
golang tour
Go 语言设计和工具链核心团队成员

Ken Thompson(肯·汤普逊)

大名鼎鼎、如雷贯耳,Unix 操作系统的发明人之一(排在第一号),C 语言前身 B 语言的设计者,UTF-8 编码设计者之一,图灵奖得主。老爷子今年快 76 岁了(1943年生)。早年一直再贝尔实验室做研究,60 多岁的时候被谷歌尊养起来。2007年,老爷子和 Rob Pike、Robert Griesemer 一起设计了做出的 Go 语言。老爷子目前基本不参与 Go 的设计和开发。
在 2011 年的一次采访中,老爷子幽默地谈到设计 Go 语言的初衷是他们很不喜欢 C++,因为 C++ 中充满了大量的垃圾特性。
“C语言之父” Dennis MacAlistair Ritchie(中文名:丹尼斯·里奇)

C 语言是 “C 语言之父” Dennis MacAlistair Ritchie(中文名:丹尼斯·里奇)创造出来的。
C 语言是 D.M.Ritchie 在 B 语言的基础上创造出来的。C 语言的出现经历了以下历程:
在 1970 年,美国贝尔实验室的 Ken Thompson,以 BCPL 语言为基础,设计出很简单且很接近硬件的 B 语言(取 BCPL 的首字母)。并且他用 B 语言写了第一个 UNIX 操作系统。
1972 年,美国贝尔实验室的 D.M.Ritchie 在 B 语言的基础上最终设计出了一种新的语言,他取了 BCPL 的第二个字母作为这种语言的名字,这就是 C 语言。
1973 年初,C 语言的主体完成。Thompson 和 Ritchie 迫不及待地开始用它完全重写了 UNIX。直到今天,各种版本的 UNIX 内核和周边工具仍然使用 C 语言作为最主要的开发语言,其中还有不少继承 Thompson 和 Ritchie 之手的代码。
丹尼斯·里奇发明出C语言之后,产生了十分强大的社会影响,具体如下:
-
C 语言是使用最广泛的语言之一。C 语言的诞生是现代程序语言革命的起点,是程序设计语言发展史中的一个里程碑。
-
自 C 语言出现后,以 C 语言为根基的 C++、Java 和 C# 等面向对象语言相继诞生,并在各自领域大获成功。但C语言依旧在系统编程、嵌入式编程等领域占据着统治地位。
-
C 语言,这种最有效、最通用的编程语言,就是丹尼斯·里奇开发的,而这还是他在做另一个项目时的副产品。丹尼斯·里奇还和肯·汤普逊一起开发了 Unix 操作系统,因此,他还是名副其实的 Unix 之父。
Rob Pike(罗布·派克)

早年在贝尔实验室和 Ken Thompson 结对编程的小弟,早已成长为业内的领军人物。UTF-8 两个发明人之一。Go 设计团队第一任老大。如今也退休并被谷歌尊养起来了。Rob Pike 仍旧活跃在各个 Go 论坛组中,适当地发表自己的意见。
顺便说一句,Go 语言的地鼠吉祥物是由 Rob Pike 的媳妇 Renee French 设计的。
顺便另说一句,Rob Pike 曾获得 1980 年奥运会射箭银牌。
Robert Griesemer(罗伯特·格里泽默)

Go 语言三名最初的设计者之一,比较年轻。曾参与 V8 JavaScript 引擎和 Java HotSpot 虚拟机的研发。目前主要维护 Go 白皮书和代码解析器等。
Russ Cox(拉斯·考克斯)

Russ Cox 为目前 Go 团队的 leader。2008 年 MIT 博士毕业后就加入了 Go 核心设计开发团队,非常年轻。代码提交量排第一。
目前很多拿不定主意的决策都是 Russ Cox 最后拍板。很多时候都是力排众议,这导致了 Go 社区很多成员对他有些不满。去年发生的 godep 和 vgo(即 Go modules)争论事件到现在还余波未了。
实事求是地说,他的大多数决策都是很合理的。
Ian Lance Taylor(伊安·泰勒)

gcc 项目活跃维护者之一,gccgo 编译器的作者和 cgo 工具链维护者。活跃于各个 go 订阅组,耐心解答各种问题。可以说,如果没有 Ian 的耐心解答,《Go 语言 101》一书很难完成。
Brad Fitzpatrick(布拉德·非茨子帕特里克)

LiveJournal.com 的创始人,Memcached 软件的作者。net/http 标准库包的主要维护者。
当然,核心团队还有很多成员。限于篇幅和未搜索到他们的足够信息,这里就不介绍了。
Getting Started (How to write Go code)
Introduction
本文档展示了一个简单 Go 包的开发,并介绍了用 go 工具来获取、 构建并安装 Go 包及命令的标准方式。
go 工具需要你按照指定的方式来组织代码。请仔细阅读本文档, 它说明了如何以最简单的方式来准备并运行你的 Go 安装。
Code organization
Workspace
go 工具为公共代码仓库中维护的开源代码而设计。 无论你会不会公布代码,该模型设置工作环境的方法都是相同的。
Go代码必须放在工作空间内。它其实就是一个目录,其中包含三个子目录:
- src 目录包含 Go 的源文件,它们被组织成包(每个目录都对应一个包)
- pkg 目录包含包对象
- bin 目录包含可执行命令
go 工具用于构建源码包,并将其生成的二进制文件安装到 pkg 和 bin 目录中。
src 子目录通常包会含多种版本控制的代码仓库(例如 Git 或 Mercurial), 以此来跟踪一个或多个源码包的开发。
以下例子展现了实践中工作空间的概念:
bin/
streak # 可执行命令
todo # 可执行命令
pkg/
linux_amd64/
code.google.com/p/goauth2/
oauth.a # 包对象
github.com/nf/todo/
task.a # 包对象
src/
code.google.com/p/goauth2/
.hg/ # mercurial 代码库元数据
oauth/
oauth.go # 包源码
oauth_test.go # 测试源码
github.com/nf/
streak/
.git/ # git 代码库元数据
oauth.go # 命令源码
streak.go # 命令源码
todo/
.git/ # git 代码库元数据
task/
task.go # 包源码
todo.go # 命令源码
此工作空间包含三个代码库(goauth2、streak 和 todo),两个命令(streak 和 todo) 以及两个库(oauth 和 task)。
命令和库从不同的源码包编译而来。稍后我们会对讨论它的特性。
Envionment Variables
$ export GOROOT='Go 安装目录'
$ export GOPATH='工作空间位置'
$ export PATH=$PATH:$GOROOT/bin
$ export PATH=$PATH:$GOPATH/bin
Package Path
标准库中的包有给定的短路径,比如 "fmt" 和 "net/http"。 对于你自己的包,你必须选择一个基本路径,来保证它不会与将来添加到标准库, 或其它扩展库中的包相冲突。
如果你将你的代码放到了某处的源码库,那就应当使用该源码库的根目录作为你的基本路径。 例如,若你在 GitHub 上有账户 github.com/user 那么它就应该是你的基本路径。
注意,在你能构建这些代码之前,无需将其公布到远程代码库上。只是若你某天会发布它, 这会是个好习惯。在实践中,你可以选择任何路径名,只要它对于标准库和更大的 Go 生态系统来说, 是唯一的就行。
我们将使用 github.com/user 作为基本路径。在你的工作空间里创建一个目录, 我们将源码存放到其中:
$ mkdir -p $GOPATH/src/github.com/user
Your first program
要编译并运行简单的程序,首先要选择包路径(我们在这里使用 github.com/user/hello),并在你的工作空间内创建相应的包目录:
$ mkdir $GOPATH/src/github.com/user/hello
接着,在该目录中创建名为 hello.go 的文件,其内容为以下Go代码:
package main
import "fmt"
func main() {
fmt.Printf("Hello, world.\n")
}
现在你可以用 go 工具构建并安装此程序了:
$ go install github.com/user/hello
注意,你可以在系统的任何地方运行此命令。go 工具会根据 GOPATH 指定的工作空间,在 github.com/user/hello 包内查找源码。
若在从包目录中运行 go install,也可以省略包路径:
$ cd $GOPATH/src/github.com/user/hello
$ go install
此命令会构建 hello 命令,产生一个可执行的二进制文件。 接着它会将该二进制文件作为 hello(在 Windows 下则为 hello.exe)安装到工作空间的 bin 目录中。
go 工具只有在发生错误时才会打印输出,因此若这些命令没有产生输出, 就表明执行成功了。
现在,你可以在命令行下输入它的完整路径来运行它了:
$ $GOPATH/bin/hello
Hello, world.
若你已经将 $GOPATH/bin 添加到 PATH 中了,只需输入该二进制文件名即可:
$ hello
Hello, world.
Your first library
让我们编写一个库,并让 hello 程序来使用它。
同样,第一步还是选择包路径(我们将使用 github.com/user/stringutil) 并创建包目录:
$ mkdir $GOPATH/src/github.com/user/stringutil
接着,在该目录中创建名为 reverse.go 的文件,内容如下:
// stringutil 包含有用于处理字符串的工具函数。
package stringutil
// Reverse 将其实参字符串以符文为单位左右反转。
func Reverse(s string) string {
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r)
}
现在用 go build 命令来测试该包是否可以被编译通过:
$ go build github.com/user/stringutil
当然,若你在该包的源码目录中,只需执行:
$ go build
go build 命令不会产生输出文件。想要输出的话,必须使用 go install 命令,它会将包的对象放到工作空间的 pkg 目录中。
确认 stringutil 包构建完毕后,修改原来的 hello.go 文件(它位于 $GOPATH/src/github.com/user/hello)去使用它:
package main
import (
"fmt"
"github.com/user/stringutil"
)
func main() {
fmt.Printf(stringutil.Reverse("!oG ,olleH"))
}
无论是安装包还是二进制文件,go 工具都会安装它所依赖的任何东西。 因此当我们通过
$ go install github.com/user/hello
来安装 hello 程序时,stringutil 包也会被自动安装。
运行此程序的新版本,你应该能看到一条新的,反向的信息:
$ hello
Hello, Go!
做完上面这些步骤后,你的工作空间应该是这样的:
bin/
hello # 可执行命令
pkg/
linux_amd64/ # 这里会反映出你的操作系统和架构
github.com/user/
stringutil.a # 包对象
src/
github.com/user/
hello/
hello.go # 命令源码
stringutil/
reverse.go # 包源码
注意 go install 会将 stringutil.a 对象放到 pkg/linux_amd64 目录中,它会反映出其源码目录。 这就是在此之后调用 go 工具,能找到包对象并避免不必要的重新编译的原因。 linux_amd64 这部分能帮助跨平台编译,并反映出你的操作系统和架构。
Go的可执行命令是静态链接的;在运行Go程序时,包对象无需存在。
Package Name
Go 源文件中的第一个语句必须是
package 名称
这里的 名称 即为导入该包时使用的默认名称。 (一个包中的所有文件都必须使用相同的 名称。)
Go 的约定是包名为导入路径的最后一个元素:作为 "crypto/rot13" 导入的包应命名为 rot13。
可执行命令必须使用 package main。
链接成单个二进制文件的所有包,其包名无需是唯一的,只有导入路径(它们的完整文件名) 才是唯一的。
Testing
Go拥有一个轻量级的测试框架,它由 go test 命令和 testing 包构成。
你可以通过创建一个名字以 _test.go 结尾的,包含名为 TestXXX 且签名为 func (t *testing.T) 函数的文件来编写测试。 测试框架会运行每一个这样的函数;若该函数调用了像 t.Error 或 t.Fail 这样表示失败的函数,此测试即表示失败。
我们可通过创建文件 $GOPATH/src/github.com/user/stringutil/reverse_test.go 来为 stringutil 添加测试,其内容如下:
package stringutil
import "testing"
func TestReverse(t *testing.T) {
cases := []struct {
in, want string
}{
{"Hello, world", "dlrow ,olleH"},
{"Hello, 世界", "界世 ,olleH"},
{"", ""},
}
for _, c := range cases {
got := Reverse(c.in)
if got != c.want {
t.Errorf("Reverse(%q) == %q, want %q", c.in, got, c.want)
}
}
}
接着使用 go test 运行该测试:
$ go test github.com/user/stringutil
ok github.com/user/stringutil 0.165s
同样,若你在包目录下运行 go 工具,也可以忽略包路径
$ go test
ok github.com/user/stringutil 0.165s
Remote Package
像 Git 或 Mercurial 这样的版本控制系统,可根据导入路径的描述来获取包源代码。
go 工具可通过此特性来从远程代码库自动获取包。例如,本文档中描述的例子也可存放到 Google Code 上的 Mercurial 仓库 code.google.com/p/go.example 中,若你在包的导入路径中包含了代码仓库的 URL,go get 就会自动地获取、 构建并安装它:
$ go get github.com/golang/example/hello
$ $GOPATH/bin/hello
Hello, Go examples!
若指定的包不在工作空间中,go get 就会将会将它放到 GOPATH 指定的第一个工作空间内。(若该包已存在,go get 就会跳过远程获取, 其行为与 go install 相同)
在执行完上面的 go get 命令后,工作空间的目录树看起来应该是这样的:
bin/
hello # 可执行命令
pkg/
linux_amd64/
code.google.com/p/go.example/
stringutil.a # 包对象
github.com/user/
stringutil.a # 包对象
src/
code.google.com/p/go.example/
hello/
hello.go # 命令源码
stringutil/
reverse.go # 包源码
reverse_test.go # 测试源码
github.com/user/
hello/
hello.go # 命令源码
stringutil/
reverse.go # 包源码
reverse_test.go # 测试源码
hello 命令及其依赖的 stringutil 包都托管在 Google Code 上的同一代码库中。
hello.go 文件使用了同样的导入路径约定, 因此 go get 命令也能够定位并安装其依赖包。
import "github.com/golang/example/stringutil"
遵循此约定可让他人以最简单的方式使用你的 Go 包。 Go 维基 与 godoc.org 提供了外部 Go 项目的列表。
Data types and structures
Array types
An array is a numbered sequence of elements of a single type, called the element type. The number of elements is called the length and is never negative.
ArrayType = "[" ArrayLength "]" ElementType .
ArrayLength = Expression .
ElementType = Type .
The length is part of the array's type; it must evaluate to a non-negative constant representable by a value of type int. The length of array a can be discovered using the built-in function len. The elements can be addressed by integer indices 0 through len(a)-1. Array types are always one-dimensional but may be composed to form multi-dimensional types.
[32]byte
[2*N] struct { x, y int32 }
[1000]*float64
[3][5]int
[2][2][2]float64 // same as [2]([2]([2]float64))
Slice types
A slice is a descriptor for a contiguous segment of an underlying array and provides access to a numbered sequence of elements from that array. A slice type denotes the set of all slices of arrays of its element type. The value of an uninitialized slice is nil.
SliceType = [] ElementType
Like arrays, slices are indexable and have a length. The length of a slice s can be discovered by the built-in function len; unlike with arrays it may change during execution. The elements can be addressed by integer indices 0 through len(s)-1. The slice index of a given element may be less than the index of the same element in the underlying array.
A slice, once initialized, is always associated with an underlying array that holds its elements. A slice therefore shares storage with its array and with other slices of the same array; by contrast, distinct arrays always represent distinct storage.
The array underlying a slice may extend past the end of the slice. The capacity is a measure of that extent: it is the sum of the length of the slice and the length of the array beyond the slice; a slice of length up to that capacity can be created by slicing a new one from the original slice. The capacity of a slice a can be discovered using the built-in function cap(a).
A new, initialized slice value for a given element type T is made using the built-in function make, which takes a slice type and parameters specifying the length and optionally the capacity. A slice created with make always allocates a new, hidden array to which the returned slice value refers. That is, executing
make([]T, length, capacity)
produces the same slice as allocating an array and slicing it, so these two expressions are equivalent:
make([]int, 50, 100)
new([100]int)[0:50]
Like arrays, slices are always one-dimensional but may be composed to construct higher-dimensional objects. With arrays of arrays, the inner arrays are, by construction, always the same length; however with slices of slices (or arrays of slices), the inner lengths may vary dynamically. Moreover, the inner slices must be initialized individually.
Struct types
A struct is a sequence of named elements, called fields, each of which has a name and a type. Field names may be specified explicitly (IdentifierList) or implicitly (AnonymousField). Within a struct, non-blank field names must be unique.
StructType = "struct" "{" { FieldDecl ";" } "}" .
FieldDecl = (IdentifierList Type | AnonymousField) [ Tag ] .
AnonymousField = [ "*" ] TypeName .
Tag = string_lit .
// An empty struct.
struct {}
// A struct with 6 fields.
struct {
x, y int
u float32
_ float32 // padding
A *[]int
F func()
}
A field declared with a type but no explicit field name is an anonymous field, also called an embedded field or an embedding of the type in the struct. An embedded type must be specified as a type name T or as a pointer to a non-interface type name *T, and T itself may not be a pointer type. The unqualified type name acts as the field name.
// A struct with four anonymous fields of type T1, *T2, P.T3 and *P.T4
struct {
T1 // field name is T1
*T2 // field name is T2
P.T3 // field name is T3
*P.T4 // field name is T4
x, y int // field names are x and y
}
The following declaration is illegal because field names must be unique in a struct type:
struct {
T // conflicts with anonymous field *T and *P.T
*T // conflicts with anonymous field T and *P.T
*P.T // conflicts with anonymous field T and *T
}
A field or method f of an anonymous field in a struct x is called promoted if x.f is a legal selector that denotes that field or method f.
Promoted fields act like ordinary fields of a struct except that they cannot be used as field names in composite literals of the struct.
Given a struct type S and a type named T, promoted methods are included in the method set of the struct as follows:
- If S contains an anonymous field T, the method sets of S and *S both include promoted methods with receiver T. The method set of *S also includes promoted methods with receiver *T.
- If S contains an anonymous field *T, the method sets of S and *S both include promoted methods with receiver T or *T.
A field declaration may be followed by an optional string literal tag, which becomes an attribute for all the fields in the corresponding field declaration. The tags are made visible through a reflection interface and take part in type identity for structs but are otherwise ignored.
// A struct corresponding to the TimeStamp protocol buffer.
// The tag strings define the protocol buffer field numbers.
struct {
microsec uint64 "field 1"
serverIP6 uint64 "field 2"
process string "field 3"
}
Pointer types
A pointer type denotes the set of all pointers to variables of a given type, called the base type of the pointer. The value of an uninitialized pointer is nil.
PointerType = "*" BaseType .
BaseType = Type .
*Point
*[4]int
Function types
A function type denotes the set of all functions with the same parameter and result types. The value of an uninitialized variable of function type is nil.
FunctionType = "func" Signature .
Signature = Parameters [ Result ] .
Result = Parameters | Type .
Parameters = "(" [ ParameterList [ "," ] ] ")" .
ParameterList = ParameterDecl { "," ParameterDecl } .
ParameterDecl = [ IdentifierList ] [ "..." ] Type .
Within a list of parameters or results, the names (IdentifierList) must either all be present or all be absent. If present, each name stands for one item (parameter or result) of the specified type and all non-blank names in the signature must be unique. If absent, each type stands for one item of that type. Parameter and result lists are always parenthesized except that if there is exactly one unnamed result it may be written as an unparenthesized type.
The final parameter in a function signature may have a type prefixed with .... A function with such a parameter is called variadic and may be invoked with zero or more arguments for that parameter.
func() {}
func(x int) int {}
func(a, _ int, z float32) bool {}
func(a, b int, z float32) (bool) {}
func(prefix string, values ...int) {}
func(a, b int, z float64, opt ...interface{}) (success bool) {}
func(int, int, float64) (float64, *[]int) {}
func(n int) func(p *T) {}
Interface types
An interface type specifies a method set called its interface. A variable of interface type can store a value of any type with a method set that is any superset of the interface. Such a type is said to implement the interface. The value of an uninitialized variable of interface type is nil.
InterfaceType = "interface" "{" { MethodSpec ";" } "}" .
MethodSpec = MethodName Signature | InterfaceTypeName .
MethodName = identifier .
InterfaceTypeName = TypeName .
As with all method sets, in an interface type, each method must have a unique non-blank name.
// A simple File interface
interface {
Read(b Buffer) bool
Write(b Buffer) bool
Close()
}
More than one type may implement an interface. For instance, if two types S1 and S2 have the method set
func (p T) Read(b Buffer) bool { return … }
func (p T) Write(b Buffer) bool { return … }
func (p T) Close() { … }
(where T stands for either S1 or S2) then the File interface is implemented by both S1 and S2, regardless of what other methods S1 and S2 may have or share.
A type implements any interface comprising any subset of its methods and may therefore implement several distinct interfaces. For instance, all types implement the empty interface:
interface{}
Similarly, consider this interface specification, which appears within a type declaration to define an interface called Locker:
type Locker interface {
Lock()
Unlock()
}
If S1 and S2 also implement
func (p T) Lock() { … }
func (p T) Unlock() { … }
they implement the Locker interface as well as the File interface.
An interface T may use a (possibly qualified) interface type name E in place of a method specification. This is called embedding interface E in T; it adds all (exported and non-exported) methods of E to the interface T.
type ReadWriter interface {
Read(b Buffer) bool
Write(b Buffer) bool
}
type File interface {
ReadWriter // same as adding the methods of ReadWriter
Locker // same as adding the methods of Locker
Close()
}
type LockedFile interface {
Locker
File // illegal: Lock, Unlock not unique
Lock() // illegal: Lock not unique
}
An interface type T may not embed itself or any interface type that embeds T, recursively.
// illegal: Bad cannot embed itself
type Bad interface {
Bad
}
// illegal: Bad1 cannot embed itself using Bad2
type Bad1 interface {
Bad2
}
type Bad2 interface {
Bad1
}
Map types
A map is an unordered group of elements of one type, called the element type, indexed by a set of unique keys of another type, called the key type. The value of an uninitialized map is nil.
MapType = "map" "[" KeyType "]" ElementType .
KeyType = Type .
The comparison operators == and != must be fully defined for operands of the key type; thus the key type must not be a function, map, or slice. If the key type is an interface type, these comparison operators must be defined for the dynamic key values; failure will cause a run-time panic.
map[string]int
map[*T]struct{ x, y float64 }
map[string]interface{}
The number of map elements is called its length. For a map m, it can be discovered using the built-in function len and may change during execution. Elements may be added during execution using assignments and retrieved with index expressions; they may be removed with the delete built-in function.
A new, empty map value is made using the built-in function make, which takes the map type and an optional capacity hint as arguments:
make(map[string]int)
make(map[string]int, 100)
The initial capacity does not bound its size: maps grow to accommodate the number of items stored in them, with the exception of nil maps. A nil map is equivalent to an empty map except that no elements may be added.
Channel types
A channel provides a mechanism for concurrently executing functions to communicate by sending and receiving values of a specified element type. The value of an uninitialized channel is nil.
ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" ) ElementType .
The optional <- operator specifies the channel direction, send or receive. If no direction is given, the channel is bidirectional. A channel may be constrained only to send or only to receive by conversion or assignment.
chan T // can be used to send and receive values of type T
chan<- float64 // can only be used to send float64s
<-chan int // can only be used to receive ints
The <- operator associates with the leftmost chan possible:
chan<- chan int // same as chan<- (chan int)
chan<- <-chan int // same as chan<- (<-chan int)
<-chan <-chan int // same as <-chan (<-chan int)
chan (<-chan int)
A new, initialized channel value can be made using the built-in function make, which takes the channel type and an optional capacity as arguments:
make(chan int, 100)
The capacity, in number of elements, sets the size of the buffer in the channel. If the capacity is zero or absent, the channel is unbuffered and communication succeeds only when both a sender and receiver are ready. Otherwise, the channel is buffered and communication succeeds without blocking if the buffer is not full (sends) or not empty (receives). A nil channel is never ready for communication.
A channel may be closed with the built-in function close. The multi-valued assignment form of the receive operator reports whether a received value was sent before the channel was closed.
A single channel may be used in send statements, receive operations, and calls to the built-in functions cap and len by any number of goroutines without further synchronization. Channels act as first-in-first-out queues. For example, if one goroutine sends values on a channel and a second goroutine receives them, the values are received in the order sent.
Go语言的各种Print函数
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error) {}
func Printf(format string, a ...interface{}) (n int, err error) {}
func Sprintf(format string, a ...interface{}) string {}
func Errorf(format string, a ...interface{}) error {}
func Fprint(w io.Writer, a ...interface{}) (n int, err error) {}
func Print(a ...interface{}) (n int, err error) {}
func Sprint(a ...interface{}) string {}
func Fprintln(w io.Writer, a ...interface{}) (n int, err error) {}
func Println(a ...interface{}) (n int, err error) {}
func Sprintln(a ...interface{}) string {}
导入包,已导出名
- 程序都是从 main 开发,main 包的源码需要以 package main 语句开始,jupyter 中不方便展示,so 被注释
- 本示例代码通过导入路径 "fmt"、"math/rand" 以及直接导入 "math" 来示范包的导入与使用;
- 按照约定,包名与导入路径的最后一个元素一致。例如,"math/rand" 包中的源码均以 package rand 语句开始。
- 如果一个名字以大写字母开头,那么它就是已导出的(exported)。例如,Pi 就是个已导出名,它导出自 math 包。已导出意味着它是 public 的,也就是说在包外部可被调用,否则如果是小写字母开头,则在包外部无法被调用。
// package main
import ( // "分组" 形式的导入语句,是更好的导入形式。
"fmt"
"math/rand"
"github.com/user_name/project_name" // 亦可使用 `go get xxx`下载 github 资源后,使用此语句导入(project_name.xxx[()])
)
import "math" // 亦可使用分别独立的导入形式
fmt.Println("My favorite number is", rand.Intn(10))
fmt.Println(math.Pi)
My favorite number is 5
3.141592653589793
函数
- 函数可以没有参数或接受多个参数
- 函数可以返回任意数量的返回值
- 当连续两个或多个函数的已命名形参类型相同时,除最后一个类型以外,其它都可以省略
- Go 的返回值可被命名,它们会被视作定义在函数顶部的变量。返回值的名称应当具有一定的意义,它可以作为文档使用。没有参数的 return 语句返回已命名的返回值,应当仅用在短函数中,在长的函数中会影响代码可读性。
- go 编译器会自动添加分号(😉,亦可显性主动添加,实现将多语句拼凑至一行中,演示用,其他时不推荐此
import "fmt"
func add(x int, y int) int { return x + y }; fmt.Println(add(1, 2))
func swap(x, y string) (string, string) { return y, x }; fmt.Println(swap("hello", "world"))
func print_nil() { fmt.Println("i am nil") }; print_nil()
func split(sum int) (x, y int) { x, y = sum * 4 / 9, sum - x; return }; fmt.Println(split(17))
3
world hello
i am nil
7 17
类型 T (Type)
Each type T has an underlying type: If T is one of the predeclared boolean, numeric, or string types, or a type literal, the corresponding underlying type is T itself. Otherwise, T's underlying type is the underlying type of the type to which T refers in its type declaration.
type T1 string
type T2 T1
type T3 []T1
type T4 T3
Type 包括基本类型和高级类型,Type 在使用时依附于 常量(variable) or 变量(constant) 的形式。
-
基本类型:
Boolean,String,Numeric -
高级类型:
Array,Map,Slice,Struct,Pointer,Function,Interface,Channel
基本类型 (underlying type)
- Boolean types :
bool (true / false)
- String types :
string
- Numeric types :
uint8 the set of all unsigned 8-bit integers (0 to 255)
uint16 the set of all unsigned 16-bit integers (0 to 65535)
uint32 the set of all unsigned 32-bit integers (0 to 4294967295)
uint64 the set of all unsigned 64-bit integers (0 to 18446744073709551615)
int8 the set of all signed 8-bit integers (-128 to 127)
int16 the set of all signed 16-bit integers (-32768 to 32767)
int32 the set of all signed 32-bit integers (-2147483648 to 2147483647)
int64 the set of all signed 64-bit integers (-9223372036854775808 to 9223372036854775807)
float32 the set of all IEEE-754 32-bit floating-point numbers
float64 the set of all IEEE-754 64-bit floating-point numbers
complex64 the set of all complex numbers with float32 real and imaginary parts
complex128 the set of all complex numbers with float64 real and imaginary parts
byte alias for uint8
rune alias for int32, 表示一个 Unicode 码点
// The value of an n-bit integer is n bits wide and represented using two's complement arithmetic.
There is also a set of predeclared numeric types with implementation-specific sizes :
uint either 32 or 64 bits
int same size as uint
uintptr an unsigned integer large enough to store the uninterpreted bits of a pointer value
// int, uint 和 uintptr 在 32 位系统上通常为 32 位宽,在 64 位系统上则为 64 位宽
// 当你需要一个整数值时应使用 int 类型,除非你有特殊的理由使用固定大小或无符号的整数类型
常量
常量使用 const 关键字,可以是字符、字符串、布尔值或数值,不能用 := 语法声明,一个未指定类型的常量由上下文来决定其类型
import "fmt"
const Pi float64 = 3.14
const World string = "世界"
const Truth = true
fmt.Println("Happy", Pi, World, "?", Truth)
Happy 3.14 世界 ? true
数值常量是高精度的值,int 类型最大可以存储一个 64 位的整数,根据平台(32位 or 64位)不同有时会少一些
const (
Big = 1 << 100 // 将 1 左移 100 位来创建一个非常大的数字, 即这个数的二进制是 1 后面跟着 100 个 0
Small = Big >> 99 // 再往右移 99 位,即 Small = 1 << 1,或者说 Small = 2
)
func needInt(x int) int { return x*10 + 1 }
func needFloat(x float64) float64 { return x * 0.1 }
fmt.Println(needInt(Small), "/", needFloat(Small), "/", needFloat(Big))
21 / 0.2 / 1.2676506002282295e+29
变量
- var 语句用于声明一个变量列表,跟函数的参数列表一样,类型在最后,var 语句可以出现在包或函数级别
- 变量的初始化:变量声明可以包含初始值,每个变量对应一个(支持平行赋值),如果未赋予初始值,默认会被初始化为其所属类型的 0 值
- 如果初始化值已存在,则可以省略类型,变量会从初始值中获得类型
- 短变量声明:在函数中,简洁赋值语句 := 可在类型明确的地方代替 var 声明
- 函数外的每个语句都必须以关键字开始(
var,func等等),因此:=结构不能在函数外使用 - 变量存在作用域
import "fmt"
var c, python, java bool
var i int
fmt.Println(i, c, python, java)
var j, k int = 1, 2
func main() {
var c, python, java = true, false, "no!"
l, m := 5, 6
fmt.Println(j, k, l, m)
fmt.Println(i, c, python, java)
}; main(); fmt.Println(i, c, python, java)
0 false false false
1 2 5 6
0 true false no!
0 false false false
同导入语句一样,变量声明也可以 "分组" 成一个语法块
import ("fmt"; "math/cmplx")
var (
ToBe bool = false
MaxInt uint64 = 1<<64 - 1
z complex128 = cmplx.Sqrt(-5 + 12i)
)
fmt.Printf("Type: %T Value: %v\n", ToBe, ToBe)
fmt.Printf("Type: %T Value: %v\n", MaxInt, MaxInt)
fmt.Printf("Type: %T Value: %v\n", z, z)
Type: bool Value: false
Type: uint64 Value: 18446744073709551615
Type: complex128 Value: (2+3i)
零值:没有明确初始值的变量声明会被赋予它们的 零值
数值类型为 -> 0
布尔类型为 -> false
字符串为 -> ""
import "fmt"
var i int
var f float64
var b bool
var s string
fmt.Printf("%v %v %v %q\n", i, f, b, s)
0 0 false ""
与 C 不同的是,Go 在不同类型的项之间赋值时需要显式转换。类型转换:表达式 T(v) 将值 v 转换为类型 T
一些关于数值的转换:
var i int = 42
var f float64 = float64(i)
var u uint = uint(f)
或者,更加简单的形式:
i := 42
f := float64(i)
u := uint(f)
import "fmt"
import "math"
var x, y int = 3, 4
var f float64 = math.Sqrt(float64(x*x + y*y)) // 试着移除例子中 float64 的转换看看会发生什么。
var z uint = uint(f) // 试着移除例子中 uint 的转换看看会发生什么。
fmt.Println(x, y, z)
3 4 5
类型推导:在声明一个变量而不指定其类型时(即:使用不带类型的 := 语法或 var = 表达式 语法),变量的类型由右值推导得出
当右值声明了类型时,新变量的类型与其相同:
var i int
j := i // j 也是一个 int
不过当右边包含未指明类型的数值常量时,新变量的类型就可能是 int, float64 或 complex128 了,这取决于常量的精度:
i := 42 // int
f := 3.142 // float64
g := 0.867 + 0.5i // complex128
import "fmt"; fmt.Printf("%T - %T - %T", 42, 3.142, 42.0 + 0.4i)
int - float64 - complex128
流程控制语句:for、if、else、switch 和 defer
for 循环
Go 只有一种循环结构:for 循环,基本的 for 循环由三部分组成,它们用分号隔开:
- 初始化语句(optional):在第一次迭代前执行,通常为一句短变量声明(支持平行赋值),该变量声明仅在 for 语句的作用域中可见。
- 条件表达式:在每次迭代前求值,一旦条件表达式的布尔值为 false,循环迭代就会终止。
- 后置语句(optional):在每次迭代的结尾执行
注意:和 C、Java、JavaScript 之类的语言不同,Go 的 for 语句后面的三个构成部分外没有小括号, 大括号 { } 则是必须的。
e.g.
for i := 0; i < 10; i++ { } // 标准的 for 写法
for i, j := 0, 0; i < 10; i++ { } // 前置语句可以平行赋值
for ; sum < 1000; { } // 初始化语句和后置语句是可选的
for sum < 1000 { } // for 是 Go 中的 "while",此时你可以去掉分号,因为 C 的 while 在 Go 中叫做 for。
for { } // 无限循环:如果省略循环条件,该循环就不会结束,因此无限循环可以写得很紧凑
if - else 语句
Go 的 if 语句与 for 循环类似,表达式外无需小括号 ( ) ,而大括号 { } 则是必须的。
if 语句也可以在条件表达式前执行一个简单的语句,该语句声明的变量作用域仅在 if 或 其对应的任何 else 块之内使用。
e.g.
if i < 10 { ... }
if i := 0; i < 10 { ... }
if i < 10 { ... } else { ... }
if i < 10 { ... } else if i < 20 { ... } else { ... }
练习:循环与函数 (牛顿法 实现平方根函数 )
计算机通常使用循环来计算 \(x\) 的平方根。从某个猜测的值 \(z\) 开始,我们可以根据 \(z^2\) 与 \(x\) 的近似度来调整 \(z\),产生一个更好的猜测:
z -= (z*z - x) / (2*z)
重复调整的过程次数越多,猜测的结果会越来越精确,得到的答案也会尽可能接近实际的平方根。
提示:可使用类型转换或浮点数语法来声明并初始化一个浮点数值:
z := 1.0
z := float64(1)
可以尝试不同的初始猜测值 \(z\),以及循环次数,然后观察算法是如何逼近结果的、提升的速度有多快等等。猜测的结果可以与标准库中的 math.Sqrt 进行比对。如果你对该算法的细节感兴趣,上面的 \(z^2 - x\) 是 \(z^2\) 到它所要到达的值(即 \(x\))的距离,除以的 \(2z\) 为 \(z^2\) 的导数,我们通过 \(z^2\) 的变化速度来改变 \(z\) 的调整量。 这种通用方法叫做 牛顿法,它对很多函数,特别是平方根而言非常有效。
import ("fmt"; "math")
func Sqrt(x float64) float64 {
z := float64(999)
for i := 0; i < 10; i++ {
z -= (z*z - x) / (2 * z)
}
return z
}
fmt.Println("猜测结果:", Sqrt(2))
fmt.Println("标准结果:", math.Sqrt(2))
猜测结果: 1.5790422108719717
标准结果: 1.4142135623730951
switch 语句
- switch 是编写一连串 if - else 语句的简便方法
- 可以在条件表达式前执行一个简单的语句
- 它运行第一个使得值等于条件表达式的 case 语句,自动在每个 case 后面提供所需的 break 语句,所以一旦满足条件,后面的 case 将不被执行
- 如果在 case 后面显性的使用关键字
fallthrough语句,那么 go 会继续执行后面的 case - switch 的 case 无需为常量,且取值不必为整数
- default 是可以选的,当所有 case 均未匹配时,default 语句块的内容将被执行
import ("fmt"; "runtime")
switch os := runtime.GOOS; os {
case "darwin":
fmt.Println("Go runs on OS X.")
fallthrough
case "linux":
fmt.Println("Go runs on Linux.")
fallthrough
default:
fmt.Printf("Case by default:%s.\n", os) // freebsd, openbsd, plan9, windows...
}
Go runs on Linux.
Case by default:linux.
switch 的求值顺序为从上到下顺次执行,直到匹配成功时停止
e.g.
switch i {
case 0:
case f(): // 在 i==0 时 f() 不会被调用
}
import ("fmt"; "time")
fmt.Println("When's Saturday?")
today := time.Now().Weekday()
switch time.Saturday {
case today + 0:
fmt.Println("Today.")
case today + 1:
fmt.Println("Tomorrow.")
case today + 2:
fmt.Println("In two days.")
default:
fmt.Println("Too far away.")
}
When's Saturday?
Tomorrow.
没有条件的 switch 同 switch true 一样,这种形式能将一长串 if-then-else 写得更加清晰
import ("fmt"; "time")
t := time.Now()
switch { // 相当于 switch true {
case t.Hour() < 12:
fmt.Println("Good morning!")
case t.Hour() < 17:
fmt.Println("Good afternoon.")
default:
fmt.Println("Good evening.")
}
Good morning!
defer 语句会将函数推迟到外层函数返回之后执行
- 推迟调用的函数其参数会立即求值,但直到外层函数返回前该函数都不会被调用
- 推迟的函数调用会被压入一个栈中。当外层函数返回时,被推迟的函数会按照后进先出的顺序调用
- 更多关于 defer 语句的信息,请阅读此博文 https://blog.go-zh.org/defer-panic-and-recover
import "fmt"
fmt.Println("counting")
defer fmt.Println(0)
defer fmt.Println(1)
defer fmt.Println(2)
fmt.Println("done")
counting
done
2
1
0
更多类型:struct、slice 和映射
高级类型:Array,Map,Slice,Struct,Pointer,Function,Interface,Channel
指针(Pointer)
Go 拥有指针,指针保存了值的内存地址。
类型 *T 是指向 T 类型值的指针。其零值为 nil。
var p *int
& 操作符会生成一个指向其操作数的指针。
i := 42
p = &i
* 操作符表示指针指向的底层值。
fmt.Println(*p) // 通过指针 p 读取 i
*p = 21 // 通过指针 p 设置 i
指针也就是通常所说的 "间接引用" 或 "重定向",与 C 不同的是 Go 没有指针运算
import "fmt"
i, j := 1, 110
p := &i; fmt.Println(p, *p)
*p = 3 ; fmt.Println(i)
p = &j
*p += 1 // *p = *p + 1
fmt.Println(j)
0x7f5b6a9541f0 1
3
111
结构体(Struct)
- 一个结构体(struct)就是一组字段(field)
- 结构体字段使用点号来访问
- 结构体字段可以通过结构体指针来访问,例如
(*p).X,为了简化,可使用隐式间接引用,直接写p.X就可以。 - 可以通过直接列出字段的值来初始化(新分配)一个结构体
- 使用
Name:语法可以仅列出部分字段(与字段名的顺序无关) - 特殊的前缀
&返回一个指向结构体的指针。
import "fmt"
type Vertex struct {
X int
Y, Z int
}
var (
v1 = Vertex{1, 2, 3} // 创建一个 Vertex 类型的结构体
v2 = Vertex{X: 1} // Y:0 Z:0 被隐式地赋予
v3 = Vertex{} // X:0 Y:0 Z:0
v4 = &Vertex{1, 2, 3} // 创建一个 *Vertex 类型的结构体(指针)
)
fmt.Println("v1 : ", v1, "\nv2 : ", v2, "\nv3 : ", v3, "\nv4 : ", v4, "\n(*v4).Y : ", (*v4).Y, "\nv4.Y : ", v4.Y)
v1.X = 4;
fmt.Println("v1.X : ", v1.X)
p := &v1; p.X = 1e9;
fmt.Println("&v1 : ", &v1, "\n&(v1.X) : ", &(v1.X), "\n(*p).X : ", (*p).X, "\np.X : ", p.X)
v1 : {1 2 3}
v2 : {1 0 0}
v3 : {0 0 0}
v4 : &{1 2 3}
(v4).Y : 2
v4.Y : 2
v1.X : 4
&v1 : &{1000000000 2 3}
&(v1.X) : 0x7f5b64866200
(p).X : 1000000000
p.X : 1000000000
数组(Array)
类型 [n]T 表示拥有 n 个 T 类型的值的数组
将变量 a 声明为拥有 10 个整数的数组:
var a [10]int
数组的长度 n 是其类型的一部分,因此数组不能改变大小,这看起来是个限制,不过没关系,Go 提供了更加便利的方式(切片)来使用数组。
数组在初始化时:
- 元素写在同一行,最后一个元素可以不带逗号
- 元素竖着排列,最后一个元素必须也要带一个逗号,否则报错
import "fmt"
var a [2]string
a[0], a[1] = "Hello", "World"
fmt.Println(a, a[0], a[1])
b := [3]int{2, 3, 5}
c := [6]int{
7,
9,
}
fmt.Println(b, c)
[Hello World] Hello World
[2 3 5] [7 9 0 0 0 0]
切片(Slice)
类型 []T 表示一个元素类型为 T 的切片。
切片通过两个下标来界定,即一个上界和一个下界,二者以冒号分隔:
a[low : high]
[low, high) 它会选择一个半开区间(左闭右开),包括第 low 个元素,但排除第 high 个元素
以下表达式创建了一个切片,它包含 a 中下标从 1 到 3 的元素:
a[1:4]
- 每个数组的大小都是固定的,而切片(slice)则为数组元素提供动态大小的、灵活的视角,在实践中,切片比数组更常用。
- 切片并不存储任何数据,它只是描述了底层数组中的一段,就像是对数组的引用
- 更改切片的元素会修改其底层数组中对应的元素,与它共享底层数组的切片都会观测到这些修改
import "fmt"
a := [6]int{2, 3, 5, 7, 11, 13}
var s []int = a[1:4]
fmt.Println(s)
names := [4]string{ "John", "Paul", "George", "Ringo" }
fmt.Println(names)
b := names[0:2]
c := names[1:3]
fmt.Println(b, c)
c[0] = "XXX"
fmt.Println(b, c, names)
[3 5 7]
[John Paul George Ringo]
[John Paul] [Paul George]
[John XXX] [XXX George] [John XXX George Ringo]
切片文法类似于没有长度的数组文法
这是一个数组文法:
[3]bool{true, true, false}
下面这样则会创建一个和上面相同的数组,然后构建一个引用了它的切片:
[]bool{true, true, false}
import "fmt"
q := []int{2, 3, 5}
r := []bool{ true, false, true }
fmt.Println(q, r)
s := []struct {
i int
b bool
}{
{2, true},
{3, false},
{5, true},
}
fmt.Println(s);print()
[2 3 5] [true false true]
[{2 true} {3 false} {5 true}]
切片的默认行为:在进行切片时,你可以利用它的默认行为来忽略上下界
切片下界的默认值为 0
切片上界得默认值为该切片的长度
对于数组
var a [10]int
来说,以下切片是等价的:
a[0:10]
a[:10]
a[0:]
a[:]
import "fmt"
s := []int{2, 3, 5, 7, 11, 13}
s = s[1:4]
fmt.Println(s)
s = s[:2]
fmt.Println(s)
s = s[1:]
fmt.Println(s)
[3 5 7]
[3 5]
[5]
切片拥有 长度 和 容量
- 切片的长度就是它所包含的元素个数
- 切片的容量是从它的第一个元素开始数,到其底层数组元素末尾的个数,这也意味着前面的元素被舍弃后就找不回来了,后面元素的可以被拓展回来
- 切片 s 的长度和容量可通过表达式
len(s)和cap(s)来获取 - 你可以通过重新切片来扩展一个切片,给它提供足够的容量
- 切片的零值是
nil,nil 切片的长度和容量为 0,且没有底层数组
试着修改示例程序中的切片操作,向外扩展它的容量,看看会发生什么
import "fmt"
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s)
if s == nil {
fmt.Print("nil!")
}
}
s := []int{2, 3, 5, 7, 11, 13}
printSlice(s)
// 截取切片使其长度为 0,这个不是 nil 切片,因为其 cap = 6
s = s[:0]
printSlice(s)
// 拓展其长度
s = s[:4]
printSlice(s)
// 舍弃前两个值,舍弃后就找不回来了,cap 从 6 变为 4
s = s[2:]
printSlice(s)
s = s[:cap(s)]
printSlice(s)
var s_nil []int // nil 切片,len 和 cap 均为 0
printSlice(s_nil)
len=6 cap=6 [2 3 5 7 11 13]
len=0 cap=6 []
len=4 cap=6 [2 3 5 7]
len=2 cap=4 [5 7]
len=4 cap=4 [5 7 11 13]
len=0 cap=0 []
nil!
make
切片可以用内建函数 make 来创建,这也是你创建动态数组的方式。它会分配一个元素为零值的数组并返回一个引用了它的切片:
a := make([]int, 5) // len(a)=5
b := make([]int, 0, 5) // len(b)=0, cap(b)=5
b = b[:cap(b)] // len(b)=5, cap(b)=5
b = b[1:] // len(b)=4, cap(b)=4
import "fmt"
func printSlice(s string, x []int) { fmt.Printf("%s len=%d cap=%d %v\n", s, len(x), cap(x), x) }
a := make([]int, 0)
printSlice("a", a)
b := make([]int, 0, 5)
printSlice("b", b)
c := make([]int, 2, 5)
printSlice("c", c)
d := c[:3]
printSlice("d", d)
e := d[1:5]
printSlice("e", e)
a len=0 cap=0 []
b len=0 cap=5 []
c len=2 cap=5 [0 0]
d len=3 cap=5 [0 0 0]
e len=4 cap=4 [0 0 0 0]
切片的切片:切片可包含任何类型,甚至包括其它的切片
import (
"fmt"
"strings"
)
// 创建一个井字板(经典游戏)
board := [][]string{
[]string{"_", "_", "_"},
[]string{"_", "_", "_"},
[]string{"_", "_", "_"},
}
// 两个玩家轮流打上 X 和 O
board[0][0] = "X"
board[2][2] = "O"
board[1][2] = "X"
board[1][0] = "O"
board[0][2] = "X"
for i := 0; i < len(board); i++ { fmt.Printf("%s\n", strings.Join(board[i], " ")) }
fmt.Println(board)
X _ X
O _ X
_ _ O
[[X _ X] [O _ X] [_ _ O]]
向切片追加元素
为切片追加新的元素是种常用的操作,为此 Go 提供了内建的 append 函数。内建函数的文档对此函数有详细的介绍。
func append(s []T, vs ...T) []T
append 的第一个参数 s 是一个元素类型为 T 的切片,其余类型为 T 的值将会追加到该切片的末尾。
append 的结果是一个包含原切片所有元素加上新添加元素的切片。
当 s 的底层数组太小,不足以容纳所有给定的值时,它就会分配一个更大的数组。返回的切片会指向这个新分配的数组。
(要了解关于切片的更多内容,请阅读文章 Go 切片:用法和本质。)
https://blog.go-zh.org/go-slices-usage-and-internals
import "fmt"
func printSlice(s []int) { fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s) }
var s []int; printSlice(s)
s = append(s, 0); printSlice(s)
s = append(s, 1); printSlice(s)
s = append(s, 2, 3, 4); printSlice(s)
len=0 cap=0 []
len=1 cap=1 [0]
len=2 cap=2 [0 1]
len=5 cap=6 [0 1 2 3 4]
Range
for 循环的 range 形式可遍历切片或映射,每次迭代会返回两个值:
- 当前元素的下标
- 当前元素的下标所对应元素的一份副本
使用 _ 接收的值将直接被舍弃,如果只想接收 index,那么 _ 也可以不用写:
for index, _ := range pow
for index := range pow
for _, value := range pow
整数进制转换:https://www.mallocfree.com/interview/c-15-0x0d.htm
二进制位运算:https://blog.csdn.net/swty3356667/article/details/78703650
import "fmt"
var pow = []int{1, 2, 4}
for i, v := range pow { fmt.Printf("2**%d = %d\n", i, v) }
pow = make([]int, 10)
for i := range pow { pow[i] = 1 << uint(i) } // shift count i must be unsigned integer, so we need use uint()
for _, value := range pow { fmt.Printf("%d ", value) }
20 = 1
21 = 2
2**2 = 4
1 2 4 8 16 32 64 128 256 512
练习:切片
例子中引用了 golang.org/x/tour/pic,为了方便,直接拷贝源码到此处,源码中只包含了两个方法 Show() and ShowImage
本例的目的是画出一些函数图像,需要自己实现 Pic(),它应当返回一个长度为 dy 的切片,其中每个元素是一个长度为 dx,元素类型为 uint8 的切片
当你运行此程序时,它会将每个整数解释为灰度值(其实是蓝度值)并显示它所对应的图像
图像的选择由你来定,几个有趣的函数包括 (x+y)/2,x*y,x^y,x*log(y) 和 x%(y+1) 供你参考
提示:
- 需要使用循环来分配
[][]uint8中的每个[]uint8 - 请使用
uint8(intValue)在类型之间转换 - 你可能会用到
math包中的函数
划线的例子:
https://www.cnblogs.com/ghj1976/p/3441536.html
此处直接调用了 _ctx.Display.PNG(),回头查看源码,看看究竟是如何实现在 jupyter 中 display an image:
https://github.com/yunabe/lgo
//import "golang.org/x/tour/pic"
import (
"bytes"
"encoding/base64"
"fmt"
"image"
"image/png"
)
func Show(f func(int, int) [][]uint8) {
const (
dx = 256
dy = 256
)
data := f(dx, dy)
m := image.NewNRGBA(image.Rect(0, 0, dx, dy))
for y := 0; y < dy; y++ {
for x := 0; x < dx; x++ {
v := data[y][x]
i := y*m.Stride + x*4
m.Pix[i] = v
m.Pix[i+1] = v
m.Pix[i+2] = 255
m.Pix[i+3] = 255
}
}
ShowImage(m)
}
func ShowImage(m image.Image) {
var buf bytes.Buffer
err := png.Encode(&buf, m)
if err != nil {
panic(err)
}
// base64 encode to string
// enc := base64.StdEncoding.EncodeToString(buf.Bytes())
// fmt.Println("IMAGE(base64):" + enc)
// display png to jupyter directly via lgo's function _ctx.Display.PNG()
_ctx.Display.PNG(buf.Bytes(), nil)
}
func Pic(dx, dy int) [][]uint8 {
a := make([][]uint8, dy)
for y := range a {
b := make([]uint8, dx)
for x := range b {
b[x] = uint8(x*y)
}
a[y] = b
}
return a
}
Show(Pic)
映射(Map)
- 映射将键映射到值,映射的零值为
nil,nil 映射既没有键,也不能添加键,可使用 make 函数,它会返回给定类型的映射,并将其初始化备用 - 映射的文法与结构体相似,不过必须有键名,若顶级类型只是一个类型名,你可以在文法的元素中省略它(e.g.
Vertex) - 可对映射 m 进行插入,修改,删除动作,也可以通过平行赋值检测某个键是否存在
m[key] = elem
elem = m[key]
delete(m, key)
elem, ok = m[key]
elem, ok := m[key]
import "fmt"
type Vertex struct { Lat, Long float64 }
var m1 map [string] Vertex
// m1["Bell Labs"] = Vertex{ 40.68433, -74.39967 } // assign value directly -> panic: assignment to entry in nil map
m1 = make(map [string] Vertex)
m1["Bell Labs"] = Vertex{ 40.68433, -74.39967 }
fmt.Println("m1[\"Bell Labs\"] : ", m1["Bell Labs"])
var m2 = map[string]Vertex{
"Bell Labs": Vertex{ 40.68433, -74.39967 },
"Google" : { 37.42202, -122.08408 },
}
fmt.Println("m2 : ", m2)
m3 := make(map[string]int)
m3["Answer"] = 42; fmt.Println("m3[\"Answer\"] : ", m3["Answer"]) // insert
m3["Answer"] = 48; fmt.Println("m3[\"Answer\"] : ", m3["Answer"]) // update
delete(m3, "Answer"); fmt.Println("m3[\"Answer\"] : ", m3["Answer"]) // delete
elem, ok := m3["Answer"]; fmt.Println("m3[\"Answer\"] : ", elem, "Present?", ok) // check if the element exists
m1["Bell Labs"] : {40.68433 -74.39967}
m2 : map[Google:{37.42202 -122.08408} Bell Labs:{40.68433 -74.39967}]
m3["Answer"] : 42
m3["Answer"] : 48
m3["Answer"] : 0
m3["Answer"] : 0 Present? false
练习:映射
实现 WordCount(),它应当返回一个映射,其中包含字符串 s 中每个 "单词" 的个数
函数 wc.Test 会对此函数执行一系列测试用例,并输出成功还是失败
你会发现 strings.Fields 很有帮助
// import "golang.org/x/tour/wc"
import "fmt"
import "strings"
// Test runs a test suite against f.
func Test(f func(string) map[string]int) {
ok := true
for _, c := range testCases {
got := f(c.in)
if len(c.want) != len(got) {
ok = false
} else {
for k := range c.want {
if c.want[k] != got[k] {
ok = false
}
}
}
if !ok {
fmt.Printf("FAIL\n f(%q) =\n %#v\n want:\n %#v",
c.in, got, c.want)
break
}
fmt.Printf("PASS\n f(%q) = \n %#v\n", c.in, got)
}
}
var testCases = []struct {
in string
want map[string]int
}{
{"I am learning Go!", map[string]int{
"I": 1, "am": 1, "learning": 1, "Go!": 1,
}},
{"The quick brown fox jumped over the lazy dog.", map[string]int{
"The": 1, "quick": 1, "brown": 1, "fox": 1, "jumped": 1,
"over": 1, "the": 1, "lazy": 1, "dog.": 1,
}},
{"I ate a donut. Then I ate another donut.", map[string]int{
"I": 2, "ate": 2, "a": 1, "donut.": 2, "Then": 1, "another": 1,
}},
{"A man a plan a canal panama.", map[string]int{
"A": 1, "man": 1, "a": 2, "plan": 1, "canal": 1, "panama.": 1,
}},
}
func WordCount(s string) map[string]int {
//return map[string]int{"x": 1}
// m := make(map[string]int)
// words := strings.Fields(s)
// for i := 0; i < len(words); i++ {
// if v, exists := m[words[i]]; exists {
// m[words[i]] = v + 1
// } else {
// m[words[i]] = 1
// }
// }
// return m
m := make(map[string]int)
for _, value := range strings.Fields(s) {
m[value] += 1
}
return m
}
Test(WordCount)
PASS
f("I am learning Go!") =
map[string]int{"learning":1, "Go!":1, "I":1, "am":1}
PASS
f("The quick brown fox jumped over the lazy dog.") =
map[string]int{"the":1, "lazy":1, "The":1, "quick":1, "brown":1, "fox":1, "jumped":1, "over":1, "dog.":1}
PASS
f("I ate a donut. Then I ate another donut.") =
map[string]int{"I":2, "ate":2, "a":1, "donut.":2, "Then":1, "another":1}
PASS
f("A man a plan a canal panama.") =
map[string]int{"A":1, "man":1, "a":2, "plan":1, "canal":1, "panama.":1}
函数
函数也是值,它可以像其它值一样被传递,用作函数的参数或返回值。函数作为参数被传递可以实现
callback()
CALLBACK,即回调函数,是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用为调用它所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
import ("fmt"; "math")
func compute(callback func(float64, float64) float64) float64 {
return callback(3, 4)
}
hypot := func(x, y float64) float64 {
return math.Sqrt(x*x + y*y)
}
fmt.Println(hypot(5, 12), compute(hypot), compute(math.Pow)); print()
13 5 81
// p_callback 是在函数内,而不是方法内,需要考虑并重新用方法来实现。。。。。。。。。。。。。。。。。。。。。。。。。。
import ("fmt"; "math")
type callback func(float64, float64) float64
func compute(callback *callback) float64 {
return (*callback)(3, 4)
}
var hypot callback = func(x, y float64) float64 { return math.Sqrt(x*x + y*y) }
mathPow := callback(math.Pow)
fmt.Println(hypot(5, 12), compute(&hypot), compute(&mathPow)); print()
13 5 81
import ("fmt"; "math")
type callback func(float64, float64) float64
type S struct {
a float64
b float64
}
func (s S) compute(callback *callback) float64 {
return (*callback)(s.a, s.b)
}
hypot := callback(func(x, y float64) float64 { return math.Sqrt(x*x + y*y) })
s := S{3, 4}
fmt.Println(s.compute(&hypot))
mathPow := callback(math.Pow)
fmt.Println(s.compute(&mathPow)); print()
5
81
函数作为返回值被传递可以实现 闭包
闭包是一个函数值,它引用了其函数体之外的变量,该函数可以访问并赋予其引用的变量的值,换句话说,该函数被这些变量 "绑定" 在一起
import "fmt"
func adder() func(int) int { // 函数 adder 返回一个闭包,每个闭包都被绑定在其各自的 sum 变量上
sum := 0
return func(x int) int {
sum += x
return sum
}
}
pos, neg := adder(), adder()
for i := 0; i < 5; i++ {
fmt.Println(
pos(i),
neg(-2*i),
)
}
0 0
1 -2
3 -6
6 -12
10 -20
练习:斐波纳契闭包
实现一个 fibonacci 函数,它返回一个函数(闭包),该闭包返回一个斐波纳契数列 (0, 1, 1, 2, 3, 5, ...)
import "fmt"
func fibonacci() func() int {
a, b := 1, 0
return func() int {
a, b = b, a + b
return a
}
}
f := fibonacci()
for i := 0; i < 10; i++ {
fmt.Print(f(), ", ")
}
fmt.Print("...")
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
方法
-
Go 没有类的概念,不过你可以为
结构体(应用最多)类型定义方法,或更一般的说法是:可以为本包内且自定义的类型定义方法 -
方法就是一类带特殊的
接收者参数的函数,接收者在它自己的参数列表内,位于func关键字和方法名之间 -
更深层的理解是,方法就是将多个函数的参数提取出来了,参数共享了,而且此基础上还可以引出接口的概念,用接口去指定、限定或者说定义这些,也就是前面提到多的多个函数,比较抽象,但是这种概念或思想好处众多,也是为了解决一些问题而衍生出来的
- 函数:实现某个功能,独享参数(某数据结构)
- 方法:某数据结构(参数)实现多个方法,也就意味着实现了多个功能,且共享共一个数据结构提供的所有参数,亦可为方法传递单独使用的参数
- 接口:我们再规定一下某数据结构所实现的方法,这意味这把该接口给到其他人,其他人就知道且可以直接调用该接口内的方法(你必实现了的)
import ("fmt"; "math")
type Vertex struct { X, Y float64 }
v := Vertex{3, 4}
// Abs 方法 - 依附于结构体
func (v Vertex) Abs() float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) }
fmt.Println(v.Abs()) // 5
/*
方法即函数,记住:方法也只是个带接收者参数的函数,下面这个 Abs 的写法就是个正常的函数,功能并没有什么变化
*/
// Abs 函数
func Abs(v Vertex) float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) }
fmt.Println(Abs(v)) // 5
/*
你也可以为非结构体类型声明方法,比如 float64
你只能为在同一包内 "自定义" 类型的接收者声明方法,注意是同一包内,且自定义的类型
而不能为其它包内定义的类型(包括自定义或 int 之类的内建类型)的接收者声明方法
*/
// Abs 方法 - 依附于 float64
type MyFloat float64
func (f MyFloat) Abs(multiplier int) float64 { // f MyFloat 共享,亦可为方法传递单独使用的参数 Abs(multiplier int)
if f < 0 { return float64(-f * MyFloat(multiplier)) }
return float64(f * MyFloat(multiplier)) // 计算过程中:类型转换须显性 int -> MyFloat -> float64
}
f := MyFloat(-math.Sqrt2)
fmt.Println(f.Abs(100)) // 141.4213562373095
5
5
141.4213562373095
你也可以为 指针接收者 类型声明方法(与 值 接收者对比,值 接收者改变副本,指针接收者 改变原始值)
- 这意味着对于某类型
T,接收者的类型可以用*T的文法,此外,T不能是像*int这样的指针 - 指针接收者的方法可以修改接收者指向的值,由于方法经常需要修改它的接收者,所以指针接收者比值接收者更常用
- 本例中:若使用
值接收者,那么 Scale 方法会对原始 Vertex 值的副本进行操作,对于函数的其它参数也是如此 - 本例中:若使用
指针接收者,那么 Scale 方法会对原始 Vertex 值(main 函数中声明的 Vertex 的值)进行操作
推荐使用 指针接收者 类型声明方法的原因:
- 方法能够修改其接收者指向的值
- 这样可以避免在每次调用方法时复制该值,若值的类型为大型结构体时,这样做会更加高效
import ("fmt"; "math")
type Vertex struct { X, Y float64 }; v := Vertex{3, 4}
func (v Vertex) Abs ( ) float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) }
func (v Vertex) Scale_v(f float64) { v.X = v.X * f; v.Y = v.Y * f }
func (v *Vertex) Scale_p(f float64) { v.X = v.X * f; v.Y = v.Y * f }
v.Scale_v(10); fmt.Println(v.Abs())
v.Scale_p(10); fmt.Println(v.Abs())
5
50
方法与函数的不同之处
- 对于函数:带指针参数的函数必须接受一个指针,而接受一个值作为参数的函数必须接受一个指定类型的值
- 对于方法:无论方法的接收者是值还是指针,在方法被调用时,接收者又既可以为值也可能为指针,Go 会自动进行重定向
var v Vertex
func Scale(v Vertex, f float64) { }
Scale(v, 5) // OK
Scale(&v, 5) // panic
func Scale(v *Vertex, f float64) { }
Scale(&v, 5) // OK
Scale(v, 5) // panic
func (v Vertex) Scale(f float64) { }
v.Scale(5) // OK
p := &v
p.Scale(10) // OK - Go 会将语句 p.Scale(10) 解释为 (*p).Scale(10)
func (v *Vertex) Scale(f float64) { }
v.Scale(5) // OK - Go 会将语句 v.Scale(5) 解释为 (&v).Scale(5)
p := &v
p.Scale(10) // OK
import "fmt"
type Vertex struct { X, Y float64 }; v := Vertex{3, 4}
// 函数名可以与方法名相同,推荐 Abs() 接收者的类型为 *Vertex,即便 Abs() 并不需要修改其接收者
func Abs (v Vertex ) float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) }
func (v *Vertex) Abs ( ) float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) }
func Scale_v (v Vertex, f float64) { v.X = v.X * f; v.Y = v.Y * f }
func Scale_p (v *Vertex, f float64) { v.X = v.X * f; v.Y = v.Y * f }
func (v Vertex) Scale_v ( f float64) { v.X = v.X * f; v.Y = v.Y * f }
func (v *Vertex) Scale_p ( f float64) { v.X = v.X * f; v.Y = v.Y * f }
//Scale_v_Func(&v, 10) // cannot use &v (value of type *Vertex) as Vertex value in argument to Scale_v_Func
Scale_v( v, 10); fmt.Println( Abs(v)) // 5
//Scale_p_Func(v, 10) // cannot use v (variable of type Vertex) as *Vertex value in argument to Scale_p_Func
Scale_p(&v, 10); fmt.Println(v.Abs( )) // 50
v.Scale_v(10); fmt.Println(v.Abs( )) // 50
p := &v; p.Scale_v(10); fmt.Println( Abs(v)) // 50
v.Scale_p(10); fmt.Println( Abs(v)) // 500
p = &v; p.Scale_p(10); fmt.Println(v.Abs( )) // 5000
5
50
50
50
500
5000
通常来说,所有 给定类型的方法 都应该有 值 或 指针接收者,但并 不应该二者混用。(我们会在接下来几页中明白为什么。)
接口
- 接口类型是由一组方法签名定义的集合
- 接口类型的变量可以保存任何实现了这些方法的值
- 如果某
值未实现 或 未完全实现 某接口中定义的方法,那么该接口类型的变量无法接收该值
import ("fmt"; "math")
type Abser interface { Abs() float64 }
type MyFloat float64
func (f MyFloat) Abs() float64 {
if f < 0 { return float64(-f) }
return float64( f)
}
type Vertex struct { X, Y float64 }
func (v *Vertex) Abs() float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) }
var a Abser
f := MyFloat(-math.Sqrt2)
a = f // a MyFloat 实现了 Abser
fmt.Println(a.Abs()) // 1.4142135623730951
v := Vertex{3, 4}
a = &v // a *Vertex 实现了 Abser
fmt.Println(a.Abs()) // 5
// 下面一行,v 是一个 Vertex(而不是 *Vertex),所以没有实现 Abser。
// a = v // cannot use v (variable of type Vertex) as Abser value in assignment: missing method Abs
1.4142135623730951
5
接口与隐式实现
- 类型通过实现一个接口的所有方法来实现该接口,但无需专门显式声明,也就是说没有 "implements" 关键字
- 隐式接口从接口的实现中解耦了定义,这样接口的实现可以出现在任何包中,无需提前准备
- 因此,也就无需在每一个实现上增加新的接口名称,这样同时也鼓励了明确的接口定义
import "fmt"
type I interface { M() }
type T struct { S string }
func (t T) M() { fmt.Println(t.S) } // 此方法表示类型 T 实现了接口 I,但我们无需显式声明此事
t := T{"hello"}; t.M() // 你可以直接初始化值,并调用该值的 M 方法,此时与接口无关
var i I = T{"world"}; i.M() // 你也可以将初始化的值赋给该接口类型的变量,此时会帮你检测某值是否实现了某接口,如未实现,赋值时会报错
hello
world
接口也是值,它可以像其它值一样被传递,用作函数的参数或返回值
在内部,接口值可以看做包含值和具体类型的元组:
(value, type)
接口值保存了一个具体底层类型的具体值,接口值调用方法时会执行其底层类型的同名方法
type I interface { M() }
type T struct { S string }
func (t T) M() { }
func (t *T) M() { }
5:13: method M already declared for type T struct{S string}
4:13: other declaration of M
import ("fmt"; "math")
type I interface { M() }
type T struct { S string }
func (t T) M() { fmt.Println(t.S) }
var i I
i = T{"Hello"}; fmt.Printf("(%v, %T) ", i, i); i.M()
i = &T{"Hello"}; fmt.Printf("(%v, %T) ", i, i); i.M()
({Hello}, lgo_exec.T) Hello
(&{Hello}, *lgo_exec.T) Hello
import ("fmt"; "math")
type I interface { M() }
type T struct { S string }
func (t *T) M() { fmt.Println(t.S) }
var i I
i = &T{"Hello"}; fmt.Printf("(%v, %T) ", i, i); i.M()
t := T{"Hello"}; fmt.Printf("(%v, %T) ", t, t); t.M()
//i = T{"Hello"}
// 返回错误 cannot use (T literal) (value of type T) as I value in assignment: missing method M
(&{Hello}, *lgo_exec.T) Hello
({Hello}, lgo_exec.T) Hello
import ("fmt"; "math")
type I interface { M() }
type F float64
func (f F) M() { fmt.Println(f) }
var i I
i = F(math.Pi); fmt.Printf("(%v, %T) ", i, i); i.M()
(3.141592653589793, lgo_exec.F) 3.141592653589793
底层值为 nil 的接口值
即便接口内的具体值为 nil,方法仍然会被 nil 接收者调用
在一些语言中,这会触发一个空指针异常,但在 Go 中通常会写一些方法来优雅地处理它(如本例中的 M 方法)
注意: 保存了 nil 具体值的接口其自身并不为 nil
import "fmt"
type I interface { M() }
type T struct { S string }
func (t *T) M() {
if t == nil {
fmt.Println("<nil>")
return
}
fmt.Println(t.S)
}
var i I
var t *T
i = t
fmt.Printf("(%v, %T) ", i, i); i.M()
i = &T{"hello"}
fmt.Printf("(%v, %T) ", i, i); i.M()
(
(&{hello}, *lgo_exec.T) hello
nil 接口值
nil 接口值既不保存值也不保存具体类型
为 nil 接口调用方法会产生运行时错误,因为接口的元组内并未包含能够指明该调用哪个具体方法的类型。
import "fmt"
type I interface { M() }
var i I
fmt.Printf("(%v, %T)\n", i, i)
i.M() // panic: runtime error: invalid memory address or nil pointer dereference
(
空接口
指定了零个方法的接口值被称为 空接口:
interface{}
空接口可保存任何类型的值,因为每个类型都至少实现了零个方法
空接口被用来处理未知类型的值,例如,fmt.Print 可接受类型为 interface{} 的任意数量的参数
import "fmt"
var i interface{}
fmt.Printf("(%v, %T)\n", i, i)
i = 42
fmt.Printf("(%v, %T)\n", i, i)
i = "hello"
fmt.Printf("(%v, %T)\n", i, i)
(
(42, int)
(hello, string)
类型断言
类型断言提供了访问接口值底层具体值的方式:
t := i.(T)
该语句断言接口值 i 保存了具体类型 T,并将其底层类型为 T 的值赋予变量 t。
若 i 并未保存 T 类型的值,该语句就会触发一个恐慌。
为了 判断 一个接口值是否保存了一个特定的类型,类型断言可返回两个值:其底层值以及一个报告断言是否成功的布尔值。
t, ok := i.(T)
若 i 保存了一个 T,那么 t 将会是其底层值,而 ok 为 true。
否则,ok 将为 false 而 t 将为 T 类型的零值,程序并不会产生恐慌。
请注意这种语法和读取一个映射时的相同之处。
import "fmt"
var i interface{} = "hello"
s := i.(string)
fmt.Println(s)
s, ok := i.(string)
fmt.Println(s, ok)
f, ok := i.(float64)
fmt.Println(f, ok)
f = i.(float64) // panic: interface conversion: interface {} is string, not float64
hello
hello true
0 false
类型选择
类型选择 是一种按顺序从几个类型断言中选择分支的结构
类型选择与一般的 switch 语句相似,不过类型选择中的 case 为类型(而非值), 它们针对给定接口值所存储的值的类型进行比较
switch v := i.(type) {
case T:
// v 的类型为 T
case S:
// v 的类型为 S
default:
// 没有匹配,v 与 i 的类型相同
}
类型选择中的声明与类型断言 i.(T) 的语法相同,只是具体类型 T 被替换成了关键字 type
此选择语句判断接口值 i 保存的值类型是 T 还是 S。在 T 或 S 的情况下,变量 v 会分别按 T 或 S 类型保存 i 拥有的值。在默认(即没有匹配)的情况下,变量 v 与 i 的接口类型和值相同。
import "fmt"
func do(i interface{}) {
switch v := i.(type) {
case int:
fmt.Printf("Twice %v is %v\n", v, v*2)
case string:
fmt.Printf("%q is %v bytes long\n", v, len(v))
default:
fmt.Printf("I don't know about type %T!\n", v)
}
}
do(21)
do("hello")
do(true)
Twice 21 is 42
"hello" is 5 bytes long
I don't know about type bool!
Stringer 接口
fmt 包中定义的 Stringer 是最普遍的接口之一
type Stringer interface {
String() string
}
Stringer 是一个可以用字符串描述自己的类型。fmt 包(还有很多包)都通过此接口来打印值
相当于 java 中的 toString(),可以被 Overwrite
import "fmt"
type Person struct {
Name string
Age int
}
func (p Person) String() string {
return fmt.Sprintf("%v (%v years)", p.Name, p.Age)
}
a := Person{"Arthur Dent", 42}
z := Person{"Zaphod Beeblebrox", 9001}
fmt.Println(a, z)
Arthur Dent (42 years) Zaphod Beeblebrox (9001 years)
练习:Stringer
通过让 IPAddr 类型实现 fmt.Stringer 来打印点号分隔的地址
例如,IPAddr{1, 2, 3, 4} 应当打印为 "1.2.3.4"
import "fmt"
type IPAddr [4]byte
func (i *IPAddr) String() string {
return fmt.Sprintf("%v.%v.%v.%v", i[0], i[1], i[2], i[3])
}
hosts := map[string]IPAddr{
"loopback": {127, 0, 0, 1},
"googleDNS": {8, 8, 8, 8},
}
for name, ip := range hosts {
fmt.Printf("%v: %v\n", name, &ip)
}
for name, ip := range hosts {
fmt.Printf("%v: %v\n", name, ip)
}
loopback: 127.0.0.1
googleDNS: 8.8.8.8
loopback: [127 0 0 1]
googleDNS: [8 8 8 8]
错误
Go 程序使用 error 值来表示错误状态。与 fmt.Stringer 类似,error 类型是一个内建接口:
type error interface {
Error() string
}
(与 fmt.Stringer 类似,fmt 包在打印值时也实现了 error 接口)
通常函数会返回一个 error 值,调用的它的代码应当判断这个错误是否等于 nil 来进行错误处理。
i, err := strconv.Atoi("42")
if err != nil {
fmt.Printf("couldn't convert number: %v\n", err)
return
}
fmt.Println("Converted integer:", i)
error 为 nil 时表示成功;非 nil 的 error 表示失败。
import (
"fmt"
"time"
)
type MyError struct {
When time.Time
What string
}
func (e *MyError) Error() string {
return fmt.Sprintf("at %v, %s", e.When, e.What)
}
func run() error {
return &MyError{ time.Now(), "it didn't work" }
}
if err := run(); err != nil {
fmt.Println(err)
}
at 2019-12-29 08:02:06.7898072 +0000 UTC m=+13592.514735001, it didn't work
练习:错误
开平方函数 Sqrt 接受到一个负数时,应当返回一个非 nil 的错误值,复数同样也不被支持。
方法使其拥有 error 值,通过 ErrNegativeSqrt(-2).Error() 调用该方法应返回 "cannot Sqrt negative number: -2"。
注意: 在 Error 方法内调用 fmt.Sprint(e) 会让程序陷入死循环。可以通过先转换 e 来避免这个问题:fmt.Sprint(float64(e))。这是为什么呢?
import ("fmt"; "math")
type ErrNegativeSqrt float64
func (e ErrNegativeSqrt) Error() string {
return fmt.Sprint("cannot Sqrt negative number:", float64(e))
}
func Sqrt(x float64) (float64, error) {
if x < 0 {
return 0, ErrNegativeSqrt(x)
}
return math.Sqrt(x), nil
}
fmt.Println(Sqrt(2))
fmt.Println(Sqrt(-2))
1.4142135623730951
0 cannot Sqrt negative number:-2
Reader
io 包指定了 io.Reader 接口,它表示从数据流的末尾进行读取。
Go 标准库包含了该接口的许多实现,包括文件、网络连接、压缩和加密等等。
io.Reader 接口有一个 Read 方法:
func (T) Read(b []byte) (n int, err error)
Read 用数据填充给定的字节切片并返回填充的字节数和错误值。在遇到数据流的结尾时,它会返回一个 io.EOF 错误。
示例代码创建了一个 strings.Reader 并以每次 8 字节的速度读取它的输出。
import (
"fmt"
"io"
"strings"
)
r := strings.NewReader("Hello, Reader!")
b := make([]byte, 8)
for {
n, err := r.Read(b)
fmt.Printf("n = %v err = %v b = %v\n", n, err, b)
fmt.Printf("b[:n] = %q\n", b[:n])
if err == io.EOF {
break
}
}
n = 8 err =
b[:n] = "Hello, R"
n = 6 err =
b[:n] = "eader!"
n = 0 err = EOF b = [101 97 100 101 114 33 32 82]
b[:n] = ""
import "fmt"
type ByteSlice []byte
func (p *ByteSlice) Write(data []byte) (n int, err error) {
slice := *p
slice = data
// 依旧和前面相同。
*p = slice
return len(data), nil
}
var b ByteSlice
fmt.Fprintf(&b, "This hour has %d days\n", 7)
fmt.Println(b)
fmt.Printf("%q\n",b[0:cap(b)])
fmt.Fprintf(os.Stdout, "This hour has %d days\n", 7)
fmt.Fprintf(os.Stderr, "This hour has %d days\n", 7)
print()
[91 57 49 32 53 55 32 52 57 32 51 50 32 53 51 32 53 53 32 51 50]
"[91 57 49 32 53 55 32 52 57 32 \x00"
This hour has 7 days
This hour has 7 days
练习:Reader
实现一个 Reader 类型,它产生一个 ASCII 字符 'A' 的无限流。
//import "golang.org/x/tour/reader"
import (
"fmt"
"io"
"os"
)
func Validate(r io.Reader) {
b := make([]byte, 1024, 2048)
i, o := 0, 0
for ; i < 1<<20 && o < 1<<20; i++ { // test 1mb
n, err := r.Read(b)
for i, v := range b[:n] {
if v != 'A' {
fmt.Fprintf(os.Stderr, "got byte %x at offset %v, want 'A'\n", v, o+i)
return
}
}
o += n
if err != nil {
fmt.Fprintf(os.Stderr, "read error: %v\n", err)
return
}
}
if o == 0 {
fmt.Fprintf(os.Stderr, "read zero bytes after %d Read calls\n", i)
return
}
fmt.Println("OK!")
}
type MyReader struct{}
// TODO: Add a Read([]byte) (int, error) method to MyReader.
func (r MyReader) Read(b []byte) (int, error) {
b[0] = 'A'
return 1, nil
}
Validate(MyReader{})
OK!
练习:rot13Reader
有种常见的模式是一个 io.Reader 包装另一个 io.Reader,然后通过某种方式修改其数据流。
例如,gzip.NewReader 函数接受一个 io.Reader(已压缩的数据流)并返回一个同样实现了 io.Reader 的 *gzip.Reader(解压后的数据流)。
编写一个实现了 io.Reader 并从另一个 io.Reader 中读取数据的 rot13Reader,通过应用 rot13 代换密码对数据流进行修改。
rot13Reader 类型已经提供。实现 Read 方法以满足 io.Reader。
import (
"io"
"os"
"strings"
)
type rot13Reader struct {
r io.Reader
}
func (reader rot13Reader) Read(b []byte) (int, error) {
n, err := reader.r.Read(b)
for i := 0; i < n; i++ {
switch {
case b[i] >= 'A' && b[i] < 'N':
b[i] += 13
case b[i] >= 'N' && b[i] <= 'Z':
b[i] -= 13
case b[i] >= 'a' && b[i] < 'n':
b[i] += 13
case b[i] >= 'n' && b[i] <= 'z':
b[i] -= 13
}
}
return n, err
}
s := strings.NewReader("Lbh penpxrq gur pbqr!")
r := rot13Reader{s}
io.Copy(os.Stdout, &r)
You cracked the code!
图像
image 包定义了 Image 接口:
package image
type Image interface {
ColorModel() color.Model
Bounds() Rectangle
At(x, y int) color.Color
}
注意: Bounds 方法的返回值 Rectangle 实际上是一个 image.Rectangle,它在 image 包中声明。
(请参阅文档了解全部信息。)
color.Color 和 color.Model 类型也是接口,但是通常因为直接使用预定义的实现 image.RGBA 和 image.RGBAModel 而被忽视了。
这些接口和类型由 image/color 包定义。
import ("fmt"; "image")
m := image.NewRGBA(image.Rect(0, 0, 100, 100))
fmt.Println(m.Bounds())
fmt.Println(m.At(0, 0).RGBA())
(0,0)-(100,100)
0 0 0 0
练习:图像
还记得之前编写的图片生成器 吗?我们再来编写另外一个,不过这次它将会返回一个 image.Image 的实现而非一个数据切片。
定义你自己的 Image 类型,实现必要的方法并调用 pic.ShowImage。
Bounds 应当返回一个 image.Rectangle ,例如 image.Rect(0, 0, w, h)。
ColorModel 应当返回 color.RGBAModel。
At 应当返回一个颜色。上一个图片生成器的值 v 对应于此次的 color.RGBA{v, v, 255, 255}。
// import "golang.org/x/tour/pic"
import (
"bytes"
"encoding/base64"
"fmt"
"image"
"image/color"
"image/png"
)
func Show(f func(int, int) [][]uint8) {
const (
dx = 256
dy = 256
)
data := f(dx, dy)
m := image.NewNRGBA(image.Rect(0, 0, dx, dy))
for y := 0; y < dy; y++ {
for x := 0; x < dx; x++ {
v := data[y][x]
i := y*m.Stride + x*4
m.Pix[i] = v
m.Pix[i+1] = v
m.Pix[i+2] = 255
m.Pix[i+3] = 255
}
}
ShowImage(m)
}
func ShowImage(m image.Image) {
var buf bytes.Buffer
err := png.Encode(&buf, m)
if err != nil {
panic(err)
}
// base64 encode to string
// enc := base64.StdEncoding.EncodeToString(buf.Bytes())
// fmt.Println("IMAGE(base64):" + enc)
// display png to jupyter directly via lgo's function _ctx.Display.PNG()
_ctx.Display.PNG(buf.Bytes(), nil)
}
type Image struct{} //新建一个Image结构体
func (i Image) ColorModel() color.Model { //实现Image包中颜色模式的方法
return color.RGBAModel
}
func (i Image) Bounds() image.Rectangle { //实现Image包中生成图片边界的方法
return image.Rect(0, 0, 200, 200)
}
func (i Image) At(x, y int) color.Color { //实现Image包中生成图像某个点的方法
return color.RGBA{uint8(x), uint8(y), uint8(255), uint8(255)}
}
m := Image{}
ShowImage(m) //调用

并发
作为语言的核心部分,Go 提供了并发的特性。这一部分概览了 goroutine 和 channel,以及如何使用它们来实现不同的并发模式。
https://blog.csdn.net/williamfan21c/article/details/60960238
goroutine 是由 Go 运行时管理的轻量级线程
go f(x, y, z)
会启动一个新的 Go 程并执行
f(x, y, z)
x, y 和 z 的求值发生在当前的 Go 程中,而 f 的执行发生在新的 Go 程中
Go 程在相同的地址空间中运行,因此在访问共享的内存时必须进行同步
sync 包提供了这种能力,不过在 Go 中并不经常用到,因为还有其它的办法
import ("fmt"; "time")
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
go say("world")
say("hello")
hello
world
world
hello
hello
world
hello
world
hello
world
信道是带有类型的管道,你可以通过它用信道操作符 <- 来发送或者接收值
ch <- v // 将 v 发送至信道 ch。
v := <-ch // 从 ch 接收值并赋予 v。
("箭头" 就是数据流的方向)
和映射与切片一样,信道在使用前必须创建:
ch := make(chan int)
默认情况下,发送和接收操作在另一端准备好之前都会阻塞。这使得 Go 程可以在没有显式的锁或竞态变量的情况下进行同步。
以下示例对切片中的数进行求和,将任务分配给两个 Go 程。一旦两个 Go 程完成了它们的计算,它就能算出最终的结果。
import "fmt"
func sum(s []int, c chan int) {
sum := 0
for _, v := range s {
sum += v
}
c <- sum // 将和送入 c
}
s := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(s[:len(s)/2], c)
go sum(s[len(s)/2:], c)
x, y := <-c, <-c // 从 c 中接收
fmt.Println(x, y, x+y)
17 -5 12
带缓冲的信道
信道可以是带缓冲的,将缓冲长度作为第二个参数提供给 make 来初始化一个带缓冲的信道:
ch := make(chan int, 100)
仅当信道的缓冲区填满后,向其发送数据时才会阻塞。当缓冲区为空时,接受方会阻塞
import "fmt"
ch := make(chan int, 2) // 修改示例填满缓冲区,然后看看会发生什么
ch <- 1
ch <- 2
fmt.Println(<-ch)
fmt.Println(<-ch)
1
2
range 和 close
发送者可通过 close 关闭一个信道来表示没有需要发送的值了。
接收者可以通过为接收表达式分配第二个参数来测试信道是否被关闭:若没有值可以接收且信道已被关闭,那么在执行完
v, ok := <-ch
之后 ok 会被设置为 false。
循环 for i := range c 会不断从信道接收值,直到它被关闭。
注意: 只有发送者才能关闭信道,而接收者不能。向一个已经关闭的信道发送数据会引发程序恐慌(panic)。
还要注意: 信道与文件不同,通常情况下无需关闭它们。只有在必须告诉接收者不再有需要发送的值时才有必要关闭,例如终止一个 range 循环。
import ("fmt")
func fibonacci(n int, c chan int) {
x, y := 0, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x+y
}
close(c)
}
c := make(chan int, 10)
go fibonacci(cap(c), c)
for i := range c { fmt.Println(i) }
0
1
1
2
3
5
8
13
21
34
select 语句
select 语句使一个 Go 程可以等待多个通信操作。
select 会阻塞到某个分支可以继续执行为止,这时就会执行该分支。当多个分支都准备好时会随机选择一个执行。
import "fmt"
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
0
1
1
2
3
5
8
13
21
34
quit
默认选择
当 select 中的其它分支都没有准备好时,default 分支就会执行。
为了在尝试发送或者接收时不发生阻塞,可使用 default 分支:
select {
case i := <-c:
// 使用 i
default:
// 从 c 中接收会阻塞时执行
}
import (
"fmt"
"time"
)
tick := time.Tick(100 * time.Millisecond)
boom := time.After(500 * time.Millisecond)
for {
select {
case <-tick:
fmt.Println("tick.")
case <-boom:
fmt.Println("BOOM!")
return
default:
fmt.Println(" .")
time.Sleep(50 * time.Millisecond)
}
}
.
.
tick.
.
.
tick.
.
.
tick.
.
.
tick.
.
.
tick.
BOOM!
练习:等价二叉查找树
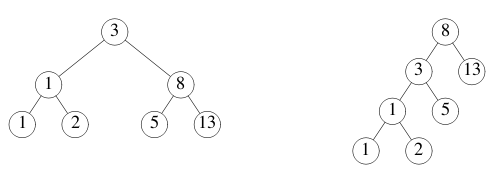
不同二叉树的叶节点上可以保存相同的值序列。例如,以下两个二叉树都保存了序列 1,1,2,3,5,8,13。
在大多数语言中,检查两个二叉树是否保存了相同序列的函数都相当复杂。 我们将使用 Go 的并发和信道来编写一个简单的解法。
本例使用了 tree 包,它定义了类型:
type Tree struct {
Left *Tree
Value int
Right *Tree
}
实现步骤:
-
实现 Walk 函数
-
测试 Walk 函数
函数 tree.New(k) 用于构造一个随机结构的已排序二叉查找树,它保存了值 k, 2k, 3k, ..., 10k
创建一个新的信道 ch 并且对其进行步进:go Walk(tree.New(1), ch)然后从信道中读取并打印 10 个值。应当是数字 1, 2, 3, ..., 10
-
用 Walk 实现 Same 函数来检测 t1 和 t2 是否存储了相同的值
-
测试 Same 函数
Same(tree.New(1), tree.New(1)) 应当返回 true,而 Same(tree.New(1), tree.New(2)) 应当返回 false。
Tree 的文档可在这里找到: https://godoc.org/golang.org/x/tour/tree#Tree
// import "golang.org/x/tour/tree"
import ("fmt"; "math/rand")
// A Tree is a binary tree with integer values.
type Tree struct {
Left *Tree
Value int
Right *Tree
}
// New returns a new, random binary tree holding the values k, 2k, ..., 10k.
func New(k int) *Tree {
var t *Tree
for _, v := range rand.Perm(10) {
t = insert(t, (1+v)*k)
}
return t
}
func insert(t *Tree, v int) *Tree {
if t == nil {
return &Tree{nil, v, nil}
}
if v < t.Value {
t.Left = insert(t.Left, v)
} else {
t.Right = insert(t.Right, v)
}
return t
}
func (t *Tree) String() string {
if t == nil {
return "()"
}
s := ""
if t.Left != nil {
s += t.Left.String() + " "
}
s += fmt.Sprint(t.Value)
if t.Right != nil {
s += " " + t.Right.String()
}
return "(" + s + ")"
}
// 以上为 tree 包内容
// Walk 步进 tree t 将所有的值从 tree 发送到 channel ch。
func Walk(t *Tree, ch chan int) {
if t.Left != nil {
Walk(t.Left, ch)
}
ch <- t.Value
if t.Right != nil {
Walk(t.Right, ch)
}
}
// Same 检测树 t1 和 t2 是否含有相同的值。
func Same(t1, t2 *Tree) bool {
total := 10
ch1, ch2 := make(chan int, total), make(chan int, total)
go Walk(t1, ch1)
go Walk(t2, ch2)
for i := 0; i < 10; i++ {
if <-ch1 != <-ch2 {
return false
}
}
return true
}
fmt.Println(Same(New(1), New(1)))
fmt.Println(Same(New(1), New(2)))
true
false
sync.Mutex
我们已经看到信道非常适合在各个 Go 程间进行通信。
但是如果我们并不需要通信呢?比如说,若我们只是想保证每次只有一个 Go 程能够访问一个共享的变量,从而避免冲突?
这里涉及的概念叫做 互斥(mutual exclusion) ,我们通常使用 互斥锁(Mutex) 这一数据结构来提供这种机制。
Go 标准库中提供了 sync.Mutex 互斥锁类型及其两个方法:
Lock()
Unlock()
我们可以通过在代码前调用 Lock 方法,在代码后调用 Unlock 方法来保证一段代码的互斥执行。参见 Inc 方法。
我们也可以用 defer 语句来保证互斥锁一定会被解锁。参见 Value 方法。
import ("fmt"; "sync"; "time")
// SafeCounter 的并发使用是安全的。
type SafeCounter struct {
v map[string]int
mux sync.Mutex
}
// Inc 增加给定 key 的计数器的值。
func (c *SafeCounter) Inc(key string) {
c.mux.Lock()
// Lock 之后同一时刻只有一个 goroutine 能访问 c.v
c.v[key]++
c.mux.Unlock()
}
// Value 返回给定 key 的计数器的当前值。
func (c *SafeCounter) Value(key string) int {
c.mux.Lock()
// Lock 之后同一时刻只有一个 goroutine 能访问 c.v
defer c.mux.Unlock()
return c.v[key]
}
c := SafeCounter{v: make(map[string]int)}
for i := 0; i < 1000; i++ {
go c.Inc("somekey")
}
time.Sleep(time.Second)
fmt.Println(c.Value("somekey"))
1000
练习:Web 爬虫
在这个练习中,我们将会使用 Go 的并发特性来并行化一个 Web 爬虫。
修改 Crawl 函数来并行地抓取 URL,并且保证不重复。
提示:你可以用一个 map 来缓存已经获取的 URL,但是要注意 map 本身并不是并发安全的!
import (
"fmt"
)
type Fetcher interface {
// Fetch 返回 URL 的 body 内容,并且将在这个页面上找到的 URL 放到一个 slice 中。
Fetch(url string) (body string, urls []string, err error)
}
// Crawl 使用 fetcher 从某个 URL 开始递归的爬取页面,直到达到最大深度。
func Crawl(url string, depth int, fetcher Fetcher) {
// TODO: 并行的抓取 URL。
// TODO: 不重复抓取页面。
// 下面并没有实现上面两种情况:
if depth <= 0 {
return
}
body, urls, err := fetcher.Fetch(url)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("found: %s %q\n", url, body)
for _, u := range urls {
Crawl(u, depth-1, fetcher)
}
return
}
// fakeFetcher 是返回若干结果的 Fetcher。
type fakeFetcher map[string]*fakeResult
type fakeResult struct {
body string
urls []string
}
func (f fakeFetcher) Fetch(url string) (string, []string, error) {
if res, ok := f[url]; ok {
return res.body, res.urls, nil
}
return "", nil, fmt.Errorf("not found: %s", url)
}
// fetcher 是填充后的 fakeFetcher。
var fetcher = fakeFetcher{
"https://golang.org/": &fakeResult{
"The Go Programming Language",
[]string{
"https://golang.org/pkg/",
"https://golang.org/cmd/",
},
},
"https://golang.org/pkg/": &fakeResult{
"Packages",
[]string{
"https://golang.org/",
"https://golang.org/cmd/",
"https://golang.org/pkg/fmt/",
"https://golang.org/pkg/os/",
},
},
"https://golang.org/pkg/fmt/": &fakeResult{
"Package fmt",
[]string{
"https://golang.org/",
"https://golang.org/pkg/",
},
},
"https://golang.org/pkg/os/": &fakeResult{
"Package os",
[]string{
"https://golang.org/",
"https://golang.org/pkg/",
},
},
}
Crawl("https://golang.org/", 4, fetcher)
found: https://golang.org/ "The Go Programming Language"
found: https://golang.org/pkg/ "Packages"
found: https://golang.org/ "The Go Programming Language"
found: https://golang.org/pkg/ "Packages"
not found: https://golang.org/cmd/
not found: https://golang.org/cmd/
found: https://golang.org/pkg/fmt/ "Package fmt"
found: https://golang.org/ "The Go Programming Language"
found: https://golang.org/pkg/ "Packages"
found: https://golang.org/pkg/os/ "Package os"
found: https://golang.org/ "The Go Programming Language"
found: https://golang.org/pkg/ "Packages"
not found: https://golang.org/cmd/
接下来去哪?
你可以从安装 Go 开始。
https://go-zh.org/doc/install
一旦安装了 Go,Go 文档是一个极好的 应当继续阅读的内容。 它包含了参考、指南、视频等等更多资料。
https://go-zh.org/doc/
了解如何组织 Go 代码并在其上工作,参阅此视频,或者阅读如何编写 Go 代码。
https://www.youtube.com/watch?v=XCsL89YtqCs
https://go-zh.org/doc/code.html
如果你需要标准库方面的帮助,请参考包手册。如果是语言本身的帮助,阅读语言规范是件令人愉快的事情。
https://go-zh.org/pkg/
https://go-zh.org/ref/spec
进一步探索 Go 的并发模型,参阅 Go 并发模型(幻灯片)以及深入 Go 并发模型(幻灯片)并阅读通过通信共享内存的代码之旅。
https://www.youtube.com/watch?v=f6kdp27TYZs
https://www.youtube.com/watch?v=QDDwwePbDtw
https://go-zh.org/doc/codewalk/sharemem/
想要开始编写 Web 应用,请参阅一个简单的编程环境(幻灯片)并阅读编写 Web 应用的指南。
https://vimeo.com/53221558
https://go-zh.org/doc/articles/wiki/
函数:Go 中的一等公民展示了有趣的函数类型。
https://go-zh.org/doc/codewalk/functions/
Go 博客有着众多关于 Go 的文章和信息。
https://blog.go-zh.org/
mikespook 的博客中有大量中文的关于 Go 的文章和翻译。
https://www.mikespook.com/tag/golang/
开源电子书 Go Web 编程和 Go 入门指南能够帮助你更加深入的了解和学习 Go 语言。
https://github.com/astaxie/build-web-application-with-golang
https://github.com/Unknwon/the-way-to-go_ZH_CN
访问 go-zh.org 了解更多内容。
https://go-zh.org/
golang 新手们容易犯的 3 个错误总结(待总结)
https://www.jb51.net/article/145529.htm
https://stackoverflow.com/questions/27140130/having-multiple-main-functions-on-go?lq=1
https://stackoverflow.com/questions/21220077/what-does-an-underscore-in-front-of-an-import-statement-mean
Golang 内存模型
引言
Go 内存模型阐明了一个 Go 程对某变量的写入,如何才能确保被另一个读取该变量的 Go 程监测到。
忠告
程序在修改被多个 Go 程同时访问的数据时必须序列化该访问。
要序列化访问,需通过信道操作,或其它像 sync 和 sync/atomic 包中的同步原语来保护数据。
若您的程序行为必须通过阅读本文档才能理解,那...想必您一定十分聪明咯?
别自作聪明。
事件的发生次序
在单个 Go 程中,读取和写入的表现必须与程序指定的执行顺序相一致。换言之, 仅在不会改变语言规范对 Go 程行为的定义时,编译器和处理器才会对读取和写入的执行重新排序。 由于存在重新排序,一个 Go 程监测到的执行顺序可能与另一个 Go 程监到的不同。例如,若一个 Go 程执行 a = 1; b = 2;,另一个 Go 程可能监测到 b 的值先于 a 更新。
为了详细论述读取和写入的必要条件,我们定义了 事件发生顺序,它表示 Go 程序中内存操作执行的 偏序关系。 若事件 \(e_1\) 发生在 \(e_2\) 之前, 那么我们就说 \(e_2\) 发生在 \(e_1\) 之后。 换言之,若 \(e_1\) 既未发生在 \(e_2\) 之前, 又未发生在 \(e_2\) 之后,那么我们就说 \(e_1\) 与 \(e_2\) 是并发的。
在单一 Go 程中,事件发生的顺序即为程序所表达的顺序。
若以下条件均成立,则对变量 v 的读取操作 \(r\) 就 允许 对 v 的写入操作 \(w\) 进行监测:
- \(r\) 不发生在 \(w\) 之前。
- 在 \(w\) 之后 \(r\) 之前,不存在其它对 v 进行的写入操作 \(w'\)。
为确保对变量 v 的读取操作 \(r\) 能够监测到特定的对 v 进行写入的操作 \(w\),需确保 \(w\) 是唯一允许被 \(r\) 监测的写入操作。也就是说,若以下条件均成立,则 \(r\) 能 保证 监测到 \(w\):
- \(w\) 发生在 \(r\) 之前。
- 对共享变量 v 的其它任何写入操作都只能发生在 \(w\) 之前或 \(r\) 之后。
这对条件的要求比第一对更强,它需要确保没有其它写入操作与 \(w\) 或 \(r\) 并发。
在单个 Go 程中并不存在并发,因此这两条定义是等价的:读取操作 \(r\) 可监测最近的写入操作 \(w\) 对 v 写入的值。当多个 Go 程访问共享变量 v 时,它们必须通过同步事件来建立发生顺序的条件,以此确保读取操作能监测到预期的写入。
以变量 v 所属类型的零值来对 v 进行初始化,其表现如同在内存模型中进行的写入操作。
对大于单个机器字的值进行读取和写入,其表现如同以不确定的顺序对多个机器字大小的值进行操作。
译注(Ants Arks):a 不在 b 之前,并不意味着 a 就在 b 之后,它们可以并发。这样的话,第一种说法, 即对于两个并发的 Go 程来说,一个 Go 程能否读到另一个 Go 程写入的数据,可能有,也可能没有。 第二种说法,由于 \(r\) 发生在 \(w\) 之后,\(r\) 之前并没有其它的 \(w'\),也没有 \(w"\) 和 \(r\) 并列,因此 \(r\) 读到的值必然是 \(w\) 写入的值。下面结合图形进行说明,其中 \(r\) 为 read,\(w\) 为 write,它们都对值进行操作。
单 Go 程的情形:
-- w0 ---- r1 -- w1 ---- w2 ---- r2 ---- r3 ------>
这里不仅是个偏序关系,还是一个良序关系:所有 r/w 的先后顺序都是可比较的。
双 Go 程的情形:
-- w0 -- r1 -- r2 ---- w3 ---- w4 ---- r5 -------->
-- w1 ----- w2 -- r3 ---- r4 ---- w5 -------->
单 Go 程上的事件都有先后顺序;而对于两条Go程,情况又有所不同。即便在时间上 r1 先于 w2 发生,
但由于每条 Go 程的执行时长都像皮筋一样伸缩不定,因此二者在逻辑上并无先后次序。换言之,即二者并发。
对于并发的 r/w,r3 读取的结果可能是前面的 w2,也可能是上面的 w3,甚至 w4 的值;
而 r5 读取的结果,可能是 w4 的值,也能是 w1、w2、w5 的值,但不可能是 w3 的值。
双 Go 程交叉同步的情形:
-- r0 -- r1 ---|------ r2 ------------|-- w5 ------>
-- w1 --- w2 --|-- r3 ---- r4 -- w4 --|------->
现在上面添加了两个同步点,即 | 处。这样的话,r3 就是后于 r1 ,先于 w5 发生的。
r2 之前的写入为 w2,但与其并发的有 w4,因此 r2 的值是不确定的:可以是 w2,也可以是 w4。
而 r4 之前的写入的是 w2,与它并发的并没有写入,因此 r4 读取的值为 w2。
到这里,Go 程间的关系就很清楚了。若不加同步控制,那么所有的 Go 程都是 “平行” 并发的。换句话说, 若不进行同步,那么 main 函数以外的 Go 程都是无意义的,因为这样可以认为 main 跟它们没有关系。 只有加上同步控制,例如锁或信道,Go 程间才有了相同的 “节点”,在它们的两边也就有了执行的先后顺序, 不过两个 “节点” 之间的部分,同样还是可以自由伸缩,没有先后顺序的。如此推广,多条 Go 程的同步就成了有向的网。
同步
初始化
程序的初始化运行在单个 Go 程中,但该 Go 程可能会创建其它并发运行的 Go 程。
若包 p 导入了包 q,则 q 的 init 函数会在 p 的任何函数启动前完成。
函数 main.main 会在所有的 init 函数结束后启动。
Go 程的创建
go 语句会在当前Go程开始执行前启动新的Go程。
例如,在此程序中,
var a string
func f() {
print(a)
}
func hello() {
a = "hello, world"
go f()
}
调用 hello 或许会在将来的某一时刻打印 "hello, world" (在 hello 返回之后则会打印零值)。
Go 程的销毁
Go 程无法确保在程序中的任何事件发生之前退出。例如,在此程序中:
var a string
func hello() {
go func() { a = "hello" }()
print(a)
}
对 a 进行赋值后并没有任何同步事件,因此它无法保证被其它任何 Go 程检测到。 实际上,一个积极的编译器可能会删除整条 go 语句。
若一个 Go 程的作用必须被另一个 Go 程监测到,需使用锁或信道通信之类的同步机制来建立顺序关系。
信道通信
信道通信是在 Go 程之间进行同步的主要方法。在特定信道上的每一次发送操作都有与其对应的接收操作相匹配, 这通常发生在不同的信道上。
信道上的发送操作总在对应的接收操作完成前发生。
此程序:
var c = make(chan int, 10)
var a string
func f() {
a = "hello, world"
c <- 0
}
func main() {
go f()
<-c
print(a)
}
可保证打印出 "hello, world"。该程序首先对 a 进行写入, 然后在 c 上发送信号,随后从 c 接收对应的信号,最后执行 print 函数。
若在信道关闭后从中接收数据,接收者就会收到该信道返回的零值。
在上一个例子中,用 close(c) 代替 c <- 0 仍能保证该程序产生相同的行为。
从无缓冲信道进行的接收,要发生在对该信道进行的发送完成之前。
此程序(与上面的相同,但交换了发送和接收语句的位置,且使用无缓冲信道):
var c = make(chan int)
var a string
func f() {
a = "hello, world"
<-c
}
func main() {
go f()
c <- 0
print(a)
}
也可保证打印出 "hello, world"。该程序首先对 a 进行写入, 然后从 c 中接收信号,随后向 c 发送对应的信号,最后执行 print 函数。
若该信道为带缓冲的(例如,c = make(chan int, 1)), 则该程序将无法保证打印出 "hello, world"。(它可能会打印出空字符串, 崩溃,或做些别的事情。)
TODO: 优化语句 在某信道上进行的的第 k 次容量为 C 的发送发生在第 k+C 次从该信道进行的接收完成之前。
The \(k\)th receive on a channel with capacity C happens before the \(k+C\)th send from that channel completes.
This rule generalizes the previous rule to buffered channels. It allows a counting semaphore to be modeled by a buffered channel: the number of items in the channel corresponds to the number of active uses, the capacity of the channel corresponds to the maximum number of simultaneous uses, sending an item acquires the semaphore, and receiving an item releases the semaphore. This is a common idiom for limiting concurrency.
This program starts a goroutine for every entry in the work list, but the goroutines coordinate using the limit channel to ensure that at most three are running work functions at a time.
var limit = make(chan int, 3)
func main() {
for _, w := range work {
go func() {
limit <- 1
w()
<-limit
}()
}
select{}
}
锁
sync 包实现了两种锁的数据类型:sync.Mutex 和 sync.RWMutex。
对于任何 sync.Mutex 或 sync.RWMutex 类型的变量 l 以及 \(n < m\) ,对 l.Unlock() 的第 n 次调用在对 l.Lock() 的第 m 次调用返回前发生。
此程序:
var l sync.Mutex
var a string
func f() {
a = "hello, world"
l.Unlock()
}
func main() {
l.Lock()
go f()
l.Lock()
print(a)
}
可保证打印出 "hello, world"。该程序首先(在 f 中)对 l.Unlock() 进行第一次调用,然后(在 main 中)对 l.Lock() 进行第二次调用,最后执行 print 函数。
对于任何 sync.RWMutex 类型的变量 l 对 l.RLock 的调用,存在一个这样的 \(n\),使得 l.RLock 在对 l.Unlock 的第 \(n\) 次调用之后发生(返回),且与其相匹配的 l.RUnlock 在对 l.Lock的第 \(n+1\) 次调用之前发生。
Once 类型
sync 包通过 Once 类型为存在多个 Go 程的初始化提供了安全的机制。 多个线程可为特定的 f 执行 once.Do(f),但只有一个会运行 f(),而其它调用会一直阻塞,直到 f() 返回。
通过 once.Do(f) 对 f() 的单次调用在对任何其它的 once.Do(f) 调用返回之前发生(返回)。
在此程序中:
var a string
var once sync.Once
func setup() {
a = "hello, world"
}
func doprint() {
once.Do(setup)
print(a)
}
func twoprint() {
go doprint()
go doprint()
}
调用 twoprint 会打印两次 "hello, world" 。 第一次对 twoprint 的调用会运行一次 setup。
错误的同步
请注意,读取操作 \(r\) 可能监测到与其并发的写入操作 \(w\) 写入的值。即便如此,也并不意味着发生在 \(r\) 之后的读取操作会监测到发生在 \(w\) 之前的写入操作。
在此程序中:
var a, b int
func f() {
a = 1
b = 2
}
func g() {
print(b)
print(a)
}
func main() {
go f()
g()
}
可能会发生 g 打印出 2 之后再打印出 0。
这个事实会使很多习惯变得无效。
双重检测锁是种避免同步开销的尝试。例如,twoprint 程序可能会错误地写成:
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func doprint() {
if !done {
once.Do(setup)
}
print(a)
}
func twoprint() {
go doprint()
go doprint()
}
但这里并不保证在 doprint 中对 done 的写入进行监测蕴含对 a 的写入进行监测。这个版本可能会(错误地)打印出一个空字符串而非 "hello, world"。
另一种错误的习惯就是忙于等待一个值,就像这样:
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func main() {
go setup()
for !done {
}
print(a)
}
和前面一样,这里不保证在 main 中对 done 的写入的监测, 蕴含对 a 的写入也进行监测,因此该程序也可能会打印出一个空字符串。 更糟的是,由于在两个线程之间没有同步事件,因此无法保证对 done 的写入总能被 main 监测到。main 中的循环不保证一定能结束。
这个主题有种微妙的变体,例如此程序:
type T struct {
msg string
}
var g *T
func setup() {
t := new(T)
t.msg = "hello, world"
g = t
}
func main() {
go setup()
for g == nil {
}
print(g.msg)
}
即便 main 能够监测到 g != nil 并退出循环, 它也无法保证能监测到 g.msg 的初始化值。
这里所有例子的解决方案都是相同的:使用显式的同步。
Effective Go (实效 Go 编程)
引言
Go 是一门全新的语言。尽管它从既有的语言中借鉴了许多理念,但其与众不同的特性, 使得使用 Go 编程在本质上就不同于其它语言。将现有的 C++ 或 Java 程序直译为 Go 程序并不能令人满意——毕竟 Java 程序是用 Java 编写的,而不是 Go 。 另一方面,若从 Go 的角度去分析问题,你就能编写出同样可行但大不相同的程序。 换句话说,要想将 Go 程序写得好,就必须理解其特性和风格。了解命名、格式化、 程序结构等既定规则也同样重要,这样你编写的程序才能更容易被其他程序员所理解。
本文档就如何编写清晰、地道的 Go 代码提供了一些技巧。它是对语言规范、 Go 语言之旅 以及 如何使用 Go 编程 的补充说明,因此我们建议您先阅读这些文档。
示例
Go 包的源码不仅是核心库,同时也是学习如何使用 Go 语言的示例源码。 此外,其中的一些包还包含了可工作的,独立的可执行示例,你可以直接在 golang.org 网站上运行它们。如果你有任何关于某些问题如何解决,或某些东西如何实现的疑问, 也可以从中获取相关的答案、思路以及后台实现。
格式化
格式化问题总是充满了争议,但却始终没有形成统一的定论。虽说人们可以适应不同的编码风格, 但抛弃这种适应过程岂不更好?若所有人都遵循相同的编码风格,在这类问题上浪费的时间将会更少。 问题就在于如何实现这种设想,而无需冗长的语言风格规范。
在 Go 中我们另辟蹊径,让机器来处理大部分的格式化问题。gofmt 程序(也可用 go fmt,它以包为处理对象而非源文件)将 Go 程序按照标准风格缩进、 对齐,保留注释并在需要时重新格式化。若你想知道如何处理一些新的代码布局,请尝试运行 gofmt;若结果仍不尽人意,请重新组织你的程序(或提交有关 gofmt 的 Bug),而不必为此纠结。
举例来说,你无需花时间将结构体中的字段注释对齐,gofmt 将为你代劳。 假如有以下声明:
type T struct {
name string // 对象名
value int // 对象值
}
gofmt 会将它按列对齐为:
type T struct {
name string // 对象名
value int // 对象值
}
标准包中所有的 Go 代码都已经用 gofmt 格式化过了。
还有一些关于格式化的细节,它们非常简短:
缩进
我们使用制表符(tab)缩进,gofmt 默认也使用它。在你认为确实有必要时再使用空格。
行的长度
Go 对行的长度没有限制,别担心打孔纸不够长。如果一行实在太长,也可进行折行并插入适当的 tab 缩进。
括号
比起 C 和 Java, Go 所需的括号更少:控制结构(if、for 和 switch)在语法上并不需要圆括号。此外,操作符优先级处理变得更加简洁,因此
x<<8 + y<<16
正表述了空格符所传达的含义。
注释
Go 语言支持C风格的块注释 /* */ 和 C++ 风格的行注释 //。 行注释更为常用,而块注释则主要用作包的注释,当然也可在禁用一大段代码时使用。
godoc 既是一个程序,又是一个Web 服务器,它对 Go 的源码进行处理,并提取包中的文档内容。 出现在顶级声明之前,且与该声明之间没有空行的注释,将与该声明一起被提取出来,作为该条目的说明文档。 这些注释的类型和风格决定了 godoc 生成的文档质量。
每个包都应包含一段包注释,即放置在包子句前的一个块注释。对于包含多个文件的包, 包注释只需出现在其中的任一文件中即可。包注释应在整体上对该包进行介绍,并提供包的相关信息。 它将出现在 godoc 页面中的最上面,并为紧随其后的内容建立详细的文档。
/*
regexp 包为正则表达式实现了一个简单的库。
该库接受的正则表达式语法为:
正则表达式:
串联 { '|' 串联 }
串联:
{ 闭包 }
闭包:
条目 [ '*' | '+' | '?' ]
条目:
'^'
'$'
'.'
字符
'[' [ '^' ] 字符遍历 ']'
'(' 正则表达式 ')'
*/
package regexp
若某个包比较简单,包注释同样可以简洁些。
// path 包实现了一些常用的工具,以便于操作用反斜杠分隔的路径.
注释无需进行额外的格式化,如用星号来突出等。生成的输出甚至可能无法以等宽字体显示, 因此不要依赖于空格对齐,godoc 会像 gofmt 那样处理好这一切。 注释是不会被解析的纯文本,因此像 HTML 或其它类似于 _这样_ 的东西将按照 原样 输出,因此不应使用它们。godoc 所做的调整, 就是将已缩进的文本以等宽字体显示,来适应对应的程序片段。 fmt 包的注释就用了这种不错的效果。
godoc 是否会重新格式化注释取决于上下文,因此必须确保它们看起来清晰易辨: 使用正确的拼写、标点和语句结构以及折叠长行等。
在包中,任何顶级声明前面的注释都将作为该声明的 文档注释。 在程序中,每个可导出(首字母大写)的名称都应该有文档注释。
文档注释最好是完整的句子,这样它才能适应各种自动化的展示。 第一句应当以被声明的东西开头,并且是单句的摘要。
// Compile 用于解析正则表达式并返回,如果成功,则 Regexp 对象就可用于匹配所针对的文本。
func Compile(str string) (regexp *Regexp, err error) {
若注释总是以名称开头,godoc 的输出就能通过 grep 变得更加有用。假如你记不住 “Compile” 这个名称,而又在找正则表达式的解析函数, 那就可以运行
$ godoc regexp | grep parse
若包中的所有文档注释都以 “此函数…” 开头,grep 就无法帮你记住此名称。 但由于每个包的文档注释都以其名称开头,你就能看到这样的内容,它能显示你正在寻找的词语。
$ godoc regexp | grep parse
Compile parses a regular expression and returns, if successful, a Regexp
parsed. It simplifies safe initialization of global variables holding
cannot be parsed. It simplifies safe initialization of global variables
$
Go 的声明语法允许成组声明。单个文档注释应介绍一组相关的常量或变量。 由于是整体声明,这种注释往往较为笼统。
// 表达式解析失败后返回错误代码。
var (
ErrInternal = errors.New("regexp: internal error")
ErrUnmatchedLpar = errors.New("regexp: unmatched '('")
ErrUnmatchedRpar = errors.New("regexp: unmatched ')'")
...
)
即便是对于私有名称,也可通过成组声明来表明各项间的关系,例如某一组由互斥体保护的变量。
var (
countLock sync.Mutex
inputCount uint32
outputCount uint32
errorCount uint32
)
命名
正如命名在其它语言中的地位,它在 Go 中同样重要。有时它们甚至会影响语义: 例如,某个名称在包外是否可见,就取决于其首个字符是否为大写字母。 因此有必要花点时间来讨论 Go 程序中的命名约定。
包名
当一个包被导入后,包名就会成了内容的访问器。在
import "bytes"
之后,被导入的包就能通过 bytes.Buffer 来引用了。 若所有人都以相同的名称来引用其内容将大有裨益, 这也就意味着包应当有个恰当的名称:其名称应该简洁明了而易于理解。按照惯例, 包应当以小写的单个单词来命名,且不应使用下划线或驼峰记法。err 的命名就是出于简短考虑的,因为任何使用该包的人都会键入该名称。 不必担心 引用次序 的冲突。包名就是导入时所需的唯一默认名称, 它并不需要在所有源码中保持唯一,即便在少数发生冲突的情况下, 也可为导入的包选择一个别名来局部使用。 无论如何,通过文件名来判定使用的包,都是不会产生混淆的。
另一个约定就是包名应为其源码目录的基本名称。在 src/pkg/encoding/base64 中的包应作为 "encoding/base64" 导入,其包名应为 base64, 而非 encoding_base64 或 encodingBase64。
包的导入者可通过包名来引用其内容,因此包中的可导出名称可以此来避免冲突。 (请勿使用 import . 记法,它可以简化必须在被测试包外运行的测试, 除此之外应尽量避免使用。)例如,bufio 包中的缓存读取器类型叫做 Reader 而非 BufReader,因为用户将它看做 bufio.Reader,这是个清楚而简洁的名称。 此外,由于被导入的项总是通过它们的包名来确定,因此 bufio.Reader 不会与 io.Reader 发生冲突。同样,用于创建 ring.Ring 的新实例的函数(这就是 Go 中的构造函数)一般会称之为 NewRing,但由于 Ring 是该包所导出的唯一类型,且该包也叫 ring,因此它可以只叫做 New,它跟在包的后面,就像 ring.New。使用包结构可以帮助你选择好的名称。
另一个简短的例子是 once.Do,once.Do(setup) 表述足够清晰, 使用 once.DoOrWaitUntilDone(setup) 完全就是画蛇添足。 长命名并不会使其更具可读性。一份有用的说明文档通常比额外的长名更有价值。
获取器
Go 并不对获取器(getter)和设置器(setter)提供自动支持。 你应当自己提供获取器和设置器,通常很值得这样做,但若要将 Get 放到获取器的名字中,既不符合习惯,也没有必要。若你有个名为 owner (小写,未导出)的字段,其获取器应当名为 Owner(大写,可导出)而非 GetOwner。大写字母即为可导出的这种规定为区分方法和字段提供了便利。 若要提供设置器方法,SetOwner 是个不错的选择。两个命名看起来都很合理:
owner := obj.Owner()
if owner != user {
obj.SetOwner(user)
}
接口名
按照约定,只包含一个方法的接口应当以该方法的名称加上 -er 后缀来命名,如 Reader、Writer、 Formatter、CloseNotifier 等。
诸如此类的命名有很多,遵循它们及其代表的函数名会让事情变得简单。 Read、Write、Close、Flush、 String 等都具有典型的签名和意义。为避免冲突,请不要用这些名称为你的方法命名, 除非你明确知道它们的签名和意义相同。反之,若你的类型实现了的方法, 与一个众所周知的类型的方法拥有相同的含义,那就使用相同的命名。 请将字符串转换方法命名为 String 而非 ToString。
驼峰记法
最后, Go 中约定使用驼峰记法 MixedCaps 或 mixedCaps。
分号
和 C 一样, Go 的正式语法使用分号来结束语句;和 C 不同的是,这些分号并不在源码中出现。 取而代之,词法分析器会使用一条简单的规则来自动插入分号,因此因此源码中基本就不用分号了。
规则是这样的:若在新行前的最后一个标记为标识符(包括 int 和 float64 这类的单词)、数值或字符串常量之类的基本字面或以下标记之一
break continue fallthrough return ++ -- ) }
则词法分析将始终在该标记后面插入分号。这点可以概括为: “如果新行前的标记为语句的末尾,则插入分号”。
分号也可在闭括号之前直接省略,因此像
go func() { for { dst <- <-src } }()
这样的语句无需分号。通常 Go 程序只在诸如 for 循环子句这样的地方使用分号, 以此来将初始化器、条件及增量元素分开。如果你在一行中写多个语句,也需要用分号隔开。
警告:无论如何,你都不应将一个控制结构(if、for、switch 或 select)的左大括号放在下一行。如果这样做,就会在大括号前面插入一个分号,这可能引起不需要的效果。 你应该这样写
if i < f() {
g()
}
而不是这样
if i < f() // 错!
{ // 错!
g()
}
控制结构
Go 中的结构控制与 C 有许多相似之处,但其不同之处才是独到之处。 Go 不再使用 do 或 while 循环,只有一个更通用的 for;switch 要更灵活一点;if 和 switch 像 for一样可接受可选的初始化语句; 此外,还有一个包含类型选择和多路通信复用器的新控制结构:select。 其语法也有些许不同:没有圆括号,而其主体必须始终使用大括号括住。
If
在 Go 中,一个简单的 if 语句看起来像这样:
if x > 0 {
return y
}
强制的大括号促使你将简单的 if 语句分成多行。特别是在主体中包含 return 或 break 等控制语句时,这种编码风格的好处一比便知。
由于 if 和 switch 可接受初始化语句, 因此用它们来设置局部变量十分常见。
if err := file.Chmod(0664); err != nil {
log.Print(err)
return err
}
在 Go 的库中,你会发现若 if 语句不会执行到下一条语句时,亦即其执行体 以 break、continue、goto 或 return 结束时,不必要的 else 会被省略。
f, err := os.Open(name)
if err != nil {
return err
}
codeUsing(f)
下例是一种常见的情况,代码必须防范一系列的错误条件。若控制流成功继续, 则说明程序已排除错误。由于出错时将以 return 结束, 之后的代码也就无需 else 了。
f, err := os.Open(name)
if err != nil {
return err
}
d, err := f.Stat()
if err != nil {
f.Close()
return err
}
codeUsing(f, d)
重新声明与再次赋值
题外话:上一节中最后一个示例展示了短声明 := 如何使用。 调用了 os.Open 的声明为
f, err := os.Open(name)
该语句声明了两个变量 f 和 err。在几行之后,又通过
d, err := f.Stat()
调用了 f.Stat。它看起来似乎是声明了 d 和 err。 注意,尽管两个语句中都出现了 err,但这种重复仍然是合法的:err 在第一条语句中被声明,但在第二条语句中只是被再次赋值罢了。也就是说,调用 f.Stat 使用的是前面已经声明的 err,它只是被重新赋值了而已。
在满足下列条件时,已被声明的变量 v 可出现在:= 声明中:
- 本次声明与已声明的 v 处于同一作用域中(若 v 已在外层作用域中声明过,则此次声明会创建一个新的变量§),
- 在初始化中与其类型相应的值才能赋予 v,且
- 在此次声明中至少另有一个变量是新声明的。
这个特性简直就是纯粹的实用主义体现,它使得我们可以很方面地只使用一个 err 值,例如,在一个相当长的 if-else 语句链中, 你会发现它用得很频繁。
§值得一提的是,即便 Go 中的函数形参和返回值在词法上处于大括号之外, 但它们的作用域和该函数体仍然相同。
For
Go 的 for 循环类似于 C,但却不尽相同。它统一了 for 和 while,不再有 do-while 了。它有三种形式,但只有一种需要分号。
// 如同C的for循环
for init; condition; post { }
// 如同C的while循环
for condition { }
// 如同C的for(;;)循环
for { }
简短声明能让我们更容易在循环中声明下标变量:
sum := 0
for i := 0; i < 10; i++ {
sum += i
}
若你想遍历数组、切片、字符串或者映射,或从信道中读取消息, range 子句能够帮你轻松实现循环。
for key, value := range oldMap {
newMap[key] = value
}
若你只需要该遍历中的第一个项(键或下标),去掉第二个就行了:
for key := range m {
if key.expired() {
delete(m, key)
}
}
若你只需要该遍历中的第二个项(值),请使用空白标识符,即下划线来丢弃第一个值:
sum := 0
for _, value := range array {
sum += value
}
空白标识符还有多种用法,它会在后面的小节中描述。
对于字符串,range 能够提供更多便利。它能通过解析 UTF-8, 将每个独立的 Unicode 码点分离出来。错误的编码将占用一个字节,并以符文 U+FFFD 来代替。 (名称“符文”和内建类型 rune 是 Go 对单个 Unicode 码点的成称谓。 详情见语言规范)。循环
for pos, char := range "日本\x80語" { // \x80 是个非法的 UTF-8 编码
fmt.Printf("字符 %#U 始于字节位置 %d\n", char, pos)
}
将打印
字符 U+65E5 '日' 始于字节位置 0
字符 U+672C '本' 始于字节位置 3
字符 U+FFFD '�' 始于字节位置 6
字符 U+8A9E '語' 始于字节位置 7
最后, Go 没有逗号操作符,而 ++ 和 -- 为语句而非表达式。 因此,若你想要在 for 中使用多个变量,应采用平行赋值的方式 (因为它会拒绝 ++ 和 --).
// 反转 a
for i, j := 0, len(a)-1; i < j; i, j = i+1, j-1 {
a[i], a[j] = a[j], a[i]
}
Switch
Go 的 switch 比 C 的更通用。其表达式无需为常量或整数,case 语句会自上而下逐一进行求值直到匹配为止。若 switch 后面没有表达式,它将匹配 true,因此,我们可以将 if-else-if-else 链写成一个 switch,这也更符合 Go 的风格。
func unhex(c byte) byte {
switch {
case '0' <= c && c <= '9':
return c - '0'
case 'a' <= c && c <= 'f':
return c - 'a' + 10
case 'A' <= c && c <= 'F':
return c - 'A' + 10
}
return 0
}
switch 并不会自动下溯,但 case 可通过逗号分隔来列举相同的处理条件。
func shouldEscape(c byte) bool {
switch c {
case ' ', '?', '&', '=', '#', '+', '%':
return true
}
return false
}
尽管它们在 Go 中的用法和其它类C语言差不多,但 break 语句可以使 switch 提前终止。不仅是 switch, 有时候也必须打破层层的循环。在 Go 中,我们只需将标签放置到循环外,然后 “蹦” 到那里即可。下面的例子展示了二者的用法。
Loop:
for n := 0; n < len(src); n += size {
switch {
case src[n] < sizeOne:
if validateOnly {
break
}
size = 1
update(src[n])
case src[n] < sizeTwo:
if n+1 >= len(src) {
err = errShortInput
break Loop
}
if validateOnly {
break
}
size = 2
update(src[n] + src[n+1]<<shift)
}
}
当然,continue 语句也能接受一个可选的标签,不过它只能在循环中使用。
作为这一节的结束,此程序通过使用两个 switch 语句对字节数组进行比较:
// Compare 按字典顺序比较两个字节切片并返回一个整数。
// 若 a == b,则结果为零;若 a < b;则结果为 -1;若 a > b,则结果为 +1。
func Compare(a, b []byte) int {
for i := 0; i < len(a) && i < len(b); i++ {
switch {
case a[i] > b[i]:
return 1
case a[i] < b[i]:
return -1
}
}
switch {
case len(a) > len(b):
return 1
case len(a) < len(b):
return -1
}
return 0
}
类型选择
switch 也可用于判断接口变量的动态类型。如 类型选择 通过圆括号中的关键字 type 使用类型断言语法。若 switch 在表达式中声明了一个变量,那么该变量的每个子句中都将有该变量对应的类型。
var t interface{}
t = functionOfSomeType()
switch t := t.(type) {
default:
fmt.Printf("unexpected type %T", t) // %T 输出 t 是什么类型
case bool:
fmt.Printf("boolean %t\n", t) // t 是 bool 类型
case int:
fmt.Printf("integer %d\n", t) // t 是 int 类型
case *bool:
fmt.Printf("pointer to boolean %t\n", *t) // t 是 *bool 类型
case *int:
fmt.Printf("pointer to integer %d\n", *t) // t 是 *int 类型
}
函数
多值返回
Go 与众不同的特性之一就是函数和方法可返回多个值。这种形式可以改善 C 中一些笨拙的习惯: 将错误值返回(例如用 -1 表示 EOF)和修改通过地址传入的实参。
在 C 中,写入操作发生的错误会用一个负数标记,而错误码会隐藏在某个不确定的位置。 而在 Go 中,Write 会返回写入的字节数以及一个错误: “是的,您写入了一些字节,但并未全部写入,因为设备已满”。 在 os 包中,File.Write 的签名为:
func (file *File) Write(b []byte) (n int, err error)
正如文档所述,它返回写入的字节数,并在 n != len(b) 时返回一个非 nil 的 error 错误值。 这是一种常见的编码风格,更多示例见错误处理一节。
我们可以采用一种简单的方法。来避免为模拟引用参数而传入指针。 以下简单的函数可从字节数组中的特定位置获取其值,并返回该数值和下一个位置。
func nextInt(b []byte, i int) (int, int) {
for ; i < len(b) && !isDigit(b[i]); i++ {
}
x := 0
for ; i < len(b) && isDigit(b[i]); i++ {
x = x*10 + int(b[i]) - '0'
}
return x, i
}
你可以像下面这样,通过它扫描输入的切片 b 来获取数字。
for i := 0; i < len(b); {
x, i = nextInt(b, i)
fmt.Println(x)
}
可命名结果形参
Go 函数的返回值或结果 “形参” 可被命名,并作为常规变量使用,就像传入的形参一样。 命名后,一旦该函数开始执行,它们就会被初始化为与其类型相应的零值; 若该函数执行了一条不带实参的 return 语句,则结果形参的当前值将被返回。
此名称不是强制性的,但它们能使代码更加简短清晰:它们就是文档。若我们命名了 nextInt 的结果,那么它返回的 int 就值如其意了。
func nextInt(b []byte, pos int) (value, nextPos int) {
由于被命名的结果已经初始化,且已经关联至无参数的返回,它们就能让代码简单而清晰。 下面的 io.ReadFull 就是个很好的例子:
func ReadFull(r Reader, buf []byte) (n int, err error) {
for len(buf) > 0 && err == nil {
var nr int
nr, err = r.Read(buf)
n += nr
buf = buf[nr:]
}
return
}
Defer
Go 的 defer 语句用于预设一个函数调用(即推迟执行函数), 该函数会在执行 defer 的函数返回之前立即执行。它显得非比寻常, 但却是处理一些事情的有效方式,例如无论以何种路径返回,都必须释放资源的函数。 典型的例子就是解锁互斥和关闭文件。
// Contents 将文件的内容作为字符串返回。
func Contents(filename string) (string, error) {
f, err := os.Open(filename)
if err != nil {
return "", err
}
defer f.Close() // f.Close 会在我们结束后运行。
var result []byte
buf := make([]byte, 100)
for {
n, err := f.Read(buf[0:])
result = append(result, buf[0:n]...) // append 将在后面讨论。
if err != nil {
if err == io.EOF {
break
}
return "", err // 我们在这里返回后,f 就会被关闭。
}
}
return string(result), nil // 我们在这里返回后,f 就会被关闭。
}
推迟诸如 Close 之类的函数调用有两点好处:第一, 它能确保你不会忘记关闭文件。如果你以后又为该函数添加了新的返回路径时, 这种情况往往就会发生。第二,它意味着“关闭”离“打开”很近, 这总比将它放在函数结尾处要清晰明了。
被推迟函数的实参(如果该函数为方法则还包括接收者)在 推迟 执行时就会求值, 而不是在 调用 执行时才求值。这样不仅无需担心变量值在函数执行时被改变, 同时还意味着单个已推迟的调用可推迟多个函数的执行。下面是个简单的例子。
for i := 0; i < 5; i++ {
defer fmt.Printf("%d ", i)
}
被推迟的函数按照后进先出(LIFO)的顺序执行,因此以上代码在函数返回时会打印 4 3 2 1 0。一个更具实际意义的例子是通过一种简单的方法, 用程序来跟踪函数的执行。我们可以编写一对简单的跟踪例程:
func trace(s string) { fmt.Println("entering:", s) }
func untrace(s string) { fmt.Println("leaving:", s) }
// 像这样使用它们:
func a() {
trace("a")
defer untrace("a")
// 做一些事情....
}
我们可以充分利用这个特点,即被推迟函数的实参在 defer 执行时才会被求值。 跟踪例程可针对反跟踪例程设置实参。以下例子:
func trace(s string) string {
fmt.Println("entering:", s)
return s
}
func un(s string) {
fmt.Println("leaving:", s)
}
func a() {
defer un(trace("a"))
fmt.Println("in a")
}
func b() {
defer un(trace("b"))
fmt.Println("in b")
a()
}
func main() {
b()
}
会打印
entering: b
in b
entering: a
in a
leaving: a
leaving: b
对于习惯其它语言中块级资源管理的程序员,defer 似乎有点怪异, 但它最有趣而强大的应用恰恰来自于其基于函数而非块的特点。在 panic 和 recover 这两节中,我们将看到关于它可能性的其它例子。
数据
new 分配
Go 提供了两种分配原语,即内建函数 new 和 make。 它们所做的事情不同,所应用的类型也不同。它们可能会引起混淆,但规则却很简单。 让我们先来看看 new。这是个用来分配内存的内建函数, 但与其它语言中的同名函数不同,它不会 初始化 内存,只会将内存 置零。 也就是说,new(T) 会为类型为 T 的新项分配已置零的内存空间, 并返回它的地址,也就是一个类型为 *T 的值。用 Go 的术语来说,它返回一个指针, 该指针指向新分配的,类型为 T 的零值。
既然 new 返回的内存已置零,那么当你设计数据结构时, 每种类型的零值就不必进一步初始化了,这意味着该数据结构的使用者只需用 new 创建一个新的对象就能正常工作。例如,bytes.Buffer 的文档中提到“零值的 Buffer 就是已准备就绪的缓冲区。同样,sync.Mutex 并没有显式的构造函数或 Init 方法, 而是零值的 sync.Mutex 就已经被定义为已解锁的互斥锁了。
“零值属性” 可以带来各种好处。考虑以下类型声明。
type SyncedBuffer struct {
lock sync.Mutex
buffer bytes.Buffer
}
SyncedBuffer 类型的值也是在声明时就分配好内存就绪了。后续代码中, p 和 v 无需进一步处理即可正确工作。
p := new(SyncedBuffer) // type *SyncedBuffer
var v SyncedBuffer // type SyncedBuffer
构造函数与复合字面
有时零值还不够好,这时就需要一个初始化构造函数,如来自 os 包中的这段代码所示。
func NewFile(fd int, name string) *File {
if fd < 0 {
return nil
}
f := new(File)
f.fd = fd
f.name = name
f.dirinfo = nil
f.nepipe = 0
return f
}
这里显得代码过于冗长。我们可通过复合字面来简化它, 该表达式在每次求值时都会创建新的实例。
func NewFile(fd int, name string) *File {
if fd < 0 {
return nil
}
f := File{fd, name, nil, 0}
return &f
}
请注意,返回一个局部变量的地址完全没有问题,这点与 C 不同。该局部变量对应的数据 在函数返回后依然有效。实际上,每当获取一个复合字面的地址时,都将为一个新的实例分配内存, 因此我们可以将上面的最后两行代码合并:
return &File{fd, name, nil, 0}
复合字面的字段必须按顺序全部列出。但如果以 字段:值 对的形式明确地标出元素,初始化字段时就可以按任何顺序出现,未给出的字段值将赋予零值。 因此,我们可以用如下形式:
return &File{fd: fd, name: name}
少数情况下,若复合字面不包括任何字段,它将创建该类型的零值。表达式 new(File) 和 &File{} 是等价的。
复合字面同样可用于创建数组、切片以及映射,字段标签是索引还是映射键则视情况而定。 在下例初始化过程中,无论 Enone、Eio 和 Einval 的值是什么,只要它们的标签不同就行。
a := [...]string {Enone: "no error", Eio: "Eio", Einval: "invalid argument"}
s := []string {Enone: "no error", Eio: "Eio", Einval: "invalid argument"}
m := map[int]string{Enone: "no error", Eio: "Eio", Einval: "invalid argument"}
make 分配
再回到内存分配上来。内建函数 make(T, args) 的目的不同于 new(T)。它只用于创建切片、映射和信道,并返回类型为 T(而非 *T)的一个 已初始化 (而非 置零)的值。 出现这种用差异的原因在于,这三种类型本质上为引用数据类型,它们在使用前必须初始化。 例如,切片是一个具有三项内容的描述符,包含一个指向(数组内部)数据的指针、长度以及容量, 在这三项被初始化之前,该切片为 nil。对于切片、映射和信道,make 用于初始化其内部的数据结构并准备好将要使用的值。例如,
make([]int, 10, 100)
会分配一个具有 100 个 int 的数组空间,接着创建一个长度为 10, 容量为 100 并指向该数组中前 10 个元素的切片结构。(生成切片时,其容量可以省略,更多信息见切片一节。) 与此相反,new([]int) 会返回一个指向新分配的,已置零的切片结构, 即一个指向 nil 切片值的指针。
下面的例子阐明了 new 和 make 之间的区别:
var p *[]int = new([]int) // 分配切片结构;*p == nil;基本没用
var v []int = make([]int, 100) // 切片 v 现在引用了一个具有 100 个 int 元素的新数组
// 没必要的复杂:
var p *[]int = new([]int)
*p = make([]int, 100, 100)
// 习惯用法:
v := make([]int, 100)
请记住,make 只适用于映射、切片和信道且不返回指针。若要获得明确的指针, 请使用 new 分配内存。
数组
在详细规划内存布局时,数组是非常有用的,有时还能避免过多的内存分配, 但它们主要用作切片的构件。这是下一节的主题了,不过要先说上几句来为它做铺垫。
以下为数组在 Go 和 C 中的主要区别。在 Go 中,
- 数组是值。将一个数组赋予另一个数组会复制其所有元素。
- 特别地,若将某个数组传入某个函数,它将接收到该数组的一份副本而非指针。
- 数组的大小是其类型的一部分。类型 [10]int 和 [20]int 是不同的。
数组为值的属性很有用,但代价高昂;若你想要C那样的行为和效率,你可以传递一个指向该数组的指针。
func Sum(a *[3]float64) (sum float64) {
for _, v := range *a {
sum += v
}
return
}
array := [...]float64{7.0, 8.5, 9.1}
x := Sum(&array) // 注意显式的取址操作
但这并不是 Go 的习惯用法,切片才是。
切片
切片通过对数组进行封装,为数据序列提供了更通用、强大而方便的接口。 除了矩阵变换这类需要明确维度的情况外, Go 中的大部分数组编程都是通过切片来完成的。
切片保存了对底层数组的引用,若你将某个切片赋予另一个切片,它们会引用同一个数组。 若某个函数将一个切片作为参数传入,则它对该切片元素的修改对调用者而言同样可见, 这可以理解为传递了底层数组的指针。因此,Read 函数可接受一个切片实参 而非一个指针和一个计数;切片的长度决定了可读取数据的上限。以下为 os 包中 File 类型的 Read 方法签名:
func (file *File) Read(buf []byte) (n int, err error)
该方法返回读取的字节数和一个错误值(若有的话)。若要从更大的缓冲区 b 中读取前 32 个字节,只需对其进行 切片 即可。
n, err := f.Read(buf[0:32])
这种切片的方法常用且高效。若不谈效率,以下片段同样能读取该缓冲区的前 32 个字节。
var n int
var err error
for i := 0; i < 32; i++ {
nbytes, e := f.Read(buf[i:i+1]) // 读取一个字节
if nbytes == 0 || e != nil {
err = e
break
}
n += nbytes
}
只要切片不超出底层数组的限制,它的长度就是可变的,只需将它赋予其自身的切片即可。 切片的容量可通过内建函数 cap 获得,它将给出该切片可取得的最大长度。 以下是将数据追加到切片的函数。若数据超出其容量,则会重新分配该切片。返回值即为所得的切片。 该函数中所使用的 len 和 cap 在应用于 nil 切片时是合法的,它会返回 0.
func Append(slice, data[]byte) []byte {
l := len(slice)
if l + len(data) > cap(slice) { // 重新分配
// 为了后面的增长,需分配两份。
newSlice := make([]byte, (l+len(data))*2)
// copy 函数是预声明的,且可用于任何切片类型。
copy(newSlice, slice)
slice = newSlice
}
slice = slice[0:l+len(data)]
for i, c := range data {
slice[l+i] = c
}
return slice
}
最终我们必须返回切片,因为尽管 Append 可修改 slice 的元素,但切片自身(其运行时数据结构包含指针、长度和容量)是通过值传递的。
向切片追加东西的想法非常有用,因此有专门的内建函数 append。 要理解该函数的设计,我们还需要一些额外的信息,我们将稍后再介绍它。
二维切片
Go 的数组和切片都是一维的。要创建等价的二维数组或切片,就必须定义一个数组的数组, 或切片的切片,就像这样:
type Transform [3][3]float64 // 一个 3x3 的数组,其实是包含多个数组的一个数组。
type LinesOfText [][]byte // 包含多个字节切片的一个切片。
由于切片长度是可变的,因此其内部可能拥有多个不同长度的切片。在我们的 LinesOfText 例子中,这是种常见的情况:每行都有其自己的长度。
text := LinesOfText{
[]byte("Now is the time"),
[]byte("for all good gophers"),
[]byte("to bring some fun to the party."),
}
有时必须分配一个二维数组,例如在处理像素的扫描行时,这种情况就会发生。 我们有两种方式来达到这个目的。一种就是独立地分配每一个切片;而另一种就是只分配一个数组, 将各个切片都指向它。采用哪种方式取决于你的应用。若切片会增长或收缩, 就应该通过独立分配来避免覆盖下一行;若不会,用单次分配来构造对象会更加高效。 以下是这两种方法的大概代码,仅供参考。首先是一次一行的:
// 分配顶层切片。
picture := make([][]uint8, YSize) // 每 y 个单元一行。
// 遍历行,为每一行都分配切片
for i := range picture {
picture[i] = make([]uint8, XSize)
}
现在是一次分配,对行进行切片:
// 分配顶层切片,和前面一样。
picture := make([][]uint8, YSize) // 每 y 个单元一行。
// 分配一个大的切片来保存所有像素
pixels := make([]uint8, XSize*YSize) // 拥有类型 []uint8,尽管图片是 [][]uint8.
// 遍历行,从剩余像素切片的前面切出每行来。
for i := range picture {
picture[i], pixels = pixels[:XSize], pixels[XSize:]
}
映射
映射是方便而强大的内建数据结构,它可以关联不同类型的值。其键可以是任何相等性操作符支持的类型, 如整数、浮点数、复数、字符串、指针、接口(只要其动态类型支持相等性判断)、结构以及数组。 切片不能用作映射键,因为它们的相等性还未定义。与切片一样,映射也是引用类型。 若将映射传入函数中,并更改了该映射的内容,则此修改对调用者同样可见。
映射可使用一般的复合字面语法进行构建,其键-值对使用逗号分隔,因此可在初始化时很容易地构建它们。
var timeZone = map[string]int{
"UTC": 0*60*60,
"EST": -5*60*60,
"CST": -6*60*60,
"MST": -7*60*60,
"PST": -8*60*60,
}
赋值和获取映射值的语法类似于数组,不同的是映射的索引不必为整数。
offset := timeZone["EST"]
若试图通过映射中不存在的键来取值,就会返回与该映射中项的类型对应的零值。 例如,若某个映射包含整数,当查找一个不存在的键时会返回 0。 集合可实现成一个值类型为 bool 的映射。将该映射中的项置为 true 可将该值放入集合中,此后通过简单的索引操作即可判断是否存在。
attended := map[string]bool{
"Ann": true,
"Joe": true,
...
}
if attended[person] { // 若某人不在此映射中,则为 false
fmt.Println(person, "正在开会")
}
有时你需要区分某项是不存在还是其值为零值。如对于一个值本应为零的 "UTC" 条目,也可能是由于不存在该项而得到零值。你可以使用多重赋值的形式来分辨这种情况。
var seconds int
var ok bool
seconds, ok = timeZone[tz]
显然,我们可称之为 “逗号 ok” 惯用法。在下面的例子中,若 tz 存在, seconds 就会被赋予适当的值,且 ok 会被置为 true; 若不存在,seconds 则会被置为零,而 ok 会被置为 false。
func offset(tz string) int {
if seconds, ok := timeZone[tz]; ok {
return seconds
}
log.Println("unknown time zone:", tz)
return 0
}
若仅需判断映射中是否存在某项而不关心实际的值,可使用空白标识符(_)来代替该值的一般变量。
_, present := timeZone[tz]
要删除映射中的某项,可使用内建函数 delete,它以映射及要被删除的键为实参。 即便对应的键不在该映射中,此操作也是安全的。
delete(timeZone, "PDT") // 现在用标准时间
打印
Go 采用的格式化打印风格和 C 的 printf 族类似,但却更加丰富而通用。 这些函数位于 fmt 包中,且函数名首字母均为大写:如 fmt.Printf、fmt.Fprintf,fmt.Sprintf 等。 字符串函数(Sprintf 等)会返回一个字符串,而非填充给定的缓冲区。
你无需提供一个格式字符串。每个 Printf、Fprintf 和 Sprintf 都分别对应另外的函数,如 Print 与 Println。 这些函数并不接受格式字符串,而是为每个实参生成一种默认格式。Println 系列的函数还会在实参中插入空格,并在输出时追加一个换行符,而 Print 版本仅在操作数两侧都没有字符串时才添加空白。以下示例中各行产生的输出都是一样的。
fmt.Printf("Hello %d\n", 23)
fmt.Fprint(os.Stdout, "Hello ", 23, "\n")
fmt.Println("Hello", 23)
fmt.Println(fmt.Sprint("Hello ", 23))
fmt.Fprint 一类的格式化打印函数可接受任何实现了 io.Writer 接口的对象作为第一个实参;变量 os.Stdout 与 os.Stderr 都是人们熟知的例子。
从这里开始,就与 C 有些不同了。首先,像 %d 这样的数值格式并不接受表示符号或大小的标记, 打印例程会根据实参的类型来决定这些属性。
var x uint64 = 1<<64 - 1
fmt.Printf("%d %x; %d %x\n", x, x, int64(x), int64(x))
将打印
18446744073709551615 ffffffffffffffff; -1 -1
若你只想要默认的转换,如使用十进制的整数,你可以使用通用的格式 %v(对应“值”);其结果与 Print 和 Println 的输出完全相同。此外,这种格式还能打印 任意 值,甚至包括数组、结构体和映射。 以下是打印上一节中定义的时区映射的语句。
fmt.Printf("%v\n", timeZone) // 或只用 fmt.Println(timeZone)
这会输出
map[CST:-21600 PST:-28800 EST:-18000 UTC:0 MST:-25200]
当然,映射中的键可能按任意顺序输出。当打印结构体时,改进的格式 %+v 会为结构体的每个字段添上字段名,而另一种格式 %#v 将完全按照 Go 的语法打印值。
type T struct {
a int
b float64
c string
}
t := &T{ 7, -2.35, "abc\tdef" }
fmt.Printf("%v\n", t)
fmt.Printf("%+v\n", t)
fmt.Printf("%#v\n", t)
fmt.Printf("%#v\n", timeZone)
将打印
&{7 -2.35 abc def}
&{a:7 b:-2.35 c:abc def}
&main.T{a:7, b:-2.35, c:"abc\tdef"}
map[string] int{"CST":-21600, "PST":-28800, "EST":-18000, "UTC":0, "MST":-25200}
(请注意其中的&符号)当遇到 string 或 []byte 值时, 可使用 %q 产生带引号的字符串;而格式 %#q 会尽可能使用反引号。 (%q 格式也可用于整数和符文,它会产生一个带单引号的符文常量。) 此外,%x 还可用于字符串、字节数组以及整数,并生成一个很长的十六进制字符串, 而带空格的格式(%x)还会在字节之间插入空格。
另一种实用的格式是 %T,它会打印某个值的类型.
fmt.Printf("%T\n", timeZone)
会打印
map[string] int
若你想控制自定义类型的默认格式,只需为该类型定义一个具有 String() string 签名的方法。对于我们简单的类型 T,可进行如下操作。
func (t *T) String() string {
return fmt.Sprintf("%d/%g/%q", t.a, t.b, t.c)
}
fmt.Printf("%v\n", t)
会打印出如下格式:
7/-2.35/"abc\tdef"
(如果你需要像指向 T 的指针那样打印类型 T 的值, String 的接收者就必须是值类型的;上面的例子中接收者是一个指针, 因为这对结构来说更高效而通用。更多详情见 指针vs.值 接收者一节.)
我们的 String 方法也可调用 Sprintf, 因为打印例程可以完全重入并按这种方式封装。不过要理解这种方式,还有一个重要的细节: 请勿通过调用 Sprintf 来构造 String 方法,因为它会无限递归你的的 String 方法。
type MyString string
func (m MyString) String() string {
return fmt.Sprintf("MyString=%s", m) // 错误:会无限递归
}
要解决这个问题也很简单:将该实参转换为基本的字符串类型,它没有这个方法。
type MyString string
func (m MyString) String() string {
return fmt.Sprintf("MyString=%s", string(m)) // 可以:注意转换
}
在初始化一节中,我们将看到避免这种递归的另一种技术。
另一种打印技术就是将打印例程的实参直接传入另一个这样的例程。Printf 的签名为其最后的实参使用了 ...interface{} 类型,这样格式的后面就能出现任意数量,任意类型的形参了。
func Printf(format string, v ...interface{}) (n int, err error) {
在 Printf 函数中,v 看起来更像是 []interface{} 类型的变量,但如果将它传递到另一个变参函数中,它就像是常规实参列表了。 以下是我们之前用过的 log.Println 的实现。它直接将其实参传递给 fmt.Sprintln 进行实际的格式化。
// Println 通过 fmt.Println 的方式将日志打印到标准记录器。
func Println(v ...interface{}) {
std.Output(2, fmt.Sprintln(v...)) // Output 接受形参 (int, string)
}
在该 Sprintln 嵌套调用中,我们将 ... 写在 v 之后来告诉编译器将 v 视作一个实参列表,否则它会将 v 当做单一的切片实参来传递。
还有很多关于打印知识点没有提及。详情请参阅 godoc 对 fmt 包的说明文档。
顺便一提,... 形参可指定具体的类型,例如从整数列表中选出最小值的函数 min,其形参可为 ...int 类型。
func Min(a ...int) int {
min := int(^uint(0) >> 1) // 最大的 int
for _, i := range a {
if i < min {
min = i
}
}
return min
}
追加
现在我们要对内建函数 append 的设计进行补充说明。append 函数的签名不同于前面我们自定义的 Append 函数。大致来说,它就像这样:
func append(slice []T, 元素 ...T) []T
其中的 T 为任意给定类型的占位符。实际上,你无法在 Go 中编写一个类型 T 由调用者决定的函数。这也就是为何 append 为内建函数的原因:它需要编译器的支持。
append 会在切片末尾追加元素并返回结果。我们必须返回结果, 原因与我们手写的 Append 一样,即底层数组可能会被改变。以下简单的例子
x := []int{1,2,3}
x = append(x, 4, 5, 6)
fmt.Println(x)
将打印 [1 2 3 4 5 6]。因此 append 有点像 Printf 那样,可接受任意数量的实参。
但如果我们要像 Append 那样将一个切片追加到另一个切片中呢? 很简单:在调用的地方使用 ...,就像我们在上面调用 Output 那样。以下代码片段的输出与上一个相同。
x := []int{1,2,3}
y := []int{4,5,6}
x = append(x, y...)
fmt.Println(x)
如果没有 ...,它就会由于类型错误而无法编译,因为 y 不是 int 类型的。
初始化
尽管从表面上看, Go 的初始化过程与 C 或 C++ 并不算太大,但它确实更为强大。 在初始化过程中,不仅可以构建复杂的结构,还能正确处理不同包对象间的初始化顺序。
常量
Go 中的常量就是不变量。它们在编译时创建,即便它们可能是函数中定义的局部变量。 常量只能是数字、字符(符文)、字符串或布尔值。由于编译时的限制, 定义它们的表达式必须也是可被编译器求值的常量表达式。例如 1<<3 就是一个常量表达式,而 math.Sin(math.Pi/4) 则不是,因为对 math.Sin 的函数调用在运行时才会发生。
在 Go 中,枚举常量使用枚举器 iota 创建。由于 iota 可为表达式的一部分,而表达式可以被隐式地重复,这样也就更容易构建复杂的值的集合了。
type ByteSize float64
const (
// 通过赋予空白标识符来忽略第一个值
_ = iota // ignore first value by assigning to blank identifier
KB ByteSize = 1 << (10 * iota)
MB
GB
TB
PB
EB
ZB
YB
)
由于可将 String 之类的方法附加在用户定义的类型上, 因此它就为打印时自动格式化任意值提供了可能性,即便是作为一个通用类型的一部分。 尽管你常常会看到这种技术应用于结构体,但它对于像 ByteSize 之类的浮点数标量等类型也是有用的。
func (b ByteSize) String() string {
switch {
case b >= YB:
return fmt.Sprintf("%.2fYB", b/YB)
case b >= ZB:
return fmt.Sprintf("%.2fZB", b/ZB)
case b >= EB:
return fmt.Sprintf("%.2fEB", b/EB)
case b >= PB:
return fmt.Sprintf("%.2fPB", b/PB)
case b >= TB:
return fmt.Sprintf("%.2fTB", b/TB)
case b >= GB:
return fmt.Sprintf("%.2fGB", b/GB)
case b >= MB:
return fmt.Sprintf("%.2fMB", b/MB)
case b >= KB:
return fmt.Sprintf("%.2fKB", b/KB)
}
return fmt.Sprintf("%.2fB", b)
}
表达式 YB 会打印出 1.00YB,而 ByteSize(1e13) 则会打印出 9.09。
在这里用 Sprintf 实现 ByteSize 的 String 方法很安全(不会无限递归),这倒不是因为类型转换,而是它以 %f 调用了 Sprintf,它并不是一种字符串格式:Sprintf 只会在它需要字符串时才调用 String 方法,而 %f 需要一个浮点数值。
变量
变量的初始化与常量类似,但其初始值也可以是在运行时才被计算的一般表达式。
var (
home = os.Getenv("HOME")
user = os.Getenv("USER")
gopath = os.Getenv("GOPATH")
)
init 函数
最后,每个源文件都可以通过定义自己的无参数 init 函数来设置一些必要的状态。 (其实每个文件都可以拥有多个 init 函数。)而它的结束就意味着初始化结束: 只有该包中的所有变量声明都通过它们的初始化器求值后 init 才会被调用, 而那些 init 只有在所有已导入的包都被初始化后才会被求值。
除了那些不能被表示成声明的初始化外,init 函数还常被用在程序真正开始执行前,检验或校正程序的状态。
func init() {
if user == "" {
log.Fatal("$USER not set")
}
if home == "" {
home = "/home/" + user
}
if gopath == "" {
gopath = home + "/go"
}
// gopath 可通过命令行中的 --gopath 标记覆盖掉。
flag.StringVar(&gopath, "gopath", gopath, "override default GOPATH")
}
方法
指针 vs. 值
正如 ByteSize 那样,我们可以为任何已命名的类型(除了指针或接口)定义方法; 接收者可不必为结构体。
在之前讨论切片时,我们编写了一个 Append 函数。 我们也可将其定义为切片的方法。为此,我们首先要声明一个已命名的类型来绑定该方法, 然后使该方法的接收者成为该类型的值。
type ByteSlice []byte
func (slice ByteSlice) Append(data []byte) []byte {
// 主体和前面相同。
}
我们仍然需要该方法返回更新后的切片。为了消除这种不便,我们可通过重新定义该方法, 将一个指向 ByteSlice 的指针作为该方法的接收者, 这样该方法就能重写调用者提供的切片了。
func (p *ByteSlice) Append(data []byte) {
slice := *p
// 主体和前面相同,但没有 return。
*p = slice
}
其实我们做得更好。若我们将函数修改为与标准 Write 类似的方法,就像这样,
func (p *ByteSlice) Write(data []byte) (n int, err error) {
slice := *p
// 依旧和前面相同。
*p = slice
return len(data), nil
}
那么类型 *ByteSlice 就满足了标准的 io.Writer 接口,这将非常实用。 例如,我们可以通过打印将内容写入。
var b ByteSlice
fmt.Fprintf(&b, "This hour has %d days\n", 7)
我们将 ByteSlice 的地址传入,因为只有 *ByteSlice 才满足 io.Writer。以指针或值为接收者的区别在于:值方法可通过指针和值调用, 而指针方法只能通过指针来调用。
之所以会有这条规则是因为指针方法可以修改接收者;通过值调用它们会导致方法接收到该值的副本, 因此任何修改都将被丢弃,因此该语言不允许这种错误。不过有个方便的例外:若该值是可寻址的, 那么该语言就会自动插入取址操作符来对付一般的通过值调用的指针方法。在我们的例子中,变量 b 是可寻址的,因此我们只需通过 b.Write 来调用它的 Write 方法,编译器会将它重写为 (&b).Write。
顺便一提,在字节切片上使用 Write 的想法已被 bytes.Buffer 所实现。
接口与其它类型
接口
Go 中的接口为指定对象的行为提供了一种方法:如果某样东西可以完成这个, 那么它就可以用在这里。我们已经见过许多简单的示例了;通过实现 String 方法,我们可以自定义打印函数,而通过 Write 方法,Fprintf 则能对任何对象产生输出。在 Go 代码中, 仅包含一两种方法的接口很常见,且其名称通常来自于实现它的方法, 如 io.Writer 就是实现了 Write 的一类对象。
每种类型都能实现多个接口。例如一个实现了 sort.Interface 接口的集合就可通过 sort 包中的例程进行排序。该接口包括 Len()、Less(i, j int) bool 以及 Swap(i, j int),另外,该集合仍然可以有一个自定义的格式化器。 以下特意构建的例子 Sequence 就同时满足这两种情况。
type Sequence []int
// Methods required by sort.Interface.
// sort.Interface 所需的方法。
func (s Sequence) Len() int {
return len(s)
}
func (s Sequence) Less(i, j int) bool {
return s[i] < s[j]
}
func (s Sequence) Swap(i, j int) {
s[i], s[j] = s[j], s[i]
}
// Method for printing - sorts the elements before printing.
// 用于打印的方法 - 在打印前对元素进行排序。
func (s Sequence) String() string {
sort.Sort(s)
str := "["
for i, elem := range s {
if i > 0 {
str += " "
}
str += fmt.Sprint(elem)
}
return str + "]"
}
类型转换
Sequence 的 String 方法重新实现了 Sprint 为切片实现的功能。若我们在调用 Sprint 之前将 Sequence 转换为纯粹的 []int,就能共享已实现的功能。
func (s Sequence) String() string {
sort.Sort(s)
return fmt.Sprint([]int(s))
}
该方法是通过类型转换技术,在 String 方法中安全调用 Sprintf 的另个一例子。若我们忽略类型名的话,这两种类型(Sequence和 []int)其实是相同的,因此在二者之间进行转换是合法的。 转换过程并不会创建新值,它只是值暂让现有的时看起来有个新类型而已。 (还有些合法转换则会创建新值,如从整数转换为浮点数等。)
在 Go 程序中,为访问不同的方法集而进行类型转换的情况非常常见。 例如,我们可使用现有的 sort.IntSlice 类型来简化整个示例:
type Sequence []int
// // 用于打印的方法 - 在打印前对元素进行排序。
func (s Sequence) String() string {
sort.IntSlice(s).Sort()
return fmt.Sprint([]int(s))
}
现在,不必让 Sequence 实现多个接口(排序和打印), 我们可通过将数据条目转换为多种类型(Sequence、sort.IntSlice 和 []int)来使用相应的功能,每次转换都完成一部分工作。 这在实践中虽然有些不同寻常,但往往却很有效。
接口转换与类型断言
类型选择是类型转换的一种形式:它接受一个接口,在选择 (switch)中根据其判断选择对应的情况(case), 并在某种意义上将其转换为该种类型。以下代码为 fmt.Printf 通过类型选择将值转换为字符串的简化版。若它已经为字符串,我们需要该接口中实际的字符串值; 若它有 String 方法,我们则需要调用该方法所得的结果。
type Stringer interface {
String() string
}
var value interface{} // 调用者提供的值。
switch str := value.(type) {
case string:
return str
case Stringer:
return str.String()
}
第一种情况获取具体的值,第二种将该接口转换为另一个接口。这种方式对于混合类型来说非常完美。
若我们只关心一种类型呢?若我们知道该值拥有一个 string 而想要提取它呢? 只需一种情况的类型选择就行,但它需要类型断言。类型断言接受一个接口值, 并从中提取指定的明确类型的值。其语法借鉴自类型选择开头的子句,但它需要一个明确的类型, 而非 type 关键字:
value.(typeName)
而其结果则是拥有静态类型 typeName 的新值。该类型必须为该接口所拥有的具体类型, 或者该值可转换成的第二种接口类型。要提取我们知道在该值中的字符串,可以这样:
str := value.(string)
但若它所转换的值中不包含字符串,该程序就会以运行时错误崩溃。为避免这种情况, 需使用 “逗号, ok” 惯用测试它能安全地判断该值是否为字符串:
str, ok := value.(string)
if ok {
fmt.Printf("字符串值为 %q\n", str)
} else {
fmt.Printf("该值非字符串\n")
}
若类型断言失败,str 将继续存在且为字符串类型,但它将拥有零值,即空字符串。
作为对能量的说明,这里有个 if-else 语句,它等价于本节开头的类型选择。
if str, ok := value.(string); ok {
return str
} else if str, ok := value.(Stringer); ok {
return str.String()
}
通用性
若某种现有的类型仅实现了一个接口,且除此之外并无可导出的方法,则该类型本身就无需导出。 仅导出该接口能让我们更专注于其行为而非实现,其它属性不同的实现则能镜像该原始类型的行为。 这也能够避免为每个通用接口的实例重复编写文档。
在这种情况下,构造函数应当返回一个接口值而非实现的类型。例如在 hash 库中,crc32.NewIEEE 和 adler32.New 都返回接口类型 hash.Hash32。要在 Go 程序中用 Adler-32 算法替代 CRC-32, 只需修改构造函数调用即可,其余代码则不受算法改变的影响。
同样的方式能将 crypto 包中多种联系在一起的流密码算法与块密码算法分开。 crypto/cipher 包中的 Block 接口指定了块密码算法的行为, 它为单独的数据块提供加密。接着,和 bufio 包类似,任何实现了该接口的密码包都能被用于构造以 Stream 为接口表示的流密码,而无需知道块加密的细节。
crypto/cipher 接口看其来就像这样:
type Block interface {
BlockSize() int
Encrypt(src, dst []byte)
Decrypt(src, dst []byte)
}
type Stream interface {
XORKeyStream(dst, src []byte)
}
这是计数器模式 CTR 流的定义,它将块加密改为流加密,注意块加密的细节已被抽象化了。
// NewCTR 返回一个 Stream,其加密/解密使用计数器模式中给定的 Block 进行。
// iv 的长度必须与 Block 的块大小相同。
func NewCTR(block Block, iv []byte) Stream
NewCTR 的应用并不仅限于特定的加密算法和数据源,它适用于任何对 Block 接口和 Stream 的实现。因为它们返回接口值, 所以用其它加密模式来代替 CTR 只需做局部的更改。构造函数的调用过程必须被修改, 但由于其周围的代码只能将它看做 Stream,因此它们不会注意到其中的区别。
接口和方法
由于几乎任何类型都能添加方法,因此几乎任何类型都能满足一个接口。一个很直观的例子就是 http 包中定义的 Handler 接口。任何实现了 Handler 的对象都能够处理 HTTP 请求。
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
ResponseWriter 接口提供了对方法的访问,这些方法需要响应客户端的请求。 由于这些方法包含了标准的 Write 方法,因此 http.ResponseWriter 可用于任何 io.Writer 适用的场景。Request 结构体包含已解析的客户端请求。
为简单起见,我们假设所有的 HTTP 请求都是 GET 方法,而忽略 POST 方法, 这种简化不会影响处理程序的建立方式。这里有个短小却完整的处理程序实现, 它用于记录某个页面被访问的次数。
// 简单的计数器服务。
type Counter struct {
n int
}
func (ctr *Counter) ServeHTTP(w http.ResponseWriter, req *http.Request) {
ctr.n++
fmt.Fprintf(w, "counter = %d\n", ctr.n)
}
(紧跟我们的主题,注意 Fprintf 如何能输出到 http.ResponseWriter。) 作为参考,这里演示了如何将这样一个服务器添加到URL树的一个节点上。
import "net/http"
...
ctr := new(Counter)
http.Handle("/counter", ctr)
但为什么 Counter 要是结构体呢?一个整数就够了。 An integer is all that's needed. (接收者必须为指针,增量操作对于调用者才可见。)
// 简单的计数器服务。
type Counter int
func (ctr *Counter) ServeHTTP(w http.ResponseWriter, req *http.Request) {
*ctr++
fmt.Fprintf(w, "counter = %d\n", *ctr)
}
当页面被访问时,怎样通知你的程序去更新一些内部状态呢?为Web页面绑定个信道吧。
// 每次浏览该信道都会发送一个提醒。
// (可能需要带缓冲的信道。)
type Chan chan *http.Request
func (ch Chan) ServeHTTP(w http.ResponseWriter, req *http.Request) {
ch <- req
fmt.Fprint(w, "notification sent")
}
最后,假设我们需要输出调用服务器二进制程序时使用的实参 /args。 很简单,写个打印实参的函数就行了。
func ArgServer() {
fmt.Println(os.Args)
}
我们如何将它转换为 HTTP 服务器呢?我们可以将 ArgServer 实现为某种可忽略值的方法,不过还有种更简单的方法。 既然我们可以为除指针和接口以外的任何类型定义方法,同样也能为一个函数写一个方法。 http 包包含以下代码:
// HandlerFunc 类型是一个适配器,它允许将普通函数用做HTTP处理程序。
// 若 f 是个具有适当签名的函数,HandlerFunc(f) 就是个调用 f 的处理程序对象。
type HandlerFunc func(ResponseWriter, *Request)
// ServeHTTP calls f(c, req).
func (f HandlerFunc) ServeHTTP(w ResponseWriter, req *Request) {
f(w, req)
}
HandlerFunc 是个具有 ServeHTTP 方法的类型, 因此该类型的值就能处理 HTTP 请求。我们来看看该方法的实现:接收者是一个函数 f,而该方法调用 f。这看起来很奇怪,但不必大惊小怪, 区别在于接收者变成了一个信道,而方法通过该信道发送消息。
为了将 ArgServer 实现成HTTP服务器,首先我们得让它拥有合适的签名。
// 实参服务器。
func ArgServer(w http.ResponseWriter, req *http.Request) {
fmt.Fprintln(w, os.Args)
}
ArgServer 和 HandlerFunc 现在拥有了相同的签名, 因此我们可将其转换为这种类型以访问它的方法,就像我们将 Sequence 转换为 IntSlice 以访问 IntSlice.Sort 那样。 建立代码非常简单:
http.Handle("/args", http.HandlerFunc(ArgServer))
当有人访问 /args 页面时,安装到该页面的处理程序就有了值 ArgServer 和类型 HandlerFunc。 HTTP服务器会以 ArgServer 为接收者,调用该类型的 ServeHTTP 方法,它会反过来调用 ArgServer(通过 f(c, req)),接着实参就会被显示出来。
在本节中,我们通过一个结构体,一个整数,一个信道和一个函数,建立了一个 HTTP 服务器, 这一切都是因为接口只是方法的集和,而几乎任何类型都能定义方法。
空白标识符
我们在 for-range 循环和映射中提过几次空白标识符。 空白标识符可被赋予或声明为任何类型的任何值,而其值会被无害地丢弃。它有点像 Unix 中的 /dev/null 文件:它表示只写的值,在需要变量但不需要实际值的地方用作占位符。 我们在前面已经见过它的用法了。
多重赋值中的空白标识符
for range 循环中对空表标识符的用法是一种具体情况,更一般的情况即为多重赋值。
若某次赋值需要匹配多个左值,但其中某个变量不会被程序使用, 那么用空白标识符来代替该变量可避免创建无用的变量,并能清楚地表明该值将被丢弃。 例如,当调用某个函数时,它会返回一个值和一个错误,但只有错误很重要, 那么可使用空白标识符来丢弃无关的值。
if _, err := os.Stat(path); os.IsNotExist(err) {
fmt.Printf("%s does not exist\n", path)
}
你偶尔会看见为忽略错误而丢弃错误值的代码,这是种糟糕的实践。请务必检查错误返回, 它们会提供错误的理由。
// 烂代码!若路径不存在,它就会崩溃。
fi, _ := os.Stat(path)
if fi.IsDir() {
fmt.Printf("%s is a directory\n", path)
}
未使用的导入和变量
若导入某个包或声明某个变量而不使用它就会产生错误。未使用的包会让程序膨胀并拖慢编译速度, 而已初始化但未使用的变量不仅会浪费计算能力,还有可能暗藏着更大的Bug。 然而在程序开发过程中,经常会产生未使用的导入和变量。虽然以后会用到它们, 但为了完成编译又不得不删除它们才行,这很让人烦恼。空白标识符就能提供一个工作空间。
这个写了一半的程序有两个未使用的导入(fmt 和 io)以及一个未使用的变量(fd),因此它不能编译, 但若到目前为止代码还是正确的,我们还是很乐意看到它们的。
package main
import (
"fmt"
"io"
"log"
"os"
)
func main() {
fd, err := os.Open("test.go")
if err != nil {
log.Fatal(err)
}
// TODO: use fd.
}
要让编译器停止关于未使用导入的抱怨,需要空白标识符来引用已导入包中的符号。 同样,将未使用的变量 fd 赋予空白标识符也能关闭未使用变量错误。 该程序的以下版本可以编译。
package main
import (
"fmt"
"io"
"log"
"os"
)
var _ = fmt.Printf // For debugging; delete when done. // 用于调试,结束时删除。
var _ io.Reader // For debugging; delete when done. // 用于调试,结束时删除。
func main() {
fd, err := os.Open("test.go")
if err != nil {
log.Fatal(err)
}
// TODO: use fd.
_ = fd
}
按照惯例,我们应在导入并加以注释后,再使全局声明导入错误静默,这样可以让它们更易找到, 并作为以后清理它的提醒。
为副作用而导入
像前例中 fmt 或 io 这种未使用的导入总应在最后被使用或移除: 空白赋值会将代码标识为工作正在进行中。但有时导入某个包只是为了其副作用, 而没有任何明确的使用。例如,在 net/http/pprof 包的 init 函数中记录了 HTTP 处理程序的调试信息。它有个可导出的 API, 但大部分客户端只需要该处理程序的记录和通过 Web 页访问数据。只为了其副作用来导入该包, 只需将包重命名为空白标识符:
import _ "net/http/pprof"
这种导入格式能明确表示该包是为其副作用而导入的,因为没有其它使用该包的可能: 在此文件中,它没有名字。(若它有名字而我们没有使用,编译器就会拒绝该程序。)
接口检查
就像我们在前面接口中讨论的那样, 一个类型无需显式地声明它实现了某个接口。取而代之,该类型只要实现了某个接口的方法, 其实就实现了该接口。在实践中,大部分接口转换都是静态的,因此会在编译时检测。 例如,将一个 *os.File 传入一个预期的 io.Reader 函数将不会被编译, 除非 *os.File 实现了 io.Reader 接口。
尽管有些接口检查会在运行时进行。encoding/json 包中就有个实例它定义了一个 Marshaler 接口。当JSON编码器接收到一个实现了该接口的值,那么该编码器就会调用该值的编组方法, 将其转换为JSON,而非进行标准的类型转换。 编码器在运行时通过类型断言检查其属性,就像这样:
m, ok := val.(json.Marshaler)
若只需要判断某个类型是否是实现了某个接口,而不需要实际使用接口本身 (可能是错误检查部分),就使用空白标识符来忽略类型断言的值:
if _, ok := val.(json.Marshaler); ok {
fmt.Printf("value %v of type %T implements json.Marshaler\n", val, val)
}
当需要确保某个包中实现的类型一定满足该接口时,就会遇到这种情况。 若某个类型(例如 json.RawMessage) 需要一种定制的JSON表现时,它应当实现 json.Marshaler, 不过现在没有静态转换可以让编译器去自动验证它。若该类型通过忽略转换失败来满足该接口, 那么 JSON 编码器仍可工作,但它却不会使用定制的实现。为确保其实现正确, 可在该包中用空白标识符声明一个全局变量:
var _ json.Marshaler = (*RawMessage)(nil)
在此声明中,我们调用了一个 *RawMessage 转换并将其赋予了 Marshaler,以此来要求 *RawMessage 实现 Marshaler,这时其属性就会在编译时被检测。 若 json.Marshaler 接口被更改,此包将无法通过编译, 而我们则会注意到它需要更新。
在这种结构中出现空白标识符,即表示该声明的存在只是为了类型检查。 不过请不要为满足接口就将它用于任何类型。作为约定, 仅当代码中不存在静态类型转换时才能这种声明,毕竟这是种罕见的情况。
内嵌
Go 并不提供典型的,类型驱动的子类化概念,但通过将类型 内嵌 到结构体或接口中, 它就能 “借鉴” 部分实现。
接口内嵌非常简单。我们之前提到过 io.Reader 和 io.Writer 接口,这里是它们的定义。
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
io 包也导出了一些其它接口,以此来阐明对象所需实现的方法。 例如 io.ReadWriter 就是个包含 Read 和 Write 的接口。我们可以通过显示地列出这两个方法来指明 io.ReadWriter, 但通过将这两个接口内嵌到新的接口中显然更容易且更具启发性,就像这样:
// ReadWriter 接口结合了 Reader 和 Writer 接口。
type ReadWriter interface {
Reader
Writer
}
正如它看起来那样:ReadWriter 能够做任何 Reader 和 Writer 可以做到的事情,它是内嵌接口的联合体 (它们必须是不相交的方法集)。只有接口能被嵌入到接口中。
同样的基本想法可以应用在结构体中,但其意义更加深远。bufio 包中有 bufio.Reader 和 bufio.Writer 这两个结构体类型, 它们每一个都实现了与 io 包中相同意义的接口。此外,bufio 还通过结合 reader/writer 并将其内嵌到结构体中,实现了带缓冲的 reader/writer:它列出了结构体中的类型,但并未给予它们字段名。
// ReadWriter 存储了指向 Reader 和 Writer 的指针。
// 它实现了 io.ReadWriter。
type ReadWriter struct {
*Reader // *bufio.Reader
*Writer // *bufio.Writer
}
内嵌的元素为指向结构体的指针,当然它们在使用前必须被初始化为指向有效结构体的指针。 ReadWriter 结构体和通过如下方式定义:
type ReadWriter struct {
reader *Reader
writer *Writer
}
但为了提升该字段的方法并满足 io 接口,我们同样需要提供转发的方法, 就像这样:
func (rw *ReadWriter) Read(p []byte) (n int, err error) {
return rw.reader.Read(p)
}
而通过直接内嵌结构体,我们就能避免如此繁琐。 内嵌类型的方法可以直接引用,这意味着 bufio.ReadWriter 不仅包括 bufio.Reader 和 bufio.Writer 的方法,它还同时满足下列三个接口: io.Reader、io.Writer 以及 io.ReadWriter。
还有种区分内嵌与子类的重要手段。当内嵌一个类型时,该类型的方法会成为外部类型的方法, 但当它们被调用时,该方法的接收者是内部类型,而非外部的。在我们的例子中,当 bufio.ReadWriter 的 Read 方法被调用时, 它与之前写的转发方法具有同样的效果;接收者是 ReadWriter 的 reader 字段,而非 ReadWriter 本身。
内嵌同样可以提供便利。这个例子展示了一个内嵌字段和一个常规的命名字段。
type Job struct {
Command string
*log.Logger
}
Job 类型现在有了 Log、Logf 和 *log.Logger 的其它方法。我们当然可以为 Logger 提供一个字段名,但完全不必这么做。现在,一旦初始化后,我们就能记录 Job 了:
job.Log("starting now...")
Logger 是 Job 结构体的常规字段, 因此我们可在 Job 的构造函数中,通过一般的方式来初始化它,就像这样:
func NewJob(command string, logger *log.Logger) *Job {
return &Job{command, logger}
}
或通过复合字面:
job := &Job{command, log.New(os.Stderr, "Job: ", log.Ldate)}
若我们需要直接引用内嵌字段,可以忽略包限定名,直接将该字段的类型名作为字段名, 就像我们在 ReaderWriter 结构体的 Read 方法中做的那样。 若我们需要访问 Job 类型的变量 job 的 *log.Logger, 可以直接写作 job.Logger。若我们想精炼 Logger 的方法时, 这会非常有用。
func (job *Job) Logf(format string, args ...interface{}) {
job.Logger.Logf("%q: %s", job.Command, fmt.Sprintf(format, args...))
}
内嵌类型会引入命名冲突的问题,但解决规则却很简单。首先,字段或方法 X 会隐藏该类型中更深层嵌套的其它项 X。若 log.Logger 包含一个名为 Command 的字段或方法,Job 的 Command 字段会覆盖它。
其次,若相同的嵌套层级上出现同名冲突,通常会产生一个错误。若 Job 结构体中包含名为 Logger 的字段或方法,再将 log.Logger 内嵌到其中的话就会产生错误。然而,若重名永远不会在该类型定义之外的程序中使用,那就不会出错。 这种限定能够在外部嵌套类型发生修改时提供某种保护。 因此,就算添加的字段与另一个子类型中的字段相冲突,只要这两个相同的字段永远不会被使用就没问题。
并发
通过通信共享内存
并发编程是个很大的论题。但限于篇幅,这里仅讨论一些 Go 特有的东西。
在并发编程中,为实现对共享变量的正确访问需要精确的控制,这在多数环境下都很困难。 Go 语言另辟蹊径,它将共享的值通过信道传递,实际上,多个独立执行的线程从不会主动共享。 在任意给定的时间点,只有一个 Go 程能够访问该值。数据竞争从设计上就被杜绝了。 为了提倡这种思考方式,我们将它简化为一句口号:
不要通过共享内存来通信,而应通过通信来共享内存。
这种方法意义深远。例如,引用计数通过为整数变量添加互斥锁来很好地实现。 但作为一种高级方法,通过信道来控制访问能够让你写出更简洁,正确的程序。
我们可以从典型的单线程运行在单 CPU 之上的情形来审视这种模型。它无需提供同步原语。 现在考虑另一种情况,它也无需同步。现在让它们俩进行通信。若将通信过程看做同步着, 那就完全不需要其它同步了。例如,Unix 管道就与这种模型完美契合。 尽管 Go 的并发处理方式来源于 Hoare 的通信顺序处理(CSP), 它依然可以看做是类型安全的 Unix 管道的实现。
Go 程
我们称之为 Go 程是因为现有的术语:线程、协程、进程等等,无法准确传达它的含义。 Go 程具有简单的模型:它是与其它 Go 程并发运行在同一地址空间的函数。它是轻量级的, 所有小号几乎就只有栈空间的分配。而且栈最开始是非常小的,所以它们很廉价, 仅在需要时才会随着堆空间的分配(和释放)而变化。
Go 程在多线程操作系统上可实现多路复用,因此若一个线程阻塞,比如说等待 I/O, 那么其它的线程就会运行。 Go 程的设计隐藏了线程创建和管理的诸多复杂性。
在函数或方法前添加 go 关键字能够在新的 Go 程中调用它。当调用完成后, 该 Go 程也会安静地退出。(效果有点像 Unix Shell 中的 & 符号,它能让命令在后台运行。)
go list.Sort() // 并发运行 list.Sort,无需等它结束。
函数字面在 Go 程调用中非常有用。
func Announce(message string, delay time.Duration) {
go func() {
time.Sleep(delay)
fmt.Println(message)
}() // 注意括号 - 必须调用该函数。
}
在 Go 中,函数字面都是闭包:其实现在保证了函数内引用变量的生命周期与函数的活动时间相同。
这些函数没什么实用性,因为它们没有实现完成时的信号处理。因此,我们需要信道。
信道
信道与映射一样,也需要通过 make 来分配内存。其结果值充当了对底层数据结构的引用。 若提供了一个可选的整数形参,它就会为该信道设置缓冲区大小。默认值是零,表示不带缓冲的或同步的信道。
ci := make(chan int) // 整数类型的无缓冲信道
cj := make(chan int, 0) // 整数类型的无缓冲信道
cs := make(chan *os.File, 100) // 指向文件指针的带缓冲信道
无缓冲信道在通信时会同步交换数据,它能确保(两个 Go 程的)计算处于确定状态。
信道有很多惯用法,我们从这里开始了解。在上一节中,我们在后台启动了排序操作。 信道使得启动的 Go 程等待排序完成。
c := make(chan int) // 分配一个信道
// 在 Go 程中启动排序。当它完成后,在信道上发送信号。
go func() {
list.Sort()
c <- 1 // 发送信号,什么值无所谓。
}()
doSomethingForAWhile()
<-c // 等待排序结束,丢弃发来的值。
接收者在收到数据前会一直阻塞。若信道是不带缓冲的,那么在接收者收到值前, 发送者会一直阻塞;若信道是带缓冲的,则发送者仅在值被复制到缓冲区前阻塞; 若缓冲区已满,发送者会一直等待直到某个接收者取出一个值为止。
带缓冲的信道可被用作信号量,例如限制吞吐量。在此例中,进入的请求会被传递给 handle,它从信道中接收值,处理请求后将值发回该信道中,以便让该 “信号量” 准备迎接下一次请求。信道缓冲区的容量决定了同时调用 process 的数量上限,因此我们在初始化时首先要填充至它的容量上限。
var sem = make(chan int, MaxOutstanding)
func handle(r *Request) {
sem <- 1 // 等待活动队列清空。
process(r) // 可能需要很长时间。
<-sem // 完成;使下一个请求可以运行。
}
func Serve(queue chan *Request) {
for {
req := <-queue
go handle(req) // 无需等待 handle 结束。
}
}
由于数据同步发生在信道的接收端(也就是说发送发生在 接受 之前,参见 Go 内存模型),因此信号必须在信道的接收端获取,而非发送端。
然而,它却有个设计问题:尽管只有 MaxOutstanding 个 Go 程能同时运行,但 Serve 还是为每个进入的请求都创建了新的 Go 程。其结果就是,若请求来得很快, 该程序就会无限地消耗资源。为了弥补这种不足,我们可以通过修改 Serve 来限制创建 Go 程,这是个明显的解决方案,但要当心我们修复后出现的 Bug。
func Serve(queue chan *Request) {
for req := range queue {
sem <- 1
go func() {
process(req) // 这儿有Bug,解释见下。
<-sem
}()
}
}
Bug 出现在 Go 的 for 循环中,该循环变量在每次迭代时会被重用,因此 req 变量会在所有的 Go 程间共享,这不是我们想要的。我们需要确保 req 对于每个 Go 程来说都是唯一的。有一种方法能够做到,就是将 req 的值作为实参传入到该 Go 程的闭包中:
func Serve(queue chan *Request) {
for req := range queue {
sem <- 1
go func(req *Request) {
process(req)
<-sem
}(req)
}
}
比较前后两个版本,观察该闭包声明和运行中的差别。 另一种解决方案就是以相同的名字创建新的变量,如例中所示:
func Serve(queue chan *Request) {
for req := range queue {
req := req // 为该 Go 程创建 req 的新实例。
sem <- 1
go func() {
process(req)
<-sem
}()
}
}
它的写法看起来有点奇怪
req := req
但在 Go 中这样做是合法且惯用的。你用相同的名字获得了该变量的一个新的版本, 以此来局部地刻意屏蔽循环变量,使它对每个 Go 程保持唯一。
回到编写服务器的一般问题上来。另一种管理资源的好方法就是启动固定数量的 handle Go 程,一起从请求信道中读取数据。 Go 程的数量限制了同时调用 process 的数量。Serve 同样会接收一个通知退出的信道, 在启动所有 Go 程后,它将阻塞并暂停从信道中接收消息。
func handle(queue chan *Request) {
for r := range queue {
process(r)
}
}
func Serve(clientRequests chan *Request, quit chan bool) {
// 启动处理程序
for i := 0; i < MaxOutstanding; i++ {
go handle(clientRequests)
}
<-quit // 等待通知退出。
}
信道中的信道
Go 最重要的特性就是信道是一等值,它可以被分配并像其它值到处传递。 这种特性通常被用来实现安全、并行的多路分解。
在上一节的例子中,handle 是个非常理想化的请求处理程序, 但我们并未定义它所处理的请求类型。若该类型包含一个可用于回复的信道, 那么每一个客户端都能为其回应提供自己的路径。以下为 Request 类型的大概定义。
type Request struct {
args []int
f func([]int) int
resultChan chan int
}
客户端提供了一个函数及其实参,此外在请求对象中还有个接收应答的信道。
func sum(a []int) (s int) {
for _, v := range a {
s += v
}
return
}
request := &Request{[]int{3, 4, 5}, sum, make(chan int)}
// 发送请求
clientRequests <- request
// 等待回应
fmt.Printf("answer: %d\n", <-request.resultChan)
On the server side, the handler function is the only thing that changes.
func handle(queue chan *Request) {
for req := range queue {
req.resultChan <- req.f(req.args)
}
}
要使其实际可用还有很多工作要做,这些代码仅能实现一个速率有限、并行、非阻塞 RPC 系统的 框架,而且它并不包含互斥锁。
并行化
这些设计的另一个应用是在多 CPU 核心上实现并行计算。如果计算过程能够被分为几块 可独立执行的过程,它就可以在每块计算结束时向信道发送信号,从而实现并行处理。
让我们看看这个理想化的例子。我们在对一系列向量项进行极耗资源的操作, 而每个项的值计算是完全独立的。
type Vector []float64
// 将此操应用至 v[i], v[i+1] ... 直到 v[n-1]
func (v Vector) DoSome(i, n int, u Vector, c chan int) {
for ; i < n; i++ {
v[i] += u.Op(v[i])
}
c <- 1 // 发信号表示这一块计算完成。
}
我们在循环中启动了独立的处理块,每个 CPU 将执行一个处理。 它们有可能以乱序的形式完成并结束,但这没有关系; 我们只需在所有 Go 程开始后接收,并统计信道中的完成信号即可。
const NCPU = 4 // CPU核心数
func (v Vector) DoAll(u Vector) {
c := make(chan int, NCPU) // 缓冲区是可选的,但明显用上更好
for i := 0; i < NCPU; i++ {
go v.DoSome(i*len(v)/NCPU, (i+1)*len(v)/NCPU, u, c)
}
// 排空信道。
for i := 0; i < NCPU; i++ {
<-c // 等待任务完成
}
// 一切完成。
}
目前 Go 运行时的实现默认并不会并行执行代码,它只为用户层代码提供单一的处理核心。 任意数量的 Go 程都可能在系统调用中被阻塞,而在任意时刻默认只有一个会执行用户层代码。 它应当变得更智能,而且它将来肯定会变得更智能。但现在,若你希望 CPU 并行执行, 就必须告诉运行时你希望同时有多少 Go 程能执行代码。有两种途径可意识形态,要么 在运行你的工作时将 GOMAXPROCS 环境变量设为你要使用的核心数, 要么导入 runtime 包并调用 runtime.GOMAXPROCS(NCPU)。 runtime.NumCPU() 的值可能很有用,它会返回当前机器的逻辑 CPU 核心数。 当然,随着调度算法和运行时的改进,将来会不再需要这种方法。
注意不要混淆并发和并行的概念:并发是用可独立执行的组件构造程序的方法, 而并行则是为了效率在多 CPU 上平行地进行计算。尽管 Go 的并发特性能够让某些问题更易构造成并行计算, 但 Go 仍然是种并发而非并行的语言,且 Go 的模型并不适合所有的并行问题。 关于其中区别的讨论,见此博文。
可能泄露的缓冲区
并发编程的工具甚至能很容易地表达非并发的思想。这里有个提取自 RPC 包的例子。 客户端 Go 程从某些来源,可能是网络中循环接收数据。为避免分配和释放缓冲区, 它保存了一个空闲链表,使用一个带缓冲信道表示。若信道为空,就会分配新的缓冲区。 一旦消息缓冲区就绪,它将通过 serverChan 被发送到服务器。 serverChan.
var freeList = make(chan *Buffer, 100)
var serverChan = make(chan *Buffer)
func client() {
for {
var b *Buffer
// 若缓冲区可用就用它,不可用就分配个新的。
select {
case b = <-freeList:
// 获取一个,不做别的。
default:
// 非空闲,因此分配一个新的。
b = new(Buffer)
}
load(b) // 从网络中读取下一条消息。
serverChan <- b // 发送至服务器。
}
}
服务器从客户端循环接收每个消息,处理它们,并将缓冲区返回给空闲列表。
func server() {
for {
b := <-serverChan // 等待工作。
process(b)
// 若缓冲区有空间就重用它。
select {
case freeList <- b:
// 将缓冲区放大空闲列表中,不做别的。
default:
// 空闲列表已满,保持就好。
}
}
}
客户端试图从 freeList 中获取缓冲区;若没有缓冲区可用, 它就将分配一个新的。服务器将 b 放回空闲列表 freeList 中直到列表已满,此时缓冲区将被丢弃,并被垃圾回收器回收。(select 语句中的 default 子句在没有条件符合时执行,这也就意味着 selects 永远不会被阻塞。)依靠带缓冲的信道和垃圾回收器的记录, 我们仅用短短几行代码就构建了一个可能导致缓冲区槽位泄露的空闲列表。
错误
库例程通常需要向调用者返回某种类型的错误提示。之前提到过, Go 语言的多值返回特性, 使得它在返回常规的值时,还能轻松地返回详细的错误描述。按照约定,错误的类型通常为 error,这是一个内建的简单接口。
type error interface {
Error() string
}
库的编写者通过更丰富的底层模型可以轻松实现这个接口,这样不仅能看见错误, 还能提供一些上下文。例如,os.Open 可返回一个 os.PathError。
// PathError 记录一个错误以及产生该错误的路径和操作。
type PathError struct {
Op string // "open"、"unlink" 等等。
Path string // 相关联的文件。
Err error // 由系统调用返回。
}
func (e *PathError) Error() string {
return e.Op + " " + e.Path + ": " + e.Err.Error()
}
PathError 的 Error 会生成如下错误信息:
open /etc/passwx: no such file or directory
这种错误包含了出错的文件名、操作和触发的操作系统错误,即便在产生该错误的调用 和输出的错误信息相距甚远时,它也会非常有用,这比苍白的 “不存在该文件或目录” 更具说明性。
错误字符串应尽可能地指明它们的来源,例如产生该错误的包名前缀。例如在 image 包中,由于未知格式导致解码错误的字符串为 “image: unknown format”。
若调用者关心错误的完整细节,可使用类型选择或者类型断言来查看特定错误,并抽取其细节。 对于 PathErrors,它应该还包含检查内部的 Err 字段以进行可能的错误恢复。
for try := 0; try < 2; try++ {
file, err = os.Create(filename)
if err == nil {
return
}
if e, ok := err.(*os.PathError); ok && e.Err == syscall.ENOSPC {
deleteTempFiles() // 恢复一些空间。
continue
}
return
}
这里的第二条 if 是另一种类型断言。若它失败,ok 将为 false,而 e 则为nil. 若它成功,ok 将为 true,这意味着该错误属于 *os.PathError 类型,而 e 能够检测关于该错误的更多信息。
Panic
向调用者报告错误的一般方式就是将 error 作为额外的值返回。 标准的 Read 方法就是个众所周知的实例,它返回一个字节计数和一个 error。但如果错误时不可恢复的呢?有时程序就是不能继续运行。
为此,我们提供了内建的 panic 函数,它会产生一个运行时错误并终止程序 (但请继续看下一节)。该函数接受一个任意类型的实参(一般为字符串),并在程序终止时打印。 它还能表明发生了意料之外的事情,比如从无限循环中退出了。
// 用牛顿法计算立方根的一个玩具实现。
func CubeRoot(x float64) float64 {
z := x/3 // 任意初始值
for i := 0; i < 1e6; i++ {
prevz := z
z -= (z*z*z-x) / (3*z*z)
if veryClose(z, prevz) {
return z
}
}
// 一百万次迭代并未收敛,事情出错了。
panic(fmt.Sprintf("CubeRoot(%g) did not converge", x))
}
这仅仅是个示例,实际的库函数应避免 panic。若问题可以被屏蔽或解决, 最好就是让程序继续运行而不是终止整个程序。一个可能的反例就是初始化: 若某个库真的不能让自己工作,且有足够理由产生 Panic,那就由它去吧。
var user = os.Getenv("USER")
func init() {
if user == "" {
panic("no value for $USER")
}
}
恢复
当 panic 被调用后(包括不明确的运行时错误,例如切片检索越界或类型断言失败), 程序将立刻终止当前函数的执行,并开始回溯 Go 程的栈,运行任何被推迟的函数。 若回溯到达 Go 程栈的顶端,程序就会终止。不过我们可以用内建的 recover 函数来重新或来取回 Go 程的控制权限并使其恢复正常执行。
调用 recover 将停止回溯过程,并返回传入 panic 的实参。 由于在回溯时只有被推迟函数中的代码在运行,因此 recover 只能在被推迟的函数中才有效。
recover 的一个应用就是在服务器中终止失败的 Go 程而无需杀死其它正在执行的 Go 程。
func server(workChan <-chan *Work) {
for work := range workChan {
go safelyDo(work)
}
}
func safelyDo(work *Work) {
defer func() {
if err := recover(); err != nil {
log.Println("work failed:", err)
}
}()
do(work)
}
在此例中,若 do(work) 触发了 Panic,其结果就会被记录, 而该 Go 程会被干净利落地结束,不会干扰到其它 Go 程。我们无需在推迟的闭包中做任何事情, recover 会处理好这一切。
由于直接从被推迟函数中调用 recover 时不会返回 nil, 因此被推迟的代码能够调用本身使用了 panic 和 recover 的库函数而不会失败。例如在 safelyDo 中,被推迟的函数可能在调用 recover 前先调用记录函数,而该记录函数应当不受 Panic 状态的代码的影响。
通过恰当地使用恢复模式,do 函数(及其调用的任何代码)可通过调用 panic 来避免更坏的结果。我们可以利用这种思想来简化复杂软件中的错误处理。 让我们看看 regexp 包的理想化版本,它会以局部的错误类型调用 panic 来报告解析错误。以下是一个 error 类型的 Error 方法和一个 Compile 函数的定义:
// Error 是解析错误的类型,它满足 error 接口。
type Error string
func (e Error) Error() string {
return string(e)
}
// error 是 *Regexp 的方法,它通过用一个 Error 触发Panic来报告解析错误。
func (regexp *Regexp) error(err string) {
panic(Error(err))
}
// Compile 返回该正则表达式解析后的表示。
func Compile(str string) (regexp *Regexp, err error) {
regexp = new(Regexp)
// doParse will panic if there is a parse error.
defer func() {
if e := recover(); e != nil {
regexp = nil // 清理返回值。
err = e.(Error) // 若它不是解析错误,将重新触发Panic。
}
}()
return regexp.doParse(str), nil
}
若 doParse 触发了 Panic,恢复块会将返回值设为 nil —被推迟的函数能够修改已命名的返回值。在 err 的赋值过程中, 我们将通过断言它是否拥有局部类型 Error 来检查它。若它没有, 类型断言将会失败,此时会产生运行时错误,并继续栈的回溯,仿佛一切从未中断过一样。 该检查意味着若发生了一些像索引越界之类的意外,那么即便我们使用了 panic 和 recover 来处理解析错误,代码仍然会失败。
通过适当的错误处理,error 方法(由于它是个绑定到具体类型的方法, 因此即便它与内建的 error 类型名字相同也没有关系) 能让报告解析错误变得更容易,而无需手动处理回溯的解析栈:
if pos == 0 {
re.error("'*' illegal at start of expression")
}
尽管这种模式很有用,但它应当仅在包内使用。Parse 会将其内部的 panic 调用转为 error 值,它并不会向调用者暴露出 panic。这是个值得遵守的良好规则。
顺便一提,这种重新触发 Panic 的惯用法会在产生实际错误时改变 Panic 的值。 然而,不管是原始的还是新的错误都会在崩溃报告中显示,因此问题的根源仍然是可见的。 这种简单的重新触发 Panic 的模型已经够用了,毕竟他只是一次崩溃。 但若你只想显示原始的值,也可以多写一点代码来过滤掉不需要的问题,然后用原始值再次触发 Panic。 这里就将这个练习留给读者了。
一个 Web 服务器
让我们以一个完整的 Go 程序作为结束吧,一个 Web 服务器。该程序其实只是个 Web 服务器的重用。 Google 在 http://chart.apis.google.com 上提供了一个将表单数据自动转换为图表的服务。不过,该服务很难交互, 因为你需要将数据作为查询放到 URL 中。此程序为一种数据格式提供了更好的的接口: 给定一小段文本,它将调用图表服务器来生成二维码(QR 码),这是一种编码文本的点格矩阵。 该图像可被你的手机摄像头捕获,并解释为一个字符串,比如 URL, 这样就免去了你在狭小的手机键盘上键入 URL 的麻烦。
以下为完整的程序,随后有一段解释。
package main
import (
"flag"
"html/template"
"log"
"net/http"
)
var addr = flag.String("addr", ":1718", "http service address") // Q=17, R=18
var templ = template.Must(template.New("qr").Parse(templateStr))
func main() {
flag.Parse()
http.Handle("/", http.HandlerFunc(QR))
err := http.ListenAndServe(*addr, nil)
if err != nil {
log.Fatal("ListenAndServe:", err)
}
}
func QR(w http.ResponseWriter, req *http.Request) {
templ.Execute(w, req.FormValue("s"))
}
const templateStr = \`
<html>
<head>
<title>QR Link Generator</title>
</head>
<body>
{{if .}}
<img src="http://chart.apis.google.com/chart?chs=300x300&cht=qr&choe=UTF-8&chl={{.}}" />
<br>
{{.}}
<br>
<br>
{{end}}
<form action="/" name=f method="GET"><input maxLength=1024 size=70
name=s value="" title="Text to QR Encode"><input type=submit
value="Show QR" name=qr>
</form>
</body>
</html>
\`
main 之前的代码应该比较容易理解。我们通过一个标志为服务器设置了默认端口。 模板变量 templ 正式有趣的地方。它构建的 HTML 模版将会被服务器执行并显示在页面中。 稍后我们将详细讨论。
main 函数解析了参数标志并使用我们讨论过的机制将 QR 函数绑定到服务器的根路径。然后调用 http.ListenAndServe 启动服务器;它将在服务器运行时处于阻塞状态。
QR 仅接受包含表单数据的请求,并为表单值 s 中的数据执行模板。
模板包 html/template 非常强大;该程序只是浅尝辄止。 本质上,它通过在运行时将数据项中提取的元素(在这里是表单值)传给 templ.Execute 执行因而重写了 HTML 文本。 在模板文本(templateStr)中,双大括号界定的文本表示模板的动作。 从 {{if .}} 到 {{end}} 的代码段仅在当前数据项(这里是点 .)的值非空时才会执行。 也就是说,当字符串为空时,此部分模板段会被忽略。
其中两段 {{.}} 表示要将数据显示在模板中 (即将查询字符串显示 Web 页面上)。HTML 模板包将自动对文本进行转义, 因此文本的显示是安全的。
余下的模板字符串只是页面加载时将要显示的 HTML。如果这段解释你无法理解,请参考 文档 获得更多有关模板包的解释。
你终于如愿以偿了:以几行代码实现的,包含一些数据驱动的 HTML 文本的 Web 服务器。 Go 语言强大到能让很多事情以短小精悍的方式解决。
Golang 一些通用实践
使用 channel 确保 Goroutines 被执行完毕
package main
import (
"fmt"
"runtime"
)
func SayHello(content string, done chan int) {
for i := 0; i < 10; i++ {
fmt.Printf("%s\n", content)
}
if done != nil {
//done <- 0 // Signal that we're done
close(done)
}
}
func main() {
runtime.GOMAXPROCS(2)
done := make(chan int)
go SayHello("hello world", done)
SayHello("the second", nil)
<-done // Wait until done signal arrives or A receive from a closed channel returns the zero value immediately
the second
the second
the second
the second
the second
the second
the second
the second
the second
the second
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
Golang 在 windows 交叉编译 linux 可执行文件
set GOARCH=amd64
set GOOS=linux
cd xxx
go build main.go
go build -o "main"
Golang 返回值命名的意义
Golang 语言的函数可以返回多个返回值,而且可以为每个返回值指定一个名称。直接将需要返回的值赋予所设置的变量即可,最后使用
return可以实现自动的返回对应的变量值。若某个变量没有出现或被赋值则返回对应变量类型的 "零值"。注意,可以显示的更改返回值。下述代码中,如果写return 5, nil,命名变量将会被忽略,返回的真正值为5, nil。
package main
import (
"errors"
"fmt"
"math"
)
func sqrt(f float64) (ret float64, err error) {
if f < 0 {
//then you can use those variables in code
ret = float64(math.NaN())
err = errors.New("I won't be able to do a sqrt of negative number!")
} else {
ret = math.Sqrt(f)
//err is not assigned, so it gets default value nil
}
//automatically return the named return variables ret and err
return
}
func main() {
value, ok := sqrt(2)
fmt.Printf("value : %v\nok : %v\n\n", value, ok)
value, ok = sqrt(-2)
fmt.Printf("value : %v\nok : %v\n", value, ok)
}
value : 1.4142135623730951
ok : <nil>
value : NaN
ok : I won't be able to do a sqrt of negative number!
