pandas.DataFrame.ewm()
DataFrame.ewm(self,com=None,halflife=None, alpha=None, min_periods=0, adjust=True, ignore_na=False, axis=0)
提供指数加权平均。
| 返回值 | DataFrame |
|---|---|
| 参数 | com:float,可选 根据质心指定衰减,α=1/(1+com), for com≥0 span:float,可选 根据范围指定衰减,α=2/(span+1), for span≥1 halflife:float,可选 根据半衰期指定衰减,α=1−exp(log(0.5)/halflife), for halflife>0 alpha:float,可选 指定平滑系数α,0<α≤1 min_periods:int,默认为0 窗口中具有值的最小观察数(否则结果为NA) adjust:bool,默认为True 除以开始阶段的衰减调整因子,以解释相对权重的不平衡(将EWMA视为移动平均线) ignore_na:bool,默认为False 计算权重时忽略缺失值;指定True重现0.15.0版本之前的行为。 axis:{0或者'index',1或‘columns’},默认为0,标识行,值1标识列。 |
必须提供质心(com)、跨度(span)、半衰期(half-life)和alpha值之一。
当adjust = True(默认)时,将使用权重(1-α)^(n-1), (1-α)^(n-2),...1-α, 1来计算加权平均值。
当adjust = False时,按照下式递归计算加权平均值:
weightd_average[0] = arg[0];
weighted_avreaged[i] = (1-α) * weighted_average[i-1] + α * arg[i]
当ignore_na = False时,权重基于绝对值位置。
当ignore_na = True时,权重基于相对值位置。
例如,用于计算 [x, None, y] 的最终加权平均值的 x 和 y 的权重分别为
(1-α)^2 和 1 (如果 adjust = True) ;
(1-α) 和 α (如果adjust = False)
例子
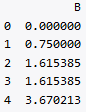
df = pd.DataFrame({'B': [0, 1, 2, np.nan, 4]})
df

df.ewm(com = 0.5).mean()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号