通过混合编程分析的方法和机器学习预测Web应用程序的漏洞
通过混合编程分析的方法和机器学习预测Web应用程序的漏洞
由于时间和资源的限制,web软件工程师需要支持识别出有漏洞的代码。一个实用的方法用来预测漏洞代码可以提高他们安全审计的工作效率。在这篇文章中,作者提出使用混合(静态和动态)代码属性来识别输入验证和输入检查的代码模式以用来标识web应用程序的漏洞。因为静态和动态程序分析相互补充,因此经常通过这种方法来提取合适的属性。现在的漏洞预测技术依靠带有数据标签的漏洞信息进行训练。对于很多真实的应用,过去的漏洞数据经常获取不到,或者至少不能完全地获取。因此为了解决获取过去数据漏洞的问题,作者同时使用监督学习和半监督学习的方法来构建基于混合代码属性的漏洞预测系统。半监督学习的方法从来没有在这个领域进行运用,作者给出了如何有效的使用该方法来进行预测。作者在7个开源的项目中进行评估。在交叉验证的过程中,监督学习的模型实现了平均达到77%的召回率,在预测SQL注入,跨站脚本攻击,远程代码执以及文件漏洞中存在5%的错误率。在小的标签数据量下,同监督学习的模型相比,半监督学习平均提高了24%的召回率,和降低了3%的错误率。因此建议半监督学习用于现实生活中很多漏洞数据缺失情况。
Web应用中常见漏洞有
SQL注入,
跨站脚本攻击,
远程代码执行,
文件包含
SQL注入:
SQL注入漏洞发生在用户输入数据查询的时候没有进行适当的查询。它允许攻击者使用技巧来来获取未授权的数据。
跨站脚本攻击:
百度百科的解释: XSS又叫CSS (Cross Site Script) ,跨站脚本攻击。它指的是恶意攻击者往Web页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web里面的html代码会被执行,从而达到恶意用户的特殊目的。
远程代码执行:
远程代码执行允许攻击者可以随意的在服务端上执行应用程序代码。允许以管理员的身份执行远程代码。
文件包含漏洞:
文件包含,包括本地文件包含(Locao file inclusion, LFI)和远程文件包含(Remote File Inclusion,RFI)。首先本地文件包好就是通过浏览器引进(包含)Web服务器上的文件,这种漏洞一般发生在浏览器包含文件时没有严格的过滤,允许比那里目录的字符注入浏览器并执行(比如:asp?file=index.html)。这类漏洞看起来并不严重,一旦被恶意利用则会带来很大的危害。本地文件包含不仅能够包含web文件目录中的一些配置文件(比如Web应用,数据配置文件,config文件),还可以查看一些Web动态页面的源代码,为攻击者进一步发掘web应用漏洞提供条件。
常用的检测方法有
static taint analysis:Static taint analysis approaches are scalable in general but are ineffective in practice due to high false positive rates.
dynamic taint analysis: can be highly accurate, but have scalability issues for large systems due to path explosion problem.
modeling checking
symbolic
concolic testing
Shin et al: scalable vulnerability prediction approaches.
但是现在预测方法是粗粒度的,他们在软件模块或者组件的级别进行预测。
从web开发人员的角度来看,输入验证和输入检查是两个安全的代码技术用来防止出现这样的漏洞。
输入验证:数据的长度,范围,类型和符号。
输入检查:只接受预先定义的字符,拒绝其他字符(包括字符对于解释器有特殊的含义)
从直观上看,如果开发人员没有实现正确的实现这些技术或者没有在一定程度上实现这些技术,那么应用将会存在漏洞。
从上面的角度来看,混合(静态和动态)代码属性来识别输入验证和输入检查的代码模式以用来标识web应用程序的漏洞
基于以上的假设,作者提出了一系系列代码属性称为(input validation and sanitization IVS属性)

通过这些可以构建漏洞预测模型,这个模型是细粒度的,准确的,可扩展的。因为是在语句级别进行识别所以是细粒度的。
作者同时使用静态的和动态的分析技术进行IVS属性的提取。静态分析方法可以帮助获取程序的通用属性。动态分析方法可以作为静态方法的互补,来获取更加细节的代码。使用动态方法仅仅是用来获取属性,而不是用来判判断他们的正确性。获取完属性后再通过机器学习的方式来进行漏洞的预测。
漏洞预测框架如下图所示

漏洞测试框架主要由两个组成部分构成
混合程序分析:对于每一个安全铭感点(sink),会有一个后台的静态分析程序分析安全铭感点(sink)的语句和变量。通过混合程序分析的方法获取上面提到的IVS属性
创建漏洞预测模型:通过这些属性基于监督学习以及半监督学习的方法进行模型的构建。
混合程序分析
混合程序分析是基于控制流图(control flow graph,CFG),程序依赖图(program dependence graph,PDG),系统依赖图(system dependency graph,SDG)对web应用程序进行编程。控制流图中的每一个节点代表一个源代码语句。
安全铭感点(sink)是控制流图中的一个节点使用的变量是来自外部,因此可能遭受到攻击。这允许我们在语句级别预测漏洞。Input nodes是一个节点用来获取外部数据。一个变量是污点(tainted)如果它是定义来自输入的节点。
漏洞测试框架的第一步是通过程序切片的方法对每一个安全铭感点k和安全铭感点使用的污点变量。切片<K,V>包含了可能影响节点k的变量值V的所有的节点(包括预测的节点)。
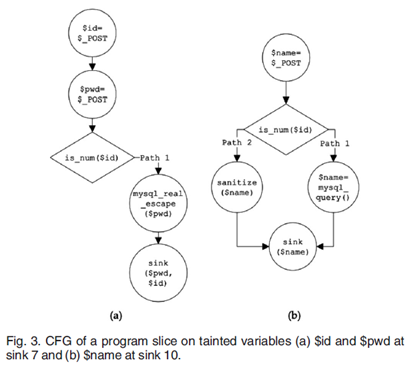
关于安全铭感点以及切片论文给出了一个例子

在安全铭感点7以及安全铭感点10对污点变量进行切片操作得到了如下图所示的控制流图。切片技术去除了与感兴趣的程序点无关的,不能影响到程序点变量取值的语句,因此消减了程序规模。
典型的一个web应用程序获取输入的内容,并且通过污点变量进行传播来执行将来程序的逻辑。这些操作可能包括铭感的程序操作比如数据库更新,HTML输出,文件获取。如果程序变量传递输入的数据在安全铭感点没有经过适当的检查,就可能引发漏洞。因此为了防止web应用程序的漏洞,开发人员在安全铭感点的路径会加入输入验证和检查。默认输入到应用程序的内容是字符串。输入验证和输入检查主要是针对字符串的操作。这些操作包括语言内置的方法,比如mysql_real_escape_string。字符串替换和字符串匹配方法,比如str_match以及正则表达式。
我们试图回答如下的问题"给出了安全敏感点的切片,是否可以从输入的类型和数量,以及输入验证以及输入检查方法的类型和数量,来对安全敏感点进行预测?"
对于属性的提取分析经过下面两个步骤:
步骤1:提取安全铭感点的所有可能结果。为了避免无限的可能性,只对循环提取一次,比如在上图中只有一条路径,有两条路径。
步骤2:对于每一个提取的路径根据IVS属性进行分类。分类是通过强制的静态分析以及可选的动态分析。
强制静态分析:我们对每一条路径根据IVS进行分类。一些标准的安全函数以及一些内建的函数以及操作可以准确的进行分类。下面进行举例说明,在上面的PHP代码中:

语句4,根据POST可以得出是一个输入类型。语句8,语句(.)对输入的数据进行了操作,因此我们可以将(.)分类为污点传播类型。
下面可以举另一个例子,在图3中,安全铭感点7和安全铭感点10都包含了路径的标准安全函数。因为安全铭感点7只有一条路径,因此只需要静态分析。

语句5中,is_numeric()被用来验证是否为数字。Mysql_real_escape被用来去除特殊的字符。根据内置的方法,我们可以将它们进行静态的分类。
可选的动态分析:如果路径包含非标准的安全函数以及内置的函数,比如复杂的正则表达式,函数的目的不能使用静态分析进行简单的推断,因此就需要使用动态的分析方法分析路径。
有一个数据维护着不同类型的测试用例。测试用例是由不同类型的攻击字符串包含着恶意字符。
在动态执行和分析的过程中,首先会从路径中提取代码,然后根据提取的代码生成测试代码。如下图所示

对于IVS每一种类型在数据库中都有相应的测试代码,如果测试代码不能通过,就可以将其分类到该类别中。
建立预测模型
数据表示
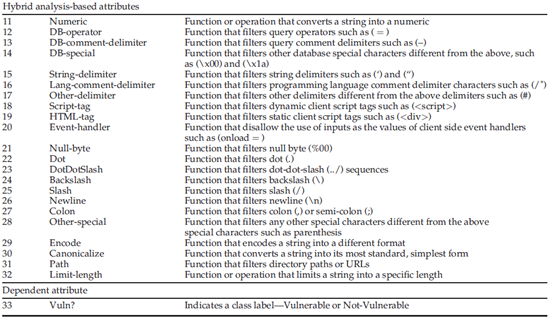
因为我们再表1中提出了33个IVS属性,因此对于数据流图中的每一条路径都可以表示成一个33维的属性向量。下图展示了安全敏感点7和安全铭感点10在它们的路径中提取的属性。最后一列是用来标识在给定的路径中是否存在漏洞,用来进行预测。

数据预处理
剔除一些相关性比较小的特征
监督学习方法
根据提供的属性论文采取了逻辑回归和随机深林的方法进行分类。
逻辑回归
是安全铭感点在路径A下存在漏洞的条件概率。
是IVS属性。
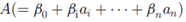
是参数,可以通过梯度下降的方法进行求解
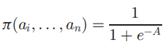
随机森林:随机森林(Random Forest)是Bagging的一个扩展变体。RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来说,传统决策树在选择划分属性时是在当前节点的属性集合(假设有d个属性)中选择一个最优属性,而在RF中,对基决策树的每个节点,先从该节点的属性集合中随机选择一个包含k属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参数k控制了随机性的引入程度:若令k=d,则基决策树的构建与传统决策树相同;若令k=1则是随机选择一个属性用于划分;一般情况下,推荐值
进行预测:对于一个新的没有标签的web程序,可以混合编程的分析方法获取代码属性IVS,再将IVS放入到训练好的模型中进行预测。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号