循环神经网络与LSTM网络
循环神经网络与LSTM网络
循环神经网络RNN
循环神经网络广泛地应用在序列数据上面,如自然语言,语音和其他的序列数据上。序列数据是有很强的次序关系,比如自然语言。通过深度学习关于序列数据的算法要比两年前的算法有了很大的提升。由此诞生了很多有趣的应用,比如语音识别,音乐合成,聊天机器人,机器翻译,自然语言理解和其他的一些应用。
符号说明:
上标[l]: 表示第层,例如,例如是第四层的激活元。和是层参数
上标(i):表示第i个样本,例如表示第训练样本输入
上标<t>:表示第个时间戳,例如是输入x在第的时间戳。是样本i
个时间戳
下标i:表示向量中的第项。例如表示激活元在l层中的第项
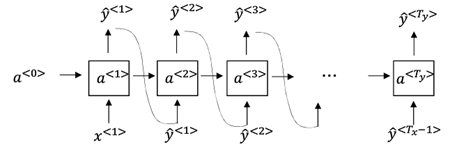
循环神经网络的基本结构如下:
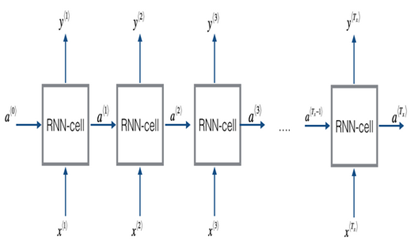
简单的说明,x就是我们输入的序列数据,如果让每一个表示一个字符的话,单词hello,就会有四个输入,分别表示h,e,l,l,o。y是我们的输出数据,我们希望通过获得的下一个字符。在这个例子中是hello的第一个字符h,的下一个字符为e,因此我们希望为e。
循环神经网络的输入:(h,e,l,l,o)
循环神经网络的输出:(根据实际的输出情况)
输出正确的标签:(e,l,l,o, )
其中为隐变量记录之前的状态信息用来计算下一个,以及
图中的每个RNN-cell结构都是相同的(所有的参数也一样)。因此上图中的循环神经网络也可以表示成如下的形式
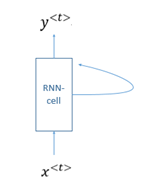
该模型有点像隐马尔可夫模型,每一个预测结果只依赖与前一个节点的信息,而与无关。
对于每一个RNN-cell的内容如下:
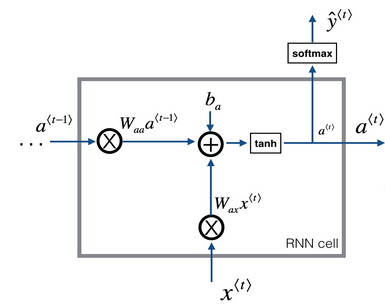
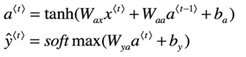
这是基本的RNN单元,通过当前的输入和(之前的隐藏状态包含了过去的信息)进行计算获得预测的下一个字符以及来给下一层RNN单元计算。
代价函数的计算
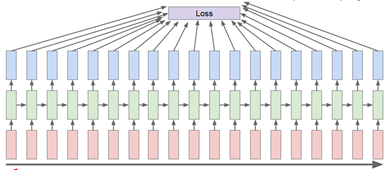
要对整个前向传播中产生的预测结果y都要用来计算代价代价函数。代价函数可以使用上次提到的交叉熵来计算。将预测结果与输出的正确标签做交叉熵。
由于给出了RNN-cell的结果因此循环神经网络可以进行前向传播了。由于现在的深度学习框架比如tensorflow等很方便,只要定义好前向传播的过程,以及代价函数,框架就会帮你进行反向传播计算。
如果不用tensorflow框架进行神经网络搭建这里还是给出了循环神经网络的反向传播计算公式(注:如果求导过于复杂可以通过Calculus软件进行求导的计算,该软件会给出具体的求导过程)

对于训练好的模型进行采样
还是以上面的例子为例,在采样的过程中用户输入第一个字符='h',循环神经网络根据'h'预测'h'的下一个字符最大概率为'e',把预测的字符'e'作为下一个输入以此循环递归。关于何时结束,我们可以指定定长的字符生成后结束。注意:在大样本的训练中,为了保证结果的多样性,我们一般不直接选择预测最大的字符作为下一个输入字符,而是在预测的结果序列进行概率采样,或者随机采样。
LSTM(长短时记忆网络)
上文中已经提到了可以对序列模型进行训练,以及采样。但是由于循环神经网络层数过多,存在梯度消失的问题。该问题直接导致的效果如下。假设有下面两个句子用来训练
"The cat, which already ate……,was full"
"The cats, which already ate……,were full"
逗号表示由很多个单词。
我们需要学习当出现cat的时候需要使用was,当出现cats的时候需要使用were。由于梯度消失的问题,理论上循环神经网络是无法学习这种具有长时间依赖关系的词性变化。由此引入了LSTM(长短时记忆网络)。
LSTM的整体结构和RNN很像都是循环递归的,只是将RNN-cell替换成LSTM-cell。LSTM-cell的表示如下

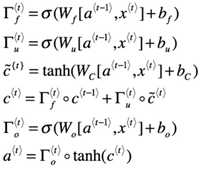
:Forget gate(忘记门),在这个例子中让我们假设每次的输入都是一个单词,我们希望LSTM保持语法结构,例如主语是单数还是复数。如果主语从单数变为复数,我们需要找到一种方法来避免之前存储的关于单数和复数的状态。在LSTM中,Forget gate让我们做这件事情。
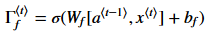
上面式子的计算结果在0到1之间。Forget gate向量会和之前cell的状态相乘,如果值为0(或者接近0)那么它意味着LSTM应该移除之前的状态信息(例如,主语是单数),如果是1,那么应该保持该信息。
:Update gate(更新门),一旦我们忘记了主语是单数,我们需要一种方式来说更新它来反应新的主语是复数。下面是更新门的表达式:
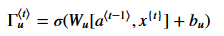
更新门会和相乘,来计算
为了计算新的主语,我们需要创建一个新的向量可以用来增加先前的cell状态。表达式如下:
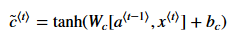
最后信息的cell状态如下:
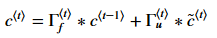
:Outputs gate(输出门),用来控制输出结果

将每一个LSTM-cell连接起来就构成了LSTM的前向传播了
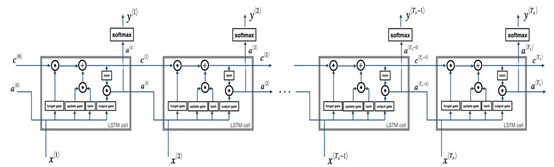
在tensorflow中根据该网络结构就可以构造出前向传播的算法,进行计算了。下面会给出LSTM的代码。
如果不用tensorflow进行计算,这里简单的给出LSTM的反向传播公式:
gate derivatives
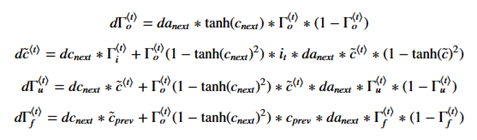
Parameter derivatives
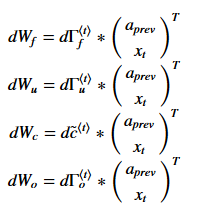
previous hidden state, previous memory state, and input
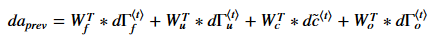
#导入相应的包 from __future__ import print_function import os import numpy as np import random import string import tensorflow as tf import zipfile from six.moves import range from six.moves.urllib.request import urlretrieve #读取莎士比亚的文本文件 path = "./shakespeare" #文件夹目录 files= os.listdir(path) #得到文件夹下的所有文件名称 text ="" for file in files: #遍历文件夹 if not os.path.isdir(file): #判断是否是文件夹,不是文件夹才打开 f = open(path+"/"+file,'r'); #打开文件 iter_f = iter(f); #创建迭代器 str = "" for line in iter_f: #遍历文件,一行行遍历,读取文本 str = str + line text+=str #每个文件的文本存到list中 print('Data size %d' % len(text)) #将莎士比亚文本中出现的所有字符做成字典并编号 vocab = set(text) vocab_to_int = {c: i for i, c in enumerate(vocab)} int_to_vocab = dict(enumerate(vocab)) #构造测试集和训练集 valid_size = 1000 valid_text = text[:valid_size] train_text = text[valid_size:] train_size = len(train_text) print(train_size, train_text[:64]) print(valid_size, valid_text[:64]) vocabulary_size =len(set(text)) batch_size = 64 num_unrollings = 10 #训练用的Batch生成器 class BatchGenerator(object): def __init__(self, text, batch_size, num_unrollings): self._text = text self._text_size = len(text) self._batch_size = batch_size self._num_unrollings = num_unrollings segment = self._text_size // batch_size self._cursor = [offset * segment for offset in range(batch_size)] self._last_batch = self._next_batch() def _next_batch(self): """Generate a single batch from the current cursor position in the data.""" batch = np.zeros(shape=(self._batch_size, vocabulary_size), dtype=np.float) for b in range(self._batch_size): #batch[b, char2id(self._text[self._cursor[b]])] = 1.0 batch[b, vocab_to_int[self._text[self._cursor[b]]]] = 1.0 self._cursor[b] = (self._cursor[b] + 1) % self._text_size return batch def next(self): """Generate the next array of batches from the data. The array consists of the last batch of the previous array, followed by num_unrollings new ones. """ batches = [self._last_batch] for step in range(self._num_unrollings): batches.append(self._next_batch()) self._last_batch = batches[-1] return batches #将概率分布转化为1-hot形式 def characters(probabilities): """Turn a 1-hot encoding or a probability distribution over the possible characters back into its (most likely) character representation.""" #return [id2char(c) for c in np.argmax(probabilities, 1)] temp=np.argmax(probabilities,1) return [int_to_vocab[c] for c in np.argmax(probabilities, 1)] #将batches转化成字符串 def batches2string(batches): """Convert a sequence of batches back into their (most likely) string representation.""" s = [''] * batches[0].shape[0] for b in batches: s = [''.join(x) for x in zip(s, characters(b))] return s train_batches = BatchGenerator(train_text, batch_size, num_unrollings) valid_batches = BatchGenerator(valid_text, 1, 1) print(batches2string(train_batches.next())) print(batches2string(train_batches.next())) print(batches2string(valid_batches.next())) print(batches2string(valid_batches.next())) def logprob(predictions, labels): """Log-probability of the true labels in a predicted batch.""" predictions[predictions < 1e-10] = 1e-10 return np.sum(np.multiply(labels, -np.log(predictions))) / labels.shape[0] #采样相关的函数,用于字符的生成 def sample_distribution(distribution): """Sample one element from a distribution assumed to be an array of normalized probabilities. """ r = random.uniform(0, 1) s = 0 for i in range(len(distribution)): s += distribution[i] if s >= r: return i return len(distribution) - 1 def sample(prediction): """Turn a (column) prediction into 1-hot encoded samples.""" p = np.zeros(shape=[1, vocabulary_size], dtype=np.float) p[0, sample_distribution(prediction[0])] = 1.0 return p def random_distribution(): """Generate a random column of probabilities.""" b = np.random.uniform(0.0, 1.0, size=[1, vocabulary_size]) tmp=np.sum(b,1) tmp1=np.sum(b,1)[:None] return b/np.sum(b, 1)[:,None] num_nodes = 64 #构造LSTM graph = tf.Graph() with graph.as_default(): # Parameters: # Input gate: input, previous output, and bias. ix = tf.Variable(tf.truncated_normal([vocabulary_size, num_nodes], -0.1, 0.1)) im = tf.Variable(tf.truncated_normal([num_nodes, num_nodes], -0.1, 0.1)) ib = tf.Variable(tf.zeros([1, num_nodes])) # Forget gate: input, previous output, and bias. fx = tf.Variable(tf.truncated_normal([vocabulary_size, num_nodes], -0.1, 0.1)) fm = tf.Variable(tf.truncated_normal([num_nodes, num_nodes], -0.1, 0.1)) fb = tf.Variable(tf.zeros([1, num_nodes])) # Memory cell: input, state and bias. cx = tf.Variable(tf.truncated_normal([vocabulary_size, num_nodes], -0.1, 0.1)) cm = tf.Variable(tf.truncated_normal([num_nodes, num_nodes], -0.1, 0.1)) cb = tf.Variable(tf.zeros([1, num_nodes])) # Output gate: input, previous output, and bias. ox = tf.Variable(tf.truncated_normal([vocabulary_size, num_nodes], -0.1, 0.1)) om = tf.Variable(tf.truncated_normal([num_nodes, num_nodes], -0.1, 0.1)) ob = tf.Variable(tf.zeros([1, num_nodes])) # Variables saving state across unrollings. saved_output = tf.Variable(tf.zeros([batch_size, num_nodes]), trainable=False) saved_state = tf.Variable(tf.zeros([batch_size, num_nodes]), trainable=False) # Classifier weights and biases. w = tf.Variable(tf.truncated_normal([num_nodes, vocabulary_size], -0.1, 0.1)) b = tf.Variable(tf.zeros([vocabulary_size])) # Definition of the cell computation. def lstm_cell(i, o, state): """Create a LSTM cell. See e.g.: http://arxiv.org/pdf/1402.1128v1.pdf Note that in this formulation, we omit the various connections between the previous state and the gates.""" input_gate = tf.sigmoid(tf.matmul(i, ix) + tf.matmul(o, im) + ib) forget_gate = tf.sigmoid(tf.matmul(i, fx) + tf.matmul(o, fm) + fb) update = tf.matmul(i, cx) + tf.matmul(o, cm) + cb state = forget_gate * state + input_gate * tf.tanh(update) output_gate = tf.sigmoid(tf.matmul(i, ox) + tf.matmul(o, om) + ob) return output_gate * tf.tanh(state), state # Input data. train_data = list() for _ in range(num_unrollings + 1): train_data.append( tf.placeholder(tf.float32, shape=[batch_size, vocabulary_size])) train_inputs = train_data[:num_unrollings] train_labels = train_data[1:] # labels are inputs shifted by one time step. # Unrolled LSTM loop. outputs = list() output = saved_output state = saved_state for i in train_inputs: output, state = lstm_cell(i, output, state) outputs.append(output) # State saving across unrollings. with tf.control_dependencies([saved_output.assign(output), saved_state.assign(state)]): # Classifier. # The Classifier will only run after saved_output and saved_state were assigned. logits = tf.nn.xw_plus_b(tf.concat(outputs, 0), w, b) loss = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits( logits=logits, labels=tf.concat(train_labels, 0))) # Optimizer. global_step = tf.Variable(0) learning_rate = tf.train.exponential_decay( 10.0, global_step, 5000, 0.1, staircase=True) optimizer = tf.train.GradientDescentOptimizer(learning_rate) gradients, v = zip(*optimizer.compute_gradients(loss)) gradients, _ = tf.clip_by_global_norm(gradients, 1.25) optimizer = optimizer.apply_gradients( zip(gradients, v), global_step=global_step) # Predictions. train_prediction = tf.nn.softmax(logits) # Sampling and validation eval: batch 1, no unrolling. sample_input = tf.placeholder(tf.float32, shape=[1, vocabulary_size]) saved_sample_output = tf.Variable(tf.zeros([1, num_nodes])) saved_sample_state = tf.Variable(tf.zeros([1, num_nodes])) reset_sample_state = tf.group( saved_sample_output.assign(tf.zeros([1, num_nodes])), saved_sample_state.assign(tf.zeros([1, num_nodes]))) sample_output, sample_state = lstm_cell( sample_input, saved_sample_output, saved_sample_state) with tf.control_dependencies([saved_sample_output.assign(sample_output), saved_sample_state.assign(sample_state)]): sample_prediction = tf.nn.softmax(tf.nn.xw_plus_b(sample_output, w, b)) saver = tf.train.Saver() num_steps = 37001 summary_frequency = 100 #saver = tf.train.Saver(var_list=[ib]) with tf.Session(graph=graph) as session: tf.global_variables_initializer().run() print('Initialized') mean_loss = 0 for step in range(num_steps): batches = train_batches.next() feed_dict = dict() # Add training data from batches to corresponding train_data position in the feed_dict for i in range(num_unrollings + 1): feed_dict[train_data[i]] = batches[i] # Train the model _, l, predictions, lr = session.run( [optimizer, loss, train_prediction, learning_rate], feed_dict=feed_dict) mean_loss += l if step % summary_frequency == 0: if step > 0: mean_loss = mean_loss / summary_frequency # The mean loss is an estimate of the loss over the last few batches. print( 'Average loss at step %d: %f learning rate: %f' % (step, mean_loss, lr)) mean_loss = 0 labels = np.concatenate(list(batches)[1:]) print('Minibatch perplexity: %.2f' % float( np.exp(logprob(predictions, labels)))) if step % (summary_frequency * 10) == 0: # Generate some samples. print('=' * 80) for _ in range(5): feed = sample(random_distribution()) tmp=characters(feed) sentence = characters(feed)[0] reset_sample_state.run() for _ in range(1379): prediction = sample_prediction.eval({sample_input: feed}) feed = sample(prediction) #feed = np.zeros(shape=[1, vocabulary_size], dtype=np.float) #feed[0, vocab_to_int[characters(prediction)[0]]] = 1.0 sentence += characters(prediction)[0] print(sentence) # Measure validation set perplexity. reset_sample_state.run() valid_logprob = 0 for _ in range(valid_size): b = valid_batches.next() predictions = sample_prediction.eval({sample_input: b[0]}) valid_logprob = valid_logprob + logprob(predictions, b[1]) print('Validation set perplexity: %.2f' % float(np.exp( valid_logprob / valid_size)))
实验结果:
在阿里云中的服务器中跑1h的结果为
Iivind to sh te no sh bnt if tete t segsunsed mrovd of teauty sormw And ttmdi n,
Aut teatme
Tr whene tn toer tone tf tftwaas srmtoundsng miser and to e stnce whrks anl the r sfer s aar thoarered
Tnd tore toaet oned
Th thol'nte miye thle theu h the seert
And stael soar,
Then trewgd then sirt thauld ttyle oegg, trwroun hhe weaath
Ahve tou sere nles thet ts teailesTour noy th mtye Autt ther ihere ore tavh trr h st tavh tyes
And tese,tove a dot su g,sart,
可以看出来它已经学会了部分单词,以及分段了
在阿里云中的服务器中跑3h的结果为:
L
Thosethet tn the sime tirte orove , Ao tolb tn the srlt shen t antrtn,
wo myst n st
Aut tune eye ds tocjenedtitl be tot ing mh trne
7
To ivesi soi teat uent temieeksand tvteem,oolrh oeintitn the sear frel d snd mfe
Tided itml r tnpge taovang snuie tor trrg r ios morld ty Ay ledd, o sii e thi ift tfrerlewe aow that toar f beathed wea
Tnd tincle silh tuape the saerher of atne tor mhes ht
Thet teve sn tour siic m'hle teseishne tn ty hlay ahat tldyn t coture tor my sene,
它已经初步知道可以给段落打标签了,如上面出现的7
[Tā yǐjīng chūbù zhīdào kěyǐ gěi duànluò dǎ biāoqiānle, rú shàngmiàn chūxiàn de]
It has initially known that it can label paragraphs, as shown above.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号