偏差与方差
1. 为什么会有偏差和方差?
对学习算法除了通过实验估计其泛化性能,往往还希望了解它 “为什么” 具有这样的性能。“偏差-方差分解”(\(bias-variance\ decomposition\))是解释学习算法泛化性能的一种工具。
在机器学习中,我们用训练数据集去训练一个模型,通常的做法定义一个误差函数,通过误差最小化,来提高模型的性能。然而我们学习一个模型的目的是为了解决训练数据集这个领域中的一般化问题,单纯地将训练数据集的损失函数最小化,并不能保证在解决更一般的问题时模型仍然是最优,甚至不能保证模型是可用的。这个训练数据集的损失与一般化的数据集的损失之间的差异就是泛化误差。
泛化误差可分解为偏差(\(Biase\))、方差(\(Variance\))、噪声(\(Noise\))。
2. 偏差、方差、噪声是什么?
2.1 简述
我们能够获得所有可能的数据集合,并在这个数据集合上将损失函数最小化,此时学习得到的模型就可以称为 “真实模型”。在现实生活中,不可能获得并训练所有可能的数据,所以 “真实模型” 存在,但无法获得。
\(Bias\) 和 \(Variance\) 分别从两方面来描述我们学习到的模型与真实模型之间的差距。
\(Bias\) 是所有可能的训练数据集训练出的所有模型输出值的平均值与真实模型的输出值的差异。
\(Variance\) 是不同的训练数据集训练出的模型输出值之间的差异。
噪声是学习算法无法解决的问题。数据的质量决定学习的上限。假设数据给定,此时上限已定。
2.2 数学公式
| 符号 | 含义 |
|---|---|
| \(\pmb{x}\) | 测试样本 |
| \(D\) | 数据集 |
| \(y_D\) | \(\pmb{x}\) 在数据集中的标记 |
| \(y\) | \(\pmb{x}\) 的真实标记 |
| \(f\) | 训练集 \(D\) 学到的模型 |
| \(f(\pmb{x};D)\) | 由训练集 \(D\) 学到的模型 \(f\) 在上的 \(\pmb{x}\) 预测输出 |
| \(\bar{f}(\pmb{x})\) | 模型 \(f\) 对 \(\pmb{x}\) 的期望预测输出 |
以回归任务为例,学习算法的期望预测为
这里的期望预测也就是针对不同数据集 \(D\),模型 \(f\) 对样本 \(\pmb{x}\) 的预测值取期望,也叫平均预测。
① 偏差(\(Biase\))
期望输出与真实标记的差别称为偏差(\(bias\)),即:
偏差含义:度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力。
② 方差(\(Variance\))
样本数相同的不同训练集产生的方差为
方差含义:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
③ 噪声(\(Noise\))
噪声含义:表达了在当前任务上任何学习算法所能达到的期望泛化误差下界,即刻画了学习问题本身的难度。
3. 泛化误差、偏差、方差的关系?
泛化误差为偏差、方差、噪声之和。
证明:
假定噪声期望为 \(0\),即 \(\mathbb{E}_D[y_D-y] = 0\)。通过简单的多项式展开合并,对算法的期望泛化误差进行分解:
于是
4. 偏差-方差窘境
一般来说,偏差与方差有冲突,这称为偏差-方差窘境(\(bias-variance\ dilemma\))。
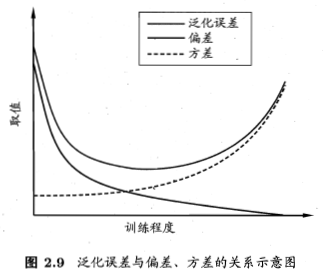
图 \(2.9\) 给出示意图,给定学习任务,假定能控制学习算法的训练程度,
则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;
随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;
在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的特性被学习器学到了,则将发生过拟合。
5. 偏差、方差与Bagging、Boosting的关系?
\(Bagging\) 算法是从训练集用自助采样法采出 \(T\) 个含 \(m\) 个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将基学习器结合。所以 \(Bagging\) 和随机森林主要关注降低方差(\(Variance\))。
\(Boosting\) 算法是迭代算法,每一次迭代都根据上一次迭代的结果对样本进行权重调整,随着迭代的不断进行,误差越来越小,所以 \(Boosting\) 主要关注降低偏差(\(Bias\))。
来自:偏差与方差

 浙公网安备 33010602011771号
浙公网安备 33010602011771号