
Linux下Redis主从复制以及SSDB主主复制环境部署记录
前面的文章已经介绍了redis作为缓存数据库的说明,本文主要说下redis主从复制及集群管理配置的操作记录:
Redis主从复制(目前redis仅支持主从复制模式,可以支持在线备份、读写分离等功能。)
1)Redis的复制功能是支持多个数据库之间的数据同步。一类是主数据库(master),一类是从数据库(slave),主数据库可以进行读写操作,当发生写操作的时候自动 将数据同步到从数据库,而从数据库一般是只读的,并接收主数据库同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。 2)通过redis的复制功能可以很好的实现数据库的读写分离,提高服务器的负载能力。主数据库主要进行写操作,而从数据库负责读操作。
Redis主从复制流程图
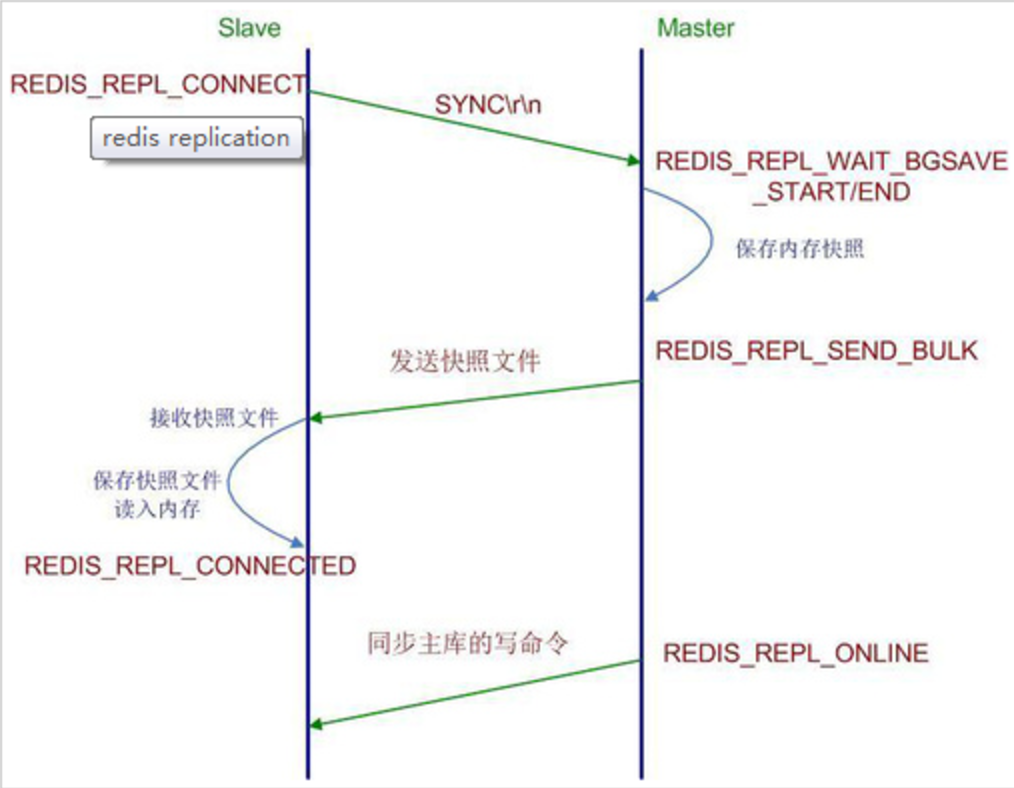
复制过程:
1)当一个从数据库启动时,会向主数据库发送sync命令, 2)主数据库接收到sync命令后会开始在后台保存快照(执行rdb操作),并将保存期间接收到的命令缓存起来 3)当快照完成后,redis会将快照文件和所有缓存的命令发送给从数据库。 4)从数据库收到后,会载入快照文件并执行收到的缓存的命令。
下面简单记录下Redis主从复制的操作记录:
1)机器信息 Redis主从结构支持一主多从,这里我使用一主两从(一主一从也行,配置一样) 主节点 182.48.115.236 master-node 从节点 182.48.115.237 slave-node1 从节点 182.48.115.238 slave-node2 关闭三个节点机的iptables防火墙和selinux 2)安装redis 三台节点机的安装步骤一样 [root@master-node ~]# wget http://download.redis.io/redis-stable.tar.gz [root@master-node ~]# tar -zvxf redis-stable.tar.gz [root@master-node ~]# cd redis-stable [root@master-node redis-stable]# make [root@master-node redis-stable]# cd src/ [root@master-node src]# cp redis-server redis-cli redis-check-aof redis-check-rdb redis-sentinel redis-trib.rb /usr/local/bin/ 然后新建目录,存放配置文件 [root@master-node src]# mkdir /etc/redis [root@master-node src]# mkdir /var/redis [root@master-node src]# mkdir /var/redis/log [root@master-node src]# mkdir /var/redis/run [root@master-node src]# mkdir /var/redis/redis 在redis解压根目录中找到配置文件模板 [root@master-node src]# cd ../ [root@master-node redis-stable]# cp redis.conf /etc/redis/redis.conf 设置启动脚本 [root@master-node redis-stable]# cp utils/redis_init_script /etc/init.d/redis [root@master-node redis-stable]# chmod 755 /etc/init.d/redis 修改脚本pid及conf路径为实际路径 [root@master-node redis-stable]# vim /etc/init.d/redis ...... REDISPORT=6379 EXEC=/usr/local/bin/redis-server CLIEXEC=/usr/local/bin/redis-cli PIDFILE=/var/redis/run/redis_6379.pid CONF="/etc/redis/redis.conf" ....... 3)主从复制配置 master-node [root@master-node ~]# vim /etc/redis/redis.conf ....... port 6379 ....... daemonize yes //这个修改为yes ....... bind 0.0.0.0 //绑定的主机地址。说明只能通过这个ip地址连接本机的redis。最好绑定0.0.0.0;注意这个不能配置成127.0.0.1,否则复制会失败!用0.0.0.0或者本机ip地址都可以 ....... pidfile /var/redis/run/redis_6379.pid ....... logfile /var/redis/log/redis_6379.log ....... dir /var/redis/redis #redis数据目录 ....... appendonly yes #启用AOF持久化方式 appendfilename "appendonly.aof" #AOF文件的名称,默认为appendonly.aof appendfsync everysec #每秒钟强制写入磁盘一次,在性能和持久化方面做了很好的折中,是受推荐的方式。 ..... save 900 1 #启用RDB快照功能,默认就是启用的 save 300 10 save 60 10000 #即在多少秒的时间内,有多少key被改变的数据添加到.rdb文件里 ....... dbfilename dump.rdb #快照文件名称 ...... slave-node1和slave-node2两个从节点相比于master-node主节点的redis.conf配置,只是多了下面一行配置,其它都一样: slaveof 182.48.115.236 6379 启动三个节点的redis(启动命令一样) [root@master-node ~]# /etc/init.d/redis start Starting Redis server... [root@master-node ~]# lsof -i:6379 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME redis-ser 10475 root 4u IPv4 88640 0t0 TCP localhost:6379 (LISTEN) 登陆主节点master-node的redis,查看状态 [root@master-node ~]# redis-cli -h 127.0.0.1 -p 6379 //使用182.48.115.236也可以登录,或者直接使用redis-cli也可以登录 127.0.0.1:6379> info ...... ...... # Replication role:master //节点在集群中的状态 connected_slaves:2 //slave节点的个数 slave0:ip=182.48.115.238,port=6379,state=online,offset=1,lag=1 slave1:ip=182.48.115.237,port=6379,state=online,offset=1,lag=1 ........ 登录从节点slave-node1的redis,查看状态 [root@slave-node1 ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> info ....... ....... # Replication role:slave master_host:182.48.115.236 master_port:6379 master_link_status:up ...... 登录从节点slave-node2的redis,查看状态 [root@slave-node2 ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> info ...... # Replication role:slave master_host:182.48.115.236 master_port:6379 master_link_status:up ...... 4)测试数据同步 主节点master-node上写入新数据 [root@master-node ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> set name wangshibo OK 127.0.0.1:6379> get name "wangshibo" 然后到两台从节点上查看是否同步了上面写入的数据 [root@slave-node1 ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> get name "wangshibo" [root@slave-node2 ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> get name "wangshibo" redis主从复制默认是读写分离的,即: 主节点上可以读写操作;从节点上只能进行读操作,不能写数据 [root@slave-node1 ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> set name huanqiu (error) READONLY You can't write against a read only slave. [root@slave-node2 ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> set name huanqiu (error) READONLY You can't write against a read only slave. 5)主从切换 5.1)停止主节点master-node的redis [root@master-node ~]# redis-cli -h 127.0.0.1 -p 6379 shutdown [root@master-node ~]# redis-cli -h 127.0.0.1 -p 6379 Could not connect to Redis at 127.0.0.1:6379: Connection refused Could not connect to Redis at 127.0.0.1:6379: Connection refused 将从节点slave-node1的redis设成主redis [root@slave-node1 ~]# redis-cli -h 127.0.0.1 -p 6379 slaveof NO ONE //这条命了只是临时将该节点设置为主节点;当redis重启后,就会失效;可以登录redis,通过info信息查看! OK [root@slave-node1 ~]# redis-cli -h 127.0.0.1 -p 6379 //变为主redis后,slave-node1就可以进行写入操作了 127.0.0.1:6379> set name huanqiu OK 127.0.0.1:6379> info ...... # Replication role:master //可知已经变成master主节点了 connected_slaves:0 master_repl_offset:0 这时候master-node节点已经故障了,而另一个从节点slave-node2还跟它有主从关系。此时slave-node1已经变成主redis了,所以可以将slave-node2的主从关系中的主节点 配置修改为slave-node1(即182.48.115.237) 5.2)原来的主redis恢复正常了,要重新切换回去 比如原来的主redis节点master-node现在恢复了 [root@master-node ~]# /etc/init.d/redis start Starting Redis server... [root@master-node ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> info ...... # Replication role:master //原来的主节点恢复了,发现只有一个从节点save-node2。另一个从节点slave-node1在master-node故障期间临时变为主节点 connected_slaves:1 slave0:ip=182.48.115.238,port=6379,state=online,offset=1,lag=0 ...... 那么现在要重新将主节点切换回去。步骤如下: a)登录临时切换的主节点slave-node1 [root@slave-node1 ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> set name hahahha OK 127.0.0.1:6379> get name "hahahha" 127.0.0.1:6379> save //将数据保存 OK b)将现在的主redis(即slave-node1节点,临时设置的主节点)根目录下app文件和dump.rdb文件拷贝覆盖到原来主redis的根目录(覆盖前将原来主redis下的持久化文件备份下) [root@slave-node1 ~]# rsync -e "ssh -p22" -avpgolr /var/redis/redis/dump.rdb 182.48.115.236:/var/redis/redis/ [root@slave-node1 ~]# rsync -e "ssh -p22" -avpgolr /var/redis/redis/appendonly.aof 182.48.115.236:/var/redis/redis/ c)重启原来的主redis(即master-node节点) [root@master-node ~]# /etc/init.d/redis stop [root@master-node ~]# /etc/init.d/redis start d)在现在的主redis(即slave-node1)中切换(或者直接重启该节点的redis,因为redis.conf文件中已经配置了;如果不想重启redis,就使用下面的命令) [root@slave-node1 ~]# redis-cli -h 127.0.0.1 -p 6379 slaveof 182.48.115.236 6379 OK e)登录原来的主redis(也就是master-node)查看 [root@master-node ~]# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> info ....... # Replication role:master connected_slaves:2 slave0:ip=182.48.115.237,port=6379,state=online,offset=1,lag=0 slave1:ip=182.48.115.238,port=6379,state=online,offset=1,lag=0 master_repl_offset:1 ...... ------------------------------------------------------------------------------------------------------------------ 注意事项 如果使用主从复制,那么要确保你的master激活了持久化,或者确保它不会在当掉后自动重启,原因: a)slave是master的完整备份,因此如果master通过一个空数据集重启,slave也会被清掉。 b)在配置redis复制功能的时候,如果主数据库设置了密码,需要在从数据的配置文件中通过masterauth参数设置主数据库的密码,这样从数据库在连接 主数据库时就会自动使用auth命令认证了。相当于做了一个免密码登录。(我上面的例子中没有设置密码)
Redis的主从自动切换(failover)可以通过Redis自带的Sentinel工具来实现(具体操作这里就先不介绍了)。redis的sentinel系统用于管理多个redis服务器,
该系统主要执行三个任务:监控、提醒、自动故障转移。
1)监控(Monitoring): Redis Sentinel实时监控主服务器和从服务器运行状态,并且实现自动切换。
2)提醒(Notification):当被监控的某个 Redis 服务器出现问题时, Redis Sentinel 可以向系统管理员发送通知, 也可以通过 API 向其他程序发送通知。
3)自动故障转移(Automatic failover): 当一个主服务器不能正常工作时,Redis Sentinel 可以将一个从服务器升级为主服务器, 并对其他从服务器进行配置,
让它们使用新的主服务器。当应用程序连接Redis 服务器时, Redis Sentinel会告之新的主服务器地址和端口。
注意:
在使用sentinel监控主从节点的时候,从节点需要是使用动态方式配置的,如果直接修改配置文件,后期sentinel实现故障转移的时候会出问题。
------------------------------------------------------------------------------------------------------------------------------------------------
Redis默认只支持主从模式,不支持主主模式,可以使用SSDB主主模式代替Redis实现主主同步环境。SSDB是一个快速的用来存储十亿级别列表数据的开源 NoSQL 数据库。支持Key-value, Keyhashmap, Key-zset(sorted set) 等数据结构,十分适合存储数亿条级别的列表, 排序表等集合数据, 是Redis的替代和增强方案。
SSDB特性:
1)替代 Redis 数据库, Redis 的100倍容量 2)LevelDB 网络支持, 使用C/C++ 开发 3)Redis API 兼容, 支持 Redis 客户端 4)适合存储集合数据, 如 list, hash, zset... 5)客户端 API 支持的语言包括: C++, PHP, Python,Cpy,Java,Nodejs,Ruby, Go等 6)持久化的队列服务 7)主从复制,支持双主(双master)和多主架构, 负载均衡 8)图形化管理工具(phpssdbadmin)
SSDB的主从同步策略非常简单, 就是把主(Master)上的所有写操作(Binlogs), 在从(Slave)上再执行一遍. MySQL 的主从同步也是一样. 而多主可以理解为互为主从.
SSDB的双主和多主配置
SSDB 数据库是支持双主(双 Master)和多主架构的. 而且, 我们的应用也是部署双主架构, 但当作单主来用. 也就是说, 平时只往其中一个写, 当出现故障时, 整体切换到另一个主上面. 如果应用层已经解决了数据拆分, 也即不会两个节点同时操作一个 key, 那么就可以放心使用双主同时写入.
SSDB 双主的配置非常简单:
server1服务器
replication:
slaveof:
id: svc_2
# sync|mirror, default is sync
type: mirror
ip: 192.168.1.10
port: 8888
server2服务器
replication:
slaveof:
id: svc_1
# sync|mirror, default is sync
type: mirror
ip: 192.168.1.11
port: 8888
只需要将type设置为mirror, 然后每个节点各指向对方即可。如果是多主, 则每个节点要指向其它 n-1 个节点。
SSDB 主主同步模式部署记录
SSDB主主模式的部署记录:
182.48.115.236 master-node1
182.48.115.237 master-node2
1)安装SSDB(在两个节点机上安装步骤一样,如下)
[root@master-node1 ~]# mkdir -p /home/slim/ssdb
[root@master-node1 ~]# wget https://github.com/ideawu/ssdb/archive/master.zip
[root@master-node1 ~]# unzip master.zip
[root@master-node1 ~]# cd ssdb-master/
[root@master-node1 ssdb-master]# make PREFIX=/home/slim/ssdb
[root@master-node1 ssdb-master]# make PREFIX=/home/slim/ssdb install
2)主主模式配置
master-node1节点上的配置
[root@master-node1 ~]# cd /home/slim/ssdb/
[root@master-node1 ssdb]# cp ssdb.conf ssdb.conf.bak
[root@master-node1 ssdb]# vim ssdb.conf
# ssdb-server config
# MUST indent by TAB!
# relative to path of this file, directory must exists
work_dir = ./var
pidfile = ./var/ssdb.pid
server:
ip: 182.48.115.236
port: 8888
# bind to public ip
#ip: 0.0.0.0
# format: allow|deny: all|ip_prefix
# multiple allows or denys is supported
#deny: all
#allow: 127.0.0.1
#allow: 192.168
# auth password must be at least 32 characters
#auth: very-strong-password
#readonly: yes
replication:
binlog: yes
# Limit sync speed to *MB/s, -1: no limit
sync_speed: -1
slaveof:
# to identify a master even if it moved(ip, port changed)
# if set to empty or not defined, ip:port will be used.
id: svc_1
# sync|mirror, default is sync
type: mirror
host: 182.48.115.237
port: 8888
logger:
level: debug
output: log.txt
rotate:
size: 1000000000
leveldb:
# in MB
cache_size: 500
# in MB
write_buffer_size: 64
# in MB/s
compaction_speed: 1000
# yes|no
compression: yes
master-node2节点上的配置
[root@master-node2 ~]# cd /home/slim/ssdb/
[root@master-node2 ssdb]# cp ssdb.conf ssdb.conf.bak
[root@master-node2 ssdb]# vim ssdb.conf
# ssdb-server config
# MUST indent by TAB!
# relative to path of this file, directory must exists
work_dir = ./var
pidfile = ./var/ssdb.pid
server:
ip: 182.48.115.237
port: 8888
# bind to public ip
#ip: 0.0.0.0
# format: allow|deny: all|ip_prefix
# multiple allows or denys is supported
#deny: all
#allow: 127.0.0.1
#allow: 192.168
# auth password must be at least 32 characters
#auth: very-strong-password
#readonly: yes
replication:
binlog: yes
# Limit sync speed to *MB/s, -1: no limit
sync_speed: -1
slaveof:
# to identify a master even if it moved(ip, port changed)
# if set to empty or not defined, ip:port will be used.
id: svc_2
# sync|mirror, default is sync
type: mirror
host: 182.48.115.236
port: 8888
logger:
level: debug
output: log.txt
rotate:
size: 1000000000
leveldb:
# in MB
cache_size: 500
# in MB
write_buffer_size: 64
# in MB/s
compaction_speed: 1000
# yes|no
compression: yes
3)启动服务(两节点启动命令一样)
[root@master-node1 ~]# /home/slim/ssdb/ssdb-server -d /home/slim/ssdb/ssdb.conf
ssdb-server 1.9.4
Copyright (c) 2012-2015 ssdb.io
[root@master-node1 ~]# ps -ef|grep ssdb
root 23803 1 0 21:05 ? 00:00:00 /home/slim/ssdb/ssdb-server -d /home/slim/ssdb/ssdb.conf
root 23819 23719 0 21:05 pts/0 00:00:00 grep ssdb
.........................................................................................................
关闭命令:
/home/slim/ssdb/ssdb-server /home/slim/ssdb/ssdb.conf -s stop
帮忙命令
/home/slim/ssdb/ssdb-server -h
.........................................................................................................
4)数据同步测试
在master-node1节点上写入数据
[root@master-node1 ~]# /home/slim/ssdb/ssdb-cli -h 182.48.115.236 -p 8888
ssdb (cli) - ssdb command line tool.
Copyright (c) 2012-2016 ssdb.io
'h' or 'help' for help, 'q' to quit.
ssdb-server 1.9.4
ssdb 182.48.115.236:8888> set name wangshibo
ok
(0.001 sec)
ssdb 182.48.115.236:8888> get name
wangshibo
(0.001 sec)
ssdb 182.48.115.236:8888>
在master-node2节点上查看:
[root@master-node2 ~]# /home/slim/ssdb/ssdb-cli -h 182.48.115.237 -p 8888
ssdb (cli) - ssdb command line tool.
Copyright (c) 2012-2016 ssdb.io
'h' or 'help' for help, 'q' to quit.
ssdb-server 1.9.4
ssdb 182.48.115.237:8888> get name
wangshibo
(0.001 sec)
同理,在master-node2节点上写入数据
[root@master-node2 ~]# /home/slim/ssdb/ssdb-cli -h 182.48.115.237 -p 8888
ssdb (cli) - ssdb command line tool.
Copyright (c) 2012-2016 ssdb.io
'h' or 'help' for help, 'q' to quit.
ssdb-server 1.9.4
ssdb 182.48.115.237:8888> set huanqiutest hahahah
ok
(0.001 sec)
ssdb 182.48.115.237:8888>
然后在另一台master-node1节点上查看
[root@master-node1 ~]# /home/slim/ssdb/ssdb-cli -h 182.48.115.236 -p 8888
ssdb (cli) - ssdb command line tool.
Copyright (c) 2012-2016 ssdb.io
'h' or 'help' for help, 'q' to quit.
ssdb-server 1.9.4
ssdb 182.48.115.236:8888> get huanqiutest
hahahah
(0.001 sec)
以上说明ssdb主主同步环境已经实现!
..............................................................................
ssdb服务监控
info 命令返回的信息
[root@master-node1 ~]# /home/slim/ssdb/ssdb-cli -h 182.48.115.236 -p 8888
........
ssdb 182.48.115.236:8888> info
........
replication
client 182.48.115.237:56014
type : mirror
status : SYNC
last_seq : 3
replication
slaveof 182.48.115.237:8888
id : svc_1
type : mirror
status : SYNC
last_seq : 2
copy_count : 1
sync_count : 1
[root@master-node2 ~]# /home/slim/ssdb/ssdb-cli -h 182.48.115.237 -p 8888
.........
ssdb 182.48.115.237:8888> info
.........
replication
client 182.48.115.236:50210
type : mirror
status : SYNC
last_seq : 2
replication
slaveof 182.48.115.236:8888
id : svc_2
type : mirror
status : SYNC
last_seq : 3
copy_count : 1
sync_count : 0
............................................................................
info命令后的消息参数解释:
1)binlogs
当前实例的写操作状态.
capacity: binlog 队列的最大长度
min_seq: 当前队列中的最小 binlog 序号
max_seq: 当前队列中的最大 binlog 序号
2)replication
可以有多条 replication 记录. 每一条表示一个连接进来的 slave(client), 或者一个当前服务器所连接的 master(slaveof).
slaveof|client ip:port, 远端 master/slave 的 ip:port。
type: 类型, sync|mirror.
status: 当前同步状态, DISCONNECTED|INIT|OUT_OF_SYNC|COPY|SYNC。
last_seq: 上一条发送或者收到的 binlog 的序号。
slaveof.id: master 的 id(这是从 slave's 角度来看的, 你永远不需要在 master 上配置它自己的 id)。
slaveof.copy_count: 在全量同步时, 已经复制的 key 的数量。
slaveof.sync_count: 发送或者收到的 binlog 的数量。
3)关于 status:
DISCONNECTED: 与 master 断开了连接, 一般是网络中断。
INIT: 初始化状态。
OUT_OF_SYNC: 由于短时间内在 master 有大量写操作, 导致 binlog 队列淘汰, slave 丢失同步点, 只好重新复制全部的数据。
COPY: 正在复制基准数据的过程中, 新的写操作可能无法及时地同步。
SYNC: 同步状态是健康的.
4)判断同步状态
binlogs.max_seq 是指当前实例上的最新一次的写(写/更新/删除)操作的序号, replication.client.last_seq 是指已发送给 slave 的最新一条 binlog 的序号。所以, 如果你想判断主从同步是否已经同步到位(实时更新), 那么就判断 binlogs.max_seq 和 replication.client.last_seq 是否相等。
---------------------SSDB备份与恢复----------------------
1)备份
支持了在线备份功能, 可以在不停止服务的情况下备份服务器数据,这个功能让 SSDB 更加成为一个真正生产环境的存储服务器。
[root@master-node1 ~]# /home/slim/ssdb/ssdb-dump 182.48.115.237 8888 ./backup_dir
这条命令从监听在182.48.115.237:8888 的SSDB服务器上备份全量的数据, 保存到本地新创建的目录 backup_dir, 这个目录其实是一个 LevelDB 的数据库(db)。
2)恢复
将 backup_dir 传输到服务器, 修改新ssdb服务器的配置文件, 将 SSDB 使用的数据库名改为 backup_dir, 然后重启 SSDB 即可。
3)使用主从(Master-Slave)架构实时备份
注意:
a)一般, 建议你将 logger.level 设置为 debug 级别。详情参考:日志解读
b)利用配置文件的 deny, allow 指令限制可信的来源 IP 访问,提高服务的安全。
c)SSDB 的配置文件使用一个 TAB 来表示一级缩进, 不要使用空格来缩进, 无论你用2个, 3个, 4个, 或者无数个空格都不行!
d)一定要记得修改你的 Linux 内核参数, 关于 max open files(最大文件描述符数)的内容,详情参考:构建C1000K的服务器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号