
LTS原理分析(version:1.6.9)
LTS做到分布式唯一执行的原理:
LTS采用类似Hadoop作业提交的方式,由JobClient submit作业任务给JobTracker,然后JobTracker会预生成一批作业任务的执行时间记录(落地到MySQL),等到TaskTracker来询问待作业的任务时,将当前待执行的作业任务push到TaskTracker,最后由TaskTracker去执行作业任务。
那么它是如何来保证分布式环境下作业任务的不重不漏呢?
它是借助负载均衡的方式来做的。
JobClient 和 TaskTracker会随机连接JobTracker节点组中的一个节点,实现JobTracker负载均衡。
JobTracker 分发任务时,是优先分配给最空闲的一个TaskTracker节点,实现TaskTracker节点的负载均衡。
这样就保证了待执行的任务在分布式环境下不会重复执行。
LTS任务执行流程:
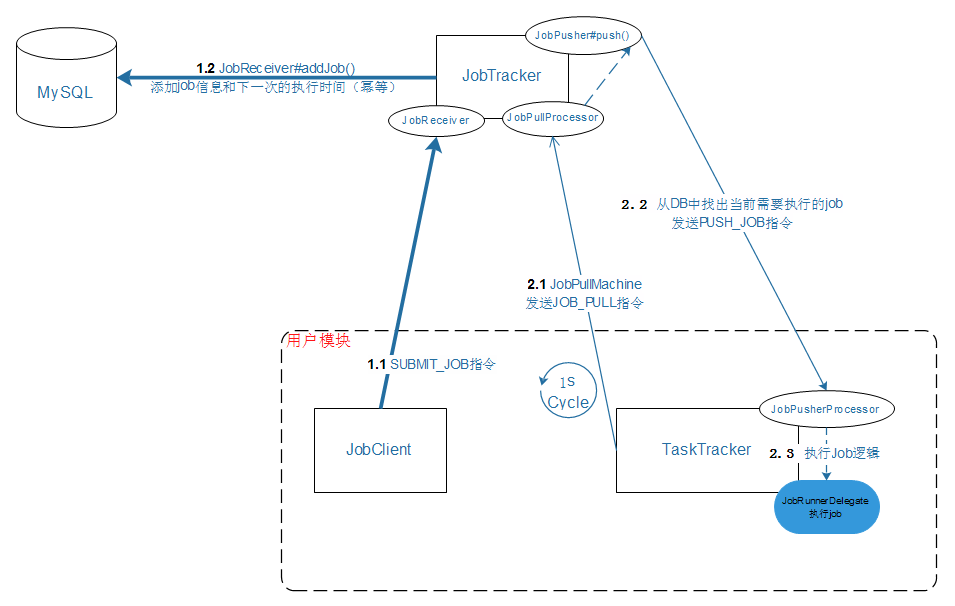
1.1 【JobClient】submit()发起[SUBMIT_JOB]指令给【JobTracker】
1.2 【JobTracker】通过JobReceiver#addJob()将提交的任务添加到数据库。
这个方法是幂等的,所以多个JVM中的JobClient提交任务只会产生一个。
添加到数据库中的数据是job信息与待执行的时间。
Corn Job存放在lts_cron_job_queue表中;Repeat Job的存放在lts_repeat_job_queue中
2.1 【TaskTracker】通过JobPullMachine#ScheduledExecutorService executorService来定时去【JobTracker】中去取待执行的任务。
具体是通过JobPullMachine去发送[JOB_PULL]指令到【JobTracker】
默认频率为:1s;
2.2 【JobTracker】的JobPullProcessor接收到[JOB_PULL]指令后,通过JobPusher#push()去MySQL中取待执行的job记录,并发送[PUSH_JOB]指令将待执行的job记录推送给【TaskTracker】
取数逻辑为:取小于等于前时间的待待执行作业记录
2.3 【TaskTracker】通过JobPushProcessor来处理[PUSH_JOB]指令,最后委托JobRunnerDelegate去执行job
原理图:
附:
JobClient和TaskTracker是部署在一起的
指令集:
com.github.ltsopensource.core.protocol.JobProtos.RequestCode.java
com.github.ltsopensource.core.protocol.JobProtos.ResponseCode.java
com.github.ltsopensource.core.cmd.HttpCmdNames.java
【JobTracker】中的Rpc指令都通过RemotingProcessor来处理:
com.github.ltsopensource.jobtracker.processor.RemotingDispatcher#Map<RequestCode, RemotingProcessor> processors
预加载任务到内存:
List<JobPo> com.github.ltsopensource.queue.AbstractPreLoader#load(String loadTaskTrackerNodeGroup, int loadSize)
JobClient#start()会去连ZK,监测节点变化
架构图:(http://www.tuicool.com/articles/iYr2u2R)

官方架构图:
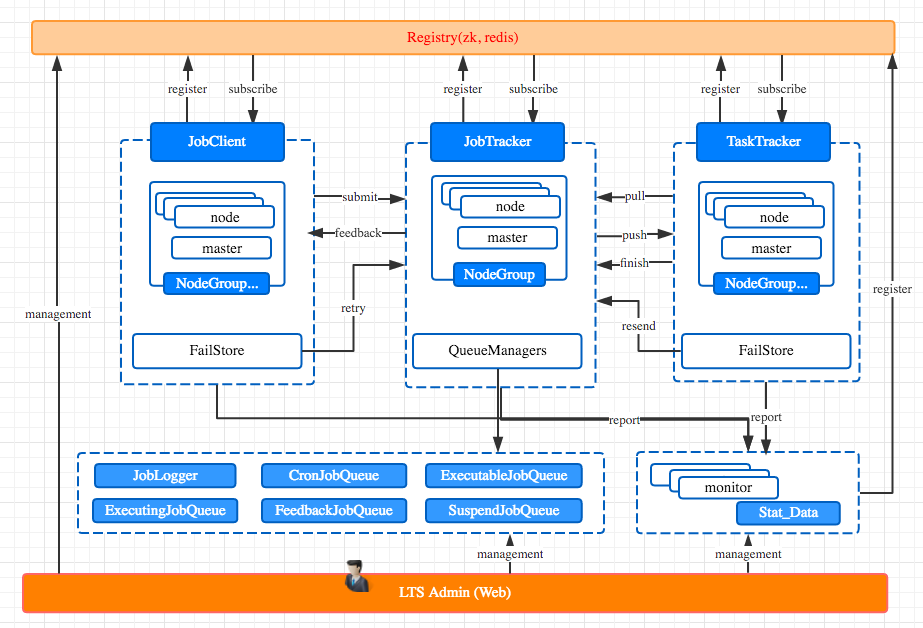
LTS框架内部自己造了很多轮子,采用Hadoop作业的方式去架构的。
代码整洁、封装优雅,值得一看。
但原理比较复杂,如果框架本身出问题了不好定位,不太推荐使用。
备选方案:Elastic-Job、xxl-job
LTS文档及相关文章:
https://my.oschina.net/itnms/blog/631216
http://www.tuicool.com/articles/iYr2u2R
http://www.open-open.com/lib/view/open1414241431434.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号