
Lucene及全文搜索实现原理
Lucene及全文搜索实现原理
全文搜索
全文搜索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文搜索搜索引擎数据库中的数据。
全文搜索的过程主要分为两个部分,索引的建立以及索引的搜索。
国内外的全文搜索常用的检索模型主要有向量模型,布尔模型等。
布尔模型
布尔模型是第一个信息检索的模型,可能也是最受争论的模型。它利用布尔运算符连接各个检索词,然后由计算机进行逻辑运算,找出所需信息的一种检索方法。布尔定义了三种基本操作:AND,OR和NOT。
概率检索模型
多是建立在相关性理论基础上,基于对相关性的不同理解而建立了不同的概率检索模型,而且由此导出不同的排序输出原则。可以说相关性原理及排序原理是概率检索模型的理论核心。
向量模型
向量空间模型(Vector Space Model,VSM)在上世纪70年代由信息检索领域奠基人Salton教授提出来,并成功地应用于著名的SMART文本检索系统。把对文本内容的处理简化为向量空间中的向量运算,它以空间上的相似度表达语义的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性。向量空间模型的数学模型基础是余弦相似性理论,下面先从数学推导上认识余弦相似性理论。
在同一个N维空间中存在两个非零向量A和B:
向量A记作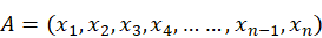
向量B记作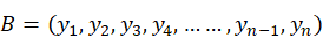
向量A和B的夹角为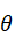 ,那么由夹角公式可得:
,那么由夹角公式可得:

夹角余弦值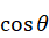 是与向量的长度无关的,仅仅与向量的指向方向相关。当向量A和B向量方向完全相同时,那么两个向量之间的夹角为0,
是与向量的长度无关的,仅仅与向量的指向方向相关。当向量A和B向量方向完全相同时,那么两个向量之间的夹角为0,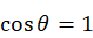 ;当A向量和B向量方向完全相反时,那么两个向量之间的夹角为180度,
;当A向量和B向量方向完全相反时,那么两个向量之间的夹角为180度,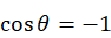 ;当A向量和B向量互相垂直时,即夹角为90度,
;当A向量和B向量互相垂直时,即夹角为90度,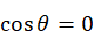 。0度角的余弦值是1,而其他任何角度的余弦值都不大于1,并且其最小值是-1,从而通过两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。用向量夹角余弦值来衡量相似度:
。0度角的余弦值是1,而其他任何角度的余弦值都不大于1,并且其最小值是-1,从而通过两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。用向量夹角余弦值来衡量相似度: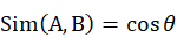
余弦相似度通常用于正空间,因此给出的值为0到1之间。如下图所示,假设两个文档doc1和doc2,doc1和doc2在向量空间中分别用向量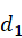 和向量
和向量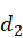 来表示。
来表示。
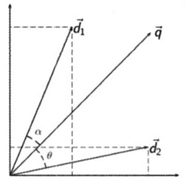
关键词查询向量为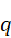 ,
,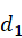 和
和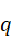 的夹角为
的夹角为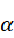 ,
,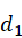 和
和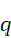 的夹角为
的夹角为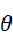 。通过计算
。通过计算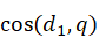 得出查询向量和doc1之间的相似性:
得出查询向量和doc1之间的相似性:
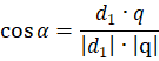
计算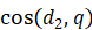 得出查询向量和doc2之间的相似性:
得出查询向量和doc2之间的相似性:
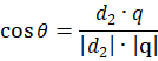
比较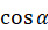 和
和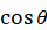 的大小可以得出文档1和文档哪个和查询关键词相关度更大。
的大小可以得出文档1和文档哪个和查询关键词相关度更大。
Lucene
Lucene的评分公式
向量空间模型是信息检索领域中一种成熟和基础的检索模型。这种方法以3维空间中的向量作为类比,维度就是做好索引的term,比如这里以3个主要的关键词百度、招聘、java为三个维度,通过文档在各个维度上的权重,每个文档以及查询都会在空间中有一个向量,直观的看起来,两个向量越相似,则他们的夹角越小,所以cos值越大,则两个向量越相似,同理便可以将3维空间推广到多维空间去。
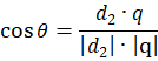
用向量空间模型,便将相关性转化为相似性,根据点积和模的定义,可以得到下式:
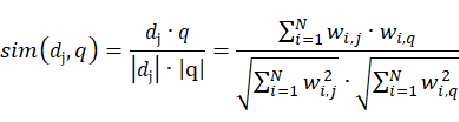
现在的问题就变成,如何求得每个维度上的term在文档中的权重,在向量空间模型中,特征权重的计算框架是TF*IDF框架,这里TF(Term Frequency)就是term在文档中的词频,TF值越大,说明该篇文档相对于这个term来说更加重要,因此权重应该更高;而IDF(Inverse Document Frequency)则是term在整个文档集中占的比重。IDF的主要思想是,如果包含词条t的文档越少,IDF越大,则说明词条t具有很好的类别区分能力。

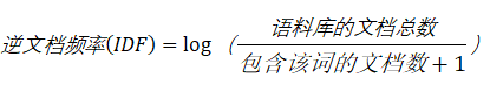
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0。
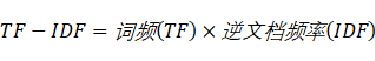
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。
有了以上基础之后可以对Lucene的公式进行简单的推导
-
令查询向量
![]() ,文档向量
,文档向量![]()
-
![]() ,
,![]()
-
由于用户在输入查询串时,一般不会输入相同的查询词,因此简单设置
![]()
![]() ,
, ![]()
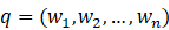 ,文档向量
,文档向量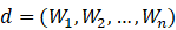
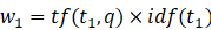
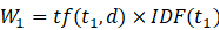
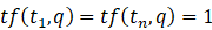
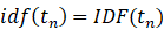
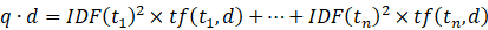
需要注意的是只有当词都存在于q和d中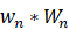 才不为0。
才不为0。
-
查询向量长度
![]() ,可能大家会认为由于评分时需要比较的是查询向量余文档向量的相似度,查询向量的长度对于所有文档的相似度而言是相同的,因此实际中就可以舍去,但实际并没有舍去;
,可能大家会认为由于评分时需要比较的是查询向量余文档向量的相似度,查询向量的长度对于所有文档的相似度而言是相同的,因此实际中就可以舍去,但实际并没有舍去; -
对于文档向量长度,lucene并没有采用标准的公式即:
![]() ,而是设置成默认的开根号(词的个数)
,而是设置成默认的开根号(词的个数) -
文档得分
![]()
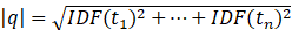 ,可能大家会认为由于评分时需要比较的是查询向量余文档向量的相似度,查询向量的长度对于所有文档的相似度而言是相同的,因此实际中就可以舍去,但实际并没有舍去;
,可能大家会认为由于评分时需要比较的是查询向量余文档向量的相似度,查询向量的长度对于所有文档的相似度而言是相同的,因此实际中就可以舍去,但实际并没有舍去; 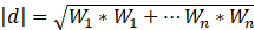 ,而是设置成默认的开根号(词的个数)
,而是设置成默认的开根号(词的个数) 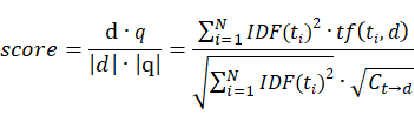
实际上当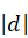 不是标准公式的时候,最终的得分也就不是两个向量的余弦了。这里不是lucene的最终公式,而是给出了大体的架子。
不是标准公式的时候,最终的得分也就不是两个向量的余弦了。这里不是lucene的最终公式,而是给出了大体的架子。
Lucene中的完整打分公式:
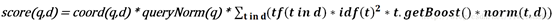
coord(q,d):协调因子,它的计算是基于文档d中所包含的所有可供查询的词条数量
queryNorm:在给出每个查询条目的方差和后,计算某查询的标准化值
tf:单词t在文档d中出现的词频
idf:单词t在文档集中的比重
t.getBoost():在搜索过程中影响评分的参数
norm(t,d):字段的标准化值
Lucene索引建立及索引搜索
非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,也即是从文件到字符串的映射。而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即从字符串到文件的映射。两者恰恰相反。于是如果索引总能够保存从字符串到文件的映射,则会大大提高搜索速度。
由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引 。
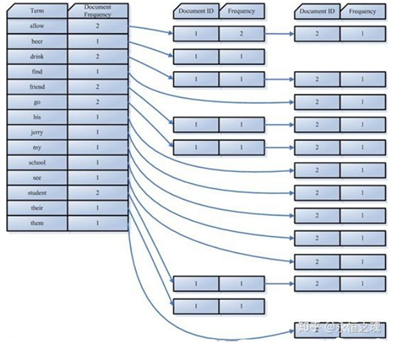
反向索引的所保存的信息一般如下:
假设我的文档集合里面有100篇文档,为了方便表示,我们为文档编号从1到100,得到下面的结构

左边保存的是一系列字符串,称为词典。每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表 (Posting List)。有了索引,便使保存的信息和要搜索的信息一致,可以大大加快搜索的速度。比如说,我们要寻找既包含字符串"lucene"又包含字符串"solr"的文档,我们只需要以下几步:
1. 取出包含字符串"lucene"的文档链表。
2. 取出包含字符串"solr"的文档链表。
3. 通过合并链表,找出既包含"lucene"又包含"solr"的文件。

看到这个地方,有人可能会说,全文检索的确加快了搜索的速度,但是多了索引的过程,两者加起来不一定比顺序扫描快多少。的确,加上索引的过程,全文检索不一定比顺序扫描快,尤其是在数据量小的时候更是如此。而对一个很大量的数据创建索引也是一个很慢的过程。然而两者还是有区别的,顺序扫描是每次都要扫描,而创建索引的过程仅仅需要一次,以后便是一劳永逸的了,每次搜索,创建索引的过程不必经过,仅仅搜索创建好的索引就可以了。这也是全文搜索相对于顺序扫描的优势之一:一次索引,多次使用。
索引结构如下
ElasticSearch
有了单机的Lucene知识基础,可以再深入了解一下分布式的ElasticSearch。Elasticsearch是一个基于Apache Lucene的分布式可扩展的实时搜索和分析引擎。
Elasticsearch在建立索引的时候,会将索引拆分成多个shard,每个 shard 存储部分数据。拆分多个 shard 是有好处的,一是支持横向扩展,二是提高性能。这个 shard 的数据实际是有多个备份,就是说每个 shard 都有一个 primary shard,负责写入数据,但是还有几个 replica shard。primary shard 写入数据之后,会将数据同步到其他几个 replica shard 上去。
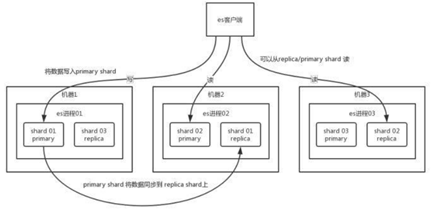
通过这个 replica 的方案,每个 shard 的数据都有多个备份,如果某个机器宕机了,没关系啊,还有别的数据副本在别的机器上呢。
es 集群多个节点,会自动选举一个节点为 master 节点,这个 master 节点其实就是干一些管理的工作的,比如维护索引元数据、负责切换 primary shard 和 replica shard 身份等。要是 master 节点宕机了,那么会重新选举一个节点为 master 节点。
如果是非 master节点宕机了,那么会由 master 节点,让那个宕机节点上的 primary shard 的身份转移到其他机器上的 replica shard。接着你要是修复了那个宕机机器,重启了之后,master 节点会控制将缺失的 replica shard 分配过去,同步后续修改的数据之类的,让集群恢复正常。
说得更简单一点,就是说如果某个非 master 节点宕机了。那么此节点上的 primary shard 不就没了。那好,master 会让 primary shard 对应的 replica shard(在其他机器上)切换为 primary shard。如果宕机的机器修复了,修复后的节点也不再是 primary shard,而是 replica shard。
es读取数据的过程
查询,GET某一条数据,写入了某个document,这个document会自动给你分配一个全局唯一的id,doc id,同时也是根据doc id进行hash路由到对应的primary shard上面去。也可以手动指定doc id,比如用订单id,用户id。
1)客户端发送请求到任意一个node,成为coordinate node
2)coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
3)接收请求的node返回document给coordinate node
4)coordinate node返回document给客户端
查询的时候根据某一id查询doc,这时候就是找一个协调节点,协调节点根据id路由找到shard然后返回数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号