
GlusterFS分布式存储数据的恢复机制(AFR)的说明
GlusterFSFS恢复数据都是基于副本卷来说的,GlusterFSFS复制卷是采用镜像的方式做的,并且是同步事务性操作。简单来说就是,某一个客户要写文件时,先把这个文件锁住,然后同时写两个或多个副本,写完后解锁,这个操作才算结束。那么在写某一个副本时发生故障没有写成功,或者运行过程中某一个节点断电了,造成数据丢失了,等等,就能通过另一个副本来恢复。
现在这里说一个疑问:
就是GlusterFS写副本时同步写的,就是客户端同时写两份数据,这样就会产生两倍的流量,测2副本的分布式复制卷性能时,能明确看到性能只有无副本的一半,或者只有读的一半;另一个分布式文件系统ceph就不是这样,是异步来写副本的,就是写到一个主OSD(ceph的存储单元)就返回了,这个OSD再通过内部网络异步写到其他的OSD,这样不是更快了。那么这两种方法有什么优缺点呢,那种比较好,或者各自为什么采用这样的方法?
说道恢复就有什么时候恢复,怎么恢复,凭什么说这个副本是好的,那个副本是坏的呢,这样的问题,一个一个来说吧。
1)首先,什么时候恢复?有这样三种场景会触发恢复,宕机的节点恢复正常时;副本缺失的文件被读写到时,比如运行如下命令:
ls -l <file-path-on-gluster-mount>; 每十分钟gluster会自行检查;手动下命令触发恢复,命令为gluster volume heal VOLNAME
2)怎么恢复?在这三种环境的任何一种下,gluster都会做检查,看需不需要来个恢复,检查什么呢,就是changelog,通过这个changelog来决定哪个副本坏了,要修复了。
3)凭什么说它坏了呢?刚才说了changelog会记录的,记录的什么呢,就是这个文件操作了什么,这个可以从文件的扩展属性反正出来,每一个文件都有一个扩展属性,主要记录了这个文件操作了什么,以及所有其他的副本操作了什么,副本的扩展属性如果不一样,那么就是有问题,要恢复自己,还是凭自己去恢复其他副本,都看这个扩展属性了,可以用命令getfattr -m . -d -e hex <FILENAME>,(和getfattr对应,有一个setfattr命令是可以设置这些属性的,具体命令为setfattr -n trusted.glusterfs.volume-id -v 0x937d9caf46544ed0a2d22e25edb23a75 /brick2,)这样设置了/brick2所在卷的id,查到扩展属性的值就是如下图所示的这样的一个东西:
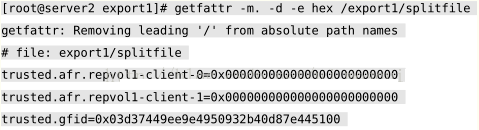
这张图中值得注意的是,trusted.afr.repvol1-client-0,还有trusted.afr.repvol1-client-1,这两条就是自己的和副本的扩展属性了。先讲名字,repvol1是卷名,client是固定的,0或1是subvolume-index,是brick的一个编号。后面的值看起来一大串,一共有24bit,分三部分,每部分4byte,如下图所示:

分别表示数据,元数据,和entry,数据就是文件内容啦,元数据就是属性这些,entry我不知道翻译成什么好,就是gfid,那么这三个东西每一个变化了在这个扩展属性上都会做相应的变化,怎么变化呢,这三个部分分别是三个计数,操作文件之前要先写计数,简单来说可以理解为加一,操作完就减一,这样最后还是保持0,就表示OK。扩展属性被设置的文件和目录会在/<BRICK>/.glusterfs/indices/xattrop目录中有一个索引,具体如下所示,这个文件的内容好像是会定时清空的,啥时候清空呢?

每一个文件不仅记了自己的状态,还记了所有副本的状态,根据这些状态的组合,有下面几种情况:
IGNORANT:压根没有changelog,比如说这个文件副本已经丢失了,这样的情况changelog也跟着丢失了
INNOCENT :表示自己和其他副本的计数值都是0,表示双方都OK的
FOOL:表示自己的计数不为0,就是说加了没有减,这之间操作出现问题了,而其他副本为0,就是自己有问题别人没问题,让别人来恢复我
WISE:相反,自己是0,别人不是0 ,自己没问题别人有问题,自己来恢复别人。
涉及到数据恢复,有如下几种场景:
1)所有文件都是IGNORANT,这是手动触发了heal,也就是通过命令,这是怎么恢复呢,就找UID最小的文件作为源,去恢复大小为0的那些文件。
2)有一个节点为WISE,其他事FOOL,或其他非WISE的状态,那么就以WISE去恢复其他节点。
3)好几个都是WISE,就是好几个副本都说自己正常,同时还说别人不正常,这就是脑裂现象,这样就必须靠管理员手动找出脑裂的副本,自行判断哪些是对的哪些不对,自行恢复了,通常的做法留下一个对的副本,其他都删除,同样还要删除 /<BRICK>/.glusters这个目录下对应的文件,这样就只有一个WISE副本了,再出发heal,就以这个为源恢复所有副本了,触发命令为 gluster volume heal <VOLMUENAME> full,这里的full是一种自愈方式,全部恢复文件,另一种自愈方式叫diff,是差异化恢复。
通常脑裂的文件时读不出来的,读写它时会报Input/Output error,查看日志/var/log/glusterfs/glustershd.log你会有收获:

要找到脑裂文件,还有一个命令可以用,gluster volume heal <VOLMUENAME> info split-brain,它的输出如下:

正常情况下,所有brick的entries都是0,这里同一个副本一个是1一个是0,就是不对劲了,通过此方法找到脑裂的文件,再按上面的方法删除也可以。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号