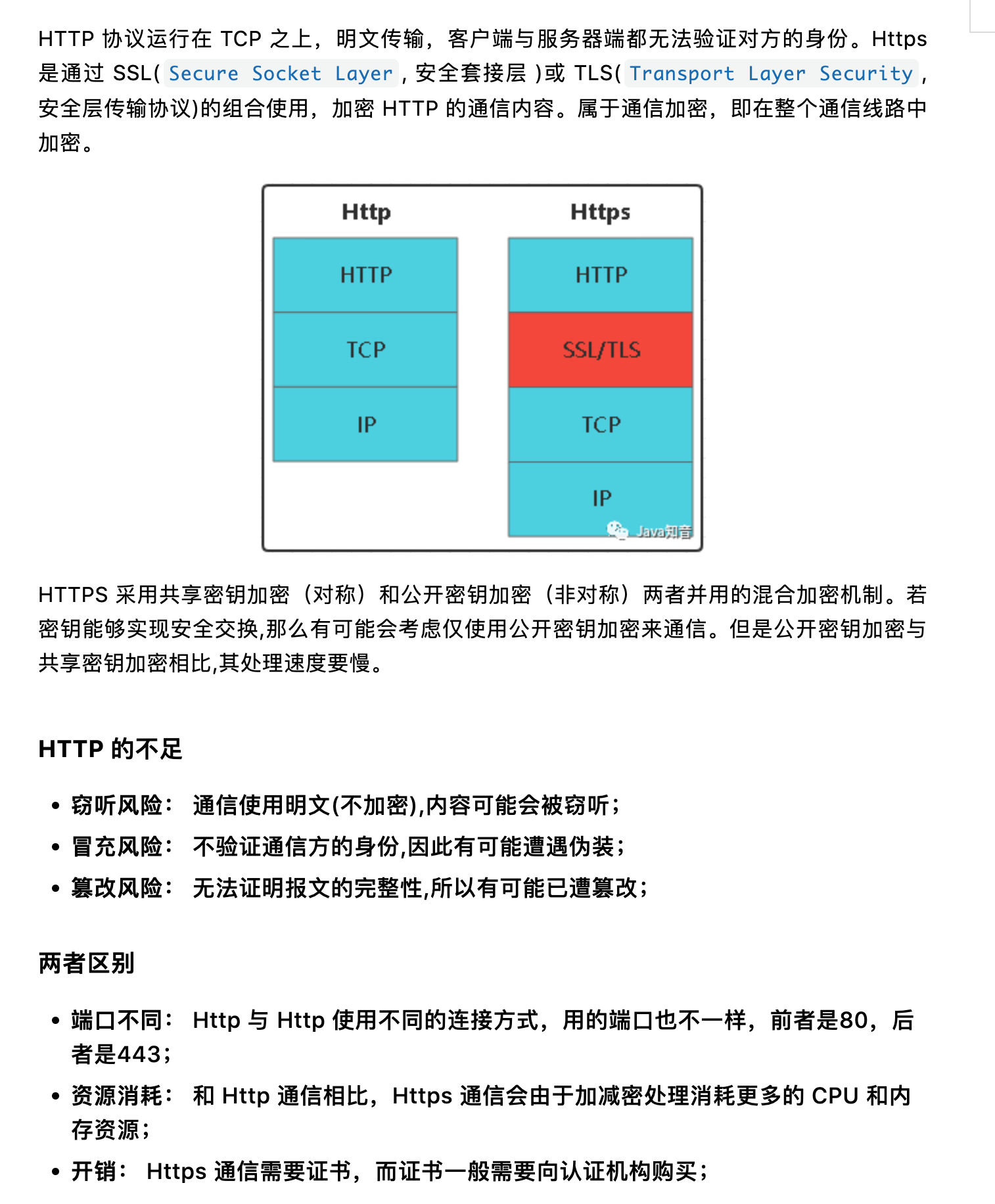
ms
1. 分布式锁
http://www.hollischuang.com/archives/1716
http://www.cnblogs.com/green-hand/p/5687611.html
分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。
我们需要的分布式锁应该是怎么样的?(这里以方法锁为例,资源锁同理)
可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
这把锁要是一把可重入锁(避免死锁)
这把锁最好是一把阻塞锁(根据业务需求考虑要不要这条)
有高可用的获取锁和释放锁功能
获取锁和释放锁的性能要好
ZK分布式锁(使用临时有序节点 。顺序值由master节点来分配?)
在 ZooKeeper 中,节点类型可以分为持久节点(PERSISTENT )、临时节点(EPHEMERAL),以及时序节点(SEQUENTIAL ),具体在节点创建过程中,一般是组合使用,可以生成 4 种节点类型:持久节点(PERSISTENT),持久顺序节点(PERSISTENT_SEQUENTIAL),临时节点(EPHEMERAL),临时顺序节点(EPHEMERAL_SEQUENTIAL);
使用Zookeeper 可以使用临时节点来实现分布式锁,不存在锁的续租问题
Redis分布式锁 (setNX + expire + getSet), watch dog 定时检查锁并续租。可重入性通过 key 里面的 value 值累加来实现。(Redission, 30s 的过期时间,10s 定期检查续租一次)
锁的可重入性都可以通过 ThreadLocal 变量来实现,第一次加锁要往 Redis (或 zk)中写入锁的 key,同一个线程第二次(或第n次)加锁,就将 ThreadLocal 变量的值进行累加,每次释放锁都将值进行递减,直到减少到 0 就将 Redis (或 zk)中的 key 进行删除。(与 spring 实现多个事务注解嵌套的方式类似)
选用不同的组件去实现的差别在于怎么解决死锁和锁的续租问题
Redis 是 AP模型,做分布式锁不完全可靠。
Zookeeper 是 CP 模型,更适合做分布式锁?
BASE理论是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency)。
当网络由于发生异常情况,导致分布式系统中部分节点之间的网络延时不断增大,最终导致组成分布式系统的所有节点中,只有部分节点之间能够正常通信,而另一些节点则不能----我们将这个现象称为网络分区。当网络分区出现时,分布式系统会出现局部小集群,在极端情况下,这些局部小集群会独立完成原本需要整个分布式系统才能完成的功能,包括对数据的事务处理,这就对分布式一致性提出了非常大的挑战
2. 数据库
内连、左连、右连、全连
oracle minus 集合操作
in(, , , ) exist


select * from ( select 1 as id, 'a' as name from dual union select 2 as id, 'b' as name from dual ) t1 left join ( select 1 as id, 'a' as name from dual union select 3 as id, 'c' as name from dual ) t2 on t1.id = t2.id 结果: ID NAME ID NAME 1 a 1 a 2 b
3. BIO、NIO
https://my.oschina.net/u/658658/blog/521016
http://www.importnew.com/22623.html
4. 短连接、长连接
dubbo(长连接 netty, socket)
HTTP的长连接和短连接本质上是TCP长连接和短连接。HTTP属于应用层协议,在传输层使用TCP协议,在网络层使用IP协议。IP协议主要解决网络路由和寻址问题,TCP协议主要解决如何在IP层之上可靠的传递数据包,使在网络上的另一端收到发端发出的所有包,并且顺序与发出顺序一致。TCP有可靠,面向连接的特点。
http://www.cnblogs.com/0201zcr/p/4694945.html
5. spring scope
默认是单例模式,即scope="singleton"。另外scope还有prototype、request、session、global session作用域。
6. netty
netty 高性能的原因:
1. NIO
2. reactor 线程模型
3. 零拷贝
4. 串行无锁化
在 NioEventLoop.java 里面有很多 inEventLoop(thread) 的判断,如果不在当前 eventLoop 里面,就会丢到 taskQueue 中,taskQueue 中的任务是串行执行的,也就是我们说的串行无锁化。

https://www.jianshu.com/p/8a7519c8997d
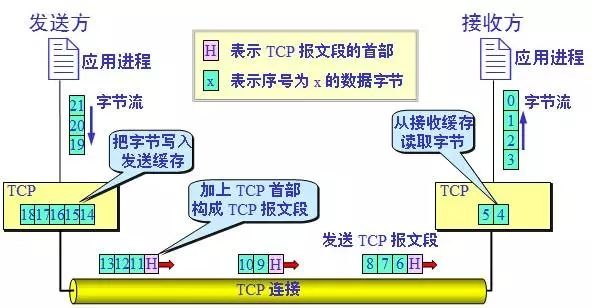
粘包:通过协议约定,比如指定数据包的size来切分消息。
为什么会发生TCP粘包、拆包
1. 应用程序写入的数据大于套接字缓冲区大小,这将会发生拆包。
2. 应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包。
3. 进行MSS(最大报文长度)大小的TCP分段,当TCP报文长度-TCP头部长度>MSS的时候将发生拆包。
4. 接收方法不及时读取套接字缓冲区数据,这将发生粘包。
如何处理粘包、拆包,通常会有以下一些常用的方法:
1. 使用带消息头的协议、消息头存储消息开始标识及消息长度信息,服务端获取消息头的时候解析出消息长度,然后向后读取该长度的内容。
2. 设置定长消息,服务端每次读取既定长度的内容作为一条完整消息,当消息不够长时,空位补上固定字符。
3. 设置消息边界,服务端从网络流中按消息编辑分离出消息内容,一般使用‘\n’。
4. 更为复杂的协议,例如楼主最近接触比较多的车联网协议808,809协议。
https://www.hchstudio.cn/article/2018/d5b3/

netty 题目 https://www.cnblogs.com/duan2/p/8819910.html
7. logback MDC 在spring异步@Async使用线程池时,值取到旧值问题
http://forum.spring.io/forum/spring-projects/container/129674-async-with-log4j-s-mdc
https://moelholm.com/2017/07/24/spring-4-3-using-a-taskdecorator-to-copy-mdc-data-to-async-threads/ (sprint boot 中使用这个)
8. stream <--> channel + buffer
9. 数据库事务隔离级别 (http://www.cnblogs.com/fjdingsd/p/5273008.html)
read uncommitted --> read committed --> repeatable read --> Serializable
脏读 不可重复读 幻读
MySQL 默认 repeatable read
https://dev.mysql.com/doc/refman/5.6/en/innodb-transaction-isolation-levels.html#isolevel_repeatable-read
https://dev.mysql.com/doc/refman/5.6/en/innodb-consistent-read.html
Oracle 默认 read committed
10. 雪崩
http://www.2cto.com/os/201508/433330.html
1。 缓存Cache在A服务上,找不到缓存去B服务查库
雪崩可能原因:a. A服务挂了,重启时缓存全部被清空,导致流量全部到B服务
b. B服务挂了导致缓存过期,B重启后流量全部到B
2。缓存Cache在A服务上,找不到Cache通过A去查库
3。缓存Cache单独部署 + A服务
关键词:雪崩、缓存击穿、过载保护、缓存预热、限流、服务降级
11. vilatile http://www.importnew.com/24082.html
Java内存模型:主内存、工作内存
并发编程的三大概念:原子性,有序性,可见性
volatile保证可见性。实现原理:通过向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写会到系统内存。
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
volatile不能确保原子性
解决方案:可以通过synchronized或lock,进行加锁,来保证操作的原子性。也可以通过AtomicInteger。
volatile保证有序性。实现原理:Lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面。
volatile的变量在被操作的时候不会产生working memory的拷贝,而是直接操作main memory,当然volatile虽然解决了变量的可见性问题,但没有解决变量操作的原子性的问题,这个还需要synchronized或者CAS相关操作配合进行。
12. Java泛型(http://www.importnew.com/24029.html)
T、 泛型通配符(?)、 ? extends T、 ? super T、 类型擦除
“Producer Extends” – 如果你需要一个只读List,用它来produce T,那么使用 ? extends T。
“Consumer Super” – 如果你需要一个只写List,用它来consume T,那么使用 ? super T。
如果需要同时读取以及写入,那么我们就不能使用通配符了。
如何阅读过一些Java集合类的源码,可以发现通常我们会将两者结合起来一起用,比如像下面这样:
public class Collections { public static <T> void copy(List<? super T> dest, List<? extends T> src) { for (int i=0; i<src.size(); i++) dest.set(i, src.get(i)); } }
类型擦除:

13. 正向代理 反向代理 (http://blog.csdn.net/m13666368773/article/details/8060481)
正向代理:位于客户端和原始服务器(origin server)之间的服务器,客户端必须要进行一些特别的设置才能使用正向代理。允许客户端通过它访问任意网站并且隐藏客户端自身
反向代理:对外都是透明的,对于客户端而言它就像是原始服务器,访问者并不知道自己访问的是一个代理,并且客户端不需要进行任何特别的设置。反向代理还可以为后端的多台服务器提供负载平衡,或为后端较慢的服务器提供缓冲服务。(nginx反向代理,动静分离)
14. 高可用(HA)架构
http://aokunsang.iteye.com/blog/2053719 浅谈web应用的负载均衡、集群、高可用(HA)解决方案
http://zhuanlan.51cto.com/art/201612/524201.htm 互联网架构“高可用”
http://www.blogjava.net/ivanwan/archive/2013/12/25/408014.html LVS/Nginx/HAProxy负载均衡器的对比分析
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
方法论上,高可用是通过 冗余(集群化) + 自动故障转移(failover)来实现的。
虚拟IP(VirtualIP/VIP): 实现原理主要是靠TCP/IP的ARP协议。 http://blog.csdn.net/whycold/article/details/11898249
常见的Tomcat集群方案:ngnix+tomcat;lvs+ngnix+tomcat;(lvs负责集群调度,nginx负责静态文件处理,tomcat负责动态文件处理[最优选择])。
15. 分布式环境下的 黏性Session 和 非黏性Session
16. 六大设计原则 http://blog.csdn.net/cq361106306/article/details/38708967
https://www.cnblogs.com/virusolf/p/5764872.html
单一职责原则
里氏替换原则
依赖倒置原则
接口隔离原则
迪米特法则
开闭原则
(约定优于配置)
单一职责原则告诉我们实现类要职责单一;
里氏替换原则告诉我们不要破坏继承体系;
依赖倒置原则告诉我们要面向接口编程;
接口隔离原则告诉我们在设计接口的时候要精简单一;
迪米特法则告诉我们要降低耦合。
而开闭原则是总纲,他告诉我们要对扩展开放,对修改关闭。
17. 浏览器与服务器交互的过程
http://www.cnblogs.com/xdp-gacl/p/3734395.html

18. 线程的状态和生命周期
http://blog.csdn.net/lonelyroamer/article/details/7949969

19. java.util.concurrent.atomic.AtomicXXX
其内部实现不是简单的使用synchronized,而是一个更为高效的方式CAS (compare and swap) + volatile和native方法,从而避免了synchronized的高开销,执行效率大为提升。
CAS指令在Intel CPU上称为CMPXCHG指令,它的作用是将指定内存地址的内容与所给的某个值相比,如果相等,则将其内容替换为指令中提供的新值,如果不相等,则更新失败。
从内存领域来说这是乐观锁,因为它在对共享变量更新之前会先比较当前值是否与更新前的值一致,如果是,则更新,如果不是,则无限循环执行(称为自旋锁),直到当前值与更新前的值一致为止,才执行更新。
20. 线程池
ThreadPoolExecutor、AbstractExecutorService、ExecutorService和Executor
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) 各个参数的含义
Java通过Executors提供四种线程池,分别为:
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
http://ifeve.com/java-threadpool/
https://www.cnblogs.com/aspirant/p/6920418.html
http://www.importnew.com/19011.html
public ThreadPoolExecutor(int corePoolSize, // 核心线程数,长驻线程池。 the number of threads to keep in the pool, even if they are idle, unless allowCoreThreadTimeOut is set int maximumPoolSize, // 最大线程数:线程池中允许的最大线程数 long keepAliveTime, // 超过核心线程数(corePoolSize )的【空闲】线程允许存活的时间。 @NotNull TimeUnit unit, @NotNull BlockingQueue<Runnable> workQueue, // task持有队列 @NotNull ThreadFactory threadFactory, @NotNull RejectedExecutionHandler handler) // 拒绝任务策略(当任务数超过线程池的处理能力时起作用)
一个线程池可以处理的最大任务数为: maximumPoolSize + workQueue.size()
ThreadPoolExecutor#execute()
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); /* * Proceed in 3 steps: * * 1. If fewer than corePoolSize threads are running, try to * start a new thread with the given command as its first * task. The call to addWorker atomically checks runState and * workerCount, and so prevents false alarms that would add * threads when it shouldn't, by returning false. * * 2. If a task can be successfully queued, then we still need * to double-check whether we should have added a thread * (because existing ones died since last checking) or that * the pool shut down since entry into this method. So we * recheck state and if necessary roll back the enqueuing if * stopped, or start a new thread if there are none. * * 3. If we cannot queue task, then we try to add a new * thread. If it fails, we know we are shut down or saturated * and so reject the task. */ int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) reject(command); }
1. 当线程池中的线程数少于 corePoolSize 时,就新起一个线程来执行 task
2. 当线程池中的线程数大于 corePoolSize 时,就将 task 添加到 queue 中
3. 当 workQueue 满了之后,就新起一个线程来执行 task
也就是说:在 workQueue 没有满时,线程池中的线程数最多为 corePoolSize 个。(已测试验证)
21. zookeeper 选举算法
zookeeper 如何保证一致性
http://blog.csdn.net/liuhaiabc/article/details/70771322
22. 安全
XSS ------ Filter进行特殊字符(<script>)过滤
CSRF ------- 更新数据时,使用POST请求并且携带token
SQL注入 ------- Filter进行特殊字符(;)过滤
23. Socket三次握手、四次挥手
http://www.cnblogs.com/Jessy/p/3535612.html
首先,我们要知道TCP是全双工的,即客户端在给服务器端发送信息的同时,服务器端也可以给客户端发送信息。而半双工的意思是A可以给B发,B也可以给A发,但是A在给B发的时候,B不能给A发,即不同时,为半双工。 单工为只能A给B发,B不能给A发; 或者是只能B给A发,不能A给B发。
https://www.cnblogs.com/zhuzhenwei918/p/7465467.html 为什么不是两次握手,而是三次
https://www.cnblogs.com/huhuuu/p/3572485.html
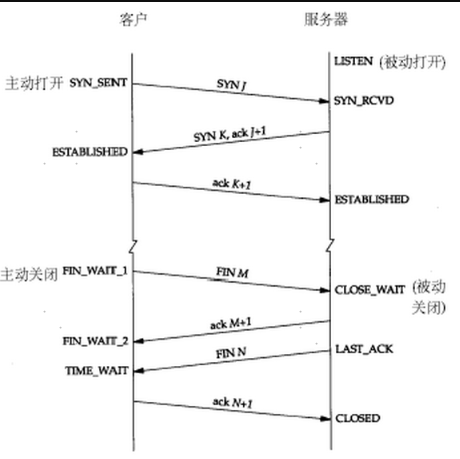
24. 分布式 id 生成器
百度uid生成器:https://github.com/baidu/uid-generator
美团点评生成器:http://tech.meituan.com/MT_Leaf.html
25. 消息队列的顺序性和重复消费问题
消息队列的顺序性:消息投递到同一个消息服务器的同一个消息队列Q1,只有一个消费者消费Q1
重复消息:消费者接口幂等
RocketMQ支持事务消息:http://blog.csdn.net/u012422829/article/details/70248286
(做本地事务前发送prepared消息,本地事务完成后发送确认消息。如果确认消息发送失败,RocketMQ会检查prepared消息,然后回调业务系统确认业务是否成功)
事务消息:解决业务做成功了,发送消息失败的问题(可靠MQ)。
也可以通过在业务系统中建一张消息发送队列表来解决,业务事务与发送消息放在同一个事务中
26. Redis、Memcache 一致性hash算法
一致性 hash 解决的问题:
在缓存场景中,当集群中加入 1 台机器后,这台机器要能够分摊其他机器的流量和缓存数据,简单的取模方式去路由和普通 hash 环是行不通的,一致性 hash 引入了虚拟节点,就可以做到了
新增节点对数据的影响比例为:(一致性 hash 的节点是均匀分布的)
3台 --> 4台 = 1/4
n-1台 --> n台 = 1/n
27. happen-before规则
出现线程安全的问题一般是因为主内存和工作内存数据不一致性和重排序导致的
在执行程序时,为了提高性能,编译器和处理器常常会对指令进行重排序。
对于主内存和工作内存的“脏读”问题,可以通过同步机制(控制不同线程间操作发生的相对顺序)来解决或者通过volatile关键字使得每次volatile变量都能够强制刷新到主存,从而对每个线程都是可见的。
针对编译器重排序,JMM的编译器重排序规则会禁止一些特定类型的编译器重排序;针对处理器重排序,编译器在生成指令序列的时候会通过插入内存屏障指令来禁止某些特殊的处理器重排序。
JMM其实是在遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。
28. Dubbo的Consumber 和 Provider 在不同的线程组中,为什么可以使用 ThreadLocal(RpcContext) 来保存微服务的上下文?
因为 Consumber 调用 Provider 时,会将 RpcContext 往 Provider 端传递,并且在 Provider 端进行反序列化,这样就可以做到了。
29. Socket 调用可以像普通的方法调用一样准确的拿到返回值吗?
不能,因为接收返回消息时,不能确切的知道返回的是哪个请求的结果。所以,需要在发出请求时,将请求打上标记(唯一id),返回结果时,带上这个标记。就像 Dubbo 一样。
(短连接是可以的,nio长连接就可能会串)
那 http 1.1 也是基于 tcp ,当 keep-alive=true(长连接)时,为什么就可以做到在同一个 channel 通道中发多个请求时,返回结果不串呢?
因为:http 1.1 协议规定 server 发送返回报文的顺序必须与接收请求的顺序相同。这样先发的请求就能先收到返回,在不需要知道请求 id 的情况下,也能正确处理响应了
https://tools.ietf.org/html/rfc2616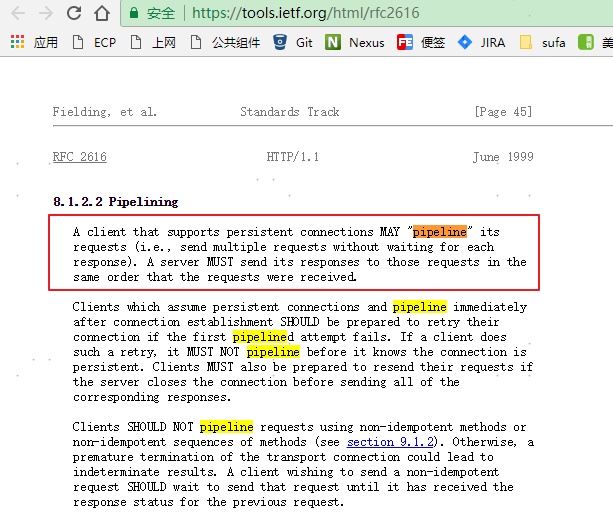
30. dubbo 按权重随机算法 https://blog.csdn.net/danny_idea/article/details/82258367
31. spring 如何解决循环依赖?
spring 通过对 bean 的早期引用(early reference)进行缓存,在预到循环依赖的bean 初始化时,取早期引用缓存进行注入
http://www.imooc.com/article/34150
深度分析 :
https://blog.csdn.net/f641385712/article/details/92801300
https://blog.csdn.net/f641385712/article/details/92797058
https://blog.csdn.net/f641385712/article/details/93475774
32. 限流算法
在开发高并发系统时,有三把利器用来保护系统:缓存、降级和限流。
a. 固定窗口
b. 滑动窗口
c. 漏桶
d. 令牌桶
https://www.cnblogs.com/linjiqin/p/9707713.html
https://blog.csdn.net/linhui258/article/details/81155622
https://www.jianshu.com/p/9f7df2ebbb82
33. 为什么 jdk 动态代理要基于接口来产生代理?
因为 jdk 底层生成的代理类会继承 Proxy 类,如果 jdk 基于实体类生成代理类的话,就会破坏 java 不能多继承的原则(java 不能多继承),所以 jdk 动态代理不能基于实体类来产生代理了,只能基于接口来产生代理。
(读 java.lang.reflect.Proxy.newProxyInstance() 源码,将代理类的字节码反编译可以看出来)
34. 阅读 spring 源码的技巧:
spring 源码非常复杂,如果一行一行读,会迷失在源码中。
举个例子,比如想知道 spring 在哪里产生 aop 代理对象的,可以在 org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#addSingleton() 上打个断点。
断点要使用条件断点(因为 spring 里面的 bean 非常多),比如 ServiceA 最后是一个代理对象的话,那么条件断点使用 beanName.equals("serviceA")
那么,为什么要将断点打在这里?
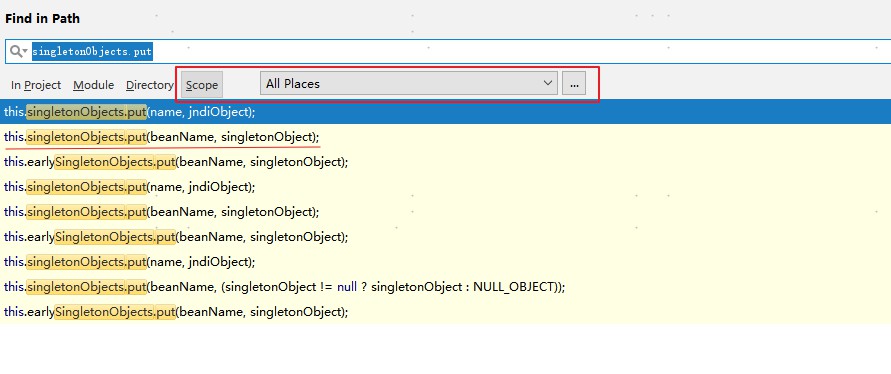
因为,spring 中所有的 bean 初始化完成后,都会添加到 DefaultSingletonBeanRegistry.singletonObjects 属性中。同样,产生的代理 bean 最后也会放到 singletonObjects 中,所以我们要找到在哪里调用的 singletonObjects.put() 方法。
在 idea 中使用 ctrl+shift+f 来全局搜索 singletonObjects.put 调用的地方,最后就找到了是 DefaultSingletonBeanRegistry#addSingleton() 方法。
最后再通过调用堆栈来查看代理对象具体是在哪里产生的。
35. spring 什么情况下使用 cglib 代理,什么时候使用 jdk 动态代理?
proxyTargetClass 默认是 false
1. 当 proxyTargetClass = false 时,默认使用 jdk 动态代理。如果被代理的类没有实现接口,则使用 cglib 代理。
2. 当 proxyTargetClass = true 时,spring 会使用 cglib 代理。
org.springframework.aop.framework.DefaultAopProxyFactory.createAopProxy
1 public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException { 2 if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) { 3 Class<?> targetClass = config.getTargetClass(); 4 if (targetClass == null) { 5 throw new AopConfigException("TargetSource cannot determine target class: " +"Either an interface or a target is required for proxy creation."); 6 } 7 if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) { 8 return new JdkDynamicAopProxy(config); 9 } 10 return new ObjenesisCglibAopProxy(config); 11 } 12 else { 13 return new JdkDynamicAopProxy(config); 14 } 15 }
从源码看, proxyTargetClass=true 时,如果 targetClass 是接口 or targetClass 是一个代理类型,也有可能走 jdk 动态代理。但是绝大多数情况是不会的。
首先,在源码中找到 targetClass 赋值的地方,可以发现 targetClass 是 bean 的实例的 class,所以通常是一个实体类,不是接口。至于 targetClass 什么时候会是代理类,还不太清楚。
那既然 targetClass 是 bean 的实例的 class 的话,它并不是一个接口,那么当 proxyTargetClass=false 的时候, jdk 怎么来产生代理呢?
答案是,spring 会找到 targetClass 对应的接口来生成代理,如果这个类没有接口的话,会将 proxyTargetClass 设置成 true,从而使用 cglib 来生成代理
spring 产生代理对象是在 populateBean() 之后的 initializeBean()。
initializeBean() --> org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator.postProcessAfterInitialization()
小技巧:在 IDEA 中,ctrl+shift+f 全局搜索 populateBean,就可以快速找到源码所在的地方
36. Spring 中可以定义枚举类型的 bean 吗?
不可以,因为 Spring 实例化 bean 时会使用反射调用类的构造函数,而枚举类型是不能使用构造函数来实例化的。所以即使将枚举类打上 @Service 注解也是不行的。
37. 数据库分区、分片(分库、分表)
分区:分区表就是把一张表分开,在逻辑上分区表还是一张表,但是在物理上它是由多个物理子表组成。
http://baijiahao.baidu.com/s?id=1655581234130331974&wfr=spider&for=pc
分区的方式:range分区、list分区、hash分区、复合分区等
create table t1( id int not null, score int ) partion by range (score) ( partion s1 values less than(60), partion s2 values less than(80), partion s3 values less than(90), partion s4 values less than(maxvalue), ); # 删除分区 alter table t1 drop partion s2;
分片:把数据分割为一个小片或者一块,然后存储到不同的节点上。分片的方案有:分库或者分表
1. 分库:可以突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。
2. 分表:能够解决单表数据量过大带来的查询效率下降的问题,但是无法给数据库的并发处理能力带来质的提升。
分库分表的问题:
1. 跨库事务
2. 跨库 join
3. 聚合函数、跨库分页等
https://blog.51cto.com/net881004/2109383
38. BeanFactory 创建的过程中为什么要加锁?
(只要涉及到锁,必定会涉及到对共享变量的操作)
bean 加载的过程中涉及到很多共享变量的操作,为了防止并发问题,所以需要加锁,例如:
1 //org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#addSingleton() 2 protected void addSingleton(String beanName, Object singletonObject) { 3 synchronized (this.singletonObjects) { 4 this.singletonObjects.put(beanName, singletonObject); 5 this.singletonFactories.remove(beanName); 6 this.earlySingletonObjects.remove(beanName); 7 this.registeredSingletons.add(beanName); 8 } 9 } 10 11 //org.springframework.beans.factory.support.DefaultListableBeanFactory#registerSingleton() 12 // Cannot modify startup-time collection elements anymore (for stable iteration) 13 synchronized (this.beanDefinitionMap) { 14 if (!this.beanDefinitionMap.containsKey(beanName)) { 15 Set<String> updatedSingletons = new LinkedHashSet<>(this.manualSingletonNames.size() + 1); 16 updatedSingletons.addAll(this.manualSingletonNames); 17 updatedSingletons.add(beanName); 18 this.manualSingletonNames = updatedSingletons; 19 } 20 }
39. 长轮询(Long Polling)
说到Long Polling(长轮询),必然少不了提起Polling(轮询),这都是拉模式的两种方式。
Polling是指不管服务端数据有无更新,客户端每隔定长时间请求拉取一次数据,可能有更新数据返回,也可能什么都没有。
Long Polling原理也很简单,相比Polling,客户端发起Long Polling,此时如果服务端没有相关数据,会hold住请求,直到服务端有相关数据,或者等待一定时间超时才会返回。返回后,客户端又会立即再次发起下一次Long Polling。这种方式也是对拉模式的一个优化,解决了拉模式数据通知不及时,以及减少了大量的无效轮询次数。(所谓的hold住请求指的服务端暂时不回复结果,保存相关请求,不关闭请求连接,等相关数据准备好,写会客户端。)
https://www.jianshu.com/p/d3f66b1eb748?from=timeline&isappinstalled=0
40. 序列化方式对比
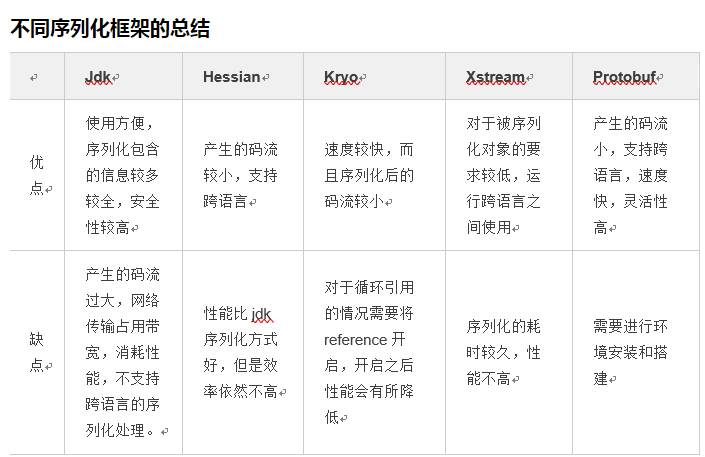
41. mysql 半同步复制
- 对于异步复制,主库将事务Binlog事件写入到Binlog文件中,此时主库只会通知一下Dump线程发送这些新的Binlog,然后主库就会继续处理提交操作,而此时不会保证这些Binlog传到任何一个从库节点上。
- 对于全同步复制,当主库提交事务之后,所有的从库节点必须收到,APPLY并且提交这些事务,然后主库线程才能继续做后续操作。这里面有一个很明显的缺点就是,主库完成一个事务的时间被拉长,性能降低。
- 对于半同步复制,是介于全同步复制和异步复制之间的一种,主库只需要等待至少一个从库节点收到并且Flush Binlog到Relay Log文件即可,主库不需要等待所有从库给主库反馈。同时,这里只是一个收到的反馈,而不是已经完全执行并且提交的反馈,这样就节省了很多时间。
https://www.cnblogs.com/zero-gg/p/9057092.html
42. 分布式一致性算法-Paxos、Raft、ZAB、Gossip
https://zhuanlan.zhihu.com/p/130332285
ZAB( Zookeeper Atomic Broadcast) 原子广播协议
- 说明:ZAB也是对Multi Paxos算法的改进,大部分和raft相同
- 和raft算法的主要区别:
- 对于Leader的任期,raft叫做term,而ZAB叫做epoch
- 在状态复制的过程中,raft的心跳从Leader向Follower发送,而ZAB则相反。
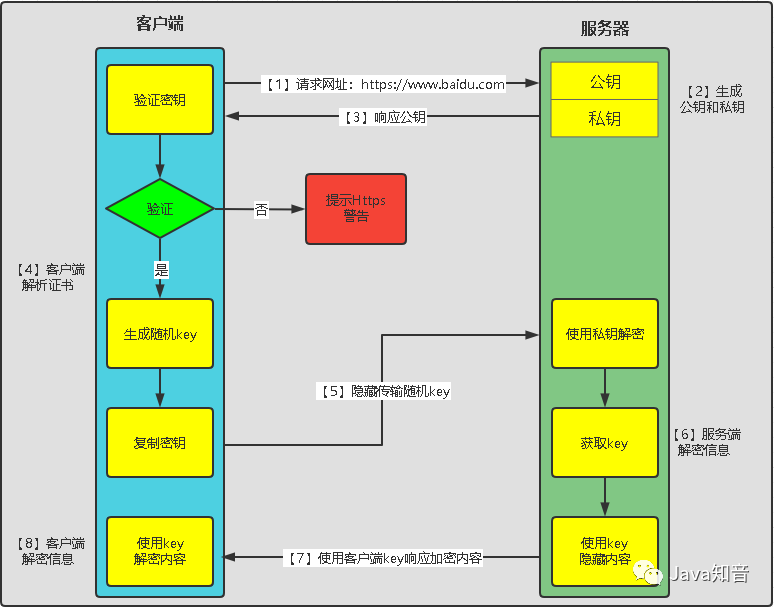
43. https 的工作原理