
Redis常见问题和解决办法梳理
一、Redis主从复制读写分离问题

1)数据复制的延迟
读写分离时,master会异步的将数据复制到slave,如果这是slave发生阻塞,则会延迟master数据的写命令,造成数据不一致的情况。
解决方法:可以对slave的偏移量值进行监控,如果发现某台slave的偏移量有问题,则将数据读取操作切换到master,但本身这个监控开销比较高,所以关于这个问题,大部分的情况是可以直接使用而不去考虑的。
读写分离时,master会异步的将数据复制到slave,如果这是slave发生阻塞,则会延迟master数据的写命令,造成数据不一致的情况。
解决方法:可以对slave的偏移量值进行监控,如果发现某台slave的偏移量有问题,则将数据读取操作切换到master,但本身这个监控开销比较高,所以关于这个问题,大部分的情况是可以直接使用而不去考虑的。
2)读到过期的数据
redis在删除过期key的时候有两种策略,第一种是懒惰型策略,即只有当redis操作这个key的时候,发现这个key过期,就会把这个key删除。第二种是定期采样一些key进行删除。
redis在删除过期key的时候有两种策略,第一种是懒惰型策略,即只有当redis操作这个key的时候,发现这个key过期,就会把这个key删除。第二种是定期采样一些key进行删除。
针对上面说的两种过期策略,会有个问题,即如果过期key的数量非常多,而采样速度根本比不上过期key的生成速度时会造成很多过期数据没有删除,但在redis里master和slave达成一种协议,slave是不能处理数据的(即不能删除数据)而客户端没有及时读到到过期数据同步给master将key删除,就会导致slave读到过期的数据(这个问题已经在redis3.2版本中解决)。
二、Redis主从配置不一致
这个问题一般很少见,但如果有,就会发生很多诡异的问题,例如:
1)max memory配置不一致:这个会导致数据的丢失。
原因:例如master配置4G,slave配置2G,这个时候主从复制可以成功,但如果在进行某一次全量复制的时候,slave拿到master的RDB加载数据时发现自身的2G内存不够用,这时就会触发slave的maxmemory策略,将数据进行淘汰。更可怕的是,在高可用的集群环境下,如果将这台slave升级成master的时候,就会发现数据已经丢失了。
2)数据结构优化参数不一致(例如hash-max-ziplist-entries):这个就会导致内存不一致。
原因:例如在master上对这个参数进行了优化,而在slave没有配置,就会造成主从节点内存不一致的诡异问题。
1)max memory配置不一致:这个会导致数据的丢失。
原因:例如master配置4G,slave配置2G,这个时候主从复制可以成功,但如果在进行某一次全量复制的时候,slave拿到master的RDB加载数据时发现自身的2G内存不够用,这时就会触发slave的maxmemory策略,将数据进行淘汰。更可怕的是,在高可用的集群环境下,如果将这台slave升级成master的时候,就会发现数据已经丢失了。
2)数据结构优化参数不一致(例如hash-max-ziplist-entries):这个就会导致内存不一致。
原因:例如在master上对这个参数进行了优化,而在slave没有配置,就会造成主从节点内存不一致的诡异问题。
三、规避全量复制
首先,redis复制有全量复制和部分复制两种,而全量复制的开销是很大的。那么来看看,如何尽量去规避全量复制。
1)第一次全量复制
当某一台slave第一次去挂到master上时,是不可避免要进行一次全量复制的,那么如何去想办法降低开销呢?
方案1:小主节点,例如把redis分成2G一个节点,这样一来会加速RDB的生成和同步,同时还可以降低fork子进程的开销(master会fork一个子进程来生成同步需要的RDB文件,而fork是要拷贝内存快的,如果主节点内存太大,fork的开销就大)。
方案2:既然第一次不可以避免,那可以选在集群低峰的时间(凌晨)进行slave的挂载。
2)节点RunID不匹配
例如主节点重启(RunID发生变化),对于slave来说,它会保存之前master节点的RunID,如果它发现了此时master的RunID发生变化,那它会认为这是master过来的数据可能是不安全的,就会采取一次全量复制。
解决办法:对于这类问题,只有是做一些故障转移的手段,例如master发生故障宕掉,选举一台slave晋升为master(哨兵或集群)。
3)复制积压缓冲区不足
在全量复制与部分复制那篇文章提到过,master生成RDB同步到slave,slave加载RDB这段时间里,master的所有写命令都会保存到一个复制缓冲队列里(如果主从直接网络抖动,进行部分复制也是走这个逻辑),待slave加载完RDB后,拿offset的值到这个队列里判断,如果在这个队列中,则把这个队列从offset到末尾全部同步过来,这个队列的默认值为1M。而如果发现offset不在这个队列,就会产生全量复制。
解决办法:增大复制缓冲区的配置 rel_backlog_size 默认1M,我们可以设置大一些,从而来加大offset的命中率。这个值,可以假设,一般网络故障时间是分钟级别,那可以根据当前的QPS来算一下每分钟可以写入多少字节,再乘以可能发生故障的分钟就可以得到我们这个理想的值。
1)第一次全量复制
当某一台slave第一次去挂到master上时,是不可避免要进行一次全量复制的,那么如何去想办法降低开销呢?
方案1:小主节点,例如把redis分成2G一个节点,这样一来会加速RDB的生成和同步,同时还可以降低fork子进程的开销(master会fork一个子进程来生成同步需要的RDB文件,而fork是要拷贝内存快的,如果主节点内存太大,fork的开销就大)。
方案2:既然第一次不可以避免,那可以选在集群低峰的时间(凌晨)进行slave的挂载。
2)节点RunID不匹配
例如主节点重启(RunID发生变化),对于slave来说,它会保存之前master节点的RunID,如果它发现了此时master的RunID发生变化,那它会认为这是master过来的数据可能是不安全的,就会采取一次全量复制。
解决办法:对于这类问题,只有是做一些故障转移的手段,例如master发生故障宕掉,选举一台slave晋升为master(哨兵或集群)。
3)复制积压缓冲区不足
在全量复制与部分复制那篇文章提到过,master生成RDB同步到slave,slave加载RDB这段时间里,master的所有写命令都会保存到一个复制缓冲队列里(如果主从直接网络抖动,进行部分复制也是走这个逻辑),待slave加载完RDB后,拿offset的值到这个队列里判断,如果在这个队列中,则把这个队列从offset到末尾全部同步过来,这个队列的默认值为1M。而如果发现offset不在这个队列,就会产生全量复制。
解决办法:增大复制缓冲区的配置 rel_backlog_size 默认1M,我们可以设置大一些,从而来加大offset的命中率。这个值,可以假设,一般网络故障时间是分钟级别,那可以根据当前的QPS来算一下每分钟可以写入多少字节,再乘以可能发生故障的分钟就可以得到我们这个理想的值。
四、规避复制风暴
什么是复制风暴?举例:master重启,其master下的所有slave检测到RunID发生变化,导致所有从节点向主节点做全量复制。尽管redis对这个问题做了优化,即只生成一份RDB文件,但需要多次传输,仍然开销很大。
1)单主节点复制风暴:主节点重启,多从节点全量复制
解决办法:更换复制拓扑,如下图:
解决办法:更换复制拓扑,如下图:
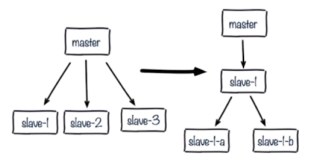
a)将原来master与slave中间加一个或多个slave,再在slave上加若干个slave,这样可以分担所有slave对master复制的压力。(这种架构还是有问题:读写分离的时候,slave1也发生了故障,怎么去处理?)
b)如果只是实现高可用,而不做读写分离,那当master宕机,直接晋升一台slave即可。
b)如果只是实现高可用,而不做读写分离,那当master宕机,直接晋升一台slave即可。
2)单机器复制风暴:机器宕机后的大量全量复制,如下图:
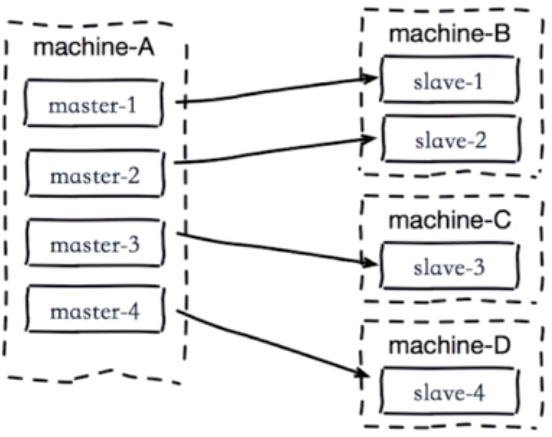
当machine-A这个机器宕机重启,会导致该机器所有master下的所有slave同时产生复制。(灾难)
解决:
a)主节点分散多机器(将master分散到不同机器上部署)
b)还有我们可以采用高可用手段(slave晋升master)就不会有类似问题了。
解决:
a)主节点分散多机器(将master分散到不同机器上部署)
b)还有我们可以采用高可用手段(slave晋升master)就不会有类似问题了。
=============Redis常见性能问题和解决办法=================
1)Master写内存快照
save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
2)Master AOF持久化
如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。
如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。
3)Master调用BGREWRITEAOF
Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
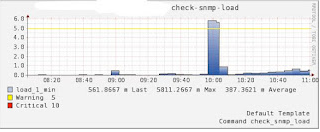
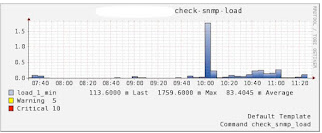
下面是我的一个实际项目的情况,大概情况是这样的:一个Master,4个Slave,没有Sharding机制,仅是读写分离,Master负责 写入操作和AOF日志备份,AOF文件大概5G,Slave负责读操作,当Master调用BGREWRITEAOF时,Master和Slave负载会 突然陡增,Master的写入请求基本上都不响应了,持续了大概5分钟,Slave的读请求过也半无法及时响应,Master和Slave的服务器负载图 如下:
Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
下面是我的一个实际项目的情况,大概情况是这样的:一个Master,4个Slave,没有Sharding机制,仅是读写分离,Master负责 写入操作和AOF日志备份,AOF文件大概5G,Slave负责读操作,当Master调用BGREWRITEAOF时,Master和Slave负载会 突然陡增,Master的写入请求基本上都不响应了,持续了大概5分钟,Slave的读请求过也半无法及时响应,Master和Slave的服务器负载图 如下:
Master Server load:
Slave server load:
上面的情况本来不会也不应该发生的,是因为以前Master的这个机器是Slave,在上面有一个shell定时任务在每天的上午10点调用 BGREWRITEAOF重写AOF文件,后来由于Master机器down了,就把备份的这个Slave切成Master了,但是这个定时任务忘记删除 了,就导致了上面悲剧情况的发生,原因还是找了几天才找到的。
将no-appendfsync-on-rewrite的配置设为yes可以缓解这个问题,设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入。最好是不开启Master的AOF备份功能。
4)Redis主从复制的性能问题
第一次Slave向Master同步的实现是:Slave向Master发出同步请求,Master先dump出rdb文件,然后将rdb文件全量 传输给slave,然后Master把缓存的命令转发给Slave,初次同步完成。第二次以及以后的同步实现是:Master将变量的快照直接实时依次发 送给各个Slave。不管什么原因导致Slave和Master断开重连都会重复以上过程。Redis的主从复制是建立在内存快照的持久化基础上,只要有 Slave就一定会有内存快照发生。虽然Redis宣称主从复制无阻塞,但由于Redis使用单线程服务,如果Master快照文件比较大,那么第一次全 量传输会耗费比较长时间,且文件传输过程中Master可能无法提供服务,也就是说服务会中断,对于关键服务,这个后果也是很可怕的。
第一次Slave向Master同步的实现是:Slave向Master发出同步请求,Master先dump出rdb文件,然后将rdb文件全量 传输给slave,然后Master把缓存的命令转发给Slave,初次同步完成。第二次以及以后的同步实现是:Master将变量的快照直接实时依次发 送给各个Slave。不管什么原因导致Slave和Master断开重连都会重复以上过程。Redis的主从复制是建立在内存快照的持久化基础上,只要有 Slave就一定会有内存快照发生。虽然Redis宣称主从复制无阻塞,但由于Redis使用单线程服务,如果Master快照文件比较大,那么第一次全 量传输会耗费比较长时间,且文件传输过程中Master可能无法提供服务,也就是说服务会中断,对于关键服务,这个后果也是很可怕的。
以上1.2.3.4根本问题的原因都离不开系统IO瓶颈问题,也就是硬盘读写速度不够快,主进程 fsync()/write() 操作被阻塞。
5)单点故障问题
由于目前Redis的主从复制还不够成熟,所以存在明显的单点故障问题,这个目前只能自己做方案解决,如:主动复制,Proxy实现Slave对 Master的替换等,这个也是目前比较优先的任务之一。
由于目前Redis的主从复制还不够成熟,所以存在明显的单点故障问题,这个目前只能自己做方案解决,如:主动复制,Proxy实现Slave对 Master的替换等,这个也是目前比较优先的任务之一。
简单总结:
- Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化。
- 如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
- 为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
- 尽量避免在压力较大的主库上增加从库
- 为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系 为:Master<–Slave1<–Slave2<–Slave3…….,这样的结构也方便解决单点故障问题,实现Slave对 Master的替换,也即,如果Master挂了,可以立马启用Slave1做Master,其他不变。
- Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化。
- 如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
- 为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
- 尽量避免在压力较大的主库上增加从库
- 为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系 为:Master<–Slave1<–Slave2<–Slave3…….,这样的结构也方便解决单点故障问题,实现Slave对 Master的替换,也即,如果Master挂了,可以立马启用Slave1做Master,其他不变。
*************** 当你发现自己的才华撑不起野心时,就请安静下来学习吧!***************

 浙公网安备 33010602011771号
浙公网安备 33010602011771号