


人工智能,大数据,云计算大杂烩
百度ABC
ABC = AI+Big data + Cloud Computing
百度 基础云, 天像(智能多媒体平台),天算(智能大数据平台),天工(智能物联网平台),天智(人工智能平台)
监督学习和无监督学习
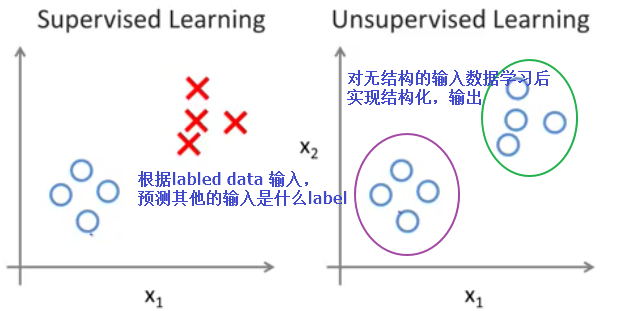
监督学习,就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的正确输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据进行分类的能力。监督学习里典型的例子就是KNN、SVM
无监督学习(也有人叫非监督学习,反正都差不多)则是另一种研究的比较多的学习方法,它与监督学习的不同之处,在于我们事先没有任何正确的训练样本,而需要直接对一堆数据进行建模,找到其中可能的特征。无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。比如,人类基因组合,输入一堆人类的基因数据,经过无监督的学习,可能会输出通过某些基因因子来划分的人类类别(cluster),而这在学习之前我们是无法知道的,甚至不知道应该由哪些基因因子来划分人类
http://blog.csdn.net/bangemantou/article/details/12966533
特征,建模,模型,机器学习,训练数据集
计算机用来学习的、反复看的图片叫“训练数据集”;“训练数据
集”中,一类数据区别于另一类数据的不同方面的属性或特质,叫作“特征”;计算机在“大
脑”中总结规律的过程,叫“建模”;计算机在“大脑”中总结出的规律,就是我们常说的“模
型”;而计算机通过反复看图,总结出规律,然后学会认字的过程,就叫“机器学 习”
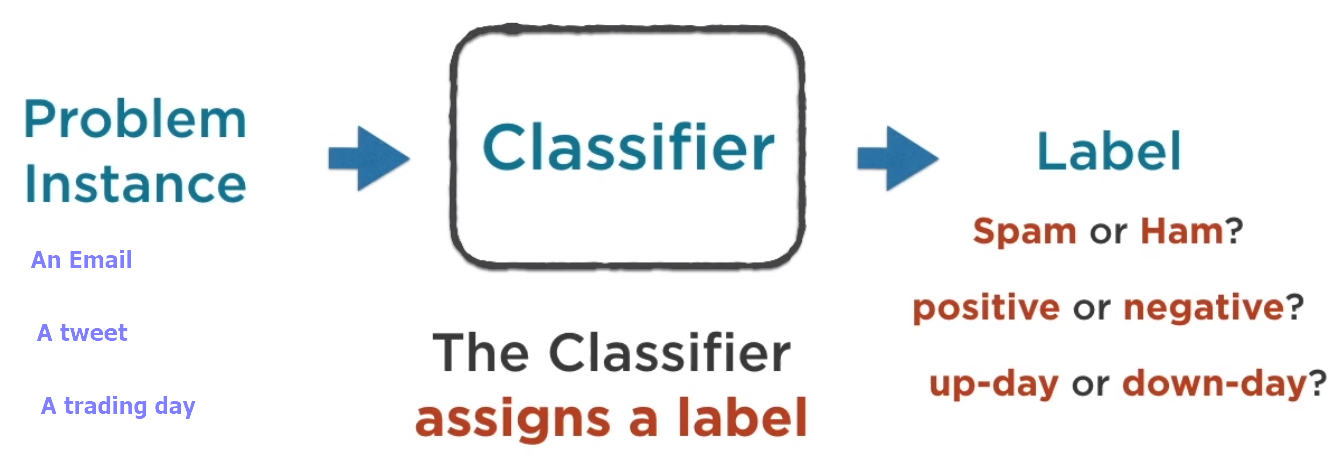
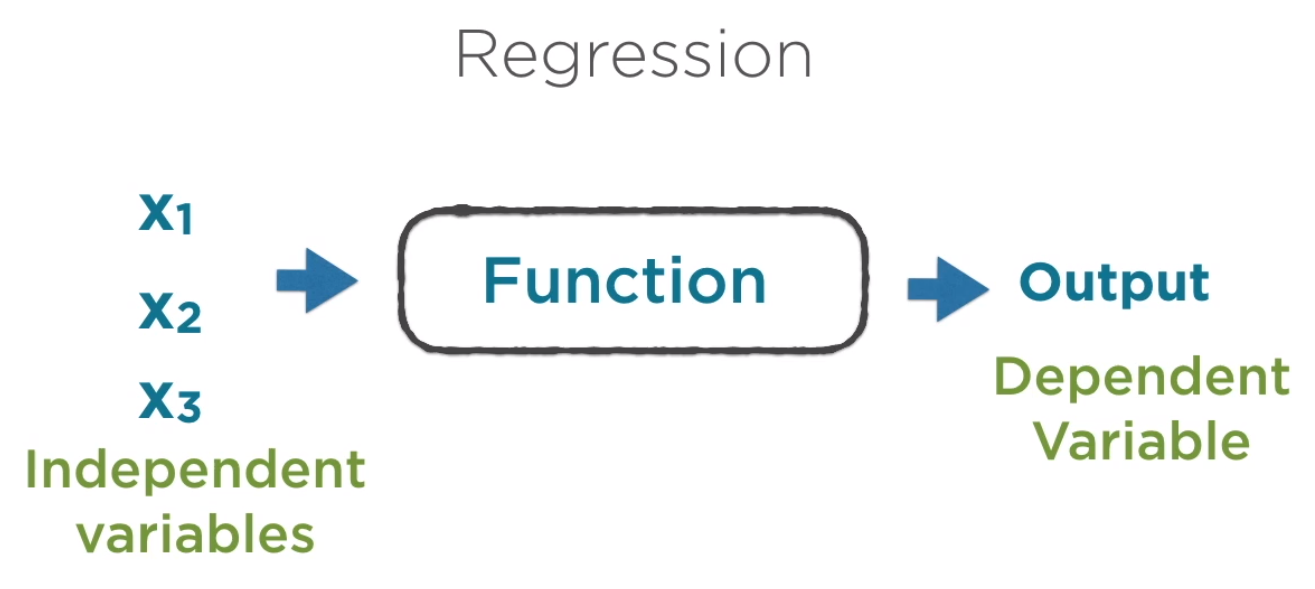
classification problem vs regression problem
分类问题输出多个类别;regression problem输出连续的预测值。
machine learning的一般性原理
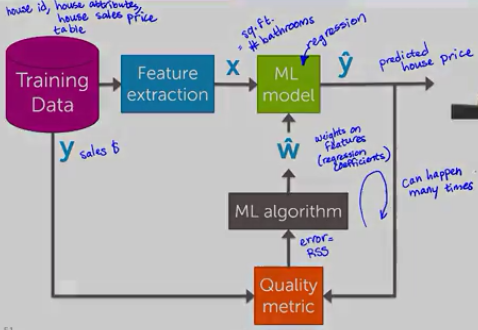
给定的training data set首先抽象出最重要的特征参数,应用到一个机器学习model(比如regression model,神经网络),得出prediction。
将prediction和实际的y值按照一定规则做出预测误差函数(w的函数),将该误差函数(loss function)应用到机器学习算法(比如梯度下降法)来优化模型model中的w参数,不断优化使得quality(loss function)最小
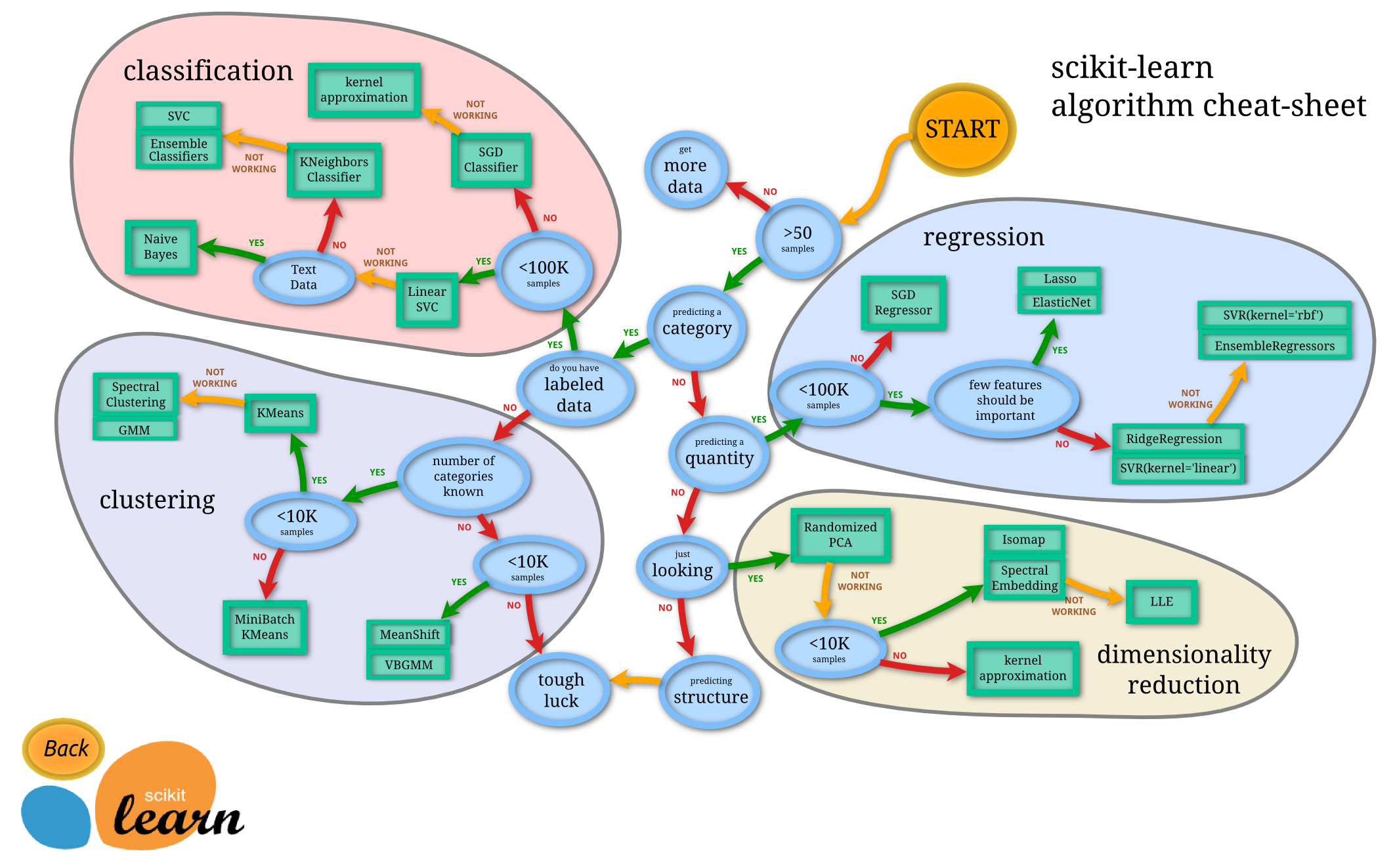
sk-learn学习模型算法决策过程
http://scikit-learn.org/stable/tutorial/machine_learning_map/
linear regression(线性回归)
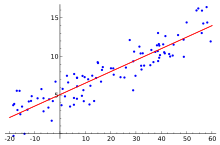
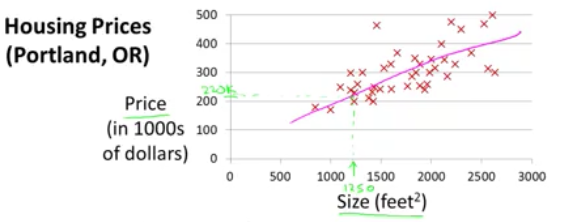
给定一组数据x=[1,2,3,4,5]和y=[0.2,0,3,5,7]得出最能拟合x,y之间关系的一个线性曲线y=kx+b(这就是一元线性回归分析,因为只有一个自变量,一个因变量.如果回归分析中包括两个或两个以上的自变量,且自变量之间存在线性相关,则称为多重线性回归分析),随后我们据此曲线再给定任何一个数据,我们来预测其应有的输出是多少(这就是regression问题的本质概念:预测一个连续的value)
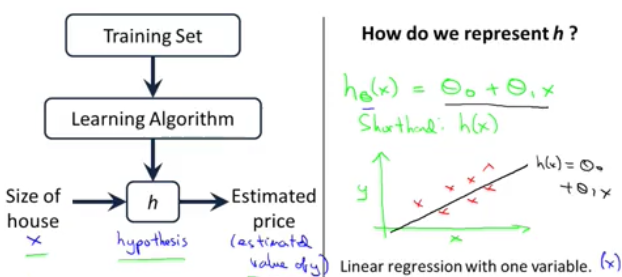
hypothesis(假设函数)(model)
在线性回归中,我们拟合出来的函数英文被成为hypothesis,也可以称此函数为学习后建立的model,比如y=kx+b,其中k和b被称为model的parameter,我们通过学习算法针对training set来进行训练学习,最终来确定这些parameter,从而就确定了最终的模型函数,通过这个函数,我们就可以做到对应的预测了
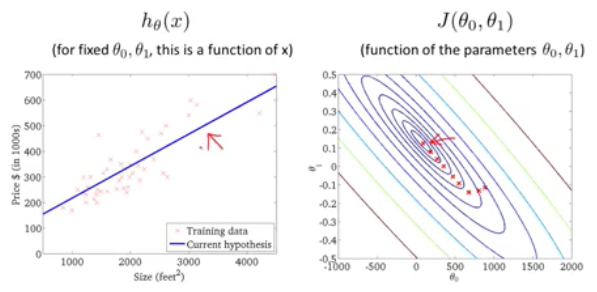
线性回归问题的目标(target)(objective): 找到最优的Θ0和Θ1两个参数使得经过对于给定的training set中的x值,经过我们y=Θ0+Θ1X的hypothesis模型得到的预测值和真实值y之间的方差均值最小化,J(Θ0,Θ1)就被成为cost function(或者说目标函数),也就是说使得目标函数最小化是我们机器学习算法的最终目标
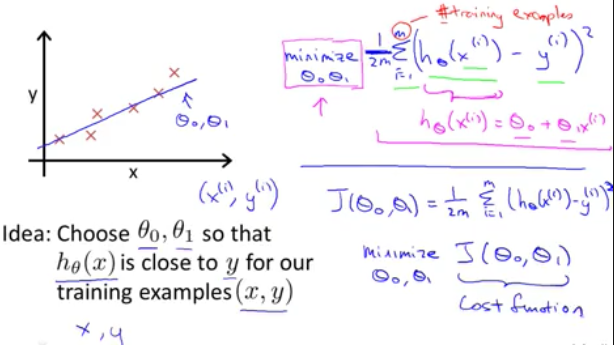
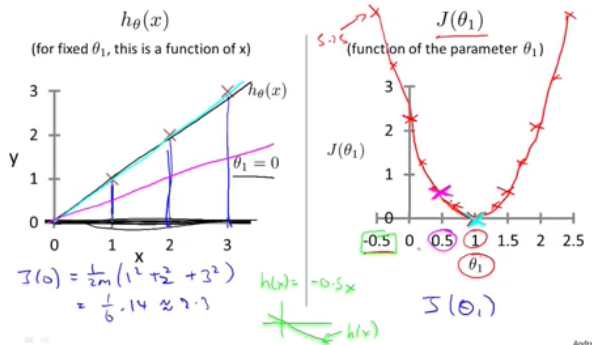
hypothesis和loss函数对比解读(假设Θ0 = 0以便简化问题), h函数为x的函数,而J函数则为Θ1的函数,我们选定不同的Θ1得到不同的h(x)函数,对应绘制图形,可以看出在Θ1=1时,J(Θ1)达到最小值,也就在这时,h函数和输入的训练集完全拟合
gradient descent(梯度下降法)
注意在梯度下降法更新参数时,必须是一次性同时更新Θ0和Θ1参数,而不运行交错更新!
梯度下降是优化loss function使得其最小化的算法

convex fuction(凸函数)
线性回归的Loss函数是一个凸函数(相一个碗一样),只有一个全局最底点
Matrix inverse
如果A是一个mXm的矩阵,如果它有逆矩阵,则:
A*A-1 = A-1 *A = I
I = [
1 0
0 1
]的单位矩阵
singular matrix:不可逆的矩阵
矩阵相乘

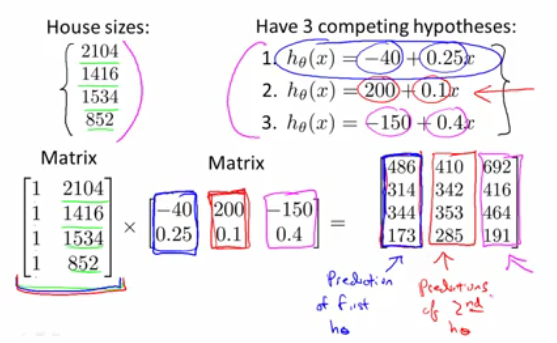
通过矩阵相乘,来实现一次批量计算多个假设函数(hypothesis)的预测值,而一般的library对于矩阵相乘都做了重要的优化,甚至可以完全发挥处理器多核,或者协处理器,高效地完成算法执行工作。
矩阵相乘的几个特性:
A*B一般不等于B*A 不具有交换律
A*I = I* A(注意这里的I的型是不同的纬度不同)

A*B*C=A*(B*C) 适用结合律
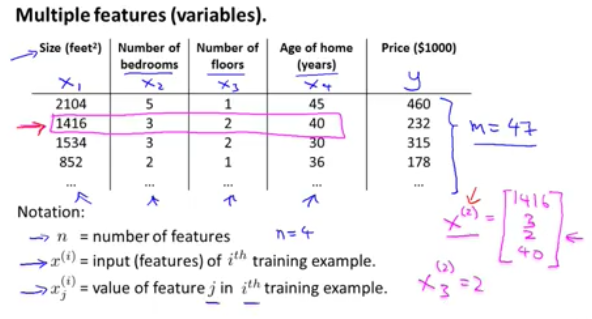
多元线性回归
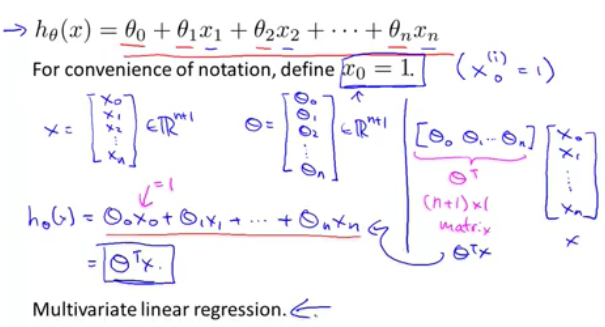
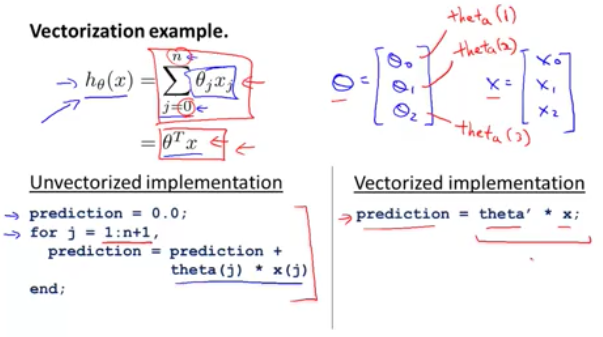
如果输入的feature有多个的话,这时线性回归问题就被称为多元回归了,其hypothesis函数就可以简化为矩阵表达方式: hθ(x)=θTX, 具体如下:

多元线性回归参数θ的更新(注意使用了新的下标表示不同feature(x)):

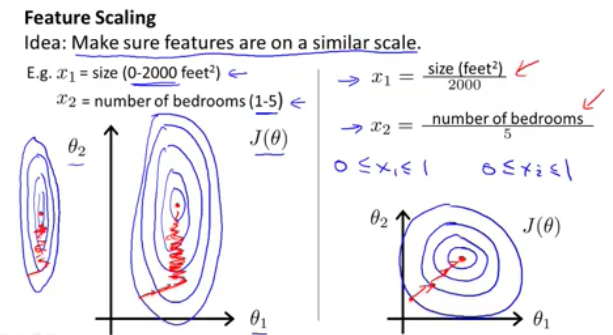
feature scaling的重要性:
我们在做线性回归梯度下降算法时,如果多个参数的输入参数(feature)值范围相差巨大,则会导致收敛速度过慢,因此我们在训练数据时,首先需要做的是输入训练数据的正规化,常用的方法是mean normalization减去均值除以范围

学习率α的重要性
如果过大,可能导致回归发散,如果过小则会导致收敛过慢。可以在实验中画出J(θ) 对于iteration number的函数图像
多元回归的部分notation图例
hypothes = 参数向量*feature向量(x)

linear regression梯度下降法的替代方案(矩阵转置直接求解法)
梯度下降法对于求解θ参数使得cost function最小化是一个通用方法,但是如果x feature个数很少的话,我们有一个替代方案,无需梯度下降无数步的迭代,一次性计算即可得出θ参数

矩阵不可逆的几种原因及其解决方案

为何一般矩阵向量都会默认写成列向量?
原因在于一般矩阵都对应着线性映射,考虑矩阵A,如果x是列向量,那么不妨把A对应的线性映射还是记作A,那么就有A(x)=Ax,右边就是矩阵的乘法.A(x)=Ax
矩阵内积的矩阵向量化求解
我们知道对于线性回归的h函数表示为h=θ0+θ1x1+θ2x2,如果要求解特定参数下的h值,我们编码有两种方案,要么for loop来求解,要么通过矩阵运算来求解。要使用矩阵运算,首先第一步我们就要将x和θ做向量化,这样矩阵运算的好处是会运用到科学计算中已经优化的库代码,甚至很好地运用到并行处理
Logistic Regression Classification
对训练集训练后,输出(0,1),表征结果的分类。这时如果使用线性回归算法并不适合,这时我们就要使用新的算法:逻辑回归。
在逻辑回归分类算法中,由于输出必须在0到1之间,因此我们要引入一个叫做sigmoid函数(或者称为logistic function)来对θTx做转换
hθ(x)=P(y=1|x;θ) 给定features x,在参数为θ的情形下,输出y=1的概率值,在逻辑回归算法中,所有的概率加起来必须为1,比如:
P(y=1|x;θ)+P(y=0|x;θ) = 1
decision boundary
决策边界只取决于给定的θ参数,和训练数据集无关,使用高阶多项式外加sigmoid函数组成hypothesis函数,则可以形成非常复杂的决策边界

获取训练数据的几个方法
1. 人工合成,比如使用已有的字体库,就可以获得大量字符不同形态的image,或者对已有的数据做变形处理,比如可以对图片做倾斜,拉伸等操作形成新的labled data set
2.自己来做搜集标注整理
3. 雇佣人工标注, https://www.mturk.com/mturk/welcome
基于tensorflow机器学习应用开发和部署流程
http://blog.csdn.net/qq_36510261/article/details/72533550
推荐系统
http://blog.csdn.net/initphp/article/details/52368867
terms used in machine learning
model accuracy vs model complexity
从下面的图中可以看到随着model复杂度增加,针对training set,模型可以完美地拟合(fit),但是对于test set却并不是持续增加的!我们必须寻找到一个平衡点,
使得我们的model既能比较好的拟合训练集,又能很好的generalize(泛化),也就是真正学到了global pattern,而不是仅仅为了拟合一些noise data(local pattern)而过拟合
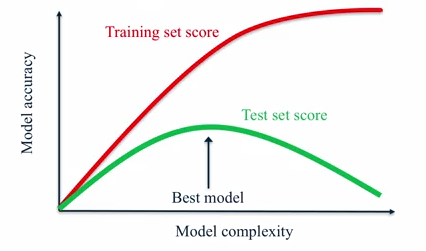
generization泛化/过拟合/欠拟合(overfitting/underfitting)概念

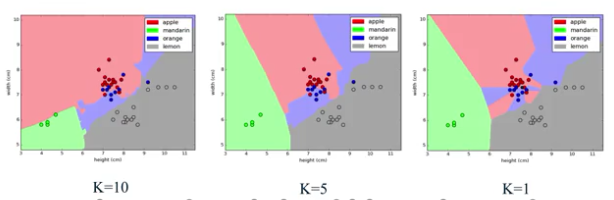
理解,检测,并且避免overfitting或许是机器学习中需要解决的最重要的问题
simple models is much more effective at ignoring minor variations in training data and capturing the more important global trend with better generization performance
处理overfit的几种思路:
1. 减少不必要的特征feature参与运算
2.大量增加有效的数据
3.通过正规惩罚项来均匀化各个特征对y的贡献

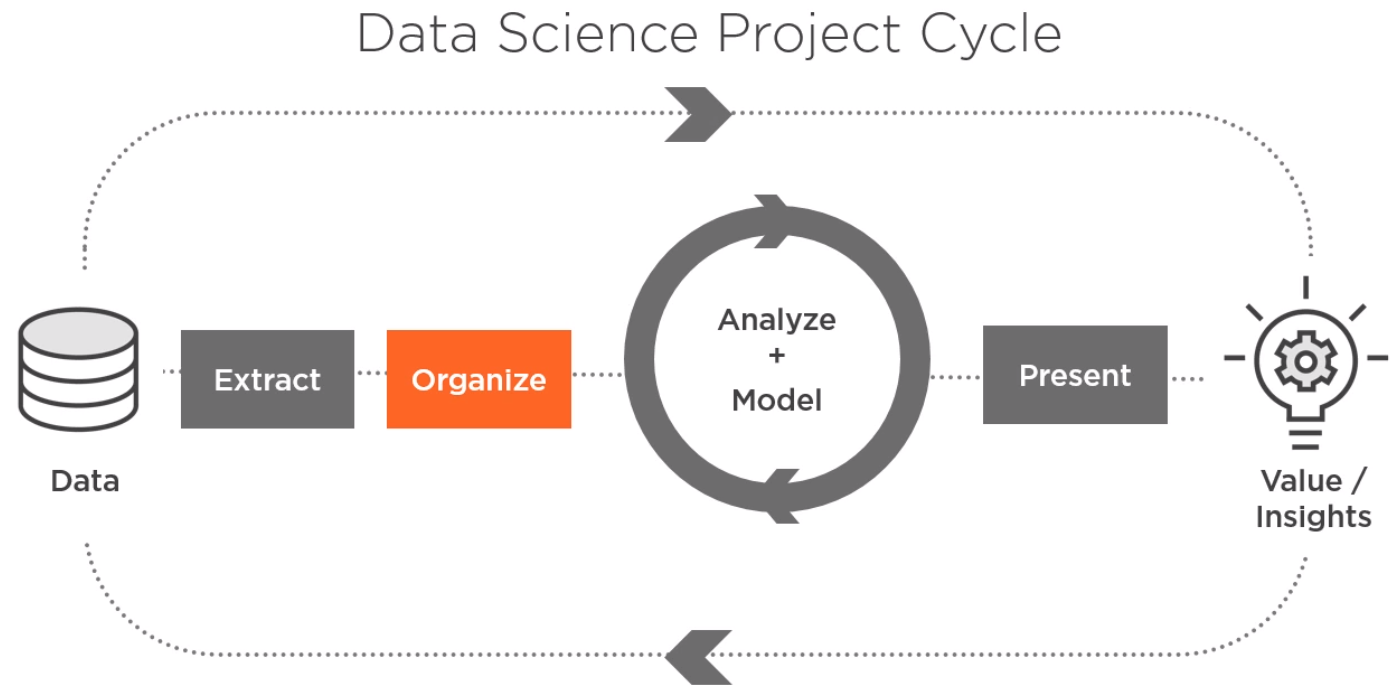
机器学习的一般过程:
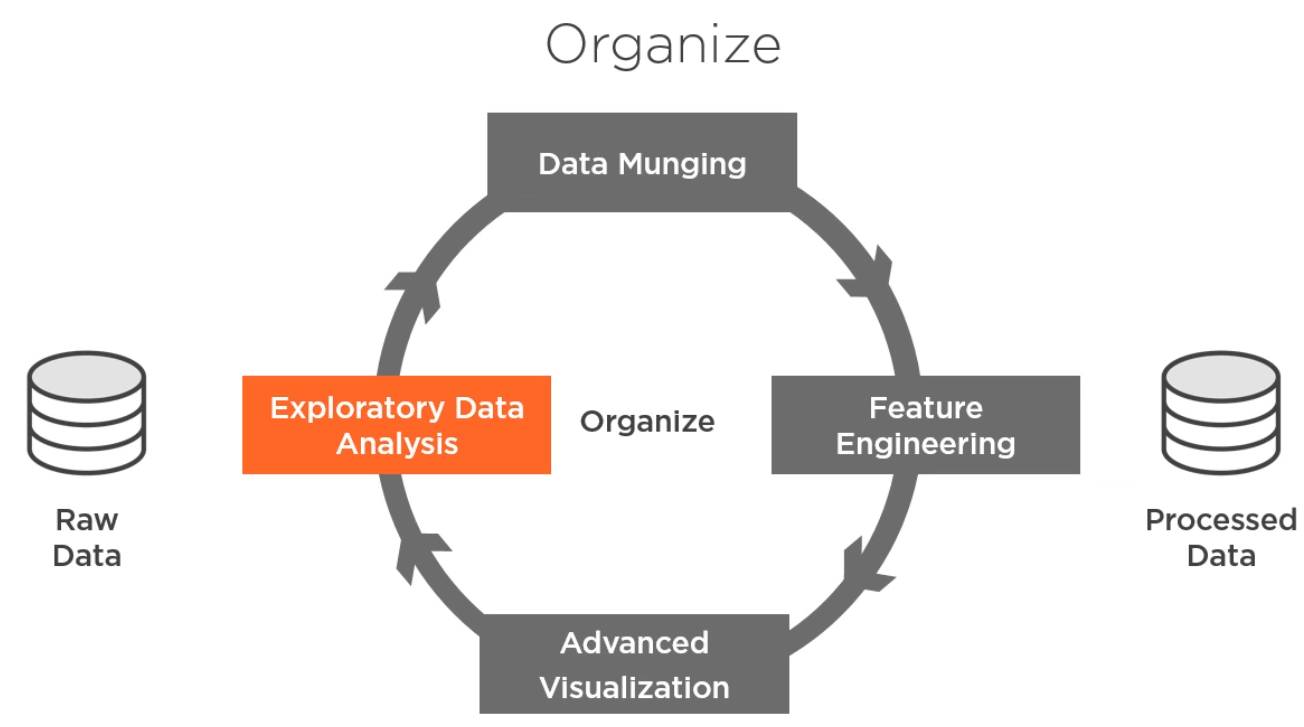
数据组织和数据清洗中用到的参数
variance: (真值-均数)的平方取和除以count
standard variance:取variance的根号
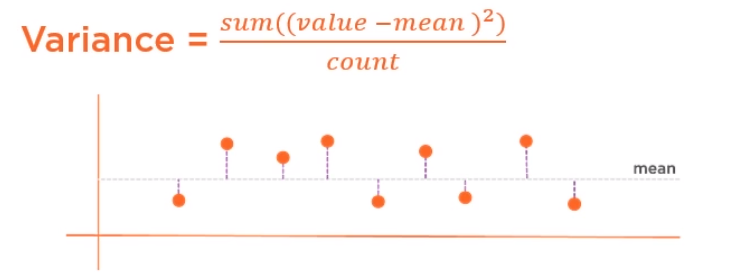


数值量:
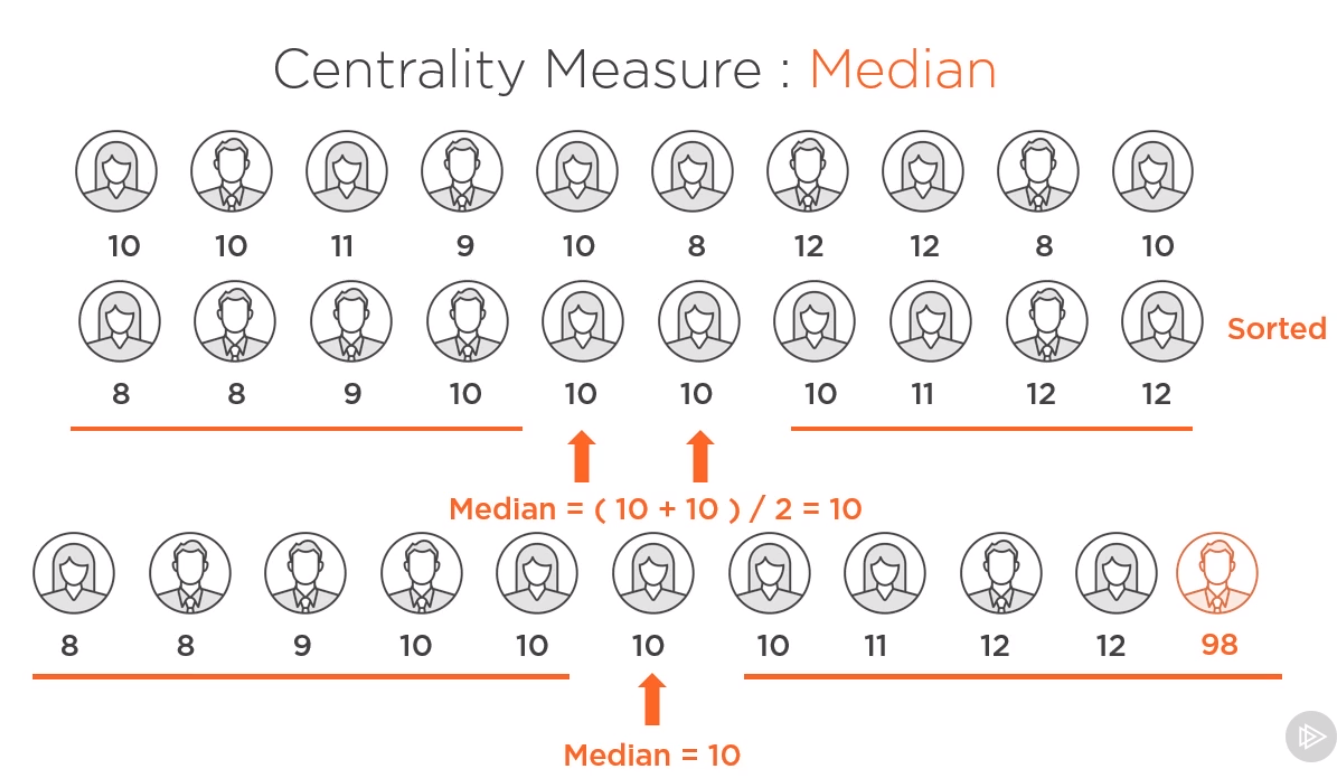
- 中点度量(mean,median)
-数据分散性度量 (range,percentile, variance, standard deviation)
类别量:
- top count
- unique count
-category counts and proportions
per category statistics

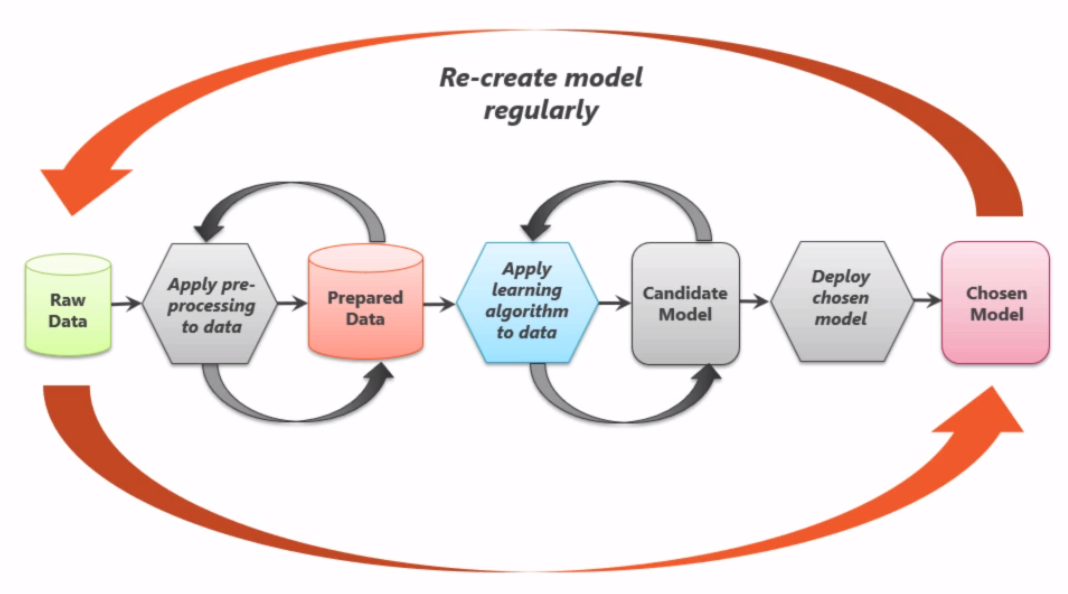

机器学习model的生命周期
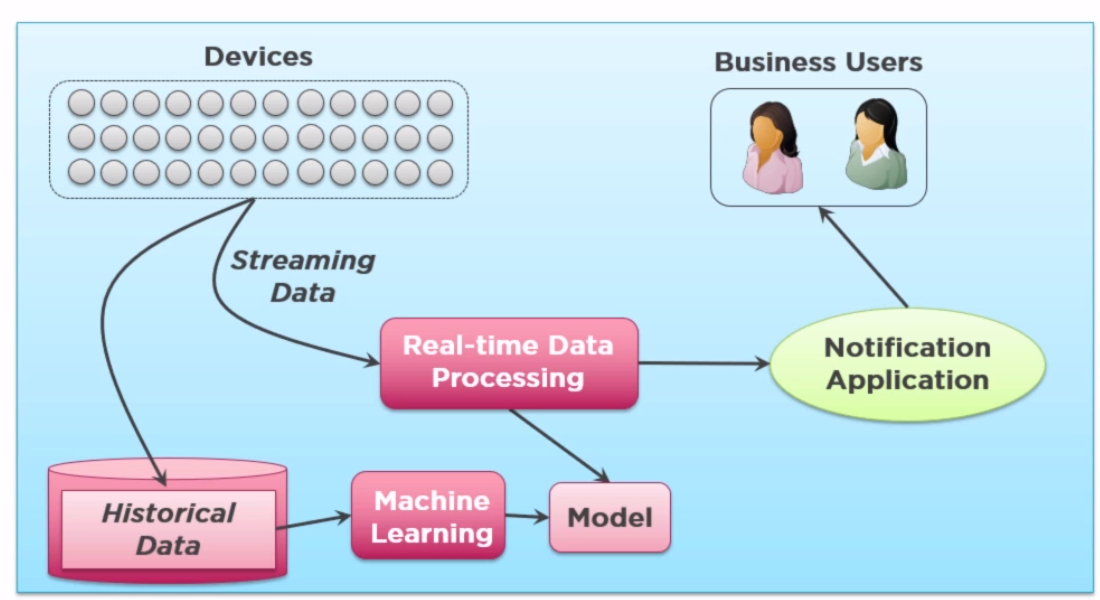
机器学习研究方法过程


机器学习问题分类

神经网络相关:


人工智能可以涉足的领域:复杂度和重复系数
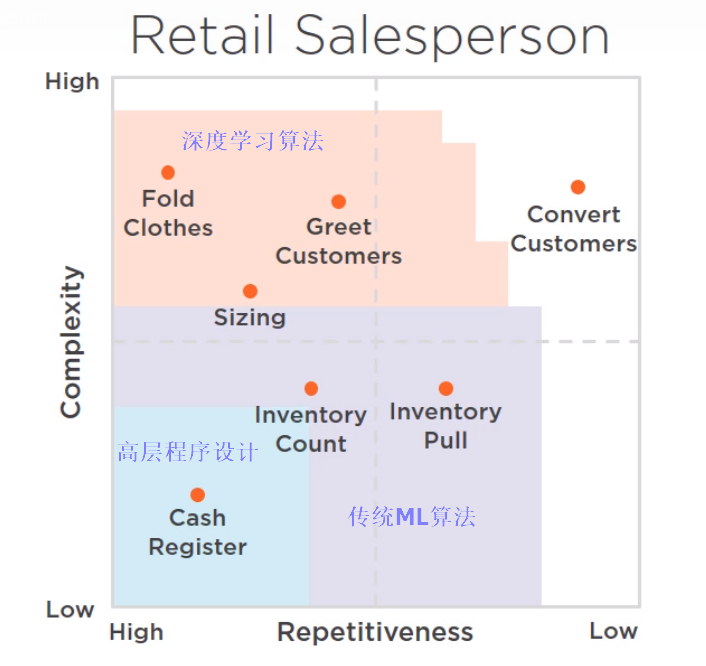
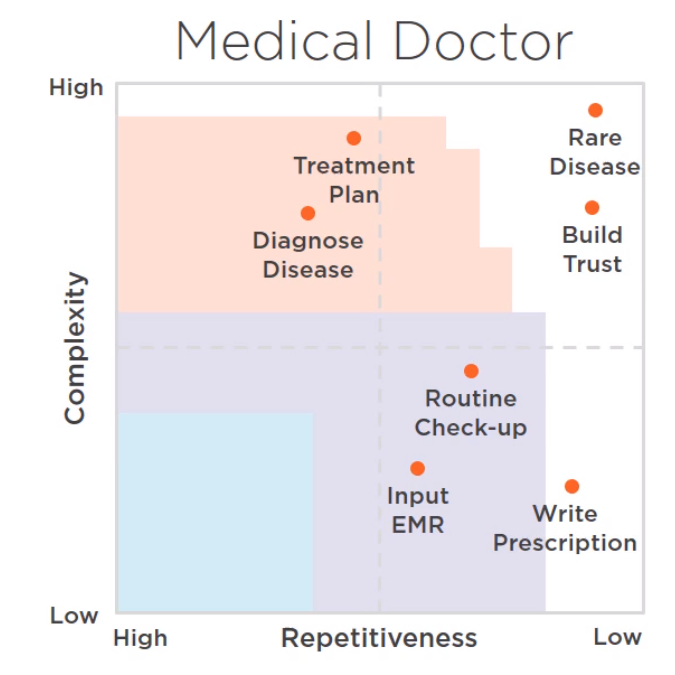
如何知道哪些features是predictive的,我们如何选择一个学习的算法?
数据科学家的重要工作就是做特征选择

