pandas分组运算(groupby)
1. groupby()
import pandas as pd df = pd.DataFrame([[1, 1, 2], [1, 2, 3], [2, 3, 4]], columns=["A", "B", "C"]) print(df)

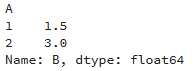
g = df.groupby('A').mean() # 按A列分组(groupby),获取其他列的均值 print(g)

# 方法1 b = df['B'].groupby(df['A']).mean() # 按A列分组,获取B列的均值 print(b) # 方法2 b = df.ix[:,1].groupby(df.ix[:, 0]).mean() # 按A列分组(0对应A列,1对应B列),获取B列的均值 print(b) # 方法3 m = df.groupby('A') b = m['B'].mean() print(b)
2. 聚合方法size()和count()
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
import pandas as pd
import numpy as np
df = pd.DataFrame({"Name":["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"],
"City":["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"],
"Val":[4,3,3,np.nan,np.nan,4]})
print(df)
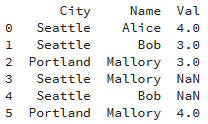
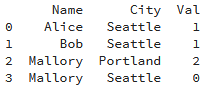
count()
a = df.groupby(["Name", "City"], as_index=False)['Val'].count()
print(a)
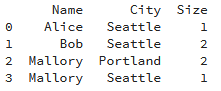
size()
b = df.groupby(["Name", "City"])['Val'].size().reset_index(name='Size')
print(b)
来自:https://blog.csdn.net/m0_37870649/article/details/80979809

 浙公网安备 33010602011771号
浙公网安备 33010602011771号