
Centos下MooseFS(MFS)分布式存储共享环境部署记录
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连,分布式文件系统的实际基于客户机/服务器模式。目前常见的分布式文件系统有很多种,比如Hadoop、Moosefs、HDFS、FastDFS、PNFS(Parallel NFS)、Lustre、TFS、GFS等等一系列。在众多的分布式文件系统解决方案中,MFS是搭建比较简单、使用起来也不需要过多的修改web程序,非常方便。
一、MooseFS是什么
MooseFS(即Moose File System,简称MFS)是一个具有容错性的网络分布式文件系统,它将数据分散存放在多个物理服务器或单独磁盘或分区上,确保一份数据 有多个备份副本,对于访问MFS的客户端或者用户来说,整个分布式网络文件系统集群看起来就像一个资源一样,也就是说呈现给用户的是一个统一的资源。 MooseFS就相当于UNIX的文件系统(类似ext3、ext4、nfs),它是一个分层的目录树结构。 MFS存储支持POSIX标准的文件属性(权限,最后访问和修改时间),支持特殊的文件,如块设备,字符设备,管道、套接字、链接文件(符合链接、硬链接); MFS支持FUSE(用户空间文件系统Filesystem in Userspace,简称FUSE),客户端挂载后可以作为一个普通的Unix文件系统使用MooseFS。 MFS可支持文件自动备份的功能,提高可用性和高扩展性。MogileFS不支持对一个文件内部的随机或顺序读写,因此只适合做一部分应用,如图片服务,静态HTML服务、 文件服务器等,这些应用在文件写入后基本上不需要对文件进行修改,但是可以生成一个新的文件覆盖原有文件。
二、MooseFS的特性
1)高可靠性,每一份数据可以设置多个备份(多分数据),并可以存储在不同的主机上 2)高可扩展性,可以很轻松的通过增加主机的磁盘容量或增加主机数量来动态扩展整个文件系统的存储量 3)高可容错性,可以通过对mfs进行系统设置,实现当数据文件被删除后的一段时间内,依旧存放于主机的回收站中,以备误删除恢复数据 4)高数据一致性,即使文件被写入、访问时,依然可以轻松完成对文件的一致性快照 5)通用文件系统,不需要修改上层应用就可以使用(那些需要专门api的dfs很麻烦!)。 6)可以在线扩容,体系架构可伸缩性极强。(官方的case可以扩到70台了!) 7)部署简单。(sa们特别高兴,领导们特别happy!) 8)可回收在指定时间内删除的文件,即可以设置删除文件的空间回收时间("回收站"提供的是系统级别的服务,不怕误操作了,提供类似oralce 的闪回等 高级dbms的即时回滚特性!),命令"mfsgettrashtime filename" 9)提供web gui监控接口。 10)提高随机读或写的效率(有待进一步证明)。 11)提高海量小文件的读写效率(有待进一步证明)
三、MooseFS的优点
1)部署简单,轻量、易配置、易维护 2)易于扩展,支持在线扩容,不影响业务,体系架构可伸缩性极强(官方的case可以扩到70台) 3)通用文件系统,不需要修改上层应用就可以使用(比那些需要专门api的dfs方便多了)。 4)以文件系统方式展示:如存图片,虽然存储在chunkserver上的数据是二进制文件,但是在挂载mfs的client端仍旧以图片文件形式展示,便于数据备份 5)硬盘利用率高。测试需要较大磁盘空间 6)可设置删除的空间回收时间,避免误删除文件丢失就恢复不及时影响业务 7)系统负载,即数据读写分配到所有的服务器上 8)可设置文件备份的副本数量,一般建议3份,未来硬盘容量也要是存储单份的容量的三倍
四、MooseFS的缺点
1)master目前是单点(虽然会把数据信息同步到备份服务器,但是恢复需要时间,因此,会影响上线,针对这个问题, 可以通过DRBD+Keeaplived方案或者DRBD+Inotify方案解决),master和backup之间的同步,类似mysql的主从不同。 2)master服务器对主机的内存要求略高 3)默认metalogger复制元数据时间较长(可调整)
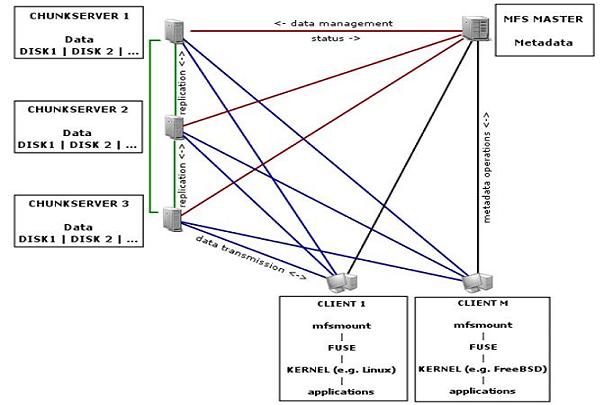
五、MooseFS文件系统架构组成及原理
MFS架构图
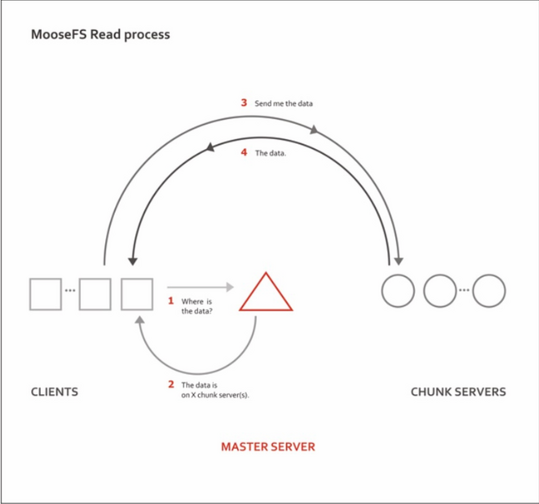
MFS文件的读写流程图
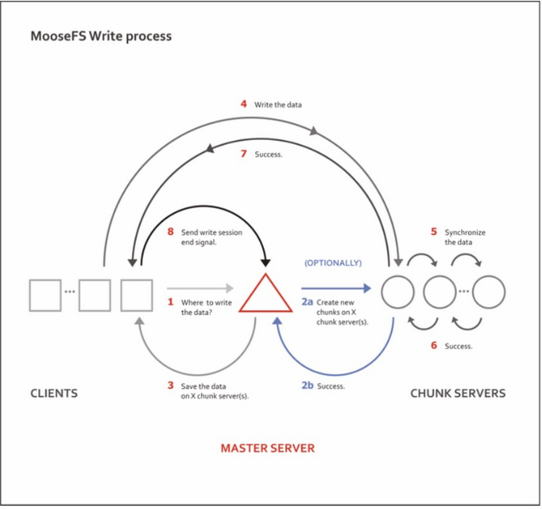
---------------------------------------------------------MFS读写处理过程--------------------------------------------------------
一、MFS读取数据步骤:
1)客户端向元数据服务器发出请求
2)元数据服务器把所需数据存放的位置(Chunk Server 的IP地址及Chunk编号)告知客户端
3)客户端向已知Chunk Server请求发送数据
4)客户端取得所需数据
数据传输并不通过元数据服务器,这既减轻了元数据服务器的压力,同时也大大增加了
整个系统的吞吐能力,在多个客户端读取数据时,读取点(Chunk Server)有可能被分散到不同
的服务器
二、MFS写入数据步骤:
1)客户端向元数据服务器发送写入请求
2)元数据服务器与Chunk Server进行交互如下:
1)元数据服务器指示在某些Chunk Server创建分块Chunks
2)Chunk Server告知元数据服务器,步骤(1)的操作成功
3)元数据服务器告知客户端,你可以在哪个Chunk Server的哪个Chunks写入数据
4)向指定的Chunk Server写入数据
5)与其他Chunk Server进行数据同步,同步的服务器依据设定的副本数而定,副本为2,则需同步一个ChunkServer
6)Chunk Sever之间同步成功
7)Chunk Server告知客户端数据写入成功
8)客户端告知元数据服务器本次写入完毕
三、MFS的删除文件过程
1)客户端有删除操作时,首先向Master发送删除信息;
2)Master定位到相应元数据信息进行删除,并将chunk server上块的删除操作加入队列异步清理;
3)响应客户端删除成功的信号
四、MFS修改文件内容的过程
1)客户端有修改文件内容时,首先向Master发送操作信息;
2)Master申请新的块给.swp文件,
3)客户端关闭文件后,会向Master发送关闭信息;
4)Master会检测内容是否有更新,若有,则申请新的块存放更改后的文件,删除原有块和.swp文件块;
5)若无,则直接删除.swp文件块。
五、MFS重命名文件的过程
1)客户端重命名文件时,会向Master发送操作信息;
2)Master直接修改元数据信息中的文件名;返回重命名完成信息;
六、MFS遍历文件的过程
1)遍历文件不需要访问chunk server,当有客户端遍历请求时,向Master发送操作信息;
2)Master返回相应元数据信息;
3—— 客户端接收到信息后显示
需要注意:
1)Master记录着管理信息,比如:文件路径|大小|存储的位置(ip,port,chunkid)|份数|时间等,元数据信息存在于内存中,会定期写入metadata.mfs.back文件中,
定期同步到metalogger,操作实时写入changelog.*.mfs,实时同步到metalogger中。master启动将metadata.mfs载入内存,重命名为metadata.mfs.back文件。
2)文件以chunk大小存储,每chunk最大为64M,小于64M的,该chunk的大小即为该文件大小(验证实际chunk文件略大于实际文件),超过64M的文件将被切分,以每一
份(chunk)的大小不超过64M为原则;块的生成遵循规则:目录循环写入(00-FF 256个目录循环,step为2)、chunk文件递增生成、大文件切分目录连续。
3)Chunkserver上的剩余存储空间要大于1GB(Reference Guide有提到),新的数据才会被允许写入,否则,你会看到No space left on device的提示,实际中,
测试发现当磁盘使用率达到95%左右的时候,就已经不行写入了,当时可用空间为1.9GB。
4)文件可以有多份copy,当goal为1时,文件会被随机存到一台chunkserver上,当goal的数大于1时,copy会由master调度保存到不同的chunkserver上,goal的大小
不要超过chunkserver的数量,否则多出的copy,不会有chunkserver去存。
MFS组件
1)管理服务器managing server简称(master): 这个组件的角色是管理整个mfs文件系统的主服务器,除了分发用户请求外,还用来存储整个文件系统中每个数据文件的metadata信息,metadate(元数据)信息包括 文件(也可以是目录,socket,管道,块设备等)的大小,属性,文件的位置路径等,很类似lvs负载均衡的主服务器,不同的是lvs仅仅根据算法分发请求,而master 根据内存里的metadata信息来分发请求,内存的信息会被实时写入到磁盘,这个master只能由一台处于激活的状态 2)元数据备份服务器Metadata backup servers(简称metalogger或backup): 这个组件的作用是备份管理服务器master的变化的metadata信息日志文件,文件类型为changelog_ml.*.mfs。以便于在管理服务器出问题时,可以经过简单的操作即可 让新的主服务器进行工作。这类似mysql主从同步,只不过它不像mysql从库那样在本地应用数据,而只是接受主服务器上文写入时记录的文件相关的metadata信息,这 个backup,可以有一台或多台,它很类似lvs从负载均衡服务器 3)数据存储服务器组data servers(chunk servers)简称data: 这个组件就是真正存放数据文件实体的服务器了,这个角色可以有多台不同的物理服务器或不同的磁盘及分区来充当,当配置数据的副本多于一份时,据写入到一个数 据服务器后,会根据算法在其他数据服务器上进行同步备份。这有点类似lvs集群的RS节点 4)客户机服务器组(client servers)简称client: 这个组件就是挂载并使用mfs文件系统的客户端,当读写文件时,客户端首先会连接主管理服务器获取数据的metadata信息,然后根据得到的metadata信息,访问数据服 务器读取或写入文件实体,mfs客户端通过fuse mechanism实现挂载mfs文件系统的,因此,只有系统支持fuse,就可以作为客户端访问mfs整个文件系统,所谓的客户端 并不是网站的用户,而是前端访问文件系统的应用服务器,如web -------------------MFS 文件系统结构包含4种角色---------------------- 1)管理服务器 Master Server(Master) 2)元数据日志服务器 Metalogger Server(Metalogger) 3)数据存储服务器 Data Servers (Chunkservers) 4)客户端 Client ---------------MFS的4种角色作用如下--------------- 1)Master管理服务器 有时也称为元数据服务器,负责管理各个数据存储服务器,调度文件读写,回收文件空间以及恢复多节点拷贝。目前MFS只支持一个元数据服务器master,这是一个单点故障, 需要一个性能稳定的服务器来充当。希望今后MFS能支持多个master服务器,进一步提高系统的可靠性。 2)Metalogger元数据日志服务器 负责备份管理服务器的变化日志文件,文件类型为changelog_ml.*.mfs,以便于在管理服务器出问题时接替其进行工作。元数据日志服务器是mfsl.6以后版本新增的服务, 可以把元数据日志保留在管理服务器中,也可以单独存储在一台服务器中。为保证数据的安全性和可靠性,建议单独用一台服务器来存放元 数据日志。需要注意的是,元 数据日志守护进程跟管理服务器在同一个服务器上,备份元数据日志服务器作为它的客户端,从管理服务器取得日志文件进行备份。 3)Chunkserver数据存储服务器(推荐至少两台chunkserver) 数据存储服务器是真正存储用户数据的服务器,负责连接管理服务器,听从管理服务器调度,提供存储空间,并为客户提供数据传输。在存储文件时,首先把文件分成块, 然后将这些块在数据存储服务器之间互相复制(复制份数手工指定,建议设置副本数为3),数据服务器可以是多个,并且数量越多,可使用的"磁盘空间"越小,可靠性也越高。 同时,数据存储服务器还负责连接管理服务器,听从管理服务器调度,并为客户提供数据传输。数据存储服务器可以有多个,并且数量越多,可靠性越高,MFS可用的磁盘空间也越大。 4)Client客户端 通过fuse内核接口挂接远程管理服务器上所管理的数据存储服务器,使共享的文件系统和使用本地Linux文件系统的效果看起来是一样的。 ----------------MFS内部运行机制------------------- 1)客户端请求访问存储,请求发送到了MFS Master 2)MFS Master根据客户访问的请求,查询所需要的文件分布在那些服务器上 3)客户端直接和存储服务器进行数据存储和读写 ---------------MFS的应用场景--------------- 1)大规模高并发的线上数据存储及访问(小文件,大文件都适合) 2)大规模的数据处理,如日志分析,小文件强调性能不用HDFS。 有大多的应用不适合分布式文件系统,不建议大家为了使用而使用。尽量在前端加cache应用,而不是一味的 扩充文件系统
六、为什么要使用MFS
由于用户数量的不断攀升,对访问量大的应用实现了可扩展、高可靠的集群部署(即lvs+keepalived的方式),但仍然有用户反馈访问慢的问题。通过排查个服务器的情况, 发现问题的根源在于共享存储服务器NFS。在我这个网络环境里,N个服务器通过NFS方式共享一个服务器的存储空间,使得NFS服务器不堪重负。察看系统日志,全是NFS服 务超时之类的报错。一般情况下,当NFS客户端数目较小的时候,NFS性能不会出现问题;一旦NFS服务器数目过多,并且是那种读写都比较频繁的操作,所得到的结果就不 是我们所期待的。
NFS缺陷(如下在web集群中使用NFS共享文件)

NFS虽然使用简单,但当NFS客户端访问量大时,通过NFS方式共享一个服务器的存储空间,使得NFS服务器不堪重负,并且执行读写都比较频繁的操作会出现 意外的错误,对于高可靠的集群部署是有挑战的。这种架构除了性能问题而外,还存在单点故障,一旦这个NFS服务器发生故障,所有靠共享提供数据的应用 就不再可用,尽管用rsync方式同步数据到另外一个服务器上做NFS服务的备份,但这对提高整个系统的性能毫无帮助。基于这样一种需求,我们需要对NFS服 务器进行优化或采取别的解决方案,然而优化并不能对应对日益增多的客户端的性能要求,因此唯一的选择只能是采取别的解决方案了; 通过调研,分布式文件系统是一个比较合适的选择。采用分布式文件系统后,服务器之间的数据访问不再是一对多的关系(1个NFS服务器,多个NFS客户端), 而是多对多的关系,这样一来,性能大幅提升毫无问题。 选择MFS分布式文件系统来作为共享存储服务器,主要考虑如下: 1)实施起来简单。MFS的安装、部署、配置相对于其他几种工具来说,要简单和容易得多。看看lustre 700多页的pdf文档,让人头昏吧。 2)不停服务扩容。MFS框架做好后,随时增加服务器扩充容量;扩充和减少容量皆不会影响现有的服务。注:hadoop也实现了这个功能。 3)恢复服务容易。除了MFS本身具备高可用特性外,手动恢复服务也是非常快捷的
MFS分布式文件系统环境部署记录

1)master-server元数据服务器上的操作记录
1)绑定host,关闭防火墙
[root@master-server ~]# vim /etc/hosts
182.48.115.233 master-server
182.48.115.235 metalogger
182.48.115.236 chunkServer1
182.48.115.237 chunkServer1
最好是关闭防火墙(selinux也要关闭,执行setenforce 0)
[root@master-server ~]# /etc/init.d/iptables stop
2)创建mfs用户和组
[root@master-server ~]# useradd mfs -s /sbin/nologin
3)编译安装mfs
百度下载地址:https://pan.baidu.com/s/1slS7JK5 (提取密码:park)
[root@master-server ~]# wget https://fossies.org/linux/misc/legacy/moosefs-3.0.91-1.tar.gz
[root@master-server ~]# tar -zvxf moosefs-3.0.91-1.tar.gz
[root@master-server ~]# cd moosefs-3.0.91
[root@master-server moosefs-3.0.91]# ./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs
[root@master-server moosefs-3.0.91]# make && make install
[root@master-server moosefs-3.0.91]# cd /usr/local/mfs/etc/mfs
[root@master-server mfs]# ls
mfschunkserver.cfg.sample mfshdd.cfg.sample mfsmetalogger.cfg.sample mfstopology.cfg.sample
mfsexports.cfg.sample mfsmaster.cfg.sample mfsmount.cfg.sample
4)master服务器需要以下文件:
mfsmaster.cfg 主文件
mfsexports.cfg mfs挂载权限设置,参考NFS文件系统中的exports.cfg
mfstopology.cfg 机架感知
下面开始修改配置文件
[root@master-server mfs]# cp -a mfsmaster.cfg.sample mfsmaster.cfg
[root@master-server mfs]# cp -a mfstopology.cfg.sample mfstopology.cfg
[root@master-server mfs]# cp -a mfsexports.cfg.sample mfsexports.cfg
[root@master-server mfs]# vim mfsexports.cfg
.......
182.48.115.0/27 / rw,alldirs,maproot=0
* . rw
设置解释:
第一个设置,代表让182.48.115.0网段机器可以挂载mfs的根分区;如果将"/"改为"."符号则表示允许访问所有
注意这里机器的netmask是255.255.255.224,所以子网掩码是27位,如果是255.255.255.0,那么掩码就是24位。
第二个设置是允许客户端挂载使用回收站功能。如果决定了挂载mfsmeta,那么一定要在mfsmaster的mfsexport.cfg文件中添加这条记录:
权限说明:
ro 只读模式
rw 读写模式
alldirs 允许挂载任何指定的子目录
maproot 映射为root,还是指定的用户
[root@master-server mfs]# cd ../../var/mfs/
[root@master-server mfs]# ls
metadata.mfs.empty
[root@master-server mfs]# cp -a metadata.mfs.empty metadata.mfs
[root@master-server mfs]# chown -R mfs:mfs /usr/local/mfs
5)启动mfsmaster命令:
[root@master-server mfs]# /usr/local/mfs/sbin/mfsmaster start //可以使用/usr/local/mfs/sbin/mfsmaster -a 命令进行启动,这种方式一般可用于修复性启动。
open files limit has been set to: 16384
working directory: /usr/local/mfs/var/mfs
lockfile created and locked
initializing mfsmaster modules ...
exports file has been loaded
topology file has been loaded
loading metadata ...
metadata file has been loaded
no charts data file - initializing empty charts
master <-> metaloggers module: listen on *:9419
master <-> chunkservers module: listen on *:9420
main master server module: listen on *:9421
mfsmaster daemon initialized properly
[root@master-server mfs]# ps -ef|grep mfs
mfs 31312 1 2 10:58 ? 00:00:00 /usr/local/mfs/sbin/mfsmaster start
root 31314 24958 0 10:58 pts/0 00:00:00 grep mfs
[root@master-server ~]# lsof -i:9420 //防火墙如果开启了,需要开放9420端口访问
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
mfsmaster 31312 mfs 9u IPv4 108440 0t0 TCP *:9420 (LISTEN)
-------------------------------------------------------------------------------------
mfsmaster相关启动命令
# /usr/local/mfs/sbin/mfsmaster start|stop|restart|reload|info|test|kill
将mfsmaster启动命令软链接到/etc/init.d下面
[root@master-server mfs]# ln -s /usr/local/mfs/sbin/mfsmaster /etc/init.d/mfsmaster
[root@master-server mfs]# /etc/init.d/mfsmaster statrt/stop/status/reload/restart //还可以使用/etc/init.d/mfsmaster -a命令进行启动
-------------------------------------------------------------------------------------
master管理节点的数据存放在/usr/local/mfs/var/mfs/目录下
6)启动和停止Web GUI
[root@master-server mfs]# /usr/local/mfs/sbin/mfscgiserv start
lockfile created and locked
starting simple cgi server (host: any , port: 9425 , rootpath: /usr/local/mfs/share/mfscgi)
[root@master-server mfs]# ps -ef|grep mfscgiserv
root 31352 1 0 11:01 ? 00:00:00 /usr/bin/python /usr/local/mfs/sbin/mfscgiserv
root 31356 24958 0 11:02 pts/0 00:00:00 grep mfscgiserv
[root@master-server mfs]# lsof -i:9425
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
mfscgiser 31352 root 3u IPv4 105260 0t0 TCP *:9425 (LISTEN)
相关启动命令
[root@master-server mfs]# /usr/local/mfs/sbin/mfscgiserv start/stop/status/restart/reload
访问Web GUI方式(如果打开了防火墙,防火墙里开放9245端口访问),访问地址是http://182.48.115.233:9425
mfscgiserv 是用python写的一个监控MFS状态的web界面,监听端口是9425,必须在master(管理服务器上)上启动。 常用的参数: -h 帮助信息 -H 绑定的IP,默认为0.0.0.0 -P 绑定端口号,默认是9425 -R mfscgi的root路径,默认是/usr/local/mfs/share/mfscgi -f 运行HTTP服务器,-f 表示在前台运行,-v表示请求的日志发往标准的错误设备 mfscgiserv监控图有8个部分组成: info 这个部分显示了MFS的基本信息。 Servers 列出现有的ChunkServer。 Disks 列出每一台ChunkServer的磁盘目录以及使用量 Exports 列出共享的目录,既可以被挂载的目录 mounts 显示被挂载的情况。 Openrations 显示正在执行的操作。 Master Charts 显示Master server的操作情况,包括读取,写入,创建目录,删除目录等消息。 Server Charts 显示ChunkServer的操作情况,数据传输率以及系统状态等信息。

访问的时候,出现上面界面,提示找不到master主机。莫慌!在DNS解析栏里输入master管理节点的主机名即可

2)chunkServer数据储存节点上的操作记录(在chunkServer1和chunkServer2上都要操作)
1)关闭防火墙(selinux也要关闭,执行setenforce 0) [root@chunkServer1 ~]# /etc/init.d/iptables stop 2)创建mfs用户和组 [root@chunkServer1 ~]# useradd mfs -s /sbin/nologin 3)编译安装mfs(下载地址在上面已经提到) [root@chunkServer1 ~]# yum install -y gcc c++ zlib-devel [root@chunkServer1 ~]# tar -zxvf moosefs-3.0.91-1.tar.gz [root@chunkServer1 ~]# cd moosefs-3.0.91 [root@chunkServer1 moosefs-3.0.91]# ./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs [root@chunkServer1 moosefs-3.0.91]# make && make install [root@chunkServer1 moosefs-3.0.91]# cd /usr/local/mfs/etc/mfs/ [root@chunkServer1 mfs]# ls mfschunkserver.cfg.sample mfsexports.cfg.sample mfshdd.cfg.sample mfsmaster.cfg.sample mfsmetalogger.cfg.sample mfstopology.cfg.sample 4)chunkserver配置文件如下: mfschunkserver.cfg 这个是mfschunkserver配置文件 mfshdd.cfg 这个是mfschunkserver上的分区,必须是独立分区! [root@chunkServer1 mfs]# cp mfschunkserver.cfg.sample mfschunkserver.cfg [root@chunkServer1 mfs]# vim mfschunkserver.cfg ....... MASTER_HOST = 182.48.115.233 //这个填写master管理节点的ip或主机名 MASTER_PORT = 9420 [root@chunkServer1 mfs]# cp mfshdd.cfg.sample mfshdd.cfg [root@chunkServer1 mfs]# vim mfshdd.cfg //在文件尾行添加下面两行内容 ....... # mount points of HDD drives /usr/local/mfsdata //由于mfschunkserver上的分区需要是独立分区!所以这里最好配置成独立分区。比如/data (df -h命令查看,/data要是独立分区) [root@chunkServer1 mfs]# mkdir /usr/local/mfsdata //这个是数据的真实存放目录。里面存放的是数据的chunks块文件 [root@chunkServer1 mfs]# chown -R mfs:mfs /usr/local/mfsdata/ [root@chunkServer1 mfs]# cd ../../var/mfs/ [root@chunkServer1 mfs]# ls metadata.mfs.empty [root@chunkServer1 mfs]# cp metadata.mfs.empty metadata.mfs [root@chunkServer1 mfs]# chown -R mfs:mfs /usr/local/mfs 5)启动chunkserver [root@chunkServer1 mfs]# ln -s /usr/local/mfs/sbin/mfschunkserver /etc/init.d/mfschunkserver [root@chunkServer1 mfs]# /etc/init.d/mfschunkserver start open files limit has been set to: 16384 working directory: /usr/local/mfs/var/mfs lockfile created and locked setting glibc malloc arena max to 4 setting glibc malloc arena test to 4 initializing mfschunkserver modules ... hdd space manager: path to scan: /usr/local/mfsdata/ hdd space manager: start background hdd scanning (searching for available chunks) main server module: listen on *:9422 no charts data file - initializing empty charts mfschunkserver daemon initialized properly [root@chunkServer1 mfs]# ps -ef|grep mfs mfs 13843 1 1 13:30 ? 00:00:00 /etc/init.d/mfschunkserver start root 13853 4768 0 13:31 pts/0 00:00:00 grep mfs [root@chunkServer1 mfs]# lsof -i:9422 #防火墙开启这个端口的访问 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME mfschunks 13843 mfs 11u IPv4 54792 0t0 TCP *:9422 (LISTEN) 其他相关命令 [root@chunkServer1 mfs]# /etc/init.d/mfschunkserver start/stop/restart/status/reload
3)metalogger元数据日志服务器操作记录
1)关闭防火墙(selinux也要关闭) [root@metalogger ~]# setenforce 0 [root@metalogger ~]# /etc/init.d/iptables stop 2)创建mfs用户和组 [root@metalogger ~]# useradd mfs -s /sbin/nologin 3)编译安装mfs [root@metalogger ~]# yum install -y gcc c++ zlib-devel [root@metalogger ~]# tar -zvxf moosefs-3.0.91-1.tar.gz [root@metalogger ~]# cd moosefs-3.0.91 [root@metalogger moosefs-3.0.91]# ./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs [root@metalogger moosefs-3.0.91]# make && make install 4)mfsmetalogger.cfg文件配置 [root@metalogger moosefs-3.0.91]# cd /usr/local/mfs/etc/mfs/ [root@metalogger mfs]# ls mfschunkserver.cfg.sample mfsexports.cfg.sample mfshdd.cfg.sample mfsmaster.cfg.sample mfsmetalogger.cfg.sample mfstopology.cfg.sample [root@metalogger mfs]# cp mfsmetalogger.cfg.sample mfsmetalogger.cfg [root@metalogger mfs]# vim mfsmetalogger.cfg ...... META_DOWNLOAD_FREQ = 1 MASTER_HOST = 182.48.115.233 #如果是单机环境的话,这个不能为localhost或127.0.0.1,要使用对外IP MASTER_PORT = 9419 参数解释: META_DOWNLOAD_FREQ 表示源数据备份下载请求频率,这里设置为1小时。默认为24小时,即每隔一天从元数据服务器(MASTER)下载一个metadata.mfs.back 文件。 当元数据服务器关闭或者出故障时,matedata.mfs.back 文件将消失,那么要恢复整个mfs,则需从metalogger 服务器取得该文件。请特别注意这个文件,它与日志 文件(即changelog_ml.0.mfs文件)一起,才能够恢复整个被损坏的分布式文件系统。元数据日志服务器的备份数据存放目录是/usr/local/mfs/var/mfs/。 [root@metalogger mfs]# cd ../../var/mfs/ [root@metalogger mfs]# ls metadata.mfs.empty [root@metalogger mfs]# cp metadata.mfs.empty metadata.mfs [root@metalogger mfs]# chown -R mfs:mfs /usr/local/mfs 5)启动metalogger节点服务 [root@metalogger mfs]# ln -s /usr/local/mfs/sbin/mfsmetalogger /etc/init.d/mfsmetalogger [root@metalogger mfs]# /etc/init.d/mfsmetalogger start open files limit has been set to: 4096 working directory: /usr/local/mfs/var/mfs lockfile created and locked initializing mfsmetalogger modules ... mfsmetalogger daemon initialized properly [root@metalogger mfs]# ps -ef|grep mfs mfs 9353 1 1 14:22 ? 00:00:00 /etc/init.d/mfsmetalogger start root 9355 3409 0 14:22 pts/0 00:00:00 grep mfs [root@metalogger mfs]# lsof -i:9419 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME mfsmetalo 9353 mfs 8u IPv4 38278 0t0 TCP 182.48.115.235:37237->182.48.115.233:9419 (ESTABLISHED) 其他相关启动命令 [root@metalogger mfs]# /etc/init.d/mfsmetalogger start/stop/status/restart/reload
接着再看看Web GUI访问页面(可以reload 重载mfscgiserv服务)


4)mfs client客户端上的操作记录
1)mfs client安装依赖与系统包fuse,通过yum方式安装(也可以源码安装)
[root@clinet-server ~]# yum -y install fuse fuse-devel
2)创建mfs用户和组
[root@clinet-server ~]# useradd mfs -s /sbin/nologin
3)编译安装mfs
[root@clinet-server ~]# yum install -y gcc c++ zlib-devel
[root@clinet-server ~]# tar -zvxf moosefs-3.0.91-1.tar.gz
[root@clinet-server ~]# cd moosefs-3.0.91
[root@clinet-server moosefs-3.0.91]# ./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs --enable-mfsmount
[root@clinet-server moosefs-3.0.91]# make && make install
4)创建mfs挂载目录
[root@clinet-server ~]# mkdir /mnt/mfs //这个是挂载的数据目录,挂载目录可以在客户机上任意定义
[root@clinet-server ~]# mkdir /mnt/mfsmeta //这个是挂载的回收站目录
5)mfs client 挂载命令
[root@clinet-server ~]# /usr/local/mfs/bin/mfsmount /mnt/mfs -H 182.48.115.233 //挂载MFS文件系统的根目录到本机的/mnt/mfs下
mfsmaster accepted connection with parameters: read-write,restricted_ip,admin ; root mapped to root:root
[root@clinet-server ~]# /usr/local/mfs/bin/mfsmount -m /mnt/mfsmeta/ -H 182.48.115.233 //挂载MFS文件系统的mfsmeta,使用回收站功能
mfsmaster accepted connection with parameters: read-write,restricted_ip
6)查看
[root@clinet-server ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root
8.3G 3.8G 4.1G 49% /
tmpfs 499M 228K 498M 1% /dev/shm
/dev/vda1 477M 35M 418M 8% /boot
/dev/sr0 3.7G 3.7G 0 100% /media/CentOS_6.8_Final
182.48.115.233:9421 16G 2.7G 14G 17% /mnt/mfs
mount查看
[root@clinet-server ~]# mount
/dev/mapper/VolGroup-lv_root on / type ext4 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
tmpfs on /dev/shm type tmpfs (rw,rootcontext="system_u:object_r:tmpfs_t:s0")
/dev/vda1 on /boot type ext4 (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
gvfs-fuse-daemon on /root/.gvfs type fuse.gvfs-fuse-daemon (rw,nosuid,nodev)
/dev/sr0 on /media/CentOS_6.8_Final type iso9660 (ro,nosuid,nodev,uhelper=udisks,uid=0,gid=0,iocharset=utf8,mode=0400,dmode=0500)
182.48.115.233:9421 on /mnt/mfs type fuse.mfs (rw,nosuid,nodev,allow_other)
182.48.115.233:9421 on /mnt/mfsmeta type fuse.mfsmeta (rw,nosuid,nodev,allow_other)
mfsmount是本地文件系统代理,挂接FUSE,监听文件系统IO。
mfsmout向master获取chunk信息,向mfschunkserver发出读写数据的命令,chunkserver是磁盘IO的执行者。mfsmount是用户发出IO请求的命令接收者,master是
mfs所有chunk和node信息的维护者。
在挂载目录/mnt/mfs下的文件就会通过master管理节点放到chunkserver上,并且是被分成多个块放到各个chunkserver上的;可以再其他的clinet机器上挂载MFS,那么挂载点里的
文件都是同步共享的。这样当一台或多台chunkserver宕机或出现故障时(只要不是全部出现故障),对于clinet端来说,共享MFS数据都是不受影响的。
到挂载目录/mnt/mfs下,就可以查看到MFS文件系统根目录下的内容了
[root@clinet-server ~]# cd /mnt/mfs
[root@clinet-server mfs]# ls
hqsb huanqiu ip_list
[root@clinet-server mfs]# echo "123123123" > test
[root@clinet-server mfs]# ls
hqsb huanqiu ip_list test
--------------------------------------------------------------------------------
卸载的话,直接使用命令:
[root@clinet-server ~]# umount /mnt/mfs
[root@clinet-server ~]# umount /mnt/mfsmeta
卸载后,在客户机上的挂载目录下就什么内容都查看不到了
[root@clinet-server ~]# cd /mnt/mfs
[root@clinet-server mfs]# ls
[root@clinet-server mfs]#
---------------------------------------------------------------------------------
5)MFS日常操作(都在client端下操作)
1->回收站功能
mfs文件系统是正规的mfs挂载系统,里面包含了所有的mfs存储的文件与目录。 mfsmeta文件系统是mfs提供用于辅助的文件系统,相当于windows的回收站。 如上,在clinet端启动管理服务器进程时,用了一个-m选项,这样可以挂载一个辅助的文件系统mfsmeta,辅助文件系统可以在如下两个方面恢复丢失的数据: 1)MFS卷上误删除了文件,而此文件又没有过垃圾文件存放期。 2)为了释放磁盘空间而删除或者移动的文件,当需要恢复这些文件时,文件又没有过垃圾文件的存放期。 要使用MFS辅助文件系统,可以执行如下指令: # mfsmount -m /mnt/mfsclient -H mfsmaster //回收站目录挂载前面已操作 需要注意的是,如果决定了挂载mfsmeta,那么一定要在mfsmaster的mfsexport.cfg文件中添加下面这条记录(前面已提到): * . rw 挂载文件系统就可以执行所所有标准的文件操作了。如创建,删除,复制,重命名文件等。MFS由于是一个网络文件系统,所以操作进度比本地的偏慢。 需要注意的是,每个文件都可以存储为多个副本,在这种情况下,每一个文件所占用的空间要比其他文件本身大的多,此外,被删除且在有效期内的文件都放在 一个“垃圾箱”中,所以他们也占用的空间,其大小也依赖文件的分钟。。为防止删除被其他进程打开的文件,数据将一直被存储,直到文件被关闭。 被删文件的文件名在“垃圾箱”目录里还可见,文件名由一个八位十六进制的数i-node 和被删文件的文件名组成,在文件名和i-node 之间不是用“/”,而是用了“|”替代。 如果一个文件名的长度超过操作系统的限制(通常是255 个字符),那么部分将被删除。通过从挂载点起全路径的文件名被删除的文件仍然可以被读写。 移动这个文件到trash/undel 子目录下,将会使原始的文件恢复到正确的MooseFS 文件系统上路径下(如果路径没有改变)。如果在同一路径下有个新的同名文件, 那么恢复不会成功。从“垃圾箱”中删除文件结果是释放之前被它站用的空间(删除有延迟,数据被异步删除)。 删除的文件通过一个单独安装的mfsmeta辅助文件系统来恢复。这个文件系统包含了目录trash(含有仍然可以被还原的删除文件的信息)和目录trash/undel(用于获取文件)。 只有管理员权限访问mfsmeta辅助文件系统(通常是root) ---------------------------下面测试下MFS回收站功能------------------------------ 在mfs挂载点删除一个文件,在mfsmeta挂载点可以找到: [root@clinet-server ~]# echo "asdfasdfnoijoiujro2er0" >/mnt/mfs/haha1 [root@clinet-server ~]# /usr/local/mfs/bin/mfsrgettrashtime /mnt/mfs/haha1 deprecated tool - use "mfsgettrashtime -r" /mnt/mfs/haha1: files with trashtime 14400 : 1 //确认回收站存放的时间为4小时 [root@clinet-server ~]# rm /mnt/mfs/haha1 //删除文件 rm: remove regular file `/mnt/mfs/haha1'? y [root@clinet-server ~]# find /mnt/mfsmeta/trash/ -name "*haha*" //在回收站里面找到被删除的文件 /mnt/mfsmeta/trash/01F/0000001F|haha1 被删除的文件名在垃圾箱里面其实还是可以找到的,文件名是由一个8位16进制数的i-node和被删的文件名组成。在文件名和i-node之间不可以用"/",而是以"|"替代。 如果一个文件名的长度超过操作系统的限制(通常是255字符),那么超出部分将被删除。从挂载点起全部路径的文件名被删除的文件仍然可以被读写。 需要注意的是,被删除的文件在使用文件名(注意文件名是两部分),一定要用单引号引起来。如下所示: [root@clinet-server ~]# cat '/mnt/mfsmeta/trash/01F/0000001F|haha1' haha1 从回收站里恢复已删除的文件 移动这个文件到文件所在目录下的undel下面,将会使原始的文件恢复到正确的MFS文件系统原来的路径下。如下所示: [root@clinet-server ~]# cd /mnt/mfsmeta/trash/01F [root@clinet-server 01F]# ls 0000001F|haha1 undel [root@clinet-server 01F]# mv 0000001F\|haha1 ./undel/ [root@clinet-server 01F]# cat /mnt/mfs/haha1 //发现haha1文件已经恢复了 asdfasdfnoijoiujro2er0 在恢复文件的时候,原来被删文件下面的目录下,不能有同名文件,不然恢复不成功。 从垃圾箱中删除文件的结构是释放之前它占用的空间(删除有延迟,因为数据是异步删除的)。在垃圾箱中删除文件后,就不能够再恢复了。 可以通过mfssetgoal命令来修改文件的副本数,也可以通过mfssettrashtime工具来改变文件存储在垃圾箱中的时间。 ----------------------------为垃圾箱设定隔离时间--------------------------------------- 删除的文件存放在"垃圾箱(trash bin)"的时间就是隔离时间(quarantine time),即一个删除文件能够存放在一个"垃圾箱"的时间。 这个时间可以用mfsrgettrashtime命令来验证,也可以用mfssettrashtime或者mfsrsettrashtime命令来设置。 设置的时间是按照小时计算,设置的单位是秒,不满一小时就按一小时计算,如下所示: [root@clinet-server ~]# /usr/local/mfs/bin/mfssettrashtime 600 /mnt/mfs/ /mnt/mfs/: 600 上面设置为600秒,即10分钟,不足1小时,算作1小时,所以查看结果是3600秒(即1小时) [root@clinet-server ~]# /usr/local/mfs/bin/mfsrgettrashtime /mnt/mfs deprecated tool - use "mfsgettrashtime -r" /mnt/mfs: files with trashtime 3600 : 2 directories with trashtime 3600 : 1 #查看这一行结果 [root@clinet-server ~]# /usr/local/mfs/bin/mfssettrashtime 6000 /mnt/mfs/ /mnt/mfs/: 6000 设置6000秒,多余1小时,不足2小时,结果算作是2小时 [root@clinet-server ~]# /usr/local/mfs/bin/mfsrgettrashtime /mnt/mfs deprecated tool - use "mfsgettrashtime -r" /mnt/mfs: files with trashtime 3600 : 2 directories with trashtime 7200 : 1 若把时间设置为0,说明文件执行删除命令后,就会立即删除,不可能再恢复,不进入回收站: [root@clinet-server ~]# /usr/local/mfs/bin/mfssettrashtime 0 /mnt/mfs/ /mnt/mfs/: 0 [root@clinet-server ~]# /usr/local/mfs/bin/mfsrgettrashtime /mnt/mfs deprecated tool - use "mfsgettrashtime -r" /mnt/mfs: files with trashtime 3600 : 2 directories with trashtime 0 : 1 mfssettrashtime -r是对目录进行递归赋值的。为一个目录设定存放时间后,在此目录下新创建的文件和目录就可以继承这个设置了。 [root@clinet-server ~]# /usr/local/mfs/bin/mfssettrashtime -r 6000 /mnt/mfs/ /mnt/mfs/: inodes with trashtime changed: 4 inodes with trashtime not changed: 0 inodes with permission denied: 0 [root@clinet-server ~]# /usr/local/mfs/bin/mfsrgettrashtime /mnt/mfs/ deprecated tool - use "mfsgettrashtime -r" /mnt/mfs/: files with trashtime 7200 : 3 directories with trashtime 7200 : 1 [root@clinet-server ~]# /usr/local/mfs/bin/mfsrgettrashtime /mnt/mfs/haha1 deprecated tool - use "mfsgettrashtime -r" /mnt/mfs/haha1: files with trashtime 7200 : 1
2->设定目标的拷贝份数
目标(goal),是指文件被拷贝的份数,设定了拷贝的份数后是可以通过mfsgetgoal 命令来证实的,也可以通过mfsrsetgoal 来改变设定。
设置mfs文件系统中文件的副本个数,比如本案例中,设置2份:
[root@clinet-server ~]# /usr/local/mfs/bin/mfssetgoal 2 /mnt/mfs/test.txt
/mnt/mfs/test.txt: goal: 2
查看文件份数:
[root@clinet-server ~]# /usr/local/mfs/bin/mfsgetgoal /mnt/mfs/test.txt
/mnt/mfs/test.txt: 2
可以看出,与设置的文件副本数一致!
根据测试:goal number<=chunkserver number
即拷贝份数要不能多余chunkserver的节点数量
目录设置与文件设置操作一致,给目录设置goal,之后在该目录下创建的文件将会继承该goal,但不会影响到已经存在的文件。
[root@clinet-server ~]# /usr/local/mfs/bin/mfssetgoal 2 /mnt/mfs
/mnt/mfs: goal: 2
[root@clinet-server ~]# /usr/local/mfs/bin/mfsgetgoal /mnt/mfs
/mnt/mfs: 2
若要使该命令递归到目录下的所有文件,添加-r参数。
用mfsgetgoal –r 和mfssetgoal –r 同样的操作可以对整个树形目录递归操作,其等效于mfsrsetgoal命令
[root@clinet-server ~]# /usr/local/mfs/bin/mfssetgoal -r 2 /mnt/mfs
/mnt/mfs:
inodes with goal changed: 0
inodes with goal not changed: 2
inodes with permission denied: 0
[root@clinet-server ~]# /usr/local/mfs/bin/mfsgetgoal -r /mnt/mfs
/mnt/mfs:
files with goal 2 : 2
directories with goal 2 : 1
[root@clinet-server ~]# /usr/local/mfs/bin/mfsrgetgoal /mnt/mfs
deprecated tool - use "mfsgetgoal -r"
/mnt/mfs:
files with goal 2 : 2
directories with goal 2 : 1
----------------------------------------------------------------------------------------------------------------------------------------
对一个目录设定“goal”,此目录下的新创建文件和子目录均会继承此目录的设定,但不会改变已经存在的文件及目录的copy份数。但使用-r选项可以更改已经存在的copy份数。
goal设置为2,只要两个chunkserver有一个能够正常运行,数据就能保证完整性。
假如每个文件的goal(保存份数)都不小于2,并且没有under-goal文件(可以用mfsgetgoal –r和mfsdirinfo命令来检查),那么一个单一的chunkserver在任何时刻都可能做
停止或者是重新启动。以后每当需要做停止或者是重新启动另一个chunkserver的时候,要确定之前的chunkserver被连接,而且要没有under-goal chunks。
实际测试时,传输一个大文件,设置存储2份。传输过程中,关掉chunkserver1,这样绝对会出现有部分块只存在chunkserver2上;启动chunkserver1,关闭chuner2,这样绝对
会有部分块只存在chuner1上。把chunkserver2启动起来。整个过程中,客户端一直能够正常传输。在客户端查看,一段时间内,无法查看;稍后一段时间后,就可以访问了。
文件正常,使用mfsfileinfo 查看此文件,发现有的块分布在chunkserver1上,有的块分布在chuner2上。使用mfssetgoal 2和mfssetgoal -r 2均不能改变此文件的目前块的现状。
但使用mfssetgoal -r 1后,所有块都修改成1块了,再mfssetgoal -r 2,所有块都修改成2份了。
测试chunkserver端,直接断电情况下,chunkserver会不会出问题:
1)数据传输过程中,关掉chunkserver1,等待数据传输完毕后,开机启动chunkserver1.
chunkserver1启动后,会自动从chunkserver2复制数据块。整个过程中文件访问不受影响。
2)数据传输过程中,关掉chunkserver1,不等待数据传输完毕,开机启动chunkserver1.
chunkserver1启动后,client端会向chunkserver1传输数据,同时chunkserver1也从chunkserver2复制缺失的块。
如果有三台chunkserver,设置goal=2,则随机挑选2个chunkserver存储。
如果有一个chunkserver不能提供服务,则剩余的2个chunkserver上肯定有部分chunks(块)保存的是一份。则在参数(REPLICATIONS_DELAY_DISCONNECT = 3600)后,只有一份的chunks
会自动复制一份,即保存两份。保存两份后,如果此时坏掉的chunkserver能够提供服务后,此时肯定有部分chunks存储了三份,mfs会自动删除一份。
当增加第三个服务器做为额外的chunkserver时,虽然goal设置为2,但看起来第三个chunkserver从另外两个chunkserver上复制数据。
是的,硬盘空间平衡器是独立地使用chunks的,因此一个文件的chunks会被重新分配到所有的chunkserver上。
----------------------------------------------------------------------------------------------------------------------------------------------
查看文件的实际副本数量可以通过mfscheckfile和mfsfileinfo命令证实。
mfscheckfile可查看copy数:
mfsfileinfo可查看具体的copy位置
注意下面几个特殊情况:
1)一个不包含数据的零长度的文件,尽管没有设置为非零的目标,但用mfscheckfile命令查询将返回一个空的结果;将文件填充内容后,其会根据设置的goal创建副本;
这时再将文件清空,其副本依然作为空文件存在。
2)假如改变一个已经存在的文件的拷贝个数,那么文件的拷贝份数将会被扩大或者被删除,这个过程会有延时。可以通过mfscheckfile 命令来证实。
3)对一个目录设定“目标”,此目录下的新创建文件和子目录均会继承此目录的设定,但不会改变已经存在的文件及目录的拷贝份数。可以通过mfsdirinfo来查看整个目录树的信息摘要。
如下示例:
[root@clinet-server ~]# touch /mnt/mfs/wangshibo
[root@clinet-server ~]# /usr/local/mfs/bin/mfscheckfile /mnt/mfs/wangshibo
/mnt/mfs/wangshibo: //虽然有文件(虽然没有设置为非零目标,the noo-zero goal),但是是一个空文件,所以mfscheckfile是为空的结果。
[root@clinet-server ~]# /usr/local/mfs/bin/mfsfileinfo /mnt/mfs/wangshibo
/mnt/mfs/wangshibo:
no chunks - empty file
往上面测试文件里写入数据
[root@clinet-server ~]# echo "1213442134" > /mnt/mfs/wangshibo
[root@clinet-server ~]# echo "1213442134" > /mnt/mfs/wangshibo
[root@clinet-server ~]# /usr/local/mfs/bin/mfscheckfile /mnt/mfs/wangshibo
/mnt/mfs/wangshibo:
chunks with 2 copies: 1
[root@clinet-server ~]# /usr/local/mfs/bin/mfsfileinfo /mnt/mfs/wangshibo
/mnt/mfs/wangshibo:
chunk 0: 0000000000000015_00000001 / (id:21 ver:1)
copy 1: 182.48.115.236:9422 (status:VALID)
copy 2: 182.48.115.237:9422 (status:VALID) //由于上面对/mnt/mfs目录进行递归设置拷贝的份数是2,所以这里显示的副本数正好是2
下面设置/mnt/mfs/wangshibo 文件的副本数为3或者大于3的副本数
[root@clinet-server ~]# /usr/local/mfs/bin/mfssetgoal 3 /mnt/mfs/wangshibo
/mnt/mfs/wangshibo: goal: 3
[root@clinet-server ~]# /usr/local/mfs/bin/mfsgetgoal /mnt/mfs/wangshibo
/mnt/mfs/wangshibo: 3
[root@clinet-server ~]# echo "asdfasdfasdf" > /mnt/mfs/wangshibo
[root@clinet-server ~]# /usr/local/mfs/bin/mfscheckfile /mnt/mfs/wangshibo
/mnt/mfs/wangshibo:
chunks with 2 copies: 1
[root@clinet-server ~]# /usr/local/mfs/bin/mfsfileinfo /mnt/mfs/wangshibo
/mnt/mfs/wangshibo:
chunk 0: 0000000000000017_00000001 / (id:23 ver:1)
copy 1: 182.48.115.236:9422 (status:VALID)
copy 2: 182.48.115.237:9422 (status:VALID)
以上可知,虽然将文件的副本数设置为3(或者大于3),理论上应该是复制3份副本,但是这里的chunkserver只有2台,所以copy也就为2了。
因此得出结论,goal number不能超过chunkserver number,要小于或等于chunkserver的数量。
另外,需要特别注意的是:
如果你的Chunkserver只有n台服务器,那么goal拷贝份数就设置为n即可,千万别设置为超过n的数目,不然往文件里写入数据时,会很卡!!
顺便说说目录继承副本数量的问题:
1)如果改变一个已经存在的文件副本份数,那么文件的副本份数就会扩大或删除,这个过程会有延迟的。
2)对于一个目录设定"目标",此目录下新创建的文件或子目录均会继承此目录的设定,但不会改变已经存在的文件以及目录副本数量。
--------------------------------------------------------------------------------------------------------------------------------
mfsdirinfo
整个目录树的内容需要通过一个功能增强、等同于“du -s”的命令mfsdirinfo来显示。mfsdirinfo可以显示MFS的具体信息,查看目录树的内容摘要:
[root@clinet-server ~]# /usr/local/mfs/bin/mfsdirinfo /mnt/mfs
/mnt/mfs:
inodes: 5
directories: 1
files: 4
chunks: 4
length: 12342
size: 294912
realsize: 1253376
其中:
1)length 表示文件大小的总和
2)size 表示块长度总和
3)realsize 表示磁盘空间的使用,包括所有的副本
3->快照功能
MFS系统可以利用mfsmakesnapshot工具给文件或者目录做快照(snapshot),如下所示,将mfs文件体系下的wangshibo文件做快照
[root@clinet-server ~]# cd /mnt/mfs
[root@clinet-server mfs]# ls
wangshibo
[root@clinet-server mfs]# /usr/local/mfs/bin/mfsmakesnapshot wangshibo /opt/wangshibo-snapshot
(/opt/wangshibo-snapshot,wangshibo): both elements must be on the same device
[root@clinet-server mfs]# /usr/local/mfs/bin/mfsmakesnapshot wangshibo wangshibo-snapshot
[root@clinet-server mfs]# ll
total 1
-rw-r--r--. 1 root root 12 May 23 10:38 wangshibo
-rw-r--r--. 1 root root 12 May 23 10:38 wangshibo-snapshot
特别要注意的是:
不能将快照放到MFS文件系统之外的其他文件系统下,快照文件和源文件必须要在同一个MFS文件系统下(即路径一致)
[root@clinet-server mfs]# /usr/local/mfs/bin/mfsfileinfo wangshibo-snapshot
wangshibo-snapshot:
chunk 0: 000000000000001A_00000001 / (id:26 ver:1)
copy 1: 182.48.115.236:9422 (status:VALID)
copy 2: 182.48.115.237:9422 (status:VALID)
[root@clinet-server mfs]# /usr/local/mfs/bin/mfsfileinfo wangshibo
wangshibo:
chunk 0: 000000000000001A_00000001 / (id:26 ver:1)
copy 1: 182.48.115.236:9422 (status:VALID)
copy 2: 182.48.115.237:9422 (status:VALID)
通过mfsfileinfo命令可以查看创建出来的文件快照,它只占用了一个inode,并不占用磁盘空间,就像ln命令创建硬链接类似!!!!
mfsmakesnapshot是一次执行中整合了一个或者一组文件的副本,而且对这些文件的源文件进行任何修改都不会影响源文件的快照,就是说任何对源文件的操作,如写入操作,将会不修改副本。
mfsmakesnapshot可以实现这个快照功能,当有多个源文件时,他们的快照会被加入到同一个目标文件中,通过对比快照的测试,可以发现快照的本质:
1)一个MFS系统下的文件做快照后,查看两个文件的块信息,他们是同一个块。接着,把原文件删除,删除源文件后(最初会留在回收站上,但过一段时间后回收站的文件也删除了),快照
文件仍然存储,并且可以访问。使用mfsfileinfo查看,发现还是原来的块。
2)对一个文件做快照后,查看两个文件的块信息,发现是同一个块。把原文件修改后,发现原文件的使用块信息变了,即使用了一个新块。而快照文件仍然使用原来的块,保持文件内容不变。
4->MFS挂载目录技巧
1)挂载目录管理 Moosefs系统支持客户端根据需要挂载对应子目录;默认不指定-S的话会挂载到根目录(/)下,当通过df –sh查看空间使用used显示的是当前整个mfs系统的硬盘使用情况; 而挂载子目录则只会看到目录的使用情况。具体操作如下: # mfsmount /mnt –H mfsmaster //挂载到MFS的根目录(/)下。即在客户端/mnt目录下写入的数据会直接写到MFS的根目录下。这里客户端的挂载路径可以自定义。 # mkdir –p /mnt/subdir # mfsmount /mnt –H mfsmaster –S /subdir //挂载到MFS子目录(/subdir)下。这个subdir目录是在MFS文件系统下真实存在的。在客户端显示的还是/mnt路径,往里面写入的数据其实是写到了MFS的/mnt/subdir路径下 在Moosefs的管理中,可以找一台机器作为管理型的client端,在master管理节点的配置文件mfsexports.cfg中限制只有该台机器可以挂载到根目录下,同时也可限制只有 该台机器可以挂载metadata目录(恢复误删除时可用到),而其他普通client端,则根据不同业务的需要让管理client端为其创建独立用途的目录,分别挂载到对应的子 目录下,这样就可以细化管理控制权限。 在master管理节点的mfsexports.cfg的配置如下: [root@master-server mfs]# pwd /usr/local/mfs/etc/mfs [root@master-server mfs]# vim mfsexports.cfg ....... 182.48.115.238 / rw,alldirs,maproot=0 182.48.115.238 . rw //即允许182.48.115.238客户机挂载MFS的根目录 # for huanqiu data 182.48.115.239 /huanqiu rw.maproot=0 //即允许182.48.115.239客户机挂载MFS的子目录huanqiu(这个子目录是真实存在MFS文件系统下的),在客户端写入的数据就会保存到MFS的子目录huanqiu下 # for hatime data 182.48.115.240 /hqsb/hqtime rw.maproot=0 //即允许182.48.115.240客户机挂载MFS的根目录hqsb/hqtime(这个子目录是真实存在MFS文件系统下的) ----------------------------------------------------------------------------------------------------------------------- 在客户机182.48.115.238上挂载MFS文件系统的根目录,命令如下(挂载后,df -h或mount命令都能查看到挂载信息) [root@clinet-238 ~]# /usr/local/mfs/bin/mfsmount /mnt/mfs -H 182.48.115.233 这样在182.48.115.238机器的挂载目录/mnt/mfs里的数据就是MFS文件系统根目录下的数据。这个挂载目录在客户机上可以随意定义。在/mnt/mfs挂载目录下写入数据,就会自动同步到MFS文件系统的根目录下 [root@clinet-238 ~]# cd /mnt/mfs [root@clinet-238 mfs]# ll total 3 drwxr-xr-x. 3 root root 0 May 23 12:57 hqsb drwxr-xr-x. 2 root root 1800 May 23 13:04 huanqiu -rw-r--r--. 1 root root 39 May 23 12:54 ip_list ----------------------------------------------------------------------------------------------------------------------- 在客户机182.48.115.239上挂载MFS文件系统的子目录huanqiu [root@clinet-239]# mkdir -p /opt/huanqiu [root@clinet-239]# /usr/local/mfs/bin/mfsmount /opt/huanqiu -H 182.48.115.233 -S huanqiu //后面的子目录写成"huanqiu"或"/huanqiu"都可以 [root@clinet-239]# cd /opt/huanqiu/ [root@clinet-239]# echo "huanqiu test data" > hq.txt //写入数据,则会自动同步到MFS文件系统的子目录huanqiu下 到挂载MFS根目录的182.48.115.238客户机上查看,发现MFS的子目录huanqiu下已经有了新数据 [root@clinet-238 ~]# cd /mnt/mfs [root@clinet-238 mfs]# ll total 3 drwxr-xr-x. 3 root root 0 May 23 12:57 hqsb drwxr-xr-x. 2 root root 1800 May 23 13:04 huanqiu -rw-r--r--. 1 root root 39 May 23 12:54 ip_list [root@clinet-238 mfs]# cd huanqiu/ [root@clinet-238 huanqiu]# ll total 1 -rw-r--r--. 1 root root 18 May 23 13:04 hq.txt [root@clinet-238 huanqiu]# cat hq.txt huanqiu test data ----------------------------------------------------------------------------------------------------------------------- 在客户机182.48.115.240上挂载MFS文件系统的子目录hqsb/hqtime [root@clinet-240 ~]# mkdir -p /mfs/data [root@clinet-240 ~]# /usr/local/mfs/bin/mfsmount /mfs/data -H 182.48.115.233 -S /hqsb/hqtime //将MFS文件系统的子目录hqsb/hqtime挂载到本机的/mfs/data下 [root@clinet-240 ~]# cd /mfs/data/ [root@clinet-240 data]# echo "hatime 12313123123" > test 到挂载MFS根目录的182.48.115.238客户机上查看,发现MFS的子目录hqsb/hqtime下已经有了新数据 [root@clinet-238 ~]# cd /mnt/mfs/hqsb/hqtime/ [root@clinet-238 hqtime]# ls test [root@clinet-238 hqtime]# cat test hatime 12313123123 2)客户端重启后自动挂载mfs目录 # vim /etc/rc.local ...... /sbin/modprobe fuse /usr/bin/mfsmount /mnt1 -H mfsmaster -S /backup/db /usr/bin/mfsmount /mnt2 -H mfsmaster -S /app/image Moosefs官方网页上有提到,1.6.x以上的版本还可以通过/etc/fstab的方式,系统重启后自动挂载mfs文件系统,测试之后,并没有成功,原因是FUSE模块没有加载到内核。 所以,用/etc/fstab,FUSE模块需要事先将其编译进系统内核中才行。fstab的配置如下: # vim /etc/fstab mfsmount /mnt fuse mfsmaster=MASTER_IP,mfsport=9421,_netdev 0 0 //重启系统后挂载MFS的根目录 mfsmount /mnt fuse mfstermaster=MASTER_IP,mfsport=9421,mfssubfolder=/subdir,_netdev 0 0 //重启系统后挂载MFS的子目录 采用fstab配置文件挂载方式可以通过如下命令,测试是否配置正确: # mount –a –t fuse 3)Moosefs可以节省空间 通过测试发现,拷贝到mfs目录下的文件大小比ext3下的小了很多,开始以为是少同步了一些文件,于是又将mfs下的所有文件拷回到ext3下,发现大小和之前的一致。 所以说,mfs对小文件(测试文件为8K左右)存储空间的节省非常明显,可以节省一半的空间。 对于大文件存储,mfs同样可以节省空间。拷贝了一个1.7G文件到mfs下,大小为1.6G。
5->MFS元数据损坏后的恢复(简单解决Master单点故障的瓶颈)
当master管理节点(即元数据服务器)出现故障导致元数据损坏后,可以通过Metalogger元数据日志服务器上的备份数据进行恢复! 通常元数据有两部分的数据: 1)主要元数据文件metadata.mfs,当mfsmaster运行的时候会被命名为metadata.mfs.back 2)元数据改变日志changelog.*.mfs,存储了过去的N小时的文件改变。主要的元数据文件需要定期备份,备份的频率取决于取决于多少小时changelogs储存。 元数据changelogs应该实时的自动复制。自从MooseFS 1.6.5,这两项任务是由mfsmetalogger守护进程做的。 元数据损坏是指由于各种原因导致master上的metadata.mfs数据文件不可用。一旦元数据损坏,所有的存储在moosefs上的文件都不可使用。 一旦master管理节点出现崩溃(比如因为主机或电源失败),需要最后一个元数据日志changelog并入主要的metadata中。 这个操作时通过mfsmetarestore工具做的,最简单的方法是: # /usr/local/mfs/sbin/mfsmetarestore -a 如果master数据被存储在MooseFS编译指定地点外的路径,则要利用-d参数指定使用,比如: # /usr/local/mfs/sbin/mfsmetarestore -a -d /storage/mfsmaster ------------------------------------------------------------------------------------------------------------------------- 下面模拟一个元数据损坏后的恢复操作 停止master节点并删除metadata.mfs及changelog.0.mfs(变更日志文件)。 [root@master-server ~]# /etc/init.d/mfsmaster stop //master服务关闭后,在客户端的现象是:挂载目录下操作一直在卡的状态中 [root@master-server ~]# cd /usr/local/mfs/var/mfs [root@master-server mfs]# ls changelog.11.mfs changelog.21.mfs changelog.24.mfs changelog.28.mfs changelog.34.mfs changelog.5.mfs metadata.mfs.empty changelog.19.mfs changelog.22.mfs changelog.25.mfs changelog.29.mfs changelog.3.mfs metadata.mfs mfsmaster changelog.1.mfs changelog.23.mfs changelog.27.mfs changelog.2.mfs changelog.4.mfs metadata.mfs.back.1 stats.mfs [root@master-server mfs]# rm -rf ./* 然后重新启动master将报错: [root@master-server mfs]# /etc/init.d/mfsmaster start open files limit has been set to: 16384 working directory: /usr/local/mfs/var/mfs lockfile created and locked initializing mfsmaster modules ... exports file has been loaded topology file has been loaded loading metadata ... can't find metadata.mfs - try using option '-a' init: metadata manager failed !!! error occurred during initialization - exiting ---------------------------------------现在进行元数据恢复--------------------------------- 从metalogger元数据日志服务器上将最新一份metadata_ml.mfs.back及changelog_ml.0.mfs复制到master元数据服务器的的数据目录下,并注意文件属主属组为mfs。 (或者可以拷贝全部数据到Master元数据服务器上,这个没验证) 先登陆metalogger元数据日志服务器上查看 [root@metalogger ~]# cd /usr/local/mfs/var/mfs total 108 -rw-r-----. 1 mfs mfs 2186 May 23 13:27 changelog_ml.0.mfs -rw-r-----. 1 mfs mfs 26 May 23 03:46 changelog_ml.10.mfs -rw-r-----. 1 mfs mfs 400 May 22 19:11 changelog_ml.18.mfs -rw-r-----. 1 mfs mfs 1376 May 23 12:57 changelog_ml.1.mfs -rw-r-----. 1 mfs mfs 1313 May 22 17:41 changelog_ml.20.mfs -rw-r-----. 1 mfs mfs 9848 May 22 16:58 changelog_ml.21.mfs -rw-r-----. 1 mfs mfs 18979 May 22 15:57 changelog_ml.22.mfs -rw-r-----. 1 mfs mfs 1758 May 22 14:58 changelog_ml.23.mfs -rw-r-----. 1 mfs mfs 2388 May 23 11:29 changelog_ml.2.mfs -rw-r-----. 1 mfs mfs 3780 May 23 10:59 changelog_ml.3.mfs -rw-r-----. 1 mfs mfs 1886 May 23 09:56 changelog_ml.4.mfs -rw-r-----. 1 mfs mfs 558 May 23 13:10 changelog_ml_back.0.mfs -rw-r-----. 1 mfs mfs 1376 May 23 13:10 changelog_ml_back.1.mfs -rw-r--r--. 1 mfs mfs 8 May 22 14:16 metadata.mfs -rw-r-----. 1 mfs mfs 4783 May 23 13:10 metadata_ml.mfs.back -rw-r-----. 1 mfs mfs 4594 May 23 12:10 metadata_ml.mfs.back.1 -rw-r-----. 1 mfs mfs 4834 May 23 11:10 metadata_ml.mfs.back.2 -rw-r-----. 1 mfs mfs 4028 May 23 10:10 metadata_ml.mfs.back.3 [root@metalogger mfs]# rsync -e "ssh -p22" -avpgolr metadata_ml.mfs.back changelog_ml.0.mfs 182.48.115.233:/usr/local/mfs/var/mfs/ 然后在master元数据服务器上修改复制过来的文件属性 [root@master-server mfs]# chown -R mfs.mfs ./* [root@master-server mfs]# ll total 12 -rw-r-----. 1 mfs mfs 27 May 23 14:40 changelog.0.mfs -rw-r-----. 1 mfs mfs 2213 May 23 14:34 changelog_ml.0.mfs 启动master服务 [root@master-server mfs]# /etc/init.d/mfsmaster start open files limit has been set to: 16384 working directory: /usr/local/mfs/var/mfs lockfile created and locked initializing mfsmaster modules ... exports file has been loaded topology file has been loaded loading metadata ... can't find metadata.mfs - try using option '-a' init: metadata manager failed !!! error occurred during initialization - exiting 发现启动还是报错!!! mfs的操作日志都记录到changelog.0.mfs里面。changelog.0.mfs每小时合并一次到metadata.mfs中 此时应该利用mfsmetarestore命令合并元数据changelogs,可以用自动恢复模式命令"mfsmetarestore –a" [root@master-server mfs]# /usr/local/mfs/sbin/mfsmetarestore -a mfsmetarestore has been removed in version 1.7, use mfsmaster -a instead 然后需要以-a方式启动master [root@master-server mfs]# /usr/local/mfs/sbin/mfsmaster -a open files limit has been set to: 16384 working directory: /usr/local/mfs/var/mfs lockfile created and locked initializing mfsmaster modules ... exports file has been loaded topology file has been loaded loading metadata ... loading sessions data ... ok (0.0000) loading storage classes data ... ok (0.0000) loading objects (files,directories,etc.) ... ok (0.1653) loading names ... ok (0.1587) loading deletion timestamps ... ok (0.0000) loading quota definitions ... ok (0.0000) loading xattr data ... ok (0.0000) loading posix_acl data ... ok (0.0000) loading open files data ... ok (0.0000) loading flock_locks data ... ok (0.0000) loading posix_locks data ... ok (0.0000) loading chunkservers data ... ok (0.0000) loading chunks data ... ok (0.1369) checking filesystem consistency ... ok connecting files and chunks ... ok all inodes: 17 directory inodes: 4 file inodes: 13 chunks: 10 metadata file has been loaded no charts data file - initializing empty charts master <-> metaloggers module: listen on *:9419 master <-> chunkservers module: listen on *:9420 main master server module: listen on *:9421 mfsmaster daemon initialized properly [root@master-server mfs]# ls changelog.0.mfs changelog_ml_back.1.mfs metadata_ml.mfs.back 此时,master服务已经启动,元数据已经恢复了。 [root@master-server mfs]# ps -ef|grep mfs mfs 556 1 0 13:46 ? 00:00:26 /usr/local/mfs/sbin/mfsmaster -a root 580 24958 0 14:32 pts/0 00:00:00 grep mfs [root@master-server mfs]# lsof -i:9420 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME mfsmaster 556 mfs 9u IPv4 120727 0t0 TCP *:9420 (LISTEN) mfsmaster 556 mfs 11u IPv4 120737 0t0 TCP master-server:9420->chunkServer1:52513 (ESTABLISHED) mfsmaster 556 mfs 12u IPv4 120742 0t0 TCP master-server:9420->chunkServer2:45785 (ESTABLISHED) [root@master-server mfs]# ll total 12 -rw-r-----. 1 mfs mfs 27 May 23 14:40 changelog.0.mfs -rw-r-----. 1 mfs mfs 2213 May 23 14:34 changelog_ml.0.mfs -rw-r-----. 1 mfs mfs 3967 May 23 14:10 metadata_ml.mfs.back 可以在客户端挂载mfs文件系统,查看元数据是否恢复及数据使用是否正常。
6->Moosefs存储空间扩容
如上的部署环境:一台master、一台metalogger、两台chunkserver(182.48.115.236和182.48.115.237)
在客户端挂载MFS,并设置副本数为2。注意,副本数不能多余chunkserver的数量!
[root@clinet-server ~]# /usr/local/mfs/bin/mfsmount /mnt/mfs -H 182.48.115.233
mfsmaster accepted connection with parameters: read-write,restricted_ip,admin ; root mapped to root:root
[root@clinet-server ~]# /usr/local/mfs/bin/mfssetgoal -r 2 /mnt/mfs/
/mnt/mfs/:
inodes with goal changed: 19
inodes with goal not changed: 0
inodes with permission denied: 0
[root@clinet-server ~]# /usr/local/mfs/bin/mfsgetgoal /mnt/mfs
/mnt/mfs: 2
准备数据
[root@clinet-server mfs]# echo "asdfasdf" > /mnt/mfs/huihui
查看副本数情况
[root@clinet-server mfs]# /usr/local/mfs/bin/mfsfileinfo /mnt/mfs/huihui
/mnt/mfs/huihui:
chunk 0: 0000000000000031_00000001 / (id:49 ver:1)
copy 1: 182.48.115.236:9422 (status:VALID)
copy 2: 182.48.115.237422 (status:VALID)
如上,这个MFS文件系统下的huihui文件被切成了1个块(chunks),做成了2个副本分别放在了182.48.115.236和182.48.115.237的chunkserver上了。
这两个chunkserver只要有一个还在提供服务,则客户端就能正常共享MFS下的这个文件数据。但如果两个chunkserver都出现故障而不提供服务了,那
么客户端就不能共享MFS下的这个文件了。
注意:
1)上面例子的文件太小,小文件的话,一般是只切割成了一个块,如果文件比较大的话,就会切成很多歌chunks块,比如chunk 0、chunk 1、chunk2、....
2)一旦副本数设定,并且副本已经存放到了分配的chunkserver上,后续再添加新的chunkserver,那么这些副本也不会再次放到这些新的chunkserver上了。
除非重新调整goal副本数,则chunks块的副本会重新匹配chunkserver进行存放。
---------------------------------再看一个大文件的例子--------------------------------------------
上传一个200多M的大文件到MFS文件系统里
[root@clinet-server ~]# cp -r install.img /mnt/mfs
[root@clinet-server ~]# du -sh /mnt/mfs/images/
270M /mnt/mfs/install.img
[root@clinet-server ~]# /usr/local/mfs/bin/mfsgetgoal /mnt/mfs/images/
/mnt/mfs/images/: 2
查看文件的副本数。如下发现这个大文件被切割成了4个chunks块
[root@clinet-server mfs]# /usr/local/mfs/bin/mfsfileinfo /mnt/mfs/install.img
/mnt/mfs/install.img:
chunk 0: 0000000000000034_00000001 / (id:52 ver:1)
copy 1: 182.48.115.236:9422 (status:VALID)
copy 2: 182.48.115.237:9422 (status:VALID)
chunk 1: 0000000000000035_00000001 / (id:53 ver:1)
copy 1: 182.48.115.236:9422 (status:VALID)
copy 2: 182.48.115.237:9422 (status:VALID)
chunk 2: 0000000000000036_00000001 / (id:54 ver:1)
copy 1: 182.48.115.236:9422 (status:VALID)
copy 2: 182.48.115.237:9422 (status:VALID)
chunk 3: 000000000000003B_00000001 / (id:59 ver:1)
copy 1: 182.48.115.236:9422 (status:VALID)
copy 2: 182.48.115.237:9422 (status:VALID)
chunk 4: 000000000000003C_00000001 / (id:60 ver:1)
copy 1: 182.48.115.236:9422 (status:VALID)
copy 2: 182.48.115.237:9422 (status:VALID)
新增加两台chunkserver节点(分别是103.10.86.20和103.10.86.22),扩容存储空间.chunkserver安装部署过程如上记录。
如果goal副本数不修改,依然保持之前设定的2个副本,那么以上文件的4个chunks的各自副本数依然还会放到之前的2个chunkserver上,
不会调整到新增加的chunkserver上。
调整goal副本数
[root@clinet-server ~]# /usr/local/mfs/bin/mfssetgoal 3 /mnt/mfs/install.img
/mnt/mfs/install.img: goal: 3
[root@clinet-server ~]# /usr/local/mfs/bin/mfsgetgoal /mnt/mfs/install.img
/mnt/mfs/install.img: 3
再次查看副本数据,可以看到数据进行重新平衡
[root@clinet-server ~]# /usr/local/mfs/bin/mfsfileinfo /mnt/mfs/install.img
/mnt/mfs/install.img:
chunk 0: 0000000000000034_00000001 / (id:52 ver:1)
copy 1: 103.10.86.22:9422 (status:VALID)
copy 2: 182.48.115.236:9422 (status:VALID)
copy 3: 182.48.115.237:9422 (status:VALID)
chunk 1: 0000000000000035_00000001 / (id:53 ver:1)
copy 1: 103.10.86.22:9422 (status:VALID)
copy 2: 182.48.115.236:9422 (status:VALID)
copy 3: 182.48.115.237:9422 (status:VALID)
chunk 2: 0000000000000036_00000001 / (id:54 ver:1)
copy 1: 103.10.86.20:9422 (status:VALID)
copy 2: 182.48.115.236:9422 (status:VALID)
copy 3: 182.48.115.237:9422 (status:VALID)
chunk 3: 000000000000003B_00000001 / (id:59 ver:1)
copy 1: 103.10.86.22:9422 (status:VALID)
copy 2: 182.48.115.236:9422 (status:VALID)
copy 3: 182.48.115.237:9422 (status:VALID)
chunk 4: 000000000000003C_00000001 / (id:60 ver:1)
copy 1: 103.10.86.20:9422 (status:VALID)
copy 2: 182.48.115.236:9422 (status:VALID)
copy 3: 182.48.115.237:9422 (status:VALID)
上面是最终重新平衡后的效果(需要经过一定的分配过程),如果中间注意观察,会发现chunks块的各个副本的分配的过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号