
Android音频压缩方法
Android音频压缩的方法
音频基础知识
采样和采样频率:
一秒钟内采样的次数称为采样频率。采样频率越高,越接近原始信号,但是也加大了运算处理的复杂度。根据Nyquist采样定理,要想重建原始信号,采样频率必须大于信号中最高频率的两倍。人能感受到的频率范围为20HZ--20kHZ, 一般音乐的采样频率为44.1kHZ, 更高的可以是48kHZ和96kHZ,不过一般人用耳听感觉不出差别了。语音主要是以沟通为主,不需要像音乐那样清晰,用16k采样的语音就称为高清语音了。现在主流的语音采样频率为16kHz。
采样位数:
数字信号是用0和1来表示的。采样位数就是采样值用多少位0和1来表示,也叫采样精度,用的位数越多就越接近真实声音。如用8位表示,采样值取值范围就是-128--127,如用16位表示,采样值取值范围就是-32768--32767。现在一般都用16位采样位数。
声道:
声道是指处理的声音是单声道还是立体声。Android支持双声道立体声和单声道。CHANNEL_IN_MONO单声道,CHANNEL_IN_STEREO立体声。单声道在声音处理过程中只有单数据流,而立体声则需要左、右声道的两个数据流。显然,立体声的效果要好,但相应的数据量要比单声道的数据量加倍。
码率:
就是比特率。比特率是指每秒传送的比特(bit)数。码率=采样率X采样位数X声道数。
音频采集和播放:
一般用专门的芯片(通常叫codec芯片)采集音频,做AD转换,然后把数字信号通过I2S总线(主流用I2S总线,也可以用其他总线,比如PCM总线)送给CPU处理(也有的会把codec芯片与CPU芯片集成在一块芯片中)。当要播放时CPU会把音频数字信号通过I2S总线送给codec芯片,然后做DA转换得到模拟信号再播放出来。
音频编码过程

时域转频域变化
时域是描述数学函数或物理信号对时间的关系。
在研究时域的信号时,常会用示波器将信号转换为其时域的波形
频域是指在对函数或信号进行分析时,分析其和频率有关部份,而不是和时间有关的部份
有兴趣的可以去了解一下傅里叶变换
心理声学原理
心理声学原理是指用功能强大的算法将我们听不到的音频信息去掉。
20hz-20000hz之间的,才是人能听到的。之外的可以称为冗余数据。
冗余数据还有被遮蔽掉的数据,分为频域遮蔽和时域遮蔽。
量化编码
通常也把音频采样过程叫脉冲编码调制编码,即PCM(Pulse Code Modulation)编码,采样值也叫PCM值。
PCM通过抽样、量化、编码三个步骤将连续变化的模拟信号转换为数字编码。
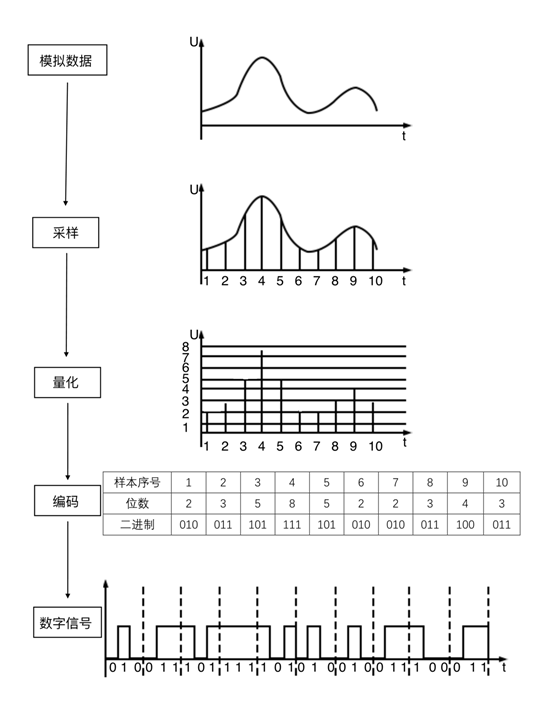
如图,我们首先对一段音频片段进行10次抽样。
每次采样,都存在不同的振幅。为了实现以数字码表示样值,必须采用"四舍五入"的方法把样值分级"取整",使一定取值范围内的样值由无限多个值变为有限个值。这一过程称为量化。
然后我们将不同的样值进行编码,将十进制的值转化为计算机认识的二进制的值。
最后根据二进制的值,我们转化为数字信号。就是所形成的方波。
音频压缩
音频压缩类型
1.有损压缩,就是消除冗余数据。音频采集过程中采集到各种各样的声音,只有一部分是人能识别出来的。其他的声音,我们直接删除掉。恢复回来的时候没有了,所以称为有损压缩。
2.哈夫曼无损压缩,利用数据的统计冗余进行压缩,可完全恢复原始数据而不引起任何数据丢失的,称为无损压缩。
使用音频压缩技术的原因
要计算一个PCM音频流的码率是一件很轻松的事情,采样率值×采样大小值×声道数。一个采样率为44.1KHz,采样大小为16bit,双声道的PCM编码的音频文件,它的码率则为 44.1K×16×2 =1411.2 Kbps。注意这边的单位是小b,单位是位。如果我们将单位转换为字节,则需要将码率除以8,就可以得到这个WAV的数据速率,即176.4KB/s。这表示存储一秒钟采样率为44.1KHz,采样大小为16bit,双声道的PCM编码的音频信号,需要176.4KB的空间,1分钟则约为10.34M,这对大部分用户是不可接受的,尤其是喜欢在电脑上听音乐的朋友,要降低磁盘占用,只有2种方法,降低采样指标或者压缩。降低指标是不可取的,因此专家们研发了各种压缩方案。
MP3发展已经有10个年头了,MP3作为前几年最为普及的音频压缩格式,他是MPEG(MPEG:Moving Picture Experts Group) Audio Layer-3的简称,是MPEG1的衍生编码方案,1993年由德国Fraunhofer IIS研究院和汤姆生公司合作发展成功。MP3可以做到12:1的惊人压缩比并保持基本可听的音质,在当年硬盘天价的日子里,MP3迅速被用户接受,为大家所大量接受。
见音频的压缩编码
目前主要有三大技术标准组织制定压缩标准:
a)ITU,主要制定有线语音的压缩标准(g系列),有g711/g722/g726/g729等。
b)3GPP,主要制定无线语音的压缩标准(amr系列等), 有amr-nb/amr-wb。后来ITU吸纳了amr-wb,形成了g722.2。
c)MPEG,主要制定音乐的压缩标准,有11172-3,13818-3/7,14496-3等。
一些大公司或者组织也制定压缩标准,比如iLBC,OPUS。
目前市场编解码器性能比较OPUS > Vorbis > AAC ,其他的已经随时间慢慢退出市场了
编码格式
PCM编码
PCM是Pulse Code Modulation的缩写。上一篇我们提到了PCM大致的工作流程,我们现在不需要关心PCM最终编码采用的是什么计算方式,我们只需要知道PCM编码的音频流的优点和缺点就可以了。PCM编码的最大的优点就是音质好,最大的缺点就是体积大。
PCM被约定俗成为无损编码,是相对于mp3,aac编码的。相对自然界的信号,音频编码最多只能做到无限接近(至少目前的技术只能这样),任何数字音频编码方案都是有损的,因为无法完全还原。在计算机应用中,能够达到最高保真水平的就是PCM编码,被广泛用于素材保存及音乐欣赏,CD、DVD以及我们常见的WAV文件中均有应用。PCM代表了数字音频中最佳的保真水准,但是并不意味着PCM就能够确保信号绝对保真,PCM也只能做到最大程度的无限接近。
Opus编码
Opus是一个有损声音编码的格式,Opus的前身是celt编码器。是由IETF开发,适用于网络上的实时声音传输,标准格式为RFC6716。使用上没有任何专利或限制。
在当今的有损音频格式争夺上,拥有众多不同编码器的AAC格式打败了同样颇有潜力的Musepack、Vorbis等格式,而在Opus格式诞生后,情况似乎不同了。通过诸多的对比测试,低码率下Opus完胜曾经优势明显的HE AAC,中码率就已经可以媲敌码率高出30%左右的AAC格式,而高码率下更接近原始音频。
简单来说,opus是一个高保真的适合在网络中传输的开源的语音编码格式,相对于其他编码格式来讲,保真性更好,但体积会稍微大一些。
Opus官网地址:http://www.opus-codec.org/
OGG编码
OGG全称是OGG Vorbis,是一种新的音频压缩格式。OGG是一个庞大的多媒体开发计划的项目名称,将涉及视频音频等方面的编码开发。整个OGG项目计划的目的就是向任何人提供完全免费多媒体编码方案!OGG的信念就是:OPEN!FREE!Vorbis这个词汇是特里·普拉特柴特的幻想小说《Small Gods》中的一个"花花公子"人物名。这个词汇成为了OGG项目中音频编码的正式命名。目前Vorbis已经开发成功,并且开发出了编码器。
和MP3一样,Ogg Vorbis是一种灵活开放的音频编码,能够在编码方案已经固定下来后还能对音质进行明显的调节和新算法的改良。因此,它的声音质量将会越来越好,和MP3相似,Ogg Vorbis更像一个音频编码框架,可以不断导入新技术逐步完善。和MP3一样,OGG也支持VBR。
AAC编码
AAC,全称Advanced Audio Coding,是一种专为声音数据设计的文件压缩格式。与MP3不同,它采用了全新的算法进行编码,更加高效,具有更高的"性价比"。利用AAC格式,可使人感觉声音质量没有明显降低的前提下,更加小巧。
AAC本身编解码器质量非常高。作为一种高压缩比的音频压缩算法,AAC通常压缩比为18:1 (也有资料说为20:1),但是还能保存较好的音质。1分钟录制的音频文件只有101KB的大小,想比较pcm数据,的确被压缩很多。
Android中使用Speex
Speex介绍
- Speex编解码器(http://www.speex.org/)的存在是因为需要一款开源且免软件专利使用费的语音编解码器,这是任何开源软件可用的必要条件。本质上来说,Speex相对于语音正如Vorbis(注:免费音乐格式)相对于音频/音乐。不像许多其他语音编解码器,Speex不是为移动电话而设计,而是为分封网络(packet network)和网络电话(VoIP)而设计的。所以当然支持基于文件的压缩。
- Speex设计灵活,支持多种不同的语音质量和比特率。对高质量语音的支持也就意味着Speex不仅能编码窄带语音(电话语音质量,8kHz采样率),也能编码宽带语音(16kHz采样率)。
- 为VoIP而不是移动电话而设计意味着Speex对丢失的数据包鲁棒,但对损坏的数据包不鲁棒。这基于在VoIP中数据包要么完整到达要么不能到达这一假设的。因为Speex针对于多种设备,所以它复杂性适度(可调节)并且占用较少内存。
- 考虑这些设计目标,我们选用CELP作为编码技术。其中一个主要原因是CELP很早就被证明在低比特率(如4.8kbps的DoD CELP)和高比特率(如16kbps的G.728)都能稳定可靠工作。
Speex编码流程
1、定义一个SpeexBits类型变量bits和一个Speex编码器状态变量enc_state。
2、调用speex_bits_init(&bits)初始化bits。
3、调用speex_encoder_init(&speex_nb_mode)来初始化enc_state。其中speex_nb_mode是SpeexMode类型的变量,表示的是窄带模式。还有speex_wb_mode表示宽带模式、speex_uwb_mode表示超宽带模式。
4、调用函数int speex_encoder_ ctl(void *state, int request, void *ptr)来设定编码器的参数,其中参数state表示编码器的状态;参数request表示要定义的参数类型,如SPEEX_ GET_ FRAME_SIZE表示设置帧大小,SPEEX_ SET_QUALITY表示量化大小,这决定了编码的质量;参数ptr表示要设定的值。可通过speex_encoder_ctl(enc_state, SPEEX_GET_FRAME_SIZE, &frame_size) 和speex_encoder_ctl(enc_state, SPEEX_SET_QUALITY, &quality)来设定编码器的参数。
5、初始化完毕后,对每一帧声音作如下处理:调用函数speex_bits_reset(&bits)再次设定SpeexBits,然后调用函数speex_encode(enc_state, input_frame, &bits),参数bits中保存编码后的数据流。
6、编码结束后,调用函数speex_bits_destroy (&bits)
Speex解码流程
1、 定义一个SpeexBits类型变量bits和一个Speex编码状态变量enc_state。
2、 调用speex_bits_init(&bits)初始化bits。
3、 调用speex_decoder_init (&speex_nb_mode)来初始化enc_state。
4、 调用函数speex_decoder_ctl (void *state, int request, void *ptr)来设定编码器的参数。
5、 调用函数 speex_decode(void *state, SpeexBits *bits, float *out)对参数bits中的音频数据进行解编码,参数out中保存解码后的数据流。
6、 调用函数speex_bits_destroy(&bits), speex_ decoder_ destroy (void *state)来关闭和销毁SpeexBits和解码器。
工程介绍
JNI封装了如下native方法可供使用:
public native int open(int compression);
public native int getFrameSize();
public native int decode(byte encoded[], short lin[], int size);
public native int encode(short lin[], int offset, byte encoded[], int size);
public native void close();
SpeexRecorder.java:用于将麦克风音频编码成speex格式并保存;
SpeexPlayer.java:用于播放speex编码格式的音频文件;
SpeexDecoder.java:用于解码speex编码格式的音频文件;
SpeexEncoder.java:将音频编码成speex格式。
参考文献
https://www.jianshu.com/p/916813e847d3

