
高性能 C++ HTTP 客户端原理与实现
一、什么是Http Client
Http协议,是全互联网共同的语言,而Http Client,可以说是我们需要从互联网世界获取数据的最基本方法,它本质上是一个URL到一个网页的转换过程。而有了基本的Http客户端功能,再搭配上我们想要的规则和策略,上至内容检索下至数据分析都可以实现了。
继上一次介绍用Workflow可以10行C++代码实现一个高性能Http服务器,今天继续给大家用C++实现一个高性能的Http客户端也同样很简单!
// [http_client.cc]
#include "stdio.h"
#include "workflow/HttpMessage.h"
#include "workflow/WFTaskFactory.h"
int main (int argc, char *argv[])
{
const char *url = "https://github.com/sogou/workflow";
WFHttpTask *task = WFTaskFactory::create_http_task (url, 2, 3,
[](WFHttpTask * task) {
fprintf(stderr, "%s %s %s\r\n",
task->get_resp()->get_http_version(),
task->get_resp()->get_status_code(),
task->get_resp()->get_reason_phrase());
});
task->start();
getchar(); // press "Enter" to end.
return 0;
}
只要安装好了Workflow,以上代码即可以通过以下命令编译出一个简单的http_client:
g++ -o http_client http_client.cc --std=c++11 -lworkflow -lssl -lcrypto -lpthread
根据Http协议,我们执行这个可执行程序 ./http_client,就会得到以下内容:
HTTP/1.1 200 OK
同理,我们还可以通过其他api来获得返回的其他Http header和Http body,一切内容都在这个 WFHttpTask 中。而因为Workflow是个异步调度框架,因此这个任务发出之后,不会阻塞当前线程,外加内部自带的连接复用,从根本上保证了我们的Http Client的高性能。
接下来给大家详细讲解一下原理~
二、请求的过程
1. 创建Http任务
上述demo可以看到,请求是通过发起一个Workflow的Http异步任务来实现的,创建任务的接口如下:
WFHttpTask *create_http_task(const std::string& url,
int redirect_max, int retry_max,
http_callback_t callback);
第一个参数就是我们要请求的URL。对应的,在一开始的示例中,我们的重定向次数redirect_max是2次,而重试次数retry_max是3次。第四个参数是一个回调函数,示例中我们用了一个lambda,由于Workflow的任务都是异步的,因此我们处理结果这件事情是被动通知我们的,结果回来就会调起这个回调函数,格式如下:
using http_callback_t = std::function<void (WFHttpTask *)>;
2. 填写header并发出
我们的网络交互无非是请求-回复,对应到Http Client上,在我们创建好了task之后,我们有一些时机是处理请求的,在Http协议里,就是在header里填好协议相关的事情,比如我们可以通过Connection来指定希望得到建立Http的长连接,以节省下次建立连接的耗时,那么我们可以把Connection设置为Keep-Alive。示例如下:
protocol::HttpRequest *req = task->get_req();
req->add_header_pair("Connection", "Keep-Alive");
task->start();
最后我们会把设置好请求的任务,通过 task->start(); 发出。最开始的 http_client.cc 示例中,有一个 getchar(); 语句,是因为我们的异步任务发出后是非阻塞的,当前线程不暂时停住就会退出,而我们希望等到回调函数回来,因此我们可以用多种暂停的方式。
3. 处理返回结果
一个返回结果,根据Http协议,会包含三部分:消息行、消息头header、消息正文body。如果我们想要获取body,可以这样:
const void *body;
size_t body_len;
task->get_resp()->get_parsed_body(&body, &body_len);
三、高性能的基本保证
我们使用C++来写Http Client,最香的就是可以利用其高性能。Workflow对高并发是如何保证的呢?其实就两点:
- 纯异步;
- 连接复用;
前者是对线程资源的重复利用、后者是对连接资源的重复利用,这些框架层级都为用户管理好了,充分减少开发者的心智负担。
1. 异步调度模式
同步和异步的模式直接决定了我们的Http Client可以有多大的并发度。为什么呢?通过下图可以先看看同步框架发起三个Http任务,线程模型是怎样的:

网络延迟往往非常大,如果我们在同步等待任务回来的话,线程就会一直被占用。这时候我们需要看看异步框架是如何实现的:
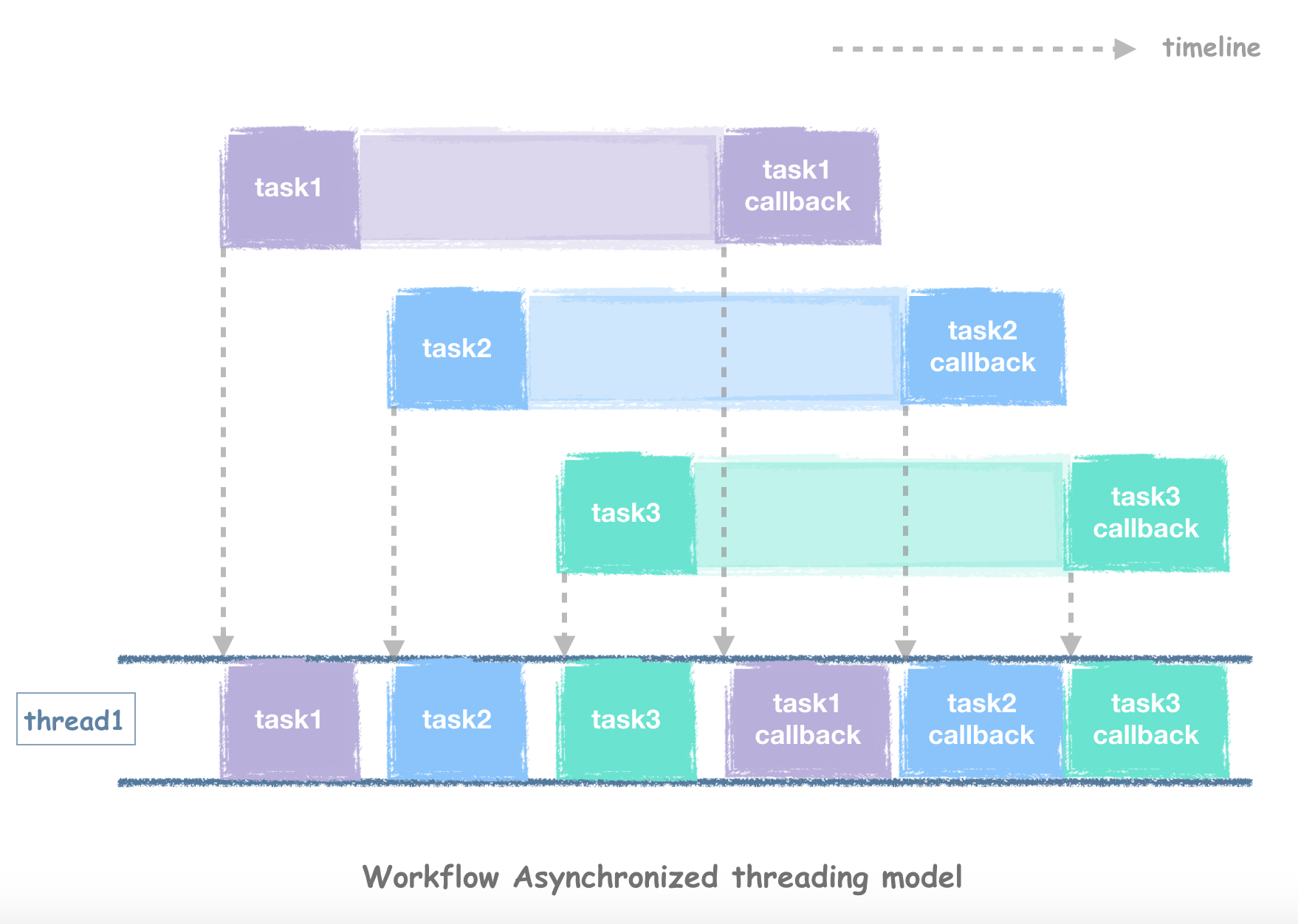
如图所示,只要任务发出之后,线程即可做其他事情,我们传入了一个回调函数做异步通知,因此等任务的网络回复收完之后,再让线程执行这个回调函数即可拿到Http请求的结果,期间多个任务并发出去的时候,线程是可以复用的,轻松达到几十万的QPS并发度。
2. 连接复用
我们刚才有提到,只要我们建立了长连接,即可提高效率。为什么呢?因为框架对连接有复用。我们先来看看如果一个请求就建立一个连接,会是什么样的情况:
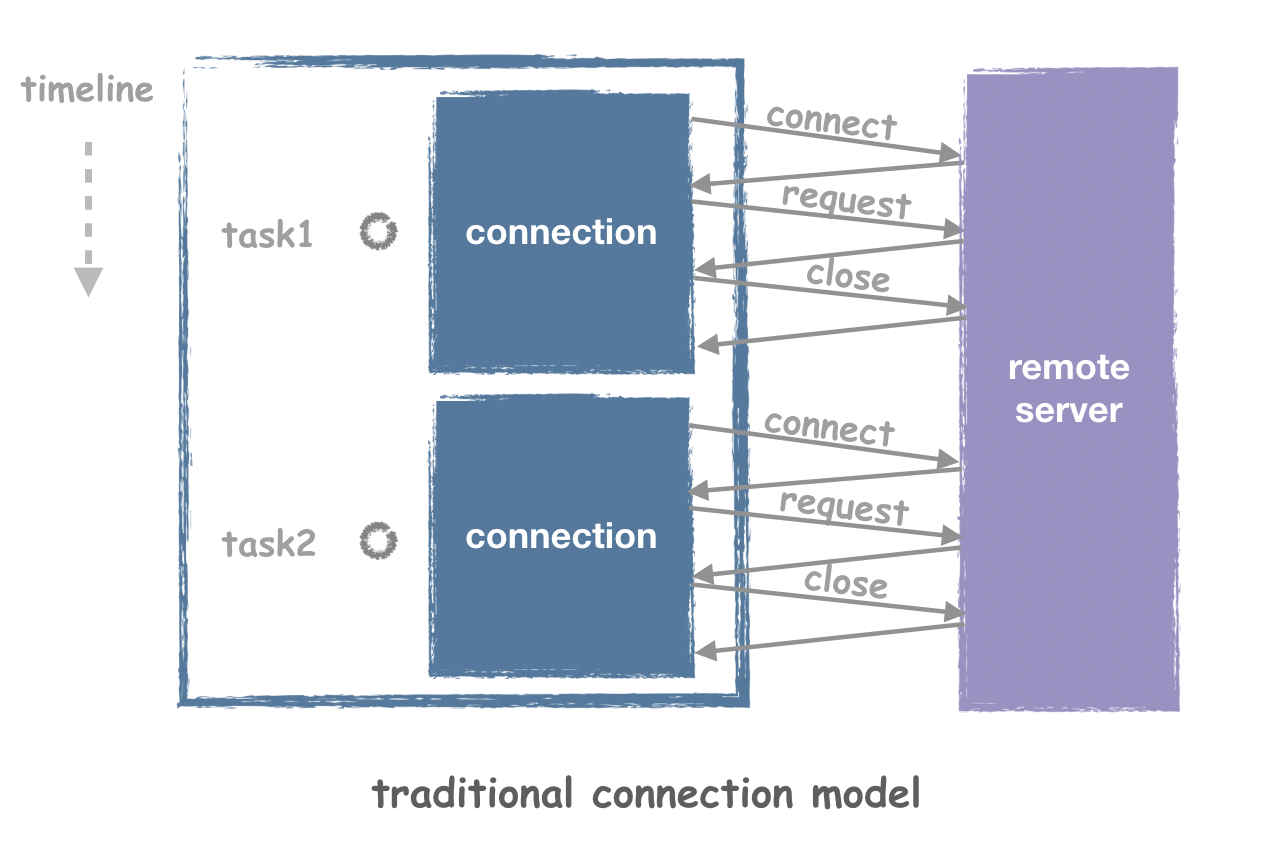
很显然,占用大量的连接是对系统资源的浪费,而且每次都要做connect以及close是非常耗时的,除了TCP常见的握手以外,许多应用层协议建立连接的过程也会相对复杂。但使用Workflow就不会有这样的烦恼,Workflow会在任务发出的时候自动查找当前可以复用的连接,如果没有才会自动创建,完全不需要开发者关心连接如何复用的细节:
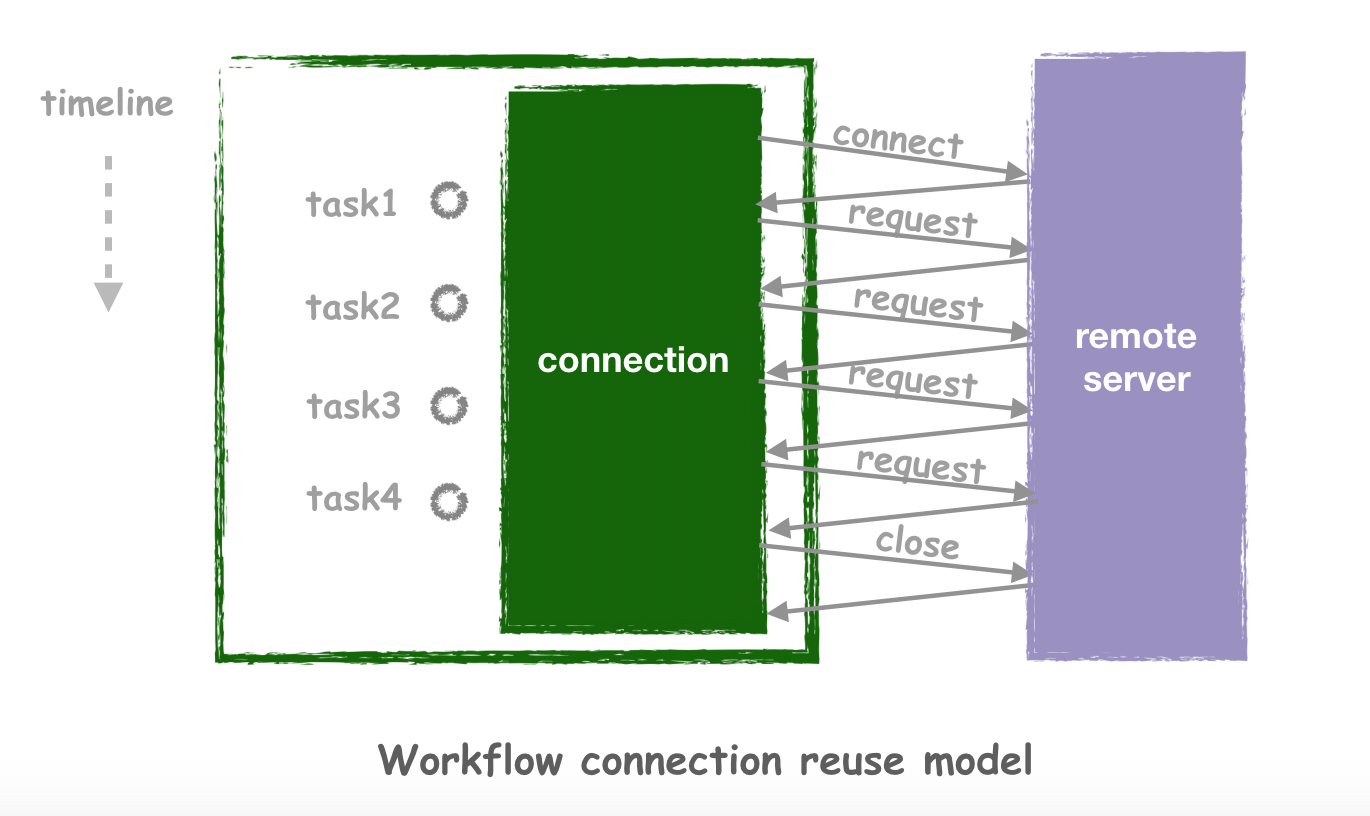
3. 解锁其他功能
当然,除了以上的高性能以外,一个高性能的Http Client往往还有许多其他的需求,这里可以结合实际情况与大家分享:
- 结合workflow的串并联任务流,实现超大规模并行抓取;
- 按顺序或者按指定速度请求某个站点的内容,避免请求过猛被封禁;
- Http Client遇到redirect可以自动帮我做跳转,一步到位请求到最终结果;
- 希望通过proxy代理访问
HTTP与HTTPS资源;
以上这些需求,要求框架对于Http任务的编排有超高的灵活性,以及对实际需求(比如redirect、ssl代理等功能)有非常接地气的支持,这些Workflow都已经实现。
项目地址
https://github.com/sogou/workflow
欢迎使用 workflow 并 star 支持一下!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号