
HA高可用集群中"脑裂"问题解决 - 运维总结
------ 什么是脑裂(split-brain)
在"双机热备"高可用(HA)系统中,当联系两个节点的"心跳线"断开时(即两个节点断开联系时),本来为一个整体、动作协调的HA系统,就分裂成为两个独立的节点(即两个独立的个体)。由于相互失去了联系,都以为是对方出了故障,两个节点上的HA软件像"裂脑人"一样,"本能"地争抢"共享资源"、争起"应用服务"。就会发生严重后果:1)或者共享资源被瓜分、两边"服务"都起不来了;2)或者两边"服务"都起来了,但同时读写"共享存储",导致数据损坏(常见如数据库轮询着的联机日志出错)。
两个节点相互争抢共享资源,结果会导致系统混乱,数据损坏。对于无状态服务的HA,无所谓脑裂不脑裂,但对有状态服务(比如MySQL)的HA,必须要严格防止脑裂
[但有些生产环境下的系统按照无状态服务HA的那一套去配置有状态服务,结果就可想而知]。
------ 集群脑裂产生的原因
一般来说,裂脑的发生,有以下几种原因:
1. 高可用服务器各节点之间心跳线链路发生故障,导致无法正常通信。
2. 因心跳线坏了(包括断了,老化)。
3. 因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)。
4. 因心跳线间连接的设备故障(网卡及交换机)。
5. 因仲裁的机器出问题(采用仲裁的方案)。
6. 高可用服务器上开启了iptables防火墙阻挡了心跳消息传输。
7. 高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败。
8. 其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等。
提示: Keepalived配置里同一VRRP实例如果virtual_router_id两端参数配置不一致也会导致裂脑问题发生。
------ 如何预防HA集群脑裂 [目前达成共识的有下面四种对策]
第一种:添加冗余的心跳线 [即冗余通信的方法]
同时使用串行电缆和以太网电缆连接,同时用两条心跳线路 (即心跳线也HA),这样一条线路坏了,另一个还是好的,依然能传送心跳消息,尽量减少"脑裂"现象的发生几率。
第二种方法:设置仲裁机制
当两个节点出现分歧时,由第3方的仲裁者决定听谁的。这个仲裁者,可能是一个锁服务,一个共享盘或者其它什么东西。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅"心跳"、还兼对外"服务"的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。
第三种方法:fence机制 [即共享资源的方法] [前提是必须要有可靠的fence设备]
当不能确定某个节点的状态时 ,通过fence设备强行关闭该心跳节点,确保共享资源被完全释放!相当于Backup备节点接收不到心跳信息,通过单独的线路发送关机命令关闭主节点的电源。
理想情况下,以上第二、三两者一个都不能少。但是如果节点没有使用共享资源,比如基于主从复制的数据库HA,也可以安全的省掉fence设备,只保留仲裁,而且很多时候线上环境里也也可能没有可用的fence设备,比如在云主机里。
那么可不可以省掉仲裁机制,只留fence设备呢?这是不可以的。因为,当两个节点互相失去联络时会同时fencing对方。如果fencing的方式是reboot,那么两台机器就会不停的重启。如果fencing的方式是power off,那么结局有可能是2个节点同归于尽,也有可能活下来一个。但是如果两个节点互相失去联络的原因是其中一个节点的网卡故障,而活下来的正好又是那个有故障的节点,那么结局一样是悲剧。所以说: 单纯的双节点,无论如何也防止不了脑裂。
第四种:启用磁盘锁
正在服务一方锁住共享磁盘,"裂脑"发生时,让对方完全"抢不走"共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动"解锁",另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了"智能"锁。即:正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
------ 没有fence设备是否安全
这里以MySQL的数据复制为例来说明这个问题。在基于复制场景下,主从节点没有共享资源(没有VIP),所以2个节点都活着本身没有问题。问题是客户端会不会访问到本该死掉的那个节点。这又牵扯到客户端路由的问题。客户端路由有几种方式: 基于VIP,基于Proxy,基于DNS或者干脆客户端维护一个服务端地址列表自己判断主从。不管采用哪种方式,主从切换的时候都要更新路由:
1)基于DNS的路由是不太靠谱的,因为DNS可能会被客户端缓存,很难清干净。
2)基于VIP的路由有一些变数,如果本该死掉的节点没有摘掉自己身上的VIP,那么它随时可能出来捣乱(即使新主已经通过arping更新了所有主机上的arp缓存,如果某个主机的arp过期,发一个arp查询,那么就会发生ip冲突)。所以可以认为VIP也是一种特殊的共享资源,必需把它从故障节点上摘掉。至于怎么摘,最简单的办法就是故障节点发现自己失联后自己摘,如果它还活着的话(如果它死了,也就不用摘了)。如果负责摘vip的进程无法工作怎么办?这时候就可以用上本来不太靠谱的软fence设备了(比如ssh)。
3)基于Proxy的路由是比较靠谱的,因为Proxy是唯一的服务入口,只要把Proxy一个地方更新了,就不会发生客户端误访问的问题了,但是也要考虑Proxy的高可用。
4)至于基于服务端地址列表的方法,客户端需要通过后台服务判断主从(比如PostgreSQL/MySQL会话是否处于只读模式)。这时,如果出现2个主,客户端就会错乱。为防止这个问题,原主节点发现自己失联后要自己把服务停掉,这和前面摘vip的道理是一样的。
因此,为了不让故障节点捣乱,故障节点应该在失联后自己释放资源,为了应对释放资源的进程本身出现故障,可以加上软fence。在这个前提下,可以认为没有可靠的物理fence设备也是安全的。
------------------------------------------------------------------------------
什么是Fence设备?
Fence设备是集群中很重要的一个组成部分,通过Fence设备可以避免因出现不可预知的情况而造成的"脑裂"现象, Fence设备主要就是通过服务器或存储本身的硬件管理接口或者外部电源管理设备,来对服务器或存储直接发出硬件管理指令,将服务器重启或关机,或者与网络断开连接。在设备为知故障发生时,Fence负责让占有浮动资源的设备与集群断开。
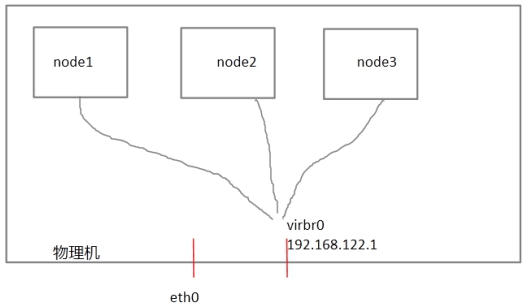
每个节点之间互相发送探测包进行判断节点的存活性。一般会有专门的线路进行探测,这条线路称为"心跳线"(上图直接使用eth0线路作为心跳线)。假设node1的心跳线出问题,则node2和node3会认为node1出问题,然后就会把资源调度在node2或者node3上运行,但node1会认为自己没问题不让node2或者node3抢占资源,此时就出现了"脑裂"(split brain)。此时如果在整个环境里有一种设备直接把node1断电,则可以避免脑裂的发生,这种设备叫做fence或者stonith(Shoot The Other Node In The Head爆头哥)。在物理机里virsh是通过串口线管理虚拟机的,比如virsh destroy nodeX,这里我们把物理机当成fence设备。
------ 主从切换后数据能否保证不丢
主从切换后数据会不会丢和脑裂可以认为是两个不同的问题。这里还以MySQL的数据复制为例来说明。对MySQL,即使配置成半同步复制,在超时发生后,它可能会自动降级为异步复制。为了防止MySQL的复制降级,可以设置一个超大的rpl_semi_sync_master_timeout,同时保持rpl_semi_sync_master_wait_no_slave为on(即默认值)。但是,这时如果从宕了,主也会hang住。这个问题的破解方法可以配置成一主两从,只要不是两个从都宕机就没事,或者由外部的集群监视软件动态切换半同步和异步。如果本来就是配置的异步复制,那就是说已经做好丢数据的准备了。这时候,主从切换时丢点数据也没啥大不了,但要控制自动切换的次数。比如控制已经被failover掉的原主不允许自动上线,否则如果因为网络抖动导致故障切换,那么主从就会不停的来回切,不停的丢数据,破坏数据的一致性。
------ 如何实现"仲裁机制+fence机制"策略,防止集群"脑裂"
可以自己完全从头开始实现一套符合上述逻辑的脚本,但是建议使用成熟的集群软件去搭建,比如Pacemaker+Corosync+合适的资源Agent。Keepalived可能不太适合用于有状态服务的HA,即使把仲裁,fence都加到方案里,也总觉得别扭。
使用Pacemaker+Corosync的方案需要注意:quorum可以认为是Pacemkaer自带的仲裁机制,集群的所有节点中的多数选出一个协调者,集群的所有指令都由这个协调者发出,可以完美的杜绝脑裂问题。为了使这套机制有效运转,集群中至少有三个节点,并且把no-quorum-policy设置成stop,这也是默认值。(注意:no-quorum-policy最好不要设置成ignore,生产环境如果也这么搞,又没有其它仲裁机制,是很危险的!)
但是,如果只有两个节点该怎么办?
1. 拉一个机器借用一下凑足三个节点,再设置location限制,不让资源分配到那个节点上。
2. 把多个不满足quorum小集群拉到一起,组成一个大的集群,同样适用location限制控制资源的分配的位置。
但是如果你有很多双节点集群,找不到那么多用于凑数的节点,又不想把这些双节点集群拉到一起凑成一个大的集群(比如觉得不方便管理)。那么可以考虑第三种方法。
3. 第三种方法是配置一个抢占资源,以及服务和这个抢占资源的colocation约束,谁抢到抢占资源谁提供服务。这个抢占资源可以是某个锁服务,比如基于zookeeper包装一个,或者干脆自己从头做一个,就像下面"corosync+pacemaker双节点脑裂问题处理"的例子:
corosync作为HA方案中成员管理层(membership layer),负责集群成员管理、通信方式(单播、广播、组播)等功能,pacemaker作为CRM层。
在利用corosync+pacemaker双节点主备模式的实践中,可能会遇到一个问题:脑裂问题。
何谓脑裂:
在HA集群中,节点间通过心跳线进行网络通信,一旦心跳网络异常。导致成员互不相认,各自作为集群中的DC,这样资源同时会在主、备两节点启动。
脑裂原因是corosync还是pacemaker导致的?
开始可能认为是corosync,原因在于心跳端导致corosync不能正常通信。
后来发现在pacemaker官网有找到脑裂(split-brain)的方案。pacemaker作为crm,主责是管理资源,还有一个作用是选择leader。
1. 解决方案:为pacemaker配置抢占资源。
原理在于,pacemaker 可以定义资源的执行顺序。如果将独占资源放在最前面,后面的资源的启动则依赖与它,成也独占资源,败也独占资源。
当心跳网络故障时候,谁先抢占到该资源,该节点就接管服务资源,提供服务。这种方案必须解决两个问题,一是必须定义一个抢占资源,二是自定义pacemaker RA,去抢夺资源。
2. 定义抢占资源
下面利用互斥锁来实现独占资源。具体由python实现一个简单的web服务,提供lock,unlock,updatelock服务。
__author__ = 'ZHANGTIANJIONG629'
import BaseHTTPServer
import threading
import time
lock_timeout_seconds = 8
lock = threading.Lock()
lock_client_ip = ""
lock_time = 0
class LockService(BaseHTTPServer.BaseHTTPRequestHandler):
def do_GET(self):
'''define url route'''
pass
def lock(self, client_ip):
global lock_client_ip
global lock_time
# if lock is free
if lock.acquire():
lock_client_ip = client_ip
lock_time = time.time()
self.send_response(200, 'ok')
self.close_connection
return
# if current client hold lock,updte lock time
elif lock_client_ip == client_ip:
lock_time = time.time()
self.send_response(200, 'ok,update')
self.close_connection
return
else:
# lock timeout,grab lock
if time.time() - lock_time > lock_timeout_seconds:
lock_client_ip = client_ip;
lock_time = time.time()
self.send_response(200, 'ok,grab lock')
self.close_connection
return
else:
self.send_response(403, 'lock is hold by other')
self.close_connection
def update_lock(self, client_ip):
global lock_client_ip
global lock_time
if lock_client_ip == client_ip:
lock_time = time.time()
self.send_response(200, 'ok,update')
self.close_connection
return
else:
self.send_response(403, 'lock is hold by other')
self.close_connection
return
def unlock(self, client_ip):
global lock_client_ip
global lock_time
if lock.acquire():
lock.release()
self.send_response(200, 'ok,unlock')
self.close_connection
return
elif lock_client_ip == client_ip:
lock.release()
lock_time = 0
lock_client_ip = ''
self.send_response(200, 'ok,unlock')
self.close_connection
return
else:
self.send_response(403, 'lock is hold by other')
self.close_connection
return
if __name__ == '__main__':
http_server = BaseHTTPServer.HTTPServer(('127.0.0.1', '88888'), LockService)
http_server.serve_forever()
上面这个例子是基于http协议的短连接,更细致的做法是使用长连接心跳检测,这样服务端可以及时检出连接断开而释放锁。但是,一定要同时确保这个抢占资源的高可用,可以把提供抢占资源的服务做成lingyig高可用的,也可以简单点,部署3个服务,双节点上个部署一个,第三个部署在另外一个专门的仲裁节点上,至少获取3个锁中的2个才视为取得了锁。这个仲裁节点可以为很多集群提供仲裁服务(因为一个机器只能部署一个Pacemaker实例,否则可以用部署了N个Pacemaker实例的仲裁节点做同样的事情。)。但是,如非迫不得已,尽量还是采用前面的方法,即满足Pacemaker法定票数,这种方法更简单,可靠。
------ 如何监控"脑裂"情况
1. 在什么服务器上进行"脑裂"情况监控?
在备节点服务器上进行监控,可以使用zabbix监控。
2. 监控什么信息?
备节点服务器上面如果出现vip情况,只可能是下面两种情况
1)脑裂情况出现。
2)正常主备切换也会出现。
3. 编写监控脑裂脚本
[root@slave-node scripts]# vim check_keepalived.sh
#!/bin/bash
# 192.168.10.10是VIP地址
while true
do
if [ `ip a show eth0 |grep 192.168.10.10|wc -l` -ne 0 ]
then
echo "keepalived is error!"
else
echo "keepalived is OK !"
fi
done
[root@slave-node scripts]# chmod 755 check_keepalived.sh
4)测试。确保两个节点的负载均衡能够正常负载
[root@master-node ~]# curl -H Host:www.kevin.cn 192.168.10.30 server-node01 www [root@master-node ~]# curl -H Host:www.kevin.cn 192.168.10.31 server-node01 www [root@slave-node ~]# curl -H Host:www.bobo.cn 192.168.10.31 server-node02 bbs [root@slave-node ~]# curl -H Host:www.kevin.cn 192.168.10.30 server-node03 www
Keepalived脑裂问题分享一
1)解决keepalived脑裂问题
检测思路:正常情况下keepalived的VIP地址是在主节点上的,如果在从节点发现了VIP,就设置报警信息。脚本(在从节点上)如下:
[root@slave-ha ~]# vim split-brainc_check.sh
#!/bin/bash
# 检查脑裂的脚本,在备节点上进行部署
LB01_VIP=192.168.1.229
LB01_IP=192.168.1.129
LB02_IP=192.168.1.130
while true
do
ping -c 2 -W 3 $LB01_VIP &>/dev/null
if [ $? -eq 0 -a `ip add|grep "$LB01_VIP"|wc -l` -eq 1 ];then
echo "ha is brain."
else
echo "ha is ok"
fi
sleep 5
done
执行结果如下:
[root@slave-ha ~]# bash check_split_brain.sh
ha is ok
ha is ok
ha is ok
ha is ok
当发现异常时候的执行结果:
[root@slave-ha ~]# bash check_split_brain.sh
ha is ok
ha is ok
ha is ok
ha is ok
ha is brain.
ha is brain.
2)keepalived脑裂的一个坑(如果启用了iptables,不设置"系统接收VRRP协议"的规则,就会出现脑裂)
曾经在做keepalived+Nginx主备架构的环境时,当重启了备用机器后,发现两台机器都拿到了VIP。这也就是意味着出现了keepalived的脑裂现象,检查了两台主机的网络连通状态,发现网络是好的。然后在备机上抓包:
[root@localhost ~]# tcpdump -i eth0|grep VRRP tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes 22:10:17.146322 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:17.146577 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:17.146972 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:18.147136 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:18.147576 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:25.151399 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:25.151942 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:26.151703 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:26.152623 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:27.152456 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:27.153261 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:28.152955 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:28.153461 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:29.153766 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:29.155652 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:30.154275 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:30.154587 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:31.155042 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:31.155428 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:32.155539 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:32.155986 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:33.156357 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:33.156979 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 22:10:34.156801 IP 192.168.1.96 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 50, authtype simple, intvl 1s, length 20 22:10:34.156989 IP 192.168.1.54 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 160, authtype simple, intvl 1s, length 20 备机能接收到master发过来的VRRP广播,那为什么还会有脑裂现象? 接着发现重启后iptables开启着,检查了防火墙配置。发现系统不接收VRRP协议。 于是修改iptables,添加允许系统接收VRRP协议的配置: -A INPUT -i lo -j ACCEPT ----------------------------------------------------------------------------------------- 我自己添加了下面的iptables规则: -A INPUT -s 192.168.1.0/24 -d 224.0.0.18 -j ACCEPT #允许组播地址通信 -A INPUT -s 192.168.1.0/24 -p vrrp -j ACCEPT #允许VRRP(虚拟路由器冗余协)通信 ----------------------------------------------------------------------------------------- 最后重启iptables,发现备机上的VIP没了。 虽然问题解决了,但备机明明能抓到master发来的VRRP广播包,却无法改变自身状态。只能说明网卡接收到数据包是在iptables处理数据包之前发生的事情。
3)预防keepalived脑裂问题
1. 可以采用第三方仲裁的方法。由于keepalived体系中主备两台机器所处的状态与对方有关。如果主备机器之间的通信出了网题,就会发生脑裂,此时keepalived体系中会出现双主的情况,产生资源竞争。
2. 一般可以引入仲裁来解决这个问题,即每个节点必须判断自身的状态。最简单的一种操作方法是,在主备的keepalived的配置文件中增加check配置,服务器周期性地ping一下网关,如果ping不通则认为自身有问题 。
3. 最容易的是借助keepalived提供的vrrp_script及track_script实现。如下所示:
# vim /etc/keepalived/keepalived.conf
......
vrrp_script check_local {
script "/root/check_gateway.sh"
interval 5
}
......
track_script {
check_local
}
脚本内容:
# cat /root/check_gateway.sh
#!/bin/sh
VIP=$1
GATEWAY=192.168.1.1
/sbin/arping -I em1 -c 5 -s $VIP $GATEWAY &>/dev/null
check_gateway.sh 就是我们的仲裁逻辑,发现ping不通网关,则关闭keepalived服务:"service keepalived stop"
4)推荐自己写脚本
写一个while循环,每轮ping网关,累计连续失败的次数,当连续失败达到一定次数则运行service keepalived stop关闭keepalived服务。如果发现又能够ping通网关,再重启keepalived服务。最后在脚本开头再加上脚本是否已经运行的判断逻辑,将该脚本加到crontab里面。
Keepalived脑裂问题分享二
在部署Nginx+Keepalived高可用集群配置时可能会出行如下脑裂现象。处理过程如下:
查看两个节点的日志, 发现Master节点和Backup节点机器都是Mastaer模式启动的! [root@Master-Ha ~]# tail -f /var/log/messages ......... ......... Dec 22 20:24:32 Master-Ha Keepalived_healtheckers[22518]:Activating healthchecker for server [xx.xx.xx.xx] Dec 22 20:24:35 Master-Ha Keepalived_keepalived_vrrp[22519]: VRRP_instance(VI_I) Transition to MASTER STATE Dec 22 20:24:38 Master-Ha Keepalived_keepalived_vrrp[22519]: VRRP_instance(VI_I) Entering MASTER STATE Dec 22 20:24:40 Master-Ha Keepalived_keepalived_vrrp[22519]: VRRP_instance(VI_I) setting protocol VIPs Dec 22 20:24:44 Master-Ha Keepalived_healtheckers[22518]:Netlink reflector reports IP xx.xx.xx.xx added ......... ......... [root@Slave-Ha ~]# tail -f /var/log/messages ......... ......... Dec 22 20:24:34 Slave-Ha Keepalived_healtheckers[29803]:Activating healthchecker for server [xx.xx.xx.xx] Dec 22 20:24:37 Slave-Ha Keepalived_keepalived_vrrp[29804]: VRRP_instance(VI_I) Transition to MASTER STATE Dec 22 20:24:40 Slave-Ha Keepalived_keepalived_vrrp[29804]: VRRP_instance(VI_I) Entering MASTER STATE Dec 22 20:24:43 Slave-Ha Keepalived_keepalived_vrrp[29804]: VRRP_instance(VI_I) setting protocol VIPs Dec 22 20:24:47 Slave-Ha Keepalived_keepalived_vrrp[29804]: VRRP_instance(VI_I) Sending gratuitous ARPS on ens160 xx.xx.xx.xx Dec 22 20:24:49 Slave-Ha Keepalived_healtheckers[22518]:Netlink reflector reports IP xx.xx.xx.xx added ......... .........
通过上面查看两个节点机器的日志,发现VRRP是基于报文实现的!!Master节点会设置一定时间发送一个报文给Backup节点,如果Backup没有收到就自己成为Master。由此可以推出导致出现上面"脑裂"问题的根源在于Backup没有收到来自Master发送的报文!所以它自己也成为了Master。
VRRP控制报文只有一种:VRRP通告(advertisement)。它使用IP多播数据包进行封装,组地址为224.0.0.18,发布范围只限于同一局域网内。这保证了VRID在不同网络中可以重复使用。为了减少网络带宽消耗只有主控路由器才可以周期性的发送VRRP通告报文。备份路由器在连续三个通告间隔内收不到VRRP或收到优先级为0的通告后启动新的一轮VRRP选举。
另外注意:Centos7安装Keepalived后, 如果不关闭防火墙, 则需要在防火墙中放行VRRP的组播IP 244.0.0.18。否则虚拟ip不能实现漂移,双机都为Master,不能实现双机热备的效果。[类似于上面"分享一"中的情况]
由于不太习惯使用Centos7下默认的Firewall防火墙,可以禁用掉Centos7默认的Firewall防火墙,使用Iptables防火墙进行设置: # systemctl stop firewalld.service # systemctl disable firewalld.service # yum install -y iptables-services # vim /etc/sysconfig/iptables 在文件中添加一下内容 -A OUTPUT -o eth0 -d 224.0.0.18 -j ACCEPT -A OUTPUT -o eth0 -s 224.0.0.18 -j ACCEPT -A INPUT -i eth0 -d 224.0.0.18 -j ACCEPT -A INPUT -i eth0 -s 224.0.0.18 -j ACCEPT # service iptables restart # systemctl enable iptables.service 此时就能实现虚拟ip的漂移,当Master挂掉时,虚拟ip会漂移到Backup上,Master启动后虚拟ip会再次漂移回来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号