感知机
感知机思想:在二维就是找到一条直线,在三维或者更高维就是找到一个分离超平面,将所有二元类别分开。
使用感知机最大前提就是数据线性可分。支持向量机面对不可分时通过核函数让数据高维可分,神经网络通过激活函数和隐藏函数让数据可分。
一、感知机模型
由输入空间(特征空间)到输出空间的如下函数:
称为感知机。\(\omega\) 叫权值或权值向量,\(b\) 叫偏置。\(sign\) 是符号函数。
二、感知机学习策略
1.数据集线性可分
数据集:\(T={(x_1,y_1), (x_2,y_2),..., (x_N,y_N)}\),\(i=1,2, \cdots, N\)
如果存在超平面 \(S\) 将数据集完全正确的划分到超平面两侧,即对所有 \(y_i=1\) 的实例 \(i\) ,有 \(\omega\cdot\ x_i+b>0\) ,对所有 \(y_i=-1\) 的实例 \(i\) ,有 \(\omega\cdot\ x_i+b<0\),则称数据集 \(T\) 线性可分,否则,线性不可分。
2.感知机学习策略
学习策略:定义损失函数并将损失函数极小化。
损失函数的两个选择:一是误分类点的总数,二是误分类点到超平面 \(S\) 的总距离。但是前者的损失函数不是 \(\omega\)、\(b\) 的连续可导函数,不易优化。所以感知机采用后者。
任一点 \(x_0\) 到超平面 \(S\) 的距离:
\(\|\omega\|\) 是 \(\omega\) 的 \(L_2\) 范数。
误分类点 \(x_i\) 到超平面 \(S\) 的距离:
因为是误分类点,所以当 \(\omega\cdot\ x_i+b>0\) 时,\(y_i=-1\);当 \(\omega\cdot\ x_i+b<0\) 时,\(y_i=1\)。
所有误分类点到超平面 \(S\) 的距离(误分类点集合 \(M\)):
不考虑 \(\frac{1}{\|\omega\|}\),就得到感知机的损失函数:
结论:
-
损失函数非负。如果没有误分类点,损失函数值为0。
-
误分类点越少,误分类点离超平面越近,损失函数越小。
-
损失函数 \(L(\omega,b)\) 是 \(\omega\)、\(b\) 的连续可导函数。
三、感知机学习算法
随机梯度下降法。基于所有样本的梯度和均值的批量梯度下降法(\(BGD\))行不通,原因在于损失函数有限定,只有 \(M\) 里的样本才参与损失函数的优化。只能采用随机梯度下降(\(SGD\))或小批量梯度下降(\(MBGD\))。
1.原始形式
损失函数极小化:
选取一个超平面 \(\omega_0\),\(b_0\),用梯度下降法不断极小化目标函数 \((3)\)。极小化过程不是一次使 \(M\) 中所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。
损失函数 \(L(\omega,b)\) 的梯度由
给出。
随机选取一个误分类点,对 \(\omega\),\(b\) 更新:
\(\eta\) 是步长,通过迭代使损失函数 \(L(\omega,b)\) 不断减小,直到为0。
感知机学习算法的原始形式:
输入:训练集 \(T={(x_1,y_1), (x_2,y_2),..., (x_N,y_N)}\),学习率 \(\eta(0<\eta≤1)\)
输出:\(\omega,b\);感知机模型\(f(x)=sign(\omega\cdot\ x+b)\)
(1)选取初始值 \(w_0\),\(b_0\)
(2)在训练集选取数据 \((x_i,y_i)\)
(3)如果 \(y_i(\omega\cdot\ x+b)≤0\)
\[\begin{aligned} & \omega\gets\omega+\eta\ y_ix_i \\ & b\gets\ b+\eta\ y_i \end{aligned} \](4)转至(2),直到没有误分类点。
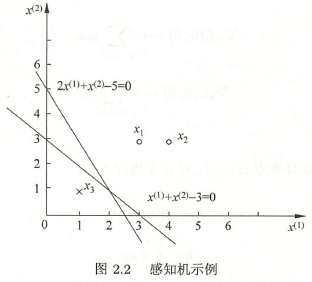
例 \(1\):正实例点 \(x_1=(3,3)^T\),\(x_2=(4,3)^T\),负实例点 \(x_3=(1,1)^T\),用感知机学习算法的原始形式求感知机模型 \(f(x)=sign(\omega\cdot\ x+b)\)。这里 \(\omega=(\omega^{(1)},\omega^{(2)})^T\),\(x=(x^{(1)},x^{(2)})^T\)。
解:构建最优化问题:
按照以上算法求解 \(\omega,b\)。
(1)取初始值 \(\omega_0=0\),\(b_0=0\)
(2)对正实例点 \(x_1=(3,3)^T\),
因为是正实例点,所以 \(y_1=1\),则 \(y_1(\omega_0\cdot\ x_1+b_0)=0\),
因为损失函数等于0,更新 \(\omega\)、\(b\)。
得到:
(3)对 \(x_1\),\(x_2\),显然,\(y_i(\omega_1\cdot\ x_i+b)>0\),被分类正确,不修改 \(\omega\),\(b\);
对负实例点 \(x_3=(1, 1)^T\),\(y_3(\omega_1\cdot\ x_3+b_1)<0\),被误分类,更新 \(\omega\),\(b\)。
得到:
如此下去,直到
对所有数据点 \(y_i(x_7\cdot\ x_i+b_7)>0\),没有误分类点,损失函数达到极小。
分离超平面:\(x^{(1)}+x^{(2)}-3=0\)
感知机模型:\(f(x)=sign(x^{(1)}+x^{(2)}-3)\)
迭代过程如下表 \(1.1\)。
| \(0\) | \(0\) | \(0\) | \(0\) | |
| \(1\) | \(x_1\) | \((3,3)^T\) | \(1\) | \(3x^{(1)}+3x^{(2)}+1\) |
| \(2\) | \(x_3\) | \((2,2)^T\) | \(0\) | \(2x^{(1)}+2x^{(2)}\) |
| \(3\) | \(x_3\) | \((1,1)^T\) | \(-1\) | \(x^{(1)}+x^{(2)}-1\) |
| \(4\) | \(x_3\) | \((0,0)^T\) | \(-2\) | \(-2\) |
| \(5\) | \(x_1\) | \((3,3)^T\) | \(-1\) | \(3x^{(1)}+3^{(2)}-1\) |
| \(6\) | \(x_3\) | \((2,2)^T\) | \(-2\) | \(2x^{(1)}+2x^{(2)}-2\) |
| \(7\) | \(x_3\) | \((1,1)^T\) | \(-3\) | \(x^{(1)}+x^{(2)}-3\) |
| \(8\) | \(0\) | \((1,1)^T\) | \(-3\) | \(x^{(1)}+x^{(2)}-3\) |
上面是误分类点先后取 \(x_1,x_3,x_3,x_3,x_1,x_3,x_3\),得到的分离超平面。
如果误分类点依次取 \(x_1,x_3,x_3,x_3,x_2,x_3,x_3,x_3,x_1,x_3,x_3\),得到分离超平面是 \(2x^{(1)}+x^{(2)}-5=0\)。
所以,感知机学习算法采用不同的初值或选取不同顺序的分类点,结果不同。
2.对偶形式
感知机学习算法的对偶形式与支持向量机学习算法的对偶形式相对应。
对偶形式的思想:将 \(\omega\)、\(b\) 表示为 \(x_i\) 和 \(y_i\) 的线性组合形式求解 \(\omega\)、\(b\)。
对误分类点 \((x_i,y_i)\) 通过
逐步修改 \(\omega\)、\(b\),设修改 \(n\) 次,则最后得到的 \(\omega\)、\(b\) 表示为(\(\alpha_i=n_i\eta\)):
这里 \(\alpha_i≥0, \ \ i=1,2,...,N\),当 \(\eta=1\) 时,表示第 \(i\) 个实例点由于误分而更新的次数。实例点更新次数越多,意味距离分离超平面越近,越难正确分类。
输入:训练集 \(T={(x_1,y_1), (x_2,y_2),..., (x_N,y_N)}\),学习率 \(\eta(0<\eta≤1)\)
输出:\(\alpha,b\);感知机模型 \(f(x)=sign(\sum_{j=1}^N\alpha_iy_ix_i\cdot\ x+b)\),其中 \(\alpha=(\alpha_1,\alpha_2,...,\alpha_N)^T\)。
(1)\(\alpha\gets0,\ \ b\gets0\);
(2)在训练集选取数据 \((x_i,y_i)\);
(3)如果 \(y_i(\sum_{j=1}^N\alpha_iy_ix_i\cdot\ x+b)≤0\),
\[\begin{aligned} & \alpha_i\gets\alpha_i+\eta \\ & b\gets\ b+\eta \ y_i \end{aligned} \](4)转至(2)直到没有误分类数据。
对偶形式中的实例仅以内积形式出现。所以将实例间的内积计算出来并以矩阵形式储存,这个矩阵就是格拉姆矩阵(\(Gram\) 矩阵)。
例 \(2\):正样本点 \(x_1=(3,3)^T\),\(x_2=(4,3)^T\),负样本点 \(x_3=(1,1)^T\),用感知机学习算法的对偶形式求感知机模型。
解:
(1)取 \(\alpha_i=0,\ b=0,\ i=1,2,3,\ \eta=1\)
(2)计算 \(Gram\) 矩阵
(3)误分条件
参数更新
(4)迭代。结果如下表 \(1.2\);
(5)
分离超平面
感知机模型
迭代过程如下表 \(1.2\):
| \(x_1\) | \(x_3\) | \(x_3\) | \(x_3\) | \(x_1\) | \(x_3\) | \(x_3\) | ||
| \(\alpha_1\) | \(0\) | \(1\) | \(1\) | \(1\) | \(1\) | \(2\) | \(2\) | \(2\) |
| \(\alpha_2\) | \(0\) | \(0\) | \(0\) | \(0\) | \(0\) | \(0\) | \(0\) | \(0\) |
| \(\alpha_3\) | \(0\) | \(0\) | \(1\) | \(2\) | \(3\) | \(3\) | \(4\) | \(5\) |
| \(b\) | \(0\) | \(1\) | \(0\) | \(-1\) | \(-2\) | \(-1\) | \(-2\) | \(-3\) |
对照表 \(1.1\),结果一致,迭代步骤也相互对应。
与原始形式一样,感知机学习算法的对偶形式迭代也是收敛的,存在多个解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号