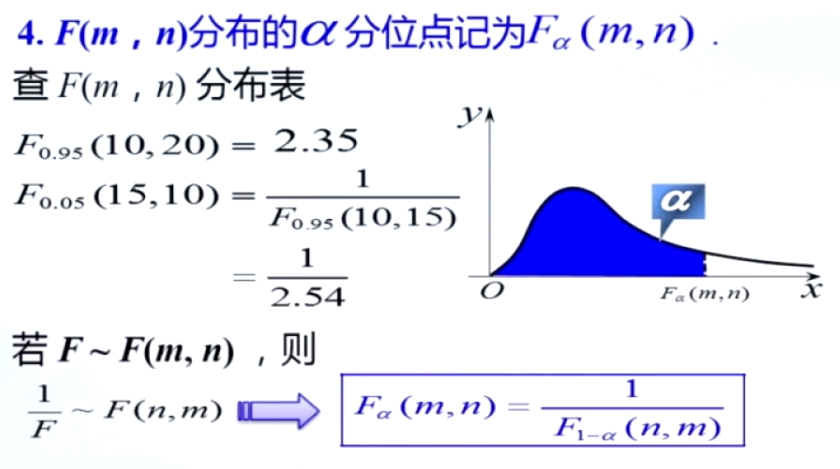
非正态总体样本均值,方差等统计量分布
参数估计
参数估计是利用从总体抽样得到的信息来估计总体的某些参数或者参数的某些函数.比如估计产品的合格率,估计降雪量,估计湖泊中的鱼的数量
设有一个统计总体,总体的分布函数已知$F(x,\theta)$,其中的$\theta$是未知参数,现在从该总体中取样本$X_1,X_2,...X_n$,要求我们根据样本对参数$\theta$做出估计,或者估计$\theta$的某个已知函数$g(\theta)$,这类问题就是"参数估计"问题
点估计
利用样本$X_1,X_2,..,X_n$确定一个统计量$\widehat{\theta} = \theta (X_1,X_2,..X_n)$,用该统计量去估计总体的未知参数$\theta$,该统计量也称为参数$\theta$的估计量,其中如果使用最大似然估计方法求得的估计量我们称为最大似然估计值。(估计值由于是统计量,因此他是一个确定的实数,只和样本本身有关)具体地,我们使用样本的观测值$x_1,x_2,..,x_n$去算得一个统计量,用于估计未知参数,常用的估计方法有矩估计法和最大似然估计法。但是点估计没能反映出估计的误差范围,使用起来把握有多大。
矩估计法:
思想:用样本矩估计总体矩,用样本矩函数估计总体矩函数,据此求解已知概率模型中的未知参数值,其理论依据为大数定理(样本的k阶原点矩以概率收敛于总体的k阶原点矩,从而样本的矩函数(本质为矩的线性组合)以概率收敛于总体的矩函数)。
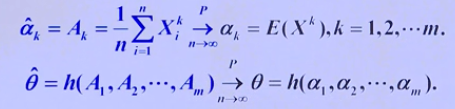

最大似然估计法(MLE)
设总体分布为$f(x,\theta )$, $X_1,X_2,...,X_n$为该总体采样得到的样本。因为$X_1,X_2,...X_n$独立同分布,于是,他们的联合密度函数为:
$$ L(x_1,x_2,...,x_n;\theta_1,\theta_2,...,\theta_k) = \prod_{i=1}^{n}f(x_i;\theta1,\theta2,...,\theta_k)$$
上述$L()$是$\theta$的函数,我们称之为似然函数,问题往往转化为求参数$\theta$的值,使得联合分布密度取得最大值(也就是似然函数)
引例:已知灌中有黑白围棋子若干,黑子和白子两者的数目之比为3:2,但是黑子和白子谁占3/5,谁占2/5并不知道,现在我们做一个实验:从灌中有放回地取4个棋子,观察实验结果为:白,黑,白,白。请根据该实验结果推断白子的占比为3/5的概率有多大?
这种问题有部分参数未知,希望通过实验结果来做参数的估计。最终根据代入法,明显取3/5时,实验结果出现的概率比较大,因此推断白棋为3/5
选择一个参数使得已发生的实验结果以最大概率出现,也就是样本随机变量的联合概率分布取得最大值(因为实验观测值已经是事实的存在,故要求其出现概率最大是合理的)的思想就是最大似然估计的基本思想。

在这个例子中,能够反映实验发生概率大小的函数就叫似然函数,也就是: $P(x_1 = 1, x_2=0,x_3=1,x_4=1) = p^3(1-p)$, 一般地,当似然函数取得最大值的时候对应的未知参数的值,就叫做参数的最大似然估计
一般定义:
设离散型总体$X$的分布律为$P(X=x) = p(x;\theta_1,\theta_2,...,\theta_m)$ 其中$\theta_1,\theta_2,...,\theta_m$为未知参数, $X_1,X2,...X_n$为样本,其观察值为$x_1,x_2,...,x_n$,观察值$(X_1=x_1,X_2=x_2,...,X_n = x_n)$出现的概率为:
$$L(\theta_1,...,\theta_m) = P\{ X_1 = x_1, X_2 = x_2, ..., X_n =x_n \} = \prod_{i=1}^{n}p(x_i;\theta_1,\theta_2,...,\theta_m)$$
若统计量(注意:统计量就是样本值的线性或非线性组合)$\widehat{\theta_1}(X_1,..,X_n),...,\widehat{\theta_m}(X_1,..,X_n)$使得似然函数取得最大值,
$$L(\widehat{\theta_1},..,\widehat{\theta_m}) = \overset{\theta_1,\theta_m} {max} L(\theta1,...\theta_m)$$
则称$\widehat{\theta_1}(X_1,...X_n),\widehat{\theta_m}(X_1,...X_n)$为$\theta_1,..\theta_m$的最大似然估计量(也是一个随机变量),每一个$\widehat{\theta_i}$则称为$\theta_i$的最大似然估计值.
对于连续型随机变量,使用总体$X$的概率密度函数$f(x;\theta_1,\theta_2,...\theta_m)$在样本$X_1,X_2...,X_n$的联合概率密度作为似然函数:
$$L(\theta_1,...,\theta_m) = f(x_1,..,x_n) = \prod_{i=1}^{n}f(x_i;\theta_1,\theta_2,...,\theta_m)$$

最大似然估计的不变性
若$\widehat{\theta}$是$\theta$的最大似然估计,则$g(\widehat{\theta})$也必然是$g(\theta)$的最大似然估计.
这个结论应用场景,比如:
设$X\sim G(p), x_1,x_2,...,x_n$是来自$X$的一个样本值,则我们先求出参数p的最大似然估计,以及$EX$的最大似然估计。
我们对于参数p可以通过构造样本的似然函数,通过求极值的方式求出p的最大似然估计。但是对于$EX$又如何求解呢?我们知道对于G分布,其
$EX=\frac{1}{p}$,所以,$\widehat{EX}= \frac{1}{\widehat{p}}$
从上面介绍的点估计两种办法:矩估计和最大似然估计的计算过程发现:矩估计本身结果并不唯一(选择不同的矩估计结果会不同);最大似然估计其结果也和选取的样本本身有关,结果本身也是一个随机变量,那么如何对点估计的结果进行评价呢?
参数估计量效果度量鉴定
由于使用不同参数估计方法得到的参数不同,如何来判断参数估计的效果呢?下面引入几个常用指标
- 无偏性
设$\widehat{\theta}(X_1,X_2,..,X_n)$是未知参数$\theta$的估计量,其本身也是一个随机变量,受抽样本身影响,如果该估计量本身在真值附近摆动,也就是说该估计量(也是随机变量,因为不同样本是会变化的)的期望等于真值的话,我们说是无偏估计。反过来如果估计量本身的期望和真值不相等的话,则称为系统误差,属于有偏估计
样本的K阶矩是总体K阶矩的无偏估计!
$A_k = \frac{1}{n}\sum_{i=1}^{n}X_i^k$是$E(X^k)$的无偏估计
特别常用地,我们使用
- 样本均值$\bar X$作为总体期望$E(X)$的无偏估计
- 样本二阶矩$A_2 = \frac{1}{n}\sum_{i=1}^{n}X_i^2$作为总体二阶矩$E(X^2)的无偏估计$
- 样本方差$S^2 = \frac{1}{n-1}\sum_{i=1}^{n}(X_i-\bar X)^2$是$D(X)$的无偏估计
- 有效性
如果$\theta_1,\theta_2$都是$\theta$的无偏估计,则计算其$E(\theta_1-\theta),E(\theta_2-\theta)$,比较其离散程度,离散程度小,方差小,也就是变化小的统计量估计值更有效靠谱

比如,上图例子中$\widehat{\mu_1},\widehat{\mu_2}$都是无偏估计量,我们可以结合方差的性质及已有统计量来计算参数估计值这个随机变量的方差:
$D(\mu_1) = \frac{1}{9}(D(X_1)+D(X_2)+D(X_3)) = \frac{1}{9}(3\sigma^2) = \frac{1}{3}\sigma^2$
而$D(\mu_2) = \frac{25}{72}\sigma^2 $故应该选用$\mu_1$作为其估计量
statsmodel库中如何计算参数估计值的方差呢?
我们知道参数估计往往使用最大似然估价法利用样本数据计算可以得出。这个值往往是确定的。只要给定一组样本,就能给出特定的参数估计,但是该参数估计的方差又是如何给出的呢???
应该就是使用上述的统计量+方差性质去求解的。也猜测是否可能会通过模拟生成多个training sets来提供计算(不很靠谱的猜测)
${X}' = \left \{ x | x From X But Replaced) \right \} \left | {X}' \right | = \left | X \right |$
- 相合性(一致性)
当样本容量越大,样本估计是总体参数依概率逼近。样本k阶矩是总体K阶矩的相合估计
- 有偏估计的均方误差准则
参数估计两个重要概念Bias vs variance
Bias: how close is the estimate to the true value?
Variance: how much does the estimate change for different runs(e.g. different datasets)?
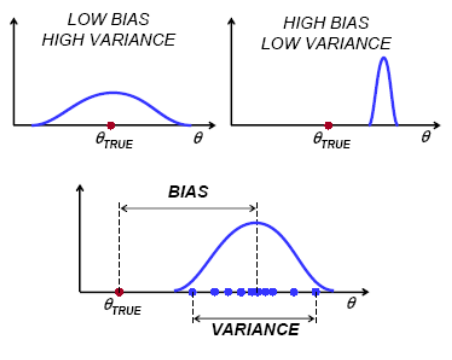
大多数情况下bias和variance两个指标是互相制约的,提高bias的表现,必然导致variance变差,反之亦然。因此我们更多的是要做一下折中。
区间估计
区间估计可以弥补点估计的缺陷,他能告诉一个范围及其可靠的概率。比如针对湖的鱼数量估计我们给出一个区间$\theta_1,\theta_2$,使得其有很大的可靠性(概率)包含未知参数$\theta$的真实值,这样我们对鱼儿数目的估计就有把握多了。
区间估计的一般定义
设总体$X$的分布函数为$F(x,\theta)$, $\theta$是未知参数,对给定的$\alpha (0<\alpha<1, \alpha=0.05)$,由样本$X_1,X_2,...,X_n$来确定两个统计量$\widehat{\theta_1} = \widehat{\theta_1}(X_1,...,X_n), \widehat{\theta_2} = \widehat{\theta_2}(X_1,...,X_n)$
使得:$P(\widehat{\theta_1} < \theta < \widehat{\theta_2}) \geq 1- \alpha$,我们称$(\widehat{\theta_1} , \widehat{\theta_2}) $为$\theta$置信度为$1-\alpha$的置信区间,$\widehat{\theta_1}$和$\widehat{\theta_2}$分别被称为置信下限和置信上限
例:$X_1,X_2,...,X_n$是来自总体$N(\mu,2)$的一个样本,则样本均值$\bar X$服从$N(\mu,1/4)$的正态分布。我们就可以计算得到 $P(\bar X -1 < \mu < \bar X +1) = 2 \phi (2) - 1 = 0.954$ ,在这里,我们就说$(\bar X -1,\bar X +1)$是$\mu$的置信度为0.954的置信区间
我们需要注意的是,针对不同的特定采样样本,根据上面的理论计算过程,其置信区间就是确定的了,要么包含真值,要么不包含真值,没有概率可言。

构构造置信区间的一般过程

置信度的几何意义

区间估计两要素:精度和可靠度
精度和区间大小成反比,可靠度和精度是负相关关系。我们往往在满足可靠性的基础上精度越高越好。
单个正态总体均值及方差的区间估计
总的来说,我们通过构造一个概率分布已知的检测统计量,根据样本值计算得出该统计量的确切值,判断该确切值是否落入拒绝域,如果是则拒绝,否则不拒绝。常用的统计量为$\bar X$均值的线性变换,依据标准正态分布去判断。。。
1. 总体方差已知,求总体期望$\mu$的置信区间:使用标准正态分布构造枢轴量

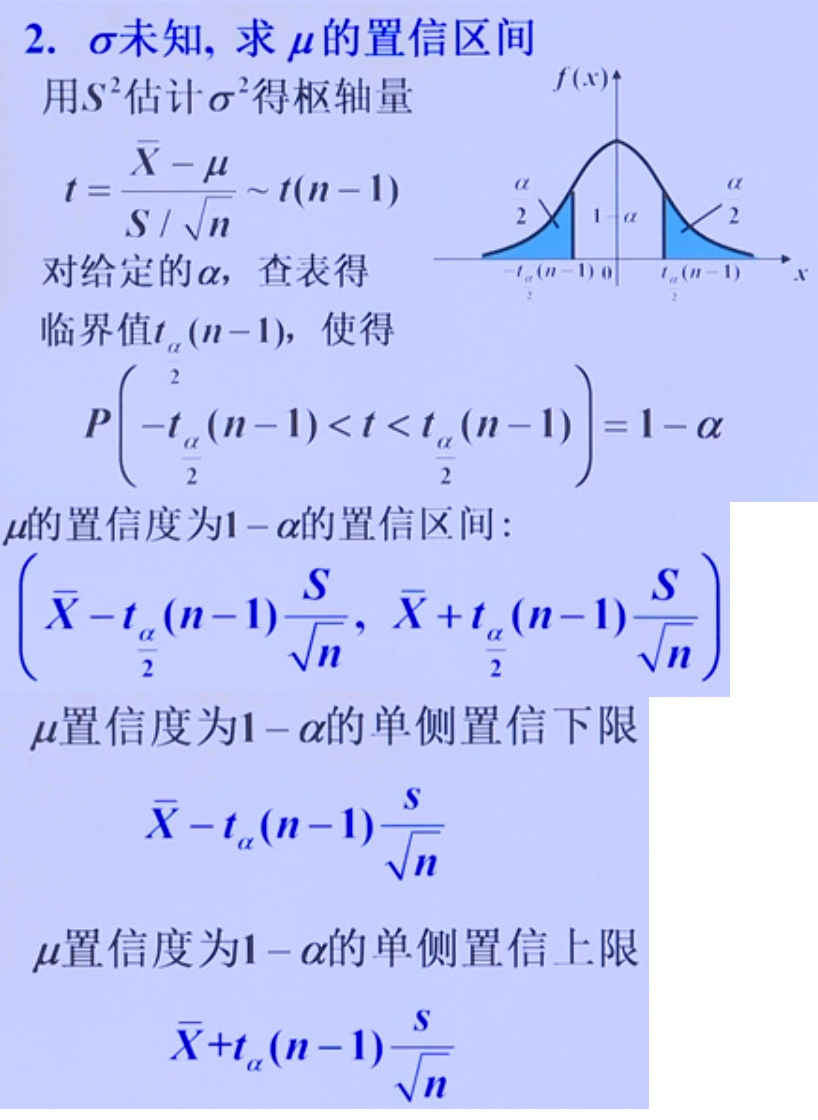
2.总体方差未知,求总体期望$\mu$的置信区间:使用t分布构造枢轴量
3. 总体期望,方差均未知,求方差的置信区间:使用卡方分布构造枢轴量

假设检验
在区间估计中,我们虽然给出了一定置信度下的区间范围,比如,通过产品质量的抽样检查,计算出来的不合格率置信区间为3%到8%,而通过样本计算出来的不合格率为4%,产品质量控制的阈值为5%,那么我们根据这些信息,是否能够判断该批次产品总体不合格率确实是小于5%的呢???如果以本次抽样计算得到的不合格率4%作为估计,我们可能说该批次产品是合格的。但是由于抽样本身是随机的,这个4%也有可能是一个随机的比较小的观测值而已。并且我们通过区间估计得到的置信区间又包含了5%以及以上值,因此没有理由认为这个本次抽样的4%不合格率是可信的。在这种情况下,我们就没有办法做出必要的推断和决策了。这也是我们要引入假设检验这种更科学的专门解决这类问题的原因。
研究的问题:根据样本的信息检验关于总体的某个假设是否正确。
可以分类为参数的假设检验和非参数的假设检验
参数假设检验:在总体分布已知前提下,检验关于未知参数的某个假设;
非参数假设检验:在总体分布未知的前提时的假设检验问题
相关概念:
被检验的假设用$H_0$表示,称为原假设或者零假设,零假设一般选择与标准一致或以往经验一致的假设。如果拒绝原假设则说明有较强的理由支持备择假设。
而其对立面称为备择假设或者对立假设,用$H_1$表示。
一般做法是:从样本出发,建立一个法则,根据样本值,利用所制定的法则,就可以做出是接受还是拒绝$H_0$的结论。这种法则称为一个检验。
显著性检验:只提出一个统计假设,而且也仅判断这个假设是否成立,这类假设检验称为"显著性检验"
常用的理论基础是小概率原理。
小概率原理
小概率事件在一次实验中基本上不会发生。
典型例题:
现有一个罐,装有红球和白球共100个,两种球一种有99个,另一种有1个,问这个罐里是白球99个还是红球99个?
解决这个问题可以先提出$H_0$假设,设:这个罐子里有99个白球,现在随机从罐子中取出一个球,结果得到的是红色。
此时我们如何根据实验结果来做判断?由于假设99个是白球,那么摸出红球的概率只有1/100,这是一个"小概率事件"
但是该小概率事件却在一次试验中发生了,从而怀疑假设的真实性。这也是一个“带概率的反证法”
假设检验基本思想:
先假设$H_0$是正确的,在此假设下,构造一个概率不超过 $\alpha(0<\alpha<1)$的小概率事件$A$,如果经过一次抽样检验,事件A出现,则拒绝$H_0$,否则接受$H_0$,这里$\alpha$就称之为"显著性水平",通常取$\alpha = 0.1,0.01,0.05$等。一般地,我们针对固定的样本容量$n$,显著性水平$\alpha$,建立检验法则,(假设检验的本质是把样本空间分成两部分,一部分为拒绝域,一部分为接受域),使得犯第一类错误(弃真错误)的概率不大于$\alpha$
我们需要将$H_0$设置为对我们重要的假设,发生弃真(弃$H_0$)错误的可能性越小越好,因此$H_0$往往是对我们来说意义重大的假设为真的假设,也就是那些不应该轻易被否决掉的假设为原假设$P(拒绝H_0|H_0为真)< \alpha$越小越好,或者说接受$H_1$这个结论时是必须可靠的!由于我们没有过多地考虑2类风险,因此即使我们接受$H_0$,也有可能结论并不十分可靠。
注意H0和H1两个假设的地位是不对等的;如果能够得出拒绝$H_0$接受$H_1$的结论时,是非常可靠的!反之不然:也就是说即使没有拒绝$H_0$,也并不意味着$H_0$确实为真,因为这时并无显著性检查的风险控制

下面我们通过假设检验的思想来判断均值$\mu = \mu_0, \mu_0$为待检验的总体均值。
单个正态总体的假设检验
u检验
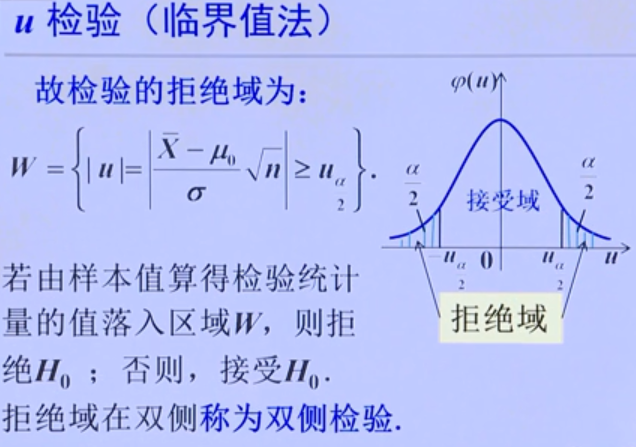
P值检验
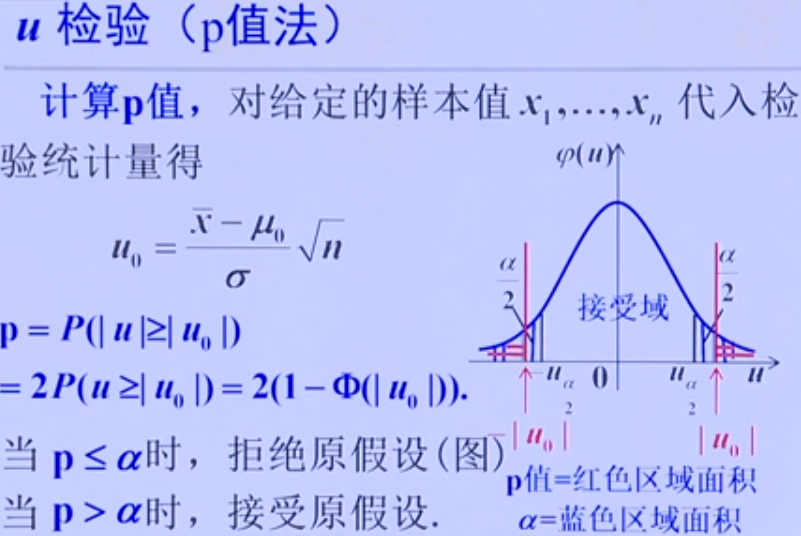
例子:判断是否存在系统误差:也就是是否均值等于实际值的假设检验

一般性方法

两个正态总体的假设检验
两个总体分别抽样两个样本,得到数据后做针对总体指标的假设检验:
1.对均值$\mu$的假设检验使用$t$检验(临界值法和p值法)
2.对方差假设检验使用$F$检验(临界值法和p值法)
非参假设检验问题
在实际生产中,总体的分布模型往往并不知道,这时就可能需要根据样本数据来检查样本是否能够拟合某一个模型。。。往往使用卡方检验法
方差分析
方差分析是基于样本方差的分解,分析鉴别一个变量或一些变量对一个特定变量的影响程度的统计分析方法。用于推断多个正态总体在方差相等的条件下,均值是否相等的假设检验问题。
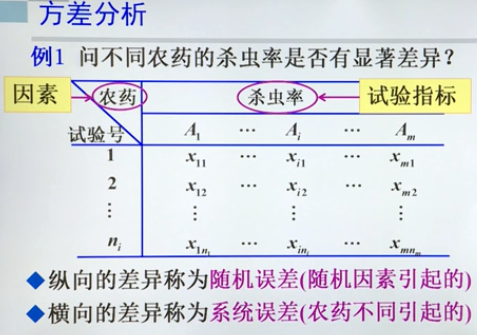
要考察农药间的杀虫率是否有显著差异,实际上就是要分析这些数据差异是由随机因素造成的,还是系统误差造成的。如果是系统误差造成的,则可以说明农药的效果是有显著不同的,
T-test, F-test及其作用
https://blog.csdn.net/mydear_11000/article/details/51576564
https://www.zhihu.com/question/60321751

