JDK1.7下的concurrentHashMap原理解析
记录这篇博客前先说为什么,再说怎么做;
hashMap在并发插入的情况下会存在死锁的问题,根本原因是多个线程并发插入的过程会判断hashmap的容量是否足够,如果不够的情况下会进行扩容操作,因为Jdk1.7对hashEntry的插入是“头部插入”也就是头插法,当多个线程同时对hashMap进行扩容的时候,就会产生死锁;文字解释比较单薄,我把扩容时的代码贴一下,各位可能就会比较清楚了;
public void transfer() {
for (Entry<k,v> e : table) {
while (e != null) {
if (rehash) {
e.hash = e.key == null ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapicity);
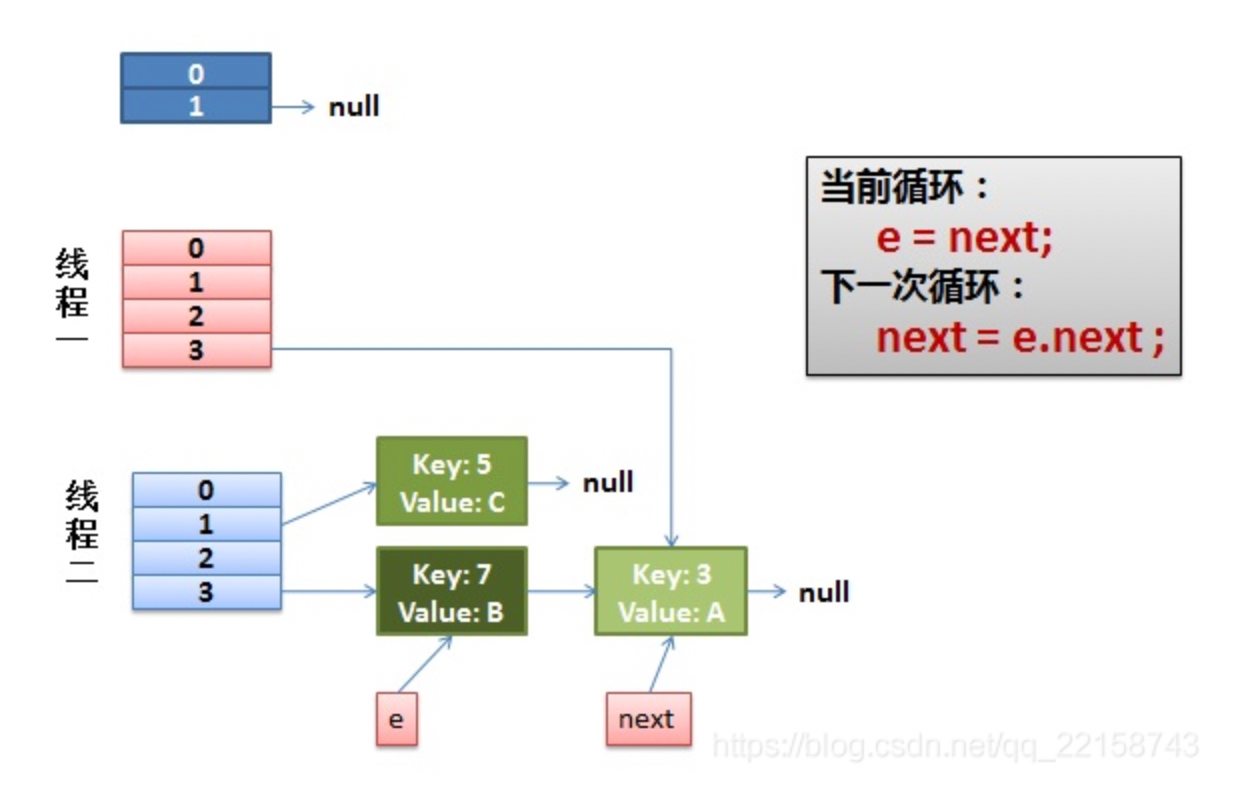
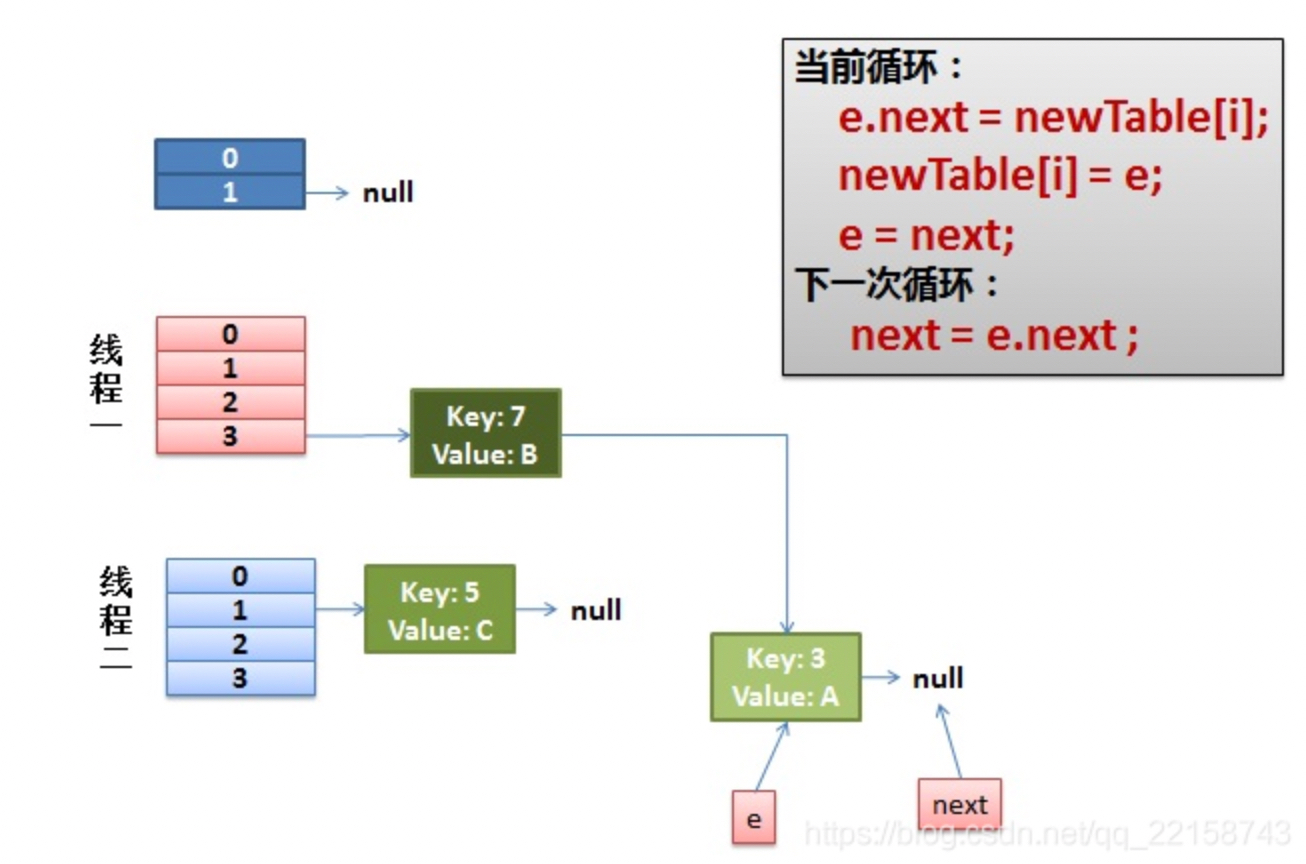
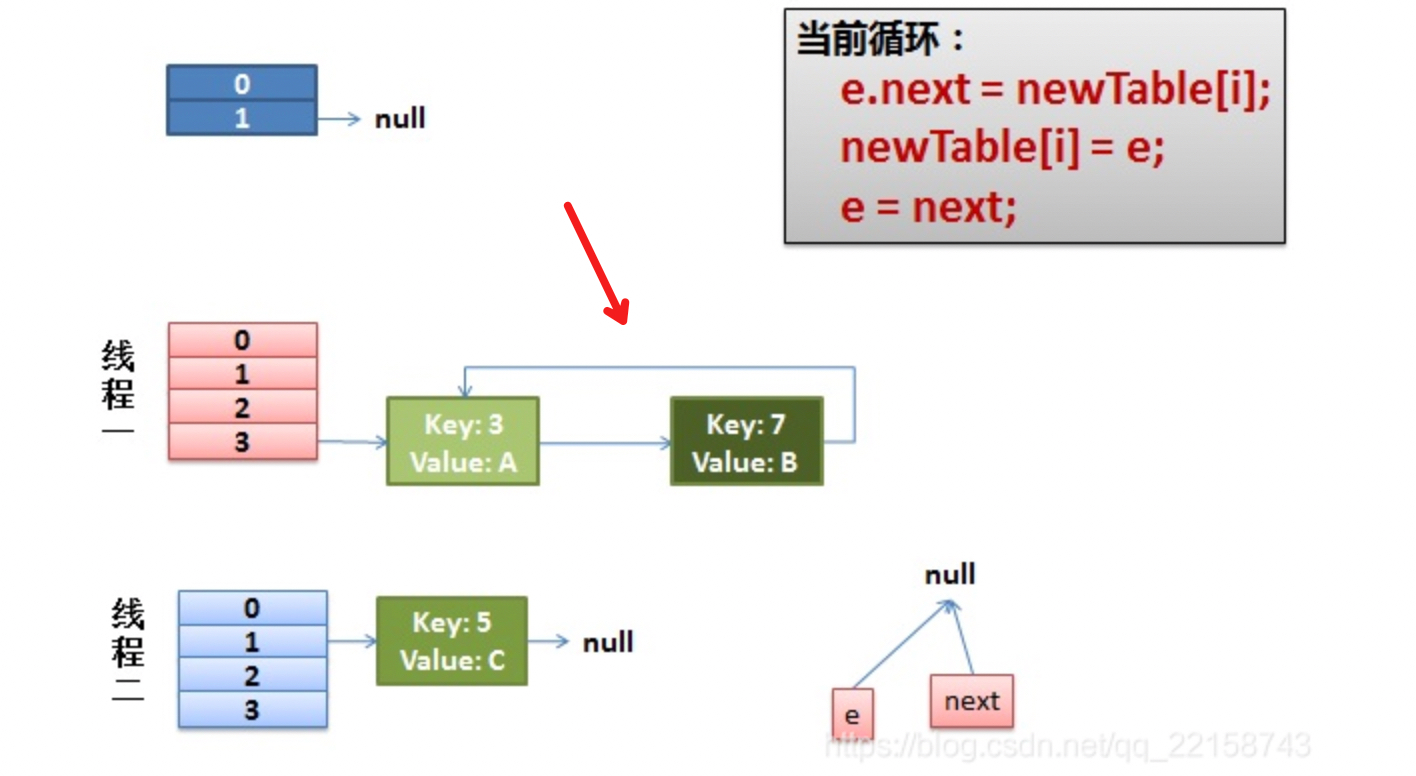
Entry<k,v> next = e.next; // 1 <------- 此处线程1交出了执行权限
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
hashMap扩容的原理大概就是这样,新建一个原来2倍容量的hashEntry数组,然后遍历旧的hashEntry数组,对其进行rehash的操作,然后插入到新的hashEntry数组的位置中去,从而完成了整个扩容的过程;
单线程情况下自然没有问题,但是在多线程的情况下就会产生死锁;
先看下扩容前整个hashEntry数组的样子;

假设在我代码注释的1处线程1交出了执行cpu的执行权限,而线程2此时完成了整个扩容的过程,此时整个hashEntry数组的样子如下图所示:

concurrentHashMap简单介绍
可能在介绍concurrentHashMap之前会有同学问,为什么不用hashtable呢,通过加锁,一样可以避免扩容死循环的问题,是的,可是hashtable是通过加synchronized锁的方式来完成线程安全的,也就是说线程1在进行put操作的时候,线程2的put操作智能阻塞,不仅如此,线程2连get操作都不能执行,因为锁的是hashtable这个对象,所以,并发场景下因为竞争同一个锁对象,效率极低,而且并发越高效率越低,难堪大用;
那concurrentHashMap又是如何解决锁争用问题的呢?没错,如果一个容器里面配置有多把锁的情况下是不是就能够大大降低锁争用的问题,提高并发程度呢!
concurrentHashMap的底层结构是由segment数组加hashEntry数组构成,segment对象继承自RetreentLock,本身是一把互斥锁,同时segment内部维护着一个hashEntry[]的数组;要想对hashEntry数组进行写入,必须先获得segment的锁,因为在concurrentHashMap的结构里有多个segment对象,所以在读写不同的segment的时候其实争用的并不是同一把锁,也就不会出现hashTable那么严重的锁竞争问题;
来看下concurrentHashMap的底层实现大概是啥样子的:

初始化
首先是segment数组的初始化,segment数组的容量是由concurrencyLevel的值来决定的;
同时还有几个其他的变量 ssize; segmentshift 和 segmentMask;
segment数组的大概初始化的伪代码如下:
public void init() {
int concurrencyLevel;
if (concurrencyLevel > MAX_SEGMENT) {
concurrencyLevel = MAX_SEGMENT;
}
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
sshift++;
ssize << 1;
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this.segements = Segment.newArray(ssize);
}
从初始化的代码中我们可以看到,segment数组的容量必须是2^n倍,这其实是为了在进行segment数组定位的时候,将取模操作等价转换为按位与操作;而这个segmentMask其实就是用来进行按位与的,对key.hashcode()进行一次rehash的扰动操作,然后右移segmentShift位,之后和segmentMask进行按位与,就完成了segment数组的定位操作,看下segment的源码:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >> segmentShift) & segmentMask];
}
再看一下每个segment里面的HashEntry数组的初始化操作的源码:
if (initialCapacity > MAXMUM_CAPACITY) {
initialCapacity = MAXMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity) {
++c; //保证容量之和一定不小于initialCapacity;
}
int cap = 1;
while (cap < c) {
cap << 1;
}
for(int i = 0; i < this.segments.length; i++){
this.segments[i] = new Segment<K,V>(cap, loadFactor);
}
}
同样的每个hashEntry数组的容量也是2的n次方,这样设计的目的其实也是为了将取模的操作变成按位于的操作,降低计算成本;但是hashEntry中元素的访问定位和segment中又有所不同,在hashEntry中是将 entry.hash() & (table.length - 1)来实现的;
get()
接下来看一下concurrentHashMap中的get()操作,在get的过程中是不需要加锁的,除非读到的值是null,才会进行一次加锁重读;
那么为什么concurrentHashMap的get()操作不需要加锁呢,是因为concurrentHashMap将统计segment内hashEntry数组大小的count字段和HashEntry<K,V>的存储值的value字段都用volatile进行修饰,我们知道volatile的内存语义保证了任何时刻任何线程对volatile变量修饰的变量进行读取,都一定能够读取到最新的主内存中的值;所以这就是为啥concurrentHashMap在进行get操作的时候不需要加锁的原因;【volatile替换锁的经典场景】
transient volatile int count; // 都用volatile修饰 volatile V value; // 都用volatile进行修饰,保证内存可见性
put()
put()操作因为需要对共享变量进行写入,所以为了保证线程安全必须进行加锁,put的过程大致是,首先根据hash值进行segment的定位,然后将put的变量插入到segment中去,在插入的过程中需要经历两个步骤,1.判断是否需要进行扩容;2定位添加元素的位置,然后执行插入操作;
(1)判断是否需要进行扩容,这个过程就是判断当前hashEntry数组的容量是否超过了阈值,如果是的话就执行扩容操作,但是concurrentHashMap的扩容操作比hashMap更合理,因为它是先扩容再插值,而hashMap是先插值再扩容;(先插值再扩容有可能后面再也没元素插入进来,无效扩容问题)
(2) 定位元素位置,执行插入操作;
size()
因为每一个segment数组内的容量大小count是用volatile进行修饰的,所以是不是只要将count读取出来然后直接求和就能拿到当前的最新的值呢?原则上是这样的,但是在求和的过程中可能会存在segment容量发生变动的问题,这时候就算你是volatile修饰也不行,可是对所有的put()/remove()/clean()操作全部锁住然后统计效率又太太太低了,所以concurrentHashMap的做法是进行两次读取求和,然后判断统计过程中容器的count是否有发生变化,如果发生了变化就进行加锁重读,如果没有发生变化,就认为求和的结果是准确的,可是如何判断segment的count是否发生变化呢?
答案是用 modCount, segment里面的hashEntry()的每一个操作(put()/clean()/remove())都会让那个modCount的值加1,所以只需要判断modCount是否发生了变化就可以啦!
