

利用python检测单词的相似度
百度了一下,似乎都不太复杂,我选择了两个不需要安装第三方组件的例子,地址分别如下
https://www.sohu.com/a/139947378_797291
https://zhuanlan.zhihu.com/p/268410388
整合了两个例子,我认为我找到了我想要的代码了,以下是我整理的源代码
from difflib import SequenceMatcher from collections import Counter print("==========第一次测试================") # 候选单词 words = {'good', 'hello', 'world', 'python','fuguo', 'yantai', 'shandong', 'great'} # 每个单词中字母频次 words = {word: dict(Counter(word)) for word in words} def checkAndModify(word): # 待检测单词的字母频次 fre = dict(Counter(word)) # 待测单词中各字母频次与所有候选单词的距离,即字母频次之差 similars = {w: [fre[ch]-words[w].get(ch, 0) for ch in word] + [words[w][ch]-fre.get(ch, 0) for ch in w] for w in words} # 返回最接近的单词,即字母频次之差的平方和最小的单词 return min(similars.items(), key=lambda item: sum(map(lambda i: i**2, item[1])))[0] # 测试 for word in ['god', 'hood', 'weloo', 'heloo', 'wello', 'helo', 'pychon', 'guguo', 'shangdong']: print(word, ':', checkAndModify(word)) print("==========第二次测试================") def similarity(a, b): return SequenceMatcher(None, a, b).ratio() def checkAndModify2(test): similars = {word: similarity(word,test) for word in words} return max(similars, key=similars.get) # 测试 for word in ['god', 'hood', 'weloo', 'heloo', 'wello', 'helo', 'pychon', 'guguo', 'shangdong']: print(word, ':', checkAndModify2(word))
以下的测试的结果
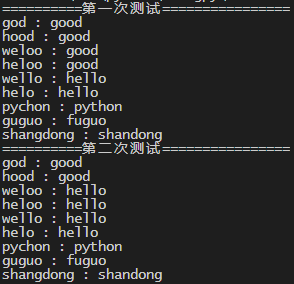
对于heloo第一个测试认为good是最接近的,第二个测试认为hello更为接近。我认为第二测试的结果。

