05-正则表达式 20210311 (一)

正则表达式
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符) 不表示字符字面意义,而表示控制或通配的功能,类似于增强版的通配符功能,但与通配符不同,通配 符功能是用来处理文件名,而正则表达式是处理文本内容中字符
正则表达式被很多程序和开发语言所广泛支持:vim, less,grep,sed,awk, nginx,mysql 等
正则表达式分两类:
1.基本正则表达式:BRE 2.扩展正则表达式:ERE
1.1 字符匹配
. 匹配任意单个字符,可以是一个汉字 [] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z] [^] 匹配指定范围外的任意单个字符,示例:[^wang] [:alnum:] 字母和数字 [:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z [:lower:] 小写字母,示例:[[:lower:]],相当于[a-z] [:upper:] 大写字母 [:blank:] 空白字符(空格和制表符) [:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广) [:cntrl:] 不可打印的控制字符(退格、删除、警铃...) [:digit:] 十进制数字 [:xdigit:]十六进制数字 [:graph:] 可打印的非空白字符 [:print:] 可打印字符 [:punct:] 标点符号
范例:
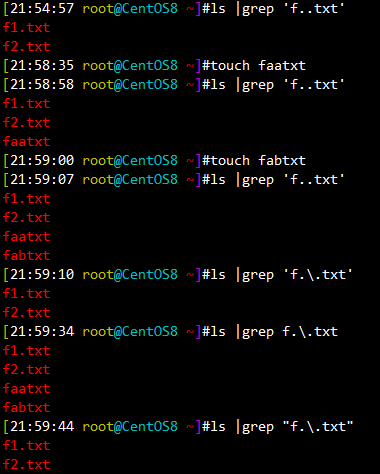
[21:54:57 root@CentOS8 ~]#ls |grep 'f..txt' f1.txt f2.txt [21:58:35 root@CentOS8 ~]#touch faatxt [21:58:58 root@CentOS8 ~]#ls |grep 'f..txt' f1.txt f2.txt faatxt [21:59:00 root@CentOS8 ~]#touch fabtxt [21:59:07 root@CentOS8 ~]#ls |grep 'f..txt' f1.txt f2.txt faatxt fabtxt [21:59:10 root@CentOS8 ~]#ls |grep 'f.\.txt' f1.txt f2.txt [21:59:34 root@CentOS8 ~]#ls |grep f.\.txt f1.txt f2.txt faatxt fabtxt [21:59:44 root@CentOS8 ~]#ls |grep "f.\.txt" f1.txt f2.txt
1.2 匹配次数
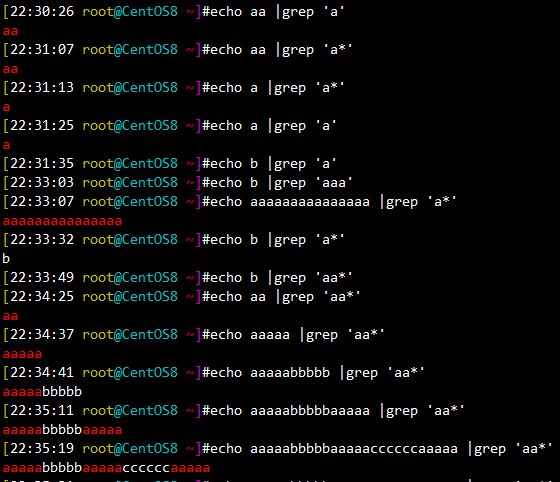
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配,如:a* 表示a出现的任意次
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次,即:可有可无
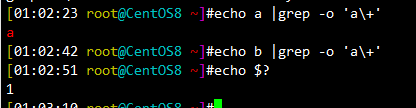
\+ 匹配其前面的字符至少1次,即:肯定有,>=1
\{n\} 匹配前面的字符n次,如:a\{10\}
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次,<=n
\{n,\} 匹配前面的字符至少n次
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配,如:a* 表示a出现的任意次
\? 匹配其前面的字符0或1次,即:可有可无
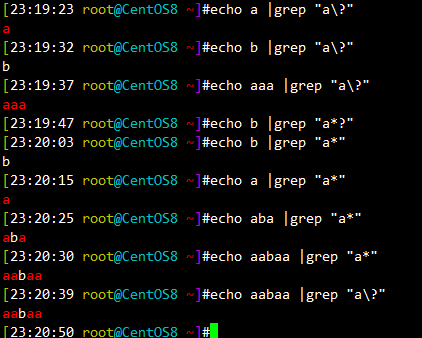
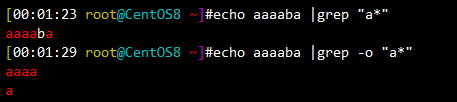
a* 和a\?用法比较:
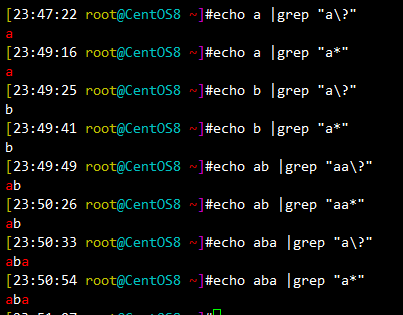
还可以配合使用,grep -o 仅显示匹配到的字符串
\+ 匹配其前面的字符至少1次,即:肯定有,>=1
\{n\} 匹配前面的字符n次,如:a\{10\}
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次,<=n
\{n,\} 匹配前面的字符至少n次

详细演示:
[01:07:25 root@CentOS8 ~]#echo aaaaaaa | grep "a\{7\}"(#前面7个a,符合条件范围,输出值正常) aaaaaaa [01:07:44 root@CentOS8 ~]#echo $?(#判断一下,返回值为0,正确) 0 [01:07:55 root@CentOS8 ~]#echo aaaaaaaaaa | grep "a\{7\}"(#前面超过7个a,输出值也正常) aaaaaaaaaa [01:08:08 root@CentOS8 ~]#echo aaaaaaaaaaaaaaaa | grep "a\{7,10\}"(#前面更多个a,符合条件范围,大于7,小于10,输出值正常) aaaaaaaaaaaaaaaa [01:08:29 root@CentOS8 ~]#echo aaaaaaaaaaaaaaaaaaaaaaaa | grep "a\{7,10\}"(#前面24个a,符合范围,2个10,输出值正常) aaaaaaaaaaaaaaaaaaaaaaaa [01:09:11 root@CentOS8 ~]#echo aaaaaaaaaaaaabaaa | grep "a\{7,10\}" aaaaaaaaaaaaabaaa [01:09:39 root@CentOS8 ~]#echo aaaaaajaaaaaaajaaa | grep "a\{7,10\}"(#中间加入其它字符j分隔后,依然满足条件,7~10之间,这个刚好7个a) aaaaaajaaaaaaajaaa [01:10:03 root@CentOS8 ~]#echo aaaaaajaaaaaajaaa | grep "a\{7,10\}"(#中间加入字符j分隔后,前面只有6个a了,不符合7~10之间的条件) [01:10:09 root@CentOS8 ~]#echo aaaaaajaaaaaajaaa | grep "a\{10\}"(#加入j后分隔了不符合至少大于10的条件,实际最多的只有6个) [01:10:28 root@CentOS8 ~]#echo aaaaaajaaaaaajaaa | grep "a\{,10\}"(#符合至少不多于10的条件,有6个的,也有3个的) aaaaaajaaaaaajaaa [01:10:39 root@CentOS8 ~]#
1.3 位置锚定可以用于定位出现的位置
^ 行首锚定,用于模式的左侧 $ 行尾锚定,用于模式的右侧 ^PATTERN$ 用于模式匹配整行 ^$ 空行 ^[[:space:]]*$ 空白行 \< 或 \b 词首锚定,用于单词模式的左侧 \> 或 \b 词尾锚定,用于单词模式的右侧 \<PATTERN\> 匹配整个单词
[root@CentOS8 ~]# echo aaaaaaaaaaaaaaaaaaaaaaaa | grep "a\{7,10\}"(#未锚定范围,输出了20个a,2个10的a) aaaaaaaaaaaaaaaaaaaaaaaa [root@CentOS8 ~]# echo aaaaaaaaaaaaaaaaaaaaaaaa | grep "\<a\{7,10\}"(#加了\<,位置锚定结束的范围,输出最大不超过10个a) aaaaaaaaaaaaaaaaaaaaaaaa

范例:
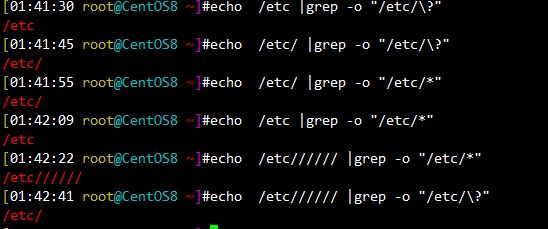
[01:41:30 root@CentOS8 ~]#echo /etc |grep -o "/etc/\?" (#前无/、后\?) /etc [01:41:45 root@CentOS8 ~]#echo /etc/ |grep -o "/etc/\?" (#前有/、后\?,输出/) /etc/ [01:41:55 root@CentOS8 ~]#echo /etc/ |grep -o "/etc/*" (#前有/、后*,输出/) /etc/ [01:42:09 root@CentOS8 ~]#echo /etc |grep -o "/etc/*" (#前无/、后*) /etc [01:42:22 root@CentOS8 ~]#echo /etc////// |grep -o "/etc/*" (#前6个/、后面*,全面输出//////) /etc////// [01:42:41 root@CentOS8 ~]#echo /etc////// |grep -o "/etc/\?" (#前6个、,后面/?,只输出一个/) /etc/
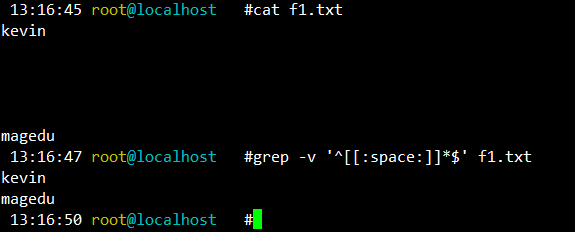
^[[:space:]]*$ 空白行 范例:
grep -v '^[[:space:]]*$' f1.txt
[13:16:45 root@localhost ~]#cat f1.txt kevin magedu [13:16:47 root@localhost ~]#grep -v '^[[:space:]]*$' f1.txt kevin magedu
压缩空白行
[12:59:17 root@localhost ~]#grep -v '^$' /etc/init.d/functions |grep -v '^#'
做如下对比,过滤了空行和#开头的行;
\< 或 \b 词首锚定,用于单词模式的左侧 \> 或 \b 词尾锚定,用于单词模式的右侧
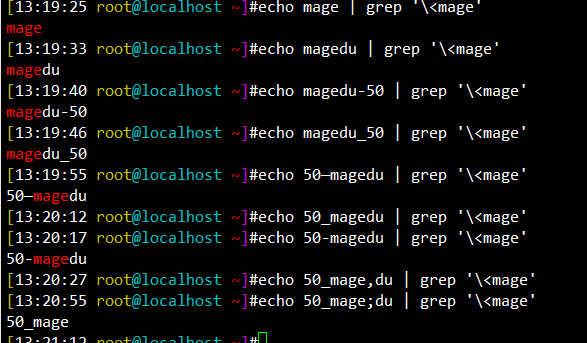
[13:19:25 root@localhost ~]#echo mage | grep '\<mage' mage [13:19:33 root@localhost ~]#echo magedu | grep '\<mage' magedu [13:19:40 root@localhost ~]#echo magedu-50 | grep '\<mage' magedu-50 [13:19:46 root@localhost ~]#echo magedu_50 | grep '\<mage' magedu_50 [13:19:55 root@localhost ~]#echo 50—magedu | grep '\<mage' 50—magedu [13:20:12 root@localhost ~]#echo 50_magedu | grep '\<mage' [13:20:17 root@localhost ~]#echo 50-magedu | grep '\<mage' 50-magedu
1.4.1 分组
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:\(root\)+ 后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名 方式为: \1, \2, \3, ... \1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
范例:
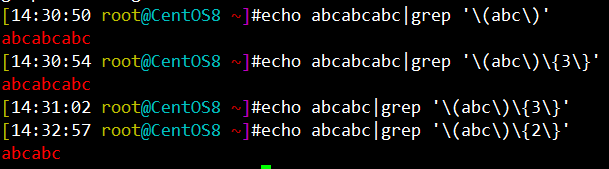
[14:30:50 root@CentOS8 ~]#echo abcabcabc|grep '\(abc\)' abcabcabc [14:30:54 root@CentOS8 ~]#echo abcabcabc|grep '\(abc\)\{3\}' abcabcabc [14:31:02 root@CentOS8 ~]#echo abcabc|grep '\(abc\)\{3\}' [14:32:57 root@CentOS8 ~]#echo abcabc|grep '\(abc\)\{2\}' abcabc
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名 方式为: \1, \2, \3, ...
范例:
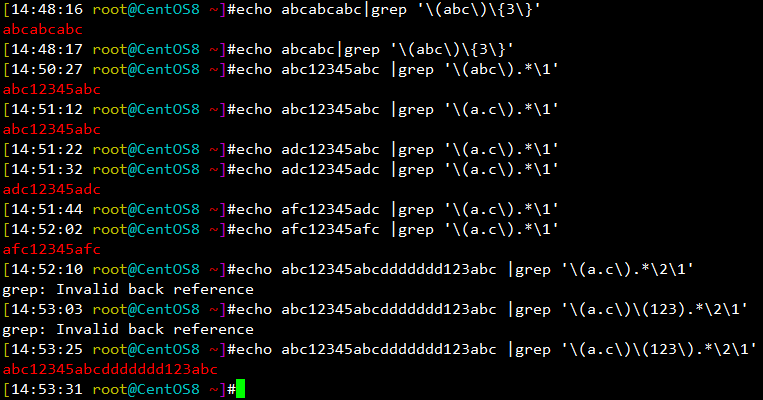
[14:48:16 root@CentOS8 ~]#echo abcabcabc|grep '\(abc\)\{3\}' abcabcabc [14:48:17 root@CentOS8 ~]#echo abcabc|grep '\(abc\)\{3\}' [14:50:27 root@CentOS8 ~]#echo abc12345abc |grep '\(abc\).*\1' abc12345abc [14:51:12 root@CentOS8 ~]#echo abc12345abc |grep '\(a.c\).*\1' abc12345abc [14:51:22 root@CentOS8 ~]#echo adc12345abc |grep '\(a.c\).*\1' [14:51:32 root@CentOS8 ~]#echo adc12345adc |grep '\(a.c\).*\1' adc12345adc [14:51:44 root@CentOS8 ~]#echo afc12345adc |grep '\(a.c\).*\1' [14:52:02 root@CentOS8 ~]#echo afc12345afc |grep '\(a.c\).*\1' afc12345afc [14:53:25 root@CentOS8 ~]#echo abc12345abcddddddd123abc |grep '\(a.c\)\(123\).*\2\1' abc12345abcddddddd123abc
注意: 后向引用 ,引用前面的分组括号中的模式所匹配字符,而非模式本身
用vim打开a.txt文本,使用%s#abc#abcde#g,
或者正则表达式写法 %s#\(abc\)#\1de#g替换内容,
回车后abc变成了abcde
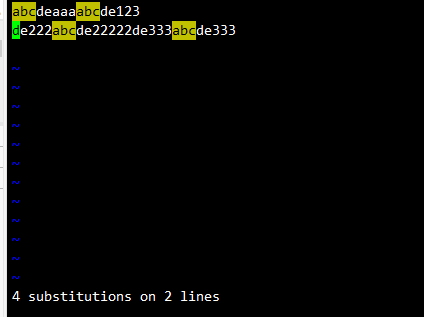
或者这样替换:%s#\(a.c\)#\1de#g替换内容
adc变成了adcde,afc变成了afcde
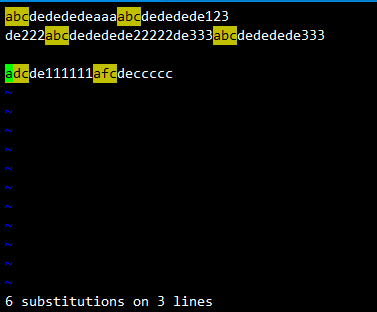
范例:
[16:05:46 root@CentOS8 ~]#echo abc |grep 'a\|b12' abc [16:05:51 root@CentOS8 ~]#echo abc |grep 'b\|b12' abc [16:05:53 root@CentOS8 ~]#echo b12 |grep 'a\|b12' b12 [16:06:29 root@CentOS8 ~]#echo b12 |grep '(a\|b\)12' grep: Unmatched ) or \) [16:07:13 root@CentOS8 ~]#echo b12 |grep '\(a\|b\)12' b12 [16:07:27 root@CentOS8 ~]#echo a12 |grep '\(a\|b\)12' a12
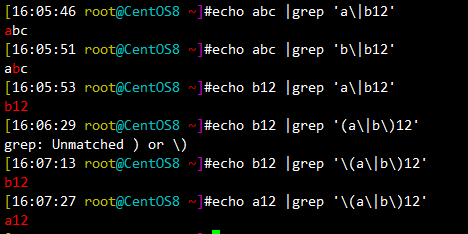
◆学习笔记、仅供参考 ◆


 浙公网安备 33010602011771号
浙公网安备 33010602011771号