Java中的HashMap低层实现原理
Java中的HashMap低层实现原理
JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率。
当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩大2倍,把原链表数组的搬移到新的数组中
即HashMap的原理图是:
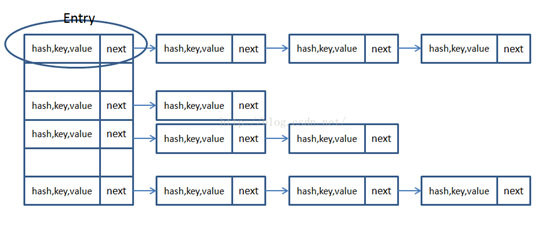
位桶数组
transient Node<k,v>[] table;//存储(位桶)的数组</k,v>
数组元素Node<K,V>实现了Entry接口
get(key)方法时获取key的hash值,计算hash&(n-1)得到在链表数组中的位置first=tab[hash&(n-1)],先判断first的key是否与参数key相等,不等就遍历后面的链表找到相同的key值返回对应的Value值即可
下面简单说下添加键值对put(key,value)的过程:
1,判断键值对数组tab[]是否为空或为null,否则以默认大小resize();
2,根据键值key计算hash值得到插入的数组索引i,如果tab[i]==null,直接新建节点添加,否则转入3
3,判断当前数组中处理hash冲突的方式为链表还是红黑树(check第一个节点类型即可),分别处理
HashMap处理"碰撞"增加了红黑树这种数据结构,当碰撞结点较少时,采用链表存储,当较大时(>8个),采用红黑树(特点是查询时间是O(logn))存储(有一个阀值控制,大于阀值(8个),将链表存储转换成红黑树存储)
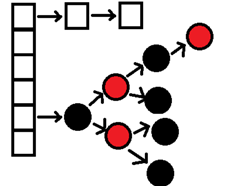
红黑树
红黑树(英语:Red–black tree)是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。它是在1972年由鲁道夫·贝尔发明的,他称之为"对称二叉B树",它现代的名字是在Leo J. Guibas和RobertSedgewick于1978年写的一篇论文中获得的。它是复杂的,但它的操作有着良好的最坏情况运行时间,并且在实践中是高效的:它可以在时间内做查找,插入和删除,这里的是树中元素的数目。
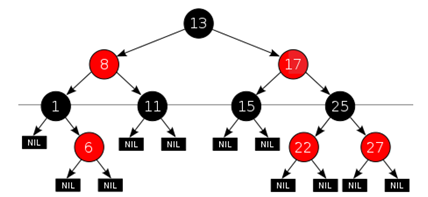
红黑树是每个节点都带有颜色属性的二叉查找树,颜色为红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
1. 节点是红色或黑色。
2. 根是黑色。
3. 所有叶子都是黑色(叶子是NIL节点)。
4. 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
5. 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
下面是一个具体的红黑树的图例:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号