北航面向对象设计与构造2021第四单元作业总结
 1. 总结本单元作业的架构设计
2. 总结自己在四个单元中架构设计及OO方法理解的演进
3. 总结自己在四个单元中测试理解与实践的演进
4. 总结自己的课程收获
5. 立足于自己的体会给课程提三个具体改进建议
1. 总结本单元作业的架构设计
2. 总结自己在四个单元中架构设计及OO方法理解的演进
3. 总结自己在四个单元中测试理解与实践的演进
4. 总结自己的课程收获
5. 立足于自己的体会给课程提三个具体改进建议
一、总结本单元作业的架构设计
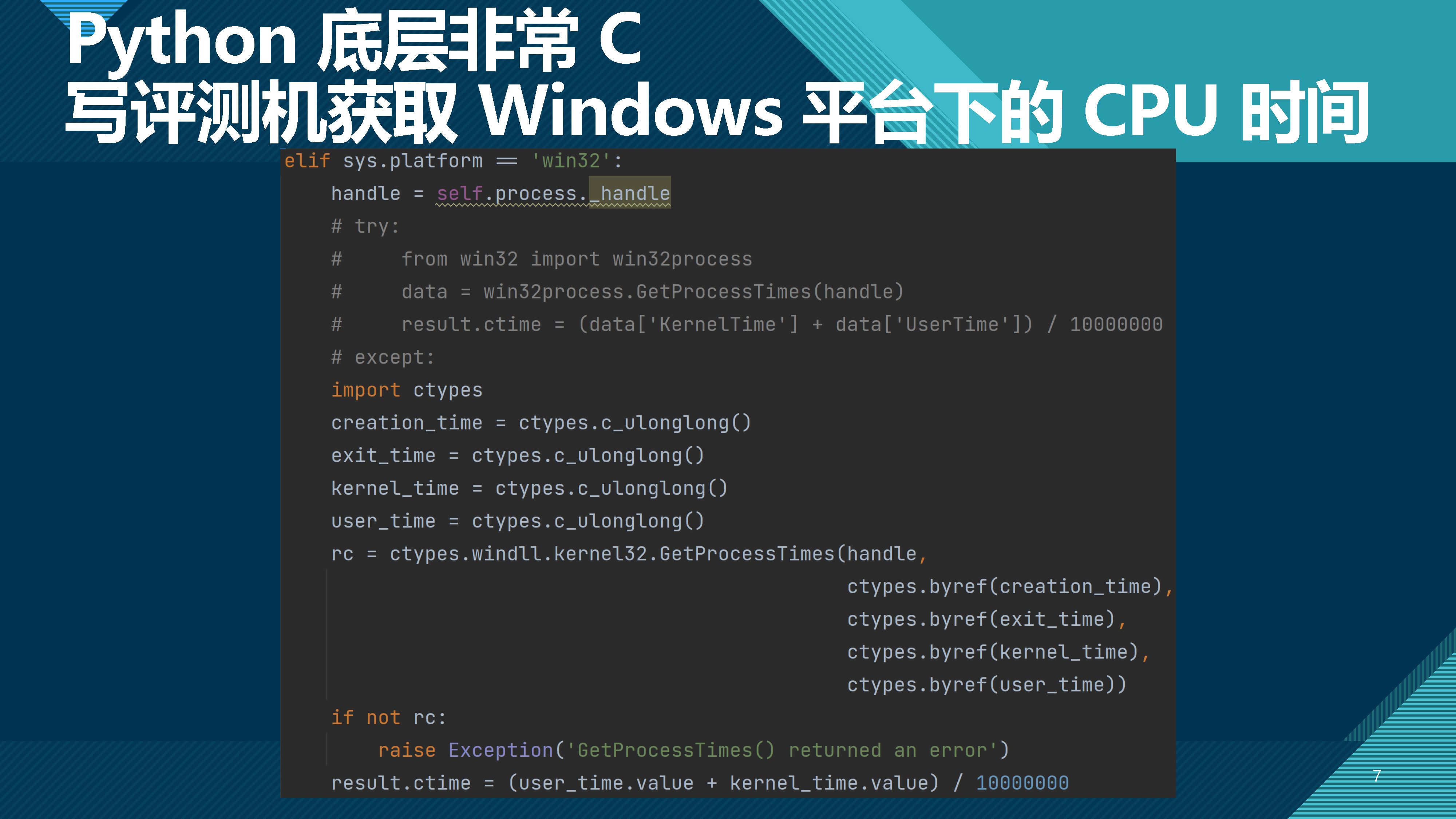
本单元的任务是在已有框架基础上,补齐关键部分,使程序能够解析 StarUML 软件用于记录 UML 数据的json格式文件,并实现一定的查询和查错功能。
json文件本来是树形结构,里面的各元素的父类都叫UmlElement。但已有框架把它们都拆散了,需要我们根据各实例的特征属性,重新建立相应的关系。
需要我们补齐的是一个叫UmlGeneralInteraction的类,程序运行时会创建这个类,并传入框架已解析出的所有UmlElement实例,它们可能是UmlClass、UmlOperation、UmlAttribute、UmlAssociation、UmlAssociationEnd、UmlGeneralization、UmlInterface、UmlInterfaceRealization、UmlParameter、UmlStateMachine、UmlStateLikeObject、UmlTransition、UmlOpaqueBehavior、UmlInteraction、UmlLifeline、UmlMessage、UmlRegion、UmlCollaboration、UmlEndpoint、UmlEvent。
为了还原树形关系,需要对UmlClass、UmlCollaboration、UmlFinalState、UmlInteraction、UmlInterface、UmlLifeline、UmlOperation、UmlPseudoState、UmlState、UmlStateMachine进行封装,但已有框架都通过final关键字禁止了继承它们,因此只能选择对他们进行包裹(wrap),得到相应的包裹类(wrapper class)。由于有些情况需要统一对UmlFinalState、UmlPseudoState和UmlState进行操作,但已有框架未建立相应层次关系,因此建立UmlStateLikeObject接口。由于有些情况需要高效便捷地保证查询的不重不漏,而已有框架不满足需求,故建立ClassAttributeInformation类。
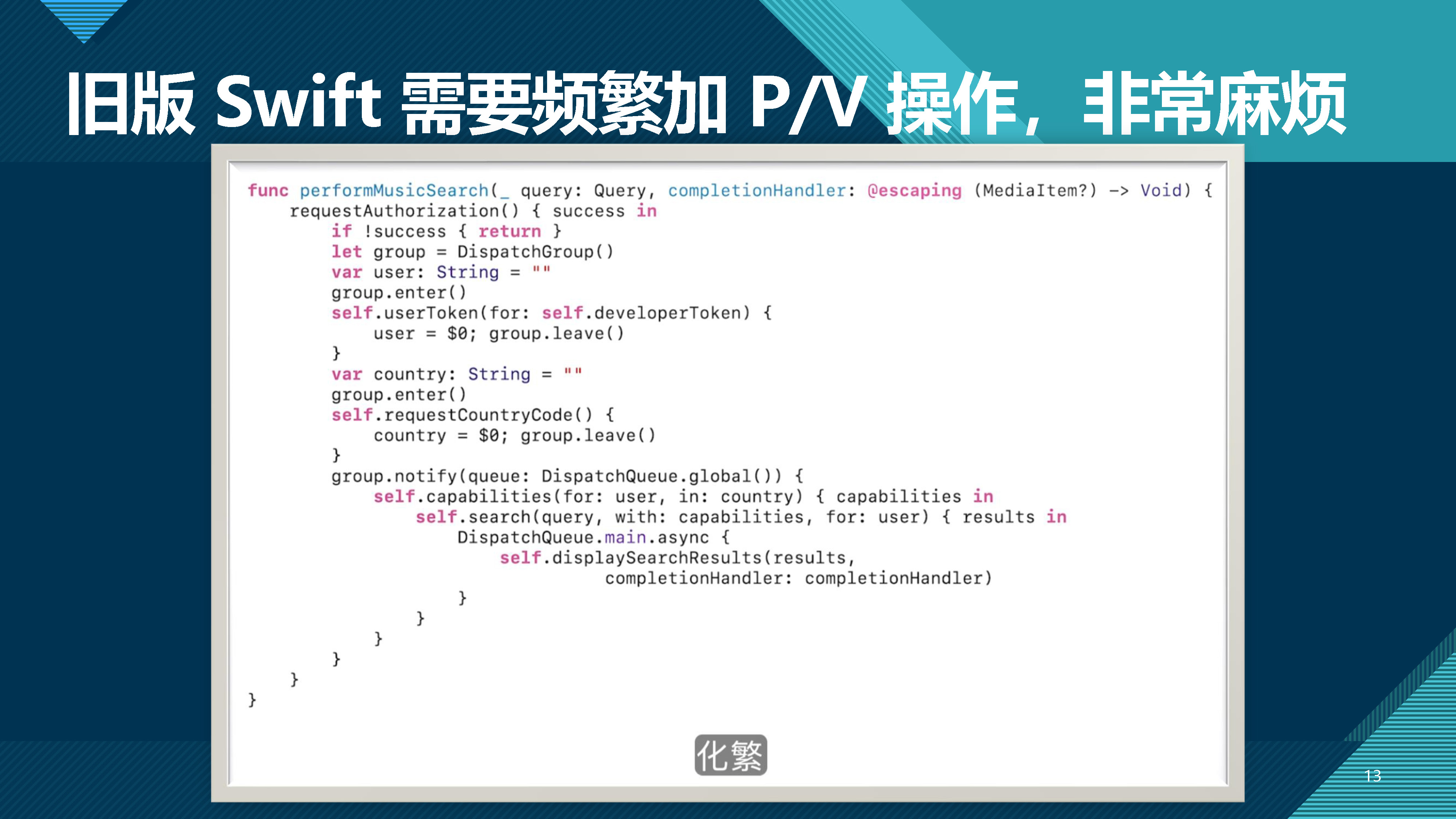
由于临近期末,为了写起来方便并减少重构的可能,并没有把查错部分、类图解析部分、状态图解析部分、时序图解析部分分到额外的相应类中,导致类行数面临超过 500 行的风险。由于课程组的 checkstyle 对超行扣分严重,而对import *形式的导入扣分较少,因此在本次需要大量导入的情况下,选择使用import *形式的导入来精简无意义的代码行。
最后,代码架构如图所示:
二、总结自己在四个单元中架构设计及OO方法理解的演进
本着高内聚、低耦合的思想,前三单元的架构设计请见前三单元博客。
在上本课程之前,我一直天真地以为,封装、继承、多态这些面向对象方法只是高级程序设计语言提供的一种控制程序复杂性的抽象语法机制,它可读性好,且利于复用和维护。
上完本课程,从层次化、多线程、规格化、模型化一路走来,我才意识到,合理识别、设计和构造对象,建立良好的架构才是面向对象的关键;至于语法,用 C 语言通过结构体、函数指针和枚举类型也能在底层手动实现这些高级语言的面向对象机制,用 Java 语言在糟糕的架构设计下也可以写出面向过程、可读性差、难以维护的程序。
同时,我感到面向对象有着浓浓的哲学色彩,感觉曾经的程序员们从面向过程的坎坷中逐渐总结出来的面向对象方法,就是从实践中把理论抽象出来了。面向对象的思维方式可能对今后认识世界和改造世界都会有独特的帮助。
三、总结自己在四个单元中测试理解与实践的演进
经过本课程的训练,我对测试的体会是——测试者应该与实现者不同。在很多情况下,我本地的自我测试无法测出隐蔽的问题,原因是我仍陷于已有的逻辑中,而问题往往出在题目理解错误等其它因素中,导致我构造不出导致程序出错的用例。通常,我只能对基本的正确性和性能手动或自动构造一些样例来测试,而这也通常能发现大多数问题。
掌握了在代码中使用assert确保前置条件、使用JUnit和 Python 的 subprocess等工具的方法。
四、总结自己的课程收获
此处先放上我研讨课上分享的前三单元收获与联想 PPT 截图,不当之处欢迎批评指正:

期末复习马原时,看到书上一句话,觉得挺贴切:

看到的表达式字符串是感性的具体,而合理识别、设计和构造对象就是抽象的过程,最终建立良好的架构就是到逻辑的具体。



大一时不会多线程,所以当时做的项目中图形界面和后台 I/O 是同一个线程,导致获取网络数据时 UI 界面未响应。遗憾的是本课程中没有涉及图形用户界面(GUI)的内容,而且编写和测试 GUI 程序有单独的架构方法,其实是很考验设计(架构与用户体验)和测试等工程能力的。




讲“里氏替换原则”的时候,老师特意用“正方形能否成为长方形的子类”来举例,这使我对继承有了更深刻的认识。期末复习马原时,看到书上一句话,觉得挺贴切:
任何现实存在的事物的矛盾都是共性和个性的有机统一,共性寓于个性之中,没有离开个性的共性,也没有离开共性的个性。
父类属于“共性”,子类属于“个性”。内存中,父类与子类对象首地址相同,父类对象在子类里,因此需要父类的地方用子类不应导致行为的变化。若对正方形对象调整长的长度,宽的长度也会相应发生变化,这种变化在需要长方形对象的地方是不正确的,因此正方形不能成为长方形的子类。
其它内容:





只要函数带有副作用,就有安全隐患。比如这种随机数生成函数,给出固定的输入,输出不一样,一定是有副作用!

果然,有个全局变量!这显然是线程不安全的。


五、立足于自己的体会给课程提三个具体改进建议
1. 在第一单元前用通俗的语言讲解“递归下降”
大家都说第一单元门槛最高,主要就在解析字符串上。像这样简单讲讲“递归下降”就好,费不了多少时间,但能提高大部分同学的效率。
2. 上机时给出评测结果或上机后给出答案
不知道 6 系的课程组们是如何考虑的,CO、OO、OS 所有上机的题目都不给答案,也不讲。大学到底是为了让大部分同学都更高效地落实学习任务还是为了区分大家的水平进行考试呢?不给答案也不讲,我们不知道理解得对不对,学到的东西也会大打折扣。
3. 推迟中测提交截止时间,至少临近期末没有互测的第四单元可以推迟
周三晚上发布作业,周四周五都是满课,周六写一天发现糟了要重构,周日连晚饭的时间都省了拼命写,赌一把看看晚上十点前能不能写出来,但很容易发现过了十点才修完 bug。这样明明完成了作业,却得不到分。或者一旦某周发烧了,那基本那周的作业也凉了。没错,以上两种情况我都发生过。
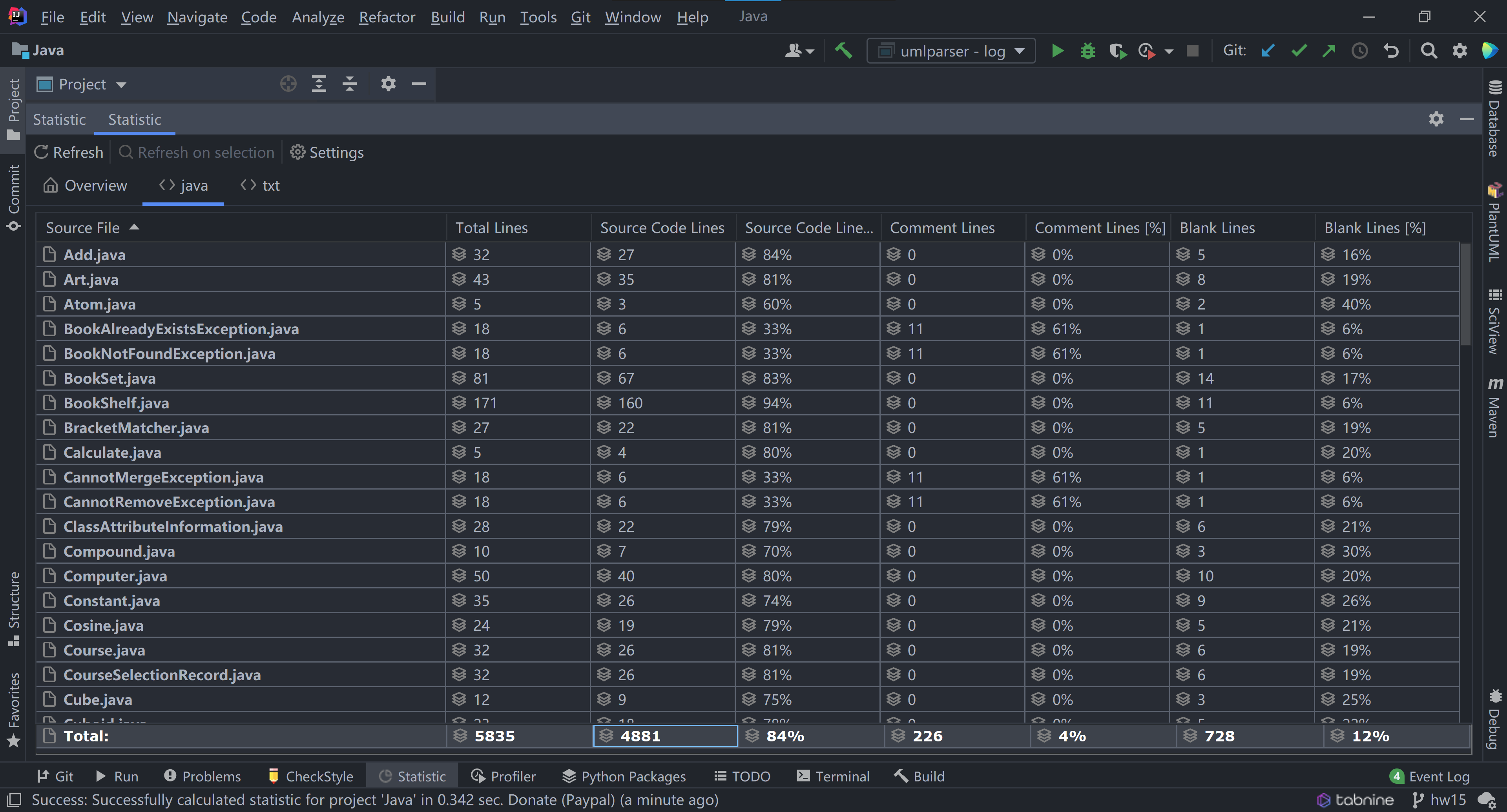
最后感谢 OO 课程组的全体老师和助教,让我在这充实的一学期不算重构写了至少近 5000 行代码,学到了很多!
衷心希望 OO 课越来越好!
Credit:本文中使用的部分资料均可通过公共知识渠道获得,在此向原作者表示感谢。

