《揭秘Java虚拟机:JVM设计原理与实现》学习笔记-第五章到第十章
第五章 常量池解析
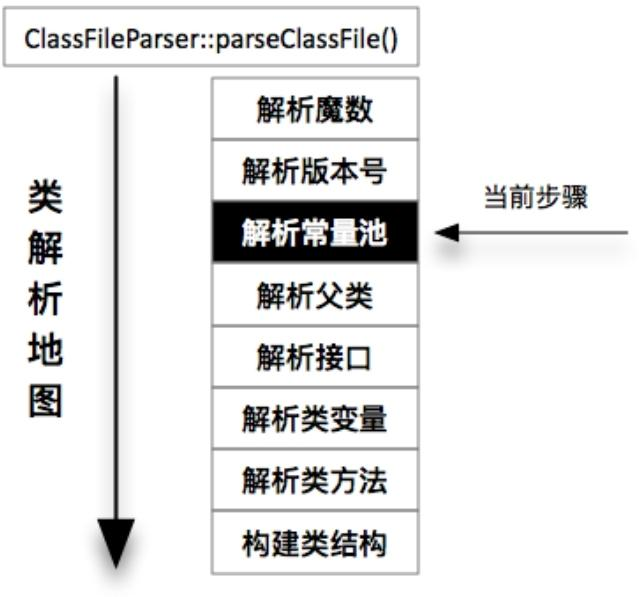
类解析地图
知识点1
- JVM对常量池的解析主要分为两步:第一步是为常量池分配内存,第二步是解析常量池信息
第六章

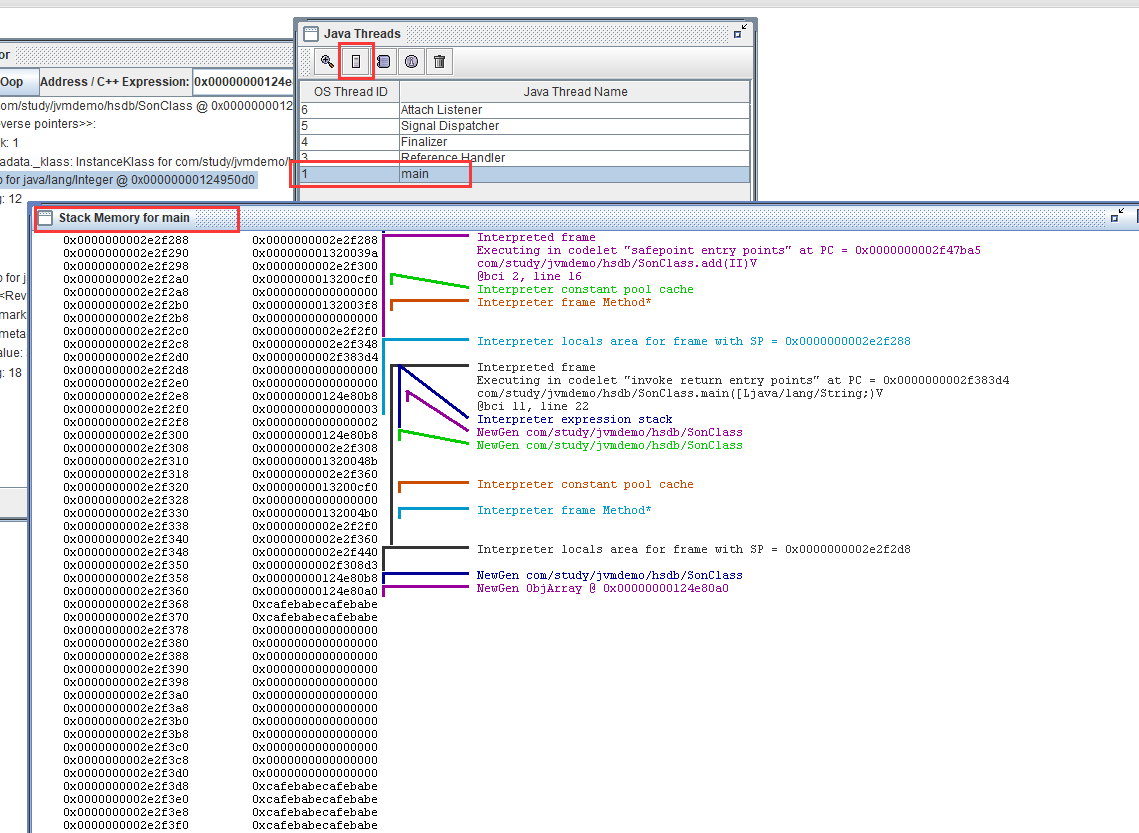
hsdb看内存
- PS E:\Study\Java\jvm\jvm-demo\out\production\classes> jdb -XX:+UseSerialGC -Xmx10m -XX:-UseCompressedOops
- 正在初始化jdb...
- > stop in com.study.jvmdemo.hsdb.SonClass.add
- 正在延迟断点com.study.jvmdemo.hsdb.SonClass.add。
- 将在加载类后设置。
- > run com.study.jvmdemo.hsdb.SonClass
- 运行 com.study.jvmdemo.hsdb.SonClass
- 设置未捕获的java.lang.Throwable
- 设置延迟的未捕获的java.lang.Throwable
- >
- VM 已启动: 设置延迟的断点com.study.jvmdemo.hsdb.SonClass.add
- 断点命中: "线程=main", com.study.jvmdemo.hsdb.SonClass.add(), 行=15 bci=0
- main[1] next
- >
- 已完成的步骤: "线程=main", com.study.jvmdemo.hsdb.SonClass.add(), 行=16 bci=2
- main[1]
查看pid
- PS C:\Users\Administrator> jps
- 10704 Jps
- 17504 TTY
- 9968 HSDB
- 17092
- 3076 KotlinCompileDaemon
- 8472 SonClass
- PS C:\Users\Administrator>
另开一个命令行
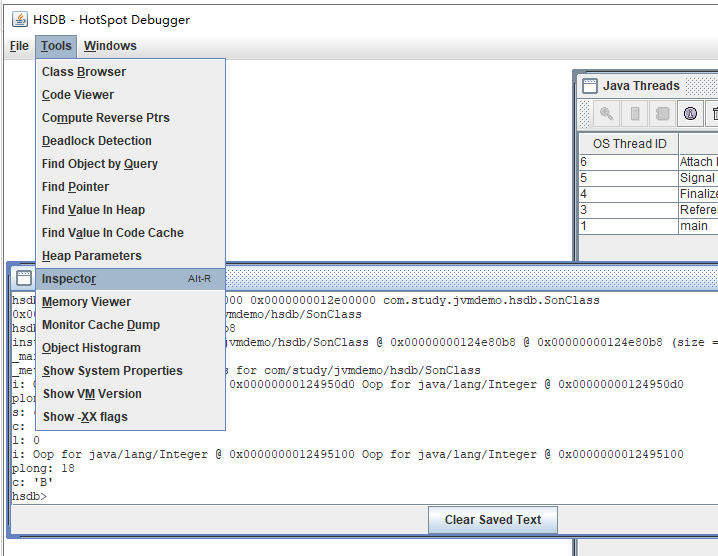
- PS D:\DevTool\Java\jdk1.8.0_191\lib> java -cp sa-jdi.jar sun.jvm.hotspot.HSDB
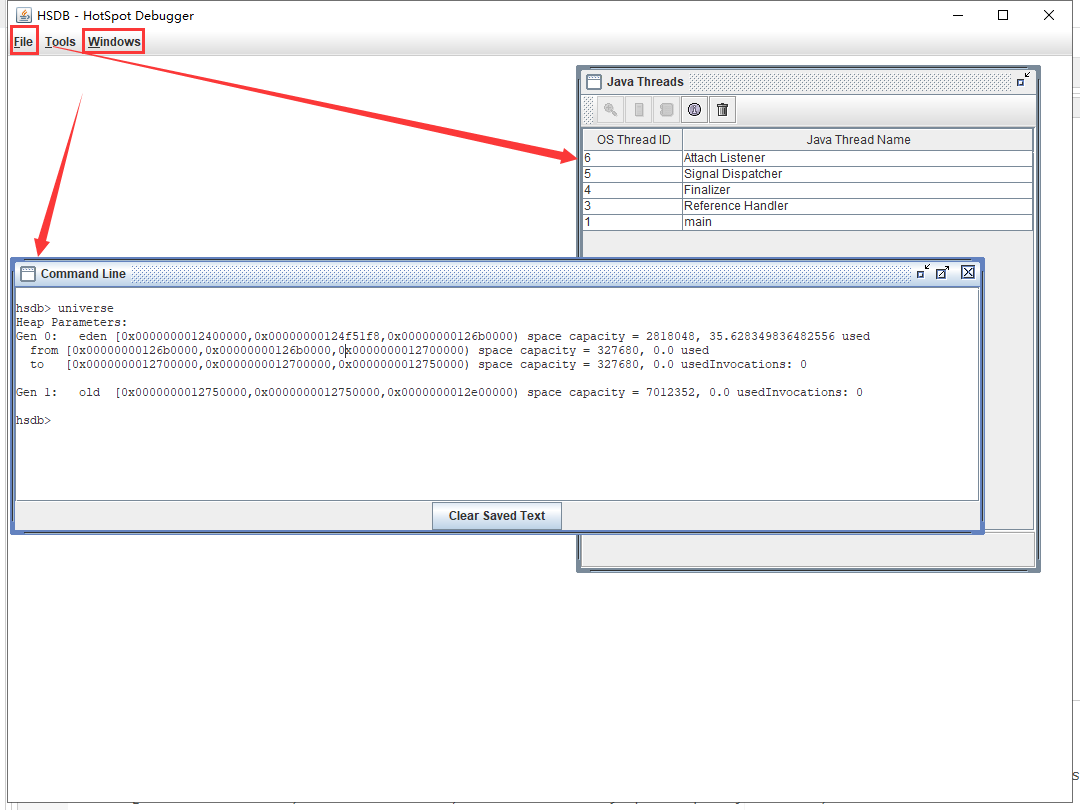
- hsdb> universe
- Heap Parameters:
- Gen 0: eden [0x0000000012400000,0x00000000124f51f8,0x00000000126b0000) space capacity = 2818048, 35.628349836482556 used
- from [0x00000000126b0000,0x00000000126b0000,0x0000000012700000) space capacity = 327680, 0.0 used
- to [0x0000000012700000,0x0000000012700000,0x0000000012750000) space capacity = 327680, 0.0 usedInvocations: 0
- Gen 1: old [0x0000000012750000,0x0000000012750000,0x0000000012e00000) space capacity = 7012352, 0.0 usedInvocations: 0
- hsdb> scanoops 0x0000000012400000 0x0000000012e00000 SonClass
- No such type.
- hsdb> scanoops 0x0000000012400000 0x0000000012e00000 com.study.jvmdemo.hsdb.SonClass
- 0x00000000124e80b8 com/study/jvmdemo/hsdb/SonClass
- hsdb> inspect 0x00000000124e80b8
- instance of Oop for com/study/jvmdemo/hsdb/SonClass @ 0x00000000124e80b8 @ 0x00000000124e80b8 (size = 72)
- _mark: 1
- _metadata._klass: InstanceKlass for com/study/jvmdemo/hsdb/SonClass
- i: Oop for java/lang/Integer @ 0x00000000124950d0 Oop for java/lang/Integer @ 0x00000000124950d0
- plong: 12
- s: 6
- c: 'A'
- l: 0
- i: Oop for java/lang/Integer @ 0x0000000012495100 Oop for java/lang/Integer @ 0x0000000012495100
- plong: 18
- c: 'B'
- hsdb>
也可用图形化工具查看

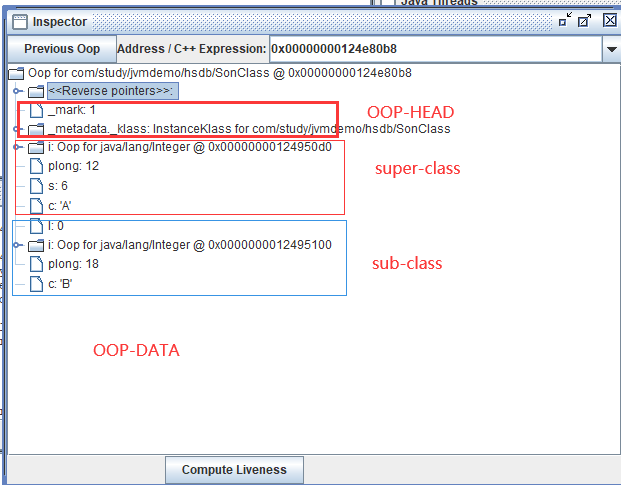
知识点
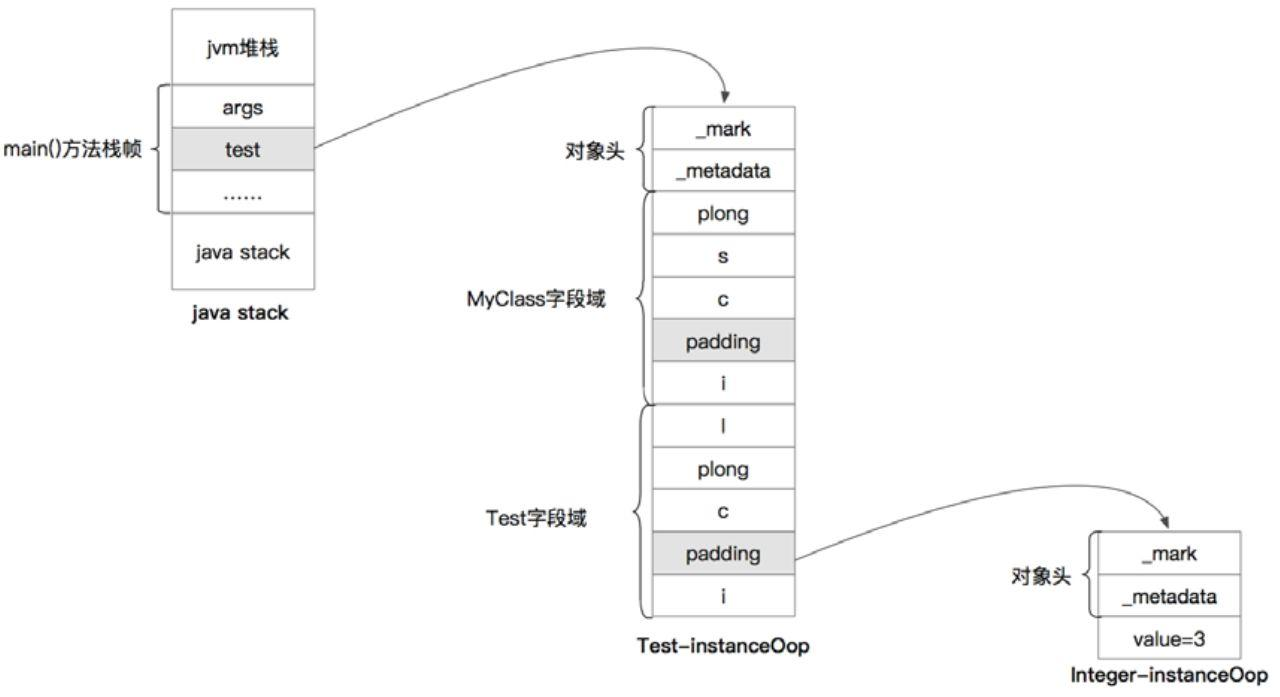
如果子类定中义了与父类同名的字段,并且当父类中的字段访问权限是private时,子类不会覆盖父类的字段,JVM会在内存中同时为父类和子类的该相同字段各分配一段内存空间。
当子类中定义了与父类相同名称、相同类型的字段时,无论父类中字段的访问权限是什么,也无论父类字段是否被final修饰,子类都不会覆盖父类字段。

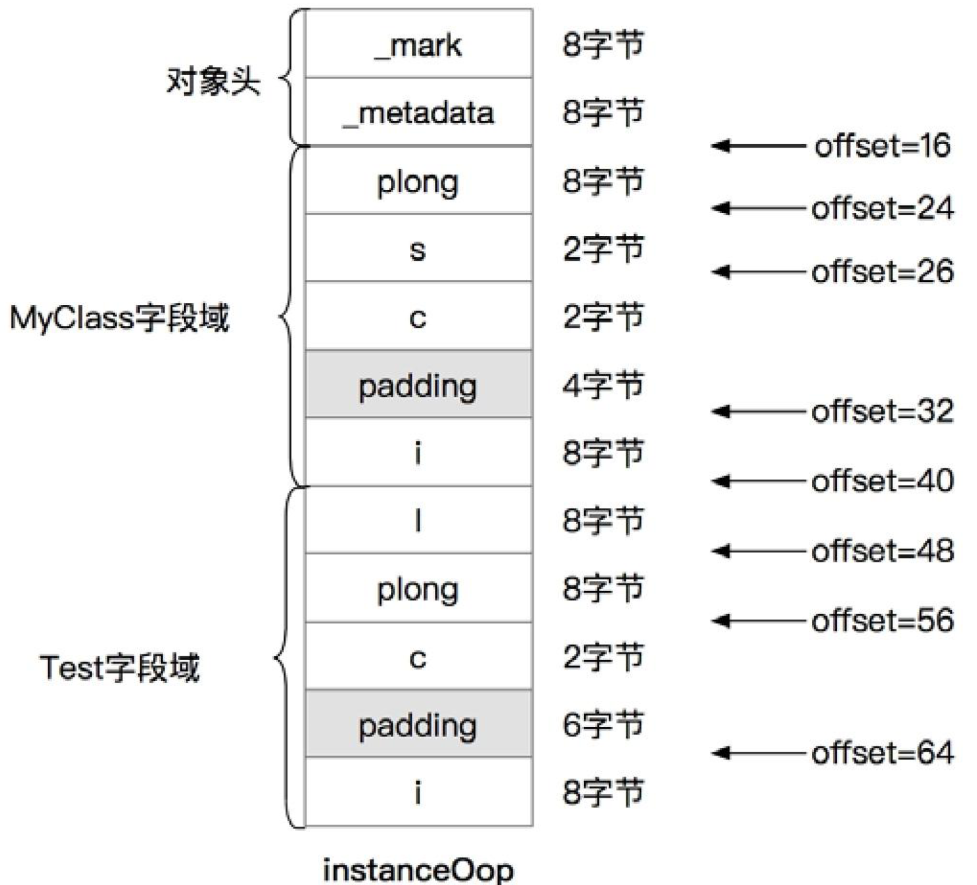
Test类所对应的instanceOop的内存布局(64位平台,关闭指针压缩选项)
2次对齐padding
知识点
由于这个位置是第一个对Test实例对象地址的引用位置,因此该位置一定属于main()主函数的局部变量表区域。由于main()函数有一个args入参,因此该位置的下面那个位置的数据类型是ObjArray,这正是Java的数组类型在JVM内部的对象表现形式,由此更加确定图6.32中方框所框住的位置一定属于main()函数的栈帧,而这一点也能够反向证明test这个局部变量的引用位于其所在方法的栈帧之中。
知识点
HotSpot解析Java类非静态字段和分配堆内存空间的主要逻辑总结为如下几步:
(1)解析常量池,统计Java类中非静态字段的总数量,按照5大类型(oops、longs/doubles、ints、 shorts/chars、 bytes)分别统计。
(2)计算Java类字段的起始偏移量,起始偏移位置从父类继承的字段域的末尾开始。
(3)按照分配策略,计算5大类型中的每一个类型的起始偏移量。
(4)以5大类型各个类型的起始偏移量为基准,计算每一个大类型下各个具体字段的偏移量。
(5)计算Java类在堆内存中所需要的内存空间。
经过上面5步,HotSpot便能确定一个Java类所需要的堆内存空间。当全部解析完Java类之后,Java类的全部字段信息及其偏移量将会保存到HotSpot所构建出来的instanceKlass中,至此,一个Java类的字段结构信息便全部解析完成。当Java程序中使用new关键字创建Java类的实例对象时,HotSpot便会从instanceKlass中读取Java类所需要的堆内存大小并分配对应的内存空间。
第七章
知识点
函数内部会定义局部变量,这些变量最终要在内存中占用一定的内存空间。由于这些变量都位于同一个函数中,因此一个很自然的想法就是将这些变量合起来当作一个整体,将其内存空间分配在一起,这样有利于变量空间的整体内存申请和释放。所以抛开“栈帧”本身的特定含义,完全可以将“栈帧”看作一个“容器”,这个容器中存放的是函数内部的局部变量。事实上,几乎所有编程语言的函数所对应的堆栈空间的确就是个容器,在容器内部会按顺序存放函数内的局部变量。
在程序运行的过程中,一个函数会有一个栈帧,多个函数的栈帧连起来,就变成堆栈。在《算法与数据结构》里,“堆栈”是一种数据结构,也是一种容器
栈帧是个容器,堆栈是多个栈帧连成一片后形成的大容器,是容器的容器。
对于现代成熟的计算机和各种编程语言而言,都不需要专门计算某个函数的堆栈起始地址,每一个函数的栈底地址直接等同于其调用者函数的栈顶

第八章 类方法解析
- 由此可见,当为java类定义多个构造函数时,编译器会将类成员变量的初始化逻辑的字节码指令编排到每一个构造函数的字节码指令中。而道理其实很简单,因为不管是通过new Test()去实例化Test类,还是通过 new Test(10)去实例化Test类,所实例化出的Test类的成员变量i都应该具有初始值3,所以编译器必须将类成员变量的初始化逻辑原封不动地复制到每一个构造函数里去。
- 全方位分析了Java类的<init>()方法(即构造函数)的生成规则,这些规则可以总结为如下几点:◎ 无论一个Java类有无定义构造函数,编译器都会自动生成一个默认的构造函数<init>()。可以使用javap命令或者HSDB来验证。◎ <init>()方法主要完成Java类的成员变量的初始化逻辑,同时会执行Java类中被{}所包裹的块逻辑。如果Java类中的成员变量没有被赋初值,则在<init>()方法中不会对其进行初始化。◎ 如果为Java类显式定义了多个构造函数,无论是否是默认的无参构造函数,Java编译器都会将Java类成员变量的初始化逻辑嵌入到每一个构造函数中,并且嵌入的位置在各构造函数自身逻辑之前。◎ 当 Java类显式继承了父类时,则Java编译器会让子类的各个构造函数调用父类的默认构造函数<init>(),从而在子类实例化时完成父类成员变量的初始化逻辑。◎ 当父类中定义了多个构造函数时,子类构造函数会调用父类默认构造函数。◎ 子类构造函数对父类默认构造函数的调用顺序,位于子类各个构造函数自身逻辑之前。
- 一个类的各个构造函数的处理逻辑是,调用父类默认构造函数,完成类自身成员变量的初始化逻辑和被{}包裹的块逻辑,调用各构造函数自身逻辑。
- 而Java编译器除了会自动生成<init>()方法,还会自动生成<clinit>()方法。前文讲过,当Java类中存在static字段,或者被static {}包裹的代码逻辑时,就会自动生成<clinit>()方法。
- <clinit>()方法不具有继承性
- 因为<clinit>()方法是在类加载过程中被调用,而父类与子类是分别加载的,当父类加载完之后,父类中的static成员变量初始化和被static{}所包裹的块逻辑已经执行完成,没必要在子类加载时再执行一次,所以子类只需完成自身static成员变量初始化以及被static {}所包裹的块逻辑即可。
- <clinit>()方法在Java类第一次被Jvm加载时调用,而<init>()方法则在Java类被实例化时调用。由于类的加载一定位于类实例化之前,因此<clinit>()方法一定在<init>()方法之前被触发。并且每一次实例化Java类都会调用<init>()方法,而<clinit>()仅在类第一次加载时被调用,以后再加载时不会重复调用。

- father.static{}...i=30
- son.static{}...a=155
- father.{}...plong=13
- father.constructor()...plong=67
- son.{}...i=2
- son.{}...a=155
- 根据该输出顺序可知,JVM先加载了父类MyClass,调用了父类的static {}块逻辑,因此首先输出“father.static{}...i=30”。接着又加载了子类Test,因此调用了子类的{}块逻辑,因此接着输出“son.static{}...a=155”。接着实例化Test类,前文总结过,类的构造函数的执行顺序是“调用父类的默认构造函数->执行类成员变量初始化逻辑和被{}包裹的块逻辑->执行构造函数自身逻辑”
- 由于Test类继承了MyClass类,因此Test的构造函数先执行父类的构造函数。而父类MyClass中包含被{}包裹的块逻辑,因此父类构造函数先执行块逻辑,再执行自身逻辑,所以接下来的输出便是按照这种顺序执行的结果。
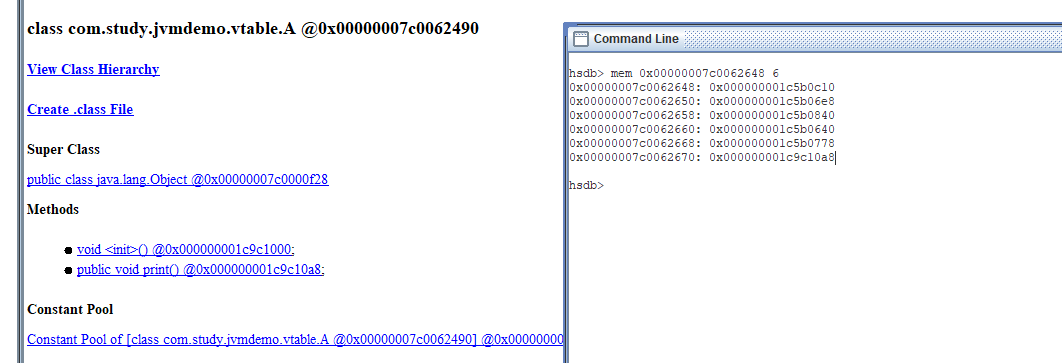
- 当HotSpot在运行期加载类A时,其vtable中将会有一个指针元素指向其void print()方法在HotSpot内部的内存首地址。当HotSpot加载类B时,首先类B完全继承其父类A的vtable,因此类B便也有一个vtable,并且vtable里有一个指针指向类A的print()方法的内存地址。HotSpot遍历类B的所有方法,并发现print()方法是public的,并且没有被static、final修饰,于是HotSpot去搜索其父类中名称相同、签名也相同的方法(即上文所讲的klassVtable. cpp::needs_new_vtable_entry()函数),结果发现父类中存在一个完全一样的方法,于是HotSpot就会将类B的vtable中原本指向类A的print()方法的内存地址的指针值修改成指向类B自己的print()方法所在的内存地址。
- 这是因为newFun()是public的,并且没有static和final修饰,因此这个方法是可以被继承的,并且是可以被子类重写的。而编译器在编译期间并不知道类B有没有子类,因此这里只能使用invokevirtual指令去调用newFun()方法,从而使newFun()方法支持在运行期进行动态绑定。
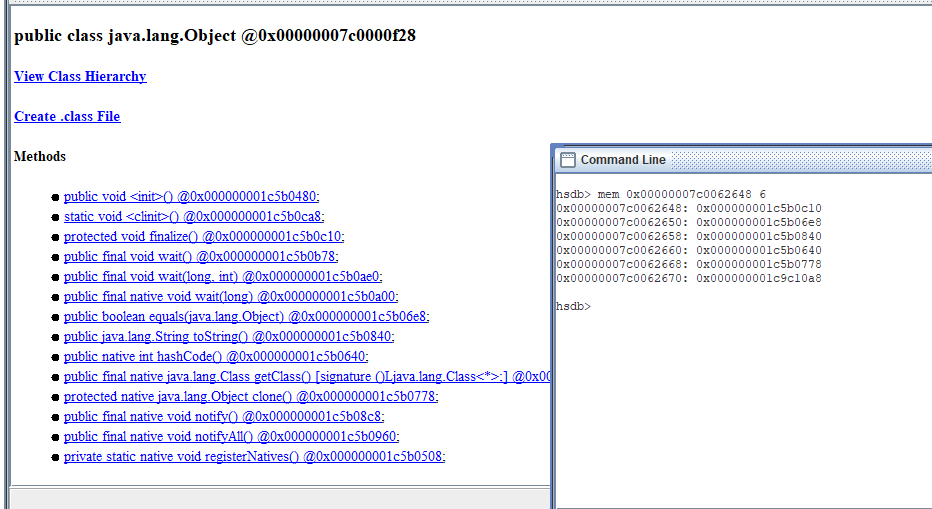
vtable首地址:
0x00000007c0062490 + 0x1b8 = 0x00000007c0062648
- 关于这个典故各位道友可以自行在网络上搜索,本书不多讲了。总之,JVM借鉴了法律上的这一充满人道主义关怀的原则,将其运用于接口类的方法实现中。如果一个Java类无法提供接口类方法的实现,那么编译器将会为其提供一个方法实现,这个方法就叫作miranda方法。这如同法律审判一样,如果一个犯罪嫌疑人没有能力请一名律师辩护,那么法庭将为其提供一个。从这个角度来重新审视程序,会发现程序设计原来和生活法则都是相通的,创意来源于生活,设计来源于生活,一切都离不开生活。
- 前文对vtable进行了比较全面的研究和验证,这里再次总结下其特点:◎ vtable分配在instanceKlassOop对象实例的内存末尾。◎ 所谓vtable,可以看作是一个数组,数组中的每一项成员元素都是一个指针,指针指向Java方法在JVM内部所对应的method实例对象的内存首地址。◎ vtable是Java实现面向对象的多态性的机制,如果一个Java方法可以被继承和重写,则最终通过invokevirtual字节码指令完成Java方法的动态绑定和分发。事实上,很多面向对象的语言都基于vtable机制去实现多态性,例如C++。◎ Java子类会继承父类的vtable。◎ Java中所有类都继承自java.lang.Object,java.lang.Object中有5个虚方法(可被继承和重写):void finalize()boolean equals(Object)String toString()
- int hashCode()Object clone()因此,如果一个Java类中不声明任何方法,则其vtalbe的长度默认为5。◎ Java类中不是每一个Java方法的内存地址都会保存到vtable表中。只有当Java子类中声明的Java方法是public或者protected的,且没有final、static修饰,并且Java子类中的方法并非对父类方法的重写时,JVM才会在vtable表中为该方法增加一个引用。◎ 如果Java子类某个方法重写了父类方法,则子类的vtable中原本对父类方法的指针引用会被替换为对子类的方法引用。
-
vtable
- Java中实现多态是通过vtable这个机制
- 根据前文所讲的vtable的构成原理,类Animal的vtable的长度应该为6,除了所继承的java.lang.Object中的5个虚方法(即可被重写的方法)外,其自身仅包含1个虚方法。并且其vtable中的第6个指针元素指向say()方法在JVM内部所对应的method实例对象的内存地址。同理,子类Dog的vtable的长度也应该等于6,因为前文讲过,子类会完全继承父类的vtable,并且如果子类重写了父类的方法,则JVM会将子类vtable中原本指向父类方法的指针成员修改成重新指向子类的方法。

第九章 执行引擎
物理CPU执行指令的流程是这样的:
(1)取指。CPU的控制器从内存读取一条指令并放入指令寄存器。物理机器指令一般由操作码和操作数组成,当然并不是所有的操作码都会有操作数。例如mov ax, 1这条机器指令,其中mov ax就是操作码,而1就是操作数,在Intel处理器上,这条指令所对应的十六进制数是0xB8 01。(2)译码。指令寄存器中的指令经过译码,确定该指令应进行何种操作(由操作码决定),操作数在哪里(由操作数决定)。(3)执行。分两个阶段,“取操作数”和“进行运算”。(4)取下一条指令。修改指令计数器(亦称程序计数器),计算下一条指令的地址,并重新进入取指、译码和执行的循环。
物理CPU执行指令的流程是这样的:
(1)取指。CPU的控制器从内存读取一条指令并放入指令寄存器。物理机器指令一般由操作码和操作数组成,当然并不是所有的操作码都会有操作数。例如mov ax, 1这条机器指令,其中mov ax就是操作码,而1就是操作数,在Intel处理器上,这条指令所对应的十六进制数是0xB8 01。(2)译码。指令寄存器中的指令经过译码,确定该指令应进行何种操作(由操作码决定),操作数在哪里(由操作数决定)。(3)执行。分两个阶段,“取操作数”和“进行运算”。(4)取下一条指令。修改指令计数器(亦称程序计数器),计算下一条指令的地址,并重新进入取指、译码和执行的循环

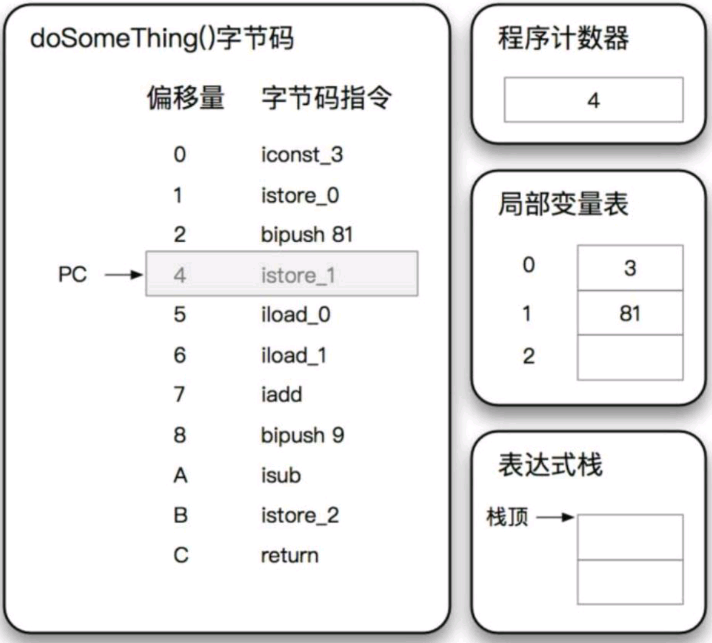
知识点
1.左侧分成两列,第一列是当前字节码相对于基址的偏移量,第二列则是具体的字节码。其中第4个字节码指令istore_1的偏移量是4,而不是3,这是因为第3条字节码指令bipush 81占用了2字节的宽度,bipush占用1个,立即数81也占用1个。同理,第9条字节码指令isub的偏移量是10,而不是9,也是因为其上一条指令bipush 9占用了2字节宽度。
2.iconst_3指令的作用是将操作数3推送至栈顶(表达式栈的栈顶)。执行之后的内存布局如图9.17所示。当执行完当前字节码指令时,程序计数器指向当前字节码指令所在的位置
3.istore指令将表达式栈栈顶的数据弹出来,并传送至局部变量表中指定的位置,该位置由紧跟在istore指令后面的数字指定。当istore_0指令执行之后,数字3从表达式栈栈顶被弹出,并保存到局部变量表的第0个槽位(slot),此时程序计数器的值更新为1,堆栈内存布局如图9.18所示。

第十章 类的生命周期
类的生命周期
类加载的内部实现及触发
类的初始化
类加载器的本质
类实例分配
类生命周期
加载 -> 链接(验证 -> 准备 -> 解析) -> 初始化 -> 使用 -> 卸载
类加载阶段其实就是为了这一目标而来——在JVM内部创建一个与Java类结构对等的数据对象。
一个Java类加载的核心流程
(1)读取魔数与版本号。
(2)解析常量池,parse_constant_pool()。
(3)解析字段信息,parse_fields()。
(4)解析方法,parse_methods()。
(5)创建与Java类对等的内部对象instanceKlass,new_instanceKlass()。
(6)创建Java镜像类,create_mirror()。
Java类加载的触发条件比较多,其中比较特殊的便是Java程序中包含main()主函数的类——这种类一般也被称作Java程序的主类。Java主类的加载由JVM自动触发——JVM执行完自身的若干初始化逻辑之后,第一个加载的便是Java程序的主类。
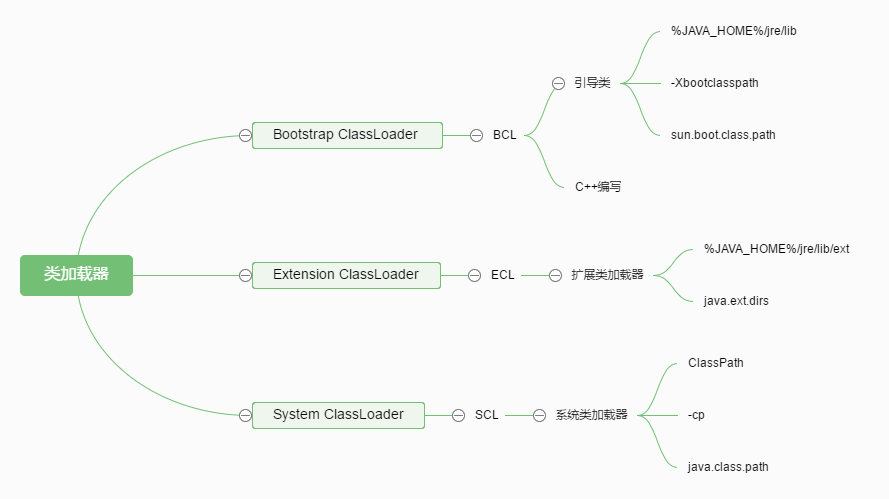
JVM体系中加载器的继承关系
类加载器
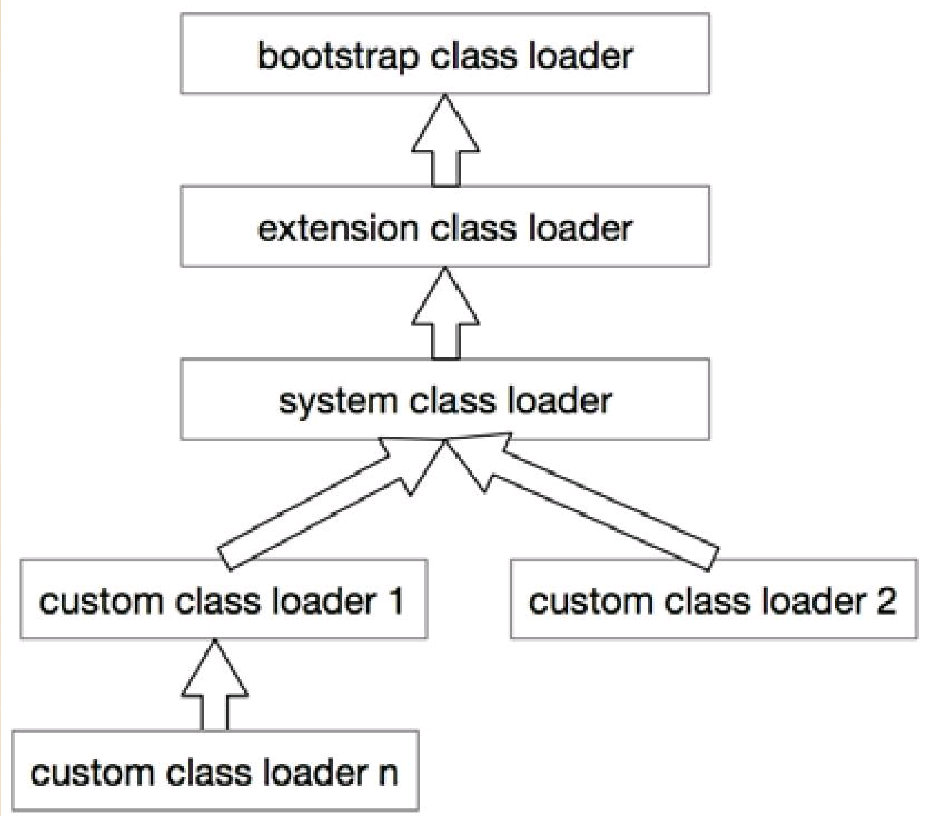
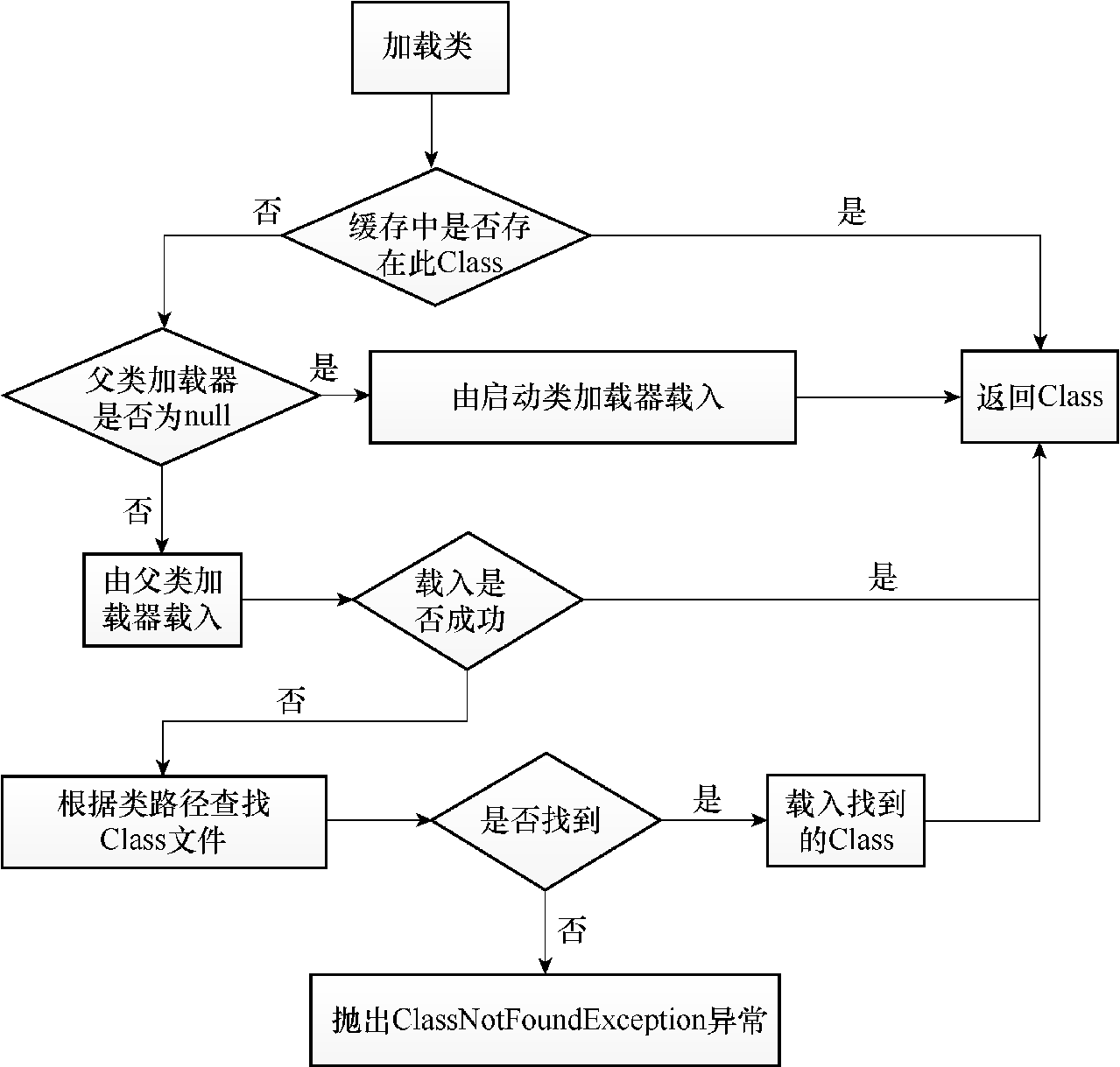
双亲委派机制
- protected Class<?> loadClass(String name, boolean resolve)
- throws ClassNotFoundException
- {
- synchronized (getClassLoadingLock(name)) {
- // First, check if the class has already been loaded
- Class<?> c = findLoadedClass(name);
- if (c == null) {
- long t0 = System.nanoTime();
- try {
- if (parent != null) {
- c = parent.loadClass(name, false);
- } else {
- c = findBootstrapClassOrNull(name);
- }
- } catch (ClassNotFoundException e) {
- // ClassNotFoundException thrown if class not found
- // from the non-null parent class loader
- }
- if (c == null) {
- // If still not found, then invoke findClass in order
- // to find the class.
- long t1 = System.nanoTime();
- c = findClass(name);
- // this is the defining class loader; record the stats
- sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
- sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
- sun.misc.PerfCounter.getFindClasses().increment();
- }
- }
- if (resolve) {
- resolveClass(c);
- }
- return c;
- }
- }
(1)先在当前加载器的缓存中查找有无目标类,如果有,直接返回。
(2)判断当前加载器的父加载器是否为空,如果不为空,则调用parent.loadClass(name, false)接口进行加载。
(3)反之,如果当前加载器的父类加载器为空,则调用findBootstrapClassOrNull(name)接口,让引导类加载器进行加载。
(4)如果通过以上3条路径都没能成功加载,则调用findClass(name)接口进行加载。该接口最终会调用java.lang.ClassLoader接口的define*系列的native接口加载目标Java类。
保证核心类库一定是由引导类加载器进行加载,而不会被多种加载器加载
类分配
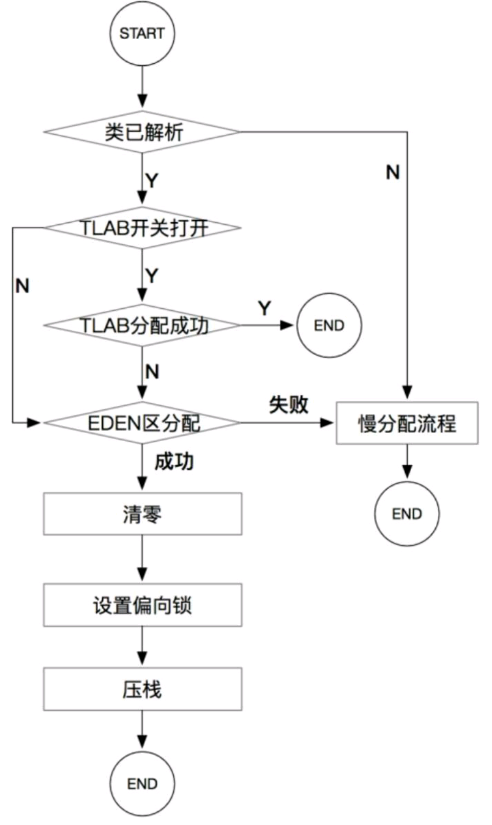
逻辑从宏观上分为两部分:一部分是快速分配,一部分则是慢分配。如果所要new的Java类型尚未被解析过(即使已经被加载也不算),则直接进入慢分配,这便是前文所讲述的JVM延迟加载的基础所在。快速分配的流程比较复杂,而慢分配则直接调用InterpreterRuntime::_new()接口。
为了尽可能地加快内存分配速度,并减少并发操作带来的性能损失,JVM在分配内存时,总是优先使用快速分配策略,当快速分配失败时,才会启用慢分配策略,
(1)若Java类尚未被解析,则直接进入慢分配,不会使用快速分配策略。
(2)快速分配。如果没有开启栈上分配或不符合条件则会进行TLAB分配。
(3)快速分配。如果TLAB分配不成功,则尝试在eden区分配。
(4)如果eden区分配失败,则会进入慢分配流程。
(5)如果对象满足了直接进入老年代的条件,那就直接分配在老年代。
(6)快速分配。对于热点代码,如果开启逃逸分析,JVM则会执行栈上分配或标量替换等优化方案。
所谓逃逸,是指一个在方法内部被创建的对象不仅在方法内部被引用,还在方法外部被其他变量引用,这带来的后果是:在该方法执行完毕之后,该方法中创建的对象无法被GC回收,因为对象在方法外部还被引用着
快速分配实现机制
完成new指令后,之所以不立即将对象内存地址写入局部变量表中,是因为接下来就会调用方法,而JVM每次调用Java方法之前,都必须要将入参压入操作数栈栈顶。如果执行完new指令之后就立即将对象内存地址写入局部变量表中,那么接下来调用类的构造函数时就需要再次将对象内存地址从局部变量表中读取出来并压入操作数栈栈顶,这样多了几次内存读写,所以JVM干脆就在执行完new指令后,直接将内存地址压入栈顶,提升性能。
快速分配的策略图
总结
当JVM启动时,会加载核心的几个类库,例如Object、Long及Integer等。剩下的Java类,无论是JDK类库中的,还是Java应用程序中的,或者是Java应用程序所依赖的第三方jar包,都采用“延迟加载”机制。在这种机制下,只有当Java真正需要使用某个类时,JVM才会真正加载,否则,即便在程序中显式import了某个类,JVM也不会加载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号