
深度学习介绍
深度学习介绍
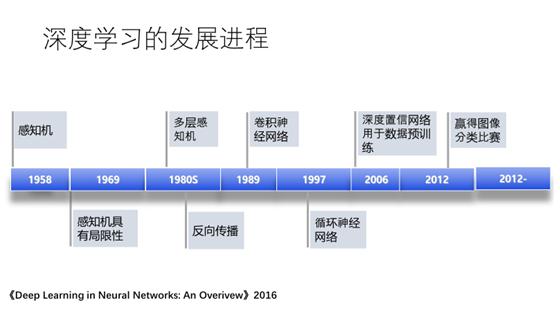
2006是深度置信网络用于数据集的预训练是深度学习爆发的前夕,
2012是深度学习开始真正的爆发
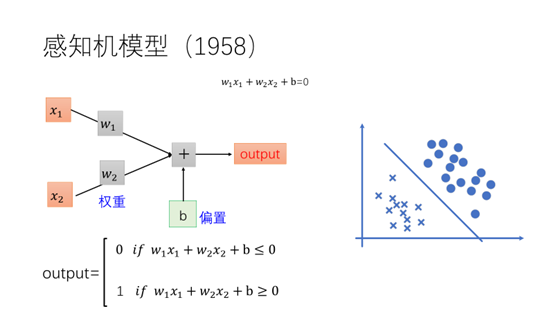
一个最简单的感知机可以理解成一条直线,具有两个权重w1,w2,一个偏置b。根据点在直线的上方或者下方进行分类为0或者1。
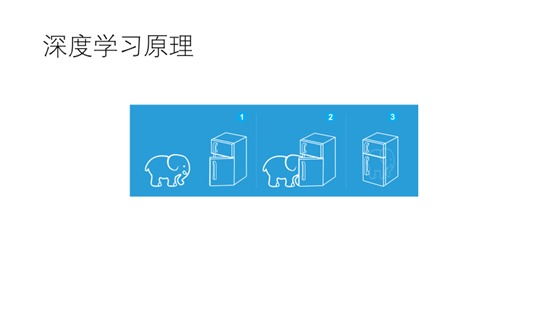
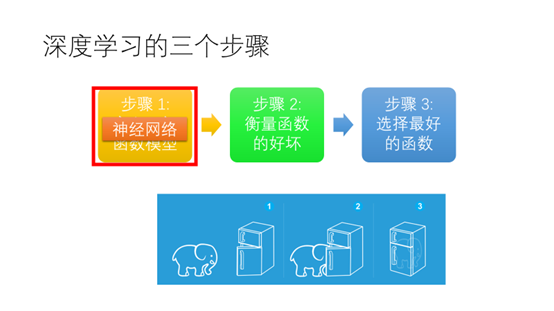
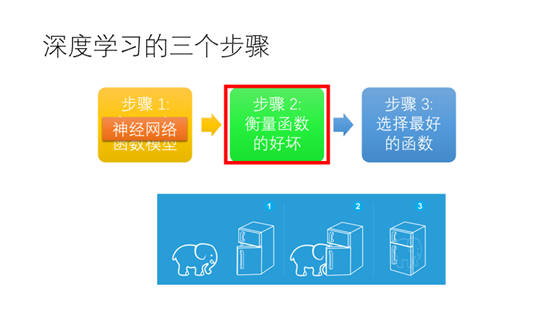
把一头大象装进冰箱需要三个步骤(1)打开冰箱的门(2)将大象塞进去(3)将冰箱的门关上
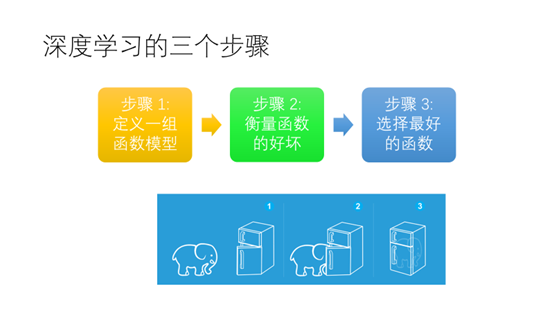
用深度学习做数据分析和把大象装进冰箱一样需要三个步骤(1)定义一组函数模型(2)衡量函数的好坏(3)选择最好的函数
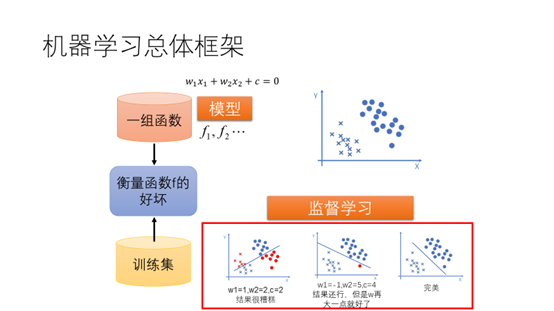
模型是抽象的,函数是具体的。比如马是抽象的,但是现实中的一只马是具体的。对于二维平面上的点进行分类,首先定义模型,这里采用刚才提到的具有两个输入的感知机模型,其实就是直线。由于模型中有两个参数w1,w2,对于每一个具体的w1,w2会会产生一个函数,因此一个具体的模型会有一组函数。可以通过训练集来衡量函数f的好坏。第一次的结果很糟糕,大部分的标签都分类错误了,因此需要重新调整参数w1,w2和c以使它符合训练集的标准。调整完之后再通过训练集来衡量它的好坏,这次结果还不错,只有一个标签分类错误,如果w再大一点就好了。第三次结果就达到最优了,将所有的类别成功的分类。通过有标签的训练集不断的调整模型的参数使其达到最优这个过程就叫做监督学习。
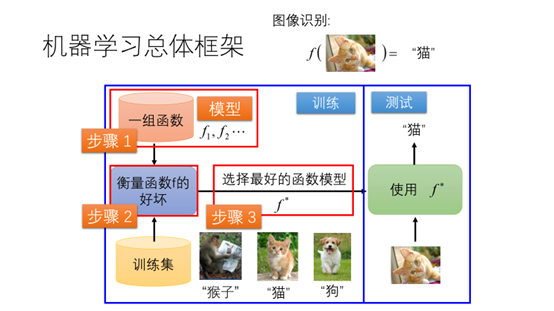
这里再举一个比较复杂的例子图像识别。和刚才一样也分为三个步骤(1)定义模型(2)通过训练集衡量函数f的好坏(3)选择最好的函数模型。这一部分过程叫做训练。我们可以通过训练好函数模型用来预测。比如输入一张新的图片,让模型判断是不是猫。
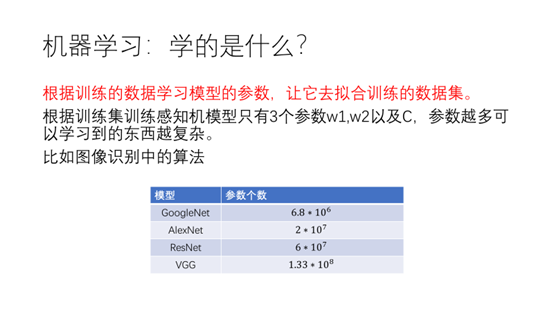
图像识别算法中的参数达到了百万,千万的级别。
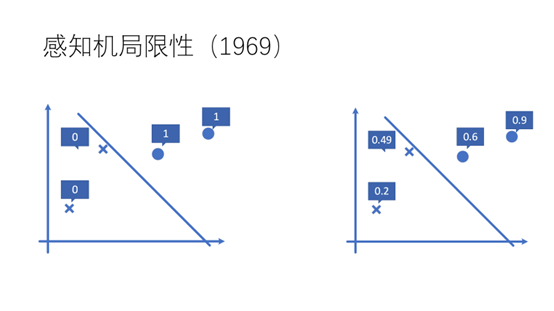
从图中我们可以看到感知机具有一个比较明显的局限性就是只能对每个点的类别进行分类(0,1)。而不能给出一个概率值,这个点属于点的概率是多少,这个点属于x的概率是多少。
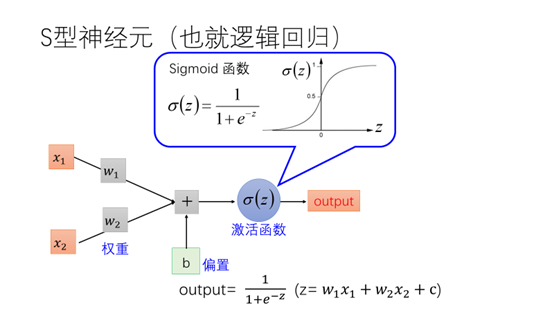
为此引入了S型神经元,通过在感知机的计算结果加上Sigmoid函数得到一个概率值。Sigmoid函数有时也叫做激活函数。
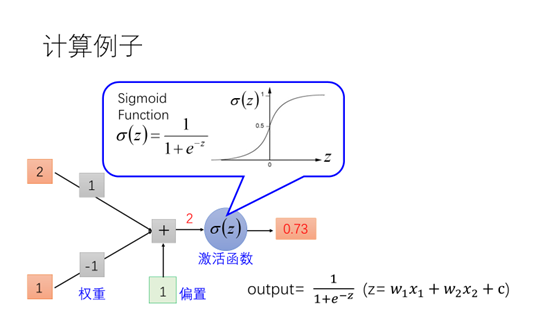
这里简单的给出一个计算的例子。计算公式如右下角所示,图中偏置为1,两个权重为1,-1。输入为2,1。得到计算计算结果为2,通过Sigmoid函数计算得到最后的值0.73。
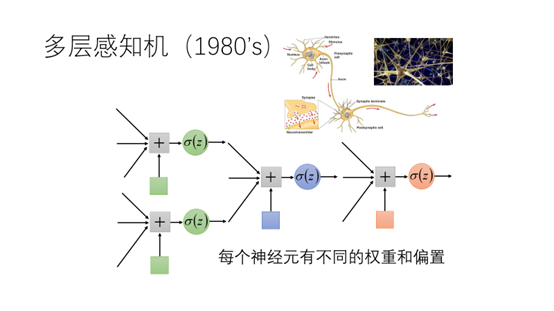
受生物学的启发,80年代人们将多个感知机连接起来得到一个网络,多层感知机也叫做人工神经网络。神经元中的权重和偏置将会通过学习的方式得到。
这里以神经网络为例子详细的介绍一下深度学习的三个步骤。步骤(1)定义一组函数模型,因为这里介绍的是神经网络,因此这里的模型就是神经网络。
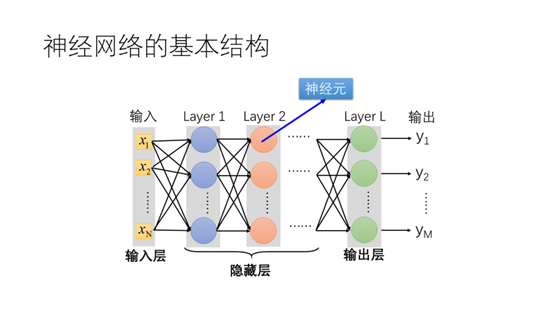
神经网络的基本结构具有一个输入层,一个输出层以及隐藏层。隐藏层的每个节点都是一个神经元,也就是之前定义的感知机。
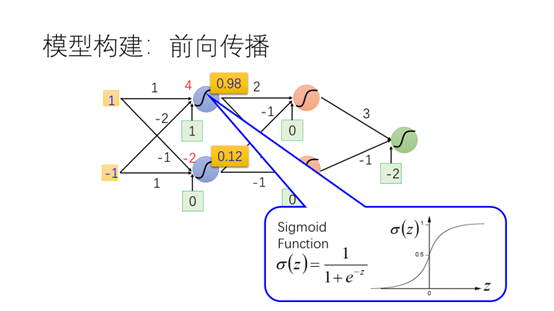
这里定义的神经网络模型具有两个输入,两个隐藏层,每个隐藏层有两个神经元,以及最后一个输出。随机的给定参数就可以得到一个具体的模型,也就一个函数。第一个隐藏层的第一个神经元按照之前感知机的计算方法得到结果0.98
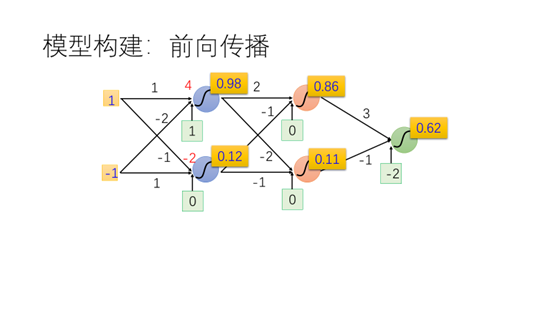
通过类似的方法计算其他神经元的值。最后得到结果0.62
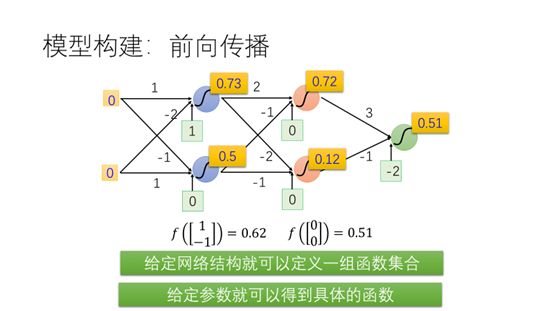
同样当输入为0,0时可以得到结果0.51
深度学习的第二步:衡量函数的好坏

假设我们的模型主要用来进行数字识别。训练集包含输入,以及对应输入的标签。比如输入为手写数字5,对应的输出为5。
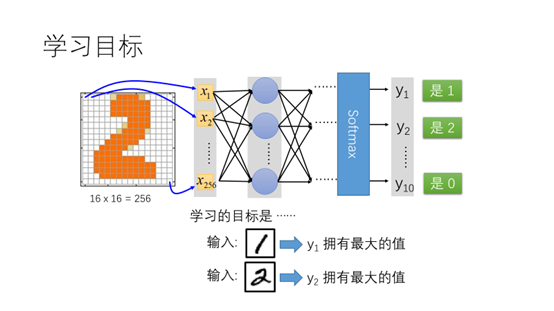
这里我们输入为256维的向量即图像的大小,输出是一个10维的向量。对应的维度表示对应的数字,如右边所示y1表示1,y2表示2…….y10表示0。学习的目标是对应输入的手写数字,代表该数字的输出值最大。
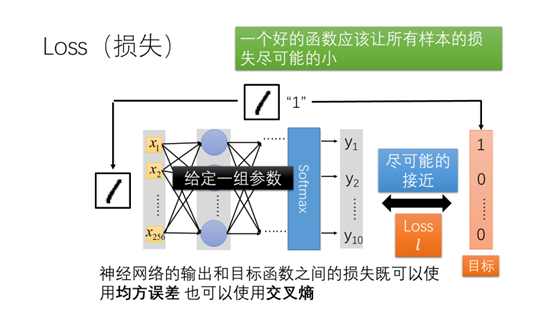
给定一组参数就确定了网络。给定一对标注好的数据,我们的目标是让输入的数据通过网络得到的输出结果尽可能的接近标注好的目标。输出和目标之间的差值叫做损失,衡量损失的大小既可以用均方误差也可以使用交叉熵来衡量。一个好的函数应该让所有样本的损失尽可能的小。
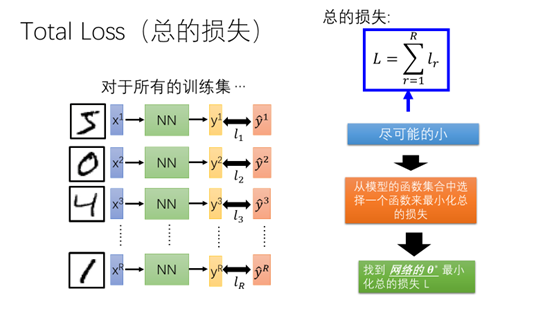
总的损失就是将每个样本的损失相加起来。我们的目标是使总的损失尽可能的小,也就是说从模型的函数集合中选择一个最小化总的损失的函数。
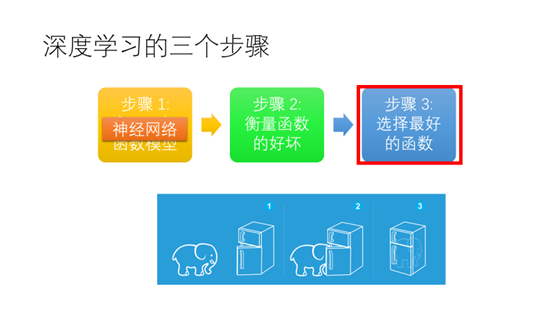
深度学习第三步(3)选择最好的函数来使损失最小化

一种简单的做法就是枚举所有可能的值,但是神经网络中的参数是数以万计的。比如图像识别中只有两层网络每层有1000个神经元,那么总共就有100万个参数了。枚举是不可能了,那么有什么比较好的方法来指导我们找到最优的参数?
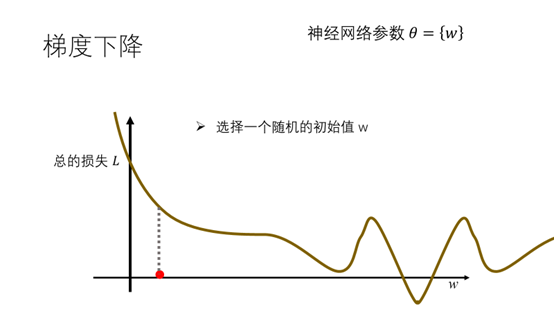
这里我们从最简单的情况开始考虑,假设网络中只有一个参数w,总的损失关于参数w的函数图如下所示。刚开始的时候随机的选择一个随机的初始值w。
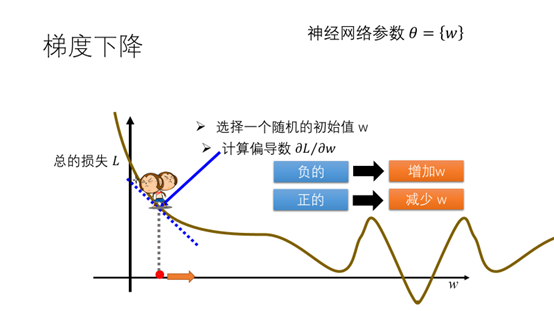
那么在该点处w往左还是往右会减少的总的损失?我们考虑在该点处总的损失关于w的偏导,如果偏导为负就增加w,如果偏导为正就减少w。这里求得偏导为负(斜率为负)因此增加w。
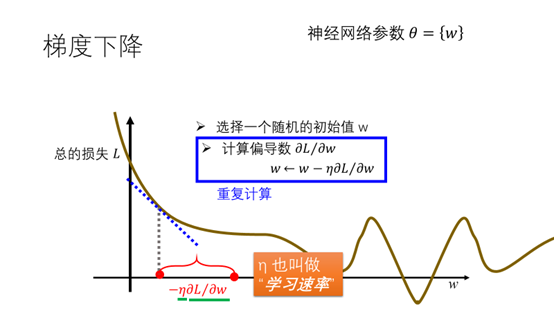
增加的值为,其中学习速率。重复计算该过程。
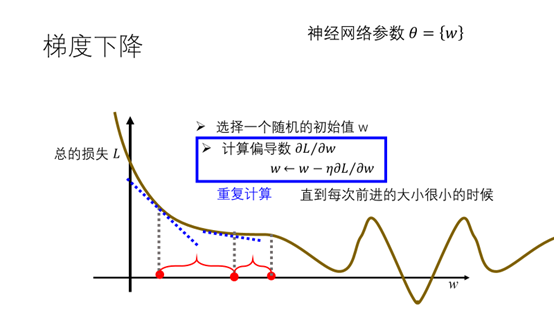
直到每次前进的大小很小的时候,如果是凸函数就会得到一个最小值,非凸函数会得到一个近似最优值
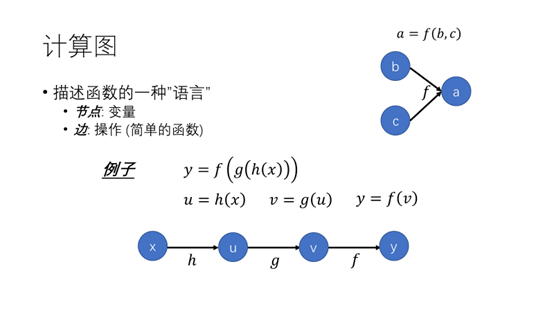
刚才考虑是一个参数的情况,由于网络中有很多参数,如何以一种较快的方法得到每个参数的梯度。这里就需要用到反向传播算法,在介绍方向传播算法之前需要了解一下计算图,这样有助于理解反向传播。计算图是用来描述函数的一种语言,节点表示变量,边表示操作(也就函数),定义了以什么样的方式得到输出。这里举一个例子,y是关于x的函数,这里嵌套了3层函数h,g,f用计算图表示如下。
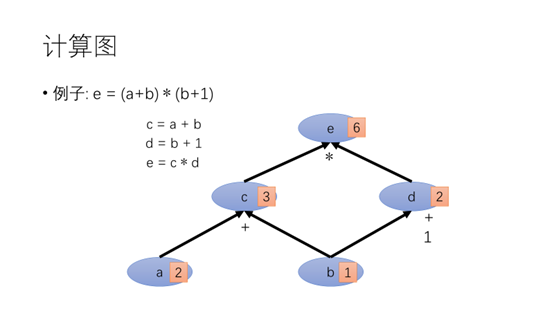
可能刚才的例子太抽象了,这里给出一个比较具体的例子。e = (a+b) ∗ (b+1),c=a+b,d=b+1,e=c*d。如果a=2,b=1,那么c=3,d=2,e=6。

我们由链式法以及导数的性质则得到的计算公式,简单的来说就是将所有b到e的路径相加。
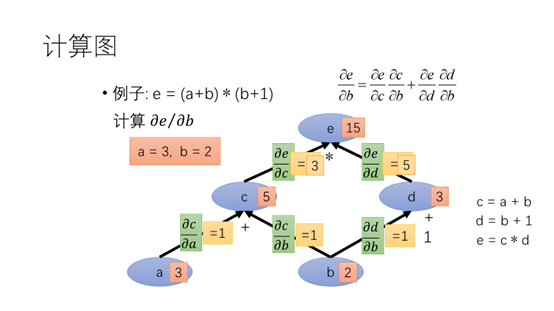
输入为a=3,b=2得到e的值为15。e对c求导的值为3,e对d求导的值为5。
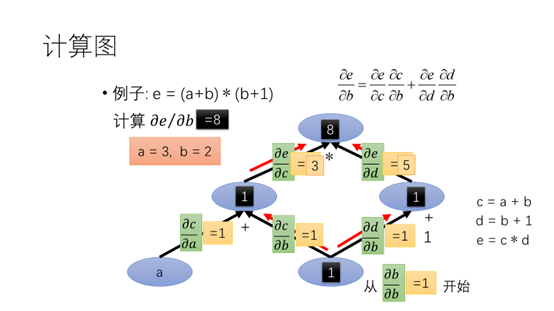
从b点出发计算e对b的导数。前一项的值为3,后一项的值为5。两项相加为8.
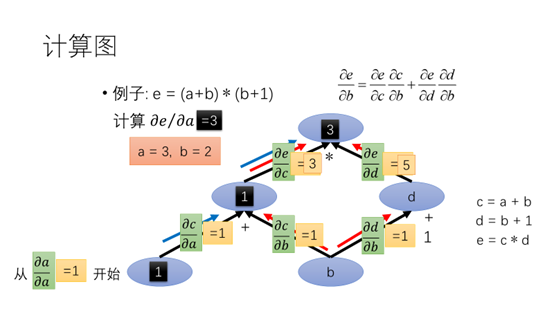
同理我们计算e对a的求导
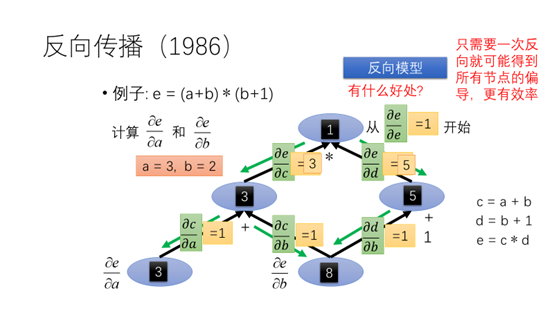
像刚才对节点求导的方法,每个节点都需要进行一次计算,比较浪费时间。如果反过来计算会怎么样?从e节点开始计算每个每个节点的导数,只需要一次反向就可以得到所有节点的偏导更有效率。

深度学习的反向传播计算是非常麻烦的,不过好在有很多框架为我们做了这一步,其中比较出名的就有tensorflow,keras,caffe。有了这些框架我们就可以致力于模型的构建。

做深度学习的研究可能看起来很神秘,其实大部分做的工作就想孩子一样在搭积木
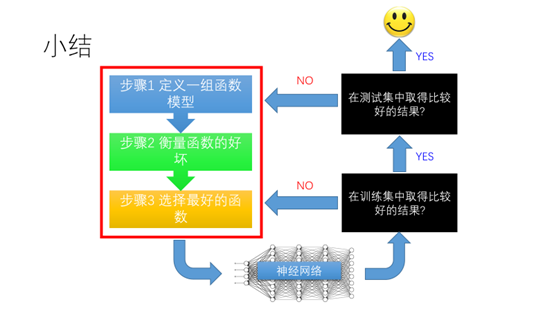
这里进行一下小结:深度学习的三个步骤(1)模型构建(2)衡量函数的好坏(3)选择最好的函数。如果在训练集中不能取得比较好的结果,应该重复步骤3.如果在训练集中取得了比较好的结果,但是在测试集中不能取得比较好的结果,那么需要重新定义模型。如果在训练集和测试集都取得不错的结果,那么恭喜你,你的神经网络可以工作了。
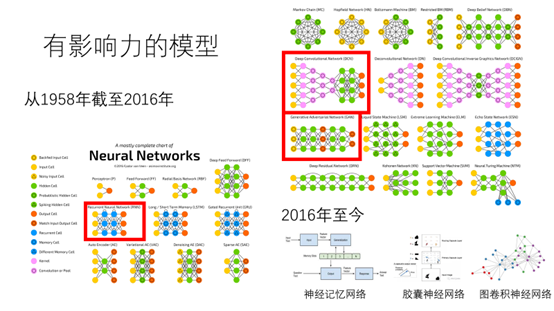
有人统计了1958年到2016年一些有影响力的模型共统计了27个。但是深度学习近几年发展速度2016年至今又出现了一些比较有影响力的模型比如神经记忆网络,胶囊神经网络,图卷积神经网络等。接下去我将简单的介绍一下三个比较流行的神经网络模型(卷积神经网络、循环神经网络、对抗生成网络)。
这里首首先介绍一下卷积神经网络,卷积神经网络广泛应用于图像图像处理
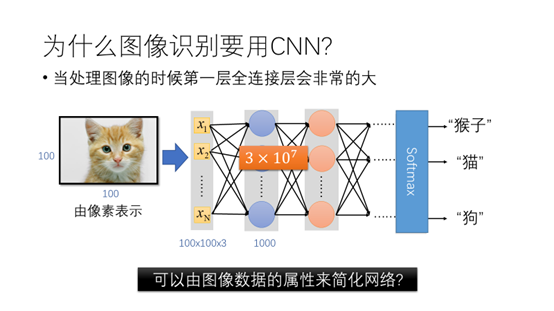
我们在刚才的例子中看到了全连接的神经网络也可以用于图像识别,那么为什么要广泛的使用卷积神经网络呢?当处理图像的时候第一层全连接层会非常的大,比如一张由100*100构成的图片,输入的大小为100*100*3,如果第一层的隐藏神经元大小为1000的话,那么这时候神经元的个数就有了千万级别了。我们可以利用图像数据的一些属性来简化网络吗?
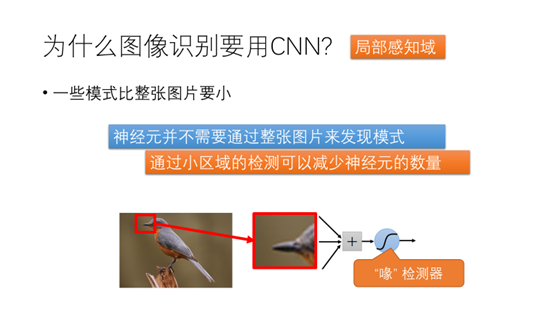
一些模型模式比整张图片要小,比如鸟的嘴,只需要一个比较小的区域就可以检测了。因此神经元并不需要通过整张图片来发现模式,通过小区域的检测就可以减少神经元的数量。这个特性也叫卷积神经网络的局部感知域特性。
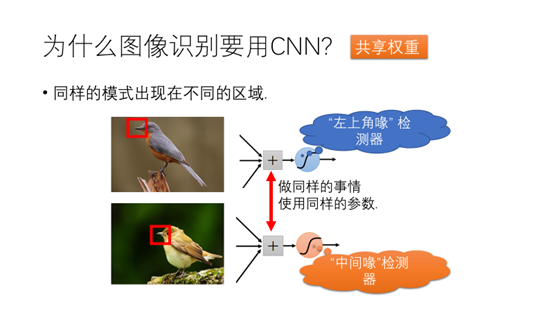
从图中我们可以看到同样的鸟嘴出现在图片中的不同位置,我们可以构造左上角嘴检测器,中间嘴检测器,但是这两个检测器都做同样的事情检测嘴,因此可以使用同一个检测器进行检测。这个特性也叫做卷积神经网络的共享权重特性。
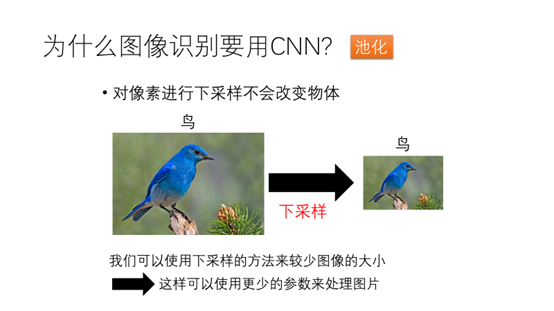
对像素进行下采样并不会改变物体的形状,我们可以使用下采样的方法来减少图片的大小。这样可以使用更少的参数来处理图片。
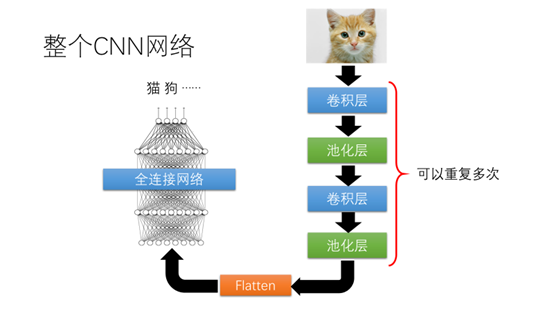
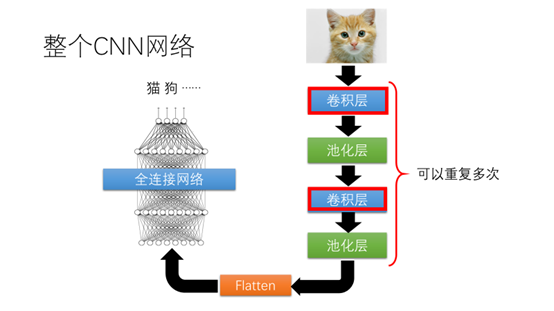
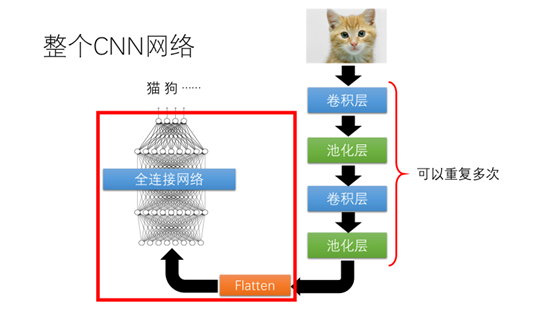
整个卷积网络的结构如图所示,有卷积层、池化层。通过Flatten操作作为全连接网络的输入。
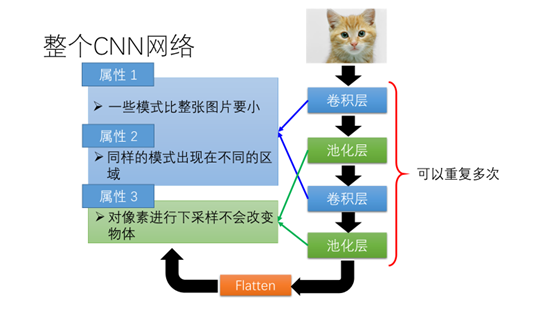
刚才提到的图像的三个属性。其中前两个属性"一些模式比整张图片要小","同样的模式出现在不同的区域"会被卷积层所考虑,"对像素进行下采样不会改变物体"会被池化层所考虑。
这里首先介绍一下卷积层进行的操作
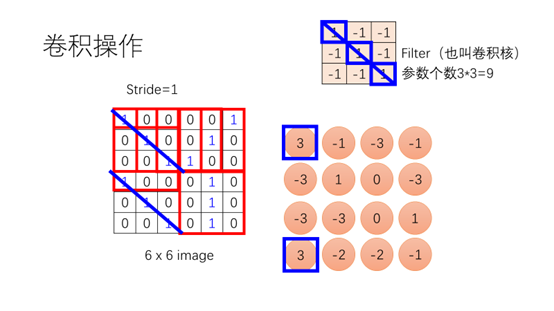
卷积层由Filter(卷积核)构造,卷积核也是一个矩阵,然后再和图片进行卷积操作,卷积操作就是对应位置的元素相乘然后再相加。如果我们观察这个卷积核可以发现卷积核的斜对角线是三个1,因此这个卷积核可以用来检测斜对角是1的pattern,如果斜对角都是1那么它的输出值会比较大。从图中我们可以看到左上角和左下角都有斜对角是1的pattern,对应的输出值都是3.
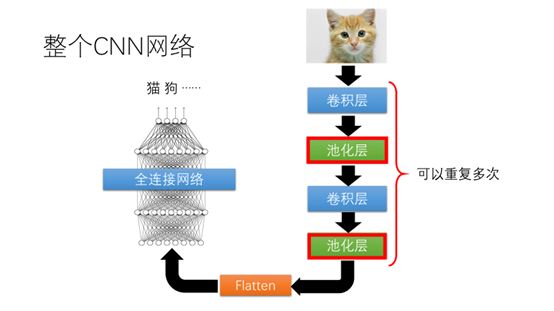
接下来介绍一下池化层
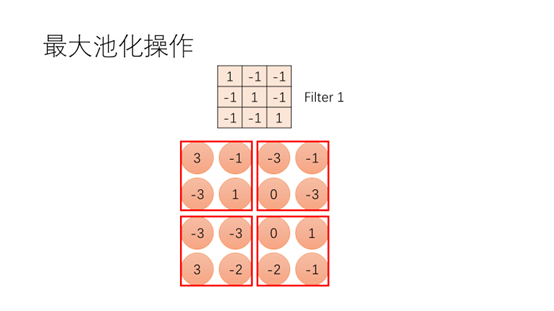
这里给出刚才由卷积核计算得到的矩阵,现在我们将矩阵分为4个区域,每个区域我们用最大值来表示,这样可以明显减少图片的大小。也有其他的池化操作比如对数据取平均。
由池化层得到的向量通过Flatten操作变为一维向量后再作为全连接网络的输入,得到分类的结果。
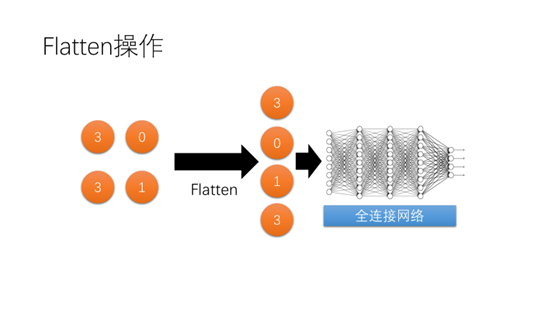
这里举的例子就是将刚才最大池化得到的结果进行Flatten操作后得到一个4维向量作为全连接网络的输入。


接下去介绍一下循环神经网络RNN,循环神经网络具有记忆性可以记住之前的状态,根据之前的状态来进行预测。
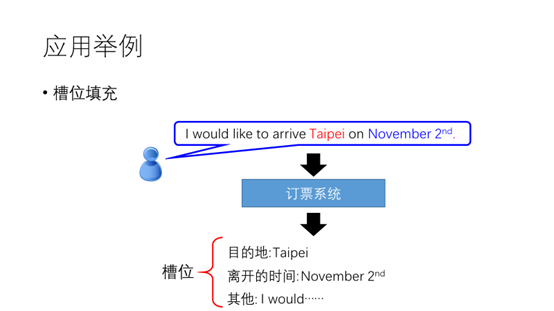
在介绍RNN之前这里给出一个槽位填充的例子,槽位填充就是将句子的每个单词放入到不同类别的槽位。假设我们有一个订票系统,根据用户的输入自动的判断目的地,离开时间,也就是说将用户的输入的单词填入到目的地槽,离开时间槽以及其他类型槽中
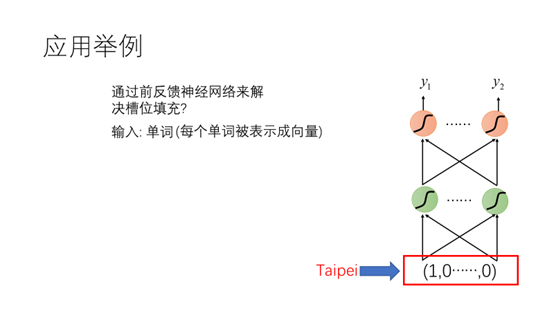
这里我们首先试一下看能不能用前反馈神经网络来解决槽位填充的问题。输入的是单词,输出是该单词属于每个槽位的概率。由于神经网络的输入必须是数字,而单词是字符串,因此需要有一种方法将每个单词表示成向量。

一种简单的做法就是通过one-hot编码的方式来对单词进行编码。假设我们有一个词典里面包含了5个单词,那么我们可以定义一个5维的向量,每一个维度对词库中的一个单词。如右边所示。
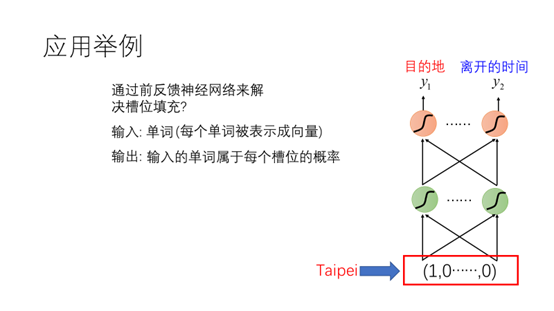
前反馈神经网络的输出为单词属于每个槽位的概率
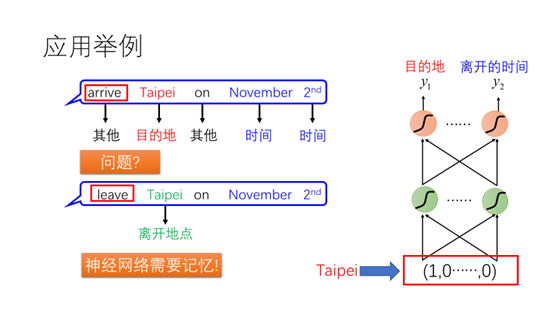
通过前反馈神经网络我们可以将每个单词放入不同的槽位。但是这样做会有什么问题呢?我们看一下下面这个句子,这里的台北是离开的地点,因为台北前面的动词是leave。因此为了进行准确的判断,神经网络需要有记忆能够记住前面的单词。
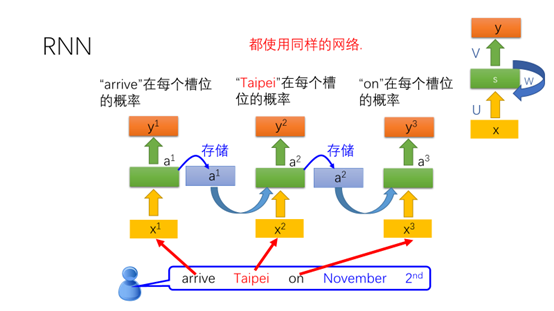
为此引入了循环神经网络,循环神经网络将前一个节点的状态同当前的输入作为网络的输入,得到当前输入的输出以及当前节点的状态作为下一个节点的输入。注意这三个网络都是相同的网络,具有相同的参数。因此有时候循环神经网络也可以画成右上角的样子。
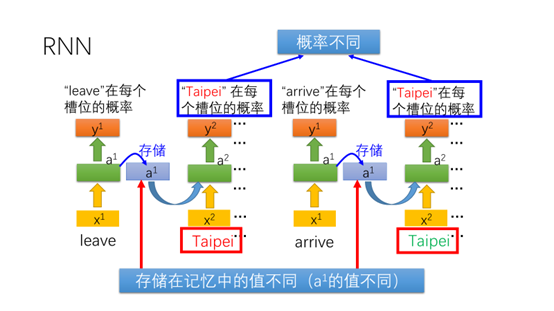
我们再来看一下之前的例子,网络的输入都是台北,但是前一个状态的值不同,因此输出的台北在每个槽位的概率也会不同。
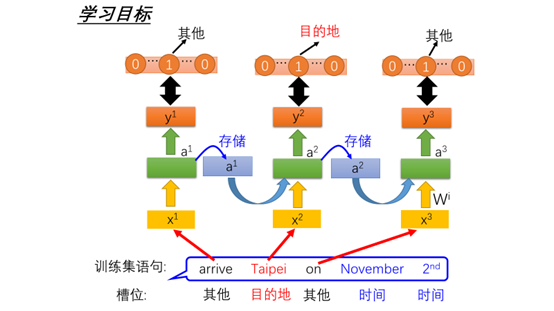
在这个例子中我们学习的目标就是在句子中的每个单词都可以正确的分配到每个槽位。


这里介绍一下RNN的一个扩展例子,文本生成。这一篇论文将Linux内核代码进行训练,然后让循环神经网络生成句子,可以看出来生成的效果还是比较好的,但只是结构比较像,并没有什么实际的含义。论文对为什么能够生成这样的代码进行可视化说明,不同的神经元对不同的代码模式感兴趣。有的神经元对if语句中的内容感兴趣,有的神经元对语句的结尾感兴趣。总的来说神经网络可以识别序列的一些基本的结构模式,才能生成这样的代码。

最后介绍一个对抗生成网络GAN,对抗生成网络可以根据已有的数据,生成和已有数据具有相似分布的数据。
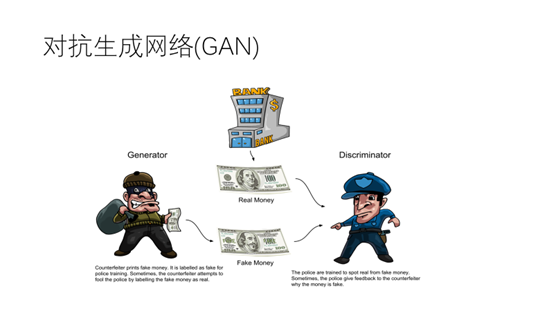
关于对抗生成网络有一有个形象的比喻。造假者想要造假币(但是不知道真币是什么样的),那么我们只能通过警察根据真钞的样子进行反馈,才知道自己造的假币到底够不够真。在这个反复的过程中警察辨识力越来越高,造假者的造假技术也越加成熟,最终我们得到了一个火眼金睛的警察,但是也得到了能以假乱真的造币工艺。我们通过这个造币工艺就可以生成长得像真钞的假钞。
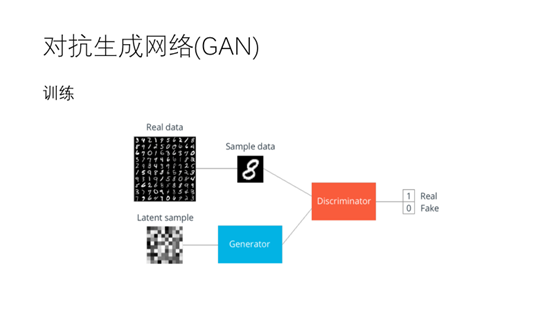
在对抗生成网络中有两个基本的模块,生成器和判别器。按照刚才的比喻生成器就是造假者,判别器就是警察。在这个例子中我们目的是训练一个可以生成数字的生成器。
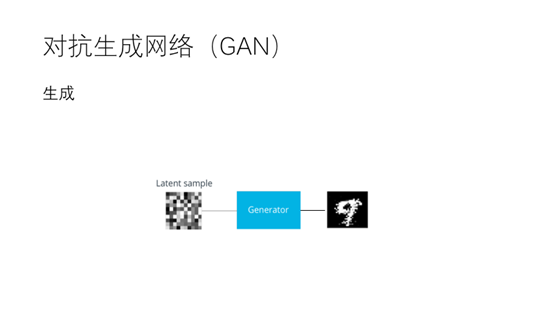
通过生成器我们可以生成一些新的数字。


最新的论文生成的图片已经达到以假乱真的程度了,一下的图片都是生成出来的。

由于近几年深度学习比较火,其他领域也渐渐的参与进来。从芯片、指令、编译器到系统都有人在做深度学习相关的研究来提升深度学习训练的速度。

深度学习研究方法和传统的机器学习的方法不太一样,传统的机器学习需要仔细的设计算法,然后通过理论来证明它的性能。但是深度学习更多是尝试,很多结果和我们的直觉相矛盾。对于得到一些比较好的结果我们需要找一些原因来解释我们所观测到的,所以深度学习更多的像化学实验或者更糟。


早在1980年代,人们对神经网络充满了兴奋和乐观,尤其是在BP被大家广泛知晓后。
而在1990年代,这样的兴奋逐渐冷却,机器学习领域的注意力转移到其他技术上,如SVM。但是谁又能说,明天会不会有一种新的方法能够击败神经网络?或者可能神经网络研究的进程有会阻滞,没有任何的进展?
所以,可能更好的方式是看看机器学习的未来而不是单单看神经网络。
还有个原因是我们对神经网络的理解还是太少了。
为何神经网络能够这么好的泛化?
为何在给定大规模学习的参数后,采取一些方法后可以避免过匹配?
为了神经网络中梯度下降很有效?
这些都是简单,根本的问题,但是当前都无法回答这些问题。
所以要说神经网络的未来很难回答

