

设计高效sql一般经验谈
1不用在sql语句使用系统默认的保留关键字
2尽量用exists 和 not exists 代替 in 和 not in
这条在sql2005之后,在索引一样,统计信息一样的情况下,exists ,in效果是一样的。
以AdventureWorks数据库为例,查询在HumanResources.EmployeeAddress有地址的Employee信息,
用in 语句如下:
SET STATISTICS IO ON
SELECT * FROM HumanResources.Employee
WHERE EmployeeID IN (SELECT EmployeeID FROM HumanResources.EmployeeAddress ea)
SET STATISTICS IO OFF
执行后,消息如下:
(290 行受影响)
表'EmployeeAddress'。扫描计数1,逻辑读取4 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
表'Employee'。扫描计数1,逻辑读取9 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
执行计划如图
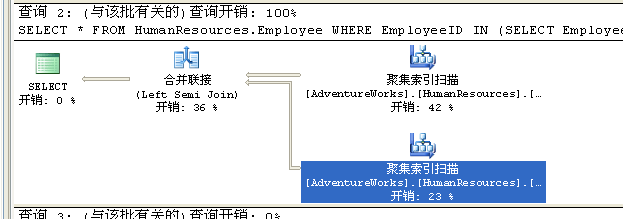
用exists ,语句如下,
SET STATISTICS IO ON
SELECT * FROM HumanResources.Employee
WHERE EXISTS(SELECT EmployeeID FROM HumanResources.EmployeeAddress ea
WHERE
HumanResources.Employee.EmployeeID=ea.EmployeeID)
SET STATISTICS IO OFF
执行后,消息如下:
(290 行受影响)
表'EmployeeAddress'。扫描计数1,逻辑读取4 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
表'Employee'。扫描计数1,逻辑读取9 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
执行计划如图:

3尽量不用select * from …..,而要写字段名 select field1,field2,…
这条没什么好说的,主要是按需查询,不要返回不必要的列和行。
4在sql 查询中应尽量使用索引列来加快查询速度
5任何在Order by 语句的非索引项或者有计算表达式都将降低查询速度
6任何在where子句中使用is null 或 is not null 的语句不允许使用索引,效率较低
7通配符%在词首时,系统不使用索引,当通配符出现在其他位置时,优化器就能利用索引
8在海量数据的sql查询语句中尽量少用格式转换
9任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等,查询时要尽可能将操作移至等号右边
10 In 、or子句常会使索引失效
11通常情况下,连接比子查询效率要高


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述
2007-10-28 CSS样式的简单使用
2007-10-28 css+js简单应用