
kafka 基础知识梳理及集群环境部署记录
一、kafka基础介绍
0. kakfa概述
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica)开源消息系统,由Scala写成,是由Apache软件基金会开发的一个开源消息系统项目,该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。kafka基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性
kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一,Kafka可以实现高效文件存储,实际应用效果极好。
1. kafka名词解释(架构的四个部分)

- Topic:在Kafka中,使用一个类别属性来划分数据的所属类,划分数据的这个类别称为topic。如果把Kafka看做为一个数据库,topic可以理解为数据库中的一张表,topic的名字即为表名。消息以topic为类别记录,Kafka将消息种子(Feed)分门别类,每一类的消息称之为一个主题(Topic)。
- Partition:物理上的分区,topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
- Partition offset:每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。
- Replicas of partition:副本是一个分区的备份。副本不会被消费者消费,副本只用于防止数据丢失,即消费者不从为follower的partition中消费数据,而是从为leader的partition中读取数据。
- Broker:以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker;消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。每个消息(也叫作record记录,也被称为消息)是由一个key,一个value和时间戳构成。
- Kafka 集群包含一个或多个服务器,服务器节点称为broker。
- broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
- 如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
- 如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
- Producer:生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
- Consumer:消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
- Leader:每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
- Follower:Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
Kafka的架构
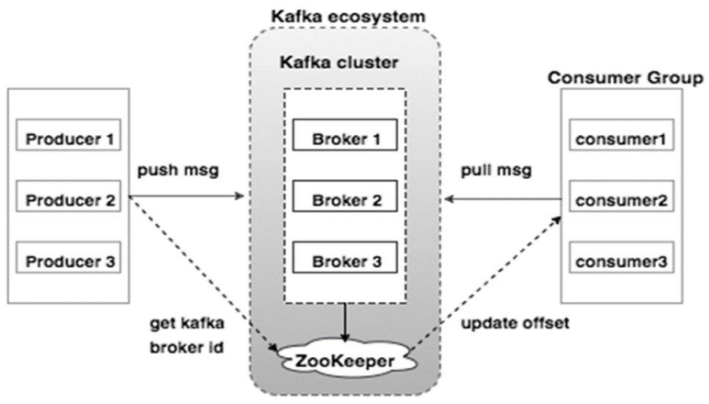
- Broker:Kafka的broker是无状态的,broker使用Zookeeper维护集群的状态。Leader的选举也由Zookeeper负责。
- Zookeeper:Zookeeper负责维护和协调broker。当Kafka系统中新增了broker或者某个broker发生故障失效时,由ZooKeeper通知生产者和消费者。生产者和消费者依据Zookeeper的broker状态信息与broker协调数据的发布和订阅任务。
- Producer:生产者将数据推送到broker上,当集群中出现新的broker时,所有的生产者将会搜寻到这个新的broker,并自动将数据发送到这个broker上。
- Consumer:因为Kafka的broker是无状态的,所以consumer必须使用partition offset来记录消费了多少数据。如果一个consumer指定了一个topic的offset,意味着该consumer已经消费了该offset之前的所有数据。consumer可以通过指定offset,从topic的指定位置开始消费数据。consumer的offset存储在Zookeeper中。
Kafka的Producer
-
Producer客户端负责消息的分发
-
kafka集群中的任何一个broker都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"、"partitions leader列表"等信息;
-
当producer获取到metadata信息之后, producer将会和Topic下所有partition leader保持socket连接;
-
消息由producer直接通过socket发送到broker,中间不会经过任何"路由层"。事实上,消息被路由到哪个partition上由producer客户端决定,比如可以采用"random""key-hash""轮询"等。
如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的。
-
在producer端的配置文件中,开发者可以指定partition路由的方式。
-
Producer消息发送的应答机制
设置发送数据是否需要服务端的反馈,有三个值0,1,-1
0: producer不会等待broker发送ack
1: 当leader接收到消息之后发送ack
-1: 当所有的follower都同步消息成功后发送ack
request.required.acks=0
Kafka的Consumer
kafka只支持Topic
-
每个group中可以有多个consumer,每个consumer属于一个consumer group;通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效那么其消费的partitions将会有其他consumer自动接管。
-
对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer;那么一个group中所有的consumer将会交错的消费整个Topic,每个group中consumer消息消费互相独立,我们可以认为一个group是一个"订阅"者。
-
在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);
一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。 -
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
kafka只能保证一个partition中的消息被某个consumer消费时是顺序的;事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的。
注意:分布式系统中,对于同一个消费者建议加分布式锁,避免重复消费
2. Kafka的特性(优势)
- 高性能:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。Kafka在数据发布和订阅过程中都能保证数据的高吞吐量。即便在TB级数据存储的情况下,仍然能保证稳定的性能。即高吞吐量,低延迟!
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。Kafka是一个具有分区机制、副本机制和容错机制的分布式消息系统
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
3. kafka有四个核心API
- 应用程序使用producer API发布消息到1个或多个topic中。
- 应用程序使用consumer API来订阅一个或多个topic,并处理产生的消息。
- 应用程序使用streams API充当一个流处理器,从1个或多个topic消费输入流,并产生一个输出流到1个或多个topic,有效地将输入流转换到输出流。
- connector API允许构建或运行可重复使用的生产者或消费者,将topic链接到现有的应用程序或数据系统。
4. kafka基本原理
通常来讲,消息模型可以分为两种:队列和发布-订阅式。队列的处理方式是一组消费者从服务器读取消息,一条消息只有其中的一个消费者来处理。在发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组(consumer group)。消费者用一个消费者组名标记自己。
一个发布在Topic上消息被分发给此消费者组中的一个消费者。假如所有的消费者都在一个组中,那么这就变成了queue模型。假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。更通用的, 我们可以创建一些消费者组作为逻辑上的订阅者。每个组包含数目不等的消费者,一个组内多个消费者可以用来扩展性能和容错。
并且,kafka能够保证生产者发送到一个特定的Topic的分区上,消息将会按照它们发送的顺序依次加入,也就是说,如果一个消息M1和M2使用相同的producer发送,M1先发送,那么M1将比M2的offset低,并且优先的出现在日志中。消费者收到的消息也是此顺序。如果一个Topic配置了复制因子(replication facto)为N,那么可以允许N-1服务器宕机而不丢失任何已经提交(committed)的消息。此特性说明kafka有比传统的消息系统更强的顺序保证。但是,相同的消费者组中不能有比分区更多的消费者,否则多出的消费者一直处于空等待,不会收到消息。
5. kafka应用场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
- 构建实时的流数据管道,可靠地获取系统和应用程序之间的数据。
- 构建实时流的应用程序,对数据流进行转换或反应。
6. 主题和日志 (Topic和Log)
每一个分区(partition)都是一个顺序的、不可变的消息队列,并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。Kafka集群保持所有的消息,直到它们过期,无论消息是否被消费了。实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。 可以看到这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。 再说说分区。Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元,稍后会谈到这一点。
7. 分布式(Distribution)
Log的分区被分布到集群中的多个服务器上。每个服务器处理它分到的分区。根据配置每个分区还可以复制到其它服务器作为备份容错。 每个分区有一个leader,零或多个follower。Leader处理此分区的所有的读写请求,而follower被动的复制数据。如果leader宕机,其它的一个follower会被推举为新的leader。 一台服务器可能同时是一个分区的leader,另一个分区的follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
8. Kakfa Broker Leader的选举
Kakfa Broker集群受Zookeeper管理。所有的Kafka Broker节点一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。(这个过程叫Controller在ZooKeeper注册Watch)。这个Controller会监听其他的Kafka Broker的所有信息,如果这个kafka broker controller宕机了,在zookeeper上面的那个临时节点就会消失,此时所有的kafka broker又会一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。例如:一旦有一个broker宕机了,这个kafka broker controller会读取该宕机broker上所有的partition在zookeeper上的状态,并选取ISR列表中的一个replica作为partition leader(如果ISR列表中的replica全挂,选一个幸存的replica作为leader; 如果该partition的所有的replica都宕机了,则将新的leader设置为-1,等待恢复,等待ISR中的任一个Replica"活"过来,并且选它作为Leader;或选择第一个"活"过来的Replica(不一定是ISR中的)作为Leader),这个broker宕机的事情,kafka controller也会通知zookeeper,zookeeper就会通知其他的kafka broker。
顺便说下曾经发生过的一个bug:TalkingData使用Kafka0.8.1的时候,kafka controller在Zookeeper上注册成功后,它和Zookeeper通信的timeout时间是6s,也就是如果kafka controller如果有6s中没有和Zookeeper做心跳,那么Zookeeper就认为这个kafka controller已经死了,就会在Zookeeper上把这个临时节点删掉,那么其他Kafka就会认为controller已经没了,就会再次抢着注册临时节点,注册成功的那个kafka broker成为controller,然后,之前的那个kafka controller就需要各种shut down去关闭各种节点和事件的监听。但是当kafka的读写流量都非常巨大的时候,TalkingData的一个bug是,由于网络等原因,kafka controller和Zookeeper有6s中没有通信,于是重新选举出了一个新的kafka controller,但是原来的controller在shut down的时候总是不成功,这个时候producer进来的message由于Kafka集群中存在两个kafka controller而无法落地。导致数据淤积。
这里曾经还有一个bug,TalkingData使用Kafka0.8.1的时候,当ack=0的时候,表示producer发送出去message,只要对应的kafka broker topic partition leader接收到的这条message,producer就返回成功,不管partition leader 是否真的成功把message真正存到kafka。当ack=1的时候,表示producer发送出去message,同步的把message存到对应topic的partition的leader上,然后producer就返回成功,partition leader异步的把message同步到其他partition replica上。当ack=all或-1,表示producer发送出去message,同步的把message存到对应topic的partition的leader和对应的replica上之后,才返回成功。但是如果某个kafka controller 切换的时候,会导致partition leader的切换(老的 kafka controller上面的partition leader会选举到其他的kafka broker上),但是这样就会导致丢数据。
9. Topic & Partition
Topic相当于传统消息系统MQ中的一个队列queue,producer端发送的message必须指定是发送到哪个topic,但是不需要指定topic下的哪个partition,因为kafka会把收到的message进行load balance,均匀的分布在这个topic下的不同的partition上( hash(message) % [broker数量] )。物理上存储上,这个topic会分成一个或多个partition,每个partiton相当于是一个子queue。在物理结构上,每个partition对应一个物理的目录(文件夹),文件夹命名是[topicname]_[partition]_[序号],一个topic可以有无数多的partition,根据业务需求和数据量来设置。在kafka配置文件中可随时更高num.partitions参数来配置更改topic的partition数量,在创建Topic时通过参数指定parittion数量。Topic创建之后通过Kafka提供的工具也可以修改partiton数量。
一般来说,a)一个Topic的Partition数量大于等于Broker的数量,可以提高吞吐率;b)同一个Partition的Replica尽量分散到不同的机器,高可用。
当add a new partition的时候,partition里面的message不会重新进行分配,原来的partition里面的message数据不会变,新加的这个partition刚开始是空的,随后进入这个topic的message就会重新参与所有partition的load balance
10. Partition Replica
每个partition可以在其他的kafka broker节点上存副本,以便某个kafka broker节点宕机不会影响这个kafka集群。存replica副本的方式是按照kafka broker的顺序存。例如有5个kafka broker节点,某个topic有3个partition,每个partition存2个副本,那么partition1存broker1,broker2,partition2存broker2,broker3。。。以此类推(replica副本数目不能大于kafka broker节点的数目,否则报错。这里的replica数其实就是partition的副本总数,其中包括一个leader,其他的就是copy副本)。这样如果某个broker宕机,其实整个kafka内数据依然是完整的。但是,replica副本数越高,系统虽然越稳定,但是回来带资源和性能上的下降;replica副本少的话,也会造成系统丢数据的风险。
a)怎样传送消息:producer先把message发送到partition leader,再由leader发送给其他partition follower。(如果让producer发送给每个replica那就太慢了)
b) 在向Producer发送ACK前需要保证有多少个Replica已经收到该消息:根据ack配的个数而定
c) 怎样处理某个Replica不工作的情况:如果这个部工作的partition replica不在ack列表中,就是producer在发送消息到partition leader上,partition leader向partition follower发送message没有响应而已,这个不会影响整个系统,也不会有什么问题。如果这个不工作的partition replica在ack列表中的话,producer发送的message的时候会等待这个不工作的partition replca写message成功,但是会等到time out,然后返回失败因为某个ack列表中的partition replica没有响应,此时kafka会自动的把这个部工作的partition replica从ack列表中移除,以后的producer发送message的时候就不会有这个ack列表下的这个部工作的partition replica了。
d)怎样处理Failed Replica恢复回来的情况:如果这个partition replica之前不在ack列表中,那么启动后重新受Zookeeper管理即可,之后producer发送message的时候,partition leader会继续发送message到这个partition follower上。如果这个partition replica之前在ack列表中,此时重启后,需要把这个partition replica再手动加到ack列表中。(ack列表是手动添加的,出现某个部工作的partition replica的时候自动从ack列表中移除的)
11. Partition leader与follower
partition也有leader和follower之分。leader是主partition,producer写kafka的时候先写partition leader,再由partition leader push给其他的partition follower。partition leader与follower的信息受Zookeeper控制,一旦partition leader所在的broker节点宕机,zookeeper会冲其他的broker的partition follower上选择follower变为parition leader。
12. 消息投递可靠性
一个消息如何算投递成功,Kafka提供了三种模式:
- 第一种是啥都不管,发送出去就当作成功,这种情况当然不能保证消息成功投递到broker;
- 第二种是Master-Slave模型,只有当Master和所有Slave都接收到消息时,才算投递成功,这种模型提供了最高的投递可靠性,但是损伤了性能;
- 第三种模型,即只要Master确认收到消息就算投递成功;实际使用时,根据应用特性选择,绝大多数情况下都会中和可靠性和性能选择第三种模型
消息在broker上的可靠性,因为消息会持久化到磁盘上,所以如果正常stop一个broker,其上的数据不会丢失;但是如果不正常stop,可能会使存在页面缓存来不及写入磁盘的消息丢失,这可以通过配置flush页面缓存的周期、阈值缓解,但是同样会频繁的写磁盘会影响性能,又是一个选择题,根据实际情况配置。
消息消费的可靠性,Kafka提供的是“At least once”模型,因为消息的读取进度由offset提供,offset可以由消费者自己维护也可以维护在zookeeper里,但是当消息消费后consumer挂掉,offset没有即时写回,就有可能发生重复读的情况,这种情况同样可以通过调整commit offset周期、阈值缓解,甚至消费者自己把消费和commit offset做成一个事务解决,但是如果你的应用不在乎重复消费,那就干脆不要解决,以换取最大的性能
13. kafka相关特性说明
- message状态:在Kafka中,消息的状态被保存在consumer中,broker不会关心哪个消息被消费了被谁消费了,只记录一个offset值(指向partition中下一个要被消费的消息位置),这就意味着如果consumer处理不好的话,broker上的一个消息可能会被消费多次。
- message持久化:Kafka中会把消息持久化到本地文件系统中,并且保持o(1)极高的效率。我们众所周知IO读取是非常耗资源的性能也是最慢的,这就是为了数据库的瓶颈经常在IO上,需要换SSD硬盘的原因。但是Kafka作为吞吐量极高的MQ,却可以非常高效的message持久化到文件。这是因为Kafka是顺序写入o(1)的时间复杂度,速度非常快。也是高吞吐量的原因。由于message的写入持久化是顺序写入的,因此message在被消费的时候也是按顺序被消费的,保证partition的message是顺序消费的。一般的机器,单机每秒100k条数据。
- message有效期:Kafka会长久保留其中的消息,以便consumer可以多次消费,当然其中很多细节是可配置的。
- Produer : Producer向Topic发送message,不需要指定partition,直接发送就好了。kafka通过partition ack来控制是否发送成功并把信息返回给producer,producer可以有任意多的thread,这些kafka服务器端是不care的。Producer端的delivery guarantee默认是At least once的。也可以设置Producer异步发送实现At most once。Producer可以用主键幂等性实现Exactly once
- Kafka高吞吐量: Kafka的高吞吐量体现在读写上,分布式并发的读和写都非常快,写的性能体现在以o(1)的时间复杂度进行顺序写入。读的性能体现在以o(1)的时间复杂度进行顺序读取, 对topic进行partition分区,consume group中的consume线程可以以很高能性能进行顺序读。
- Kafka delivery guarantee(message传送保证):(1)At most once消息可能会丢,绝对不会重复传输;(2)At least once 消息绝对不会丢,但是可能会重复传输;(3)Exactly once每条信息肯定会被传输一次且仅传输一次,这是用户想要的。
- 批量发送:Kafka支持以消息集合为单位进行批量发送,以提高push效率。
- push-and-pull : Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生产和消费是异步的。
- Kafka集群中broker之间的关系:不是主从关系,各个broker在集群中地位一样,我们可以随意的增加或删除任何一个broker节点。
- 负载均衡方面: Kafka提供了一个 metadata API来管理broker之间的负载(对Kafka0.8.x而言,对于0.7.x主要靠zookeeper来实现负载均衡)。
- 同步异步:Producer采用异步push方式,极大提高Kafka系统的吞吐率(可以通过参数控制是采用同步还是异步方式)。
- 分区机制partition:Kafka的broker端支持消息分区partition,Producer可以决定把消息发到哪个partition,在一个partition 中message的顺序就是Producer发送消息的顺序,一个topic中可以有多个partition,具体partition的数量是可配置的。partition的概念使得kafka作为MQ可以横向扩展,吞吐量巨大。partition可以设置replica副本,replica副本存在不同的kafka broker节点上,第一个partition是leader,其他的是follower,message先写到partition leader上,再由partition leader push到parition follower上。所以说kafka可以水平扩展,也就是扩展partition。
- 离线数据装载:Kafka由于对可拓展的数据持久化的支持,它也非常适合向Hadoop或者数据仓库中进行数据装载。
- 实时数据与离线数据:kafka既支持离线数据也支持实时数据,因为kafka的message持久化到文件,并可以设置有效期,因此可以把kafka作为一个高效的存储来使用,可以作为离线数据供后面的分析。当然作为分布式实时消息系统,大多数情况下还是用于实时的数据处理的,但是当cosumer消费能力下降的时候可以通过message的持久化在淤积数据在kafka。
- 插件支持:现在不少活跃的社区已经开发出不少插件来拓展Kafka的功能,如用来配合Storm、Hadoop、flume相关的插件。
- 解耦: 相当于一个MQ,使得Producer和Consumer之间异步的操作,系统之间解耦。
- 冗余: replica有多个副本,保证一个broker node宕机后不会影响整个服务。
- 扩展性: broker节点可以水平扩展,partition也可以水平增加,partition replica也可以水平增加。
- 峰值: 在访问量剧增的情况下,kafka水平扩展, 应用仍然需要继续发挥作用。
- 可恢复性: 系统的一部分组件失效时,由于有partition的replica副本,不会影响到整个系统。
- 顺序保证性:由于kafka的producer的写message与consumer去读message都是顺序的读写,保证了高效的性能。
- 缓冲:由于producer那面可能业务很简单,而后端consumer业务会很复杂并有数据库的操作,因此肯定是producer会比consumer处理速度快,如果没有kafka,producer直接调用consumer,那么就会造成整个系统的处理速度慢,加一层kafka作为MQ,可以起到缓冲的作用。
- 异步通信:作为MQ,Producer与Consumer异步通信。
kafka部分名称解释
Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
- Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Segment:partition物理上由多个segment组成,每个Segment存着message信息。
- Producer : 生产message发送到topic。
- Consumer : 订阅topic消费message, consumer作为一个线程来消费。
- Consumer Group:一个Consumer Group包含多个consumer, 这个是预先在配置文件中配置好的。各个consumer(consumer 线程)可以组成一个组(Consumer group ),partition中的每个message只能被组(Consumer group ) 中的一个consumer(consumer 线程 )消费,如果一个message可以被多个consumer(consumer 线程 ) 消费的话,那么这些consumer必须在不同的组。Kafka不支持一个partition中的message由两个或两个以上的consumer thread来处理,即便是来自不同的consumer group的也不行。它不能像AMQ那样可以多个BET作为consumer去处理message,这是因为多个BET去消费一个Queue中的数据的时候,由于要保证不能多个线程拿同一条message,所以就需要行级别悲观所(for update),这就导致了consume的性能下降,吞吐量不够。而kafka为了保证吞吐量,只允许一个consumer线程去访问一个partition。如果觉得效率不高的时候,可以加partition的数量来横向扩展,那么再加新的consumer thread去消费。这样没有锁竞争,充分发挥了横向的扩展性,吞吐量极高。这也就形成了分布式消费的概念。
14. kafka一些原理概念
持久化
kafka使用文件存储消息(append only log),这就直接决定kafka在性能上严重依赖文件系统的本身特性.且无论任何OS下,对文件系统本身的优化是非常艰难的.文件缓存/直接内存映射等是常用的手段.因为kafka是对日志文件进行append操作,因此磁盘检索的开支是较小的;同时为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数.对于kafka而言,较高性能的磁盘,将会带来更加直接的性能提升.
性能
除磁盘IO之外,我们还需要考虑网络IO,这直接关系到kafka的吞吐量问题.kafka并没有提供太多高超的技巧;对于producer端,可以将消息buffer起来,当消息的条数达到一定阀值时,批量发送给broker;对于consumer端也是一样,批量fetch多条消息.不过消息量的大小可以通过配置文件来指定.对于kafka broker端,似乎有个sendfile系统调用可以潜在的提升网络IO的性能:将文件的数据映射到系统内存中,socket直接读取相应的内存区域即可,而无需进程再次copy和交换(这里涉及到"磁盘IO数据"/"内核内存"/"进程内存"/"网络缓冲区",多者之间的数据copy).
其实对于producer/consumer/broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制是一个良好的策略;压缩需要消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑.可以将任何在网络上传输的消息都经过压缩.kafka支持gzip/snappy等多种压缩方式.
负载均衡
kafka集群中的任何一个broker,都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"/"partitions leader列表"等信息(请参看zookeeper中的节点信息). 当producer获取到metadata信息之后, producer将会和Topic下所有partition leader保持socket连接;消息由producer直接通过socket发送到broker,中间不会经过任何"路由层".
异步发送,将多条消息暂且在客户端buffer起来,并将他们批量发送到broker;小数据IO太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率;不过这也有一定的隐患,比如当producer失效时,那些尚未发送的消息将会丢失。
Topic模型
其他JMS实现,消息消费的位置是有prodiver保留,以便避免重复发送消息或者将没有消费成功的消息重发等,同时还要控制消息的状态.这就要求JMS broker需要太多额外的工作.在kafka中,partition中的消息只有一个consumer在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,可见kafka broker端是相当轻量级的.当消息被consumer接收之后,consumer可以在本地保存最后消息的offset,并间歇性的向zookeeper注册offset.由此可见,consumer客户端也很轻量级。
kafka中consumer负责维护消息的消费记录,而broker则不关心这些,这种设计不仅提高了consumer端的灵活性,也适度的减轻了broker端设计的复杂度;这是和众多JMS prodiver的区别.此外,kafka中消息ACK的设计也和JMS有很大不同,kafka中的消息是批量(通常以消息的条数或者chunk的尺寸为单位)发送给consumer,当消息消费成功后,向zookeeper提交消息的offset,而不会向broker交付ACK.或许你已经意识到,这种"宽松"的设计,将会有"丢失"消息/"消息重发"的危险.
消息传输一致
Kafka提供3种消息传输一致性语义:最多1次,最少1次,恰好1次。
最少1次:可能会重传数据,有可能出现数据被重复处理的情况;
最多1次:可能会出现数据丢失情况;
恰好1次:并不是指真正只传输1次,只不过有一个机制。确保不会出现“数据被重复处理”和“数据丢失”的情况。
at most once: 消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中consumer进程失效(crash),导致部分消息未能继续处理.那么此后可能其他consumer会接管,但是因为offset已经提前保存,那么新的consumer将不能fetch到offset之前的消息(尽管它们尚没有被处理),这就是"at most once".
at least once: 消费者fetch消息,然后处理消息,然后保存offset.如果消息处理成功之后,但是在保存offset阶段zookeeper异常或者consumer失效,导致保存offset操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once".
"Kafka Cluster"到消费者的场景中可以采取以下方案来得到“恰好1次”的一致性语义:
最少1次+消费者的输出中额外增加已处理消息最大编号:由于已处理消息最大编号的存在,不会出现重复处理消息的情况。
副本
kafka中,replication策略是基于partition,而不是topic;kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有);备份的个数可以通过broker配置文件来设定。leader处理所有的read-write请求,follower需要和leader保持同步.Follower就像一个"consumer",消费消息并保存在本地日志中;leader负责跟踪所有的follower状态,如果follower"落后"太多或者失效,leader将会把它从replicas同步列表中删除.当所有的follower都将一条消息保存成功,此消息才被认为是"committed",那么此时consumer才能消费它,这种同步策略,就要求follower和leader之间必须具有良好的网络环境.即使只有一个replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可.
选择follower时需要兼顾一个问题,就是新leader server上所已经承载的partition leader的个数,如果一个server上有过多的partition leader,意味着此server将承受着更多的IO压力.在选举新leader,需要考虑到"负载均衡",partition leader较少的broker将会更有可能成为新的leader.
log
每个log entry格式为"4个字节的数字N表示消息的长度" + "N个字节的消息内容";每个日志都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此partition中所处的起始位置..每个partition在物理存储层面,有多个log file组成(称为segment).segment file的命名为"最小offset".kafka.例如"00000000000.kafka";其中"最小offset"表示此segment中起始消息的offset.
获取消息时,需要指定offset和最大chunk尺寸,offset用来表示消息的起始位置,chunk size用来表示最大获取消息的总长度(间接的表示消息的条数).根据offset,可以找到此消息所在segment文件,然后根据segment的最小offset取差值,得到它在file中的相对位置,直接读取输出即可.
分布式
kafka使用zookeeper来存储一些meta信息,并使用了zookeeper watch机制来发现meta信息的变更并作出相应的动作(比如consumer失效,触发负载均衡等)
Broker node registry: 当一个kafka broker启动后,首先会向zookeeper注册自己的节点信息(临时znode),同时当broker和zookeeper断开连接时,此znode也会被删除.
Broker Topic Registry: 当一个broker启动时,会向zookeeper注册自己持有的topic和partitions信息,仍然是一个临时znode.
Consumer and Consumer group: 每个consumer客户端被创建时,会向zookeeper注册自己的信息;此作用主要是为了"负载均衡".一个group中的多个consumer可以交错的消费一个topic的所有partitions;简而言之,保证此topic的所有partitions都能被此group所消费,且消费时为了性能考虑,让partition相对均衡的分散到每个consumer上.
Consumer id Registry: 每个consumer都有一个唯一的ID(host:uuid,可以通过配置文件指定,也可以由系统生成),此id用来标记消费者信息.
Consumer offset Tracking: 用来跟踪每个consumer目前所消费的partition中最大的offset.此znode为持久节点,可以看出offset跟group_id有关,以表明当group中一个消费者失效,其他consumer可以继续消费.
Partition Owner registry: 用来标记partition正在被哪个consumer消费.临时znode。此节点表达了"一个partition"只能被group下一个consumer消费,同时当group下某个consumer失效,那么将会触发负载均衡(即:让partitions在多个consumer间均衡消费,接管那些"游离"的partitions)
当consumer启动时,所触发的操作:
A) 首先进行"Consumer id Registry";
B) 然后在"Consumer id Registry"节点下注册一个watch用来监听当前group中其他consumer的"leave"和"join";只要此znode path下节点列表变更,都会触发此group下consumer的负载均衡.(比如一个consumer失效,那么其他consumer接管partitions).
C) 在"Broker id registry"节点下,注册一个watch用来监听broker的存活情况;如果broker列表变更,将会触发所有的groups下的consumer重新balance.
总结:
1) Producer端使用zookeeper用来"发现"broker列表,以及和Topic下每个partition leader建立socket连接并发送消息.
2) Broker端使用zookeeper用来注册broker信息,已经监测partition leader存活性.
3) Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息。
Leader的选择
Kafka的核心是日志文件,日志文件在集群中的同步是分布式数据系统最基础的要素。
如果leaders永远不会down的话我们就不需要followers了!一旦leader down掉了,需要在followers中选择一个新的leader.但是followers本身有可能延时太久或者crash,所以必须选择高质量的follower作为leader.必须保证,一旦一个消息被提交了,但是leader down掉了,新选出的leader必须可以提供这条消息。大部分的分布式系统采用了多数投票法则选择新的leader,对于多数投票法则,就是根据所有副本节点的状况动态的选择最适合的作为leader.Kafka并不是使用这种方法。
Kafka动态维护了一个同步状态的副本的集合(a set of in-sync replicas),简称ISR,在这个集合中的节点都是和leader保持高度一致的,任何一条消息必须被这个集合中的每个节点读取并追加到日志中了,才回通知外部这个消息已经被提交了。因此这个集合中的任何一个节点随时都可以被选为leader.ISR在ZooKeeper中维护。ISR中有f+1个节点,就可以允许在f个节点down掉的情况下不会丢失消息并正常提供服。ISR的成员是动态的,如果一个节点被淘汰了,当它重新达到“同步中”的状态时,他可以重新加入ISR.这种leader的选择方式是非常快速的,适合kafka的应用场景。
一个邪恶的想法:如果所有节点都down掉了怎么办?Kafka对于数据不会丢失的保证,是基于至少一个节点是存活的,一旦所有节点都down了,这个就不能保证了。
实际应用中,当所有的副本都down掉时,必须及时作出反应。可以有以下两种选择:
1. 等待ISR中的任何一个节点恢复并担任leader。
2. 选择所有节点中(不只是ISR)第一个恢复的节点作为leader.
这是一个在可用性和连续性之间的权衡。如果等待ISR中的节点恢复,一旦ISR中的节点起不起来或者数据都是了,那集群就永远恢复不了了。如果等待ISR意外的节点恢复,这个节点的数据就会被作为线上数据,有可能和真实的数据有所出入,因为有些数据它可能还没同步到。Kafka目前选择了第二种策略,在未来的版本中将使这个策略的选择可配置,可以根据场景灵活的选择。
这种窘境不只Kafka会遇到,几乎所有的分布式数据系统都会遇到。
副本管理
以上仅仅以一个topic一个分区为例子进行了讨论,但实际上一个Kafka将会管理成千上万的topic分区.Kafka尽量的使所有分区均匀的分布到集群所有的节点上而不是集中在某些节点上,另外主从关系也尽量均衡这样每个几点都会担任一定比例的分区的leader.
优化leader的选择过程也是很重要的,它决定了系统发生故障时的空窗期有多久。Kafka选择一个节点作为“controller”,当发现有节点down掉的时候它负责在游泳分区的所有节点中选择新的leader,这使得Kafka可以批量的高效的管理所有分区节点的主从关系。如果controller down掉了,活着的节点中的一个会备切换为新的controller.
Leader与副本同步
对于某个分区来说,保存正分区的"broker"为该分区的"leader",保存备份分区的"broker"为该分区的"follower"。备份分区会完全复制正分区的消息,包括消息的编号等附加属性值。为了保持正分区和备份分区的内容一致,Kafka采取的方案是在保存备份分区的"broker"上开启一个消费者进程进行消费,从而使得正分区的内容与备份分区的内容保持一致。一般情况下,一个分区有一个“正分区”和零到多个“备份分区”。可以配置“正分区+备份分区”的总数量,关于这个配置,不同主题可以有不同的配置值。注意,生产者,消费者只与保存正分区的"leader"进行通信。
Kafka允许topic的分区拥有若干副本,这个数量是可以配置的,你可以为每个topic配置副本的数量。Kafka会自动在每个副本上备份数据,所以当一个节点down掉时数据依然是可用的。
Kafka的副本功能不是必须的,你可以配置只有一个副本,这样其实就相当于只有一份数据。
创建副本的单位是topic的分区,每个分区都有一个leader和零或多个followers.所有的读写操作都由leader处理,一般分区的数量都比broker的数量多的多,各分区的leader均匀的分布在brokers中。所有的followers都复制leader的日志,日志中的消息和顺序都和leader中的一致。followers向普通的consumer那样从leader那里拉取消息并保存在自己的日志文件中。
许多分布式的消息系统自动的处理失败的请求,它们对一个节点是否着(alive)”有着清晰的定义。Kafka判断一个节点是否活着有两个条件:
1. 节点必须可以维护和ZooKeeper的连接,Zookeeper通过心跳机制检查每个节点的连接。
2. 如果节点是个follower,他必须能及时的同步leader的写操作,延时不能太久。
符合以上条件的节点准确的说应该是“同步中的(in sync)”,而不是模糊的说是“活着的”或是“失败的”。Leader会追踪所有“同步中”的节点,一旦一个down掉了,或是卡住了,或是延时太久,leader就会把它移除。至于延时多久算是“太久”,是由参数replica.lag.max.messages决定的,怎样算是卡住了,怎是由参数replica.lag.time.max.ms决定的。
只有当消息被所有的副本加入到日志中时,才算是“committed”,只有committed的消息才会发送给consumer,这样就不用担心一旦leader down掉了消息会丢失。Producer也可以选择是否等待消息被提交的通知,这个是由参数acks决定的。
Kafka保证只要有一个“同步中”的节点,“committed”的消息就不会丢失。
===========================================================================
二、kafka集群环境部署记录
1)服务器信息
ip地址 主机名 安装软件 192.168.10.202 kafka01 zookeeper、kafka 192.168.10.203 kafka02 zookeeper、kafka 192.168.10.205 kafka03 zookeeper、kafka 192.168.10.206 kafka-manager kafka-manager 4台机器关闭iptables和selinux [root@kafka01 ~]# /etc/init.d/iptables stop [root@kafka01 ~]# vim /etc/sysconfig/selinux ...... SELINUX=disabled [root@kafka01 ~]# setenforce 0 [root@kafka01 ~]# getenforce Permissive 4台机器做hosts绑定 [root@kafka01 ~]# vim /etc/hosts ...... 192.168.10.202 kafka01 192.168.10.203 kafka02 192.168.10.205 kafka03 192.168.10.206 kafka-manager
2)jdk安装(四台机器都要操作,安装1.7以上版本)
将jdk-8u131-linux-x64.rpm下载到/opt目录下 下载地址:https://pan.baidu.com/s/1pLaAjPp 提取密码:x27s [root@kafka01 ~]# cd /usr/local/src/ [root@kafka01 src]# ll jdk-8u131-linux-x64.rpm -rw-r--r--. 1 root root 169983496 Sep 28 2017 jdk-8u131-linux-x64.rpm [root@kafka01 src]# rpm -ivh jdk-8u131-linux-x64.rpm [root@kafka01 src]# vim /etc/profile ...... JAVA_HOME=/usr/java/jdk1.8.0_131 JAVA_BIN=/usr/java/jdk1.8.0_131/bin PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/bin:/sbin/ CLASSPATH=.:/lib/dt.jar:/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATH [root@kafka01 src]# source /etc/profile [root@kafka01 src]# java -version java version "1.8.0_131" Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
3)安装及配置kafka(192.168.10.202、192.168.10.203、192.168.10.205三台机器如下同样操作)
1)安装三个节点的zookeeper(zookeeper集群部署可以参考:http://www.cnblogs.com/kevingrace/p/7879390.html) [root@kafka01 ~]# cd /usr/local/src/ [root@kafka01 src]# wget http://apache.forsale.plus/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz [root@kafka01 src]# tar -zvxf zookeeper-3.4.10.tar.gz [root@kafka01 src]# mkdir /data [root@kafka01 src]# mv zookeeper-3.4.10 /data/zk 修改三个节点的zookeeper的配置文件,内容如下所示: [root@kafka01 src]# mkdir -p /data/zk/data [root@kafka01 src]# cp /data/zk/conf/zoo_sample.cfg /data/zk/conf/zoo_sample.cfg.bak [root@kafka01 src]# cp /data/zk/conf/zoo_sample.cfg /data/zk/conf/zoo.cfg [root@kafka01 src]# vim /data/zk/conf/zoo.cfg #清空之前的内容,配置成下面内容 tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data/zk/data/zookeeper dataLogDir=/data/zk/data/logs clientPort=2181 maxClientCnxns=60 autopurge.snapRetainCount=3 autopurge.purgeInterval=1 server.1=192.168.10.202:2888:3888 server.2=192.168.10.203:2888:3888 server.3=192.168.10.205:2888:3888 =============== 配置参数说明: server.id=host:port:port:表示了不同的zookeeper服务器的自身标识,作为集群的一部分,每一台服务器应该知道其他服务器的信息。 用户可以从"server.id=host:port:port" 中读取到相关信息。 在服务器的data(dataDir参数所指定的目录)下创建一个文件名为myid的文件,这个文件的内容只有一行,指定的是自身的id值。 比如,服务器"1"应该在myid文件中写入"1"。这个id必须在集群环境中服务器标识中是唯一的,且大小在1~255之间。 这一样配置中,zoo1代表第一台服务器的IP地址。第一个端口号(port)是从follower连接到leader机器的端口,第二个端口是用来进行leader选举时所用的端口。 所以,在集群配置过程中有三个非常重要的端口:clientPort=2181、port:2888、port:3888。 =============== 注意:如果想更换日志输出位置,除了在zoo.cfg加入"dataLogDir=/data/zk/data/logs"外,还需要修改zkServer.sh文件,大概修改方式地方在 125行左右,内容如下: [root@kafka01 src]# cp /data/zk/bin/zkServer.sh /data/zk/bin/zkServer.sh.bak [root@kafka01 src]# vim /data/zk/bin/zkServer.sh ....... 125 ZOO_LOG_DIR="$($GREP "^[[:space:]]*dataLogDir" "$ZOOCFG" | sed -e 's/.*=//')" #添加这一行 126 if [ ! -w "$ZOO_LOG_DIR" ] ; then 127 mkdir -p "$ZOO_LOG_DIR" 128 fi [root@kafka01 src]# diff /data/zk/bin/zkServer.sh /data/zk/bin/zkServer.sh.bak 125d124 < ZOO_LOG_DIR="$($GREP "^[[:space:]]*dataLogDir" "$ZOOCFG" | sed -e 's/.*=//')" 在启动zookeeper服务之前,还需要分别在三个zookeeper节点机器上创建myid,方式如下: [root@kafka01 src]# mkdir /data/zk/data/zookeeper/ [root@kafka01 src]# echo 1 > /data/zk/data/zookeeper/myid ================================================================= 另外两个节点的myid分别为2、3(注意这三个节点机器的myid决不能一样,配置文件等其他都是一样配置) [root@kafka02 src]# mkdir /data/zk/data/zookeeper [root@kafka02 src]# echo 2 > /data/zk/data/zookeeper/myid [root@kafka03 src]# mkdir /data/zk/data/zookeeper [root@kafka03 src]# echo 3 > /data/zk/data/zookeeper/myid ================================================================= 启动三个节点的zookeeper服务 [root@kafka01 src]# /data/zk/bin/zkServer.sh start ZooKeeper JMX enabled by default Using config: /data/zk/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@kafka01 src]# ps -ef|grep zookeeper root 25512 1 0 11:49 pts/0 00:00:00 /usr/java/jdk1.8.0_131/bin/java -Dzookeeper.log.dir=/data/zk/data/logs -Dzookeeper.root.logger=INFO,CONSOLE -cp /data/zk/bin/../build/classes:/data/zk/bin/../build/lib/*.jar:/data/zk/bin/../lib/slf4j-log4j12-1.6.1.jar:/data/zk/bin/../lib/slf4j-api-1.6.1.jar:/data/zk/bin/../lib/netty-3.10.5.Final.jar:/data/zk/bin/../lib/log4j-1.2.16.jar:/data/zk/bin/../lib/jline-0.9.94.jar:/data/zk/bin/../zookeeper-3.4.10.jar:/data/zk/bin/../src/java/lib/*.jar:/data/zk/bin/../conf:.:/lib/dt.jar:/lib/tools.jar -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=false org.apache.zookeeper.server.quorum.QuorumPeerMain /data/zk/bin/../conf/zoo.cfg root 25555 24445 0 11:51 pts/0 00:00:00 grep zookeeper [root@kafka01 src]# lsof -i:2181 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 25512 root 23u IPv6 8293793 0t0 TCP *:eforward (LISTEN) 查看三个节点的zookeeper角色 [root@kafka01 src]# /data/zk/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /data/zk/bin/../conf/zoo.cfg Mode: follower [root@kafka02 src]# /data/zk/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /data/zk/bin/../conf/zoo.cfg Mode: leader [root@kafka03 src]# /data/zk/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /data/zk/bin/../conf/zoo.cfg Mode: follower ————————————————————————————————————————————————————————————————————————————————————————————— 2)安装kafka(三个节点同样操作) 下载地址:http://kafka.apache.org/downloads.html [root@kafka01 ~]# cd /usr/local/src/ [root@kafka01 src]# wget http://mirrors.shu.edu.cn/apache/kafka/1.1.0/kafka_2.11-1.1.0.tgz [root@kafka01 src]# tar -zvxf kafka_2.11-1.1.0.tgz [root@kafka01 src]# mv kafka_2.11-1.1.0 /data/kafka 进入kafka下面的config目录,修改配置文件server.properties: [root@kafka01 src]# cp /data/kafka/config/server.properties /data/kafka/config/server.properties.bak [root@kafka01 src]# vim /data/kafka/config/server.properties broker.id=0 delete.topic.enable=true listeners=PLAINTEXT://192.168.10.202:9092 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/data/kafka/data num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.flush.interval.messages=10000 log.flush.interval.ms=1000 log.retention.hours=168 log.retention.bytes=1073741824 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=192.168.10.202:2181,192.168.10.203:2181,192.168.10.205:2181 zookeeper.connection.timeout.ms=6000 group.initial.rebalance.delay.ms=0 其他两个节点的server.properties只需要修改下面两行,其他配置都一样 [root@kafka02 src]# vim /data/kafka/config/server.properties [root@kafka02 src]# cat /data/kafka/config/server.properties broker.id=1 ...... listeners=PLAINTEXT://192.168.10.203:9092 ....... [root@kafka03 src]# vim /data/kafka/config/server.properties [root@kafka03 src]# cat /data/kafka/config/server.properties broker.id=2 ...... listeners=PLAINTEXT://192.168.10.205:9092 ...... 启动三个节点的kafka服务 [root@kafka01 src]# nohup /data/kafka/bin/kafka-server-start.sh /data/kafka/config/server.properties >/dev/null 2>&1 & [root@kafka01 src]# lsof -i:9092 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 26114 root 97u IPv6 8298666 0t0 TCP kafka01:XmlIpcRegSvc (LISTEN) java 26114 root 113u IPv6 8298672 0t0 TCP kafka01:53112->kafka01:XmlIpcRegSvc (ESTABLISHED) java 26114 root 114u IPv6 8298673 0t0 TCP kafka01:XmlIpcRegSvc->kafka01:53112 (ESTABLISHED) 验证服务 随便在其中一台节点主机执行 [root@kafka01 src]# /data/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.10.202:2181,192.168.10.203:2181,192.168.10.205:2181 --replication-factor 1 --partitions 1 --topic test 出现下面信息说明创建成功 Created topic "test". 然后再在其他主机查看上面创建的topic [root@kafka02 src]# /data/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.10.202:2181,192.168.10.203:2181,192.168.10.205:2181 test 到此,kafka集群环境已部署完成!
4)安装kafka集群管理工具kafka-manager
为了简化开发者和服务工程师维护Kafka集群的工作,yahoo构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka Manager。kafka-manager 项目地址:https://github.com/yahoo/kafka-manager。这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具,kafka-manager有如下功能:
- 管理多个kafka集群
- 便捷的检查kafka集群状态(topics,brokers,备份分布情况,分区分布情况)
- 选择你要运行的副本
- 基于当前分区状况进行
- 可以选择topic配置并创建topic(0.8.1.1和0.8.2的配置不同)
- 删除topic(只支持0.8.2以上的版本并且要在broker配置中设置delete.topic.enable=true)
- Topic list会指明哪些topic被删除(在0.8.2以上版本适用)
- 为已存在的topic增加分区
- 为已存在的topic更新配置
- 在多个topic上批量重分区
- 在多个topic上批量重分区(可选partition broker位置)
kafka-manager安装过程如下
下载安装 kafka-manager 想要查看和管理Kafka,完全使用命令并不方便,我们可以使用雅虎开源的Kafka-manager,GitHub地址如下: https://github.com/yahoo/kafka-manager 也可以使用Git或者直接从Releases中下载,此处从下面的地址下载 1.3.3.7 版本: https://github.com/yahoo/kafka-manager/releases 需要注意: 上面下载的是源码,下载后需要按照后面步骤进行编译。如果觉得麻烦,可以直接下载编译好的kafka-manager-1.3.3.7.zip。 下载地址:https://pan.baidu.com/s/12j2DEt94WsWRY6dD9aR6BQ 提取密码:8x57 [root@kafka-manager src]# ls kafka-manager-1.3.3.7.zip kafka-manager-1.3.3.7.zip [root@kafka-manager src]# unzip kafka-manager-1.3.3.7.zip [root@kafka-manager src]# mv kafka-manager-1.3.3.7 /data/ [root@kafka-manager src]# cd /data/kafka-manager-1.3.3.7 [root@kafka-manager kafka-manager-1.3.3.7]# cd conf/ [root@kafka-manager conf]# cp application.conf application.conf.bak [root@kafka-manager conf]# vim application.conf ...... #kafka-manager.zkhosts="localhost:2181" #注释这一行,下面添加一行 kafka-manager.zkhosts="192.168.10.202:2181,192.168.10.203:2181,192.168.10.205:2181" 启动kafka-manager [root@kafka-manager conf]# nohup /data/kafka-manager-1.3.3.7/bin/kafka-manager >/dev/null 2>&1 & ---------------------------------------------------------------------------------------------------- 需要注意: kafka-manager 默认的端口是9000,可通过 -Dhttp.port,指定端口; -Dconfig.file=conf/application.conf指定配置文件: [root@kafka-manager conf]# nohup bin/kafka-manager -Dconfig.file=/data/kafka-manager-1.3.3.7/conf/application.conf -Dhttp.port=8080 & ---------------------------------------------------------------------------------------------------- 启动完毕后可以查看端口是否启动,由于启动过程需要一段时间,端口起来的时间可能会延后。 [root@kafka-manager conf]# lsof -i:9000 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 27218 root 114u IPv6 3766984 0t0 TCP *:cslistener (LISTEN) 最后就可以使用http://192.168.10.206:9000访问了
kafka-mamager测试
新建 Cluster1
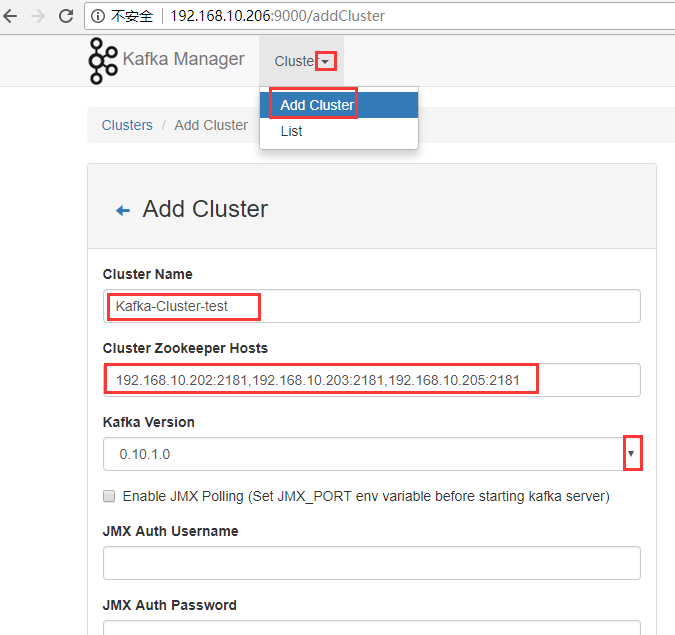
点击【Cluster】>【Add Cluster】打开如下添加集群的配置界面:
输入集群的名字(如Kafka-Cluster-test)和 Zookeeper 服务器地址(如localhost:2181),选择最接近的Kafka版本(如0.10.1.1)
-------------------------------------------------------------------
注意:如果没有在 Kafka 中配置过 JMX_PORT,千万不要选择第一个复选框。
Enable JMX Polling
如果选择了该复选框,Kafka-manager 可能会无法启动。
-------------------------------------------------------------------
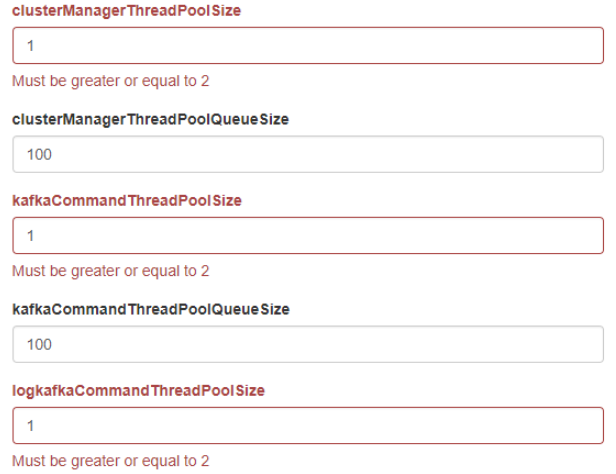
其他broker的配置可以根据自己需要进行配置,默认情况下,点击【保存】时,会提示几个默认值为1的配置错误,需要配置为>=2的值。提示如下。
新建完成后,运行界面如下:


查看TOPIC 信息
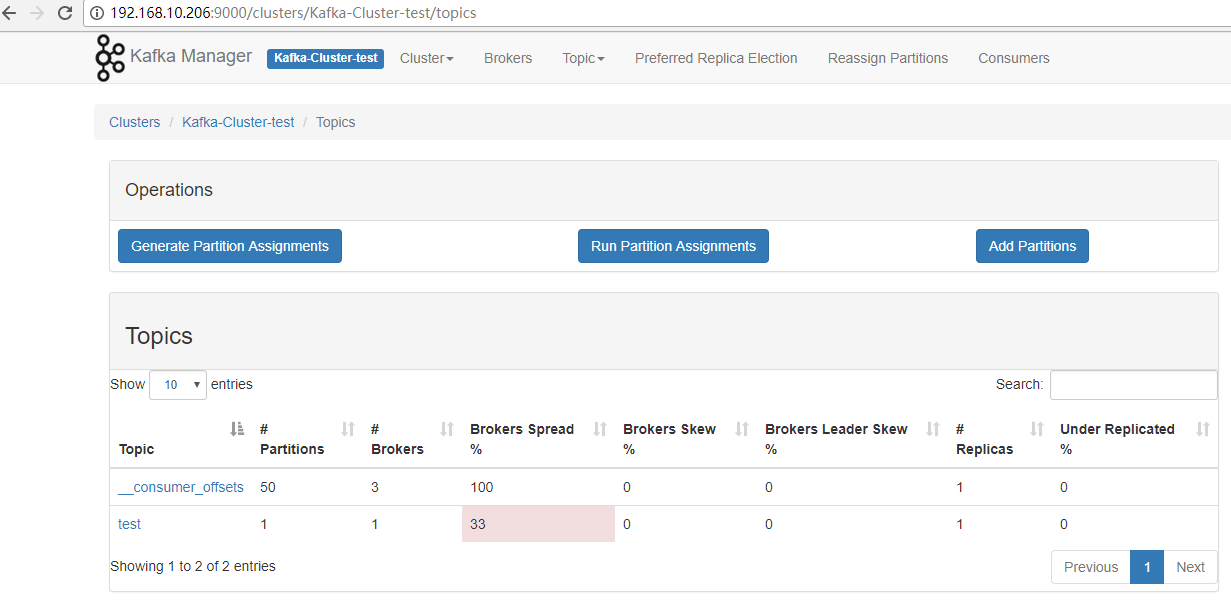
查看broker信息

管理 kafka-mamager
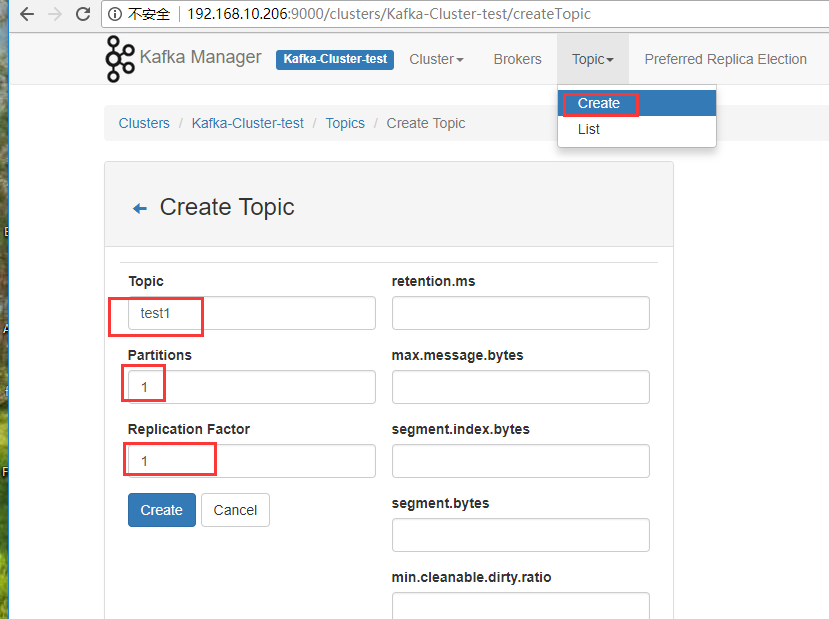
新建主题
点击【Topic】>【Create】可以方便的创建并配置主题。如下显示。
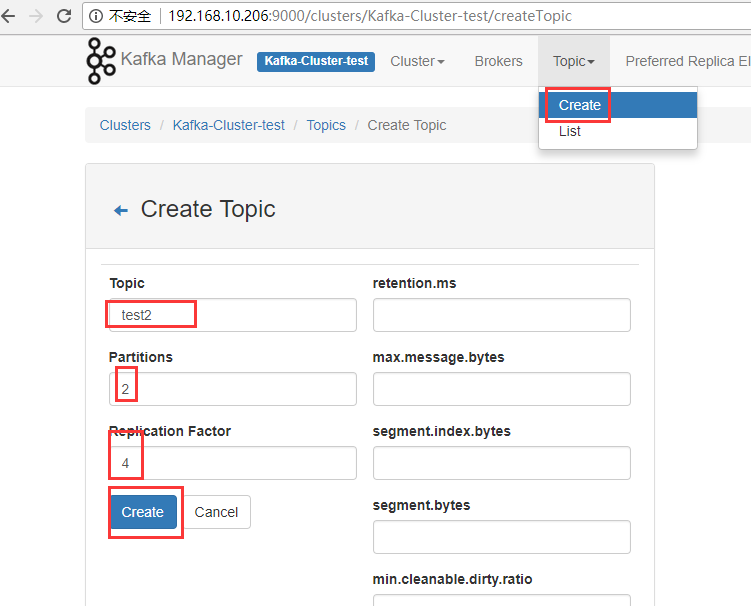

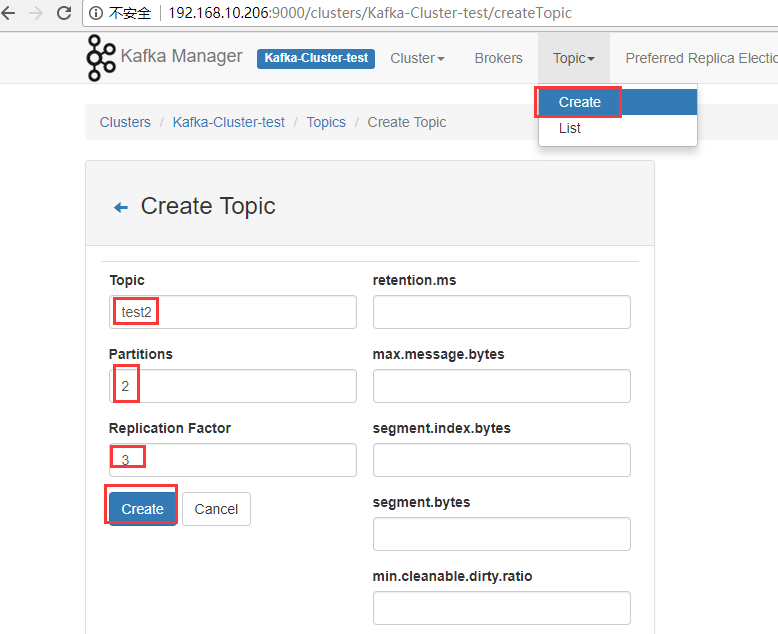
由于集群只有三个节点,故replication factor最多只能设置为3


================================================
针对上面Topic->Create新建主题的配置,下面根据一张图讲解

在上图一个Kafka集群中,有两个服务器,每个服务器上都有2个分区。P0,P3可能属于同一个主题,也可能是两个不同的主题。
如果设置的Partitons和Replication Factor都是2,这种情况下该主题的分步就和上图中Kafka集群显示的相同,此时P0,P3是同一个主题的两个分区。P1,P2也是同一个主题的两个分区,Server1和Server2其中一个会作为Leader进行读写操作,另一个通过复制进行同步。
如果设置的Partitons和Replication Factor都是1,这时只会根据算法在某个Server上创建一个分区,可以是P0~4中的某一个(分区都是新建的,不是先存在4个然后从中取1个)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号