消息队列
消息队列
什么是消息队列?
消息队列是在消息的传输过程中保存消息的容器。这里的消息可以非常简单,例如只包含文本字符串;也可以更复杂,可能包含嵌入对象。消息被发送到队列中。
"消息队列"是在消息的传输过程中保存消息的容器。消息队列管理器在将消息从它的源中继到它的目标时充当中间人。队列的主要目的是提供路由并保证消息的传递。如果发送消息时接受者不可用,消息队列会保留消息,直到可以成功地传递它。
为什么要用消息队列?
解耦
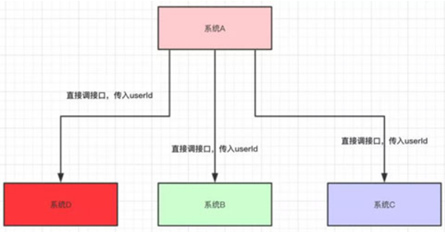
现在我有一个系统A,系统A可以产生一个userId
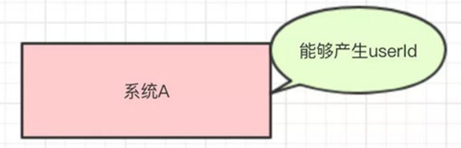
然后,现在有系统B和系统C都需要这个userId去做相关的操作
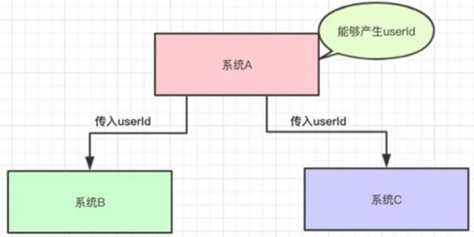
写成伪代码可能是这样的:

ok,一切平安无事度过了几个天。
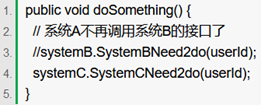
某一天,系统B的负责人告诉系统A的负责人,现在系统B的SystemBNeed2do(String userId)这个接口不再使用了,让系统A别去调它了。
于是,系统A的负责人说"好的,那我就不调用你了。",于是就把调用系统B接口的代码给删掉了:
又过了几天,系统D的负责人接了个需求,也需要用到系统A的userId,于是就跑去跟系统A的负责人说:"老哥,我要用到你的userId,你调一下我的接口吧"
于是系统A说:"没问题的,这就搞"
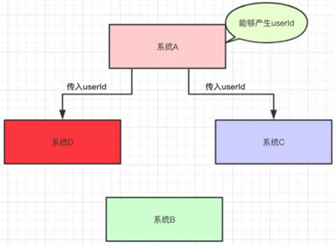
然后,系统A的代码如下:

时间飞逝:
- 又过了几天,系统E的负责人过来了,告诉系统A,需要userId。
- 又过了几天,系统B的负责人过来了,告诉系统A,还是重新掉那个接口吧。
- 又过了几天,系统F的负责人过来了,告诉系统A,需要userId。
- ……
于是系统A的负责人,每天都被这给骚扰着,改来改去,改来改去…….
还有另外一个问题,调用系统C的时候,如果系统C挂了,系统A还得想办法处理。如果调用系统D时,由于网络延迟,请求超时了,那系统A是反馈fail还是重试??
***,系统A的负责人,觉得隔一段时间就改来改去,没意思,于是就跑路了。
然后,公司招来一个大佬,大佬经过几天熟悉,上来就说:将系统A的userId写到消息队列中,这样系统A就不用经常改动了。为什么呢?下面我们来一起看看:

系统A将userId写到消息队列中,系统C和系统D从消息队列中拿数据。这样有什么好处?
- 系统A只负责把数据写到队列中,谁想要或不想要这个数据(消息),系统A一点都不关心。
- 即便现在系统D不想要userId这个数据了,系统B又突然想要userId这个数据了,都跟系统A无关,系统A一点代码都不用改。
- 系统D拿userId不再经过系统A,而是从消息队列里边拿。系统D即便挂了或者请求超时,都跟系统A无关,只跟消息队列有关。
这样一来,系统A与系统B、C、D都解耦了。
异步
我们再来看看下面这种情况:系统A还是直接调用系统B、C、D

假设系统A运算出userId具体的值需要50ms,调用系统B的接口需要300ms,调用系统C的接口需要300ms,调用系统D的接口需要300ms。那么这次请求就需要50+300+300+300=950ms
并且我们得知,系统A做的是主要的业务,而系统B、C、D是非主要的业务。比如系统A处理的是订单下单,而系统B是订单下单成功了,那发送一条短信告诉具体的用户此订单已成功,而系统C和系统D也是处理一些小事而已。
那么此时,为了提高用户体验和吞吐量,其实可以异步地调用系统B、C、D的接口。所以,我们可以弄成是这样的:

系统A执行完了以后,将userId写到消息队列中,然后就直接返回了(至于其他的操作,则异步处理)。
- 本来整个请求需要用950ms(同步)
- 现在将调用其他系统接口异步化,从请求到返回只需要100ms(异步)
(例子可能举得不太好,但我觉得说明到点子上就行了,见谅。)
削峰/限流
我们再来一个场景,现在我们每个月要搞一次大促,大促期间的并发可能会很高的,比如每秒3000个请求。假设我们现在有两台机器处理请求,并且每台机器只能每次处理1000个请求。
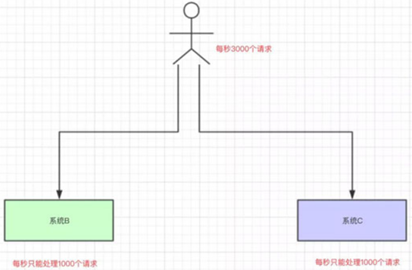
那多出来的1000个请求,可能就把我们整个系统给搞崩了…所以,有一种办法,我们可以写到消息队列中:
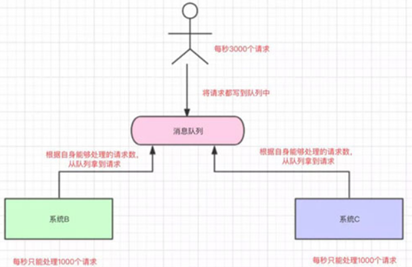
系统B和系统C根据自己的能够处理的请求数去消息队列中拿数据,这样即便有每秒有8000个请求,那只是把请求放在消息队列中,去拿消息队列的消息由系统自己去控制,这样就不会把整个系统给搞崩。
消息模式
PTP点对点
点对点模型用于消息生产者和消息消费者之间点到点的通信
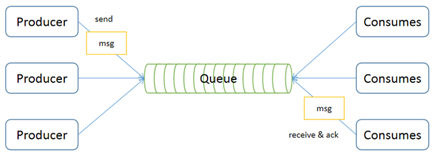
点对点模式包含三个角色:
-
消息队列(Queue)
-
发送者(Sender)
-
接收者(Receiver)
每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,可以放在内存中也可以持久化,直到他们被消费或超时。
特点:
-
每个消息只有一个消费者(Consumer)(即一旦被消费,消息就不再在消息队列中)
-
发送者和接收者之间在时间上没有依赖性
-
接收者在成功接收消息之后需要向队列应答成功
-
利用FIFO先进先出的特点,可以保证消息的顺序性
Pub/Sub发布订阅
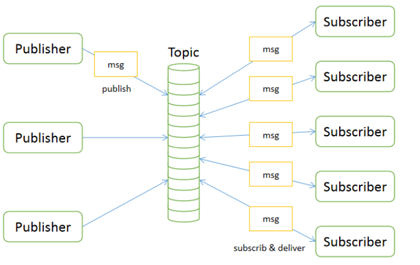
发布订阅模型包含三个角色:
-
主题(Topic)
-
发布者(Publisher)
-
订阅者(Subscriber)
多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者
特点:
-
每个消息可以有多个消费者:和点对点的方式不同,发布消息可以被所有订阅者消费。
-
发布者和订阅者之间有时间上的依赖性。
-
针对某个主体(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
-
为了消费信息,订阅者必须保持运行状态。
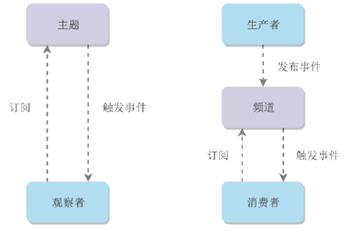
发布与订阅模式和观察者模式有以下不同:
观察者模式中,观察者和主体都知道对方的存在;而在发布与订阅模式中,生产者与消费者不知道对方的存在,它们之间通过频道进行通信。
观察者模式是同步的,当事件触发时,主题会调用观察者的方法,然后等待方法返回;而发布与订阅模式是异步的,生产者向频道发送一个消息之后,就不需要关心消费者何时去订阅这个消息,可以立即返回。
常用的消息队列产品
|
特性 |
ActiveMQ |
RabbitMQ |
RocketMQ |
kafka |
|
开发语言 |
erlang |
java |
java |
scala |
|
单机吞吐量 |
万级 |
万级 |
10万级 |
10万级 |
|
时效性 |
ms级 |
us级 |
ms级 |
ms级以内 |
|
可用性 |
高(主从架构) |
高(主从架构) |
非常高(分布式架构) |
非常高(分布式架构) |
|
功能特性 |
成熟的产品,在很多公司得到应用;有较多的文档;各种协议支持较好 |
基于erlang开发,所以并发能力很强,性能极其好,延时很低;管理界面较丰富 |
MQ功能比较完备,扩展性佳 |
只支持主要的MQ功能,像一些消息查询,消息回溯等功能没有提供,毕竟是为大数据准备的,在大数据领域应用广。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号