Pytorch学习2020春-2-softmax和分类模型
1. Softmax基本知识
-
分类问题
一个简单的图像分类问题,输入图像的高和宽均为2像素,色彩为灰度。
图像中的4像素分别记为 𝑥1,𝑥2,𝑥3,𝑥4 。
假设真实标签为狗、猫或者鸡,这些标签对应的离散值为 𝑦1,𝑦2,𝑦3 。
我们通常使用离散的数值来表示类别,例如 𝑦1=1,𝑦2=2,𝑦3=3 。 -
权重矢量
\(o_1 = x_1 w_{11} + x_2 w_{21} + x_3 w_{31} + x_4 w_{41} + b_1\)
\(o_2 = x_1 w_{12} + x_2 w_{22} + x_3 w_{32} + x_4 w_{42} + b_2\)
\(o_3 = x_1 w_{13} + x_2 w_{23} + x_3 w_{33} + x_4 w_{43} + b_3\)
-
神经网络图
下图用神经网络图描绘了上面的计算。softmax回归同线性回归一样,也是一个单层神经网络。由于每个输出 𝑜1,𝑜2,𝑜3 的计算都要依赖于所有的输入𝑥1,𝑥2,𝑥3,𝑥4 ,softmax回归的输出层也是一个全连接层。
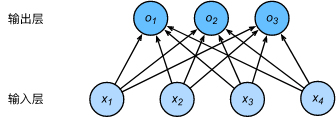
既然分类问题需要得到离散的预测输出,一个简单的办法是将输出值\(o_i\)当作预测类别是\(i\)的置信度,并将值最大的输出所对应的类作为预测输出,即输出\(arg\;m_iax\;o_i\)。例如,如果\(o_1,o_2,o_3\)分别为\(0.1,10,0.1\),由于\(o_2\)最大,那么预测类别为2,其代表猫。
-
输出问题
直接使用输出层的输出有两个问题:
- 一方面,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。例如,刚才举的例子中的输出值10表示“很置信”图像类别为猫,因为该输出值是其他两类的输出值的100倍。但如果 𝑜1=𝑜3=103 ,那么输出值10却又表示图像类别为猫的概率很低。
- 另一方面,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax运算符(softmax operator)解决了以上两个问题。它通过下式将输出值变换成值为正且和为1的概率分布:
其中\(\hat{y}1 = \displaystyle\frac{ \exp(o_1)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}2 = \displaystyle\frac{ \exp(o_2)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}3 = \displaystyle\frac{ \exp(o_3)}{\sum_{i=1}^3 \exp(o_i)}.\)
容易看出\(\hat{y}_1+\hat{y}_2+\hat{y}_3=1\)且\(0\leq \hat{y}_1,\hat{y}_2,\hat{y}_3\leq 1\),因此\(\hat{y}_1,\hat{y}_2,\hat{y}_3\)是一个合法的概率分布。这时候,如果\(\hat{y}_2=0.8\),不管\(\hat{y}_1\)和\(\hat{y}_3\)的值是多少,我们都知道图像类别为猫的概率是80%。此外,我们注意到
因此softmax运算不改变预测类别输出。
-
计算效率
-
单样本矢量计算表达式
为了提高计算效率,我们可以将单样本分类通过矢量计算来表达。在上面的图像分类问题中,假设softmax回归的权重和偏差参数分别为
\[\boldsymbol{W} = \begin{bmatrix} w_{11} & w_{12} & w_{13} \\ w_{21} & w_{22} & w_{23} \\ w_{31} & w_{32} & w_{33} \\ w_{41} & w_{42} & w_{43} \end{bmatrix},\quad \boldsymbol{b} = \begin{bmatrix} b_1 & b_2 & b_3 \end{bmatrix}, \]设高和宽分别为2个像素的图像样本 𝑖 的特征为
\[\boldsymbol{x}^{(i)} = \begin{bmatrix}x_1^{(i)} & x_2^{(i)} & x_3^{(i)} & x_4^{(i)}\end{bmatrix}, \]输出层的输出为
\[\boldsymbol{o}^{(i)} = \begin{bmatrix}o_1^{(i)} & o_2^{(i)} & o_3^{(i)}\end{bmatrix}, \]预测为狗、猫或鸡的概率分布为
\[\boldsymbol{\hat{y}}^{(i)} = \begin{bmatrix}\hat{y}_1^{(i)} & \hat{y}_2^{(i)} & \hat{y}_3^{(i)}\end{bmatrix}. \]softmax回归对样本 𝑖 分类的矢量计算表达式为
\[\begin{aligned} \boldsymbol{o}^{(i)} &= \boldsymbol{x}^{(i)} \boldsymbol{W} + \boldsymbol{b},\\ \boldsymbol{\hat{y}}^{(i)} &= \text{softmax}(\boldsymbol{o}^{(i)}). \end{aligned} \] -
小批量矢量计算表达式
为了进一步提升计算效率,我们通常对小批量数据做矢量计算。广义上讲,给定一个小批量样本,其批量大小为\(n\),输入个数(特征数)为\(d\),输出个数(类别数)为\(q\)。设批量特征为\(X\in\mathbb{R}^{n\times d}\)。假设softmax回归的权重和偏差参数分别为\(W\in\mathbb{R}^{d\times q}\)和\(b\in\mathbb{R}^{1\times q}\)。softmax回归的矢量计算表达式为
\[\begin{aligned} \boldsymbol{O} &= \boldsymbol{X} \boldsymbol{W} + \boldsymbol{b},\\ \boldsymbol{\hat{Y}} &= \text{softmax}(\boldsymbol{O}), \end{aligned} \]其中的加法运算使用了广播机制,\(O,\hat Y\in\mathbb{R}^{n\times q}\),且这两个矩阵的第\(i\)行分别为样本\(i\)的输出\(o^{(i)}\)和概率分布\(\hat y^{(i)}\)。
-
1.1 交叉熵损失函数
1.1.1 信息论
信息量大小与信息发生概率成反比,假设某时间发生概率为\(p(x)\),其信息量为
1.1.2 信息熵
信息熵也被称为熵,用来表示所有信息量的期望。
期望是试验中每次可能结果的概率乘以其结果的总和。
所以信息量的熵可表示为:(这里的X是一个离散型随机变量)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号