
决策树后剪枝
决策树的剪枝通过极小化决策树整体的损失函数。(决策树的生成只考虑局部最优,决策树的剪枝考虑全局最优)。
设 \(t\) 是树 \(T\) 的叶节点,个数为 \(|T|\),该叶节点有 \(N_t\) 个样本点,其中 \(k\) 类的样本点有 \(N_{tk}\) 个,\(k=1,2,...,K\),\(H_t(T)\) 为叶节点 \(t\) 上的经验熵,\(\alpha \ge 0\) 为参数,则决策树的损失函数为
所有叶节点的经验熵 + \(\alpha\) \(\times\) 所有叶节点的个数
经验熵(特征熵)为
在损失函数中,将式 \((1)\) 右端的第 \(1\) 项记为
这时有
式 \((4)\) 中,\(C(T)\) 表示模型对训练集的预测误差,即模型与训练集的拟合程度。\(|T|\) 表示模型复杂度,
参数 \(\alpha \ge 0\) 控制两者之间的影响。较大的 \(\alpha\) 促使选择较简单的模型(树),较小的 \(\alpha\) 促使选择较复杂的模型(树)。\(\alpha=0\) 表示只考虑模型与训练集的拟合程度,不考虑模型的复杂度。
剪枝通过优化损失函数减小模型复杂度,就是当 \(\alpha\) 确定时,选择损失函数最小的模型,即损失函数最小的子树。
当 \(\alpha\) 值确定时,子树越大,与训练集拟合越好,但模型复杂度越高;子树越小,与训练集拟合的不好,复杂度越低。损失函数表示了对两者的平衡。
式 \((1)\)、\((4)\) 定义的损失函数极小化等价于正则化的极大似然估计。所以,利用损失函数最小原则进行剪枝就是用正则化的极大似然估计进行模型选择。
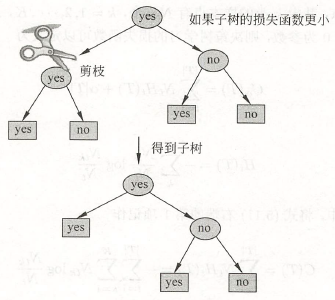
后剪枝算法:
输入:生成的决策树 \(T\),参数 \(\alpha\);
输出:修剪后的子树 \(T_\alpha\)。
① 计算每个叶节点的经验熵。
② 递归地从树上的叶节点向上回缩。
设一组叶节点回缩到父结点之前与之后的整体树分别为 \(T_B\) 与 \(T_A\),其对应的损失函数值分别为 \(C_\alpha(T_B)\)、\(C_\alpha(T_A)\),如果
\[C_\alpha(T_A) \le C_\alpha(T_B) \tag{5} \]则进行剪枝,将父结点变为新的叶节点。
③ 返回 ②,直至不能继续为止,得到损失函数最小的子树 \(T_\alpha\)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号