Python groupby()
用法一:
groupby()函数扫描整个序列并且查找连续相同值(或根据指定 key 函数返回值相同)的元素序列。
每次迭代,返回一个值和一个迭代器对象。
from operator import itemgetter from itertools import groupby rows = [ {'address': '5412 N CLARK', 'date': '07/01/2012'}, {'address': '5148 N CLARK', 'date': '07/04/2012'}, {'address': '5800 E 58TH', 'date': '07/02/2012'}, {'address': '2122 N CLARK', 'date': '07/03/2012'}, {'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'}, {'address': '1060 W ADDISON', 'date': '07/02/2012'}, {'address': '4801 N BROADWAY', 'date': '07/01/2012'}, {'address': '1039 W GRANVILLE', 'date': '07/04/2012'}, ] for date, items in groupby(rows, key=itemgetter('date')): print(date) for i in items: print(i)
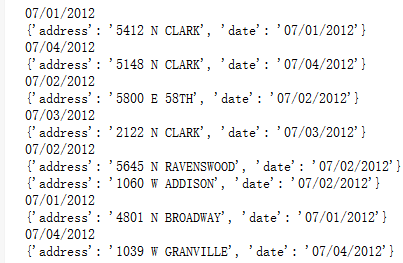
对 groupby() 的使用,最重要的的是要根据指定字段将数据排序,因为 groupby() 仅仅检查连续的元素。
from operator import itemgetter from itertools import groupby rows = [ {'address': '5412 N CLARK', 'date': '07/01/2012'}, {'address': '5148 N CLARK', 'date': '07/04/2012'}, {'address': '5800 E 58TH', 'date': '07/02/2012'}, {'address': '2122 N CLARK', 'date': '07/03/2012'}, {'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'}, {'address': '1060 W ADDISON', 'date': '07/02/2012'}, {'address': '4801 N BROADWAY', 'date': '07/01/2012'}, {'address': '1039 W GRANVILLE', 'date': '07/04/2012'}, ] rows.sort(key=itemgetter('date')) for date, items in groupby(rows, key=itemgetter('date')): print(date) for i in items: print(i)
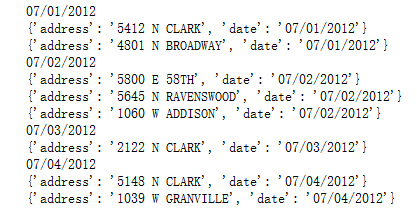
用法二:
groupby() 函数可以进行数据的分组以及分组后的组内运算。
print(df["评分"].groupby([df["地区"],df["类型"]]).mean())
该条语句的功能:输出数据中不同地区不同类型的评分的平均值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号