
deep learning自学知识积累笔记
推荐系统的演变过程
协同过滤(英雄所见略同)思想为类似喜好的人的选择必然也类似。比如小学男生普遍喜欢打手游,中年大叔普遍喜欢射雕英雄传
随后有了SVD奇异值分解,但是SVD要求不能太稀疏,因此有了隐语意模型
隐语意模型的推荐系统
https://www.jianshu.com/p/7b6bb28c1753
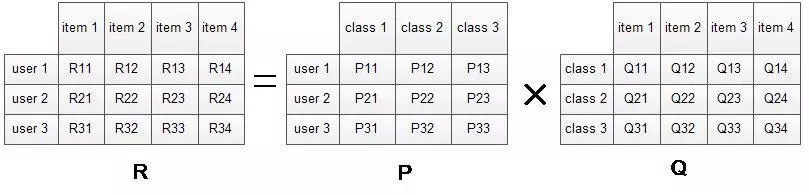
核心思想是将user-item ranking矩阵通过隐含的类别向量分解为user-class, class-item矩阵的乘积。
定义损失函数,使用梯度下降法,将P,Q两个矩阵求解出来,后续的推荐就基于$P_I \times Q$获得第i个用户对所有item的评分(兴趣)情况,排序后就可以做出推荐
早前的奇异值分解SVD理论:
假设矩阵M是一个m*n的矩阵,则一定存在一个分解 ,其中U是m*m的正交矩阵,V是n*n的正交矩阵,Σ是m*n的对角阵,可以说是完美契合分解评分矩阵这个需求。但是奇异值分解要求矩阵是稠密的,但现实中往往无法满足这个要求。
https://zhuanlan.zhihu.com/p/34497989
PCA降维的本质
比如30*1000000直接就降到了30*29,这不是减少的数据有点太多了么,会不会对性能造成影响。之所以有这个迷惑,是因为最初并不了解pca的工作方式.pca并不是直接对原来的数据进行删减,而是把原来的数据映射到新的一个特征空间中继续表示,所有新的特征空间如果有29维.那么这29维足以能够表示非常非常多的数据,并没有对原来的数据进行删减,只是把原来的数据映射到新的空间中进行表示,所以你的测试样本也要同样的映射到这个空间中进行表示,这样就要求你保存住这个空间坐标转换矩阵,把测试样本同样的转换到相同的坐标空间中。
https://blog.csdn.net/watkinsong/article/details/8234766
Embedding原理
https://blog.csdn.net/laolu1573/article/details/77170407
应用中一般将物体嵌入到一个低维空间 ,只需要再compose上一个从
到
的线性映射就好了。每一个
的矩阵
都定义了
到
的一个线性映射:
。当
是一个标准基向量的时候,
对应矩阵
中的一列,这就是对应id的向量表示。这个概念用神经网络图来表示如下:
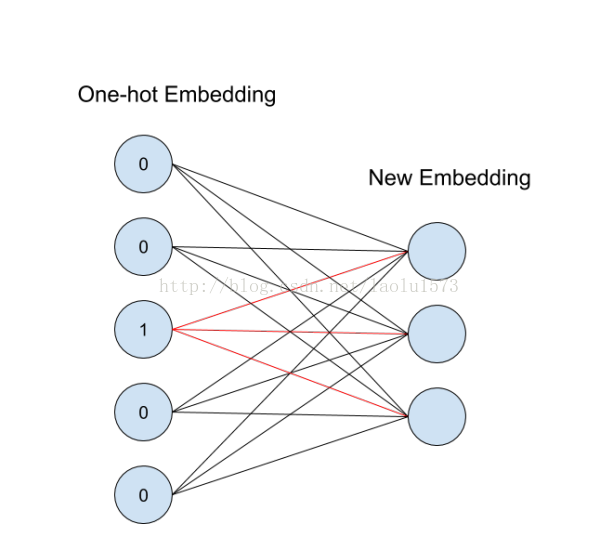

从id(索引)找到对应的One-hot encoding,然后红色的weight就直接对应了输出节点的值(注意这里没有activation function),也就是对应的embedding向量。
One-hot型的矩阵相乘,可以简化为查表操作,这大大降低了运算量。
tf.nn.embedding_lookup:
tf.nn.embedding_lookup()就是根据input_ids中的id,寻找embeddings中的第ids行。比如input_ids=[1,3,5],则找出embeddings中第1,3,5行,组成一个tensor返回。
embedding_lookup不是简单的查表,id对应的向量是可以训练的,训练参数个数应该是 category num*embedding size,也就是说lookup是一种全连接层。

Concisely, it gets the corresponding rows of a embedding layer, specified by a list of IDs and provide that as a tensor. It is achieved through the following process.
- Define a placeholder
lookup_ids = tf.placeholder([10]) - Define a embedding layer
embeddings = tf.Variable([100,10],...) - Define the tensorflow operation
embed_lookup = tf.embedding_lookup(embeddings, lookup_ids) - Get the results by running
lookup = session.run(embed_lookup, feed_dict={lookup_ids:[95,4,14]})
#!/usr/bin/env/python # coding=utf-8 import tensorflow as tf import numpy as np # 定义一个未知变量input_ids用于存储索引 input_ids = tf.placeholder(dtype=tf.int32, shape=[None]) # 定义一个已知变量embedding,是一个5*5的对角矩阵 # embedding = tf.Variable(np.identity(5, dtype=np.int32)) # 或者随机一个矩阵 embedding = a = np.asarray([[0.1, 0.2, 0.3], [1.1, 1.2, 1.3], [2.1, 2.2, 2.3], [3.1, 3.2, 3.3], [4.1, 4.2, 4.3]]) # 根据input_ids中的id,查找embedding中对应的元素 input_embedding = tf.nn.embedding_lookup(embedding, input_ids) sess = tf.InteractiveSession() sess.run(tf.global_variables_initializer()) # print(embedding.eval()) print(sess.run(input_embedding, feed_dict={input_ids: [1, 2, 3, 0, 3, 2, 1]}))
tensorflow: what it is
tensorflow is:
1. open source software library for numerical computation using data flow graphs
2. originally developed by google brain team to conduct machine learning research
3. tensorflow is an interface for expressing maching learning algorithms, and an implementation for executing such algorithms.
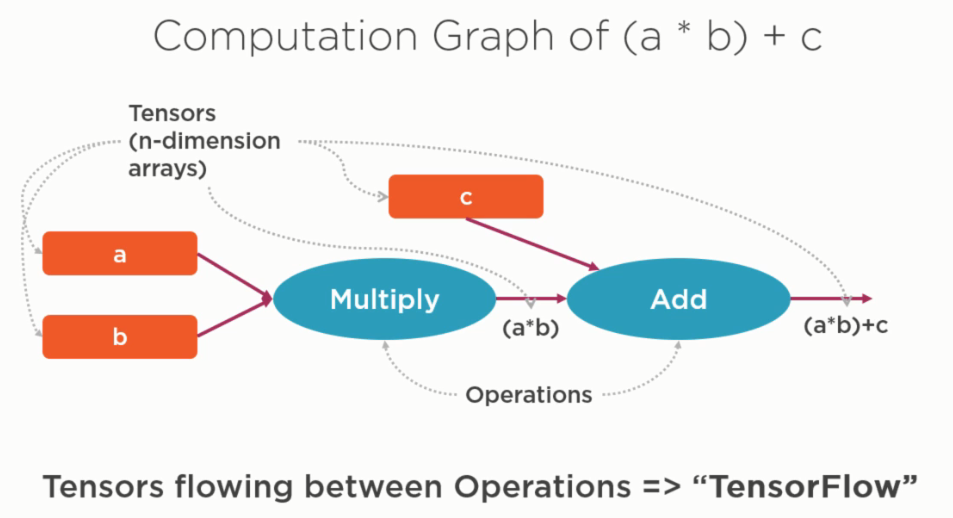
最重要的思想:将数值计算通过graph来表达,在graph中:
operation:
计算图中的节点node被称为operation,他可以有多个inputs(tensor),一个output(tensor).
也可以将op理解为一个可以视为计算图中可以被evaluated value的function
tensor
node之间的edge连接被称为tensor,tensor在node之间流动。从代码角度讲,tensor就是n-dimensional array
tensorflow programming model
import tensorflow as tf import numpy as np b = tf.Variable(tf.zeros((100,)),name='b') W = tf.Variable(tf.random_uniform((784,100),-1,1),name='W') x = tf.placeholder(tf.float32,(100,784),name='x') h = tf.nn.relu(tf.matmul(x,W)+b,name='hRelu') print(tf.get_default_graph().get_operations()) # [ # <tf.Operation 'zeros' type=Const>, # <tf.Operation 'b' type=VariableV2>, # <tf.Operation 'b/Assign' type=Assign>, # <tf.Operation 'b/read' type=Identity>, # <tf.Operation 'random_uniform/shape' type=Const>, # <tf.Operation 'random_uniform/min' type=Const>, # <tf.Operation 'random_uniform/max' type=Const>, # <tf.Operation 'random_uniform/RandomUniform' type=RandomUniform>, # <tf.Operation 'random_uniform/sub' type=Sub>, # <tf.Operation 'random_uniform/mul' type=Mul>, # <tf.Operation 'random_uniform' type=Add>, # <tf.Operation 'W' type=VariableV2>, # <tf.Operation 'W/Assign' type=Assign>, # <tf.Operation 'W/read' type=Identity>, # <tf.Operation 'x' type=Placeholder>, # <tf.Operation 'MatMul' type=MatMul>, # <tf.Operation 'add' type=Add>, # <tf.Operation 'hRelu' type=Relu> # ] print(tf.get_default_graph().get_all_collection_keys()) # ['variables', 'trainable_variables'] print(tf.get_default_graph().get_name_scope()) print(tf.get_default_graph().get_tensor_by_name('W:0')) # Tensor("W:0", shape=(784, 100), dtype=float32_ref) sess = tf.Session() sess.run(tf.global_variables_initializer())
# run global init op to initialize tf.Variable so that we can go!
# 需要注意的是Variable必须被初始化,因为这是tf的lazy evaluate机制,变量是有状态的,只有初始化了他们我们才能继续计算graph
hValue = sess.run(h,{x: np.random.random((100,784))}) print(h) # Tensor("hRelu:0", shape=(100, 100), dtype=float32) print(hValue) #[[ 3.706625 0. 0. ... 0. 5.529948 # 18.503458 ] #[ 0. 0. 0. ... 0. 6.702546 #20.58909 ]]
需要注意的是h这个python变量引用了最后一个Relu的op(node)! 有的时候并不需要一定使用类似tf_add,tf_multiply这样的函数调用,我们可以直接使用 +, - , *等基本的python运算操作符,而只要其中一个操作数为tensor,则结果也将是一个tensor,比如aTensor+b = c =>则c也是一个tensor。
session.run将返回一个numpy array
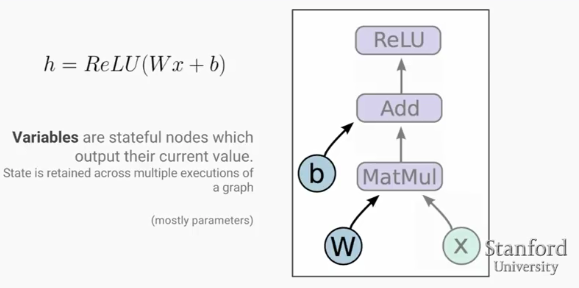
如上图所示,在深度学习中基本计算模块Relu(wx+b)映射到tensorflow计算图中,w和b为Variable,x则是placeholder,将来从外输入值作为x的值。
图中除了线以外都是operation,因此都可以evaluate其value.
Variable是stateful node,他们保持其值在一系列计算过程中,并且默认地会由优化算法在反向传播后来更新他们的值。variable的值可以方便地在训练中或者训练后被存储到disk或者从disk中恢复其快照值。variable就是你的网络中希望训练出来的参数!
Placeholder是那些value可以在执行时execution time被fed的nodes节点(op).他们在计算图定义时没有初始值,但是需要定义其datatype,其shape。
Mathematical Operation:
MatMul, Add, Relu都是数学计算op,他们可以是builtin的,可以是你自己定义的函数
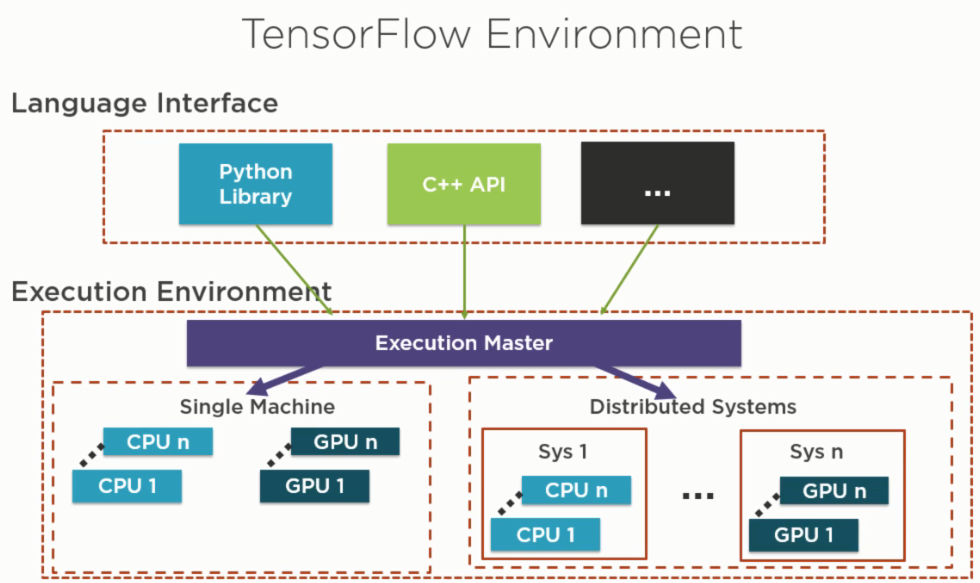
tensorflow architecture: language interface and execution environment
我們可以使用python, c++等语言通过计算图来定义model,随后将graph deploy到一个Session(指定了CPU或者GPU的硬件执行环境)执行环境下训练和预测.
首先定义计算图(compution graph),随后使用一个session来计算graph中的operation
tensor, operations
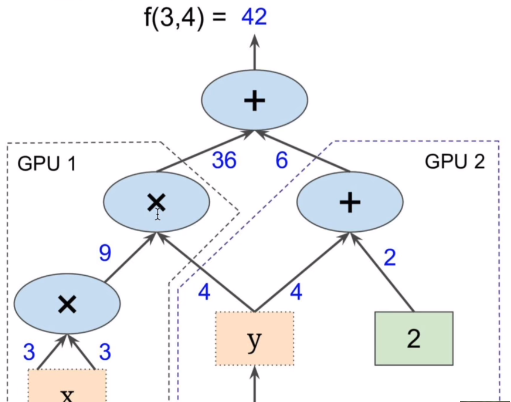
tensorflow计算时分布于不同gpu
tensorboard检查gradientDecent更新房价参数

上图中ApplyGradientDecent为一个Operation,my_optimizer是一个含有3个nodes的subGraph,也可以sess.run他
tf_price_pred为一个Add的op,tf_cost_op为一个Sum的op
tf_price_pred = tf.add(tf.multiply(tf_size_factor, tf_house_size), tf_price_offset,name="tf_price_pred") # 3. Define the Loss Function (how much error) - Mean squared error tf_cost = tf.reduce_sum(tf.pow(tf_price_pred-tf_price, 2),name="tf_cost_op")/(2*num_train_samples) optimizer = tf.train.GradientDescentOptimizer(learning_rate,name="my_optimizer").minimize(tf_cost) sess.run(optimizer, feed_dict={tf_house_size: x, tf_price: y})
程序和计算图示例:
import tensorflow as tf a = tf.constant(2,name="a") b = tf.constant(2,name="b") x = tf.add(a,b,name="x") y = tf.multiply(x, 3,name="y") z = tf.pow(y,3,name="z") with tf.Session() as sess: writer = tf.summary.FileWriter("./graphs2",sess.graph) print(sess.run(z)) writer.close() # 输出1728
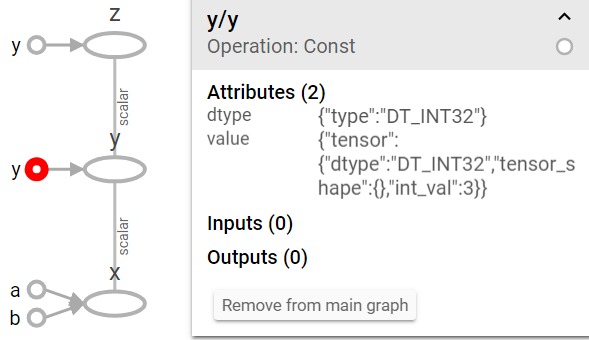
上图中左面的y是tensorflow自动对所有常量数据,比如2,2,3上面的数字自动起名为y(op为Constant),和我们给的x,y,z op是不同的。
x = Add
y = Mul
z = Pow
三个分别为对应的Add, Mul,Pow Operation
当tensorflow session run返回一个tensor时,其value就是一个numpy ndarray
constants stored in the graph defination
tf.constant is an op, tf.Variable is a class and holds serveral ops
import tensorflow as tf x = tf.Variable(...) x.initializer # init op x.assign(...) # write op x.value() #read op x.assign_add(...)
variable在使用之前必须用tf.global_variable_initializer来做初始化
使用tf实现lr的计算图
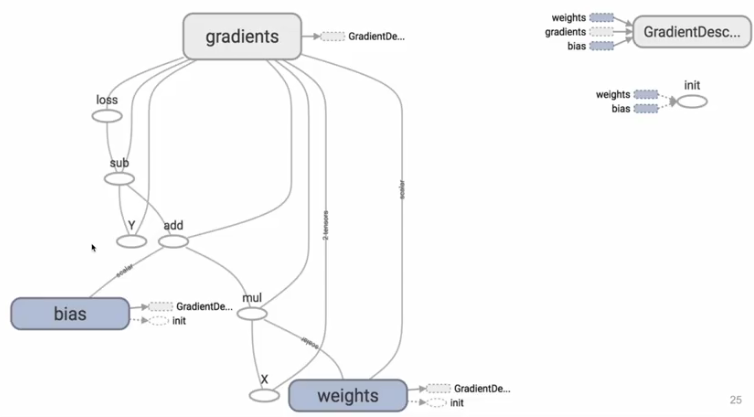
GradientDecent optimizer依赖于weight,bias以及gradients(从optimizer的loss输入查找到对应的依赖!),而gradients这个是tensorflow默认自带的tensor,由tensorflow自己想办法找到导数的计算方法的
OPs
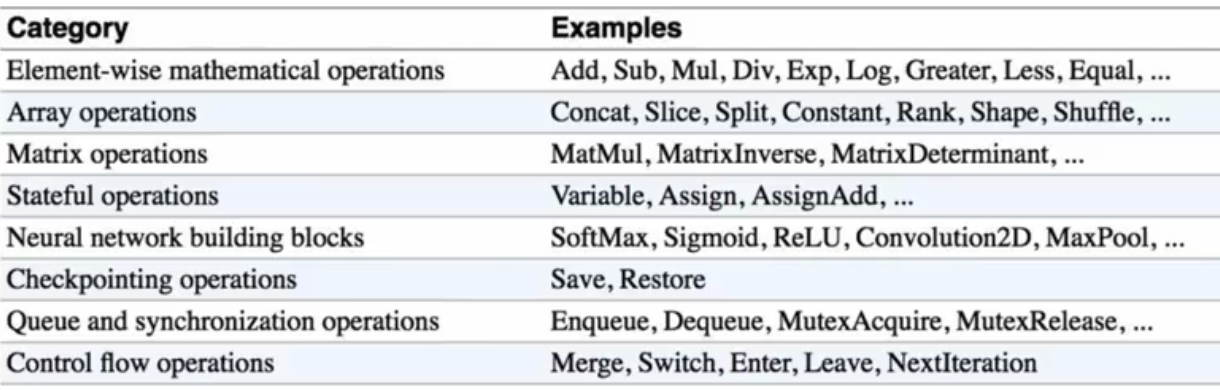
tensorflow的优化算法又是如何知道应该训练哪些参数的呢?
我们知道tf在训练模型时,核心是使用优化器,比如gradient Decent算法来优化损失函数。但是问题是tf怎么知道sgd在迭代过程中要更新哪些参数呢?
答案就是Variable的Trainable属性为true的变量。所有这些变量都是loss函数所依赖的!
LR自定义huber loss函数对异常值不敏感方案
简单线性回归中,由于使用MSE作为loss的话,对于异常值是比较敏感的,我们可以自己定义loss函数改进相应的机制,比如以下算法
def huber_loss(labels, predictions, delta=1.0): residual = tf.abs(predictions - labels) condition = tf.less(residual, delta) small_res = 0.5 * tf.square(residual) large_res = delta * residual - 0.5 * tf.square(delta) return tf.select(condition, small_res, large_res)
需要注意的是,我们仅仅通过定义这个loss函数,也就是定义了forward path的计算方法,而不用明确指出其反向求导,因为tensorflow会自动通过该函数定义中的不同op通过链式法则自动求解对应的导数。
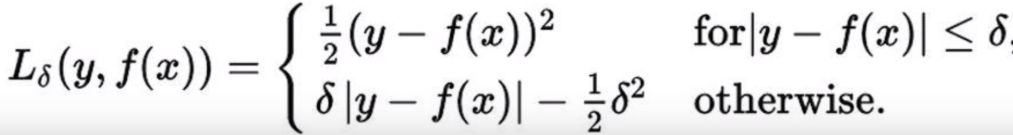
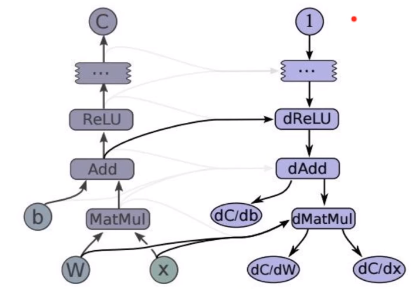
tf.gradients求解任意导数
import tensorflow as tf # sess = tf.InteractiveSession() x = tf.Variable(2.0) y = 2.0* (x ** 3) z = 3.0+y**2 grad_z = tf.gradients(z,[x,y]) with tf.Session() as sess: sess.run(x.initializer) print(sess.run(grad_z))
tensorflow典型loop

https://jizhi.im/blog/post/gpu-p2

