
Elasticsearch简单介绍 和 集群环境部署记录
一. ElasticSearch简单介绍
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
ElasticSearch不但包括了全文搜索功能,还可以进行以下工作:
-> 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
-> 实时分析的分布式搜索引擎。
-> 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
Elasticsearch使用案例:
-> 维基百科使用Elasticsearch来进行全文搜做并高亮显示关键词,以及提供search-as-you-type、did-you-mean等搜索建议功能。
-> 英国卫报使用Elasticsearch来处理访客日志,以便能将公众对不同文章的反应实时地反馈给各位编辑。
-> StackOverflow将全文搜索与地理位置和相关信息进行结合,以提供more-like-this相关问题的展现。
-> GitHub使用Elasticsearch来检索超过1300亿行代码。
-> 每天,Goldman Sachs使用它来处理5TB数据的索引,还有很多投行使用它来分析股票市场的变动。
二. Elasticsearch数据写入过程
Lucene 把每次生成的倒排索引,叫做一个段(segment)。然后另外使用一个 commit 文件,记录索引内所有的 segment。而生成 segment 的数据来源,则是内存中的 buffer。
1) 数据写入 --> 进入ES内存 buffer (同时记录到translog)--> 生成倒排索引分片(segment);
2) 将 buffer 中的 segment 先同步到文件系统缓存中,然后再刷写到磁盘;
问题1: ES如何做到实时检索?
由于在buffer中的索引片先同步到文件系统缓存,再刷写到磁盘,因此在检索时可以直接检索文件系统缓存,保证了实时性。这一步刷到文件系统缓存的步骤,在 Elasticsearch 中,是默认设置为 1 秒间隔的,对于大多数应用来说,几乎就相当于是实时可搜索了.
# curl -XPOST http://127.0.0.1:9200/logstash-2019.02.21/_settings -d' { "refresh_interval": "10s" }
问题2: 当segment从文件系统缓存同步到磁盘时发生了错误怎么办? 数据会不会丢失?
由于Elasticsearch 在把数据写入到内存 buffer 的同时,其实还另外记录了一个ranslog日志,如果在这期间故障发生时,Elasticsearch会从commit位置开始,恢复整个translog文件中的记录,保证数据的一致性。等到真正把 segment 刷到磁盘,且 commit 文件进行更新的时候, translog 文件才清空。这一步,叫做 flush。同样,Elasticsearch也提供了 /_flush 接口。
Elasticsearch 的flush操作主要通过以下几个参数控制:
默认设置为:每 30 分钟主动进行一次 flush,或者当 translog 文件大小大于 512MB 时主动触发flush。这两个行为,可以分别通过:
index.translog.flush_threshold_period 每隔多长时间执行一次flush(默认30m)
index.translog.flush_threshold_size 当事务日志大小到达此预设值,则执行flush。(默认512mb)
index.translog.flush_threshold_ops 当事务日志累积到多少条数据后flush一次。
问题3: 索引数据的一致性通过 translog 保证。那么 translog 文件自己呢?
Elasticsearch 2.0 以后为了保证不丢失数据,每次 index、bulk、delete、update 完成的时候,一定触发刷新 translog 到磁盘上,才给请求返回 200 OK。这个改变在提高数据安全性的同时当然也降低了一点性能。如果你不在意这点可能性,还是希望性能优先,可以在 index template 里设置如下参数:
"index.translog.durability": "async"
三. segment merge 对写入性能的影响
Elasticsearch会不断在后台运行任务,主动将这些零散的 segment 做数据归并,尽量让索引内只保有少量的,每个都比较大的,segment 文件。这个过程是有独立的线程来进行的,并不影响新 segment 的产生。
当归并完成,较大的这个 segment 刷到磁盘后,commit 文件做出相应变更,删除之前几个小 segment,改成新的大 segment。等检索请求都从小 segment 转到大 segment 上以后,删除没用的小 segment。这时候,索引里 segment 数量就下降了
segment 归并的过程,需要先读取 segment,归并计算,再写一遍 segment,最后还要保证刷到磁盘。可以说,这是一个非常消耗磁盘 IO 和 CPU 的任务。所以,ES 提供了对归并线程的限速机制,确保这个任务不会过分影响到其他任务。
默认情况下,归并线程的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。对于 ELK Stack 应用,建议可以适当调大到 100MB或者更高。
通过API的设置方式,也可以写在配置文件中:
curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}'
用于控制归并线程的数目,推荐设置为cpu核心数的一半。 如果觉得自己磁盘性能跟不上,可以降低配置,免得IO情况瓶颈。
index.merge.scheduler.max_thread_count
Elasticsearch的归并策略
归并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
index.merge.policy.floor_segment 默认 2MB,小于这个大小的 segment,优先被归并。
index.merge.policy.max_merge_at_once 默认一次最多归并 10 个 segment
index.merge.policy.max_merge_at_once_explicit 默认 optimize 时一次最多归并 30 个 segment。
index.merge.policy.max_merged_segment 默认 5 GB,大于这个大小的 segment,不用参与归并。optimize 除外。
Elasticsearch的optimize 接口
既然默认的最大 segment 大小是 5GB。那么一个比较庞大的数据索引,就必然会有为数不少的 segment 永远存在,这对文件句柄,内存等资源都是极大的浪费。但是由于归并任务太消耗资源,所以一般不太选择加大 index.merge.policy.max_merged_segment 配置,而是在负载较低的时间段,通过 optimize 接口,强制归并 segment.
curl -XPOST http://127.0.0.1:9200/logstash-2015-06.10/_optimize?max_num_segments=1
由于 optimize 线程对资源的消耗比普通的归并线程大得多,所以,绝对不建议对还在写入数据的热索引执行这个操作。
四. Elasticsearch副本分片的存储过程
默认情况下Elasticsearch通过对每个数据的id值进行哈希计算,对索引的主分片取余,就是数据实际应该存储的分片ID。由于取余这个计算,完全依赖于分母,所以导致Elasticsearch索引有一个限制,索引的主分片数,不可以随意修改。因为一旦主分片数不一样,所以数据的存储位置计算结果都会发生改变,索引数据就完全不可读了。
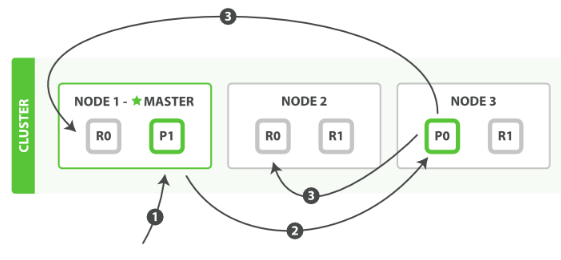
有副本配置情况下,Elasticsearch的写入流程
1) 客户端请求发送给Node1节点,图中的Node1是Master节点,实际环境中也可以不是(通常Master节点和Data_Node部署在不同的服务器)。
2) Node 1 用数据的 _id 取余计算得到应该讲数据存储到 P0 上。通过 cluster state 信息发现 P0 的主分片已经分配到了 Node 3 上。Node 1 转发请求数据给 Node 3。
3) Node3 完成请求数据的索引过程,存入主分片 P0。然后并行转发数据给分配有 P0 的副本分片(R0)的 Node1 和 Node2。当收到任一节点汇报副本分片数据写入成功,Node 3 即返回给初始的接收节点 Node 1,宣布数据写入成功。Node 1 返回成功响应给客户端.
副本配置和分片配置不一样,是可以随时调整的。有些较大的索引,甚至可以在做 optimize 前,先把副本全部取消掉,等 optimize 完后,再重新开启副本,节约单个 segment 的重复归并消耗.
curl -XPUT http://127.0.0.1:9200/logstash-mweibo-2015.05.02/_settings -d '{ "index": { "number_of_replicas" : 0 } }'
五. Elasticsearch的fielddata
indices.fielddata.cache.size 节点用于 fielddata 的最大内存,如果 fielddata 达到该阈值,就会把旧数据交换出去。该参数可以设置百分比或者绝对值。默认设置是不限制,所以强烈建议设置该值,比如 10%。
需要注意: indices.fielddata.cache.expire 这个参数绝对绝对不要设置!
indices.breaker.fielddata.limit 默认值是JVM堆内存的60%,注意为了让设置正常生效,一定要确保 indices.breaker.fielddata.limit 的值大于 indices.fielddata.cache.size 的值。否则的话,fielddata 大小一到 limit 阈值就报错,就永远道不了 size 阈值,无法触发对旧数据的交换任务了。
六. Elasticsearch全文搜索
Elasticsearch对搜索请求,有简易语法和完整语法两种方式。简易语法作为以后在 Kibana 上最常用的方式.
# 命令行示例: curl -XGET http://127.0.0.1:9200/logstash-2019.06.21/log/_search?q=first # curl指令 -请求方式 http://服务器IP:端口/索引库名称/_type(索引类型)/_search?q=querystring 语法
?q=后面跟的是querystring 语法,这种语法在Kibana上是通用的
querystring 语法解析:
-> 全文检索:直接写搜索的单词,如 q=Shanghai
-> 单字段的全文检索:比如知道想检索的信息可能出现在某字段中,可以在搜索单词之前加上字段名和冒号,如:q=name:tuchao
-> 单字段的精确检索:在搜索单词前后加双引号,比如 clientip:"192.168.12.1"
-> 多个检索条件的组合:可以使用 NOT, AND 和 OR 来组合检索,注意必须是大写。比如:
http://127.0.0.1:9200/logstash-nginxacclog-2019.02.23/_search?q=status:>400 AND size:168
字段是否存在:_exists_:user 表示要求 user 字段存在,_missing_:user 表示要求 user 字段不存在;
通配符:用 ? 表示单字母,* 表示任意个字母。比如 fir?t mess*
正则: 不建议使用
近似搜索:用 ~ 表示搜索单词可能有一两个字母写的不对,请 ES 按照相似度返回结果。比如 frist~;
七. Elasticsearch映射的定制
Elasticsearch 是一个 schema-less 的系统,会尽量根据 JSON 源数据的基础类型猜测你想要的字段类型映射。如果你对这种动态生成的映射关系不满意,或者想要使用一些更高级的映射设置,那么就需要使用自定义映射。Elasticsearch可以随时根据数据中的新字段来创建新的映射关系。我们也可以在还没有正式数据写入之前,先创建一个基础的映射。等后续数据有其他字段时,ES 也一样会自动处理。Elasticsearch映射的创建方式如下:
curl -XPUT http://127.0.0.1:9200/logstash-2019.02.20/_mapping -d '
{
"mappings": {
"syslog" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"message" : {
"type" : "string"
},
"pid" : {
"type" : "long"
}
}
}
}
}'
注意:对于已存在的映射,Elasticsearch的自动处理仅限于新字段出现。已经生成的字段映射,是不可变更的。 如果确实需要,可以参考reindex接口.
而如果是新增一个字段映射的更新,那还是可以通过 /_mapping 接口直接完成的:
curl -XPUT http://127.0.0.1:9200/logstash-2019.02.21/_mapping/syslog -d '
{
"properties" : {
"syslogtag" : {
"type" : "string",
"index": "not_analyzed"
}
}
}'
这里只需要单独写这个新字段的内容就够了。ES 会自动合并进去。
Elasticsearch 删除映射
删除数据并不代表会删除数据的映射。比如:
curl -XDELETE http://127.0.0.1:9200/logstash-2019.02.21/syslog
删除了索引下 syslog 的全部数据,但是 syslog 的映射还在。删除映射(同时也就删掉了数据)的命令是:
curl -XDELETE http://127.0.0.1:9200/logstash-2019.02.21/_mapping/syslog
当然,如果删除整个索引,那映射也是同时被清除的。
查看已有数据的映射
用 logstash 写入 ES 的数据,都会根据 logstash 自带的 template,生成一个很有学习意义的映射:
curl -XGET http://127.0.0.1:9200/logstash-nginxacclog-2019.02.20/_mapping/
Elasticsearch特殊字段
Elasticsearch有一些默认的特殊字段,这些字段统一以_下划线开头。如_index,_type,_id。默认不开启的还有 _ttl,_timestamp,_size,_parent 等;这里介绍两个对我们索引和检索性能都有较大影响的:
_all
_all 里存储了各字段的数据内容。其作用是,在检索的时候,如果无法或者未指明具体搜索哪个字段的数据,那么 ES 默认就会是从 _all 里去查找。对于日志场景,如果你的日志划分出来的字段比较少且数目固定。那么,完全可以关闭掉 _all 功能,节省这部分 IO 和 CPU:
"_all" : {
"enabled" : false
}
_source
_source 里存储了该条记录的 JSON 源数据内容。这部分内容只是按照 ES 接收到的内容原样存储下来,并不经过索引过程。对于 ES 的请求过程来说,它不参与 Query 阶段,而只用于 Fetch 阶段。我们在 GET 或者 /_search 时看到的数据内容,都是从 _source 里获取到的。所以,虽然 _source 也重复了一遍索引中的数据,一般我们并不建议关闭这个功能。因为一旦关闭,你搜索的结果除了一个 _id,啥都看不到。对于日志场景,意义不是很大。
当然,也有少数场景是可以关闭 _source 的:
-> 把Elasticsearch作为时间序列数据库使用,只要聚合统计结果,不要源数据内容。
-> 把Elasticsearch作为纯检索工具使用,_id 对应的内容在 HDFS 上另外存储,搜索后使用所得 _id 去 HDFS 上读取内容。
八. Elasticsearch动态模板映射
当你有一类相似的数据字段,想要统一设置其映射,就可以用到这项功能 动态模板映射(dynamic_templates)
"_default_" : {
"dynamic_templates" : [ {
"message_field" : {
"mapping" : {
"index" : "analyzed",
"omit_norms" : true,
"store" : false,
"type" : "string"
},
"match" : "*msg",
"match_mapping_type" : "string"
}
}, {
"string_fields" : {
"mapping" : {
"index" : "not_analyzed",
"ignore_above" : 256,
"store" : false,
"doc_values" : true,
"type" : "string"
},
"match" : "*",
"match_mapping_type" : "string"
}
} ],
"properties" : {
}
}
这样只会匹配字符串类型字段名以 msg 结尾的,都会经过全文索引,其他字符串字段则进行精确索引。同理,还可以继续书写其他类型(long, float, date 等)的 match_mapping_type 和 match。
Elasticsearch索引模板
对每个希望自定义映射的索引,都要定时提前通过发送 PUT 请求的方式创建索引的话,未免太过麻烦。Elasticsearch对此设计了索引模板功能。我们可以针对同一类索引,定制相同的模板。模板中的内容包括两大类,setting(设置)和 mapping(映射)。setting 部分,多为在 elasticsearch.yml 中可以设置全局配置的部分,而 mapping 部分,则是这节之前介绍的内容。如下为定义所有以 te 开头的索引的模板:
curl -XPUT http://localhost:9200/_template/template_1 -d '
{
"template" : "te*",
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"type1" : {
"_source" : { "enabled" : false }
}
}
}'
同时,索引模板是有序合并的。如果我们在同一类索引里,又想单独修改某一小类索引的一两处单独设置,可以再累加一层模板:
curl -XPUT http://localhost:9200/_template/template_2 -d '
{
"order" : 1,
"template" : "te*",
"settings" : {
"number_of_shards" : 2
},
"mappings" : {
"type1" : {
"_all" : { "enabled" : false }
}
}
}'
默认的 order 是 0,那么新创建的 order 为 1 的 template_2 在合并时优先级大于 template_1。最终,对tete*/type1 的索引模板效果相当于:
{
"settings" : {
"number_of_shards" : 2
},
"mappings" : {
"type1" : {
"_source" : { "enabled" : false },
"_all" : { "enabled" : false }
}
}
}
注意1: 模版合并可以用在,当不想改变原模版,又想微调模版的相关参数时可使用。 创建一个小模版,设置相关修改的参数,保证template值设置和原模版相同,由于两个模版的template相同,那么当有新的索引被创建时会匹配到两个模版,这时两个模版的配置将会合并,order值大的模版参数,将会覆盖order值小的模版参数。
关于创建小模版的配置编写需要注意几个点:
-> 先认真分析原模版要修改的几个段值的嵌套关系(建议使用网页的json解析工具辅助查看);
-> 小模版不需要写原模版所有内容,只需要写想变更的几个字段值;
-> 小模版不可和原模版同名;
-> 可以通过请求Elasticsearch输出原模版json参考,更改,但是需要删除一些导入不兼容的字段;
注意2: 从Elasticsearch中导出的模版无法直接复制导入,格式有差异
通过访问Elasticsearch中已有模版logstash3,得到以下模版json
http://10.10.1.90:9200/_template/logstash3?pretty

通过删除以上我标红的字符,也就是模版名称段和别名段和多余的符号。 就可以变成以下可以导入的格式.
curl -XPUT http://10.0.8.44:9200/_template/logstash5 -d '
{
"order" : 1,
"template" : "logstash-*",
"settings" : {
"index" : {
"refresh_interval" : "120s"
}
},
"mappings" : {
"_default_" : {
"_all" : {
"enabled" : false
}
}
}
}'
关键参数解释 :
"order":1 优先级
"template":"logstash-*" 匹配索引库的 Pattern
"aliases" : { } 别名段
变更模版配置也是一样的:
1) 访问该模版得到json
curl http://10.0.8.47:9200/_template/logstash3?pretty
2) 变更配置,删除不兼容的字符(以上标红的字符)
3) 删除原模版,重新导入
# 删除模版 curl -XDELETE http://10.0.8.47:9200/_template/logstash3 # 导入 (修改后的template json) curl -XPUT http://10.0.8.47:9200/_template/logstash3 -d '
九. Elasticsearch 常用配置参数总结
# ---------------------------------- Cluster ----------------------------------- # Use a descriptive name for your cluster: # 集群名称,用于定义哪些elasticsearch节点属同一个集群。 cluster.name: bigdata # ------------------------------------ Node ------------------------------------ # 节点名称,用于唯一标识节点,不可重名 node.name: server3 # 1、以下列出了三种集群拓扑模式,如下: # 如果想让节点不具备选举主节点的资格,只用来做数据存储节点。 node.master: false node.data: true # 2、如果想让节点成为主节点,且不存储任何数据,只作为集群协调者。 node.master: true node.data: false # 3、如果想让节点既不成为主节点,又不成为数据节点,那么可将他作为搜索器,从节点中获取数据,生成搜索结果等 node.master: false node.data: false # 这个配置限制了单机上可以开启的ES存储实例的个数,当我们需要单机多实例,则需要把这个配置赋值2,或者更高。 #node.max_local_storage_nodes: 1 # ----------------------------------- Index ------------------------------------ # 设置索引的分片数,默认为5 "number_of_shards" 是索引创建后一次生成的,后续不可更改设置 index.number_of_shards: 5 # 设置索引的副本数,默认为1 index.number_of_replicas: 1 # 索引的刷新频率,默认1秒,太小会造成索引频繁刷新,新的数据写入就慢了。(此参数的设置需要在写入性能和实时搜索中取平衡)通常在ELK场景中需要将值调大一些比如60s,在有_template的情况下,需要设置在应用的_template中才生效。 index.refresh_interval: 120s # ----------------------------------- Paths ------------------------------------ # 数据存储路径,可以设置多个路径用逗号分隔,有助于提高IO。 # path.data: /home/path1,/home/path2 path.data: /home/elk/server3_data # 日志文件路径 path.logs: /var/log/elasticsearch # 临时文件的路径 path.work: /path/to/work # ----------------------------------- Memory ------------------------------------- # 确保 ES_MIN_MEM 和 ES_MAX_MEM 环境变量设置为相同的值,以及机器有足够的内存分配给Elasticsearch # 注意:内存也不是越大越好,一般64位机器,最大分配内存别才超过32G # 当JVM开始写入交换空间时(swapping)ElasticSearch性能会低下,你应该保证它不会写入交换空间 # 设置这个属性为true来锁定内存,同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过 `ulimit -l unlimited` 命令 bootstrap.mlockall: true # 节点用于 fielddata 的最大内存,如果 fielddata # 达到该阈值,就会把旧数据交换出去。该参数可以设置百分比或者绝对值。默认设置是不限制,所以强烈建议设置该值,比如 10%。 indices.fielddata.cache.size: 50mb # indices.fielddata.cache.expire 这个参数绝对绝对不要设置! indices.breaker.fielddata.limit 默认值是JVM堆内存的60%,注意为了让设置正常生效,一定要确保 indices.breaker.fielddata.limit 的值 大于 indices.fielddata.cache.size 的值。否则的话,fielddata 大小一到 limit 阈值就报错,就永远道不了 size 阈值,无法触发对旧数据的交换任务了。 #------------------------------------ Network And HTTP ----------------------------- # 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0 network.bind_host: 192.168.0.1 # 设置其它节点和该节点通信的ip地址,如果不设置它会自动设置,值必须是个真实的ip地址 network.publish_host: 192.168.0.1 # 同时设置bind_host和publish_host上面两个参数 network.host: 192.168.0.1 # 设置集群中节点间通信的tcp端口,默认是9300 transport.tcp.port: 9300 # 设置是否压缩tcp传输时的数据,默认为false,不压缩 transport.tcp.compress: true # 设置对外服务的http端口,默认为9200 http.port: 9200 # 设置请求内容的最大容量,默认100mb http.max_content_length: 100mb # ------------------------------------ Translog ------------------------------------- #当事务日志累积到多少条数据后flush一次。 index.translog.flush_threshold_ops: 50000 # --------------------------------- Discovery -------------------------------------- # 这个参数决定了要选举一个Master至少需要多少个节点,默认值是1,推荐设置为 N/2 + 1,N是集群中节点的数量,这样可以有效避免脑裂 discovery.zen.minimum_master_nodes: 1 # 在java里面GC是很常见的,但在GC时间比较长的时候。在默认配置下,节点会频繁失联。节点的失联又会导致数据频繁重传,甚至会导致整个集群基本不可用。 # discovery参数是用来做集群之间节点通信的,默认超时时间是比较小的。我们把参数适当调大,避免集群GC时间较长导致节点的丢失、失联。 discovery.zen.ping.timeout: 200s discovery.zen.fd.ping_timeout: 200s discovery.zen.fd.ping.interval: 30s discovery.zen.fd.ping.retries: 6 # 设置集群中节点的探测列表,新加入集群的节点需要加入列表中才能被探测到。 discovery.zen.ping.unicast.hosts: ["10.10.1.244:9300",] # 是否打开广播自动发现节点,默认为true discovery.zen.ping.multicast.enabled: false indices.store.throttle.type: merge indices.store.throttle.max_bytes_per_sec: 100mb
十. Elasticsearch调优建议
- 调优集群的稳定性
1) 增大系统最大打开文件描述符数,即65535;
2) 关闭swap,锁定进程地址空间,防止内存swap;
3) JVM调优
-Xms 和 -Xmx 设置成相同值
# 设置方法 # vim /etc/sysconfig/elasticsearch ES_HEAP_SIZE=1g #根据机器的实际情况设置. 默认为2g
Heap Size不超过物理内存的一半,且小于32G
- 调优节点丢失问题
由于在Java里面GC是很常见的,但在GC时间比较长时。在默认配置下, 节点会频繁失联。节点失联又会导致数据频繁重传,甚至导致整个集群基本不可用。我们可以通过参数调整来避免这些问题.

discovery参数ElasticSearch是用来做集群之间发现的,默认设置的超时时间是比较小的。我们把参数适当调大,避免集群GC时间较长导致节点的丢失、失联。
- 调优集群脑裂问题
-> 建议采用角色分离的方法。
-> Master 节点不做数据节点
-> 数据节点也没有资格竞选Master节点。
-> 即不做Master节点,又不做数据节点,就是Client节点,用于响应请求,查询数据。
因为角色混合在一起会产生一个问题,当某个数据节点成为Master之后,它马上就会往其他节点发送数据以保证副本的冗余。如果数据量很大的情况下,这个Master就会一直在传送数据,而其他节点确认Master的请求可能就会被丢掉或者超时,这个时候其他节点就会重新选举新Master,造成集群脑裂。
- 调优索引写入速率
Index调优 (下面这几个参数的调优原理,上面都有详细的解释。)
-> index.refresh_interval: 120s 索引速率与搜索实时直接的平衡;
-> index.translog.flush_threshold_ops: 50000 事务日志的刷新间隔,适当增大可降低磁盘IO;
-> indices.store.throttle.max_bytes_per_sec: 100mb 当磁盘IO比较充足,可增大索引合并的限流值;
- 提高查询速度
严格限制 fielddata cache 占用的内存,最好完全不用。
- 索引日常维护
定时删除过期索引,可以使用工具,或者写脚本跑计划任务;
关闭暂时无需搜索的索引;
对不再更新的索引进行optimize;
十一. Centos7下Elasticsearch集群部署记录
Elasticsearch是一个分布式搜索服务,提供Restful API,底层基于Lucene,采用多shard的方式保证数据安全,并且提供自动resharding的功能,github等大型的站点也都采用Elasticsearch作为其搜索服务。废话在此就不多赘述了,下面记录下CentOS7下Elasticsearch集群部署过程:
1)基础信息
elk-es01.kevin.cn 192.168.10.44 elk-es02.kevin.cn 192.168.10.45 elk-es03.kevin.cn 192.168.10.46 下面操作在三个节点机上都要操作 [root@elk-es01 ~]# systemctl stop firewalld.service [root@elk-es01 ~]# systemctl disable firewalld.service [root@elk-es01 ~]# firewall-cmd --state not running [root@elk-es01 ~]# setenforce 0 setenforce: SELinux is disabled [root@elk-es01 ~]# getenforce Disabled [root@elk-es01 ~]# vim /etc/sysconfig/selinux ...... SELINUX=disabled [root@elk-es01 ~]# cat /etc/hosts ..... 192.168.10.44 elk-es01.kevin.cn 192.168.10.45 elk-es02.kevin.cn 192.168.10.46 elk-es03.kevin.cn [root@elk-es01 ~]# /usr/sbin/ntpdate ntp1.aliyun.com
2)安装java8环境,官方建议5.4版本最至少Java 8或以上(三个节点机都要操作)
[root@elk-es01 ~]# cd /usr/local/src/ [root@elk-es01 src]# ll jdk-8u131-linux-x64_.rpm -rw-r--r-- 1 root root 169983496 Nov 19 2017 jdk-8u131-linux-x64_.rpm [root@elk-es01 src]# rpm -ivh jdk-8u131-linux-x64_.rpm [root@elk-es01 src]# java -version java version "1.8.0_131" Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
3)安装elasticsearch(三个节点机都要操作)
官方下载地址:https://www.elastic.co/downloads/past-releases 这里选择5.6.9版本 [root@elk-es01 src]# pwd /usr/local/src [root@elk-es01 src]# ll /usr/local/src/elasticsearch-5.6.9.rpm -rw-r--r-- 1 root root 33701914 May 28 09:54 /usr/local/src/elasticsearch-5.6.9.rpm [root@elk-es01 src]# rpm -ivh elasticsearch-5.6.9.rpm --force elasticsearch集群配置 [root@elk-es01 src]# cat /etc/elasticsearch/elasticsearch.yml |grep -v "#" cluster.name: kevin-elk #集群名称,三个节点的集群名称配置要一样 node.name: elk-es01.kevin.cn #集群节点名称,一般为本节点主机名。注意这个要是能ping通的,即在各节点的/etc/hosts里绑定。 path.data: /data/es-data #集群数据存放目录 path.logs: /var/log/elasticsearch #日志路径 network.host: 192.168.10.44 #服务绑定的网络地址,一般填写本节点ip;也可以填写0.0.0.0 http.port: 9200 #服务接收请求的端口号 discovery.zen.ping.unicast.hosts: ["192.168.10.44", "192.168.10.45", "192.168.10.46"] #添加集群中的主机地址,会自动发现并自动选择master主节点 另外两个节点的elasticsearch.yml文件配置,如上相似,只需修改节点名和地址即可。 [root@elk-es01 src]# mkdir -p /data/es-data [root@elk-es01 src]# chown -R elasticsearch.elasticsearch /data/es-data #这一步授权不能忘记,否则下面的es服务器启动会失败! 启动elasticsearch [root@elk-es01 src]# systemctl daemon-reload [root@elk-es01 src]# systemctl start elasticsearch [root@elk-es01 src]# systemctl status elasticsearch [root@elk-es01 src]# lsof -i:9200 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 20061 elasticsearch 195u IPv6 1940586 0t0 TCP elk-es01.kevin.cn:wap-wsp (LISTEN)
4)查看集群信息(如下操作在任意一台节点机上都可操作)
注意:Elasticsearch 5.x版本不再支持相关插件,比如elasticsearch-head,解释可以访问官网,实在需要,可以独立运行(此处跳过)。
a)查询集群状态方法
[root@elk-es01 src]# curl -XGET 'http://192.168.10.44:9200/_cat/nodes'
192.168.10.44 8 37 0 0.00 0.01 0.05 mdi - elk-es01.kevin.cn
192.168.10.46 20 36 0 0.00 0.01 0.05 mdi - elk-es03.kevin.cn
192.168.10.45 14 36 0 0.00 0.01 0.05 mdi * elk-es02.kevin.cn #带*号表示该节点是master主节点
后面添加 ?v ,表示详细显示
[root@elk-es01 src]# curl -XGET 'http://192.168.10.44:9200/_cat/nodes?v'
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.10.44 9 37 0 0.00 0.01 0.05 mdi - elk-es01.kevin.cn
192.168.10.46 20 36 0 0.00 0.01 0.05 mdi - elk-es03.kevin.cn
192.168.10.45 16 36 0 0.00 0.01 0.05 mdi * elk-es02.kevin.cn
b)查询集群状态方法
[root@elk-es01 src]# curl -XGET 'http://192.168.10.44:9200/_cluster/state/nodes?pretty'
{
"cluster_name" : "kevin-elk",
"nodes" : {
"8xvAOooeQlK1cilfHGTdHw" : {
"name" : "elk-es01.kevin.cn",
"ephemeral_id" : "9MeQir6KQ-aG0_nlZnq87g",
"transport_address" : "192.168.10.44:9300",
"attributes" : { }
},
"Uq94w9gHRR6ewtI4SoXC2Q" : {
"name" : "elk-es03.kevin.cn",
"ephemeral_id" : "PLZfo1q9TzyJ61v2v4-5aA",
"transport_address" : "192.168.10.46:9300",
"attributes" : { }
},
"NOM0bFmvRDSJDLbJzRsKEQ" : {
"name" : "elk-es02.kevin.cn",
"ephemeral_id" : "VnhtQtjrT4eL3P4C3cY6uA",
"transport_address" : "192.168.10.45:9300",
"attributes" : { }
}
}
}
c)查询集群中的master
[root@elk-es01 src]# curl -XGET 'http://192.168.10.44:9200/_cluster/state/master_node?pretty'
{
"cluster_name" : "kevin-elk",
"master_node" : "NOM0bFmvRDSJDLbJzRsKEQ"
}
或者
[root@elk-es01 src]# curl -XGET 'http://192.168.10.44:9200/_cat/master?v'
id host ip node
NOM0bFmvRDSJDLbJzRsKEQ 192.168.10.45 192.168.10.45 elk-es02.kevin.cn
d)查询集群的健康状态(一共三种状态:green、yellow,red;其中green表示健康。)
[root@elk-es01 src]# curl -XGET 'http://192.168.10.44:9200/_cat/health?v'
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1527489534 14:38:54 kevin-elk green 3 3 2 1 0 0 0 0 - 100.0%
或者
[root@elk-es01 src]# curl -XGET 'http://192.168.10.44:9200/_cluster/health?pretty'
{
"cluster_name" : "kevin-elk",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 1,
"active_shards" : 2,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
=====================下面贴一个之前线上es集群服务追加节点的操作记录======================
之前线上的一个图片搜索业务使用了elasticsearch集群服务, 集群一开始是3个节点, 后来随着业务量增加, 需要再追加一台es节点到这个集群中去. 以下是操作记录: 在追加的那台es节点集群上擦着: 1)安装jdk和elasticsearch jdk-8u5-linux-x64.rpm下载地址: https://pan.baidu.com/s/1bpxtX5X (提取密码:df6s) elasticsearch-5.5.0.rpm下载地址: https://pan.baidu.com/s/1mibwWeG (提取密码:vtm2) [root@qd-vpc-op-es04 ~]# cd tools/ [root@qd-vpc-op-es04 tools]# ls elasticsearch-5.5.0.rpm jdk-8u5-linux-x64.rpm [root@qd-vpc-op-es04 tools]# rpm -ivh elasticsearch-5.5.0.rpm [root@qd-vpc-op-es04 tools]# rpm -ivh jdk-8u5-linux-x64.rpm [root@qd-vpc-op-es04 tools]# java -version java version "1.8.0_05" Java(TM) SE Runtime Environment (build 1.8.0_05-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.5-b02, mixed mode) 2)配置elasticsearch [root@qd-vpc-op-es04 ~]# cd /etc/elasticsearch/ [root@qd-vpc-op-es04 elasticsearch]# ls elasticsearch.yml elasticsearch.yml.bak jvm.options log4j2.properties nohup.out scripts [root@qd-vpc-op-es04 elasticsearch]# cat elasticsearch.yml|grep -v "#" //集群中每个节点的配置内容都基本一致 cluster.name: image_search //集群名称 node.name: image_search_node_4 //集群中本节点的节点名称,这里定义即可 path.data: /data/es/data //服务目录路径 path.logs: /data/es/logs //服务日志路径 discovery.zen.ping.unicast.hosts: ["172.16.50.247","172.16.50.249","172.16.50.254","172.16.50.16"] //这里是各节点的ip地址 network.host: 0.0.0.0 //服务绑定的网络地址 默认elasticsearch服务端口时9200 [root@qd-vpc-op-es04 elasticsearch]# cat elasticsearch.yml|grep 9200 #http.port: 9200 [root@qd-vpc-op-es04 elasticsearch]# systemctl start elasticsearch.service [root@qd-vpc-op-es04 elasticsearch]# systemctl restart elasticsearch.service [root@qd-vpc-op-es04 elasticsearch]# systemctl status elasticsearch.service [root@qd-vpc-op-es04 elasticsearch]# ps -ef|grep elasticsearch [root@qd-vpc-op-es04 elasticsearch]# lsof -i:9200 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 10998 elasticsearch 320u IPv4 39255 0t0 TCP *:wap-wsp (LISTEN) 检查elasticsearch的健康状态 [root@qd-vpc-op-es04 elasticsearch]# curl 'localhost:9200/_cat/indices?v' health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open video_filter Bx7He6ZtTEWuRBqXYC6gRw 5 1 458013 0 4.1gb 2gb green open recommend_history_image svYo_Do4SM6wUiv6taUWug 5 1 2865902 0 24.9gb 12.4gb green open recommend_history_gif rhN3MDN2TbuYILqEDksQSg 5 1 265731 0 2.4gb 1.2gb green open post_images TMsMsMEoR5Sdb7UEQJsR5Q 5 1 48724932 0 407.3gb 203.9gb green open review_images_v2 qzqnknpgTniU4rCsvXzs0w 5 1 50375955 0 61.6gb 30.9gb green open review_images rWC4WlfMS8aGe-GOkTauZg 5 1 51810877 0 439.3gb 219.7gb green open sensitive_images KxSrjvXdSz-y8YcqwBMsZA 5 1 13393 0 128.1mb 64mb green open post_images_v2 FDphBV4-QuKVoD4_G3vRtA 5 1 49340491 0 55.8gb 27.8gb 从上面的命令结果中可以看出,本节点已经成功加入到名为image_search的elasticsearch集群中了,green表示节点状态很健康,数据也已经在同步中了。 3)在代码中更新elasticsearch的配置 通知开发同事,在代码中增加新增elasticsearch节点的配置,上线更新后,到新节点上查看elasticsearch日志是否有信息写入: [root@qd-vpc-op-es04 ~]# cd /data/es/logs/ [root@qd-vpc-op-es04 ~]# chown -R elasticsearch.elasticsearch /data/es [root@qd-vpc-op-es04 logs]# ls image_search_deprecation.log image_search_index_indexing_slowlog.log image_search_index_search_slowlog.log image_search.log ======特别注意======= 如果往elasticsearch集群中新增一个节点,做法如下: 1)在新节点上安装jdk和elasticsearch服务,配置elasticsearch.yml文件了,启动elasticsearch服务 2)在集群中其他节点上配置elasticsearch.yml文件,不需要启动elasticsearch服务 3)在新节点上执行curl 'localhost:9200/_cat/indices?v'命令,查看健康状态以及数据同步情况 4)在代码中增加新增elasticsearch节点的配置,上线更新后,查看新增节点的elasticsearch日志是否有信息写入 ============================================================== 顺便贴一下之前其他三个es节点的elasticsearch.yml文件配置: [root@qd-vpc-op-es01 ~]# cat /etc/elasticsearch/elasticsearch.yml |grep -v "#" cluster.name: image_search node.name: image_search_node_1 path.data: /data/es/data path.logs: /data/es/logs discovery.zen.ping.unicast.hosts: ["172.16.50.16","172.16.50.247","172.16.50.249","172.16.50.254"] network.host: 0.0.0.0 [root@qd-vpc-op-es02 ~]# cat /etc/elasticsearch/elasticsearch.yml |grep -v "#" cluster.name: image_search node.name: image_search_node_2 path.data: /data/es/data path.logs: /data/es/logs discovery.zen.ping.unicast.hosts: ["172.16.50.16","172.16.50.247","172.16.50.249","172.16.50.254"] network.host: 0.0.0.0 [root@qd-vpc-op-es03 ~]# cat /etc/elasticsearch/elasticsearch.yml|grep -v "#" cluster.name: image_search node.name: image_search_node_3 path.data: /data/es/data path.logs: /data/es/logs discovery.zen.ping.unicast.hosts: ["172.16.50.247","172.16.50.249","172.16.50.254","172.16.50.16"] network.host: 0.0.0.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号