
[C11] 推荐系统(Recommender Systems)
推荐系统(Recommender Systems)
问题阐述(Problem Formulation)
将 推荐系统 纳入这门课程来讲有以下两个原因:
第一、仅仅因为它是机器学习中的一个重要的应用。在过去几年,我偶尔访问硅谷不同的技术公司,我常和工作在这儿致力于机器学习应用的人们聊天,我常问他们,最重要的机器学习的应用是什么,或者,你最想改进的机器学习应用有哪些。我最常听到的答案是推荐系统。现在,在硅谷有很多团体试图建立很好的推荐系统。因此,如果你考虑网站像Amazon,或Netflix或Ebay,或iTunes Genius,有很多的网站或系统试图推荐新产品给用户。如,亚马逊推荐新书给你,网飞公司试图推荐新电影给你,等等。这些推荐系统,根据浏览你过去买过什么书,或过去评价过什么电影来判断。这些系统会带来很大一部分收入,比如为亚马逊和像网飞这样的公司。因此,对推荐系统性能的改善,将对这些企业的有实质性和直接的影响。推荐系统在机器学习的学术研究中,是一种有趣的问题,我之前参加过一些机器学习的学术会议,发现推荐系统问题实际上受到关注较少,或者说在学术界,它仅占了很小的份额,但是正如你所见,对于许多科技公司来说,构建这些系统的能力,似乎是它们的首要任务。这是我为什么在这节课讨论它的原因之一。
我想讨论推荐系统的第二个原因是:在最后几集视频时,我想谈谈机器学习中的一些大思想,并和大家分享机器学习中一些伟大的想法。我们已经在这门课中见识到,特征对于机器学习来说是非常重要的,你所选择的特征,对于学习算法的性能有很大的影响。机器学习领域有一个伟大的想法,对于一些问题,可能并不是所有的问题,有一些算法可以自动地学习一些列特征,所以比起目前为止我们做的最多的手动设计或编写特征,there are a few settings where you might be able to have an algorithm just to learn what feature to use and the recommender systems is just one example of that sort of setting. 当然,还有很多其他的,但是通过推荐系统我们能够领略一小部分特征学习的思想,并且你将能够至少了解一个关于这个伟大思想的例子。
从一个例子开始定义推荐系统的问题

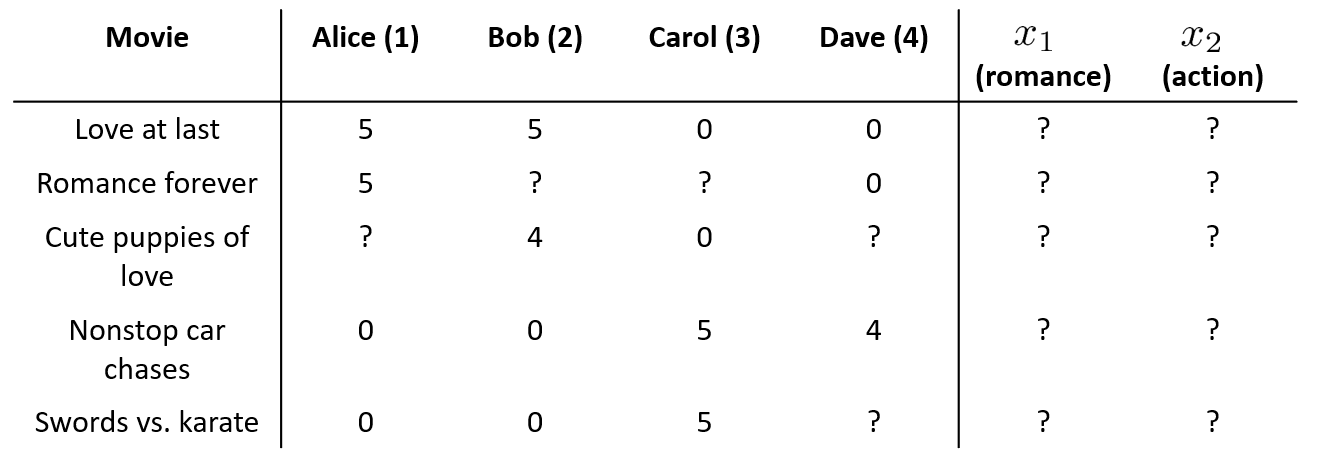
Say 我们是一个电影供应商,我们有 5 部电影和 4 个用户,我们要求用户为电影打分。如上图所示,有的用户为某电影打了 5 分,有的用户为某电影打了 0 分,还有的用户对某些电影未评分(图中 ?表示未评分)。前三部电影是爱情片,后两部则是动作片,我们可以看出 Alice 和 Bob 似乎更倾向与爱情片, 而 Carol 和 Dave 似乎更倾向与动作片。并且没有一个用户给所有的电影都打过分,因为图中存在 ?,表示该用户没有对该电影评分,此处假设该用户没有看过该电影。现在我们想找一个算法,来帮我们填补上 ?的部分,也就是预估用户对某些电影的评分,并以此作为推荐给该用户电影的依据(她没看过这个电影,算法预估打分,如分数很高,就可以推荐这部电影给该用户)。
基于内容的推荐系统(Content Based Recommendations)
下面介绍第一种推荐系统的算法,即:基于内容的推荐系统。在这种算法中,我们会假定对于每部电影我们都已经提取了一些特征,然后对每个用户建立一个线性回归模型,由于我们假定已经获取了电影的相关特征,就可以用梯度下降求解出每个用户的参数 \(\theta\),继而当输入一个新电影特征的时候,我们就可以用这个线性回归模型来预测该用户可能对该电影给出的评分。后面还会介绍另一种推荐系统的算法,叫协同过滤,它的主要思想是,假定电影的特征也不存在,当然用户参数 \(\theta\) 也不存在,而协同过滤算法会同时自动学习这两者。具体后面再看,先来看下基于内容的推荐系统是如何工作的。

上图中,预先给出了电影的两个特征,\(x_1\) 代表电影的浪漫程度,\(x_2\) 代表电影的动作程度。
对于基于内容的推荐系统,需要针对每个用户 \(j\) 建立线性回归模型,由于有多个用户,所以需要建立多个线性回归模型,接下来我们在原有线性回归模型的基础上进行稍微的修改以及优化,使它与推荐系统更加的契合,下面让我们一步一步来进行。
首先定义一些需要用到的符号:
- \(n_u\) = no. users
- \(n_m\) = no. movies
- \(r(i, j)\) = 1 if user j has reted movie i
- \(y^{(i, j)}\) = rating given by user \(j\) to movie \(i\) (defined only if \(r(i, j) = 1\))
- \(x^{(i)}\) = feature vector for movie \(i\)
- \(\theta^{(j)} \in \mathbb{R}^{n+1}\) = parameter vector for user \(j\)
- For user \(j\), movie \(i\), predicted rating: \((\theta^{(i)})^T(x^{(i)})\)
- $m^{(j)} = $ no. of movies rated by user \(j\)
To learn \(\theta^{(j)}\) :
\(\underset{\theta (j)}{\mathrm{min}} \quad \frac{1}{2m^{(j)}}\sum\limits_{i:r(i,j)=1}^{}\Big((\theta^{(j)})^Tx^{(i)} - y^{(i,j)}\Big)^2+\frac{\lambda}{2m^{(j)}} \sum\limits_{k=1}^{n} \left(\theta_{k}^{(j)}\right)^2\)
To learn \(\theta^{(j)}\) (parameter for user j),优化去除 \(m^{(j)}\),它是一个实数去除不会影响结果 :
\(\underset{\theta (j)}{\mathrm{min}} \quad \frac{1}{2}\sum\limits_{i:r(i,j)=1}^{}\Big((\theta^{(j)})^Tx^{(i)} - y^{(i,j)}\Big)^2+\frac{\lambda}{2} \sum\limits_{k=1}^{n} \left(\theta_{k}^{(j)}\right)^2\)
To learn \(\theta^{(1)},\theta^{(2)},...,\theta^{(n_u)}\) 上面的代价函数只是针对一个用户的,为了学习所有用户,需将所有用户的代价函数求和,\(i:r(i,j)\) 表示我们只计算那些用户 \(j\) 评过分的电影 :
\(\underset{\theta^{(1)},\theta^{(2)},...,\theta^{(n_u)}}{\mathrm{min}} \quad \frac{1}{2}\sum\limits_{j=1}^{n_u} \quad \sum\limits_{i:r(i,j)=1}\Big((\theta^{(j)})^Tx^{(i)}-y^{(i,j)}\Big)^2+\frac{\lambda}{2}\sum\limits_{j=1}^{n_u}\sum\limits_{k=1}^{n}(\theta_k^{(j)})^2\)
Gradient descent update:
\(\theta_k^{(j)}:=\theta_k^{(j)}-\alpha\sum\limits_{i:r(i,j)=1}\Big((\theta^{(j)})^Tx^{(i)}-y^{(i,j)}\Big)x_{k}^{(i)}\) (for k = 0)
\(\theta_k^{(j)}:=\theta_k^{(j)}-\alpha\left(\sum\limits_{i:r(i,j)=1}\Big((\theta^{(j)})^Tx^{(i)}-y^{(i,j)}\Big)x_{k}^{(i)}+\lambda\theta_k^{(j)}\right)\) for \((k \neq 0)\)
协同过滤算法(Collaborative Filtering Algorithm)
如上图,对于协同过滤算法,和基于内容的推荐算法不同的地方是,电影特征已经变成了 ?,也就意味着,预先既没有给定电影特征,也未给定用户的参数 \(\theta\)。而协同过滤算法可以同时求解它们。现在假定同时初始化了 \(\theta\) 和 \(x\),通过已知的 \(\theta\) 可以梯度下降优化 \(x\),通过被优化后变成已知的 \(x\) 亦可反过来再次梯度下降优化参数 \(\theta\),以此类推,直到满足递归次数,或达到最优。事实证明,这种算法运行的很好,能够计算出合理的 \(\theta\) 和 \(x\) ,以满足 \(\theta^Tx\) 约等于用户的评分,不过这种方式求解出来的电影特征 \(x\) 无法让人直观的理解或读懂其含义,但好处是它可以预估出某些用户对于某些电影的评分,填补用户评分数据中的 ?,并以此作为给某用户推荐电影的依据。同时,协同过滤算法也间接的反应了机器学习领域中的一种伟大思想,就是让算法自己来学习特征。
以上是对协同过滤算法直观的阐述,下面通过公式来进一步讲解协同过滤算法:
Collaborative filtering optimization objective:
-
Given \(x^{(1)},...,x^{(n_m)}\), estimate \(\theta^{(1)},...,\theta^{(n_u)}\) :
\(\mathop{\mathrm{min}}\limits_{\theta^{(1)},...,\theta^{(n_u)}}\quad\frac{1}{2}\sum\limits_{j=1}^{n_u}\sum\limits_{i:{r(i,j)=1}}\Big((\theta^{(j)})^Tx^{(i)}-y^{(i,j)}\Big)^2+\frac{\lambda}{2}\sum\limits_{j=1}^{n_u}\sum\limits_{k=1}^{n}(x_k^{(j)})^2\) -
Given \(\theta^{(1)},...,\theta^{(n_u)}\), estimate \(x^{(1)},...,x^{(n_m)}\) :
\(\mathop{\mathrm{min}}\limits_{x^{(1)},...,x^{(n_m)}}\quad\frac{1}{2}\sum\limits_{i=1}^{n_m}\sum\limits_{j:{r(i,j)=1}}\Big((\theta^{(j)})^Tx^{(i)}-y^{(i,j)}\Big)^2+\frac{\lambda}{2}\sum\limits_{i=1}^{n_m}\sum\limits_{k=1}^{n}(x_k^{(i)})^2\) -
Minimizing \(x^{(1)},...,x^{(n_m)}\) and \(\theta^{(1)},...,\theta^{(n_u)}\) simultaneously :
\(J(x^{(1)},...,x^{(n_m)},\theta^{(1)},...,\theta^{(n_u)})=\frac{1}{2}\sum\limits_{(i,j):r(i,j)=1}\Big((\theta^{(j)})^Tx^{(i)}-y^{(i,j)}\Big)^2+\frac{\lambda}{2}\sum\limits_{i=1}^{n_m}\sum\limits_{k=1}^{n}(x_k^{(i)})^2+\frac{\lambda}{2}\sum\limits_{j=1}^{n_u}\sum\limits_{k=1}^{n}(\theta_k^{(j)})^2\)
\(\underset{\theta^{(1)},...,\theta^{(n_u)}}{\underset{x^{(1)},...,x^{(n_m)}}{\mathrm{min}}}J(x^{(1)},...,x^{(n_m)},\theta^{(1)},...,\theta^{(n_u)})\)
注:上面公式中的\(\sum\limits_{j=1}^{n_u}\sum\limits_{i:{r(i,j)=1}}\) 等同于 \(\sum\limits_{i=1}^{n_m}\sum\limits_{j:{r(i,j)=1}}\) 同时也等同于 \(\sum\limits_{(i,j):r(i,j)=1}\),前面两个突出不同的计算角度,最后一种体现出了综合,但它们三个的最终的计算结果,和实际意义完全相同。
Collaborative filtering algorithm:
- Initialize \(x^{(1)},...,x^{(n_m)},\theta^{(1)},...,\theta^{(n_u)}\) to small random values.
- Minimize \(J(x^{(1)},...,x^{(n_m)},\theta^{(1)},...,\theta^{(n_u)})\) using gradient descent(or an advanced optimization algorithm).E.g. for every \(j=1,...,n_u,i=1,...,n_m\) :
\(x_k^{(i)}:=x_k^{(i)}-\alpha\left(\sum\limits_{j:r(i,j)=1}\Big((\theta^{(j)})^Tx^{(i)}-y^{(i,j)}\Big)\theta_k^{(j)}+\lambda x_k^{(i)}\right)\)
\(\theta_k^{(j)}:=\theta_k^{(j)}-\alpha\left(\sum\limits_{i:r(i,j)=1}\Big((\theta^{(j)})^Tx^{(i)}-y^{(i,j)}\Big)x_k^{(i)}+\lambda \theta_k^{(j)}\right)\) - For a user with parameters \(\theta\) and a movie with (learned) features \(x\), predict a star rating of \(\theta^Tx\) .
注:在协同过滤算法中,我们不引入截距项,或偏执单元(貌似是神经网络中的叫法),即 \(x_0 \equiv 1\)。因为算法会自动学习特征,所以没必要强制把某个特征恒赋值为1。所以,在梯度下降的公式中,没有体现中之前的 \(k=0\)(不对截距项正则化)的情况,因为不含有截距项。
向量化:低秩矩阵分解(Vectorization: Low Rank Matrix Factorization)

上图是显示的是用户对电影的评分信息,可以放到下面的矩阵中:
\(Y = \begin{bmatrix}5&5&0&0\\[0.3em] 5&?&?&0\\[0.3em] ?&4&0&?\\[0.3em] 0&0&5&4\\[0.3em] 0&0&5&0\\[0.3em] \end{bmatrix}\)
在运行协同过滤算法后,得到电影特征矩阵 \(X\) 和 用户参数矩阵 \(\Theta\)。
Predicted ratings = \(X\Theta^T\) = \(\begin{bmatrix}\big(\theta^{(1)}\big)^T\big(x^{(1)}\big)&\big(\theta^{(2)}\big)^T\big(x^{(1)}\big)&\cdots&\big(\theta^{(n_u)}\big)^T\big(x^{(1)}\big)\\[0.3em]\big(\theta^{(1)}\big)^T\big(x^{(2)}\big)&\big(\theta^{(2)}\big)^T\big(x^{(2)}\big)&\cdots&\big(\theta^{(n_u)}\big)^T\big(x^{(2)}\big)\\[0.3em] \vdots&\vdots&\vdots&\vdots\\[0.3em] \big(\theta^{(1)}\big)^T\big(x^{(n_m)}\big)&\big(\theta^{(2)}\big)^T\big(x^{(n_m)}\big)&\cdots&\big(\theta^{(n_u)}\big)^T\big(x^{(n_m)}\big)\\[0.3em] \end{bmatrix}\)
经过上面计算后,可得用户评分矩阵 Predicted ratings,它与矩阵 \(Y\) 中的元素是一一对应的,\(Y\) 中 为 ?的元素,已经在 Predicted ratings 中被预测出来了。
Predicted ratings 在线性代数中具有低秩的性质,顾协同过滤算法也被称作 低秩矩阵分解。
Finding related movies:
For each product \(i\), we learn a feature vector \(x^{(i)} \in \mathbb{R}^n\).
How to find movies \(j\) related to movie \(i\) ?
small \(||x^{(i)} - x^{(j)}||\) --> movie \(j\) and \(i\) are "similar"
5 most similar movies to movie \(i\):
Find the 5 movies \(j\) with the smallest \(||x^{(i)} - x^{(j)}||\)
Say 用户看了一个电影 \(x^{(i)}\), 现在找出该用户所有没看过的电影,并用这些电影的特征分别计算和 \(x^{(i)}\) 的距离,将结果升序排列后取前 5 个,那么这结果就是你可以推荐给该用户的和电影 \(x^{(i)}\) 最相似的 5 部电影了。
实现时的细节:均值归一化(Implementational Detail: Mean Normalization)
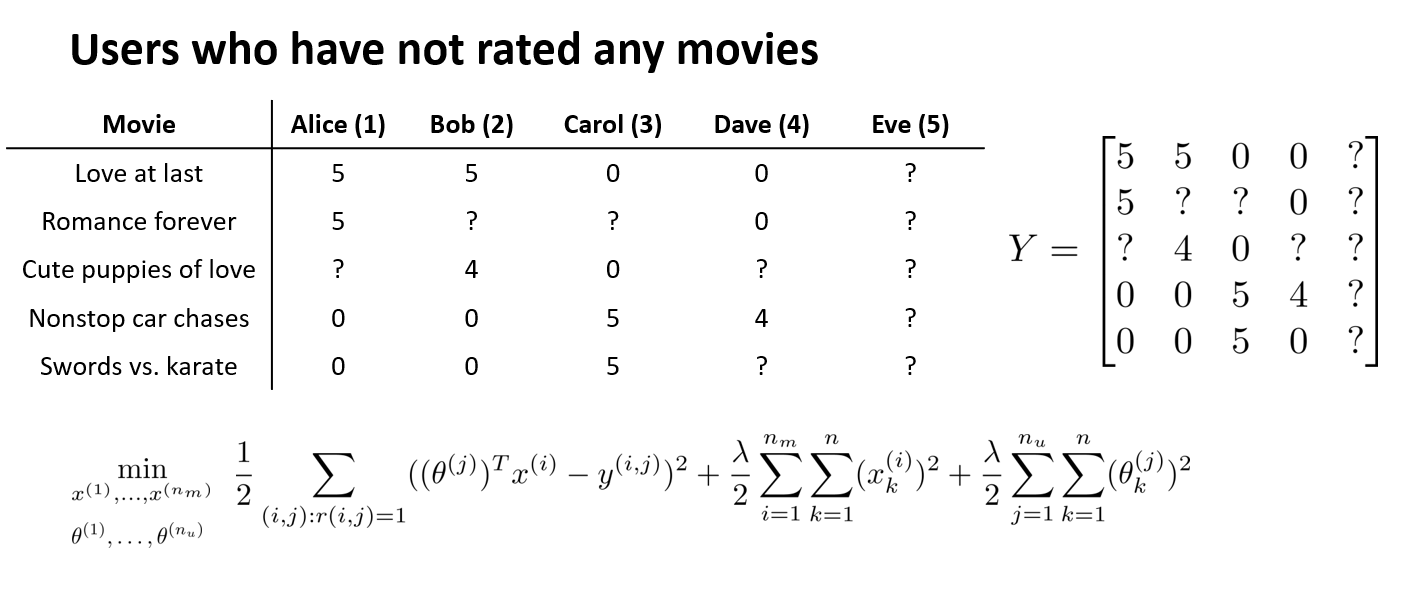
现在新加入一个用户 Eve, 她未对任何电影评分。如果此时进行协同过滤,见上图公式,因为她未对任何电影评分,所以当上述公式计算到用户 \(j\),即 Eve 的时候,公式中但凡涉及 \(x\) 的项全部为 \(0\),有意义的只有最后一项 \(\frac{\lambda}{2}\sum\limits_{j=1}^{n_u}\sum\limits_{k=1}^{n}(\theta_k^{(j)})^2\),但是为了防止过拟合,当 \(\lambda\) 很大的时候,\(\theta\) 也是趋近于 \(0\) 的,这就意味着与用户 Eve 相关的所有参数均为 \(0\),对最小化式子毫无影响力,而且最后评估的分数也全都是 \(0\) ,这不是我们想要的。所以,均值归一化,能解决这个问题。
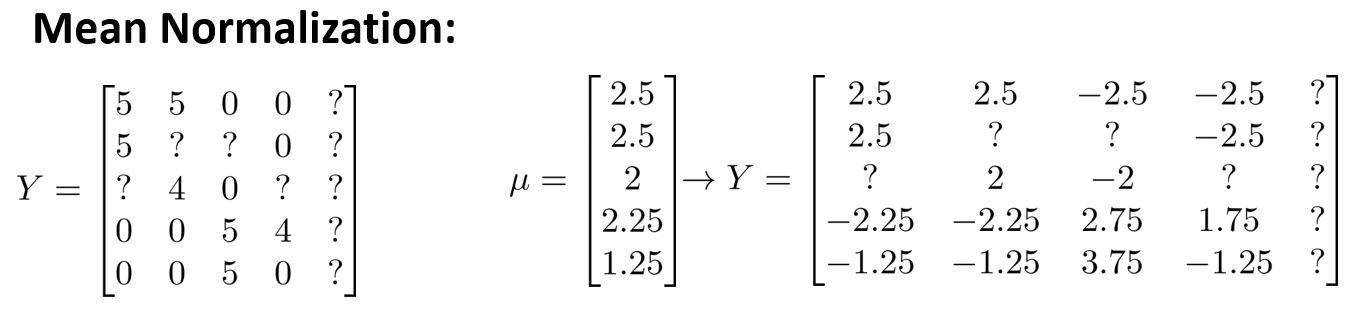
上图中,对每行求均值,然后让每个元素减去对应所在行的均值,?项不不变,结果会得到一个关于 \(Y\) 的新矩阵。
Then,用新的 \(Y\) 进行协同过滤算法。After that, for user \(j\), on movie \(i\) predict is \((\theta^{(j)})^T(x^{(i)}) + \mu_i\)
So, finally, for user 5 (Eve)'s rating is \(\theta^Tx + \mu\) = \(0 + \mu\) = \(\mu\)
事实证明,这么做是有意义的。
同样道理,当有一个新电影加入的时候,此时没有任何用户为它评分,你可以尝试应用同样的做法,不同的是这次是按列来计算平均值,让每个元素减去该平均值,然后再运行协同过滤。
但是,实际上,这种方法对于新添加的用户来讲更有意义。因为用户是上帝,而我们的目的是:要给上帝推荐电影。
程序代码
直接查看Recommender Systems - Collaborative Filtering Algorithm.ipynb可点击
获取源码以其他文件,可点击右上角 Fork me on GitHub 自行 Clone。
