
Elasticsearch 最佳运维实践 - 总结(二)
一、ElasticSearch使用场景
存储
ElasticSearch天然支持分布式,具备存储海量数据的能力,其搜索和数据分析的功能都建立在ElasticSearch存储的海量的数据之上;ElasticSearch很方便的作为海量数据的存储工具,特别是在数据量急剧增长的当下,ElasticSearch结合爬虫等数据收集工具可以发挥很大用处
搜索
ElasticSearch使用倒排索引,每个字段都被索引且可用于搜索,更是提供了丰富的搜索api,在海量数据下近实时实现近秒级的响应,基于Lucene的开源搜索引擎,为搜索引擎(全文检索,高亮,搜索推荐等)提供了检索的能力。 具体场景:
1. Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案;
2. GitHub(开源代码管理),搜索上千亿行代码;
3. 电商网站,检索商品;
4. 日志数据分析,logstash采集日志,ElasticSearch进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana);
数据分析
ElasticSearch也提供了大量数据分析的api和丰富的聚合能力,支持在海量数据的基础上进行数据的分析和处理。具体场景:
爬虫爬取不同电商平台的某个商品的数据,通过ElasticSearch进行数据分析(各个平台的历史价格、购买力等等);
二、ElasticSearch架构
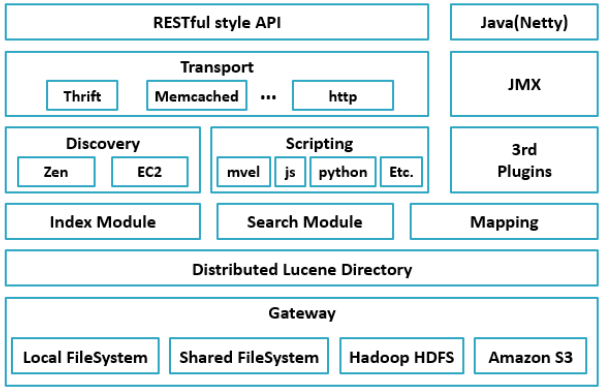
1. Gateway是ES用来存储索引的文件系统,支持多种类型。
2. Gateway的上层是一个分布式的lucene框架。
3. Lucene之上是ES的模块,包括:索引模块、搜索模块、映射解析模块等
4. ES模块之上是 Discovery、Scripting和第三方插件。Discovery是ES的节点发现模块,不同机器上的ES节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是由Discovery模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure。Scripting用来支持在查询语句中插入javascript、python等脚本语言,scripting模块负责解析这些脚本,使用脚本语句性能稍低。ES也支持多种第三方插件。
5. 再上层是ES的传输模块和JMX.传输模块支持多种传输协议,如 Thrift、memecached、http,默认使用http。JMX是java的管理框架,用来管理ES应用。
6. 最上层是ES提供给用户的接口,可以通过RESTful接口和ES集群进行交互。
[[ 小提示:目前市场上开放源代码的最好全文检索引擎工具包就属于 Apache 的 Lucene了。但是 Lucene 只是一个工具包,它不是一个完整的全文检索引擎。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。目前以 Lucene 为基础建立的开源可用全文搜索引擎主要是 Solr 和 Elasticsearch。Solr 和 Elasticsearch 都是比较成熟的全文搜索引擎,能完成的功能和性能也基本一样。但是 ES 本身就具有分布式的特性和易安装使用的特点,而 Solr 的分布式需要借助第三方来实现,例如通过使用 ZooKeeper 来达到分布式协调管理。不管是 Solr 还是 Elasticsearch 底层都是依赖于 Lucene,而 Lucene 能实现全文搜索主要是因为它实现了倒排索引的查询结构。]]
三、ElasticSearch核心概念
Near Realtime (NRT)近实时:数据提交索引后,立马就可以搜索到。
Cluster集群:一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具体相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。ElasticSearch的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看ElasticSearch集群,在逻辑上是个整体,你与任何一个节点的通信和与整个ElasticSearch集群通信是等价的。
Node 节点:存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。每一个运行实例称为一个节点,每一个运行实例既可以在同一机器上,也可以在不同的机器上。所谓运行实例,就是一个服务器进程,在测试环境中可以在一台服务器上运行多个服务器进程,在生产环境中建议每台服务器运行一个服务器进程。
Index 索引: 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。索引作动词时,指索引数据、或对数据进行索引。Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。Elasticsearch里的索引概念是名词而不是动词,在elasticsearch里它支持多个索引。 一个索引就是一个拥有相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来 标识(必须全部是小写字母的),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,你能够创建任意多个索引。
Document 文档:被索引的一条数据,索引的基本信息单元,以JSON格式来表示。一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档、某一个产品的一个文档、某个订单的一个文档。文档以JSON格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,一个文档物理上存在于一个索引之中,但文档必须被索引/赋予一个索引的type。
Shard 分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上(分片数创建索引时指定,创建后不可改了。备份数可以随时改)。索引分片,ElasticSearch可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。分片的好处:
- 允许我们水平切分/扩展容量
- 可在多个分片上进行分布式的、并行的操作,提高系统的性能和吞吐量。
Replication 备份: 一个分片可以有多个备份(副本)。备份的好处:
- 高可用扩展搜索的并发能力、吞吐量。
- 搜索可以在所有的副本上并行运行。
primary shard:主分片,每个文档都存储在一个分片中,当你存储一个文档的时候,系统会首先存储在主分片中,然后会复制到不同的副本中。默认情况下,一个索引有5个主分片。你可以在事先制定分片的数量,当分片一旦建立,分片的数量则不能修改。
replica shard:副本分片,每一个分片有零个或多个副本。副本主要是主分片的复制,其中有两个目的:
- 增加高可用性:当主分片失败的时候,可以从副本分片中选择一个作为主分片。
- 提高性能:当查询的时候可以到主分片或者副本分片中进行查询。默认情况下,一个主分配有一个副本,但副本的数量可以在后面动态的配置增加。副本必须部署在不同的节点上,不能部署在和主分片相同的节点上。
term索引词:在elasticsearch中索引词(term)是一个能够被索引的精确值。foo,Foo几个单词是不相同的索引词。索引词(term)是可以通过term查询进行准确搜索。
text文本:是一段普通的非结构化文字,通常,文本会被分析称一个个的索引词,存储在elasticsearch的索引库中,为了让文本能够进行搜索,文本字段需要事先进行分析;当对文本中的关键词进行查询的时候,搜索引擎应该根据搜索条件搜索出原文本。
analysis:分析是将文本转换为索引词的过程,分析的结果依赖于分词器,比如: FOO BAR, Foo-Bar, foo bar这几个单词有可能会被分析成相同的索引词foo和bar,这些索引词存储在elasticsearch的索引库中。当用 FoO:bAR进行全文搜索的时候,搜索引擎根据匹配计算也能在索引库中搜索出之前的内容。这就是elasticsearch的搜索分析。
routing路由:当存储一个文档的时候,他会存储在一个唯一的主分片中,具体哪个分片是通过散列值的进行选择。默认情况下,这个值是由文档的id生成。如果文档有一个指定的父文档,从父文档ID中生成,该值可以在存储文档的时候进行修改。
type类型:在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组相同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台 并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
template:索引可使用预定义的模板进行创建,这个模板称作Index templatElasticSearch。模板设置包括settings和mappings。
mapping:映射像关系数据库中的表结构,每一个索引都有一个映射,它定义了索引中的每一个字段类型,以及一个索引范围内的设置。一个映射可以事先被定义,或者在第一次存储文档的时候自动识别。
field:一个文档中包含零个或者多个字段,字段可以是一个简单的值(例如字符串、整数、日期),也可以是一个数组或对象的嵌套结构。字段类似于关系数据库中的表中的列。每个字段都对应一个字段类型,例如整数、字符串、对象等。字段还可以指定如何分析该字段的值。
source field:默认情况下,你的原文档将被存储在_source这个字段中,当你查询的时候也是返回这个字段。这允许您可以从搜索结果中访问原始的对象,这个对象返回一个精确的json字符串,这个对象不显示索引分析后的其他任何数据。
id:一个文件的唯一标识,如果在存库的时候没有提供id,系统会自动生成一个id,文档的index/type/id必须是唯一的。
recovery:代表数据恢复或叫数据重新分布,ElasticSearch在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
River:代表ElasticSearch的一个数据源,也是其它存储方式(如:数据库)同步数据到ElasticSearch的一个方法。它是以插件方式存在的一个ElasticSearch服务,通过读取river中的数据并把它索引到ElasticSearch中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的,river这个功能将会在后面的文件中重点说到。
gateway:代表ElasticSearch索引的持久化存储方式,ElasticSearch默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个ElasticSearch集群关闭再重新启动时就会从gateway中读取索引数据。ElasticSearch支持多种类型的gateway,有本地文件系统(默认), 分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
discovery.zen:代表ElasticSearch的自动发现节点机制,ElasticSearch是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport:代表ElasticSearch内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
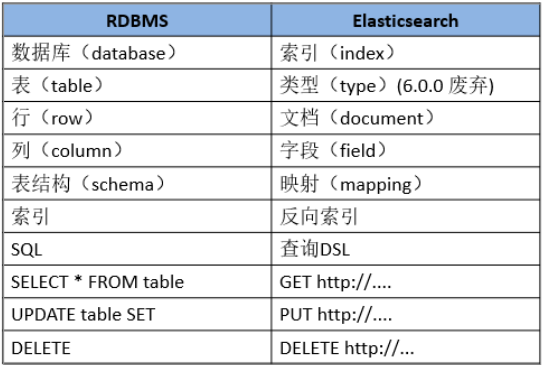
对比RDBMS (关系型数据库管理系统)
四、ElasticSearch配置
1. 数据目录和日志目录,生产环境下应与软件分离
#注意:数据目录可以有多个,可以通过逗号分隔指定多个目录。一个索引数据只会放入一个目录中!! path.data: /path/to/data1,/path/to/data2 # Path to log files: path.logs: /path/to/logs # Path to where plugins are installed: path.plugins: /path/to/plugins
cluster.name: kevin_elasticsearch
3. 节点名,默认为 UUID前7个字符,可自定义
node.name: kevin_elasticsearch_node01
默认绑定的是["127.0.0.1", "[::1]"]回环地址,集群下要服务间通信,需绑定一个ipv4或ipv6地址或0.0.0.0
network.host: 172.16.60.11
5. http.port: 9200-9300
对外服务的http 端口, 默认 9200-9300 。可以为它指定一个值或一个区间,当为区间时会取用区间第一个可用的端口。
6. transport.tcp.port: 9300-9400
节点间交互的端口, 默认 9300-9400 。可以为它指定一个值或一个区间,当为区间时会取用区间第一个可用的端口。
7. Discovery Config 节点发现配置
ES中默认采用的节点发现方式是 zen(基于组播(多播)、单播)。在应用于生产前有两个重要参数需配置
8. discovery.zen.ping.unicast.hosts: ["host1","host2:port","host3[portX-portY]"]
单播模式下,设置具有master资格的节点列表,新加入的节点向这个列表中的节点发送请求来加入集群。
9. discovery.zen.minimum_master_nodes: 1
这个参数控制的是,一个节点需要看到具有master资格的节点的最小数量,然后才能在集群中做操作。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
10. transport.tcp.compress: false
是否压缩tcp传输的数据,默认false
11. http.cors.enabled: true
是否使用http协议对外提供服务,默认true
12. http.max_content_length: 100mb
http传输内容的最大容量,默认100mb
13. node.master: true
指定该节点是否可以作为master节点,默认是true。ES集群默认是以第一个节点为master,如果该节点出故障就会重新选举master。
14. node.data: true
该节点是否存索引数据,默认true。
15. discover.zen.ping.timeout: 3s
设置集群中自动发现其他节点时ping连接超时时长,默认为3秒。在网络环境较差的情况下,增加这个值,会增加节点等待响应的时间,从一定程度上会减少误判。
16. discovery.zen.ping.multicast.enabled: false
是否启用多播来发现节点。
17. Jvm heap 大小设置
生产环境中一定要在jvm.options中调大它的jvm内存。
18. JVM heap dump path 设置
生产环境中指定当发生OOM异常时,heap的dump path,好分析问题。在jvm.options中配置:
-XX:HeapDumpPath=/var/lib/elasticsearch
五、ElasticSearch安装配置手册
1)环境要求
Elasticsearch 6.0版本至少需要JDK版本1.8。
可以使用java -version 命令查看JDK版本。
2)安装步骤
在ES 官网下载ES安装包,现以6.1.1版本为例。
1. 搜索历史版本,找到ES6.1.1版本下载连接。
https://www.elastic.co/cn/downloads/past-releases#elasticsearch

2. 将下载好的安装包上传至需要安装的服务器目录下并解压。
# cd /opt/gov
# tar -zxvf elasticsearch-6.1.1.tar.gz
3. 解压完毕
文件夹elasticsearch-6.1.1 为elasticsearch-6.1.1所在目录。
3)配置Elasticsearch
1. 进入Elasticsearch-6.1.1所在目录结构,其中config文件夹为es配置文件所在位置,进入config文件夹。
2. 修改elasticsearch.yml文件中的集群名称和节点名称
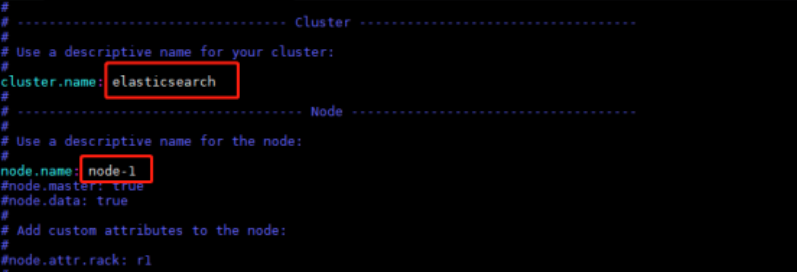
cluster.name(集群名称) 和node.name(节点名称) 可以自己配置简单易懂的值。node.name为节点名称,如果多个es实例,可加上数字1.2.3进行区分,方便查看日志和区分节点,简单易懂。如果该es集群用于落地skywalking的apm-collector数据,建议将cluster.name配置为cluster.name: CollectorDBCluster,即该名称需要和skywalking的collector配置文件一致。同一集群下多个es节点的cluster.name应该保持一致。

node.master指定该节点是否有资格被选举成为master,默认是true,elasticsearch默认集群中的第一台启动的机器为master,如果这台机挂了就会重新选举master。
node.data指定该节点是否存储索引数据,默认为true。如果节点配置node.master:false并且node.data: false,则该节点将起到负载均衡的作用。
3. 修改elasticsearch.yml文件中的数据和日志保存目录

此处作为实例将data目录和logs目录建立在了elasticsearch-6.1.1下,这样是危险的。当es被卸载,数据和日志将完全丢失。可以根据具体环境将数据目录和日志目录保存到其他路径下以确保数据和日志完整、安全。
4. 修改elasticsearch.yml文件中的network信息

如果一台主机将要安装多个es实例,请自行更改端口,以免端口被占用。http.port默认端口为9200。transport.tcp.port 默认端口为9300。
5. 修改elasticsearch.yml文件中的discovery信息

discovery.zen.ping.unicast.hosts: ["192.168.0.8:9300", "192.168.0.9:9300","192.168.0.10:9300"]
如果多个es实例组成集群,各节点ip+port信息用逗号分隔。其中port为各es实例中配置的transport.tcp.port。
discovery.zen.minimum_master_nodes: 1
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
6. 在elasticsearch.yml文件末尾添加配置
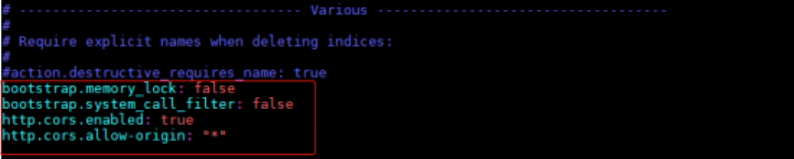
bootstrap.memory_lock: false
是否锁住内存。因为当jvm开始swapping时es的效率会降低,配置为true时要允许elasticsearch的进程可以锁住内存,同时一定要保证机器有足够的内存分配给es。如果不熟悉机器所处环境,建议配置为false。
bootstrap.system_call_filter: false
Centos6不支持SecComp,而ES5.2.0版本默认bootstrap.system_call_filter为true
禁用:在elasticsearch.yml中配置bootstrap.system_call_filter为false,注意要在Memory的后面配置该选项。
http.cors.enabled: true
是否支持跨域,默认为false。
http.cors.allow-origin: "*"
当设置允许跨域,默认为*,表示支持所有域名,如果我们只是允许某些网站能访问,那么可以使用正则表达式。比如只允许本地地址 /https?:\/\/localhost(:[0-9]+)?/
六、启动Elasticsearch
1. 进入elasticsearch-6.1.1下的bin目录。
2. 运行 ./elasticsearch -d 命令。
3. 如果出现./elasticsearch: Permission denied ,这时执行没有权限。
需要授权执行命令:chmod +x bin/elasticsearch 。
4. 再次执行./elasticsearch -d即可启动
5. 在我们配置的es日志目录中,查看日志文件elasticsearch.log,确保es启动成功。
6. 查看elasticssearch进程, 运行"ps -aux|grep elasticsearch" 命令即可
七、Elasticsearch 配置文件详解
elasticsearch的配置文件是在elasticsearch目录下的config文件下的elasticsearch.yml,同时它的日志文件在elasticsearch目录下的logs,由于elasticsearch的日志也是使用log4j来写日志的,所以其配置模式与log4j基本相同。
Cluster部分
cluster.name: kevin-elk (默认值:elasticsearch)
cluster.name可以确定你的集群名称,当你的elasticsearch集群在同一个网段中elasticsearch会自动的找到具有相同cluster.name 的elasticsearch服务。所以当同一个网段具有多个elasticsearch集群时cluster.name就成为同一个集群的标识。
Node部分
node.name: "elk-node01" 节点名,可自动生成也可手动配置。
node.master: true (默认值:true) 允许一个节点是否可以成为一个master节点,es是默认集群中的第一台机器为master,如果这台机器停止就会重新选举master。
node.client 当该值设置为true时,node.master值自动设置为false,不参加master选举。
node.data: true (默认值:true) 允许该节点存储数据。
node.rack 无默认值,为节点添加自定义属性。
node.max_local_storage_nodes: 1 (默认值:1) 设置能运行的节点数目,一般采用默认的1即可,因为我们一般也只在一台机子上部署一个节点。
配置文件中给出了三种配置高性能集群拓扑结构的模式,如下:
workhorse:如果想让节点从不选举为主节点,只用来存储数据,可作为负载器
node.master: false
node.data: true
coordinator:如果想让节点成为主节点,且不存储任何数据,并保有空闲资源,可作为协调器
node.master: true
node.data: false
search load balancer:(fetching data from nodes, aggregating results, etc.理解为搜索的负载均衡节点,从其他的节点收集数据或聚集后的结果等),客户端节点可以直接将请求发到数据存在的节点,而不用查询所有的数据节点,另外可以在它的上面可以进行数据的汇总工作,可以减轻数据节点的压力。
node.master: false
node.data: false
另外配置文件提到了几种监控es集群的API或方法:
Cluster Health API:http://127.0.0.1:9200/_cluster/health
Node Info API:http://127.0.0.1:9200/_nodes
还有图形化工具:
https://www.elastic.co/products/marvel
https://github.com/karmi/elasticsearch-paramedic
https://github.com/hlstudio/bigdesk
https://github.com/mobz/elasticsearch-head
Indices部分
index.number_of_shards: 5 (默认值为5) 设置默认索引分片个数。 index.number_of_replicas: 1(默认值为1) 设置索引的副本个数
服务器够多,可以将分片提高,尽量将数据平均分布到集群中,增加副本数量可以有效的提高搜索性能。
需要注意: "number_of_shards" 是索引创建后一次生成的,后续不可更改设置 "number_of_replicas" 是可以通过update-index-settings API实时修改设置。
Indices Circuit Breaker
elasticsearch包含多个circuit breaker来避免操作的内存溢出。每个breaker都指定可以使用内存的限制。另外有一个父级breaker指定所有的breaker可以使用的总内存
indices.breaker.total.limit 所有breaker使用的内存值,默认值为 JVM 堆内存的70%,当内存达到最高值时会触发内存回收。
Field data circuit breaker 允许elasticsearch预算待加载field的内存,防止field数据加载引发异常
indices.breaker.fielddata.limit field数据使用内存限制,默认为JVM 堆的60%。 indices.breaker.fielddata.overhead elasticsearch使用这个常数乘以所有fielddata的实际值作field的估算值。默认为 1.03。
请求断路器(Request circuit breaker) 允许elasticsearch防止每个请求的数据结构超过了一定量的内存
indices.breaker.request.limit request数量使用内存限制,默认为JVM堆的40%。 indices.breaker.request.overhead elasticsearch使用这个常数乘以所有request占用内存的实际值作为最后的估算值。默认为 1。
Indices Fielddata cache
字段数据缓存主要用于排序字段和计算聚合。将所有的字段值加载到内存中,以便提供基于文档快速访问这些值
indices.fielddata.cache.size:unbounded 设置字段数据缓存的最大值,值可以设置为节点堆空间的百分比,例:30%,可以值绝对值,例:12g。默认为无限。 该设置是静态设置,必须配置到集群的每个节点。
Indices Node query cache
query cache负责缓存查询结果,每个节点都有一个查询缓存共享给所有的分片。缓存实现一个LRU驱逐策略:当缓存使用已满,最近最少使用的数据将被删除,来缓存新的数据。query cache只缓存过滤过的上下文
indices.queries.cache.size 查询请求缓存大小,默认为10%。也可以写为绝对值,例:512m。 该设置是静态设置,必须配置到集群的每个数据节点。
Indexing Buffer
索引缓冲区用于存储新索引的文档。缓冲区写满,缓冲区的文件才会写到硬盘。缓冲区划分给节点上的所有分片。
Indexing Buffer的配置是静态配置,必须配置都集群中的所有数据节点
indices.memory.index_buffer_size 允许配置百分比和字节大小的值。默认10%,节点总内存堆的10%用作索引缓冲区大小。 indices.memory.min_index_buffer_size 如果index_buffer_size被设置为一个百分比,这个设置可以指定一个最小值。默认为 48mb。 indices.memory.max_index_buffer_size 如果index_buffer_size被设置为一个百分比,这个设置可以指定一个最小值。默认为无限。 indices.memory.min_shard_index_buffer_size 设置每个分片的最小索引缓冲区大小。默认为4mb。
Indices Shard request cache
当一个搜索请求是对一个索引或者多个索引的时候,每一个分片都是进行它自己内容的搜索然后把结果返回到协调节点,然后把这些结果合并到一起统一对外提供。分片缓存模块缓存了这个分片的搜索结果。这使得搜索频率高的请求会立即返回。
注意:请求缓存只缓存查询条件 size=0的搜索,缓存的内容有hits.total, aggregations, suggestions,不缓存原始的hits。通过now查询的结果将不缓存。
缓存失效:只有在分片的数据实际上发生了变化的时候刷新分片缓存才会失效。刷新的时间间隔越长,缓存的数据越多,当缓存不够的时候,最少使用的数据将被删除。
缓存过期可以手工设置,例如:
curl -XPOST 'localhost:9200/kimchy,elasticsearch/_cache/clear?request_cache=true'
默认情况下缓存未启用,但在创建新的索引时可启用,例如:
curl -XPUT localhost:9200/my_index -d'
{
"settings": {
"index.requests.cache.enable": true
}
}
'
当然也可以通过动态参数配置来进行设置:
curl -XPUT localhost:9200/my_index/_settings -d'
{ "index.requests.cache.enable": true }
'
每请求启用缓存,查询字符串参数request_cache可用于启用或禁用每个请求的缓存。例如:
curl 'localhost:9200/my_index/_search?request_cache=true' -d'
{
"size": 0,
"aggs": {
"popular_colors": {
"terms": {
"field": "colors"
}
}
}
}
'
注意:如果你的查询使用了一个脚本,其结果是不确定的(例如,它使用一个随机函数或引用当前时间)应该设置 request_cache=false 禁用请求缓存。
缓存key,数据的缓存是整个JSON,这意味着如果JSON发生了变化 ,例如如果输出的顺序顺序不同,缓存的内容江将会不同。不过大多数JSON库对JSON键的顺序是固定的。
分片请求缓存是在节点级别进行管理的,并有一个默认的值是JVM堆内存大小的1%,可以通过配置文件进行修改。 例如: indices.requests.cache.size: 2%
分片缓存大小的查看方式:
curl 'localhost:9200/_stats/request_cache?pretty&human'
或者
curl 'localhost:9200/_nodes/stats/indices/request_cache?pretty&human'
Indices Recovery
indices.recovery.concurrent_streams 限制从其它分片恢复数据时最大同时打开并发流的个数。默认为 3。 indices.recovery.concurrent_small_file_streams 从其他的分片恢复时打开每个节点的小文件(小于5M)流的数目。默认为 2。 indices.recovery.file_chunk_size 默认为 512kb。 indices.recovery.translog_ops 默认为 1000。 indices.recovery.translog_size 默认为 512kb。 indices.recovery.compress 恢复分片时,是否启用压缩。默认为 true。 indices.recovery.max_bytes_per_sec 限制从其它分片恢复数据时每秒的最大传输速度。默认为 40mb。
Indices TTL interval
indices.ttl.interval 允许设置多久过期的文件会被自动删除。默认值是60s。 indices.ttl.bulk_size 设置批量删除请求的数量。默认值为1000。
Paths部分
path.conf: /path/to/conf 配置文件存储位置。 path.data: /path/to/data 数据存储位置,索引数据可以有多个路径,使用逗号隔开。 path.work: /path/to/work 临时文件的路径 。 path.logs: /path/to/logs 日志文件的路径 。 path.plugins: /path/to/plugins 插件安装路径 。
Memory部分
bootstrap.mlockall: true(默认为false)
锁住内存,当JVM进行内存转换的时候,es的性能会降低,所以可以使用这个属性锁住内存。同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过`ulimit -l unlimited`命令,或者在/etc/sysconfig/elasticsearch文件中取消 MAX_LOCKED_MEMORY=unlimited 的注释即可。如果使用该配置则ES_HEAP_SIZE必须设置,设置为当前可用内存的50%,最大不能超过31G,默认配置最小为256M,最大为1G。
可以通过请求查看mlockall的值是否设定:
curl http://localhost:9200/_nodes/process?pretty
如果mlockall的值是false,则设置失败。可能是由于elasticsearch的临时目录(/tmp)挂载的时候没有可执行权限。
可以使用下面的命令来更改临时目录:
./bin/elasticsearch -Djna.tmpdir=/path/to/new/dir
Network 、Transport and HTTP 部分
network.bind_host
设置绑定的ip地址,可以是ipv4或ipv6的。
network.publish_host
设置其它节点和该节点交互的ip地址,如果不设置它会自动设置,值必须是个真实的ip地址。
network.host
同时设置bind_host和publish_host两个参数,值可以为网卡接口、127.0.0.1、私有地址以及公有地址。
http_port
接收http请求的绑定端口。可以为一个值或端口范围,如果是一个端口范围,节点将绑定到第一个可用端口。默认为:9200-9300。
transport.tcp.port
节点通信的绑定端口。可以为一个值或端口范围,如果是一个端口范围,节点将绑定到第一个可用端口。默认为:9300-9400。
transport.tcp.connect_timeout
套接字连接超时设置,默认为 30s。
transport.tcp.compress
设置为true启用节点之间传输的压缩(LZF),默认为false。
transport.ping_schedule
定时发送ping消息保持连接,默认transport客户端为5s,其他为-1(禁用)。
httpd.enabled
是否使用http协议提供服务。默认为:true(开启)。
http.max_content_length
最大http请求内容。默认为100MB。如果设置超过100MB,将会被MAX_VALUE重置为100MB。
http.max_initial_line_length
http的url的最大长度。默认为:4kb。
http.max_header_size
http中header的最大值。默认为8kb。
http.compression
支持压缩(Accept-Encoding)。默认为:false。
http.compression_level
定义压缩等级。默认为:6。
http.cors.enabled
启用或禁用跨域资源共享。默认为:false。
http.cors.allow-origin
启用跨域资源共享后,默认没有源站被允许。在//中填写域名支持正则,例如 /https?:\/\/localhost(:[0-9]+)?/。 * 是有效的值,但是开放任何域名的跨域请求被认为是有安全风险的elasticsearch实例。
http.cors.max-age
浏览器发送‘preflight’OPTIONS-request 来确定CORS设置。max-age 定义缓存的时间。默认为:1728000 (20天)。
http.cors.allow-methods
允许的http方法。默认为OPTIONS、HEAD、GET、POST、PUT、DELETE。
http.cors.allow-headers
允许的header。默认 X-Requested-With, Content-Type, Content-Length。
http.cors.allow-credentials
是否允许返回Access-Control-Allow-Credentials头部。默认为:false。
http.detailed_errors.enabled
启用或禁用输出详细的错误信息和堆栈跟踪响应输出。默认为:true。
http.pipelining
启用或禁用http管线化。默认为:true。
http.pipelining.max_events
一个http连接关闭之前最大内存中的时间队列。默认为:10000。
Discovery部分
discovery.zen.minimum_master_nodes: 3
预防脑裂(split brain)通过配置大多数节点(总节点数/2+1)。默认为3。
discovery.zen.ping.multicast.enabled: false
设置是否打开组播发现节点。默认false。
discovery.zen.ping.unicast.host
单播发现所使用的主机列表,可以设置一个属组,或者以逗号分隔。每个值格式为 host:port 或 host(端口默认为:9300)。默认为 127.0.0.1,[::1]。
discovery.zen.ping.timeout: 3s
设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
discovery.zen.join_timeout
节点加入到集群中后,发送请求到master的超时时间,默认值为ping.timeout的20倍。
discovery.zen.master_election.filter_client:true
当值为true时,所有客户端节点(node.client:true或node.date,node.master值都为false)将不参加master选举。默认值为:true。
discovery.zen.master_election.filter_data:false
当值为true时,不合格的master节点(node.data:true和node.master:false)将不参加选举。默认值为:false。
discovery.zen.fd.ping_interval
发送ping监测的时间间隔。默认为:1s。
discovery.zen.fd.ping_timeout
ping的响应超时时间。默认为30s。
discovery.zen.fd.ping_retries
ping监测失败、超时的次数后,节点连接失败。默认为3。
discovery.zen.publish_timeout
通过集群api动态更新设置的超时时间,默认为30s。
discovery.zen.no_master_block
设置无master时,哪些操作将被拒绝。all 所有节点的读、写操作都将被拒绝。write 写操作将被拒绝,可以读取最后已知的集群配置。默认为:write。
Gateway部分
gateway.expected_nodes: 0
设置这个集群中节点的数量,默认为0,一旦这N个节点启动,就会立即进行数据恢复。
gateway.expected_master_nodes
设置这个集群中主节点的数量,默认为0,一旦这N个节点启动,就会立即进行数据恢复。
gateway.expected_data_nodes
设置这个集群中数据节点的数量,默认为0,一旦这N个节点启动,就会立即进行数据恢复。
gateway.recover_after_time: 5m
设置初始化数据恢复进程的超时时间,默认是5分钟。
gateway.recover_after_nodes
设置集群中N个节点启动时进行数据恢复。
gateway.recover_after_master_nodes
设置集群中N个主节点启动时进行数据恢复。
gateway.recover_after_data_nodes
设置集群中N个数据节点启动时进行数据恢复。
八. Elasticsearch常用插件
elasticsearch-head 插件
一个elasticsearch的集群管理工具,它是完全由html5编写的独立网页程序,你可以通过插件把它集成到es。
项目地址:https://github.com/mobz/elasticsearch-head
插件安装方法1
elasticsearch/bin/plugin install mobz/elasticsearch-head 重启elasticsearch 打开http://localhost:9200/_plugin/head/
插件安装方法2
根据地址https://github.com/mobz/elasticsearch-head 下载zip解压 建立elasticsearch/plugins/head/_site文件 将解压后的elasticsearch-head-master文件夹下的文件copy到_site 重启elasticsearch 打开http://localhost:9200/_plugin/head/
bigdesk插件
elasticsearch的一个集群监控工具,可以通过它来查看es集群的各种状态,如:cpu、内存使用情况,索引数据、搜索情况,http连接数等。
项目地址: https://github.com/hlstudio/bigdesk
插件安装方法1
elasticsearch/bin/plugin install hlstudio/bigdesk 重启elasticsearch 打开http://localhost:9200/_plugin/bigdesk/
插件安装方法2
https://github.com/hlstudio/bigdesk下载zip 解压 建立elasticsearch-1.0.0\plugins\bigdesk\_site文件 将解压后的bigdesk-master文件夹下的文件copy到_site 重启elasticsearch 打开http://localhost:9200/_plugin/bigdesk/
Kopf 插件
一个ElasticSearch的管理工具,它也提供了对ES集群操作的API。
项目地址:https://github.com/lmenezes/elasticsearch-kopf
插件安装方法
elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf 重启elasticsearch 打开http://localhost:9200/_plugin/kopf/
九、Elasticsearch 的fielddata内存控制、预加载以及circuit breaker断路器
fielddata核心原理
fielddata加载到内存的过程是lazy加载的,对一个analzyed field执行聚合时,才会加载,而且是field-level加载的一个index的一个field,所有doc都会被加载,而不是少数doc不是index-time创建,是query-time创建
fielddata内存限制
elasticsearch.yml: indices.fielddata.cache.size: 20%,超出限制,清除内存已有fielddata数据fielddata占用的内存超出了这个比例的限制,那么就清除掉内存中已有的fielddata数据默认无限制,限制内存使用,但是会导致频繁evict和reload,大量IO性能损耗,以及内存碎片和gc
监控fielddata内存使用
#各个分片、索引的fielddata在内存中的占用情况 [root@elk-node03 ~]# curl -X GET 'http://10.0.8.47:9200/_stats/fielddata?fields=*' #每个node的fielddata在内存中的占用情况 [root@elk-node03 ~]# curl -X GET 'http://10.0.8.47:9200/_nodes/stats/indices/fielddata?fields=*' #每个node中的每个索引的fielddata在内存中的占用情况 [root@elk-node03 ~]# curl -X GET 'http://10.0.8.47:9200/_nodes/stats/indices/fielddata?level=indices&fields=*'
circuit breaker断路由
如果一次query load的feilddata超过总内存,就会oom --> 内存溢出;
circuit breaker会估算query要加载的fielddata大小,如果超出总内存,就短路,query直接失败;
在elasticsearch.yml文件中配置如下内容:
indices.breaker.fielddata.limit: fielddata的内存限制,默认60%
indices.breaker.request.limit: 执行聚合的内存限制,默认40%
indices.breaker.total.limit: 综合上面两个,限制在70%以内
限制内存使用 (Elasticsearch聚合限制内存使用)
通常为了让聚合(或者任何需要访问字段值的请求)能够快点,访问fielddata一定会快点, 这就是为什么加载到内存的原因。但是加载太多的数据到内存会导致垃圾回收(gc)缓慢, 因为JVM试着发现堆里面的额外空间,甚至导致OutOfMemory (即OOM)异常。
然而让人吃惊的发现, Elaticsearch不是只把符合你的查询的值加载到fielddata. 而是把index里的所document都加载到内存,甚至是不同的 _type 的document。逻辑是这样的,如果你在这个查询需要访问documents X,Y和Z, 你可能在下一次查询就需要访问别documents。而一次把所有的值都加载并保存在内存 , 比每次查询都去扫描倒排索引要更方便。
JVM堆是一个有限制的资源需要聪明的使用。有许多现成的机制去限制fielddata对堆内存使用的影响。这些限制非常重要,因为滥用堆将会导致节点的不稳定(多亏缓慢的垃圾回收)或者甚至节点死亡(因为OutOfMemory异常);但是垃圾回收时间过长,在垃圾回收期间,ES节点的性能就会大打折扣,查询就会非常缓慢,直到最后超时。
如何设置堆大小
对于环境变量 $ES_HEAP_SIZE 在设置Elasticsearch堆大小的时候有2个法则可以运用:
1) 不超过RAM的50%
Lucene很好的利用了文件系统cache,文件系统cache是由内核管理的。如果没有足够的文件系统cache空间,性能就会变差;
2) 不超过32G
如果堆小于32GB,JVM能够使用压缩的指针,这会节省许多内存:每个指针就会使用4字节而不是8字节。把对内存从32GB增加到34GB将意味着你将有更少的内存可用,因为所有的指针占用了双倍的空间。同样,更大的堆,垃圾回收变得代价更大并且可能导致节点不稳定;这个限制主要是大内存对fielddata影响比较大。
Fielddata大小
参数 indices.fielddata.cache.size 控制有多少堆内存是分配给fielddata。当你执行一个查询需要访问新的字段值的时候,将会把值加载到内存,然后试着把它们加入到fielddata。如果结果的fielddata大小超过指定的大小 ,为了腾出空间,别的值就会被驱逐出去。默认情况下,这个参数设置的是无限制 — Elasticsearch将永远不会把数据从fielddata里替换出去。
这个默认值是故意选择的:fielddata不是临时的cache。它是一个在内存里为了快速执行必须能被访问的数据结构,而且构建它代价非常昂贵。如果你每个请求都要重新加载数据,性能就会很差。
一个有限的大小强迫数据结构去替换数据。下面来看看什么时候去设置下面的值,首先看一个警告: 这个设置是一个保护措施,而不是一个内存不足的解决方案!
如果你没有足够的内存区保存你的fielddata到内存里,Elasticsearch将会经常性的从磁盘重新加载数据,并且驱逐别的数据区腾出空间。这种数据的驱逐会导致严重的磁盘I/O,并且在内存里产生大量的垃圾,这个会在后面被垃圾回收。
监控fielddata (上面提到了)
监控fielddata使用了多少内存以及是否有数据被驱逐是非常重要的。大量的数据被驱逐会导致严重的资源问题以及不好的性能。
Fielddata使用可以通过下面的方式来监控:
对于单个索引使用 {ref}indices-stats.html[indices-stats API]:
[root@elk-node03 ~]# curl -X GET 'http://10.0.8.47:9200/_stats/fielddata?fields=
对于单个节点使用 {ref}cluster-nodes-stats.html[nodes-stats API]:
[root@elk-node03 ~]# curl -X GET 'http://10.0.8.47:9200/_nodes/stats/indices/fielddata?fields=*'
或者甚至单个节点单个索引
[root@elk-node03 ~]# curl -X GET 'http://10.0.8.47:9200/_nodes/stats/indices/fielddata?level=indices&fields=*'
通过设置 ?fields=* 内存使用按照每个字段分解了.
断路器(breaker)
fielddata的大小是在数据被加载之后才校验的。如果一个查询尝试加载到fielddata的数据比可用的内存大会发生什么情况?答案是不客观的:你将会获得一个OutOfMemory异常。
Elasticsearch包含了一个 fielddata断路器 ,这个就是设计来处理这种情况的。断路器通过检查涉及的字段(它们的类型,基数,大小等等)来估计查询需要的内存。然后检查加 载需要的fielddata会不会导致总的fielddata大小超过设置的堆的百分比。
如果估计的查询大小超过限制,断路器就会触发并且查询会被抛弃返回一个异常。这个发生在数据被加载之前,这就意味着你不会遇到OutOfMemory异常。
Elasticsearch拥有一系列的断路器,所有的这些都是用来保证内存限制不会被突破:
indices.breaker.fielddata.limit
这个 fielddata 断路器限制fielddata的大小为堆大小的60%,默认情况下。
indices.breaker.request.limit
这个 request 断路器估算完成查询的其他部分要求的结构的大小,比如创建一个聚集通, 以及限制它们到堆大小的40%,默认情况下。
indices.breaker.total.limit
这个total断路器封装了 request 和 fielddata 断路器去确保默认情况下这2个 使用的总内存不超过堆大小的70%。
curl -PUT 'http://10.0.8.47:9200/_cluster/settings{
"persistent" : {
"indices.breaker.fielddata.limit" : 40% (1)
}
}
这个限制设置的是堆的百分比。
断路器和Fielddata大小
在 Fielddata大小部分我们谈到了要给fielddata大小增加一个限制去保证老的不使用 的fielddata被驱逐出去。indices.fielddata.cache.size 和 indices.breaker.fielddata.limit 的关系是非常重要的。如果断路器限制比缓冲区大小要小,就会没有数据会被驱逐。为了能够 让它正确的工作,断路器限制必须比缓冲区大小要大。
我们注意到断路器是和总共的堆大小对比查询大小,而不是和真正已经使用的堆内存区比较。 这样做是有一系列技术原因的(比如,堆可能看起来是满的,但是实际上可能正在等待垃圾 回收,这个很难准确的估算)。但是作为终端用户,这意味着设置必须是保守的,因为它是 和整个堆大小比较,而不是空闲的堆比较。
十、Elasticserach索引详解
- 分词器集成
1. 获取 ES-IKAnalyzer插件:
地址: https://github.com/medcl/elasticsearch-analysis-ik/releases
一定要获取匹配的版本

2. 安装插件
将 ik 的压缩包解压到 ES安装目录的plugins/目录下(最好把解出的目录名改一下,防止安装别的插件时同名冲突),然后重启ES。
3. 扩展词库
修改配置文件config/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典--> <entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">custom/ext_stopword.dic</entry> <!--用户可以在这里配置远程扩展字典--> <entry key="remote_ext_dict">location</entry> <!--用户可以在这里配置远程扩展停止词字典--> <entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry> </properties>
4. 测试 IK
5. 创建一个索引
# curl -XPUT http://localhost:9200/index
6.创建一个映射mapping
# curl -XPOST http://localhost:9200/index/fulltext/_mapping -H 'Content-Type:application/json' -d'
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}'
7. 索引一些文档
# curl -XPOST http://localhost:9200/index/fulltext/1 -H 'Content-Type:application/json' -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}'
# curl -XPOST http://localhost:9200/index/fulltext/2 -H 'Content-Type:application/json' -d'
{"content":"公安部:各地校车将享最高路权"}'
# curl -XPOST http://localhost:9200/index/fulltext/3 -H 'Content-Type:application/json' -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}'
8. 搜索
# curl -XPOST http://localhost:9200/index/fulltext/_search -H 'Content-Type:application/json' -d'
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}'
- 索引收缩
索引的分片数是不可更改的,如要减少分片数可以通过收缩方式收缩为一个新的索引。新索引分片数必须是原分片数的因子值,如原分片数是8,则新索引分片数可以为4、2、1 。
收缩流程
- 先把所有主分片都转移到一台主机上;
- 在这台主机上创建一个新索引,分片数较小,其他设置和原索引一致;
- 把原索引的所有分片,复制(或硬链接)到新索引的目录下;
- 对新索引进行打开操作恢复分片数据;(可选)重新把新索引的分片均衡到其他节点上。
a) 收缩前准备工作
将原索引设置为只读;将原索引各分片的一个副本重分配到同一个节点上,并且要是健康绿色状态。
PUT /my_source_index/_settings
{
"settings": {
"index.routing.allocation.require._name": "shrink_node_name",
"index.blocks.write": true
}
}
b) 进行收缩
POST my_source_index/_shrink/my_target_index
{
"settings": {
"index.number_of_replicas": 1,
"index.number_of_shards": 1,
"index.codec": "best_compression"
}}
c) 监控收缩过程
GET _cat/recovery?v GET _cluster/health
- Split Index 拆分索引
当索引的分片容量过大时,可以通过拆分操作将索引拆分为一个倍数分片数的新索引。能拆分为几倍由创建索引时指定的index.number_of_routing_shards 路由分片数决定。这个路由分片数决定了根据一致性hash路由文档到分片的散列空间。如index.number_of_routing_shards = 30 ,指定的分片数是5,则可按如下倍数方式进行拆分:
5 → 10 → 30 (split by 2, then by 3)
5 → 15 → 30 (split by 3, then by 2)
5 → 30 (split by 6)
注意:只有在创建时指定了index.number_of_routing_shards 的索引才可以进行拆分,ES7开始将不再有这个限制。
a) 准备一个索引来做拆分
PUT my_source_index
{
"settings": {
"index.number_of_shards" : 1,
"index.number_of_routing_shards": 2
}
}
b) 设置索引只读
PUT /my_source_index/_settings
{
"settings": {
"index.blocks.write": true
}
}
c) 监控拆分过程
GET _cat/recovery?v GET _cluster/health
- 别名滚动
对于有时效性的索引数据,如日志,过一定时间后,老的索引数据就没有用了。我们可以像数据库中根据时间创建表来存放不同时段的数据一样,在ES中也可用建多个索引的方式来分开存放不同时段的数据。比数据库中更方便的是ES中可以通过别名滚动指向最新的索引的方式,让你通过别名来操作时总是操作的最新的索引。
ES的rollover index API 让我们可以根据满足指定的条件(时间、文档数量、索引大小)创建新的索引,并把别名滚动指向新的索引。
- Rollover Index 示例
- 创建一个名字为logs-0000001 、别名为logs_write 的索引
PUT /logs-000001
{
"aliases": {
"logs_write": {}
}
}
- 如果别名logs_write指向的索引是7天前(含)创建的或索引的文档数>=1000或索引的大小>= 5gb,则会创建一个新索引 logs-000002,并把别名logs_writer指向新创建的logs-000002索引
# Add > 1000 documents to logs-000001
POST /logs_write/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 1000,
"max_size": "5gb"
}
}
- Rollover Index 新建索引的命名规则
如果索引的名称是-数字结尾,如logs-000001,则新建索引的名称也会是这个模式,数值增1。
如果索引的名称不是-数值结尾,则在请求rollover api时需指定新索引的名称:
POST /my_alias/_rollover/my_new_index_name
{
"conditions": {
"max_age": "7d",
"max_docs": 1000,
"max_size": "5gb"
}
}
- 在名称中使用Date math(时间表达式)
如果你希望生成的索引名称中带有日期,如logstash-2016.02.03-1 ,则可以在创建索引时采用时间表达式来命名:
# PUT /<logs-{now/d}-1> with URI
encoding:
PUT /%3Clogs-%7Bnow%2Fd%7D-1%3E
{
"aliases": {
"logs_write": {}
}
}
PUT logs_write/_doc/1
{
"message": "a dummy log"
}
POST logs_write/_refresh
# Wait for a day to pass
POST /logs_write/_rollover
{
"conditions": {
"max_docs": "1"
}
}
注意:rollover是你请求它才会进行操作,并不是自动在后台进行的。你可以周期性地去请求它。
- 路由
1. 集群组成
集群元信息
Cluster-name:ess
Nodes:
node1 10.0.1.11 master
node2 10.0.1.12
node3 10.0.1.13
Indics:
s0:
shard0:
primay: 10.0.1.11
rep:10.0.1.13
……

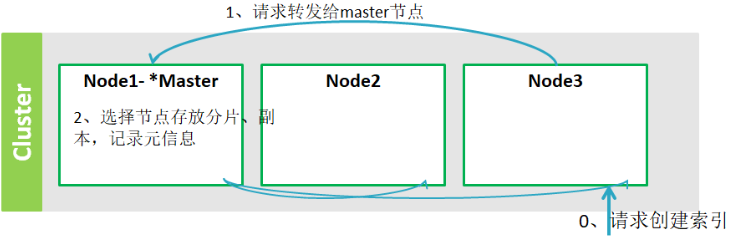
2. 创建索引的流程
PUT s1
{
"settings" : {
"index" : {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}
1. 请求node3创建索引
2. node3请求转发给master节点
3. 选择节点存放分片、副本,记录元信息
4. 通知给参与存放索引分片、副本的节点从节点,创建分片、副本
5. 参与节点向主节点反馈结果
6. 等待时间到了,master向node3反馈结果信息,node3响应请求。
7. 主节点将元信息广播给所有从节点。
3. 节点故障

集群元信息
Cluster-name:ess
Nodes:
node1 10.0.1.11 master 故障
node2 10.0.1.12 master
node3 10.0.1.13
Indics:
s0:
shard0:
primay:10.0.1.12
rep:10.0.1.13
……
节点数据自动重新分配
4. 索引文档
索引文档的步骤:
1. node2计算文档的路由值得到文档存放的分片(假定路由选定的是分片0)。
2. 将文档转发给分片0的主分片节点 node1。
3. node1索引文档,同步给副本节点node3索引文档。
4. node1向node2反馈结果
5. node2作出响应
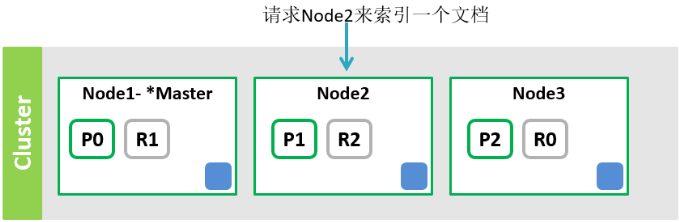
5. 搜索
1. node2解析查询。
2. node2将查询发给索引s1的分片/副本(R1,R2,R0)节点
3. 各节点执行查询,将结果发给Node2
4. Node2合并结果,作出响应。

6. 文档如何路由
1. 文档该存到哪个分片上?
决定文档存放到哪个分片上就是文档路由。ES中通过下面的计算得到每个文档的存放分片:
shard = hash(routing) % number_of_primary_shards
routing 是用来进行hash计算的路由值,默认是使用文档id值。我们可以在索引文档时通过routing参数指定别的路由值,在索引、删除、更新、查询中都可以使用routing参数(可多值)指定操作的分片。
POST twitter/_doc?routing=kimchy
{
"user" : "kimchy",
"post_date": "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
强制要求给定路由值
PUT my_index2
{
"mappings": {
"_doc": {
"_routing": {
"required": true
}
}
}
}
2. 关系型数据库中有分区表,通过选定分区,可以降低操作的数据量,提高效率。在ES的索引中能不能这样做?
可以:通过指定路由值,让一个分片上存放一个区的数据。如按部门存放数据,则可指定路由值为部门值。
十一、Elasticserach性能优化
1. 硬件选择
目前公司的物理机机型在CPU和内存方面都满足需求,建议使用SSD机型。原因在于,可以快速把 Lucene 的索引文件加载入内存(这在宕机恢复的情况下尤为明显),减少 IO 负载和 IO wait以便CPU不总是在等待IO中断。建议使用多裸盘而非raid,因为 ElasticSearch 本身就支持多目录,raid 要么牺牲空间要么牺牲可用性。
2. 系统配置
ElasticSearch 理论上必须单独部署,并且会独占几乎所有系统资源,因此需要对系统进行配置,以保证运行 ElasticSearch 的用户可以使用足够多的资源。生产集群需要调整的配置如下:
1. 设置 JVM 堆大小;
2. 关闭 swap;
3. 增加文件描述符;
4. 保证足够的虚存;
5. 保证足够的线程;
6. 暂时不建议使用G1GC;
3. 设置 JVM 堆大小
ElasticSearch 需要有足够的 JVM 堆支撑索引数据的加载,对于公司的机型来说,因为都是大于 128GB 的,所以推荐的配置是 32GB(如果 JVM 以不等的初始和最大堆大小启动,则在系统使用过程中可能会因为 JVM 堆的大小调整而容易中断。 为了避免这些调整大小的暂停,最好使用初始堆大小等于最大堆大小的 JVM 来启动),预留足够的 IO Cache 给 Lucene(官方建议超过一半的内存需要预留)。
4. 关闭 swap & 禁用交换
必须要关闭 swap,因为在物理内存不足时,如果发生 FGC,在回收虚拟内存的时候会造成长时间的 stop-the-world,最严重的后果是造成集群雪崩。公司的默认模板是关闭的,但是要巡检一遍,避免有些机器存在问题。设置方法:
Step1. root 用户临时关闭 # swapoff -a # sysctl vm.swappiness=0 Step2. 修改 /etc/fstab,注释掉 swap 这行 Step3. 修改 /etc/sysctl.conf,添加: vm.swappiness = 0 Step4. 确认是否生效 # sysctl vm.swappiness
也可以通过修改 yml 配置文件的方式从 ElasticSearch 层面禁止物理内存和交换区之间交换内存,修改 ${PATH_TO_ES_HOME}/config/elasticsearch.yml,添加:
bootstrap.memory_lock: true
==========================小提示=======================
Linux 把它的物理 RAM 分成多个内存块,称之为分页。内存交换(swapping)是这样一个过程,它把内存分页复制到预先设定的叫做交换区的硬盘空间上,以此释放内存分页。物理内存和交换区加起来的大小就是虚拟内存的可用额度。
内存交换有个缺点,跟内存比起来硬盘非常慢。内存的读写速度以纳秒来计算,而硬盘是以毫秒来计算,所以访问硬盘比访问内存要慢几万倍。交换次数越多,进程就越慢,所以应该不惜一切代价避免内存交换的发生。
ElasticSearch 的 memory_lock 属性允许 Elasticsearch 节点不交换内存。(注意只有Linux/Unix系统可设置。)这个属性可以在yml文件中设置。
======================================================
5. 增加文件描述符
单个用户可用的最大进程数量(软限制)&单个用户可用的最大进程数量(硬限制),超过软限制会有警告,但是无法超过硬限制。 ElasticSearch 会使用大量的文件句柄,如果超过限制可能会造成宕机或者数据缺失。
文件描述符是用于跟踪打开“文件”的 Unix 结构体。在Unix中,一切都皆文件。 例如,“文件”可以是物理文件,虚拟文件(例如/proc/loadavg)或网络套接字。 ElasticSearch 需要大量的文件描述符(例如,每个 shard 由多个 segment 和其他文件组成,以及到其他节点的 socket 连接等)。
设置方法(假设是 admin 用户启动的 ElasticSearch 进程):
# Step1. 修改 /etc/security/limits.conf,添加: admin soft nofile 65536 admin hard nofile 65536 # Step2. 确认是否生效 su - admin ulimit -n # Step3. 通过 rest 确认是否生效 GET /_nodes/stats/process?filter_path=**.max_file_descriptors
6. 保证足够的虚存
单进程最多可以占用的内存区域,默认为 65536。Elasticsearch 默认会使用 mmapfs 去存储 indices,默认的 65536 过少,会造成 OOM 异常。设置方法:
# Step1. root 用户修改临时参数 sudo sysctl -w vm.max_map_count=262144 # Step2. 修改 /etc/sysctl.conf,在文末添加: vm.max_map_count = 262144 # Step3. 确认是否生效 sudo sysctl vm.max_map_count
7. 保证足够的线程
Elasticsearch 通过将请求分成几个阶段,并交给不同的线程池执行(Elasticsearch 中有各种不同的线程池执行器)。 因此,Elasticsearch 需要创建大量线程的能力。进程可创建线程的最大数量确保 Elasticsearch 进程有权在正常使用情况下创建足够的线程。 这可以通过/etc/security/limits.conf 使用 nproc 设置来完成。设置方法:
修改 /etc/security/limits.d/90-nproc.conf,添加: admin soft nproc 2048
8. 暂时不建议使用G1GC
已知 JDK 8 附带的 HotSpot JVM 的早期版本在启用 G1GC 收集器时会导致索引损坏。受影响的版本是早于 JDK 8u40 附带的HotSpot 的版本,出于稳定性的考虑暂时不建议使用。
十二、Elasticserach内存优化
ElasticSearch 自身对内存管理进行了大量优化,但对于持续增长的业务仍需进行一定程度的内存优化(而不是纯粹的添加节点和扩展物理内存),以防止 OOM 发生。ElasticSearch 使用的 JVM 堆中主要包括以下几类内存使用:
1. Segment Memory;
2. Filter Cache;
3. Field Data Cache;
4. Bulk Queue;
5. Indexing Buffer;
6. Cluster State Buffer;
7. 超大搜索聚合结果集的 fetch;
1. 减少 Segment Memory
- 删除无用的历史索引。删除办法,使用 rest API
# 删除指定某个索引
DELETE /${INDEX_NAME}
# 删除符合 pattern 的某些索引
DELETE /${INDEX_PATTERN}
- 关闭无需实时查询的历史索引,文件仍然存在于磁盘,只是释放掉内存,需要的时候可以重新打开。关闭办法,使用 rest API
# 关闭指定某个索引
POST /${INDEX_NAME}/_close
# 关闭符合 pattern 的某些索引
POST /${INDEX_PATTERN}/_close
- 定期对不再更新的索引做 force merge(会占用大量 IO,建议业务低峰期触发)force merge 办法,使用 rest API
# Step1. 在合并前需要对合并速度进行合理限制,默认是 20mb,SSD可以适当放宽到 80mb:
PUT /_cluster/settings -d '
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "20mb"
}
}'
# Step2. 强制合并 API,示例表示的是最终合并为一个 segment file:
# 对某个索引做合并
POST /${INDEX_NAME}/_forcemerge?max_num_segments=1
# 对某些索引做合并
POST /${INDEX_PATTERN}/_forcemerge?max_num_segments=1
2. Filter Cache
默认的 10% heap 设置工作得够好,如果实际使用中 heap 没什么压力的情况下,才考虑加大这个设置。
3. Field Data Cache
对需要排序的字段不进行 analyzed,尽量使用 doc values(5.X版本天然支持,不需要特别设置)。对于不参与搜索的字段 ( fields ),将其 index 方法设置为 no,如果对分词没有需求,对参与搜索的字段,其 index 方法设置为 not_analyzed。
4. Bulk Queue
一般来说官方默认的 thread pool 设置已经能很好的工作了,建议不要随意去调优相关的设置,很多时候都是适得其反的效果。
5. Indexing Buffer
这个参数的默认值是10% heap size。根据经验,这个默认值也能够很好的工作,应对很大的索引吞吐量。 但有些用户认为这个 buffer 越大吞吐量越高,因此见过有用户将其设置为 40% 的。到了极端的情况,写入速度很高的时候,40%都被占用,导致OOM。
6. Cluster State Buffer
在超大规模集群的情况下,可以考虑分集群并通过 tribe node 连接做到对用户透明,这样可以保证每个集群里的 state 信息不会膨胀得过大。在单集群情况下,缩减 cluster state buffer 的方法就是减少 shard 数量,shard 数量的确定有以下几条规则:
1. 避免有非常大的分片,因为大分片可能会对集群从故障中恢复的能力产生负面影响。 对于多大的分片没有固定限制,但分片大小为 50GB 通常被界定为适用于各种用例的限制;
2. 尽可能使用基于时间的索引来管理数据。根据保留期(retention period,可以理解成有效期)将数据分组。基于时间的索引还可以轻松地随时间改变主分片和副本分片的数量(以为要生成的下一个索引进行更改)。这简化了适应不断变化的数据量和需求;(周期性的通过删除或者关闭历史索引以减少分片)
3. 小分片会导致小分段(segment),从而增加开销。目的是保持平均分片大小在几GB和几十GB之间。对于具有基于时间数据的用例,通常看到大小在 20GB 和 40GB 之间的分片;
4. 由于每个分片的开销取决于分段数和大小,通过强制操作迫使较小的段合并成较大的段可以减少开销并提高查询性能。一旦没有更多的数据被写入索引,这应该是理想的。请注意,这是一个消耗资源的(昂贵的)操作,较为理想的处理时段应该在非高峰时段执行;(对应使用 force meger 以减少 segment 数量的优化,目的是降低 segment memory 占用)
5. 可以在集群节点上保存的分片数量与可用的堆内存大小成正比,但这在 Elasticsearch 中没有的固定限制。 一个很好的经验法则是:确保每个节点的分片数量保持在低于每 1GB 堆内存对应集群的分片在 20-25 之间。 因此,具有 32GB 堆内存的节点最多可以有 600-750 个分片;
6. 对于单索引的主分片数,有这么 2 个公式:节点数 <= 主分片数 *(副本数 + 1) 以及 (同一索引 shard 数量 * (1 + 副本数)) < 3 * 数据节点数,比如有 3 个节点全是数据节点,1 个副本,那么主分片数大于等于 1.5,同时同一索引总分片数需要小于 4.5,因为副本数为 1,所以单节点主分片最适为 2,索引总分片数最适为 6,这样每个节点的总分片为 4;
7. 单分片小于 20GB 的情况下,采用单分片较为合适,请求不存在网络抖动的顾虑;
小结:分片不超 20GB,且单节点总分片不超 600。比如互联网区域,每天新建索引(lw-greenbay-online) 1 个分片 1 个副本,3 个月前的历史索引都关闭,3 节点总共需要扛 90 * 2 = 180 个分片,每个分片大约 6 GB,可谓比较健康的状态。
7. 超大搜索聚合结果集的 fetch
避免用户 fetch 超大搜索聚合结果集,确实需要大量拉取数据可以采用 scan & scroll API 来实现。在 ElasticSearch 上搜索数据时,默认只会返回10条文档,当我们想获取更多结果,或者只要结果中的一个区间的数据时,可以通过 size 和 from 来指定。
GET /_search?size=3&from=20
如上的查询语句,会返回排序后的结果中第 20 到第 22 条数据。ElasticSearch 在收到这样的一个请求之后,每一个分片都会返回一个 top22 的搜索结果,然后将这些结果汇总排序,再选出 top22 ,最后取第 20 到第 22 条数据作为结果返回。这样会带来一个问题,当我们搜索的时候,如果想取出第 10001 条数据,那么就相当于每个一分片都要对数据进行排序,取出前 10001 条文档,然后 ElasticSearch 再将这些结果汇总再次排序,之后取出第 10001 条数据。这样对于 ElasticSearch 来说就会产生相当大的资源和性能开销。如果我们不要求 ElasticSearch 对结果进行排序,那么就会消耗很少的资源,所以针对此种情况,ElasticSearch 提供了scan & scroll的搜索方式。
GET /old_index/_search?search_type=scan&scroll=1m
{
"query": { "match_all": {}},
"size": 1000
}
我们可以首先通过如上的请求发起一个搜索,但是这个请求不会返回任何文档,它会返回一个 _scroll_id ,接下来我们再通过这个 id 来从 ElasticSearch 中读取数据:
GET /_search/scroll?scroll=1m c2Nhbjs1OzExODpRNV9aY1VyUVM4U0NMd2pjWlJ3YWlBOzExOTpRNV9aY1VyUVM4U0 NMd2pjWlJ3YWlBOzExNjpRNV9aY1VyUVM4U0NMd2pjWlJ3YWlBOzExNzpRNV9aY1VyUVM4U0NMd2pjWlJ3YWlBOzEyMDpRNV9aY1VyUVM4U0NMd2pjWlJ3YWlBOzE7dG90YWxfaGl0czoxOw==
此时除了会返回搜索结果以外,还会再次返回一个 _scroll_id,当我们下次继续取数据时,需要用最新的 id。
十三、Elasticserach存储优化
1. 关闭不需要的功能
默认情况下 ElasticSearch 会将 indexs 和 doc values 添加到大多数字段中,以便可以搜索和聚合它们。 例如,如果有一个名为 foo 的数字字段,需要运行 histograms 但不需要 filter,则可以安全地禁用映射中此字段的索引:
PUT ${INDEX_NAME}
{
"mappings": {
"type": {
"properties": {
"foo": {
"type": "integer",
"index": false
}
}
}
}
}
text 字段在索引中存储规范化因子以便能够对文档进行评分。 如果只需要在 text 字段上使用 matching 功能,但不关心生成的 score,则可以命令 ElasticSearch 配置为不将规范写入索引:
PUT ${INDEX_NAME}
{
"mappings": {
"type": {
"properties": {
"foo": {
"type": "text",
"norms": false
}
}
}
}
}
text 字段也默认存储索引中的频率和位置。 频率用于计算分数,位置用于运行短语查询(phrase queries)。 如果不需要运行短语查询,可以告诉 ElasticSearch 不要索引位置:
PUT ${INDEX_NAME}
{
"mappings": {
"type": {
"properties": {
"foo": {
"type": "text",
"index_options": "freqs"
}
}
}
}
}
此外,如果不关心计分,则可以配置 ElasticSearch 以仅索引每个 term 的匹配文档。 这样做仍然可以在此字段上进行搜索(search),但是短语查询会引发错误,评分将假定 term 在每个文档中只出现一次。
PUT ${INDEX_NAME}
{
"mappings": {
"type": {
"properties": {
"foo": {
"type": "text",
"norms": false,
"index_options": "freqs"
}
}
}
}
}
2. 强制清除已标记删除的数据
Elasticsearch 是建立在 Apache Lucene 基础上的实时分布式搜索引擎,Lucene 为了提高搜索的实时性,采用不可再修改(immutable)方式将文档存储在一个个 segment 中。也就是说,一个 segment 在写入到存储系统之后,将不可以再修改。那么 Lucene 是如何从一个 segment 中删除一个被索引的文档呢?简单的讲,当用户发出命令删除一个被索引的文档#ABC 时,该文档并不会被马上从相应的存储它的 segment 中删除掉,而是通过一个特殊的文件来标记该文档已被删除。当用户再次搜索到 #ABC 时,Elasticsearch 在 segment 中仍能找到 #ABC,但由于 #ABC 文档已经被标记为删除,所以Lucene 会从发回给用户的搜索结果中剔除 #ABC,所以给用户感觉的是 #ABC 已经被删除了。
Elasticseach 会有后台线程根据 Lucene 的合并规则定期进行 segment merging 合并操作,一般不需要用户担心或者采取任何行动。被删除的文档在 segment 合并时,才会被真正删除掉。在此之前,它仍然会占用着JVM heap和操作系统的文件cach 等资源。在某些情况下,需要强制 Elasticsearch 进行 segment merging,已释放其占用的大量系统资源。
POST /${INDEX_NAME}/_forcemerge?max_num_segments=1&only_expunge_deletes=true&wait_for_completion=true
POST /${INDEX_PATTERN}/_forcemerge?max_num_segments=1&only_expunge_deletes=true&wait_for_completion=true
Force Merge 命令可强制进行 segment 合并,并删除所有标记为删除的文档。Segment merging 要消耗 CPU,以及大量的 I/O 资源,所以一定要在 ElasticSearch 集群处于维护窗口期间,并且有足够的 I/O 空间的(如:SSD)的条件下进行;否则很可能造成集群崩溃和数据丢失。
3. 减少副本数
最直接的存储优化手段是调整副本数,默认 ElasticSearch 是有 1 个副本的,假设对可用性要求不高,允许磁盘损坏情况下可能的数据缺失,可以把副本数调整为0,操作如下:
PUT /_template/${TEMPLATE_NAME}
{
"template":"${TEMPLATE_PATTERN}",
"settings" : {
"number_of_replicas" : 0
},
"version" : 1
}
其中 ${TEMPLATE_NAME} 表示模板名称,可以是不存在的,系统会新建。${TEMPLATE_PATTERN} 是用于匹配索引的表达式,比如 lw-greenbay-online-*。
与此相关的一个系统参数为:index.merge.scheduler.max_thread_count,默认值为 Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)),这个值在 SSD 上工作没问题,但是 SATA 盘上还是使用 1 个线程为好,因为太多也来不及完成。
# SATA 请设置 merge 线程为 1
PUT /_template/${TEMPLATE_NAME}
{
"template":"${TEMPLATE_PATTERN}",
"settings" : {
"index.merge.scheduler.max_thread_count": 1
},
"version" : 1
}
4. 请勿使用默认的动态字符串映射
默认的动态字符串映射会将字符串字段索引为文本(text)和关键字(keyword)。 如果只需要其中的一个,这样做无疑是浪费的。 通常情况下,一个 id 字段只需要被索引为一个 keyword,而一个 body 字段只需要被索引为一个 text 字段。可以通过在字符串字段上配置显式映射或设置将字符串字段映射为文本(text)或关键字(keyword)的动态模板来禁用此功能。例如下面的模板,可以用来将 strings 字段映射为关键字:
PUT ${INDEX_NAME}
{
"mappings": {
"type": {
"dynamic_templates": [
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
}
5. 禁用 _all 字段
_all 字段是由所有字段拼接成的超级字段,如果在查询中已知需要查询的字段,就可以考虑禁用它。
PUT /_template/${TEMPLATE_NAME}
{
"template": "${TEMPLATE_PATTERN}",
"settings" : {...},
"mappings": {
"type_1": {
"_all": {
"enabled": false
},
"properties": {...}
}
},
"version" : 1
}
6. 使用 best_compression
_source 字段和 stored fields 会占用大量存储,可以考虑使用 best_compression 进行压缩。默认的压缩方式为 LZ4,但需要更高压缩比的话,可以通过 inex.codec 进行设置,修改为 DEFLATE,在 force merge 后生效:
# Step1. 修改压缩算法为 best_compression
PUT /_template/${TEMPLATE_NAME}
{
"template":"${TEMPLATE_PATTERN}",
"settings" : {
"index.codec" : "best_compression"
},
"version" : 1
}
# Step2. force merge
POST /${INDEX_NAME}/_forcemerge?max_num_segments=1&wait_for_completion=true
POST /${INDEX_PATTERN}/_forcemerge?max_num_segments=1&wait_for_completion=true
7. 使用最优数据格式
我们为数字数据选择的类型可能会对磁盘使用量产生重大影响。 首先,应使用整数类型(byte,short,integer或long)来存储整数,浮点数应该存储在 scaled_float 中,或者存储在适合用例的最小类型中:使用 float 而不是 double,使用 half_float 而不是 float。
PUT /_template/${TEMPLATE_NAME}
{
"template": "${TEMPLATE_PATTERN}",
"settings" : {...},
"mappings": {
"type_1": {
"${FIELD_NAME}": {
"type": "integer"
},
"properties": {...}
}
},
"version" : 1
}
十四、Elasticserach搜索速度优化
1. 避免Join和Parent-Child
Join会使查询慢数倍、 Parent-Child会使查询慢数百倍,请在进行 query 语句编写的时候尽量避免。
2. 映射
某些数据本身是数字,但并不意味着它应该总是被映射为一个数字字段。 通常存储着标识符的字段(如ISBN)或来自另一个数据库的数字型记录,可能映射为 keyword 而不是 integer 或者 long 会更好些。
3. 避免使用 Scripts
之前 Groovy 脚本曝出了很大的漏洞,总的来说是需要避免使用的。如果必须要使用,尽量用 5.X 以上版本自带的 painless 和 expressions 引擎。
4. 根据四舍五入的日期进行查询
根据 timestamp 字段进行的查询通常不可缓存,因为匹配的范围始终在变化。 但就用户体验而言,以四舍五入对日期进行转换通常是可接受的,这样可以有效利用系统缓存。举例说明,有以下查询:
PUT index/type/1
{
"my_date": "2016-05-11T16:30:55.328Z"
}
GET index/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"my_date": {
"gte": "now-1h",
"lte": "now"
}
}
}
}
}
}
可以对时间范围进行替换:
GET index/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"my_date": {
"gte": "now-1h/m",
"lte": "now/m"
}
}
}
}
}
}
在这种情况下,我们四舍五入到分钟,所以如果当前时间是 16:31:29 ,范围查询将匹配 my_date 字段的值在 15:31:00 和16:31:59 之间的所有内容。 如果多个用户在同一分钟内运行包含这个范围的查询,查询缓存可以帮助加快速度。 用于四舍五入的时间间隔越长,查询缓存可以提供的帮助就越多,但要注意过于积极的舍入也可能会伤害用户体验。
为了能够利用查询缓存,建议将范围分割成大的可缓存部分和更小的不可缓存的部分,如下所示:
GET index/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"should": [
{
"range": {
"my_date": {
"gte": "now-1h",
"lte": "now-1h/m"
}
}
},
{
"range": {
"my_date": {
"gt": "now-1h/m",
"lt": "now/m"
}
}
},
{
"range": {
"my_date": {
"gte": "now/m",
"lte": "now"
}
}
}
]
}
}
}
}
}
然而,这种做法可能会使查询在某些情况下运行速度较慢,因为由 bool 查询引入的开销可能会因更好地利用查询缓存而失败。
5. 对只读 indices 进行 force merge
建议将只读索引被合并到一个单独的分段中。 基于时间的索引通常就是这种情况:只有当前时间索引会写入数据,而旧索引是只读索引。
6. 预热 global ordinals
全局序号(global ordinals)是用于在关键字(keyword)字段上运行 terms aggregations 的数据结构。 由于 ElasticSearch 不知道聚合使用哪些字段、哪些字段不使用,所以它们在内存中被加载得很慢。 我们可以通过下面的 API 来告诉 ElasticSearch 通过配置映射来在 refresh 的时候加载全局序号:
PUT index
{
"mappings": {
"type": {
"properties": {
"foo": {
"type": "keyword",
"eager_global_ordinals": true
}
}
}
}
}
十五、Elasticserach写入性能优化
之前描述了 ElasticSearch 在内存管理方面的优化,接下来梳理下如何对写入性能进行优化,写入性能的优化也和 HBase 类似,无非就是增加吞吐,而增加吞吐的方法就是增大刷写间隔、合理设置线程数量、开启异步刷写(允许数据丢失的情况下)。
1. 增大刷写间隔
通过修改主配置文件 elasticsearch.yml 或者 Rest API 都可以对 index.refresh_interval进行修改,增大该属性可以提升写入吞吐。
PUT /_template/{TEMPLATE_NAME}
{
"template":"{INDEX_PATTERN}",
"settings" : {
"index.refresh_interval" : "30s"
}
}
PUT {INDEX_PAATERN}/_settings
{
"index.refresh_interval" : "30s"
}
2. 合理设置线程数量
调整 elasticsearch.yml ,对 bulk/flush 线程池进行调优,根据本机实际配置:
threadpool.bulk.type:fixed threadpool.bulk.size:8 #(CPU核数) threadpool.flush.type:fixed threadpool.flush.size:8 #(CPU核数)
3. 开启异步刷写
如果允许数据丢失,可以对特定 index 开启异步刷写:
PUT /_template/{TEMPLATE_NAME}
{
"template":"{INDEX_PATTERN}",
"settings" : {
"index.translog.durability": "async"
}
}
PUT {INDEX_PAATERN}/_settings
{
"index.translog.durability": "async"
}
十六、Elasticserach审计优化
1. 开启慢查询日志
不论是数据库还是搜索引擎,对于问题的排查,开启慢查询日志是十分必要的,ElasticSearch 开启慢查询的方式有多种,但是最常用的是调用模板 API 进行全局设置:
PUT /_template/{TEMPLATE_NAME}
{
"template":"{INDEX_PATTERN}",
"settings" : {
"index.indexing.slowlog.level": "INFO",
"index.indexing.slowlog.threshold.index.warn": "10s",
"index.indexing.slowlog.threshold.index.info": "5s",
"index.indexing.slowlog.threshold.index.debug": "2s",
"index.indexing.slowlog.threshold.index.trace": "500ms",
"index.indexing.slowlog.source": "1000",
"index.search.slowlog.level": "INFO",
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.query.info": "5s",
"index.search.slowlog.threshold.query.debug": "2s",
"index.search.slowlog.threshold.query.trace": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "800ms",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.search.slowlog.threshold.fetch.trace": "200ms"
},
"version" : 1
}
对于已经存在的 index 使用 settings API:
PUT {INDEX_PAATERN}/_settings
{
"index.indexing.slowlog.level": "INFO",
"index.indexing.slowlog.threshold.index.warn": "10s",
"index.indexing.slowlog.threshold.index.info": "5s",
"index.indexing.slowlog.threshold.index.debug": "2s",
"index.indexing.slowlog.threshold.index.trace": "500ms",
"index.indexing.slowlog.source": "1000",
"index.search.slowlog.level": "INFO",
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.query.info": "5s",
"index.search.slowlog.threshold.query.debug": "2s",
"index.search.slowlog.threshold.query.trace": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "800ms",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.search.slowlog.threshold.fetch.trace": "200ms"
}
这样,在日志目录下的慢查询日志就会有输出记录必要的信息了。
十七、ElasticSearch运维手册
在管理es集群时,我们可以直接向es安装所在服务器9200端口(默认端口)发送请求查看查询结果。也可使用Cerebro可视化管理工具对es进行管理。
1. ElasticSearch管理工具
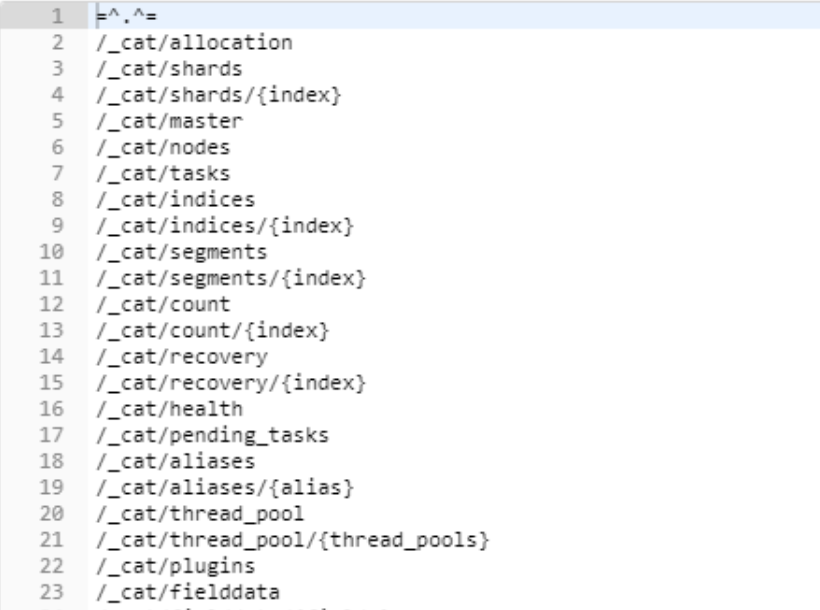
通过 GET 请求发送 cat 命名可以列出所有可用的cat API,我们可以使用postman或者浏览器发送请求到es的9200端口。

查询结果如下,请求返回了所有可用的cat API
又或者可以使用Cerebro可视化管理工具对es进行管理。比如我的管理工具访问地址http://172.16.60.14:9002/#/connect
如下图所示,进入到可视化管理界面以后,选择顶部导航菜单more,在下拉选项框中选择cat apis。
进入cat api查询页面


2. 常用cat API介绍
1. 健康检查
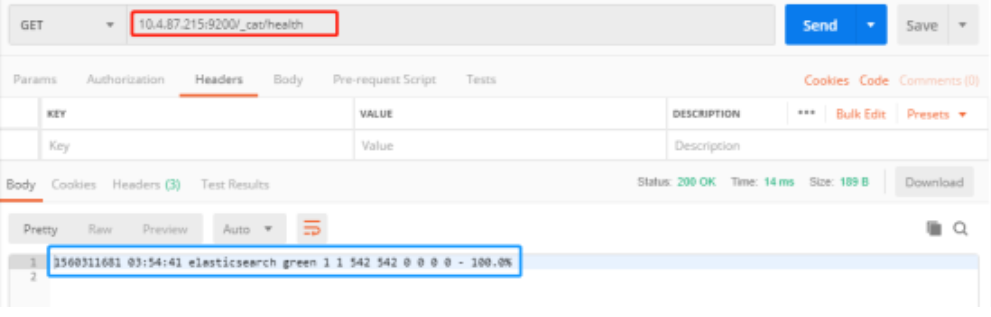
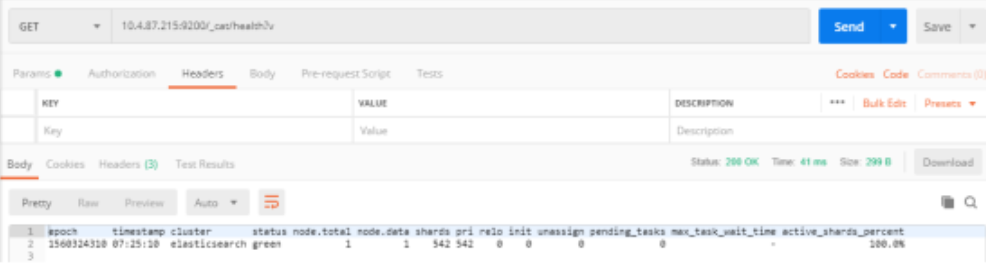
/_cat/health 和 /_cat/health?v 查询请求带了?v 将返回表头,在postman中我们可以发起如下请求,可以看到es集群的健康状况,但是结果并不直观。
通过es管理工具很方便的就能使用cat api,下拉框中选中health
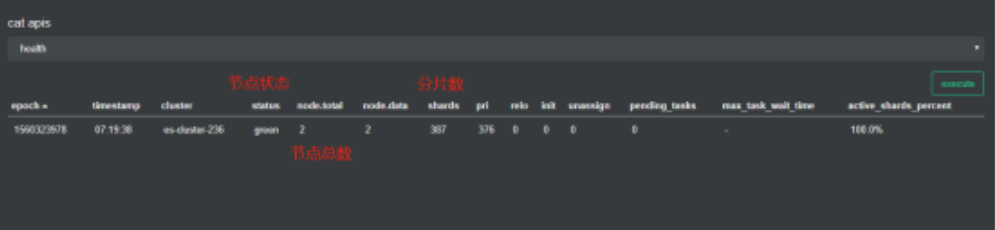
点击excute按钮即可对需要管理的es集群进行健康检查。

2. 节点分片数量查询
/_cat/allocation?v

查询每个节点上分配的分片(shard)的数量和每个分片(shard)所使用的硬盘容量
3. 节点统计
/_cat/nodes 或/_cat/nodes?v
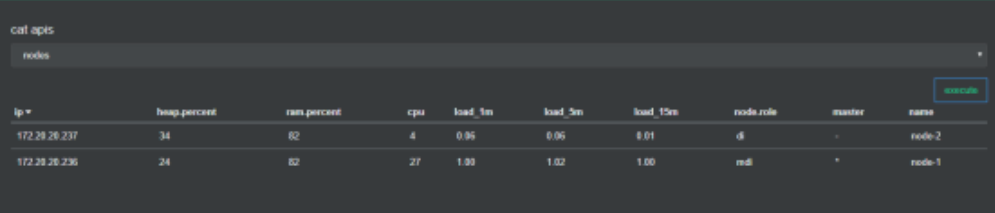
显示当前es集群节点的状况。
4. 文档数量查询
/_cat/count?v

快速查询当前集群document数量
5. 查询master节点
/_cat/master?v

用于显示master的节点ID,绑定IP地址,节点名称。
6. 查询节点自定义属性
/_cat/nodeattrs?v
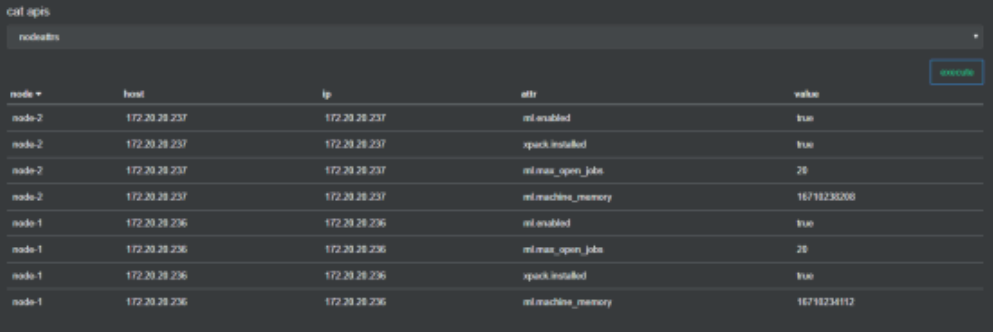
显示节点自定义属性。
7. 执行任务查询
/_cat/pending_tasks?v

8. 索引分片恢复查询
/_cat/recovery?v
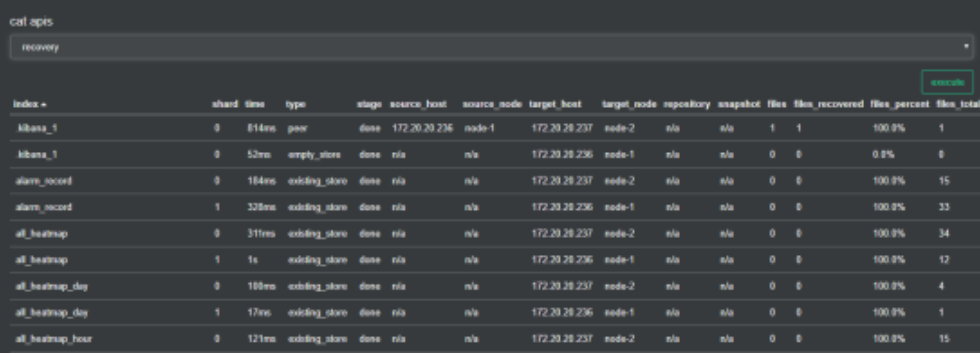
索引分片正在恢复或者已经完成恢复的相关信息。
9. 节点线程查询
/_cat/thread_pool
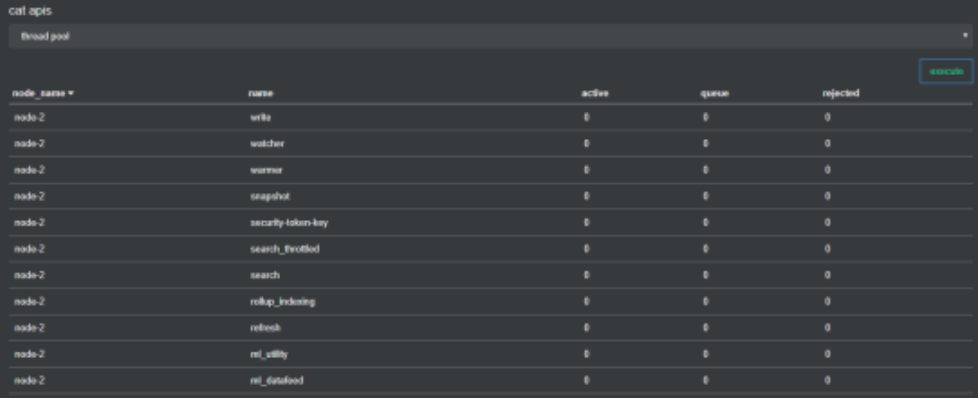
输出每个节点的线程池统计信息,默认情况下显示正在活动、队列和被拒绝的统计信息。
10. 索引所在分片查询
/_cat/shards
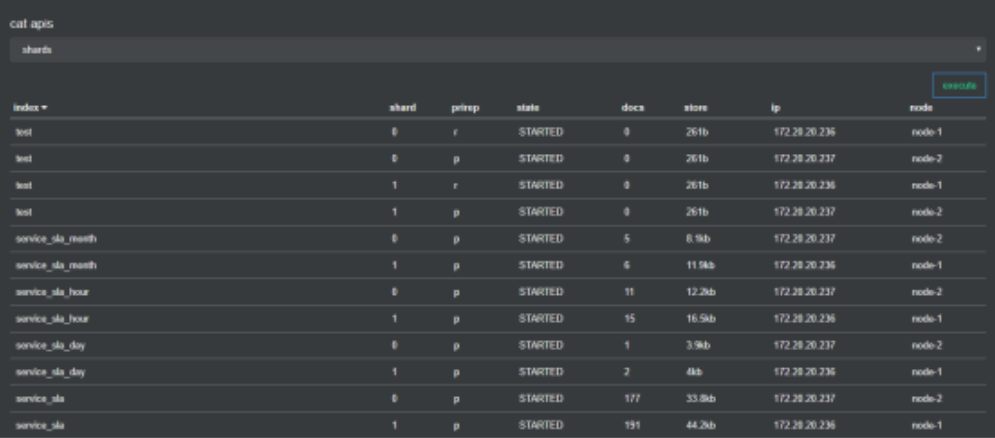
输出节点包含分片的详细信息(当前分片是primary shard还是 replica shard,doc的数量,硬盘上占用的字节已经该节点被分配在哪里等)。
十八、Elasticsearch 是如何做到分布式,可扩展和近实时搜索的
1. 集群(Cluster)
Elasticsearch 的集群搭建很简单,不需要依赖第三方协调管理组件,自身内部就实现了集群的管理功能。Elasticsearch 集群由一个或多个 Elasticsearch 节点组成,每个节点配置相同的 cluster.name 即可加入集群,默认值为 "elasticsearch"。确保不同的环境中使用不同的集群名称,否则最终会导致节点加入错误的集群。一个 Elasticsearch 服务启动实例就是一个节点(Node)。节点通过 node.name 来设置节点名称,如果不设置则在启动时给节点分配一个随机通用唯一标识符作为名称。
① 发现机制
那么有一个问题,Elasticsearch 内部是如何通过一个相同的设置 cluster.name 就能将不同的节点连接到同一个集群的?答案是 Zen Discovery。
Zen Discovery 是 Elasticsearch 的内置默认发现模块(发现模块的职责是发现集群中的节点以及选举 Master 节点)。它提供单播和基于文件的发现,并且可以扩展为通过插件支持云环境和其他形式的发现。Zen Discovery 与其他模块集成,例如,节点之间的所有通信都使用 Transport 模块完成。节点使用发现机制通过 Ping 的方式查找其他节点。
Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。如果集群的节点运行在不同的机器上,使用单播,你可以为 Elasticsearch 提供一些它应该去尝试连接的节点列表。
当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 Master 节点,并加入集群。这意味着单播列表不需要包含集群中的所有节点, 它只是需要足够的节点,当一个新节点联系上其中一个并且说上话就可以了。
如果你使用 Master 候选节点作为单播列表,你只要列出三个就可以了。这个配置在 elasticsearch.yml 文件中:
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]
节点启动后先 Ping ,如果 discovery.zen.ping.unicast.hosts 有设置,则 Ping 设置中的 Host ,否则尝试 ping localhost 的几个端口。Elasticsearch 支持同一个主机启动多个节点,Ping 的 Response 会包含该节点的基本信息以及该节点认为的 Master 节点。
选举开始,先从各节点认为的 Master 中选,规则很简单,按照 ID 的字典序排序,取第一个。如果各节点都没有认为的 Master ,则从所有节点中选择,规则同上。这里有个限制条件就是 discovery.zen.minimum_master_nodes ,如果节点数达不到最小值的限制,则循环上述过程,直到节点数足够可以开始选举。最后选举结果是肯定能选举出一个 Master ,如果只有一个 Local 节点那就选出的是自己。如果当前节点是 Master ,则开始等待节点数达到 discovery.zen.minimum_master_nodes,然后提供服务。如果当前节点不是 Master ,则尝试加入 Master 。Elasticsearch 将以上服务发现以及选主的流程叫做 Zen Discovery 。
由于它支持任意数目的集群( 1- N ),所以不能像 Zookeeper 那样限制节点必须是奇数,也就无法用投票的机制来选主,而是通过一个规则。只要所有的节点都遵循同样的规则,得到的信息都是对等的,选出来的主节点肯定是一致的。但分布式系统的问题就出在信息不对等的情况,这时候很容易出现脑裂(Split-Brain)的问题。大多数解决方案就是设置一个 Quorum 值,要求可用节点必须大于 Quorum(一般是超过半数节点),才能对外提供服务。而 Elasticsearch 中,这个 Quorum 的配置就是 discovery.zen.minimum_master_nodes 。
② 节点的角色
每个节点既可以是候选主节点也可以是数据节点,通过在配置文件 ../config/elasticsearch.yml 中设置即可,默认都为 true。
node.master: true #是否候选主节点 node.data: true #是否数据节点
数据节点负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作,所以数据节点(Data 节点)对机器配置要求比较高,对 CPU、内存和 I/O 的消耗很大。
通常随着集群的扩大,需要增加更多的数据节点来提高性能和可用性。候选主节点可以被选举为主节点(Master 节点),集群中只有候选主节点才有选举权和被选举权,其他节点不参与选举的工作。主节点负责创建索引、删除索引、跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点、追踪集群中节点的状态等,稳定的主节点对集群的健康是非常重要的。

一个节点既可以是候选主节点也可以是数据节点,但是由于数据节点对 CPU、内存核 I/O 消耗都很大。所以如果某个节点既是数据节点又是主节点,那么可能会对主节点产生影响从而对整个集群的状态产生影响。
因此为了提高集群的健康性,我们应该对 Elasticsearch 集群中的节点做好角色上的划分和隔离。可以使用几个配置较低的机器群作为候选主节点群。主节点和其他节点之间通过 Ping 的方式互检查,主节点负责 Ping 所有其他节点,判断是否有节点已经挂掉。其他节点也通过 Ping 的方式判断主节点是否处于可用状态。
虽然对节点做了角色区分,但是用户的请求可以发往任何一个节点,并由该节点负责分发请求、收集结果等操作,而不需要主节点转发。这种节点可称之为协调节点,协调节点是不需要指定和配置的,集群中的任何节点都可以充当协调节点的角色。
③ 脑裂现象
同时如果由于网络或其他原因导致集群中选举出多个 Master 节点,使得数据更新时出现不一致,这种现象称之为脑裂,即集群中不同的节点对于 Master 的选择出现了分歧,出现了多个 Master 竞争。
"脑裂"问题可能有以下几个原因造成:
1. 网络问题:集群间的网络延迟导致一些节点访问不到 Master,认为 Master 挂掉了从而选举出新的 Master,并对 Master 上的分片和副本标红,分配新的主分片。
2. 节点负载:主节点的角色既为 Master 又为 Data,访问量较大时可能会导致 ES 停止响应(假死状态)造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
3. 内存回收:主节点的角色既为 Master 又为 Data,当 Data 节点上的 ES 进程占用的内存较大,引发 JVM 的大规模内存回收,造成 ES 进程失去响应。
为了避免脑裂现象的发生,我们可以从原因着手通过以下几个方面来做出优化措施:
1. 适当调大响应时间,减少误判。通过参数 discovery.zen.ping_timeout 设置节点状态的响应时间,默认为 3s,可以适当调大。如果 Master 在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。调大参数(如 6s,discovery.zen.ping_timeout:6),可适当减少误判。
2. 选举触发。我们需要在候选集群中的节点的配置文件中设置参数 discovery.zen.munimum_master_nodes 的值。这个参数表示在选举主节点时需要参与选举的候选主节点的节点数,默认值是 1,官方建议取值(master_eligibel_nodes/2)+1,其中 master_eligibel_nodes 为候选主节点的个数。这样做既能防止脑裂现象的发生,也能最大限度地提升集群的高可用性,因为只要不少于 discovery.zen.munimum_master_nodes 个候选节点存活,选举工作就能正常进行。当小于这个值的时候,无法触发选举行为,集群无法使用,不会造成分片混乱的情况。
3. 角色分离。即是上面我们提到的候选主节点和数据节点进行角色分离,这样可以减轻主节点的负担,防止主节点的假死状态发生,减少对主节点“已死”的误判。
2. 分片(Shards)
Elasticsearch 支持PB级全文搜索,当索引上的数据量太大的时候,Elasticsearch 通过水平拆分的方式将一个索引上的数据拆分出来分配到不同的数据块上,拆分出来的数据库块称之为一个分片。这类似于 MySQL 的分库分表,只不过 MySQL 分库分表需要借助第三方组件而 Elasticsearch 内部自身实现了此功能。
在一个多分片的索引中写入数据时,通过路由来确定具体写入哪一个分片中,所以在创建索引的时候需要指定分片的数量,并且分片的数量一旦确定就不能修改。分片的数量和下面介绍的副本数量都是可以通过创建索引时的 Settings 来配置,Elasticsearch 默认为一个索引创建 5 个主分片, 并分别为每个分片创建一个副本。
PUT /myIndex
{
"settings" : {
"number_of_shards" : 5,
"number_of_replicas" : 1
}
}
Elasticsearch 通过分片的功能使得索引在规模上和性能上都得到提升,每个分片都是 Lucene 中的一个索引文件,每个分片必须有一个主分片和零到多个副本。
3. 副本(Replicas)
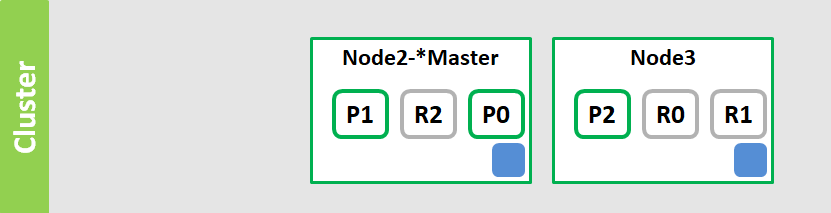
副本就是对分片的 Copy,每个主分片都有一个或多个副本分片,当主分片异常时,副本可以提供数据的查询等操作。主分片和对应的副本分片是不会在同一个节点上的,所以副本分片数的最大值是 N-1(其中 N 为节点数)。对文档的新建、索引和删除请求都是写操作,必须在主分片上面完成之后才能被复制到相关的副本分片。
Elasticsearch 为了提高写入的能力这个过程是并发写的,同时为了解决并发写的过程中数据冲突的问题,Elasticsearch 通过乐观锁的方式控制,每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。一旦所有的副本分片都报告写成功才会向协调节点报告成功,协调节点向客户端报告成功。
从上图可以看出为了达到高可用,Master 节点会避免将主分片和副本分片放在同一个节点上。假设这时节点 Node1 服务宕机了或者网络不可用了,那么主节点上主分片 S0 也就不可用了。幸运的是还存在另外两个节点能正常工作,这时 ES 会重新选举新的主节点,而且这两个节点上存在我们所需要的 S0 的所有数据。
我们会将 S0 的副本分片提升为主分片,这个提升主分片的过程是瞬间发生的。此时集群的状态将会为 Yellow。为什么我们集群状态是 Yellow 而不是 Green 呢?虽然我们拥有所有的 2 个主分片,但是同时设置了每个主分片需要对应两份副本分片,而此时只存在一份副本分片。所以集群不能为 Green 的状态。
如果我们同样关闭了 Node2 ,我们的程序依然可以保持在不丢失任何数据的情况下运行,因为 Node3 为每一个分片都保留着一份副本。如果我们重新启动 Node1 ,集群可以将缺失的副本分片再次进行分配,那么集群的状态又将恢复到原来的正常状态。如果 Node1 依然拥有着之前的分片,它将尝试去重用它们,只不过这时 Node1 节点上的分片不再是主分片而是副本分片了,如果期间有更改的数据只需要从主分片上复制修改的数据文件即可。
小结:
1. 将数据分片是为了提高可处理数据的容量和易于进行水平扩展,为分片做副本是为了提高集群的稳定性和提高并发量。
2. 副本是乘法,越多消耗越大,但也越保险。分片是除法,分片越多,单分片数据就越少也越分散。
3. 副本越多,集群的可用性就越高,但是由于每个分片都相当于一个 Lucene 的索引文件,会占用一定的文件句柄、内存及 CPU。并且分片间的数据同步也会占用一定的网络带宽,所以索引的分片数和副本数也不是越多越好。
4. 映射(Mapping)
映射是用于定义 ES 对索引中字段的存储类型、分词方式和是否存储等信息,就像数据库中的 Schema ,描述了文档可能具有的字段或属性、每个字段的数据类型。只不过关系型数据库建表时必须指定字段类型,而 ES 对于字段类型可以不指定然后动态对字段类型猜测,也可以在创建索引时具体指定字段的类型。
对字段类型根据数据格式自动识别的映射称之为动态映射(Dynamic Mapping),我们创建索引时具体定义字段类型的映射称之为静态映射或显示映射(Explicit Mapping)。在讲解动态映射和静态映射的使用前,我们先来了解下 ES 中的数据有哪些字段类型?之后我们再讲解为什么我们创建索引时需要建立静态映射而不使用动态映射。

Text 用于索引全文值的字段,例如电子邮件正文或产品说明。这些字段是被分词的,它们通过分词器传递 ,以在被索引之前将字符串转换为单个术语的列表。分析过程允许 Elasticsearch 搜索单个单词中每个完整的文本字段。文本字段不用于排序,很少用于聚合。
Keyword 用于索引结构化内容的字段,例如电子邮件地址,主机名,状态代码,邮政编码或标签。它们通常用于过滤,排序,和聚合。Keyword 字段只能按其确切值进行搜索。
通过对字段类型的了解我们知道有些字段需要明确定义的,例如某个字段是 Text 类型还是 Keyword 类型差别是很大的,时间字段也许我们需要指定它的时间格式,还有一些字段我们需要指定特定的分词器等等。如果采用动态映射是不能精确做到这些的,自动识别常常会与我们期望的有些差异。所以创建索引的时候一个完整的格式应该是指定分片和副本数以及 Mapping 的定义,如下:
PUT my_index
{
"settings" : {
"number_of_shards" : 5,
"number_of_replicas" : 1
}
"mappings": {
"_doc": {
"properties": {
"title": { "type": "text" },
"name": { "type": "text" },
"age": { "type": "integer" },
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
}
5. Elasticsearch集群健康状态
Elasticsearch默认在 9200 端口运行,请求 curl http://localhost:9200/ 或者浏览器输入 http://localhost:9200,得到一个 JSON 对象,其中包含当前节点、集群、版本等信息。
{
"name" : "U7fp3O9",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "-Rj8jGQvRIelGd9ckicUOA",
"version" : {
"number" : "6.8.1",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "1fad4e1",
"build_date" : "2019-06-18T13:16:52.517138Z",
"build_snapshot" : false,
"lucene_version" : "7.7.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
要检查群集运行状况,我们可以在 Kibana 控制台中运行以下命令 GET /_cluster/health,得到如下信息:
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 9,
"active_shards" : 9,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 5,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 64.28571428571429
}
集群状态通过 绿,黄,红 来标识:
绿色:集群健康完好,一切功能齐全正常,所有分片和副本都可以正常工作。
黄色:预警状态,所有主分片功能正常,但至少有一个副本是不能正常工作的。此时集群是可以正常工作的,但是高可用性在某种程度上会受影响。
红色:集群不可正常使用。某个或某些分片及其副本异常不可用,这时集群的查询操作还能执行,但是返回的结果会不准确。对于分配到这个分片的写入请求将会报错,最终会导致数据的丢失。
当集群状态为红色时,它将会继续从可用的分片提供搜索请求服务,但是你需要尽快修复那些未分配的分片。
6. Elasticsearch 机制原理
Elasticsearch 的基本概念和基本操作介绍完了之后,我们可能还有很多疑惑:
1. 它们内部是如何运行的?
2. 主分片和副本分片是如何同步的?
3. 创建索引的流程是什么样的?
4. Elasticsearch 如何将索引数据分配到不同的分片上的?以及这些索引数据是如何存储的?
5. 为什么说 Elasticsearch 是近实时搜索引擎而文档的 CRUD (创建-读取-更新-删除) 操作是实时的?
6. 以及 Elasticsearch 是怎样保证更新被持久化在断电时也不丢失数据?
7. 还有为什么删除文档不会立刻释放空间?
带着这些疑问我们进入接下来的内容。
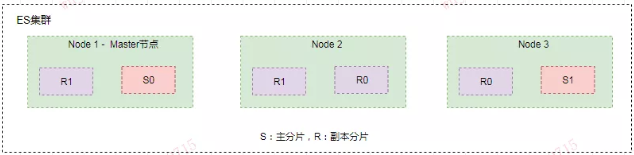
a) 写索引原理
下图描述了 3 个节点的集群,共拥有 12 个分片,其中有 4 个主分片(S0、S1、S2、S3)和 8 个副本分片(R0、R1、R2、R3),每个主分片对应两个副本分片,节点 1 是主节点(Master 节点)负责整个集群的状态。

写索引是只能写在主分片上,然后同步到副本分片。这里有四个主分片,一条数据 ES 是根据什么规则写到特定分片上的呢?这条索引数据为什么被写到 S0 上而不写到 S1 或 S2 上?那条数据为什么又被写到 S3 上而不写到 S0 上了?
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
Routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。Routing 通过 Hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数。这个在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。这就解释了为什么我们要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
由于在 ES 集群中每个节点通过上面的计算公式都知道集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。在一个写请求被发送到某个节点后,该节点即为前面说过的协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上。

假如此时数据通过路由计算公式取余后得到的值是 shard=hash(routing)%4=0。
则具体流程如下:
1. 客户端向 ES1 节点(协调节点)发送写请求,通过路由计算公式得到值为 0,则当前数据应被写到主分片 S0 上。
2. ES1 节点将请求转发到 S0 主分片所在的节点 ES3,ES3 接受请求并写入到磁盘。
3. 并发将数据复制到两个副本分片R0上,其中通过乐观并发控制数据的冲突。一旦所有的副本分片都报告成功,则节点 ES3 将向协调节点报告成功,协调节点向客户端报告成功。
b)存储原理
上面介绍了在 Elasticsearch 内部索引的写处理流程,这个流程是在 Elasticsearch 的内存中执行的,数据被分配到特定的分片和副本上之后,最终是存储到磁盘上的,这样在断电的时候就不会丢失数据。具体的存储路径可在配置文件 ../config/elasticsearch.yml 中进行设置,默认存储在安装目录的 Data 文件夹下。
建议不要使用默认值,因为若 Elasticsearch 进行了升级,则有可能导致数据全部丢失:
path.data: /path/to/data #索引数据 path.logs: /path/to/logs #日志记录
① 分段存储
索引文档以段的形式存储在磁盘上,何为段?索引文件被拆分为多个子文件,则每个子文件叫作段,每一个段本身都是一个倒排索引,并且段具有不变性,一旦索引的数据被写入硬盘,就不可再修改。在底层采用了分段的存储模式,使它在读写时几乎完全避免了锁的出现,大大提升了读写性能。
段被写入到磁盘后会生成一个提交点,提交点是一个用来记录所有提交后段信息的文件。一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限。相反,当段在内存中时,就只有写的权限,而不具备读数据的权限,意味着不能被检索。
段的概念提出主要是因为:在早期全文检索中为整个文档集合建立了一个很大的倒排索引,并将其写入磁盘中。
如果索引有更新,就需要重新全量创建一个索引来替换原来的索引。这种方式在数据量很大时效率很低,并且由于创建一次索引的成本很高,所以对数据的更新不能过于频繁,也就不能保证时效性。
索引文件分段存储并且不可修改,那么新增、更新和删除如何处理呢?
1. 新增,新增很好处理,由于数据是新的,所以只需要对当前文档新增一个段就可以了。
2. 删除,由于不可修改,所以对于删除操作,不会把文档从旧的段中移除而是通过新增一个 .del 文件,文件中会列出这些被删除文档的段信息。这个被标记删除的文档仍然可以被查询匹配到, 但它会在最终结果被返回前从结果集中移除。
3. 更新,不能修改旧的段来进行反映文档的更新,其实更新相当于是删除和新增这两个动作组成。会将旧的文档在 .del 文件中标记删除,然后文档的新版本被索引到一个新的段中。可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就会被移除。
段被设定为不可修改具有一定的优势也有一定的缺点,优势主要表现在:
1. 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
2. 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
3. 其它缓存(像 Filter 缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
4. 写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和需要被缓存到内存的索引的使用量。
段的不变性的缺点如下:
1. 当对旧数据进行删除时,旧数据不会马上被删除,而是在 .del 文件中被标记为删除。而旧数据只能等到段更新时才能被移除,这样会造成大量的空间浪费。
2. 若有一条数据频繁的更新,每次更新都是新增新的标记旧的,则会有大量的空间浪费。
3. 每次新增数据时都需要新增一个段来存储数据。当段的数量太多时,对服务器的资源例如文件句柄的消耗会非常大。
4. 在查询的结果中包含所有的结果集,需要排除被标记删除的旧数据,这增加了查询的负担。
② 延迟写策略
介绍完了存储的形式,那么索引写入到磁盘的过程是怎样的?是否是直接调 Fsync 物理性地写入磁盘?答案是显而易见的,如果是直接写入到磁盘上,磁盘的 I/O 消耗上会严重影响性能。那么当写数据量大的时候会造成 Elasticsearch 停顿卡死,查询也无法做到快速响应。如果真是这样 Elasticsearch 也就不会称之为近实时全文搜索引擎了。为了提升写的性能,Elasticsearch 并没有每新增一条数据就增加一个段到磁盘上,而是采用延迟写的策略。
每当有新增的数据时,就将其先写入到内存中,在内存和磁盘之间是文件系统缓存。当达到默认的时间(1 秒钟)或者内存的数据达到一定量时,会触发一次刷新(RefrElasticsearchh),将内存中的数据生成到一个新的段上并缓存到文件缓存系统 上,稍后再被刷新到磁盘中并生成提交点。这里的内存使用的是 Elasticsearch 的 JVM 内存,而文件缓存系统使用的是操作系统的内存。新的数据会继续的被写入内存,但内存中的数据并不是以段的形式存储的,因此不能提供检索功能。由内存刷新到文件缓存系统的时候会生成新的段,并将段打开以供搜索使用,而不需要等到被刷新到磁盘。
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 RefrElasticsearchh (即内存刷新到文件缓存系统)。默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是近实时搜索,因为文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。我们也可以手动触发 RefrElasticsearchh,POST /_refrElasticsearchh 刷新所有索引,POST /nba/_refrElasticsearchh 刷新指定的索引。
Tips:尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候, 手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新, 而且并不是所有的情况都需要每秒刷新。
可能你正在使用 Elasticsearch 索引大量的日志文件, 你可能想优化索引速度而不是近实时搜索。这时可以在创建索引时在 Settings 中通过调大 refresh_interval = "30s" 的值 , 降低每个索引的刷新频率,设值时需要注意后面带上时间单位,否则默认是毫秒。当 refresh_interval=-1 时表示关闭索引的自动刷新。
虽然通过延时写的策略可以减少数据往磁盘上写的次数提升了整体的写入能力,但是我们知道文件缓存系统也是内存空间,属于操作系统的内存,只要是内存都存在断电或异常情况下丢失数据的危险。为了避免丢失数据,Elasticsearch 添加了事务日志(Translog),事务日志记录了所有还没有持久化到磁盘的数据。

添加了事务日志后整个写索引的流程如上图所示:
1. 一个新文档被索引之后,先被写入到内存中,但是为了防止数据的丢失,会追加一份数据到事务日志中。不断有新的文档被写入到内存,同时也都会记录到事务日志中。这时新数据还不能被检索和查询。
2. 当达到默认的刷新时间或内存中的数据达到一定量后,会触发一次 Refresh,将内存中的数据以一个新段形式刷新到文件缓存系统中并清空内存。这时虽然新段未被提交到磁盘,但是可以提供文档的检索功能且不能被修改。
3. 随着新文档索引不断被写入,当日志数据大小超过 512M 或者时间超过 30 分钟时,会触发一次 Flush。内存中的数据被写入到一个新段同时被写入到文件缓存系统,文件系统缓存中数据通过 Fsync 刷新到磁盘中,生成提交点,日志文件被删除,创建一个空的新日志。
通过这种方式当断电或需重启时,Elasticsearch 不仅要根据提交点去加载已经持久化过的段,还需要工具 Translog 里的记录,把未持久化的数据重新持久化到磁盘上,避免了数据丢失的可能。
③ 段合并
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。每一个段都会消耗文件句柄、内存和 CPU 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段然后合并查询结果,所以段越多,搜索也就越慢。
Elasticsearch 通过在后台定期进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档不会被拷贝到新的大段中。合并的过程中不会中断索引和搜索。

- 段合并在进行索引和搜索时会自动进行,合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中,这些段既可以是未提交的也可以是已提交的。
- 合并结束后老的段会被删除,新的段被 Flush 到磁盘,同时写入一个包含新段且排除旧的和较小的段的新提交点,新的段被打开可以用来搜索。
- 段合并的计算量庞大, 而且还要吃掉大量磁盘 I/O,段合并会拖累写入速率,如果任其发展会影响搜索性能。
- Elasticsearch 在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。
7. Elasticsearch优化性能的措施
① 存储设备
磁盘在现代服务器上通常都是瓶颈。Elasticsearch 重度使用磁盘,你的磁盘能处理的吞吐量越大,你的节点就越稳定。
这里有一些优化磁盘 I/O 的技巧:
1. 使用 SSD。就像其他地方提过的, 他们比机械磁盘优秀多了。
2. 使用 RAID 0。条带化 RAID 会提高磁盘 I/O,代价显然就是当一块硬盘故障时整个就故障了。不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能。
3. 另外使用多块硬盘,并允许 Elasticsearch 通过多个 path.data 目录配置把数据条带化分配到它们上面。
4. 不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰的。
5. 如果你用的是 EC2,当心 EBS。即便是基于 SSD 的 EBS,通常也比本地实例的存储要慢。
内部索引优化

Elasticsearch 为了能快速找到某个 Term,先将所有的 Term 排个序,然后根据二分法查找 Term,时间复杂度为 logN,就像通过字典查找一样,这就是 Term Dictionary。现在再看起来,似乎和传统数据库通过 B-Tree 的方式类似。但是如果 Term 太多,Term Dictionary 也会很大,放内存不现实,于是有了 Term Index。就像字典里的索引页一样,A 开头的有哪些 Term,分别在哪页,可以理解 Term Index是一棵树。这棵树不会包含所有的 Term,它包含的是 Term 的一些前缀。通过 Term Index 可以快速地定位到 Term Dictionary 的某个 Offset,然后从这个位置再往后顺序查找。
在内存中用 FST 方式压缩 Term Index,FST 以字节的方式存储所有的 Term,这种压缩方式可以有效的缩减存储空间,使得 Term Index 足以放进内存,但这种方式也会导致查找时需要更多的 CPU 资源。对于存储在磁盘上的倒排表同样也采用了压缩技术减少存储所占用的空间。
② 调整配置参数
调整配置参数建议如下:
1. 给每个文档指定有序的具有压缩良好的序列模式 ID,避免随机的 UUID-4 这样的 ID,这样的 ID 压缩比很低,会明显拖慢 Lucene。
2. 对于那些不需要聚合和排序的索引字段禁用 Doc values。Doc Values 是有序的基于 document=>field value 的映射列表。
3. 不需要做模糊检索的字段使用 Keyword 类型代替 Text 类型,这样可以避免在建立索引前对这些文本进行分词。
4. 如果你的搜索结果不需要近实时的准确度,考虑把每个索引的 index.refresh_interval 改到 30s 。
5. 如果你是在做大批量导入,导入期间你可以通过设置这个值为 -1 关掉刷新,还可以通过设置 index.number_of_replicas: 0 关闭副本。别忘记在完工的时候重新开启它。
6. 避免深度分页查询建议使用 Scroll 进行分页查询。普通分页查询时,会创建一个 from+size 的空优先队列,每个分片会返回 from+size 条数据,默认只包含文档 ID 和得分 Score 给协调节点。
7. 如果有 N 个分片,则协调节点再对(from+size)×n 条数据进行二次排序,然后选择需要被取回的文档。当 from 很大时,排序过程会变得很沉重,占用 CPU 资源严重。
8. 减少映射字段,只提供需要检索,聚合或排序的字段。其他字段可存在其他存储设备上,例如 Hbase,在 ES 中得到结果后再去 Hbase 查询这些字段。
9. 创建索引和查询时指定路由 Routing 值,这样可以精确到具体的分片查询,提升查询效率。路由的选择需要注意数据的分布均衡。
③ JVM 调优
JVM 调优建议如下:
1. 确保堆内存最小值( Xms )与最大值( Xmx )的大小是相同的,防止程序在运行时改变堆内存大小。
2. Elasticsearch 默认安装后设置的堆内存是 1GB。可通过 ../config/jvm.option 文件进行配置,但是最好不要超过物理内存的50%和超过 32GB。
3. GC 默认采用 CMS 的方式,并发但是有 STW 的问题,可以考虑使用 G1 收集器。
4. Elasticsearch 非常依赖文件系统缓存(FilElasticsearchystem Cache),快速搜索。一般来说,应该至少确保物理上有一半的可用内存分配到文件系统缓存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号