
GlusterFS分布式存储学习笔记
分布式文件系统
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源并不直接与本地节点相连,而是分布于计算网络中的一个或者多个节点的计算机上。目前意义上的分布式文件系统大多都是由多个节点计算机构成,结构上是典型的客户机/服务器模式。流行的模式是当客户机需要存储数据时,服务器指引其将数据分散的存储到多个存储节点上,以提供更快的速度,更大的容量及更好的冗余特性。
分布式文件系统的产生
计算机通过文件系统管理、存储数据,而现在数据信息爆炸的时代中人们可以获取的数据成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储容量的方式,已经不能满足目前的需求。
分布式文件系统可以有效解决数据的存储和管理难题,将固定于某个地点的某个文件系统,扩展到任意多个地点/多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点从获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据。
.典型代表NFS
NFS(Network File System)即网络文件系统,它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。
.NFS的优点如下:
1)节约使用的磁盘空间
客户端经常使用的数据可以集中存放在一台机器上,并使用NFS发布,那么网络内部所有计算机可以通过网络访问,不必单独存储。
2)节约硬件资源
NFS还可以共享软驱,CDROM和ZIP等的存储设备,减少整个网络上的可移动设备的数量。
3)用户主目录设定
对于特殊用户,如管理员等,为了管理的需要,可能会经常登录到网络中所有的计算机,若每个客户端,均保存这个用户的主目录很繁琐,而且不能保证数据的一致性.实际上,经过NFS服务的设定,然后在客户端指定这个用户的主目录位置,并自动挂载,就可以在任何计算机上使用用户主目录的文件。
.NFS面临的问题
1)存储空间不足,需要更大容量的存储。
2)直接用NFS挂载存储,有一定风险,存在单点故障。
3)某些场景不能满足要求,大量的访问磁盘IO是瓶颈。
目前流行的分布式文件系统有许多,如MooseFS、FastDFS、GlusterFS、Ceph、MogileFS等,常见的分布式存储对比如下:
- FastDFS:一个开源的轻量级分布式文件系统,是纯C语言开发的。它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。FastDFS 针对大量小文件存储有优势。
- GlusterFS:主要应用在集群系统中,具有很好的可扩展性。软件的结构设计良好,易于扩展和配置,通过各个模块的灵活搭配以得到针对性的解决方案。GlusterFS适合大文件,小文件性能相对较差。
- MooseFS:比较接近GoogleFS的c++实现,通过fuse支持了标准的posix,支持FUSE,相对比较轻量级,对master服务器有单点依赖,用perl编写,算是通用的文件系统,可惜社区不是太活跃,性能相对其他几个来说较差,国内用的人比较多。
- Ceph:C++编写,性能很高,支持Fuse,并且没有单点故障依赖;Ceph 是一种全新的存储方法,对应于 Swift 对象存储。在对象存储中,应用程序不会写入文件系统,而是使用存储中的直接 API 访问写入存储。因此,应用程序能够绕过操作系统的功能和限制。在openstack社区比较火,做虚机块存储用的很多!
- GoogleFS:性能十分好,可扩展性强,可靠性强。用于大型的、分布式的、对大数据进行访问的应用。运用在廉价的硬件上。
GlusterFS存储基础梳理
GlusterFS系统是一个可扩展的网络文件系统,相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。Glusterfs是一个横向扩展的分布式文件系统,就是把多台异构的存储服务器的存储空间整合起来给用户提供统一的命名空间。用户访问存储资源的方式有很多,可以通过NFS,SMB,HTTP协议等访问,还可以通过gluster本身提供的客户端访问。
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
GlusterFS 适合大文件还是小文件存储?弹性哈希算法和Stripe 数据分布策略,移除了元数据依赖,优化了数据分布,提高数据访问并行性,能够大幅提高大文件存储的性能。对于小文件,无元数据服务设计解决了元数据的问题。但GlusterFS 并没有在I/O 方面作优化,在存储服务器底层文件系统上仍然是大量小文件,本地文件系统元数据访问是一个瓶颈,数据分布和并行性也无法充分发挥作用。因此,GlusterFS 适合存储大文件,小文件性能较差,还存在很大优化空间。
GlusterFS 在企业中应用场景
理论和实践上分析,GlusterFS目前主要适用大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能都表现不佳。海量小文件LOSF问题是工业界和学术界公认的难题,GlusterFS作为通用的分布式文件系统,并没有对小文件作额外的优化措施,性能不好也是可以理解的。
Media − 文档、图片、音频、视频
Shared storage − 云存储、虚拟化存储、HPC(高性能计算)
Big data − 日志文件、RFID(射频识别)数据
1)GlusterFS存储的几个术语
Brick:GlusterFS中的存储单元,通过是一个受信存储池中的服务器的一个导出目录。可以通过主机名和目录名来标识,如'SERVER:EXPORT'。
Client:挂载了GlusterFS卷的设备。
GFID:GlusterFS卷中的每个文件或目录都有一个唯一的128位的数据相关联,其用于模拟inode
Namespace:每个Gluster卷都导出单个ns作为POSIX的挂载点。
Node:一个拥有若干brick的设备。
RDMA:远程直接内存访问,支持不通过双方的OS进行直接内存访问。
RRDNS:round robin DNS是一种通过DNS轮转返回不同的设备以进行负载均衡的方法
Self-heal:用于后台运行检测复本卷中文件和目录的不一致性并解决这些不一致。
Split-brain:脑裂
Volfile:Glusterfs进程的配置文件,通常位于/var/lib/glusterd/vols/volname
Volume:一组bricks的逻辑集合
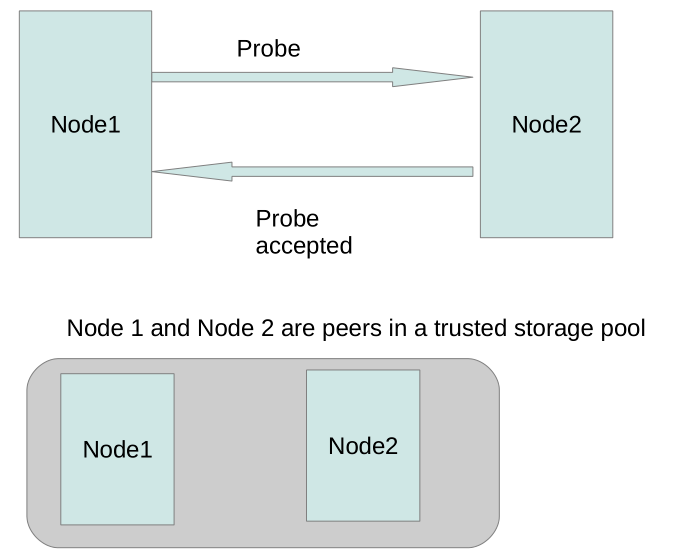
a)Trusted Storage Pool
• 一堆存储节点的集合
• 通过一个节点“邀请”其他节点创建,这里叫probe
• 成员可以动态加入,动态删除
添加命令如下:
node1# gluster peer probe node2
删除命令如下:
node1# gluster peer detach node3
2)Bricks
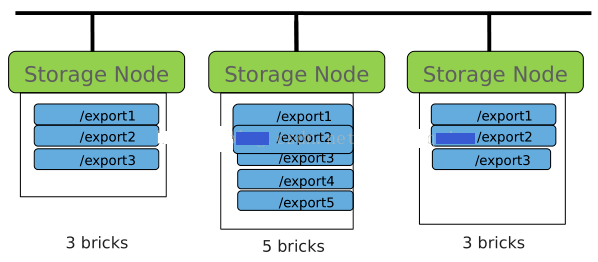
• Brick是一个节点和一个导出目录的集合,e.g. node1:/brick1
• Brick是底层的RAID或磁盘经XFS或ext4文件系统格式化而来,所以继承了文件系统的限制
• 每个节点上的brick数是不限的
• 理想的状况是,一个集群的所有Brick大小都一样。
3)Volumes
• Volume是brick的逻辑组合
• 创建时命名来识别
• Volume是一个可挂载的目录
• 每个节点上的brick数是不变的,e.g.mount –t glusterfs www.std.com:test /mnt/gls
• 一个节点上的不同brick可以属于不同的卷
• 支持如下种类:
a) 分布式卷
b) 条带卷
c) 复制卷
d) 分布式复制卷
e) 条带复制卷
f) 分布式条带复制卷
3.1)分布式卷
• 文件分布存在不同的brick里
• 目录在每个brick里都可见
• 单个brick失效会带来数据丢失
• 无需额外元数据服务器
3.2)复制卷
• 同步复制所有的目录和文件
• 节点故障时保持数据高可用
• 事务性操作,保持一致性
• 有changelog
• 副本数任意定
3.3)分布式复制卷
• 最常见的一种模式
• 读操作可以做到负载均衡
3.4)条带卷
• 文件切分成一个个的chunk,存放于不同的brick上
• 只建议在非常大的文件时使用(比硬盘大小还大)
• Brick故障会导致数据丢失,建议和复制卷同时使用
• Chunks are files with holes – this helps in maintaining offset consistency.
2)GlusterFS无元数据设计
元数据是用来描述一个文件或给定区块在分布式文件系统中所在的位置,简而言之就是某个文件或某个区块存储的位置。传统分布式文件系统大都会设置元数据服务器或者功能相近的管理服务器,主要作用就是用来管理文件与数据区块之间的存储位置关系。相较其他分布式文件系统而言,GlusterFS并没有集中或者分布式的元数据的概念,取而代之的是弹性哈希算法。集群中的任何服务器和客户端都可以利用哈希算法、路径及文件名进行计算,就可以对数据进行定位,并执行读写访问操作。
这种设计带来的好处是极大的提高了扩展性,同时也提高了系统的性能和可靠性;另一显著的特点是如果给定确定的文件名,查找文件位置会非常快。但是如果要列出文件或者目录,性能会大幅下降,因为列出文件或者目录时,需要查询所在节点并对各节点中的信息进行聚合。此时有元数据服务的分布式文件系统的查询效率反而会提高许多。
3)GlusterFS服务器间的部署
在之前的版本中服务器间的关系是对等的,也就是说每个节点服务器都掌握了集群的配置信息,这样做的好处是每个节点度拥有节点的配置信息,高度自治,所有信息都可以在本地查询。每个节点的信息更新都会向其他节点通告,保证节点间信息的一致性。但如果集群规模较大,节点众多时,信息同步的效率就会下降,节点信息的非一致性概率就会大大提高。因此GlusterFS未来的版本有向集中式管理变化的趋势。
4)Gluster技术特点
GlusterFS在技术实现上与传统存储系统或现有其他分布式文件系统有显著不同之处,主要体现在如下几个方面。
a)完全软件实现(SoftwareOnly)
GlusterFS认为存储是软件问题,不能够把用户局限于使用特定的供应商或硬件配置来解决。GlusterFS采用开放式设计,广泛支持工业标准的存储、网络和计算机设备,而非与定制化的专用硬件设备捆绑。对于商业客户,GlusterFS可以以虚拟装置的形式交付,也可以与虚拟机容器打包,或者是公有云中部署的映像。开源社区中,GlusterFS被大量部署在基于廉价闲置硬件的各种操作系统上,构成集中统一的虚拟存储资源池。简言之,GlusterFS是开放的全软件实现,完全独立于硬件和操作系统。
b)完整的存储操作系统栈(CompleteStorage Operating System Stack)
GlusterFS不仅提供了一个分布式文件系统,而且还提供了许多其他重要的分布式功能,比如分布式内存管理、I/O调度、软RAID和自我修复等。GlusterFS汲取了微内核架构的经验教训,借鉴了GNU/Hurd操作系统的设计思想,在用户空间实现了完整的存储操作系统栈。
c)用户空间实现(User Space)
与传统的文件系统不同,GlusterFS在用户空间实现,这使得其安装和升级特别简便。另外,这也极大降低了普通用户基于源码修改GlusterFS的门槛,仅仅需要通用的C程序设计技能,而不需要特别的内核编程经验。
d)模块化堆栈式架构(ModularStackable Architecture)
GlusterFS采用模块化、堆栈式的架构,可通过灵活的配置支持高度定制化的应用环境,比如大文件存储、海量小文件存储、云存储、多传输协议应用等。每个功能以模块形式实现,然后以积木方式进行简单的组合,即可实现复杂的功能。比如,Replicate模块可实现RAID1,Stripe模块可实现RAID0,通过两者的组合可实现RAID10和RAID01,同时获得高性能和高可性。
e)原始数据格式存储(DataStored in Native Formats)
GlusterFS无元数据服务设计(NoMetadata with the Elastic Hash Algorithm)以原始数据格式(如EXT3、EXT4、XFS、ZFS)储存数据,并实现多种数据自动修复机制。因此,系统极具弹性,即使离线情形下文件也可以通过其他标准工具进行访问。如果用户需要从GlusterFS中迁移数据,不需要作任何修改仍然可以完全使用这些数据。
对Scale-Out存储系统而言,最大的挑战之一就是记录数据逻辑与物理位置的映像关系,即数据元数据,可能还包括诸如属性和访问权限等信息。传统分布式存储系统使用集中式或分布式元数据服务来维护元数据,集中式元数据服务会导致单点故障和性能瓶颈问题,而分布式元数据服务存在性能负载和元数据同步一致性问题。特别是对于海量小文件的应用,元数据问题是个非常大的挑战。
GlusterFS独特地采用无元数据服务的设计,取而代之使用算法来定位文件,元数据和数据没有分离而是一起存储。集群中的所有存储系统服务器都可以智能地对文件数据分片进行定位,仅仅根据文件名和路径并运用算法即可,而不需要查询索引或者其他服务器。这使得数据访问完全并行化,从而实现真正的线性性能扩展。无元数据服务器极大提高了GlusterFS的性能、可靠性和稳定性。
5)Glusterfs整体工作流程(即GlusterFS数据访问流程)
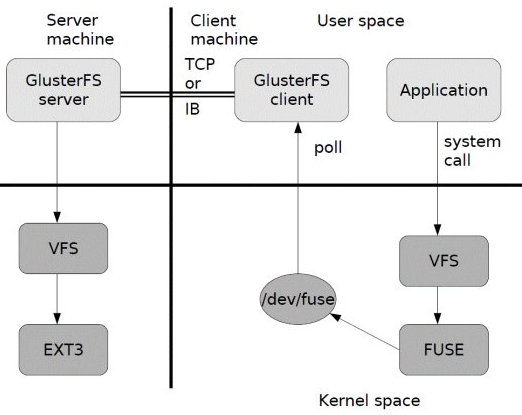
a)首先是在客户端, 用户通过glusterfs的mount point 来读写数据, 对于用户来说,集群系统的存在对用户是完全透明的,用户感觉不到是操作本地系统还是远端的集群系统。
b)用户的这个操作被递交给 本地linux系统的VFS来处理。
c)VFS 将数据递交给FUSE 内核文件系统:在启动 glusterfs 客户端以前,需要想系统注册一个实际的文件系统FUSE,如上图所示,该文件系统与ext3在同一个层次上面, ext3 是对实际的磁盘进行处理, 而fuse 文件系统则是将数据通过/dev/fuse 这个设备文件递交给了glusterfs client端。所以, 我们可以将 fuse文件系统理解为一个代理。
d)数据被fuse 递交给Glusterfs client 后, client 对数据进行一些指定的处理(所谓的指定,是按照client 配置文件据来进行的一系列处理, 我们在启动glusterfs client 时需要指定这个文件。
e)在glusterfs client的处理末端,通过网络将数据递交给 Glusterfs Server,并且将数据写入到服务器所控制的存储设备上。
这样, 整个数据流的处理就完成了。
GlusterFS客户端访问流程
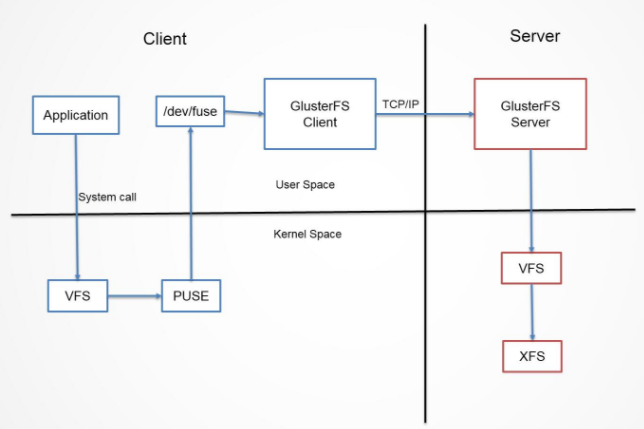
当客户端访问GlusterFS存储时,首先程序通过访问挂载点的形式读写数据,对于用户和程序而言,集群文件系统是透明的,用户和程序根本感觉不到文件系统是本地还是在远程服务器上。读写操作将会被交给VFS(Virtual File System)来处理,VFS会将请求交给FUSE内核模块,而FUSE又会通过设备/dev/fuse将数据交给GlusterFS Client。最后经过GlusterFS Client的计算,并最终经过网络将请求或数据发送到GlusterFS Server上。
6)GlusterFS集群模式
GlusterFS分布式存储集群的模式只数据在集群中的存放结构,类似于磁盘阵列中的级别。
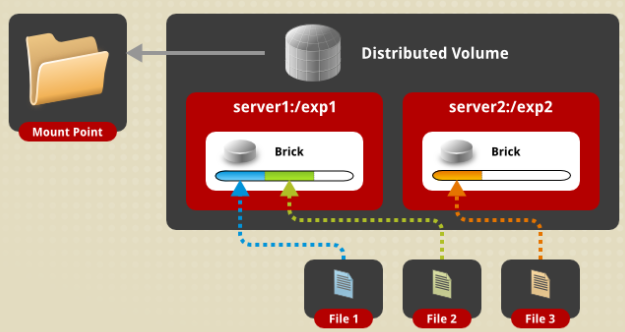
a)分布式卷(Distributed Volume),默认模式,DHT
又称哈希卷,近似于RAID0,文件没有分片,文件根据hash算法写入各个节点的硬盘上,优点是容量大,缺点是没冗余。
# gluster volume create test-volume server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
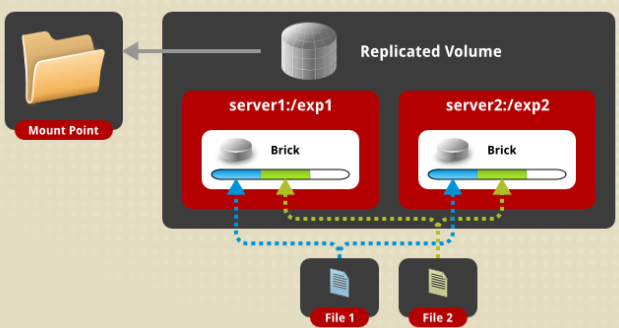
b)复制卷(Replicated Volume),复制模式,AFR
相当于raid1,复制的份数,决定集群的大小,通常与分布式卷或者条带卷组合使用,解决前两种存储卷的冗余缺陷。缺点是磁盘利用率低。复本卷在创建时可指定复本的数量,通常为2或者3,复本在存储时会在卷的不同brick上,因此有几个复本就必须提供至少多个brick,当其中一台服务器失效后,可以从另一台服务器读取数据,因此复制GlusterFS卷提高了数据可靠性的同事,还提供了数据冗余的功能。
# gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2
避免脑裂,加入仲裁:
# gluster volume create replica 3 arbiter 1 host1:brick1 host2:brick2 host3:brick3
c)分布式复制卷(Distributed Replicated Volume),最少需要4台服务器。
# gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4

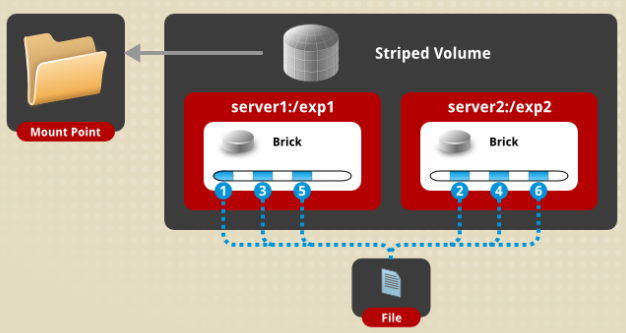
d)条带卷(Striped Volume)
相当于raid0,文件是分片均匀写在各个节点的硬盘上的,优点是分布式读写,性能整体较好。缺点是没冗余,分片随机读写可能会导致硬盘IOPS饱和。
# gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2
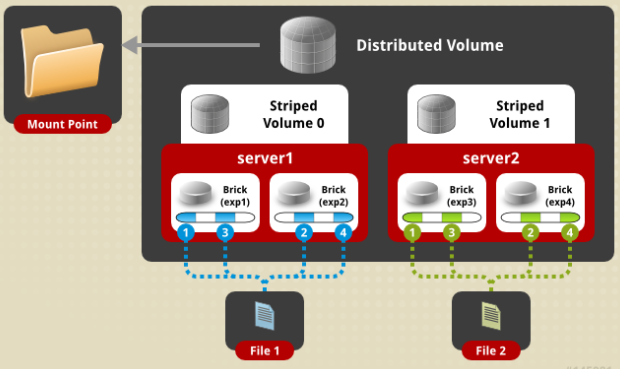
e)分布式条带卷(Distributed Striped Volume),最少需要4台服务器。
当单个文件的体型十分巨大,客户端数量更多时,条带卷已经无法满足需求,此时将分布式与条带化结合起来是一个比较好的选择。其性能与服务器数量有关。
# gluster volume create test-volume stripe 4 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6 server7:/exp7 server8:/exp8
7)Glusterfs存储特点
a)扩展性和高性能
GlusterFS利用双重特性来提供几TB至数PB的高扩展存储解决方案。Scale-Out架构允许通过简单地增加资源来提高存储容量和性能,磁盘、计算和I/O资源都可以独立增加,支持10GbE和InfiniBand等高速网络互联。Gluster弹性哈希(Elastic Hash)解除了GlusterFS对元数据服务器的需求,消除了单点故障和性能瓶颈,真正实现了并行化数据访问。
b)高可用性
GlusterFS可以对文件进行自动复制,如镜像或多次复制,从而确保数据总是可以访问,甚至是在硬件故障的情况下也能正常访问。自我修复功能能够把数据恢复到正确的状态,而且修复是以增量的方式在后台执行,几乎不会产生性能负载。GlusterFS没有设计自己的私有数据文件格式,而是采用操作系统中主流标准的磁盘文件系统(如EXT3、ZFS)来存储文件,因此数据可以使用各种标准工具进行复制和访问。
c)全局统一命名空间
全局统一命名空间将磁盘和内存资源聚集成一个单一的虚拟存储池,对上层用户和应用屏蔽了底层的物理硬件。存储资源可以根据需要在虚拟存储池中进行弹性扩展,比如扩容或收缩。当存储虚拟机映像时,存储的虚拟映像文件没有数量限制,成千虚拟机均通过单一挂载点进行数据共享。虚拟机I/O可在命名空间内的所有服务器上自动进行负载均衡,消除了SAN环境中经常发生的访问热点和性能瓶颈问题。
d)弹性哈希算法
GlusterFS采用弹性哈希算法在存储池中定位数据,而不是采用集中式或分布式元数据服务器索引。在其他的Scale-Out存储系统中,元数据服务器通常会导致I/O性能瓶颈和单点故障问题。GlusterFS中,所有在Scale-Out存储配置中的存储系统都可以智能地定位任意数据分片,不需要查看索引或者向其他服务器查询。这种设计机制完全并行化了数据访问,实现了真正的线性性能扩展。
e)弹性卷管理
数据储存在逻辑卷中,逻辑卷可以从虚拟化的物理存储池进行独立逻辑划分而得到。存储服务器可以在线进行增加和移除,不会导致应用中断。逻辑卷可以在所有配置服务器中增长和缩减,可以在不同服务器迁移进行容量均衡,或者增加和移除系统,这些操作都可在线进行。文件系统配置更改也可以实时在线进行并应用,从而可以适应工作负载条件变化或在线性能调优。
f)基于标准协议
Gluster存储服务支持NFS, CIFS, HTTP, FTP以及Gluster原生协议,完全与POSIX标准兼容。现有应用程序不需要作任何修改或使用专用API,就可以对Gluster中的数据进行访问。这在公有云环境中部署Gluster时非常有用,Gluster对云服务提供商专用API进行抽象,然后提供标准POSIX接口。
8)GlusterFS功能简介
8.1)基本管理功能
GlusterFS服务管理:启动、停止、重启服务;
TrustedStorage Pools管理:增加或删除peer;
Volume管理:增加卷、启动卷、停止卷;
上述这些基本的管理功能不再做介绍。
8.2)TuningVolume Options(调整卷配置)
GlustreFS提供了45项配置用来调整Volume属性,包括端口、cache、安全、存储空间、自愈、日志、扩展性、通讯协议、性能等配置项。用户可以通过gluster volume info命令来查看自定义配置项。
8.3)ConfiguringTransport Types for Volume(配置传输类型)
创建卷的时候,可以选择client与brick的通讯协议。
也可以通过"gluster volume set volnameconfig.transport tcp,rdma OR tcp OR rdma"命令更改通讯协议,需要注意的在更改通讯协议前,必须先停止volume。
默认情况是TCP,根据部署场景可选择RDMA或RDMA+TCP组合,而选择RDMA协议需要相应硬件的支持。
8.4)ExpandingVolumes(扩容)
GlusterFS集群的扩容就是通过增加volume来实现,通过"glustervolume add-brick"命令增加卷。
注意,扩容复制卷的时候,必须同时增加卷的数量是replica的倍数。例如replica 2的集群扩容,需要同时增加2个volume;replica3的集群扩容,需要同时增加3个volume。
8.5)ShrinkingVolumes(缩容)
集群缩减存储空间通过删除卷的“glustervolume remove-brick”命令实现,删除卷的命令执行后,GlustreFS会启动数据迁移,若迁移的数据较大,迁移过程将耗时较长,可能通过命令观察迁移状态。
8.6)Replacefaulty brick(更换坏块)
用好的brick替换故障的brick。
使用方法如下:"glustervolume replace-brick test-volume server3:/exp3 server5:/exp5 commit force",将test-volume卷中的server3:/exp3故障brick替换掉。
8.7)RebalancingVolumes(负载调整)
扩容或缩容卷,集群中可能会出现不同卷的存储利用率较大的不均衡的现象。通过Rebalancing机制,在后台以人工方式来执行负载平滑,将进行文件移动和重新分布,此后所有存储服务器都会均会被调度。为了便于控制管理,rebalance操作分为两个阶段进行实际执行,即FixLayout和MigrateData。
a)FixLayout:修复layout以使得新旧目录下新建文件可以在新增节点上分布上。
b)MigrateData:新增或缩减节点后,在卷下所有节点上进行容量负载平滑。为了提高rebalance效率,通常在执行此操作前先执行FixLayout。
8.8)TriggeringSelf-Heal on Replicate(文件自愈)
在复制卷中,若出现复本间文件不同步的情况,系统每十分钟会自动启动Self-Heal。
也可以主动执行"glustervolume heal"命令触发Self-Heal,通过"gluster volume heal info"可以查看需要heal的文件列表。
在healing过程中,可以通过"gluster volume heal info healed"查看已修复文件的列表;
通过"gluster volume heal info failed"查看修复失败的文件列表。
8.9)Geo-replication(异地备份)
异地备份可以提供数据的灾难恢复。以本地集群作为主存储,异地存储为备份,通过局域网或互联网持续、增量、异步备份数据。
使用"gluster volume geo-replication"相关的命令实现异地备份创建管理。
8.10)Quota(限额管理)
GlusterFS提供目录或卷的存储使用空间的限制设置功能。通过目录限额可以实现对用户按存储容量计费的功能。
使用方法为:"gluster volume quota"
8.11)VolumeSnapshots(卷快照)
卷快照功能用于卷的备份和恢复,在非复制卷的应用场景,通过卷快照实现数据冗余备份。
8.12)MonitoringWorkload(性能监控)
监控每一个brick文件操作的IO性能,主要监控打开fd的数量和最大fd数量、最大读文件调用数、最大写文件调用数、最大打开目录调用数、brick读性能、brcik写性能等。
使用方法:"gluster volume profile"
分析GlusterFS分布式文件系统的缺点
GlusterFS(GNU ClusterFile System)是一个开源的分布式文件系统,它的历史可以追溯到2006年,最初的目标是代替Lustre和GPFS分布式文件系统。经过八年左右的蓬勃发展,GlusterFS目前在开源社区活跃度非常之高,这个后起之秀已经俨然与Lustre、MooseFS、CEPH并列成为四大开源分布式文件系统。由于GlusterFS新颖和KISS(KeepIt as Stupid and Simple)的系统架构,使其在扩展性、可靠性、性能、维护性等方面具有独特的优势,目前开源社区风头有压倒之势,国内外有大量用户在研究、测试和部署应用。
当然,GlusterFS不是一个完美的分布式文件系统,这个系统自身也有许多不足之处,包括众所周知的元数据性能和小文件问题。没有普遍适用各种应用场景的分布式文件系统,通用的意思就是通通不能用,四大开源系统不例外,所有商业产品也不例外。每个分布式文件系统都有它适用的应用场景,适合的才是最好的。这一次我们反其道而行之,不再谈GlusterFS的各种优点,而是深入谈谈GlusterFS当下的问题和不足,从而更加深入地理解GlusterFS系统,期望帮助大家进行正确的系统选型决策和规避应用中的问题。同时,这些问题也是GlusterFS研究和研发的很好切入点。
1)元数据性能
GlusterFS使用弹性哈希算法代替传统分布式文件系统中的集中或分布式元数据服务,这个是GlusterFS最核心的思想,从而获得了接近线性的高扩展性,同时也提高了系统性能和可靠性。GlusterFS使用算法进行数据定位,集群中的任何服务器和客户端只需根据路径和文件名就可以对数据进行定位和读写访问,文件定位可独立并行化进行。
这种算法的特点是,给定确定的文件名,查找和定位会非常快。但是,如果事先不知道文件名,要列出文件目录(ls或ls -l),性能就会大幅下降。对于Distributed哈希卷,文件通过HASH算法分散到集群节点上,每个节点上的命名空间均不重叠,所有集群共同构成完整的命名空间,访问时使用HASH算法进行查找定位。列文件目录时,需要查询所有节点,并对文件目录信息及属性进行聚合。这时,哈希算法根本发挥不上作用,相对于有中心的元数据服务,查询效率要差很多。
从接触的一些用户和实践来看,当集群规模变大以及文件数量达到百万级别时,ls文件目录和rm删除文件目录这两个典型元数据操作就会变得非常慢,创建和删除100万个空文件可能会花上15分钟。如何解决这个问题呢?我们建议合理组织文件目录,目录层次不要太深,单个目录下文件数量不要过多;增大服务器内存配置,并且增大GlusterFS目录缓存参数;网络配置方面,建议采用万兆或者InfiniBand。从研发角度看,可以考虑优化方法提升元数据性能。比如,可以构建全局统一的分布式元数据缓存系统;也可以将元数据与数据重新分离,每个节点上的元数据采用全内存或数据库设计,并采用SSD进行元数据持久化。
2)小文件问题
理论和实践上分析,GlusterFS目前主要适用大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能都表现不佳。海量小文件LOSF问题是工业界和学术界公认的难题,GlusterFS作为通用的分布式文件系统,并没有对小文件作额外的优化措施,性能不好也是可以理解的。
对于LOSF而言,IOPS/OPS是关键性能衡量指标,造成性能和存储效率低下的主要原因包括元数据管理、数据布局和I/O管理、Cache管理、网络开销等方面。从理论分析以及LOSF优化实践来看,优化应该从元数据管理、缓存机制、合并小文件等方面展开,而且优化是一个系统工程,结合硬件、软件,从多个层面同时着手,优化效果会更显著。GlusterFS小文件优化可以考虑这些方法,这里不再赘述,关于小文件问题请参考“海量小文件问题综述”一文。
3)集群管理模式
GlusterFS集群采用全对等式架构,每个节点在集群中的地位是完全对等的,集群配置信息和卷配置信息在所有节点之间实时同步。这种架构的优点是,每个节点都拥有整个集群的配置信息,具有高度的独立自治性,信息可以本地查询。但同时带来的问题的,一旦配置信息发生变化,信息需要实时同步到其他所有节点,保证配置信息一致性,否则GlusterFS就无法正常工作。在集群规模较大时,不同节点并发修改配置时,这个问题表现尤为突出。因为这个配置信息同步模型是网状的,大规模集群不仅信息同步效率差,而且出现数据不一致的概率会增加。
实际上,大规模集群管理应该是采用集中式管理更好,不仅管理简单,效率也高。可能有人会认为集中式集群管理与GlusterFS的无中心架构不协调,其实不然。GlusterFS 2.0以前,主要通过静态配置文件来对集群进行配置管理,没有Glusterd集群管理服务,这说明glusterd并不是GlusterFS不可或缺的组成部分,它们之间是松耦合关系,可以用其他的方式来替换。从其他分布式系统管理实践来看,也都是采用集群式管理居多,这也算一个佐证,GlusterFS 4.0开发计划也表现有向集中式管理转变的趋势。
4)容量负载均衡
GlusterFS的哈希分布是以目录为基本单位的,文件的父目录利用扩展属性记录了子卷映射信息,子文件在父目录所属存储服务器中进行分布。由于文件目录事先保存了分布信息,因此新增节点不会影响现有文件存储分布,它将从此后的新创建目录开始参与存储分布调度。这种设计,新增节点不需要移动任何文件,但是负载均衡没有平滑处理,老节点负载较重。GlusterFS实现了容量负载均衡功能,可以对已经存在的目录文件进行Rebalance,使得早先创建的老目录可以在新增存储节点上分布,并可对现有文件数据进行迁移实现容量负载均衡。
GlusterFS目前的容量负载均衡存在一些问题。由于采用Hash算法进行数据分布,容量负载均衡需要对所有数据重新进行计算并分配存储节点,对于那些不需要迁移的数据来说,这个计算是多余的。Hash分布具有随机性和均匀性的特点,数据重新分布之后,老节点会有大量数据迁入和迁出,这个多出了很多数据迁移量。相对于有中心的架构,可谓节点一变而动全身,增加和删除节点增加了大量数据迁移工作。GlusterFS应该优化数据分布,最小化容量负载均衡数据迁移。此外,GlusterFS容量负载均衡也没有很好考虑执行的自动化、智能化和并行化。目前,GlusterFS在增加和删除节点上,需要手工执行负载均衡,也没有考虑当前系统的负载情况,可能影响正常的业务访问。GlusterFS的容量负载均衡是通过在当前执行节点上挂载卷,然后进行文件复制、删除和改名操作实现的,没有在所有集群节点上并发进行,负载均衡性能差。
5)数据分布问题
Glusterfs主要有三种基本的集群模式,即分布式集群(Distributed cluster)、条带集群(Stripe cluster)、复制集群(Replica cluster)。这三种基本集群还可以采用类似堆积木的方式,构成更加复杂的复合集群。三种基本集群各由一个translator来实现,分别由自己独立的命名空间。对于分布式集群,文件通过HASH算法分散到集群节点上,访问时使用HASH算法进行查找定位。复制集群类似RAID1,所有节点数据完全相同,访问时可以选择任意个节点。条带集群与RAID0相似,文件被分成数据块以Round Robin方式分布到所有节点上,访问时根据位置信息确定节点。
哈希分布可以保证数据分布式的均衡性,但前提是文件数量要足够多,当文件数量较少时,难以保证分布的均衡性,导致节点之间负载不均衡。这个对有中心的分布式系统是很容易做到的,但GlusteFS缺乏集中式的调度,实现起来比较复杂。复制卷包含多个副本,对于读请求可以实现负载均衡,但实际上负载大多集中在第一个副本上,其他副本负载很轻,这个是实现上问题,与理论不太相符。条带卷原本是实现更高性能和超大文件,但在性能方面的表现太差强人意,远远不如哈希卷和复制卷,没有被好好实现,连官方都不推荐应用。
6)数据可用性问题
副本(Replication)就是对原始数据的完全拷贝。通过为系统中的文件增加各种不同形式的副本,保存冗余的文件数据,可以十分有效地提高文件的可用性,避免在地理上广泛分布的系统节点由网络断开或机器故障等动态不可测因素而引起的数据丢失或不可获取。GlusterFS主要使用复制来提供数据的高可用性,通过的集群模式有复制卷和哈希复制卷两种模式。复制卷是文件级RAID1,具有容错能力,数据同步写到多个brick上,每个副本都可以响应读请求。当有副本节点发生故障,其他副本节点仍然正常提供读写服务,故障节点恢复后通过自修复服务或同步访问时自动进行数据同步。
一般而言,副本数量越多,文件的可靠性就越高,但是如果为所有文件都保存较多的副本数量,存储利用率低(为副本数量分之一),并增加文件管理的复杂度。目前GlusterFS社区正在研发纠删码功能,通过冗余编码提高存储可用性,并且具备较低的空间复杂度和数据冗余度,存储利用率高。
GlusterFS的复制卷以brick为单位进行镜像,这个模式不太灵活,文件的复制关系不能动态调整,在已经有副本发生故障的情况下会一定程度上降低系统的可用性。对于有元数据服务的分布式系统,复制关系可以是以文件为单位的,文件的不同副本动态分布在多个存储节点上;当有副本发生故障,可以重新选择一个存储节点生成一个新副本,从而保证副本数量,保证可用性。另外,还可以实现不同文件目录配置不同的副本数量,热点文件的动态迁移。对于无中心的GlusterFS系统来说,这些看起来理所当然的功能,实现起来都是要大费周折的。不过值得一提的是,4.0开发计划已经在考虑这方面的副本特性。
7)数据安全问题
GlusterFS以原始数据格式(如EXT4、XFS、ZFS)存储数据,并实现多种数据自动修复机制。因此,系统极具弹性,即使离线情形下文件也可以通过其他标准工具进行访问。如果用户需要从GlusterFS中迁移数据,不需要作任何修改仍然可以完全使用这些数据。
然而,数据安全成了问题,因为数据是以平凡的方式保存的,接触数据的人可以直接复制和查看。这对很多应用显然是不能接受的,比如云存储系统,用户特别关心数据安全。私有存储格式可以保证数据的安全性,即使泄露也是不可知的。GlusterFS要实现自己的私有格式,在设计实现和数据管理上相对复杂一些,也会对性能产生一定影响。
GlusterFS在访问文件目录时根据扩展属性判断副本是否一致,这个进行数据自动修复的前提条件。节点发生正常的故障,以及从挂载点进行正常的操作,这些情况下发生的数据不一致,都是可以判断和自动修复的。但是,如果直接从节点系统底层对原始数据进行修改或者破坏,GlusterFS大多情况下是无法判断的,因为数据本身也没有校验,数据一致性无法保证。
8)Cache一致性
为了简化Cache一致性,GlusterFS没有引入客户端写Cache,而采用了客户端只读Cache。GlusterFS采用简单的弱一致性,数据缓存的更新规则是根据设置的失效时间进行重置的。对于缓存的数据,客户端周期性询问服务器,查询文件最后被修改的时间,如果本地缓存的数据早于该时间,则让缓存数据失效,下次读取数据时就去服务器获取最新的数据。
GlusterFS客户端读Cache刷新的时间缺省是1秒,可以通过重新设置卷参数Performance.cache-refresh-timeout进行调整。这意味着,如果同时有多个用户在读写一个文件,一个用户更新了数据,另一个用户在Cache刷新周期到来前可能读到非最新的数据,即无法保证数据的强一致性。因此实际应用时需要在性能和数据一致性之间进行折中,如果需要更高的数据一致性,就得调小缓存刷新周期,甚至禁用读缓存;反之,是可以把缓存周期调大一点,以提升读性能。
==============GlusterFS分布式系统维护管理手册===================
1)管理说明
在解释系统管理时会提供实例,首先提供一个环境说明。 系统节点: IP 别名 Brick 192.168.2.100 server0 /mnt/sdb1 /mnt/sdc1 /mnt/sdd1 192.168.2.101 server1 /mnt/sdb1 /mnt/sdc1 /mnt/sdd1 192.168.2.102 server2 /mnt/sdb1 /mnt/sdc1 /mnt/sdd1 创建了三个节点,并每台虚拟机 mount 三块磁盘作为 Brick 使用,每个 brick 分配了 30G 的虚拟容量。 实例约定 AFR 卷名: afr_vol DHT 卷名: dht_vol Stripe 卷名: str_vol 客户端挂载点: /mnt/gluster
2)系统部署
2.1) 在每个节点上启动glusterd服务
[root@localhost ~]# service glusterd start
2.2) 添加节点到存储池,在其中一个节点上操作 ,如 server0
[root@localhost ~]# gluster peer probe server1
[root@localhost ~]# gluster peer probe server2
//可以使用 gluster peer status 查看当前有多少个节点,显示不包括该节点
2.3) 创建系统卷, 部署最常见的分布式卷,在 server0上操作
[root@localhost ~]# gluster volume create dht_vol 192.168.2.{100,101,102}:/mnt/sdb1
//分别使用 server0/1/2 的磁盘挂载目录/mnt/sdb1 作为 brick
2.4) 启动系统卷,在 server0上操作
[root@localhost ~]# gluster volume start dht_vol
2.5) 挂载客户端,例如在server2上
[root@localhost ~]# mount.glusterfs server0:/dht_vol /mnt/gluster
//将系统卷挂载到 server2 上的/mnt/gluster 目录下就可以正常使用了。该目录聚合了三个不同主机上的三块磁盘。
//从启动服务到提供全局名字空间,整个部署流程如上。
3)基本系统管理
3.1)节点管理
# gluster peer command 1)节点状态 [root@localhost ~]# gluster peer status //在serser0上操作,只能看到其他节点与 server0 的连接状态 Number of Peers: 2 Hostname: server1 Uuid: 5e987bda-16dd-43c2-835b-08b7d55e94e5 State: Peer in Cluster (Connected) Hostname: server2 Uuid: 1e0ca3aa-9ef7-4f66-8f15-cbc348f29ff7 State: Peer in Cluster (Connected) 2)添加节点 [root@localhost ~]# gluster peer probe HOSTNAME #gluster peer probe server2 //将server2添加到存储池中 3)删除节点 [root@localhost ~]# gluster peer detach HOSTNAME [root@localhost ~]# gluster peer detach server2 //将server2从存储池中移除 //移除节点时,需要确保该节点上没有 brick ,需要提前将 brick 移除
3.2)卷管理
1)创建卷
[root@localhost ~]# gluster volume create NEW-VOLNAME [transport [tcp | rdma | tcp,rdma]]
NEW-BRICK...
-------------创建分布式卷(DHT)-------------
[root@localhost ~]# gluster volume create dht_vol 192.168.2.{100,101,102}:/mnt/sdb1
//DHT 卷将数据以哈希计算方式分布到各个 brick 上,数据是以文件为单位存取,基本达到分布均衡,提供的容量和为各个 brick 的总和。
-------------创建副本卷(AFR)-------------
[root@localhost ~]# gluster volume create afr_vol replica 3 192.168.2.{100,101,102}:/mnt/sdb1
//AFR 卷提供数据副本,副本数为 replica,即每个文件存储 replica 份数,文件不分割,以文件为单位存储;副本数需要等于brick数;当brick数是副本的倍数时,则自动变化为
Replicated-Distributed卷。
[root@localhost ~]# gluster volume create afr_vol replica 2 192.168.2.{100,101,102}:/mnt/sdb1 192.168.2.{100,101,102}:/mnt/sdc1
//每两个 brick 组成一组,每组两个副本,文件又以 DHT 分布在三个组上,是副本卷与分布式卷的组合。
-------------创建条带化卷(Stripe)-------------
[root@localhost ~]# gluster volume create str_vol stripe 3 192.168.2.{100,101,102}:/mnt/sdb1
//Stripe 卷类似 RAID0,将数据条带化,分布在不同的 brick,该方式将文件分块,将文件分成stripe块,分别进行存储,在大文件读取时有优势;stripe 需要等于 brick 数;当 brick 数等于 stripe 数的倍数时,则自动变化为 Stripe-Distributed 卷。
[root@localhost ~]# gluster volume create str_vol stripe 3 192.168.2.{100,101,102}:/mnt/sdb1 192.168.2.{100,101,102}:/mnt/sdc1
//没三个 brick 组成一个组,每组三个 brick,文件以 DHT 分布在两个组中,每个组中将文件条带化成 3 块。
-------------创建Replicated-Stripe-Distributed卷-------------
[root@localhost ~]# gluster volume create str_afr_dht_vol stripe 2 replica 2 192.168.2.{100,101,102}:/mnt/sdb1 192.168.2.{100,101,102}:/mnt/sdc1 192.168.2.{100,101}:/mnt/sdd1
//使用8个 brick 创建一个组合卷,即 brick 数是 stripe*replica 的倍数,则创建三种基本卷的组合卷,若刚好等于 stripe*replica 则为 stripe-Distrbuted 卷。
2)卷 信息
[root@localhost ~]# gluster volume info
//该命令能够查看存储池中的当前卷的信息,包括卷方式、包涵的 brick、卷的当前状态、卷名及 UUID 等。
3)卷 状态
[root@localhost ~]# gluster volume status
//该命令能够查看当前卷的状态,包括其中各个 brick 的状态,NFS 的服务状态及当前 task执行情况,和一些系统设置状态等。
4)启动/ 停止 卷
[root@localhost ~]# gluster volume start/stop VOLNAME
//将创建的卷启动,才能进行客户端挂载;stop 能够将系统卷停止,无法使用;此外 gluster未提供 restart 的重启命令
5)删除卷
[root@localhost ~]# gluster volume delete VOLNAME
//删除卷操作能够将整个卷删除,操作前提是需要将卷先停止
3.3)Brick 管理
1)添加 Brick 若是副本卷,则一次添加的 Bricks 数是 replica 的整数倍;stripe 具有同样的要求。 # gluster volume add-brick VOLNAME NEW-BRICK # gluster volume add-brick dht_vol server3:/mnt/sdc1 //添加 server3 上的/mnt/sdc1 到卷 dht_vol 上。 2)移除 Brick 若是副本卷,则移除的 Bricks 数是 replica 的整数倍;stripe 具有同样的要求。 [root@localhost ~]# gluster volume remove-brick VOLNAME BRICK start/status/commit [root@localhost ~]# gluster volume remove-brick dht_vol server3:/mnt/sdc1 start //GlusterFS_3.4.1 版本在执行移除 Brick 的时候会将数据迁移到其他可用的 Brick 上,当数据迁移结束之后才将 Brick 移除。执行 start 命令,开始迁移数据,正常移除 Brick。 [root@localhost ~]# gluster volume remove-brick dht_vol server3:/mnt/sdc1 status //在执行开始移除 task 之后,可以使用 status 命令进行 task 状态查看。 [root@localhost ~]# gluster volume remove-brick dht_vol server3:/mnt/sdc1 commit //使用 commit 命令执行 Brick 移除,则不会进行数据迁移而直接删除 Brick,符合不需要数据迁移的用户需求。 PS :系统的扩容及缩容可以通过如上节点管理、Brick 管理组合达到目的。 (1) 扩容时,可以先增加系统节点,然后 添加新增节点上的 Brick 即可。 (2) 缩容时,先移除 Brick ,然后再。 进行节点删除则达到缩容的目的,且可以保证数据不丢失。 3)替换 Brick [root@localhost ~]# gluster volume replace-brick VOLNAME BRICKNEW-BRICK start/pause/abort/status/commit [root@localhost ~]# gluster volume replace-brick dht_vol server0:/mnt/sdb1 server0:/mnt/sdc1 start //如上,执行 replcace-brick 卷替换启动命令,使用 start 启动命令后,开始将原始 Brick 的数据迁移到即将需要替换的 Brick 上。 [root@localhost ~]# gluster volume replace-brick dht_vol server0:/mnt/sdb1 server0:/mnt/sdc1 status //在数据迁移的过程中,可以查看替换任务是否完成。 [root@localhost ~]# gluster volume replace-brick dht_vol server0:/mnt/sdb1 server0:/mnt/sdc1 abort //在数据迁移的过程中,可以执行 abort 命令终止 Brick 替换。 [root@localhost ~]# gluster volume replace-brick dht_vol server0:/mnt/sdb1 server0:/mnt/sdc1 commit //在数据迁移结束之后,执行 commit 命令结束任务,则进行Brick替换。使用volume info命令可以查看到 Brick 已经被替换。
4)GlusterFS系统扩展维护
4.1)系统配额
1)开启/关闭系统配额 [root@localhost ~]# gluster volume quota VOLNAME enable/disable //在使用系统配额功能时,需要使用 enable 将其开启;disable 为关闭配额功能命令。 2)设置( 重置) 目录配额 [root@localhost ~]# gluster volume quota VOLNAME limit-usage /directory limit-value [root@localhost ~]# gluster volume quota dht_vol limit-usage /quota 10GB //如上,设置 dht_vol 卷下的 quota 子目录的限额为 10GB。 PS:这个目录是以系统挂载目录为根目录”/”,所以/quota 即客户端挂载目录下的子目录 quota 3)配额查看 [root@localhost ~]# gluster volume quota VOLNAME list [root@localhost ~]# gluster volume quota VOLNAME list /directory name //可以使用如上两个命令进行系统卷的配额查看,第一个命令查看目的卷的所有配额设置,第二个命令则是执行目录进行查看。 //可以显示配额大小及当前使用容量,若无使用容量(最小 0KB)则说明设置的目录可能是错误的(不存在)。
4.2)地域复制(geo-replication)
# gluster volume geo-replication MASTER SLAVE start/status/stop 地域复制 是系统提供的灾备功能,能够将系统的全部数据进行异步的增量备份到另外的磁盘中。 [root@localhost ~]# gluster volume geo-replication dht_vol 192.168.2.104:/mnt/sdb1 start //如上,开始执行将 dht_vol 卷的所有内容备份到 2.104 下的/mnt/sdb1 中的 task,需要注意的是,这个备份目标不能是系统中的 Brick。
4.3)I/O 信息查看
Profile Command 提供接口查看一个卷中的每一个brick的IO信息。 [root@localhost ~]# gluster volume profile VOLNAME start //启动 profiling,之后则可以进行 IO 信息查看 [root@localhost ~]# gluster volume profile VOLNAME info //查看 IO 信息,可以查看到每一个 Brick 的 IO 信息 [root@localhost ~]# gluster volume profile VOLNAME stop //查看结束之后关闭 profiling 功能
4.4)Top 监控
Top command 允许你查看bricks的性能例如:read, write, file open calls, file read calls, file write calls, directory open calls, and directory real calls所有的查看都可以设置 top数,默认100 [root@localhost ~]# gluster volume top VOLNAME open [brick BRICK-NAME] [list-cnt cnt] //查看打开的 fd [root@localhost ~]# gluster volume top VOLNAME read [brick BRICK-NAME] [list-cnt cnt] //查看调用次数最多的读调用 [root@localhost ~]# gluster volume top VOLNAME write [brick BRICK-NAME] [list-cnt cnt] //查看调用次数最多的写调用 [root@localhost ~]# gluster volume top VOLNAME opendir [brick BRICK-NAME] [list-cnt cnt] [root@localhost ~]# gluster volume top VOLNAME readdir [brick BRICK-NAME] [list-cnt cnt] //查看次数最多的目录调用 [root@localhost ~]# gluster volume top VOLNAME read-perf [bs blk-size count count] [brick BRICK-NAME] [list-cnt] //查看每个 Brick 的读性能 [root@localhost ~]# gluster volume top VOLNAME write-perf [bs blk-size count count] [brick BRICK-NAME] [list-cnt cnt] //查看每个 Brick 的写性能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号