

【MCA进阶杂记】关于三高的相关问题——高可用
本文借鉴CSDN@码爱baba的文章并加入个人理解,原文传送门点击此处
首先行业内推使用n9来衡量系统的可用性
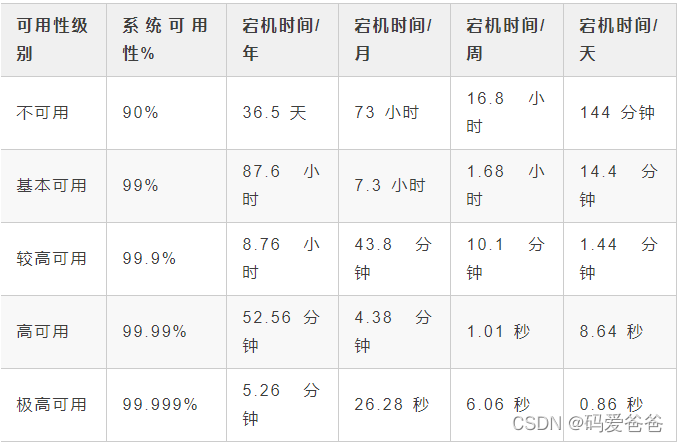
大厂要求4个9,极其严苛的业务需要5个9,例如列车时刻等.
目前大多数互联网使用的微服务架构如下图:
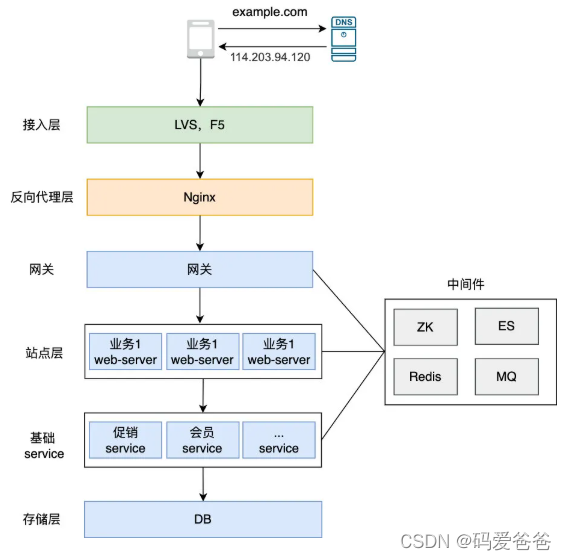
高可用处理的范围主要有以下几个地方:
(1) 接入层&反向代理层 : Nginx / LVS / F5
(2) 微服务 : 网关 / 站点层 / 基础服务层 (Dubbo等RPC架构)
(3) 中间件 : ZK / Redis / ES / MQ
(4) 存储层 : MySql等DB
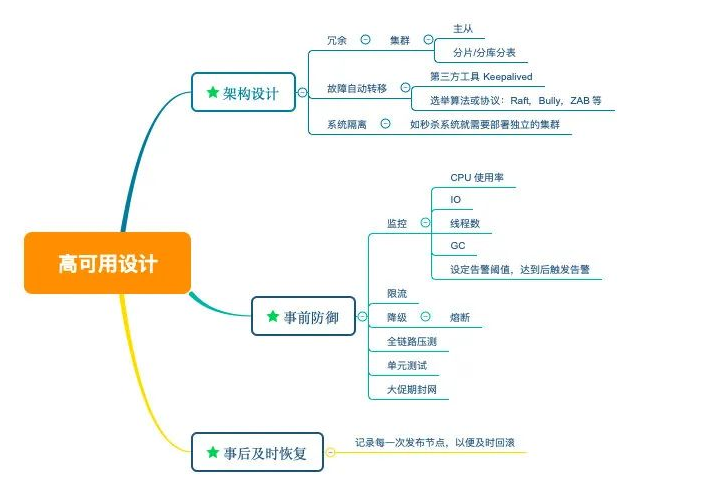
可以说高可用的处理贯穿了整个架构的始终,而且这些处理的地方都有共同点 : 主从 / 集群 模式,而且可能会用到分片方式,对于一主多从,高可用体现在选举,从而提高容灾能力.多主多从也可以,主要需注意的问题就是数据同步.
除了整体架构各个组件做了高可用处理,其他地方也需要注意,例如:
(1) 瞬时流量问题:比如我们可能会面临秒杀带来的瞬时流量激增导致系统的承载能力被压垮,这种情况可能影响日常交易等核心链路,所以需要做到系统之间的隔离,如单独为秒杀部署一套独立的集群
(2) 安全问题:比如 DDOS 攻击,爬虫频繁请求甚至删库跑路等导致系统拒绝服务
(3) 代码问题:比如代码 bug 引起内存泄露导致 FullGC 导致系统无法响应等
(4) 部署问题:在发布过程中如果贸然中止当前正在运行的服务也是不行的,需要做到优雅停机,平滑发布
(5) 第三方问题:比如我们之前的服务依赖第三方系统,第三方可能出问题导致影响我们的核心业务
(6) 不可抗力:如机房断电,所以需要做好容灾,异地多活,之前我司业务就由于机房故障导致服务四小时不可用,损失惨重
所以除了做好架构的高可用之外,我们还需要在做好系统隔离,限流,熔断,风控,降级,对关键操作限制操作人权限等措施以保证系统的可用.
这里特别提一下降级,这是为了保证系统可用性采取的常用的措施,简单举几个例子
(1) 我们之前对接过一个第三方资金方由于自身原因借款功能出了问题导致无法借款,这种情况为了避免引起用户恐慌,于是我们在用户申请第三方借款的时候返回了一个类似「为了提升你的额度,资金方正在系统升级」这样的文案,避免了客诉
(2) 在流媒体领域,当用户观看直播出现严重卡顿时,很多企业的第一选择不是查 log 排查问题,而是为用户自动降码率。因为比起画质降低,卡得看不了显然会让用户更痛苦
(3) 双十一零点高峰期,我们把用户的注册登录等非核心功能给停掉了,以保证下单等核心流程的顺利
另外我们最好能做到事前防御,在系统出问题前把它扼杀在摇篮里,所以我们需要做单元测试,做全链路压测等来发现问题,还需要针对 CPU,线程数等做好监控,当其达到我们设定的域值时就触发告警以让我们及时发现修复问题(我司之前就碰到过一个类似的生产事故复盘大家可以看一下),此外在做好单元测试的前提下,依然有可能因为代码的潜在 bug 引起线上问题,所以我们需要在关键时间(比如双十一期间)封网(也就是不让发布代码)
此外我们还需要在出事后能快速定位问题,快速回滚,这就需要记录每一次的发布时间,发布人等,这里的发布不仅包括工程的发布,还包括配置中心等的发布
高可用手段总结如下:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异