
《高性能mysql》阅读笔记
第一章
mysql底层结构
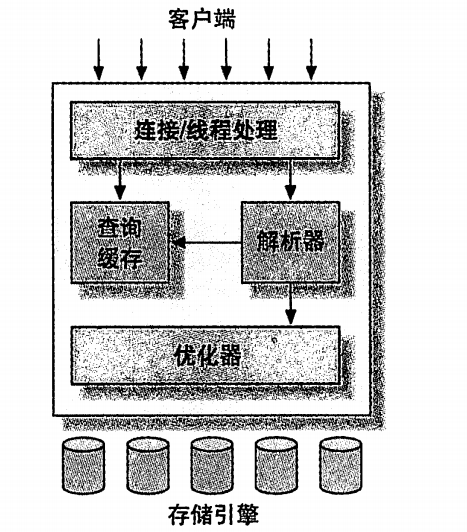
大致分为三层:
- 连接层:处理授权认证,权限等
- sql服务层:解析优化sql,内置函数,存储过程,触发器,视图;缓存也在本层
- 引擎层:各个引擎不同信,不解析sql,除了innodb会解析外键
并发控制
读锁:共享锁
写锁:排它锁
这里结合1.2.2索粒度,1.3.2死锁,1.4 MVCC和1.3.1隔离级别综合记录
数据库要想支持并发处理数据,必然要用到锁。分为俩种操作,读和写(update,insert)。一般来讲读影响比较小。从锁力度来讲要不然锁整个表要不然锁一行。行锁都由引擎完成,读或者写相互之间有多大的影响成为隔离级别分四种:
- read uncommitted :没提交我也能读,容易造成脏读(事务回滚后读出来的数据就脏的)
- repeated read :读就别写了,写就别让他人写也别读。造成幻读。(读写读模式,发现两次读结果多了一行)
- read committed:读等写完
- 穿行:最严格的的级别,所有操作串着来
innodb默认采用 repeate read的模式,有俩问题:幻读和死锁。
幻读解决:MVCC多版本并发控制,即每一行都有一个创建时间(版本)和过期时间(版本)。删除,创建,和更改都同时修改版本号(详细怎么做不做阐述),这样基本保证读操作不会阻塞,写也只是锁必要的行。
死锁:A事务要锁定a表的第一行要求修改b表的一行,B事务锁定b也要求修改a表的那行。innodb俩种解决方式:死锁检测和超时机制,回滚锁少的事务来完成。
事务
先说四大特征:
- atomic:原子性,不必说。一个事务就一个完整的sql语句,要么完成要么回滚
- isolation:隔离性,俩事务之间不相互影响
- duration:持久性,修改了就修改了,不能因为奔溃等原因又丢了数据
- consistency:一致性,数据库原来啥样,后来还啥样。比如说原来这个字段不能负数,之后也不能。不改变数据库的一致性
mysql本身有binlog等日志,可设置详细程度。repair db也是根据此来修复数据
mysql是自动commit,一句sql自动执行完自己commit;
一个事务中混着innodb表和myISAM表,回滚自然有问题
隐式锁定,事务中锁定,commit或者回滚后释放
innodb
innodb是mysql的默认引擎在create表的时候不设置则默认
上述诸多的说的都是innodb的特点这里总结和添加些
间隙锁,next-key lock 锁定一个范围避免幻读的产生
支持热备份,其他引擎:myISAM-非事务,表结构有放一个其他文件记录rows;memry-内存库;Archive-面向列数据
索引
定义:快速找到记录的一种数据结构
B+tree:
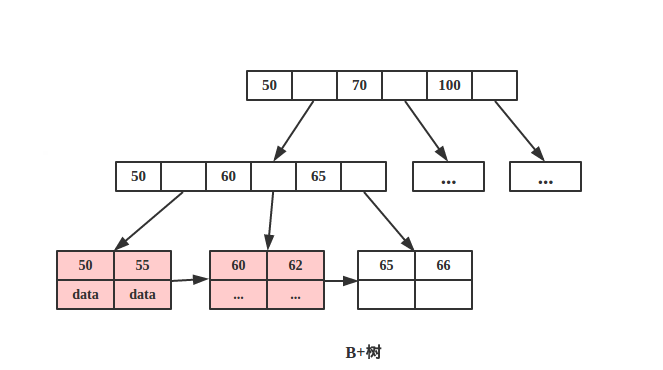
上图是简单b+tree,这里可简单的理解为树的左边都比右边小,每次查询数据随机漂移,最终找到记录。又主键和数据都在子叶中,成为聚簇原则。
主键设置遵循:小,短,最好自增。因为innodb有页数据存储方式。如每次添加主键不是自增,会造成数据频繁右移或者页分裂,造成访问缓慢,消耗磁盘的问题。实在需要的可以通过optimize table重新排列数据。
覆盖索引:当查询的数据就是索引本身,那直接返回索引就好。注意,二级索引(非主键)叶子节点保存的是主键值,最后要再依赖主键找数据。所以二级索引利用覆盖索引速度更快
例子:
mysql> explain select * from client_folder limit 1000000, 10;
+----+-------------+---------------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | client_folder | NULL | ALL | NULL | NULL | NULL | NULL | 574 | 100.00 | NULL |
+----+-------------+---------------+------------+------+---------------+------+---------+------+------+----------+-------+
这样每次都要找10000010条数据,抛弃后取10条
mysql> explain select * from client_folder inner join (select id from client_folder limit 100000, 10) as client_folder USING (id);
+----+-------------+---------------+------------+--------+---------------+------------------------------------------------------+---------+------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------+------------+--------+---------------+------------------------------------------------------+---------+------------------+------+----------+-------------+
| 1 | PRIMARY |
| 1 | PRIMARY | client_folder | NULL | eq_ref | PRIMARY | PRIMARY | 4 | client_folder.id | 1 | 100.00 | NULL |
| 2 | DERIVED | client_folder | NULL | index | NULL | client_folder_parent_id_00be4418_fk_client_folder_id | 5 | NULL | 574 | 100.00 | Using index |
+----+-------------+---------------+------------+--------+---------------+------------------------------------------------------+---------+------------------+------+----------+-------------+
利用主键的索引覆盖
最左原则:btree结构的索引,每次寻数据遵循最左原则。例如:a_b_c 联合索引查询a=3 b like "张%" c=3 的数据时候只能命中3_张 即ab。而b=“张三”c=3的情况不走索引。
一些索引优化: 有a_c就没必要在a上做索引,原因如上;去除多的索引;数据量小没必要做索引
其他索引
hash索引,一般用简单的crc方式(不用md5())。hash索引中,只保存响应的hash值和数据指针。优缺点
- 对长字符串很有效,很快。
- 无顺序,order by不能用索引排序
- 没聚簇原则
- 只支持等值查询,范围查询不走索引
- 很快,除非有hash冲突,因为是用简单hash,直接显式容易查出来多条数据
同时,innodb利用自适应hash在btree上再加一行hash索引,这样某些索引被频繁使用时候,提升了速度。不过是引擎隐式完成。在innodb中可以在表单中用触发器加一列crc保存hash值,这样查一些长字符串数据会变快。
全文索引:全文索引不是把字符串一个个匹配,而是关键词索引
空间索引:更神奇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号