
sklearn dataset 模块学习
sklearn.datasets官网:http://scikit-learn.org/stable/datasets/
sklearn.datasets 模块主要提供一些导入、在线下载及本地生成数据集的方法,可以通过 dir 或 help 命令查看,会发现主要有三种形式:load_<dataset_name>、fetch_<dataset_name> 及 make_<dataset_name> 的方法
sklearn 的数据集有好多个种
- 自带的小数据集(packaged dataset):sklearn.datasets.load_<name>
- 可在线下载的数据集(Downloaded Dataset):sklearn.datasets.fetch_<name>
- 计算机生成的数据集(Generated Dataset):sklearn.datasets.make_<name>
- svmlight/libsvm格式的数据集:sklearn.datasets.load_svmlight_file(...)
- 从买了data.org在线下载获取的数据集:sklearn.datasets.fetch_mldata(...)
1. dataset.load_<dataset_name>:sklearn包自带的小数据集

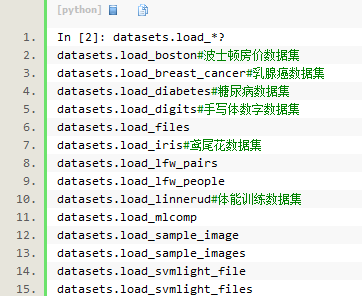
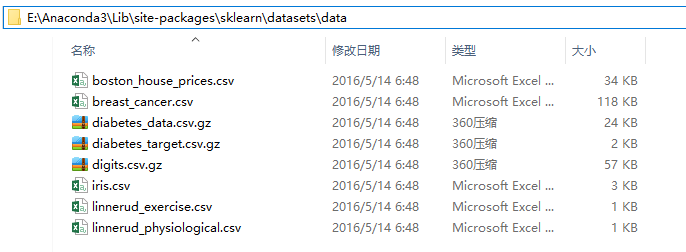
数据集文件在 sklearn 安装目录下 datasets\data 文件下
2. datasets.fetch_<dataset_name> :比较大的数据集,主要用于测试解决实际问题,支持在线下载
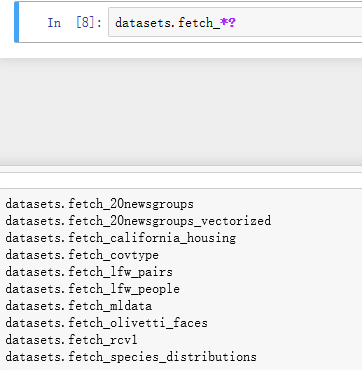
下载下来的数据,默认保存在~/scikit_learn_data文件夹下,可以通过设置环境变量SCIKIT_LEARN_DATA修改路径,datasets.get_data_home()获取下载路径

3. datasets.make_*?:构造数据集
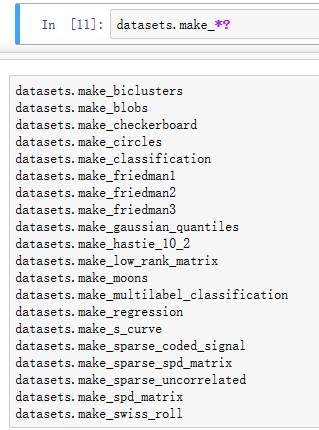
下面以make_regression()函数为例,首先看看函数语法:
make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)
参数说明:
- n_samples:样本数
- n_features:特征数(自变量个数)
- n_informative:相关特征(相关自变量个数)即参与了建模型的特征数
- n_targets:因变量个数
- bias:偏差(截距)
- coef:是否输出coef标识
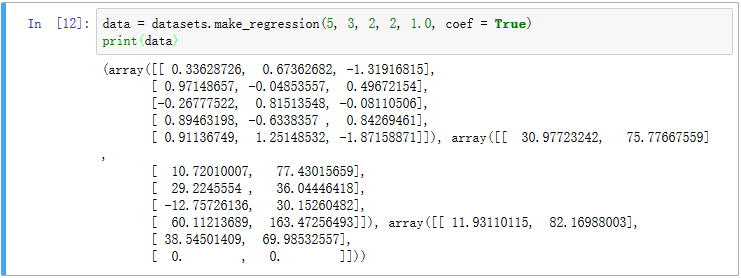
上述输出结果:元组中的三个数组分别对应输入数据X,输出数据y,coef对应数组。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号