深度卷积神经网络(AlexNet)
1. AlexNet
\(2012\) 年,\(AlexNet\) 横空出世。使用 \(8\) 层卷积神经网络,赢得 \(ImageNet\ 2012\) 图像识别挑战赛。
\(AlexNet\) 网络结构:
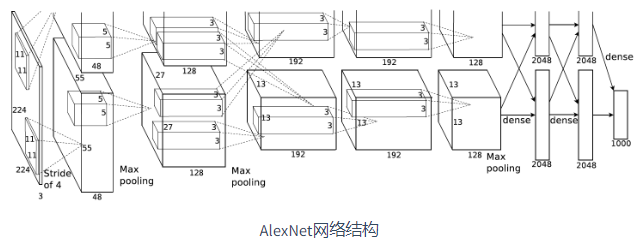
1.1 第一个卷积层
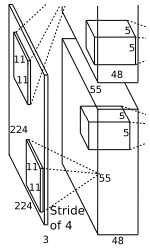
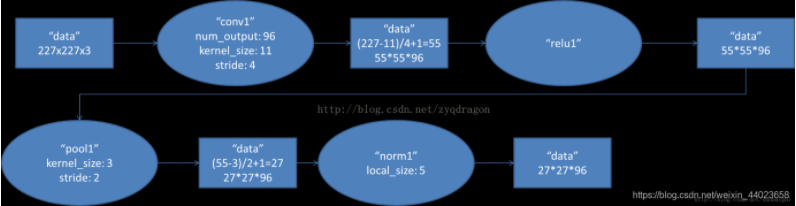
- 卷积运算:原始数据为 \(227 \times 227 \times 3\) 的图像。卷积核尺寸 \(11 \times 11 \times 3\)(\(高 \times 宽 \times 深度\)),步长 \(4\),每次卷积都生成一个新的像素,共有 \(96\)(\(2\) 个 \(48\)) 个卷积核。卷积核在移动过程中生成 \(\frac{(227-11)}{4} + 1 = 55\) 个像素。则卷积后的像素层为 \(55 \times 55 \times 96\)(\(2\) 组 \(55 \times 55 \times 48\)),每组在一个独立的 \(GPU\) 上运算。
- 激活函数:激活函数 \(ReLU\) 处理,生成激活像素层,尺寸为 \(55 \times 55 \times 96\)。
- 池化:池化窗口 \(3 \times 3\),步长 \(2\),则池化后图像的尺寸为 \(\frac{55-3}{2} + 1 = 27\)。池化后的像素层为 \(27 \times 27 \times 96\)。
- 归一化:归一化运算尺寸为 \(5 \times 5\)。
反向传播时,每个卷积核对应一个偏差值。即第一层的 \(96\) 个卷积核对应上层输入的 \(96\) 个偏差值。
1.2 第二个卷积层
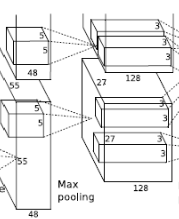
- 卷积运算:输入数据为 \(27 \times 27 \times 96\) 的像素层。上下左右都填充 \(2\) 个像素,卷积核尺寸 \(5 \times 5 \times 96\),步长 \(1\),每次卷积都生成一个新的像素,共有 \(256\)(\(2\) 个 \(128\)) 个卷积核。卷积核在移动过程中生成 \(\frac{(27 + 2 \times 2-5)}{1} + 1 = 27\) 个像素。则卷积后的像素层为 \(27 \times 27 \times 256\)(\(2\) 组 \(27 \times 27 \times 128\)),每组在一个独立的 \(GPU\) 上运算。
- 激活函数:激活函数 \(ReLU\) 处理,生成激活像素层,尺寸为 \(27 \times 27 \times 256\)。
- 池化:池化窗口 \(3 \times 3\),步长 \(2\),则池化后图像的尺寸为 \(\frac{27-3}{2} + 1 = 13\)。池化后的像素层为 \(13 \times 13 \times 256\)。
- 归一化:尺寸为 \(5 \times 5\)。
反向传播时,每个卷积核对应一个偏差值。即第一层的 \(256\) 个卷积核对应上层输入的 \(256\) 个偏差值。
1.3 第三个卷积层
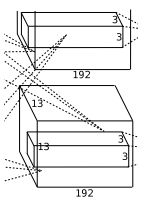

- 卷积运算:输入数据为 \(13 \times 13 \times 256\) 的像素层。上下左右都填充 \(1\) 个像素,卷积核尺寸 \(3 \times 3 \times 256\),步长 \(1\),每次卷积都生成一个新的像素,共有 \(384\)(\(2\) 个 \(192\)) 个卷积核。卷积核在移动过程中生成 \(\frac{(13 + 1 \times 2-3)}{1} + 1 = 13\) 个像素。则卷积后的像素层为 \(13 \times 13 \times 384\)(\(2\) 组 \(13 \times 13 \times 192\)),每组在一个独立的 \(GPU\) 上运算。
- 激活函数:激活函数 \(ReLU\) 处理,生成激活像素层,尺寸为 \(13 \times 13 \times 384\)。
1.4 第四个卷积层
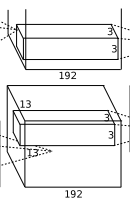

- 卷积运算:输入数据为 \(13 \times 13 \times 384\) 的像素层。上下左右都填充 \(1\) 个像素,卷积核尺寸 \(3 \times 3 \times 384\),步长 \(1\),每次卷积都生成一个新的像素,共有 \(384\)(\(2\) 个 \(192\)) 个卷积核。卷积核在移动过程中生成 \(\frac{(13 + 1 \times 2-3)}{1} + 1 = 13\) 个像素。则卷积后的像素层为 \(13 \times 13 \times 384\)(\(2\) 组 \(13 \times 13 \times 192\)),每组在一个独立的 \(GPU\) 上运算。
- 激活函数:激活函数 \(ReLU\) 处理,生成激活像素层,尺寸为 \(13 \times 13 \times 384\)。
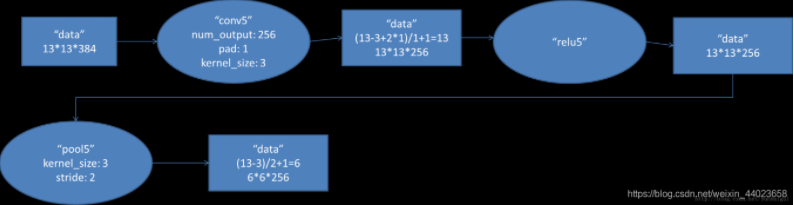
1.5 第五个卷积层
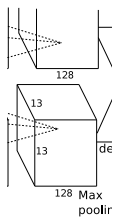
-
卷积运算:输入数据为 \(13 \times 13 \times 384\) 的像素层。上下左右都填充 \(1\) 个像素,卷积核尺寸 \(3 \times 3 \times 384\),步长 \(1\),每次卷积都生成一个新的像素,共有 \(256\)(\(2\) 个 \(128\)) 个卷积核。卷积核在移动过程中生成 \(\frac{(13 + 1 \times 2-3)}{1} + 1 = 13\) 个像素。则卷积后的像素层为 \(13 \times 13 \times 256\)(\(2\) 组 \(13 \times 13 \times 128\)),每组在一个独立的 \(GPU\) 上运算。
-
激活函数:激活函数 \(ReLU\) 处理,生成激活像素层,尺寸为 \(13 \times 13 \times 256\)。
-
池化:池化窗口 \(3 \times 3\),步长 \(2\),则池化后图像的尺寸为 \(\frac{13-3}{2} + 1 = 6\)。池化后的像素层为 \(6 \times 6 \times 256\)。
1.6 全连接层
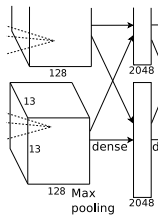
-
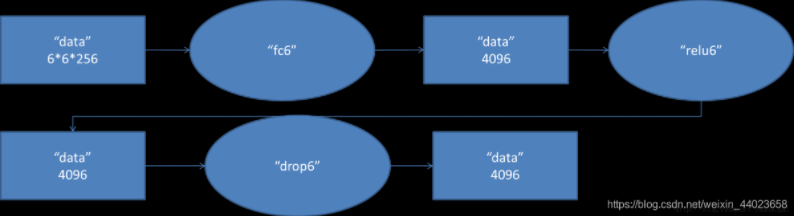
全连接层:输入数据为 \(6 \times 6 \times 256 = 9216\) 的像素层,输出为 \(4096\)
-
激活函数:激活函数 \(ReLU\) 处理,生成激活像素层,尺寸为 \(4096\)。
-
丢弃法(\(Dropout\)):全连接层的输出数量是 \(LeNet\) 中的好几倍。使用 \(Dropout\) 层来减轻过拟合。
1.7 全连接层
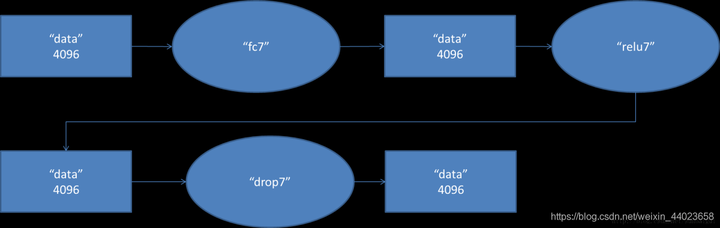
第六层输出的 \(4096\) 个数据与第七层的 \(4096\) 个神经元进行全连接,然后经由 \(ReLU7\) 进行处理后生成 \(4096\) 个数据,再经过 \(Dropout7\) 处理后输出 \(4096\) 个数据。
1.8 全连接层

第七层输出的 \(4096\) 个数据与第八层的 \(1000\) 个神经元进行全连接,经过训练后输出被训练的数值。
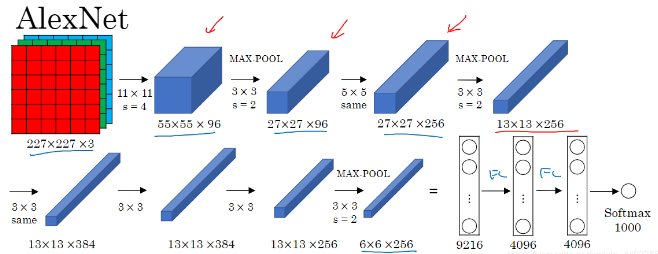
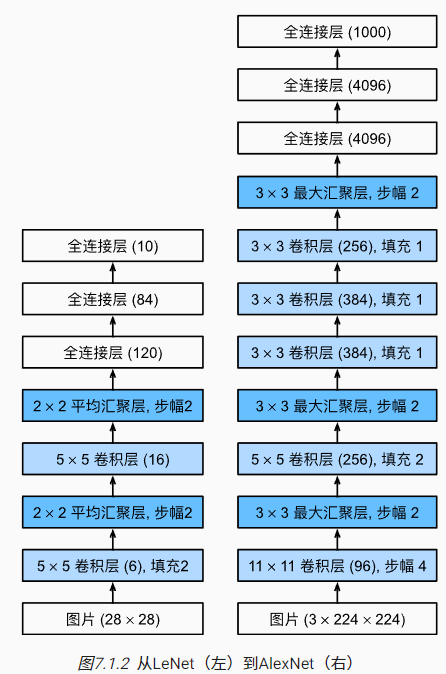
1.9 AlexNet 网络架构
\(AlexNet\) 网络架构:
2. AlexNet与LeNet5区别
- \(AlexNet\) 比 \(LeNet5\) 网络深。\(AlexNet\) 由 \(8\) 层组成:\(5\) 个卷积层、\(2\) 个全连接隐藏层和 \(1\) 全连接输出层。
- 第一个卷积层窗口形状 \(11 \times 11\)。
- 第二个卷积层窗口形状 \(5 \times 5\)。
- 第三、四、五个卷积层窗口形状 \(3 \times 3\)。
- 第一、第二和第五个卷积层之后都使用了窗口形状 \(3 \times 3\)、步幅 \(2\) 的最大池化层。
- \(AlexNet\) 卷积通道数是 \(LeNet\) 的十倍。
- \(AlexNet\) 使用 \(ReLU\) 激活函数。原因:
- \(ReLU\) 激活函数的计算更简单,没有求幂运算。
- \(ReLU\) 激活函数在不同的参数初始化方法下使模型更容易训练。这是由于当 \(sigmoid\) 激活函数输出极接近 \(0\) 或 \(1\) 时,这些区域的梯度几乎为 \(0\),从而造成反向传播无法继续更新部分模型参数;而 \(ReLU\) 激活函数在正区间的梯度恒为 \(1\)。因此,若模型参数初始化不当,\(sigmoid\) 函数可能在正区间得到几乎为 \(0\) 的梯度,从而令模型无法得到有效训练。
- \(AlexNet\) 通过丢弃法控制全连接层的模型复杂度。而 \(LeNet\) 没有。
3. AlexNet在当时包含的新技术点
\(AlexNet\) 在当时包含了几个比较新的技术点,首次在 \(CNN\) 中成功应用了 \(ReLU、Dropout、LRN\) 等 \(Trick\)。同时也使用了 \(GPU\) 加速。
- 使用 \(ReLU\) 代替 \(Sigmoid\),成功解决了 \(Sigmod\) 在网络较深的梯度弥散问题。
- 训练时使用 \(Dropout\) 对隐藏层的输出随机置 \(0\),避免模型过拟合。
- 使用最大池化代替平均池化,避免平均池化的模糊化效果。并且 \(AlexNet\) 中池化的步长比池化窗口的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升特征的丰富性。
- 使用 \(CUDA\) 加速。
- 使用数据增强。
- 训练:随机从 \(256 \times 256\) 的原始图中截取 \(224 \times 224\) 大小的区域(以及水平翻转的镜像),相当增加了 \(2 \times (256-254)^2 = 2048\) 倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的 \(CNN\) 会陷入过拟合。
- 预测:取图片的四个角加中间共 \(5\) 个位置,并进行左右翻转,一共获得 \(10\) 张图片,对他们进行预测并对 \(10\) 次结果求均值。
- \(AlexNet\) 论文中提到会对图像的 \(RGB\) 数据进行 \(PCA\) 处理,对主成分做一个标准差为 \(0.1\) 的高斯扰动,增加一些噪声,这个\(Trick\) 让错误率再下降 \(1 \%\)。
附录
- 最大池化层优于平均池化层原因:最大池化层输出值比较大,从而梯度值比较大,使得训练更加容易。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号