哈夫曼树及哈夫曼编码
哈夫曼树及哈夫曼编码
哈夫曼树
给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
树节点间的边相关的数叫做权。
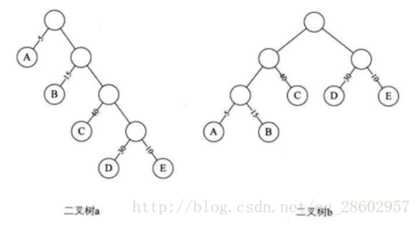
从树中的一个节点到另一个节点之间的分支构成两个点之间的路径,路径上的分支数目称作路径长度。
图中二叉树a中,跟节点到D的路径长度就是4,b中根节点到D的路径长度为2。
树的路径长度就是从树根到每一个节点的路径长度之和。二叉树a的路径长度就为1+1+2+2+3+3+4+4=20。二叉树b的树路径长度就为1+2+3+3+2+1+2+2=16。
如果考虑带权的节点,节点的带权的路径长度就是从该节点到树根之间的路径长度乘该节点的权。
数的带权路径长度就是所有叶子节点的带权路径长度之和。
带权路径长度(WPL)最小的二叉树称作哈夫曼树。
如何构造哈夫曼树
下面我们以【5、8、4、11、9、13】为例来画出哈夫曼树(数字大小代表权重大小,越大的权重越大)
第一步:按从小到大排序。
【5、8、4、11、9、13】→【4、5、8、9、11、13】
第二步:选最小两个数画出一个树,最小数为4和5。
给定的4、5、8、9、11、13为白色, 红色的9为4+5,与给定的白9无关,新序列为:【红9(含子节点4、5)、8、9、11、13】

取两个最小数8和9:

排序:
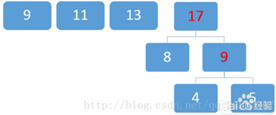
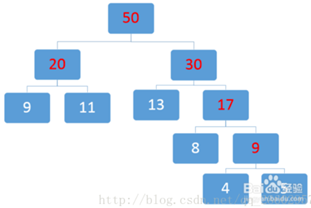
重复该过程直到最后的结果
哈夫曼编码
哈夫曼研究这种最优树的目的是为了解决当年远距离通信(主要是电报)的数据传输的最优化问题。
比如我们有一段文字"BADCADFEED",显然用二进制数字(0和1)表示是很自然的想法。

这样真正传输的数据就是"001000011010000011101100100011",对方接收时同样按照3位一组解码。如果一篇文章很长,这样的二进制串也非常的可怕。而且事实上,每个字母或者汉子的出现频率是不同的。
假设六个字母的频率为A 27,B 8, C 15, D 15 , E 30, F 5,合起来正好是100%,那就意味着我们完全可以用哈夫曼树来规划它们。
左图为构造哈夫曼树的过程的权值显示。右图为将权值左分支改为0,右分支改为1后的哈夫曼树。

我们对这六个字母用其从树根到叶子所经过的路径的0或1来编码,可以得到下表:


也就是说我们的数据被压缩了,节约了大概17%的存储或传输成本。随着字符的增加和多字符权重的不同,这种压缩会更显出优势来。
接收到哈夫曼编码后应如何解码
仔细观察上面的赫夫曼编码表中各个字母的编码会发现,不存在容易与1001、1000混淆的10、100等编码。这就说明若要设计长短不等的编码,则必须是任一字符的编码都不是另一个字符的编码的前缀,这种编码称作前缀编码。
可仅仅是这样不足以让我们去方便的解码,因此解码时,还是要用到哈夫曼树,即发送方和接收方必须约定好同样的哈夫曼编码规则。
下面是赫夫曼编码的定义:
一般的,设需要编码的字符集为{d1,d2,…,dn},各个字符在电文中出现的次数或频率集合为{w1,w2,…,wn},以d1,d2,…dn作为叶子结点,以w1,w2,…wn作为相应叶子结点的权值来构造一棵赫夫曼树。规定赫夫曼树的左分支代表0,右分支代表1,则从根节点到叶子节点所经过的路径分支组成的0和1的序列便为该结点对应字符的编码,这就是赫夫曼编码。
哈夫曼树的应用场景
其实赫夫曼树使用场景还真不少,例如apache负载均衡的按权重请求策略的底层算法、咱们生活中的路由器的路由算法、利用哈夫曼树实现汉字点阵字形的压缩存储、快速检索信息等等底层优化算法,其实核心就是因为目标带有权重,长度远近这类信息才能构建哈夫曼模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号