C++ #define,typedef,using用法区别
一.#define
#define 是宏定义命令,宏定义就是将一个标识符定义为一个字符串,源程序中的该标识符均以指定的字符串来代替,是预编译命令,因此会在预编译阶段被执行
1.无参宏定义
无参宏的宏名后不带参数
其定义的一般形式为:
#define 标识符 字符串
其中的“#”表示这是一条预处理命令。凡是以“#”开头的均为预处理命令。“define”为宏定义命令。“标识符”为所定义的宏名。“字符串”可以是常数、表达式、格式串等。
例如:
#define Success 13
这样Success 就被简单的定义为13
带#的都是预处理命令, 预处理命令后通常不加分号。但并不是所有的预处理命令都不能带分号,#define就可以,由于#define只是用宏名对一个字符串进行简单的替换,因此如果在宏定义命令后加了分号,将会连同分号一起进行置换,如:
#define Success 13;
这样也不会报错,只不过Success就被定义为了 13; 既13后面跟一个分号
2.有参宏定义
C++语言允许宏带有参数。在宏定义中的参数称为形式参数,在宏调用中的参数称为实际参数。
对带参数的宏,在调用中,不仅要宏展开,而且要用实参去代换形参。
带参宏定义的一般形式为:
#define 宏名(形参表) 字符串
在字符串中含有各个形参。在使用时调用带参宏调用的一般形式为:宏名(实参表); 如:
#define add(x,y) (x+y) //此处要打括号,不然执行2*add(x,y) 会变成 2*x + y
int main()
{
std::cout << add(9,12) << std::endl;//输出21
return 0;
}这个“函数”定义了加法,但是该“函数”没有类型检查,有点类似模板,但没有模板安全,可以看做一个简单的模板。
#define也可以定义一些简单的函数,但因为只是简单的替换,有时后会发生一些错误,谨慎(不建议)使用,在替换列表中的各个参数最好使用圆括号括起来
4.宏定义中的条件编译
在大规模的开发过程中,头文件很容易发生嵌套包含,而#ifndef 配合 #define ,#endif 可以避免这个问题
#ifndef DATATYPE_H
#define DATATYPE_H
int a = 0;
#endif这里的#ifndef #define #endif 其实和#pragma once 作用类似,都是为了防止多次编译一个头文件
5.跨平台
在大规模的开发过程中,特别是跨平台和系统的软件里,需要用到#define
#ifdef WINDOWS
......
(#else)
......
#endif
#ifdef LINUX
......
(#else)
......
#endif可以在编译的时候通过#define设置编译环境
6.宏定义中的特殊操作符
define 中的特殊操作符有#,## 和 … and __VA_ARGS__
简单来说#,##都是类似于变量替换的功能,这里不赘述
__VA_ARGS__ 是一个可变参数的宏,这个可变参数的宏是新的C99规范中新增的,目前似乎只有gcc支持
实现思想就是宏定义中参数列表的最后一个参数为省略号(也就是三个点)。这样预定义宏__VA_ARGS__就可以被用在替换部分中,替换省略号所代表的字符串,如:
#define PR(...) printf(__VA_ARGS__)
int main()
{
int wt=1,sp=2;
PR("hello\n"); //输出:hello
PR("weight = %d, shipping = %d",wt,sp); //输出:weight = 1, shipping = 2
return 0;
}
这里再介绍几个系统的宏:
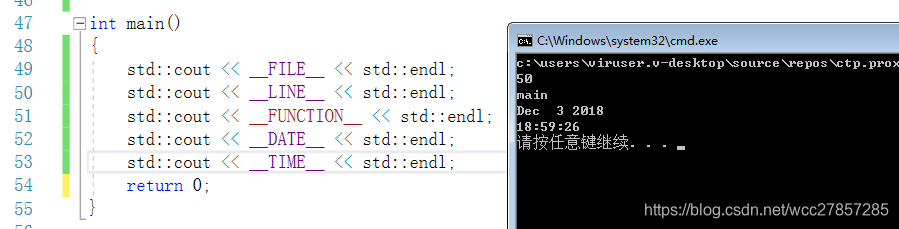
__FILE__ 宏在预编译时会替换成当前的源文件cpp名
__LINE__宏在预编译时会替换成当前的行号
__FUNCTION__宏在预编译时会替换成当前的函数名称
__DATE__:进行预处理的日期(“Mmm dd yyyy”形式的字符串文字)
__TIME__:源文件编译时间,格式微“hh:mm:ss”
这些是在编译器里定义的,所以F12并不能转到定义。在打印日志的时候特别好用。如:
二.typedef
C 语言提供了 typedef 关键字,为现有类型创建一个新的名字。比如人们常常使用 typedef 来编写更美观和可读的代码。所谓美观,意指 typedef 能隐藏笨拙的语法构造以及平台相关的数据类型,从而增强可移植性和以及未来的可维护性。
1.最简单的类型替换
下面的实例为单字节数字定义了一个新类型UBYTE:
typedef unsigned char UBYTE;
在这个类型定义之后,标识符 UBYTE 可作为类型 unsigned char 的缩写,例如:
UBYTE b1, b2;
按照惯例,定义时会大写字母,以便提醒用户类型名称是一个象征性的缩写,但也可以使用小写字母。
2.结构体&自定类型义替换
也可以使用 typedef 来为用户自定义的数据类型取一个新的名字。例如,您可以对结构体使用 typedef 来定义一个新的数据类型名字,然后使用这个新的数据类型来直接定义结构变量,如下:
#include <stdio.h>
#include <string.h>
typedef struct LearningBooks
{
char title[50];
char author[50];
} Book;
int main( )
{
Book book;
strcpy( book.title, "c++");
strcpy( book.author, "kevin");
book.book_id = 0001;
printf( "书标题 : %s\n", book.title);
printf( "书作者 : %s\n", book.author);
return 0;
}
3.typedef函数指针用法
typedef经常用于替换一些复制的函数指针,说到函数指针,就必须先了解一下函数指针和指针函数。了解了之后在来讲typedef
1)指针函数
指针函数是指带指针的函数,即本质是一个函数。函数返回类型是某一类型的指针,声明格式如下:
类型标识 *函数名(参数表)
int *getptr(int x); //声明一个参数为int , 返回值为int * 的 指针函数
首先它是一个函数,只不过这个函数的返回值是一个指针。函数返回值必须用同类型的指针变量来接受,也就是说,指针函数一定有函数返回值,而且,在主调函数中,函数返回值必须赋给同类型的指针变量,如下:
double *getptr(double x) //声明同时定义一个返回值为double* 的指针函数
{
return &x;
};
int main()
{
double *p;
p = getptr(7); //返回double* 赋给p
return 0;
}2)函数指针
函数指针是指向函数地址的指针变量,它的本质是一个指针变量,函数也是有分配内存的,所以指向函数地址的指针,即为函数指针,声明函数指针格式如下:
类型说明符 (*变量名)(参数)
int (*funp) (int x); // 声明一个 指向参数类型为 int ,返回类型为 int 的函数 的 指针
int *(*funp) (int x); // 声明一个 指向参数类型为 int ,返回类型为 int* 的函数 的 指针
其实这里的func不能称为函数名,应该叫做指针的变量名。这个特殊的指针指向一个返回整型值的函数。指针的声明必须和它指向函数的声明保持一致,如:
double (*funp)(double x); // 声明一个 指向参数类型为 int ,返回类型为 int 的函数 的 指针
double *(*funp1)(double x); // 声明一个 指向参数类型为 int ,返回类型为 int* 的函数 的 指针
int main()
{
funp = getnum; //报错,因为类型对不上,右边类型是double *(*)(double x),左边是double(*)(double x)
funp1 = getnum; //正确,两边类型都是double *(*)(double x)
return 0;
}看到这里应该能明白了函数指针的写法,再剖析一遍int (*funp) (int x);这是我的理解:
首先,变量名为funp,而funp左边有个*,代表funp是指针类型,这个*很关键,之前理解不准确,以为这个*是函数返回值,其实这个*是修饰funp本身的,代表funp是指针类型,至于具体是什么指针类型(是int?,char?,还是函数?)要结合整个表达式看,然后再看右边有括号,说明是个函数,这个函数的参数类型为int,既funp是一个指向函数的指针,再看最左边的int,那就说明func是一个指向参数类型为int,返回值为int的函数 的指针。
那么int *(*funp) (int x);就能瞬间秒懂了,funp是一个指向参数类型为int,返回值为int*的函数 的指针
再来看看网上流行的“右左法则”解析:
理解复杂声明可用的“右左法则”:从变量名看起,先往右,再往左,碰到一个圆括号就调转阅读的方向;括号内分析完就跳出括号,还是按先右后左的顺序,如此循环,直到整个声明分析完。还是那个例子:
int (*func)(int *p);
首先找到变量名func,外面有一对圆括号,而且左边是一个*号,这说明func是一个指针;然后跳出这个圆括号,先看右边,又遇到圆括号,这说明(*func)是一个函数,所以func是一个指向这类函数的指针,即函数指针,这类函数具有int*类型的形参,返回值类型是int
再比如:
int (*func[5])(int *);
看到数组了,所以func是一个数组呢还是一个指针呢?先别着急,不妨回顾下数组的定义
int a[10] ; //声明一个int型数组a,a有10个元素 , 这个很简单吧,在进一步
int *a[10] ; //声明一个int*型数组a,a有10个元素
所以这里可以看出来在 int *a[10] ; 中,a[10]是一个整体,*是修饰a[10]的,而不是修饰a的,如果修饰a,那么a就是一个指针了,但实际上a是数组,所以*是修饰a[10]的,意味着a[10]这个数组中的元素类型为指针。这是C++决定的,[]的优先级较高,把a[]当成一个整体来看,也就是说在类似数组的定义中,如:
类型 变量名[数量n]; 类型是用来表示数组元素的,而变量名也就是a本身是一个数组。
那么问题来了?怎么表达一个指向数组的指针呢?怎么越扯越远了........
数组指针(也称行指针)
定义格式如下:
类型 (*变量名)[数量n];
int (*p)[5];
因为()优先级高,所以(*p)代表p是一个指针,指向一个int型的一维数组,这个一维数组的长度是5,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。所以 int (*p)[5]; 的含义是定义一个数组指针,指向含5个元素的一维int型数组。
如要将二维数组赋给一指针,应这样赋值:
int a[3][4]; //定义一个二维int型数组
int (*p)[4]; //定义一个数组指针,指向含4个元素的一维int数组。
p=a; //将该二维数组的首地址赋给p,也就是a[0]或&a[0][0]
p++; //该语句执行过后,也就是p=p+1;p跨过行a[0][]指向了行a[1][]
所以数组指针也称指向一维数组的指针,亦称行指针
好了,回到上面讨论的int (*func[5])(int *);
再来对比
int *a[10] ; //a是一个数组,数组元素类型为int*型指针
int (*func[5])(int *); //func是一个数组,数组元素类型是什么? 看到*应该知道了是指针类型,所以答案应该是某某类型的指针,什么类型的指针呢?
再看完整的右左法则”解析:
func右边是一个[]运算符,说明func是具有5个元素的数组;func的左边有一个*,说明func的元素是指针(注意这里的*不是修饰func,而是修饰func[5]的,原因是[]运算符优先级比*高,func先跟[]结合,把func[]看成一个整体)。跳出这个括号,看右边,又遇到圆括号,说明func数组的元素是函数类型的指针,它指向的函数具有int*类型的形参,返回值类型为int.
所以在分析复制的声明时,优先级很关键()比较高,其次是[],再然后是*
终于扯完了,讲完函数指针,指针函数,数组指针,指针数组了,最后回到我们的typedef上
用typedef来定义这些复杂的类型,比如上面的函数指针,格式为:
typedef 返回类型 (*新类型名) (参数表)
typedef int (*PTRFUN) (int);
typedef char(*PTRFUN)(int); //定义char(*)(int)的函数指针 的别名为PTRFUN
PTRFUN pfun; //直接用别名PTRFUN定义char(*)(int)类型的变量
char getchar(int a) //定义一个形参为int,返回值为char的函数
{
return '1';
}
int main()
{
pfun = getchar; //把函数赋给指针
(*pfun)(5); //用函数指针取函数,调用
return 0;
}这样能简化代码,隐藏难懂的声明类型,方便阅读
三.using
看某些项目源码时,里面使用了很多using关键字。之前对using关键字的概念,一直停留在引入命名空间中。其实,using关键字还些其他的用途。
1.声明命名空间
using namespace std;
2.给类型取别名, 在C++11中提出了通过using指定别名
例如:
using 别名 = 原先类型;
using ty= unsigned char;
以后使用ty value; 就代表 unsigned char value;
这不就跟typedef没啥区别吗,那么using 跟typedef有什么区别呢?哪个更好用些呢?
例如:
typedef std::unique_ptr<std::unordered_map<std::string, std::string>> UPtrMapSS;
而用using:
using UPtrMapSS = std::unique_ptr<std::unordered_map<std::string, std::string>>;
从这个例子中,可能看不出有什么明显的好处,但是从我个人角度,更倾向于using,因为更好理解,但是并没有要强烈使用using的感觉
再来看下:
typedef void (*FP) (int, const std::string&);
这就是上面typedef 函数指针的用法,FP代表着的是一个函数指针,而指向的这个函数返回类型是void,接受参数是int, const std::string&。那么,让我们换成using的写法:
using FP = void (*) (int, const std::string&);
我想,即使第一次读到这样代码,并且不了解using的童鞋也能很容易知道FP是一个别名,using的写法把别名的名字强制分离到了左边,而把别名指向的放在了右边,中间用 = 号等起来,非常清晰
那么,若是从可读性的理由支持using,力度也是稍微不足的。来看第二个理由,那就是举出了一个typedef做不到,而using可以做到的例子:alias templates, 模板别名
template <typename T>
using Vec = MyVector<T, MyAlloc<T>>;
// usage
Vec<int> vec;
这一切都会非常的自然。
那么,若你使用typedef来做这一切:
template <typename T>
typedef MyVector<T, MyAlloc<T>> Vec;
// usage
Vec<int> vec;
当你使用编译器编译的时候,将会得到类似:error: a typedef cannot be a template的错误信息。。
所以我个人认为using和typedef都有各自的用处,并没有谁好谁坏,而标准委员会他们的观点是,在C++11中,鼓励用using,而不用typedef的
最后,p是什么类型
void *(*(*p)[10]) (int*)
答案:
p是个指针,指向一个指针数组,数组的元素是指针,指向 返回值为void*,形参为int*的函数
更深入的理解:https://blog.csdn.net/hai008007/article/details/80651886

 浙公网安备 33010602011771号
浙公网安备 33010602011771号