转载:【AI系统】算子手工优化
在上一篇中,探讨了算子计算和调度的概念,并强调了高效调度策略在释放硬件性能和降低延迟方面的重要性。本文,我们将深入讨论手写算子调度时需要考虑的关键因素,并介绍一些著名的高性能算子库。
计算分析
在优化算子前,首先需要知道当前程序的瓶颈在哪里,是计算瓶颈还是访存瓶颈。对于这两者,往往是通过 RoofLine 模型进行分析。
计算分析指标
首先定义几个关键指标:
-
计算量:指当前程序经过一次完整计算发生的浮点运算个数,即时间复杂度,单位为 Flops。例如卷积层的计算量为 $M2*K2C_{in}C_{out}$,其中 M 为输入特征图大小,K 为卷积核大小,C 为通道数。
-
访存量:指当前程序经过一次完整计算发生的内存交换总量,即空间复杂度。在理想的情况下,程序的访存量就是模型的参数和输出的特征图的内存占用总和(输入的内存占用算作上一个算子的输出占用上),单位为 Byte,在 float32 类型下需要乘以 4。对于卷积层,内存占用为 $K2*C_{in}*C_{out}+M*C_{out}$。
-
模型的计算强度:计算量除以访存量就是算子的计算强度,表示计算过程中,每字节内存交换用于进行多少次浮点计算。计算强度越大,其内存使用效率越高。
-
模型的理论性能:模型在计算平台上所能达到的每秒浮点运算次数的上限,Roofline 模型给出的就是计算这个指标的方法。
Roofline 模型
Roofline 模型是一种用于评估和分析高性能计算平台性能的有效工具。它通过分析计算量和访存量来确定在特定算力和带宽条件下,计算任务所能达到的理论性能上限。Roofline 模型的核心在于,它能够揭示硬件资源的限制,并帮助开发者和研究人员理解在现有计算平台的约束下,他们的应用程序能够实现的理论性能上限。
-
算力决定“屋顶”的高度(绿色线段)
-
带宽决定“房檐”的斜率(红色线段)
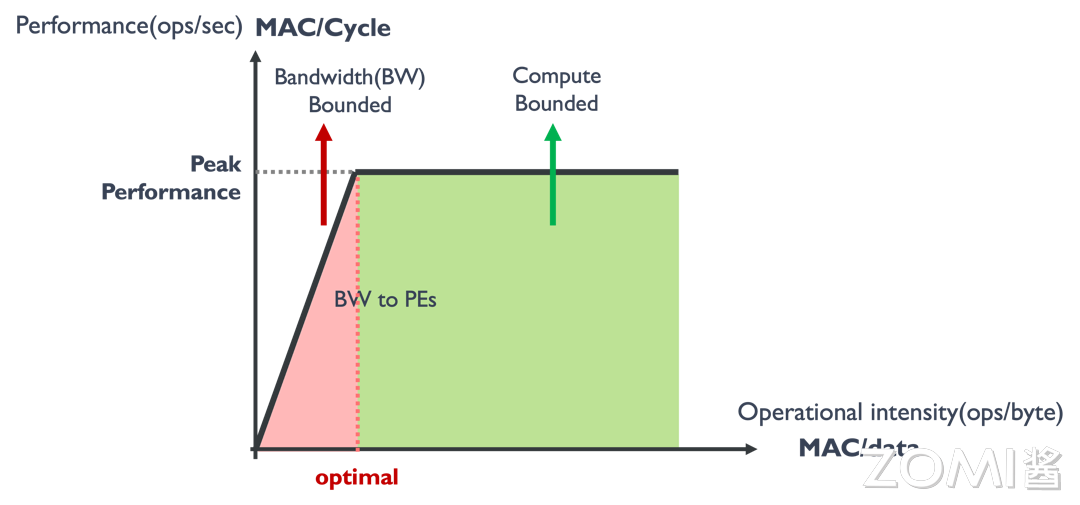
-
Compute-Bound: 当算子的计算强度大于计算平台的计算强度上限时,算子在当前计算平台上处于计算瓶颈。从充分利用计算平台算力的角度来看,此时算子已经利用了计算平台的全部算力。
-
Memory-Bound: 当算子的计算强度小于计算平台的强度上限时,算子的性能完全由计算平台的带宽上限以及模型自身的计算强度所决定,因此这时候就称模型处于 Memory-Bound 状态。可见,在模型处于带宽瓶颈区间的前提下,计算平台的带宽越大(房檐越陡),或者模型的计算强度越大,模型的理论性能可呈线性增长。
在(3,224,224)的输入下,VGG16 模型的前向传播计算量为 15GFLOPs,访存量大约为 600MB,则计算强度为 25FLOPSs/Byte。MobileNet 计算量为 0.5GFLOPs,访存量为 74MB,那么它的计算强度只有 7FLOPs/Byte。在 1080Ti GPU 上,其算力为 11.3TFLOP/s,带宽为 484GB/s,因此该平台的最大计算强度约为 24。
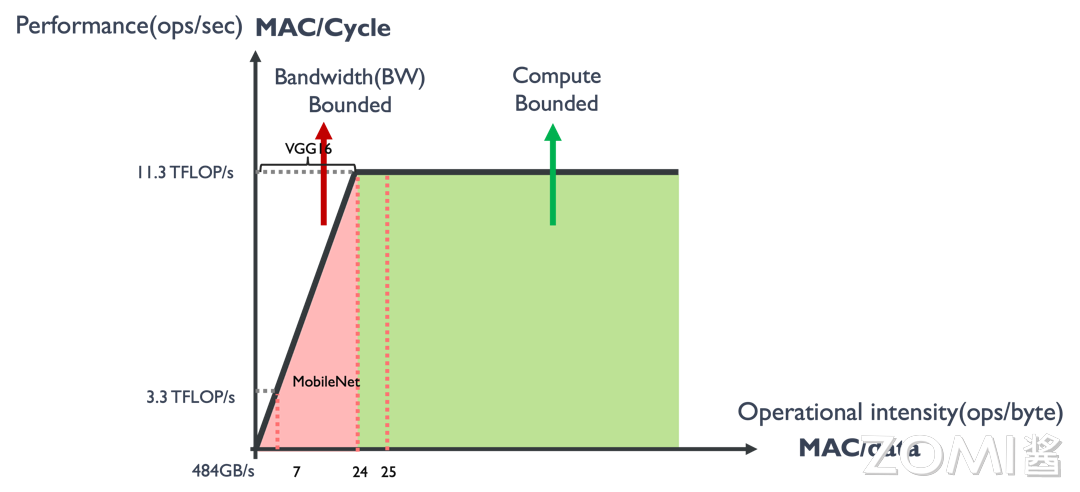
由上图可以看出,MobileNet 处于 Memory-Bound 区域,在 1080Ti 上的理论性能只有 3.3TFLOPs,VGG 处于 Compute-Bound 区域,完全利用 1080Ti 的全部算力。通过 Roofline 模型,我们可以清晰地看到,当计算量和访存量增加时,性能提升会受到硬件算力和带宽的限制。这种分析对于优化计算密集型和内存带宽密集型应用至关重要,因为它可以帮助开发者识别性能瓶颈,并作出相应的优化策略。
此外,Roofline 模型还可以用来指导硬件设计和软件算法的选择。例如,如果一个应用的性能受限于内存带宽,那么开发者可能会考虑使用更高效的数据结构或算法来减少内存访问。同样,硬件设计师也可以利用 Roofline 模型来评估不同硬件配置对特定应用性能的影响,从而做出更合理的设计决策。
要注意的是,Roofline 模型是理论性能上界,在实际运行中,除了算力和带宽,还有其他许多因素会影响程序的执行,例如缓存大小与速度。
优化策略
在深入探讨具体的优化策略时,主要关注三大核心领域:循环优化、指令优化和存储优化。这些优化策略旨在针对算子的计算特性以及硬件资源的特点进行量身定制。本节内容将简要概述这些优化技术,而在后续章节中,将提供更为详尽的分析和讨论。
- 循环优化
由于 AI 算子普遍具有高度规则化的多层嵌套循环结构,这为优化提供了丰富的技术手段。以逐元素操作为例,如 ReLU、加法(Add)和乘法(Mul)等,可以通过在所有循环轴上进行迭代来执行计算。即使是较为复杂的操作,比如卷积(Conv),也可以通过七层的嵌套循环来实现。然而,如果仅仅采用这些直观的原生计算方法,往往会导致效率低下。
通过对算子的数据布局和内存访问特性进行深入分析,然后相应地调整循环结构,可以显著减少不必要的开销,更高效地利用硬件资源,从而降低延迟。常见的循环优化技术包括循环分块(Loop Blocking)、循环展开(Loop Unrolling)、循环重排(Loop Reordering)、循环融合(Loop Fusion)和循环拆分(Loop Splitting)等。这些优化技术通过精心设计的循环变换,不仅能够提升计算密度,还能改善数据的局部性,进而优化内存访问模式,最终实现性能的飞跃。
- 指令优化
现代处理器,如 Intel 的 AVX-512 或 ARM 的 SVE,提供了强大的向量处理能力,允许单个指令同时操作多个数据点。通过这种方式,指令优化能够减少指令的数量和执行周期,进而降低延迟并提升性能。此外,针对特定硬件定制的指令集,如英伟达的 Tensor Cores,可以进一步增强并行处理能力,为深度学习中的张量运算提供专门优化。
在指令优化中,开发者需要深入理解目标硬件的架构特性,以及如何将这些特性映射到算法实现中。这可能涉及到对现有算法的重新设计,以确保它们能够充分利用硬件的并行处理单元。例如,通过将数据重新排列以适应 SIMD(单指令多数据)架构,或者通过调整算法以利用特定的硬件加速器。除了硬件特性的利用,指令优化还涉及到编译器级别的优化,如自动向量化、指令调度和寄存器分配等。这些编译器技术能够自动识别并应用优化,进一步释放硬件的潜力。
- 存储优化
在存储优化方面,致力于通过精细调整数据访问模式和内存层次结构来提升系统的整体性能。内存延迟隐藏技术旨在最小化等待内存访问完成的时间。这通常通过预取(prefetching)数据到缓存、调整数据访问模式以提高缓存命中率,或者通过并行执行其他计算任务来实现。
内存延迟隐藏的目的是让处理器在等待数据加载的同时,也能保持忙碌状态,从而提高资源利用率。双缓冲通过使用两个缓冲区来平滑数据流和隐藏延迟。当一个缓冲区的数据正在被处理时,另一个缓冲区可以被用来加载新的数据。这种方法特别适用于图形渲染和视频处理等领域,其中连续的数据流和时间敏感的操作需要无缝衔接。存储优化还包括合理分配内存资源、优化数据结构以减少内存占用、以及使用内存池来减少内存分配和释放的开销。这些策略共同作用,可以显著提高应用程序的内存访问效率,减少因内存瓶颈导致的性能损失
DSL 开发算子
手写算子的开发往往要求开发者深入底层硬件的细节,这涉及到对数据布局、指令选择、索引计算等诸多方面的精细调整,从而显著提高了编写 Kernel 的难度。为了简化这一过程,已经发展出多种高级语言(DSL)来加速开发,其中 TVM 和 Triton 是该领域的杰出代表。
这些 DSL 通过提供高级抽象,封装了多种常用的优化技术,并通过编译器的优化阶段自动识别并应用这些技术。开发者在使用这些 DSL 时,只需专注于高层次的计算逻辑,并利用 DSL 提供的 API 接口,即可实现高性能的算子。与传统的手写代码和极限优化相比,这种方法虽然可能无法达到极致的性能,但已经能够实现超过 90%的性能水平,同时开发效率却能提升数十倍。这种权衡在许多情况下是合理的,因为它允许开发者以更高的效率开发出性能优异的应用程序。
TVM 开发算子
TVM 是 OctoML 研发的可扩展、开放的端到端 AI 编译器,用于神经网络模型的优化和部署,目标是减少企业为特定硬件开发和深度学习软件部署所花费的成本和时间。
TVM 极大的发扬了 Halide 的计算与调度思想,将可实现的优化都以调度 API 的方式呈现。相比 Triton,TVM 不局限于 CUDA,支持了更多的后端,并且也易于扩展更多后端。TVM 上一个典型的调度如下:
def schedule_dense_packed(cfg, outs):
"""Packed dense schedule."""
assert len(outs) == 1
output = outs[0]
const_ops = []
ewise_inputs = []
ewise_ops = []
dense_res = []
assert "int" in output.op.input_tensors[0].dtype
def _traverse(op):
if topi.tag.is_broadcast(op.tag):
if not op.same_as(output.op):
if not op.axis:
const_ops.append(op)
else:
ewise_ops.append(op)
for tensor in op.input_tensors:
if isinstance(tensor.op, tvm.te.PlaceholderOp):
ewise_inputs.append((op, tensor))
else:
_traverse(tensor.op)
else:
assert op.tag == "dense_pack"
dense_res.append(op)
_traverse(output.op)
assert len(dense_res) == 1
dense_stage = dense_res[0].output(0)
s = te.create_schedule(output.op)
##### space definition begin #####
b, c_o, _, _ = s[dense_stage].op.axis
c_i, _ = s[dense_stage].op.reduce_axis
cfg.define_split("tile_b", b, num_outputs=2)
cfg.define_split("tile_ci", c_i, num_outputs=2)
cfg.define_split("tile_co", c_o, num_outputs=2)
cfg.define_knob("oc_nthread", [1, 2])
###### space definition end ######
data, weight = dense_stage.op.input_tensors
env = get_env()
cdata = s.cache_read(data, env.inp_scope, [dense_stage])
cweight = s.cache_read(weight, env.wgt_scope, [dense_stage])
s[dense_stage].set_scope(env.acc_scope)
# cache read input
cache_read_ewise = []
for consumer, tensor in ewise_inputs:
cache_read_ewise.append(s.cache_read(tensor, env.acc_scope, [consumer]))
# set ewise scope
for op in ewise_ops:
s[op].set_scope(env.acc_scope)
s[op].pragma(s[op].op.axis[0], env.alu)
for op in const_ops:
s[op].compute_inline()
# apply tiling for SRAM reuse
x_b, x_c, _, _ = s[output].op.axis
x_bo, x_bi = cfg["tile_b"].apply(s, output, x_b)
x_co, x_ci = cfg["tile_co"].apply(s, output, x_c)
s[output].reorder(x_bo, x_co, x_bi, x_ci)
store_pt = x_co
# set all compute scopes
s[dense_stage].compute_at(s[output], store_pt)
for op in ewise_ops:
s[op].compute_at(s[output], store_pt)
for tensor in cache_read_ewise:
s[tensor].compute_at(s[output], store_pt)
s[tensor].pragma(s[tensor].op.axis[0], env.dma_copy)
# virtual threading along output channel axes
if cfg["oc_nthread"].val > 1:
_, v_t = s[output].split(x_co, factor=cfg["oc_nthread"].val)
s[output].reorder(v_t, x_bo)
s[output].bind(v_t, te.thread_axis("cthread"))
x_bo, x_co, x_bi, _ = s[dense_stage].op.axis
k_o, _ = s[dense_stage].op.reduce_axis
s[dense_stage].reorder(x_bo, k_o, x_co)
k_o, _ = cfg["tile_ci"].apply(s, dense_stage, k_o)
s[cdata].compute_at(s[dense_stage], k_o)
s[cweight].compute_at(s[dense_stage], k_o)
# Use VTA instructions
s[cdata].pragma(s[cdata].op.axis[0], env.dma_copy)
s[cweight].pragma(s[cweight].op.axis[0], env.dma_copy)
s[dense_stage].tensorize(x_bi, env.gemm)
s[output].pragma(x_ci, env.dma_copy)
return s
使用 TVM 提供的调度 API,可以轻松实现循环、指令、存储等级别的优化,还可以这些优化参数化,利用自动调优器来搜索一个更高效的实现,
TVM 当前被多个加速器厂商采用,进行了适应自家硬件的定制开发:
-
希姆计算
希姆计算基于 TVM 的 AI 编译器端到端支持希姆一代二代芯片,实现了自定义算子方案,其模型性能接近手写极致。
-
华为 TBE 张量加速引擎
TBE(Tensor Boost Engine)负责执行昇腾 AI 处理器中运行在 AI Core 上的算子,TBE 提供了基于 TVM 框架的自定义算子开发能力,通过 TBE 提供的 API 可以完成相应神经网络算子的开发。
Triton 开发算子
Triton 是 OpenAI 研发的专为深度学习和高性能计算任务设计的编程语言和编译器,它旨在简化并优化在 GPU 上执行的复杂操作的开发。Triton 的目标是提供一个开源环境,以比 CUDA 更高的生产力编写快速代码。
Triton 的核心理念是基于分块的编程范式可以有效促进神经网络的高性能计算核心的构建。CUDA 的编程模型是传统的 SIMT(Single Instruction Multi Thread)GPU 执行模型,在线程的细粒度上进行编程,Triton 是在分块的细粒度上进行编程。例如,在矩阵乘法的情况下,CUDA 和 Triton 有以下不同。
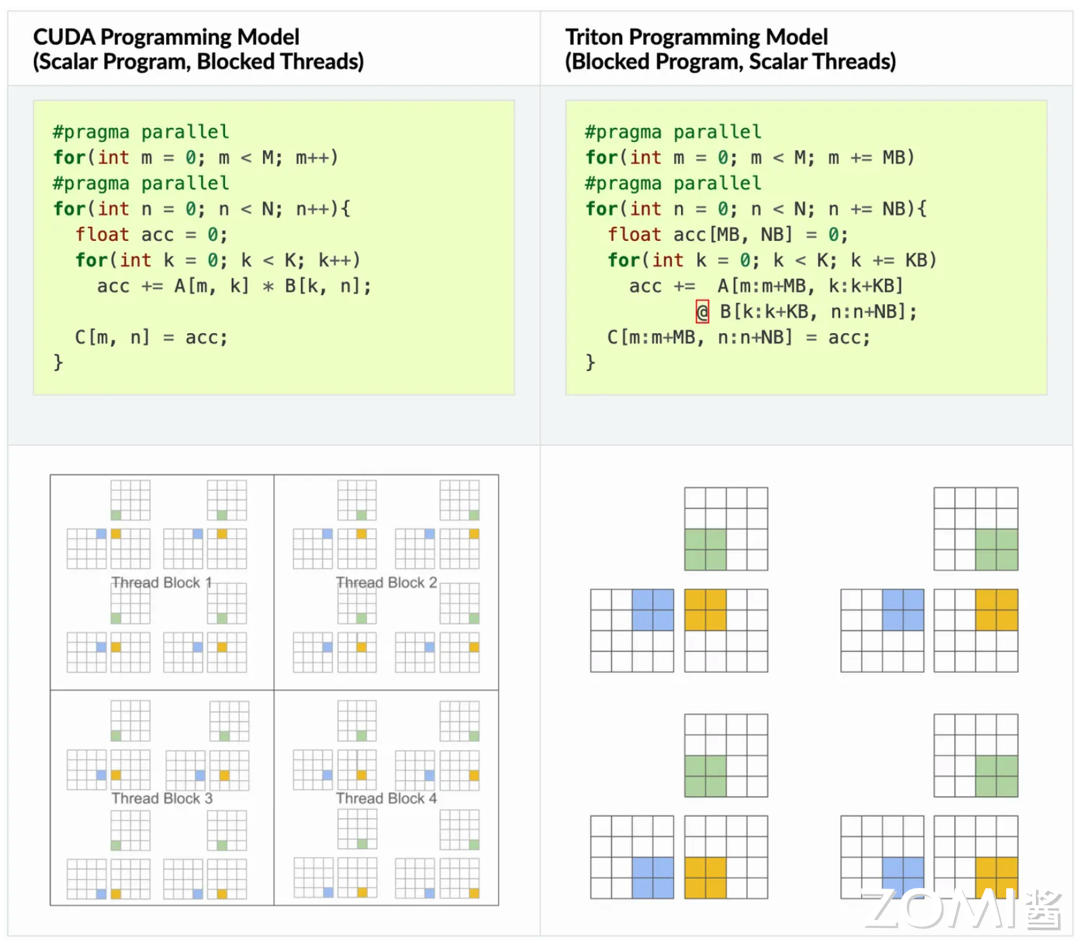
可以看出 triton 在循环中是逐块进行计算的。这种方法的一个关键优势是,它导致了块结构的迭代空间,相较于现有的 DSL,为程序员在实现稀疏操作时提供了更多的灵活性,同时允许编译器为数据局部性和并行性进行积极的优化。下面是一个使用 Triton 实现矩阵乘法的例子:
@triton.jit
def matmul_kernel(
a_ptr, b_ptr, c_ptr,
stride_am, stride_ak,
stride_bk, stride_bn,
stride_cm, stride_cn,
M: tl.constexpr, N: tl.constexpr, K: tl.constexpr, # M=N=K=1024
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr, #BLOCK_M=BLOCK_N=BLOCK_K=32
):
offs_m = tl.arange(0, BLOCK_M)
offs_n = tl.arange(0, BLOCK_N)
offs_k = tl.arange(0, BLOCK_K)
a_ptrs = a_ptr + offs_m[:, None] * stride_am + offs_k[None, :] * stride_ak
b_ptrs = b_ptr + offs_k[:, None] * stride_bk + offs_n[None, :] * stride_bn
accumulator = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
for k in range(0, K, BLOCK_K):
a = tl.load(a_ptrs)
b = tl.load(b_ptrs)
accumulator += tl.dot(a, b)
a_ptrs += BLOCK_K * stride_ak
b_ptrs += BLOCK_K * stride_bk
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_n[None, :] * stride_cn
tl.store(c_ptrs, accumulator)
Triton 的前端是基于 Python 实现的,这使得用户的学习成本大大降低,而其后端是基于 MLIR 构建的。Triton 的优化思想包括两部分:
-
Layout 抽象:Layout 抽象描述的是计算资源和输入、输出元素的坐标映射关系,主要包括块编码、共享内存编码、切片编码等几类定义,这些编码信息会作为 attribute 附着在一个一个的 Tensor 对象上,来描述这个 Tensor 作为输入或输出时所需满足的映射关系。如果出现一个 Tensor 作为输入和输出时的映射关系不兼容的情况,会再通过插入一些中转 layout 来完成兼容性的适配,代价是可能引入额外的转换开销。
-
优化 Pass:主要包括了英伟达 GPU 计算 kernel 优化的一些常见技巧,包括用于辅助向量化访存的coalescing、用于缓解计算访存差异的pipeline/prefetch,用于避免 shared memory 访问 bank-conflict 的swizzling。用户在开发 Kernel 时,主要关注其业务逻辑,而底层硬件优化的细节由 Trition 编译器实现。对于一些十分精细的优化,使用 Triton 可能就无法实现。
在应用场景上,Triton 已经被集成进了多个著名的课程中:
-
jax-ml/jax-triton:JAX 是一个用于加速数值计算的 Python 库,使用 Triton 编写可以嵌入到 JAX 程序中的自定义 GPU 内核。在 JAX 中可以使用 triton_call 方便的调用 Triton kernel。
-
PyTorch/inductor:Inductor 在 Triton 的集成方面做得更加全面且务实。Inductor 一共包含三种使用 Triton 的方式,针对非计算密集算子,基于 Inductor IR,实现了相对通用的Codegen的支持。针对 GEMM,基于 Jinja2,通过模式匹配的方式实现了半定制的 codegen。针对 Conv,调用pre-baked Triton kernel,没有提供定制能力。
Triton 实现原理
在没有 Triton 之前,算子工程师在开发算子时,需要同时处理 DRAM、SRAM、计算单元,面临诸多挑战:
- 内存管理:合理利用内存体系,将频繁访问的数据块缓存到较快的存储区域;对齐和合并访存请求,避免带宽浪费。
- 线程管理:最大化利用硬件计算资源,规划并行线程数量和线程束大小。
- 指令使用:使用 CUDA 实现一个功能有相应多种指令,不同指令具有不同延迟和吞吐量。
Triton 提高了算子开发时的效率,使得开发者不再囿于硬件细节。CUDA 直接面向 Thread 变成,而 Triton 面向 Thread Block 编程,开发者只需关注 1)Kernel launch 的参数;2)每个数据分块的大小;3)数据分块之间的交互。在这之下的细节由 Triton 实现。
Triton 是基于 MLIR 实现的,其架构如下图[1]:

Frontend 用于将开发者利用 Python 编写的 kernel 转换为对应的 Triton IR (Triton Dialect)。使用@triton.jit来标注 kernel,Triton 解析 Python AST,将用户定义的计算过程带入 MLIR 体系,之后继续做后续的优化。
Optimizer 大致工作流如下:

主要分为 1)TritonIR 的优化;2)TritonIR 到 TritonGPU IR 的转换;3)TritonGPU IR 的优化。贯穿中间的数据结构是 TritonGPU IR。
TritonGPU Dialect 相比 Triton Dialect,主要是增加了 GPU 硬件相关的 Op 和 Type。关键 Op 为数据布局转换。当前有以下几种数据布局:
- Blocked Layout:表示 thread 间平均分配 workload 的情况,每个线程处理一块 memory 上连续的数据。
- Shared Layout:表示数据在 shared memory 的一些特性。
- MMA Layout:表示 Tensor Core 中 MMA 指令结果的 data layout
- DotOperand Layout:表示 Triton 的 DotOp 的输入的 layout
列举一些典型的 data layout 的转换,以及特点:
#shared -> #blocked,正常是代表数据从 shared memory 被 load 到 register file 中,需要考虑 swizzle#blocked -> #shared,代表数据从 register file 存储到 shared memory 中,需要上一步相同的 swizzle 方式#mma -> #blocked,正常是 DotOp 的输出转换为更简单的 layout 来进一步计算,由于涉及到跨 thread 间的数据传递,因此一般会借由 shared memory 中转一次#blocked -> #dot_operand,转换为 DotOp 的输入,这一步可能也需要 shared memory 中转
TritonIR 上的优化主要是计算本身的,与硬件无关的优化,包含了如下 Pass:1)Inliner Pass,将 Kernel Call 的子函数 Inline 展开;2)Combine Pass,一些特定的 Pattern rewrite;3)Canonicalizer Pass,一些化简的 Pattern rewrite;4)CSE Pass,MLIR 的 cse Pass,用于 消除公共子表达式;5)LICM Pass,MLIR 的 LoopInvariantCodeMotion Pass ,将循环无关的变量挪到 forloop 外面。
TritonGPU IR 优化在计算本身优化外,新增了 GPU 硬件相关的优化,具体的 Pass 列表如下:1)ConvertTritonToTritonGPU Pass,将 Triton IR 转换为 TritonGPU IR,主要是增加 TritonGPU 特有的 layout;2)Coalesce Pass,重排 order,使得最大 contiguity 的维度排在最前面;3)Pipeline Pass,MMA 指令对应的 global memory 到 shared memory 的 N-Buffer 优化;4)Prefetch Pass,MMA 指令对应的 shared memory 到 register file 的 N-Buffer 优化
参考文献
[1]:Superjomn's blog | OpenAI/Triton MLIR 迁移工作简介
如果您想了解更多AI知识,与AI专业人士交流,请立即访问昇腾社区官方网站https://www.hiascend.com/或者深入研读《AI系统:原理与架构》一书,这里汇聚了海量的AI学习资源和实践课程,为您的AI技术成长提供强劲动力。不仅如此,您还有机会投身于全国昇腾AI创新大赛和昇腾AI开发者创享日等盛事,发现AI世界的无限奥秘~
转载自:https://www.cnblogs.com/ZOMI/articles/18560308

 浙公网安备 33010602011771号
浙公网安备 33010602011771号