
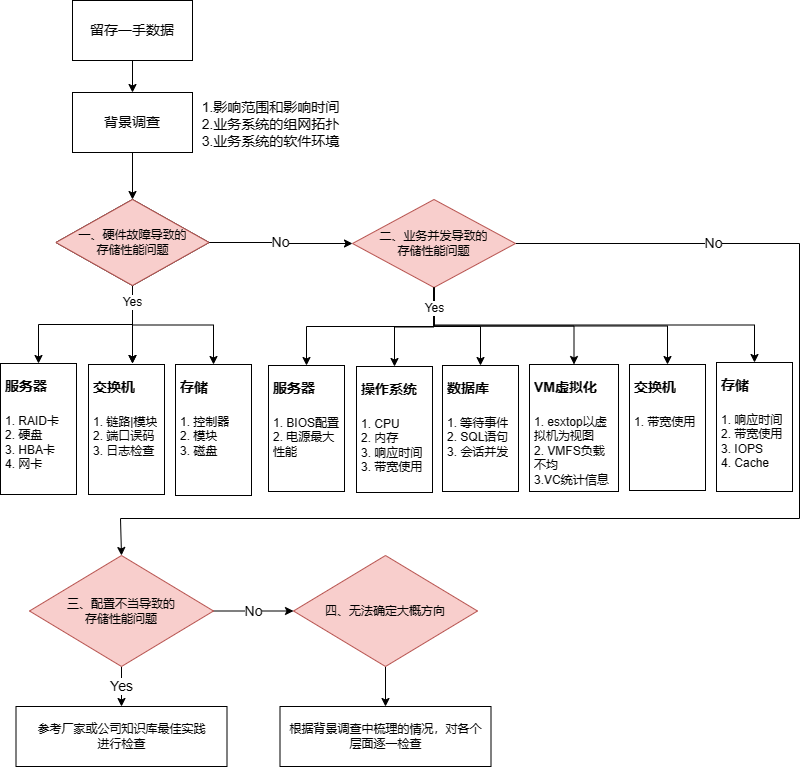
存储性能问题排查和诊断步骤
1 整体思路概述
对存储性能进行排查,要求理解IOPS、吞吐量、响应时间这些性能指标,业务系统正常运行情况下的性能指标有基本的了解。除此之外排查存储性能问题,不单是要熟悉存储设备本身,还涉及交换机、服务器、操作系统、应用软件多个层面,是一个全流程的工作。性能问题可能出现在整个I/O路径的各个环节。可能是应用本身的问题,或是所在的端口带宽不足出现拥塞,或者后端存储系统的问题。出现性能问题,是由系统中出现短板的环节决定的。因此对于性能相关的问题,应该从多个方面逐一排查,找出整个系统的性能瓶颈所在并针对性地解决。
本篇文档也是对多个方面如何排查性能问题进行了介绍,在遇到存储性能问题时,可参考一下思路,根据实际情况可以进行适当的裁剪。
2 留存一手数据
在发现或者遇到存储性能问题时,首先要做的事情是留存一手数据,可以使用截图、录屏和生成support日志来记录系统的运行状态。一手数据除了对后面深入排查具有方向性的指导作用外,还能够提供给他人共同进行排查和讨论。
1. ****服务器
a) 硬件:ILO/BMC进行截图或者导出日志。
b) Windows:导出事件查看器中的“系统”和“应用程序”两种类型日志;若未配置性能计数器,需要手动配置。
c) Linux:执行sosreport命令自动打包配置文件和日志,或者手动收集message日志;也可以保存sar生成的数据。
d) AIX:安装sosreport工具,或执行errpt -a输出日志。
2. ****数据库
a) Oracle:alert日志;在出现问题时生成awr快照,收集awr报告。
b) SQL Server:error日志;若未提前配置数据收集器,需使用Profile或者扩展事件监控运行状态。
3. ****SAN交换机
a) supportsave命令,生成支持包,一般用于厂家工程师分析。
b) errdump -r名称,输出日志,可直接查看分析。
4. ****存储
a) EMC
l Unity系列:登录Unisphere GUI,System->Service-> Service Tasks-> Collect Service Information->在日志窗口点击“+”号即可收集日志,随后手动下载到本地。
l PowerStore系列:登录PowerStore GUI,Settings-> Gather Support Materials->保持默认配置,点击“START”后收集日志,随后手动下载到本地。
b) 华为
l OceanStor V3系列:登录DeviceManager GUI,选择“导出数据”,根据所需收集日志,随后手动下载到本地。
l Dorado系列:登录DeviceManager GUI,选择“设置”图标->导出数据,根据所需收集日志,随后手动下载到本地。
c) 华三
l 3par系列:需要使用VSP收集日志,在主菜单找到“Support”,点击Insplore会自动收集日志,然后再主菜单的“File”中下载到本地。
如果没有安装VSP,则可以手动导出系统日志和性能图标。
3 调查背景
3.1 影响范围和发生时间
发生性能问题后,需要确定两个问题:
1. 确定问题的影响范围是单个业务系统还是多个或者所有业务系统。
a) 记录受影响的业务系统,将这些信息代入在组网拓扑中进一步分析。
2. 确定问题的发生时间是在业务高峰期还是非高峰期,是有规律可循,还是随机出现的。
a) 如果是有规律可循,可在对应的业务系统上提前做好监控工作。
b) 如果是随机出现,并且前期没有日志数据可分析,可以部署监控工具收集数据以进一步分析。
3.2 业务系统的组网拓扑
将发生问题的业务系统代入组网拓扑中进一步分析:
1. 架构:分布式/集中式
2. 协议:NAS/SAN/Object
3. ****链路:冗余程度和速率大小
4. 硬件:
a) 组网拓扑中涉及的设备型号
b) ****存储的硬盘类型
c) ****存储的RAID级别
d) 控制器数量和缓存大小
3.3 业务系统的软件环境
在上述两个方面进行了调查后,我们还需要再进一步确定该业务系统的软件环境,包括其操作系统类型、版本,应用软件的类型、架构和版本。
1. 该业务系统是物理机、虚拟机还是使用了Docker之类的容器技术。
2. 其底层操作系统是Windows、Linux、AIX,虚拟化的话是ESXi、FusionCompute还是CAS。
3. 安装的应用软件是数据库还是中间件,架构是主备高可用还是主主高可用,还是单机,其应用软件的版本。
4 主机端检查
在确认链路正常的情况下,常用的思路是对主机和存储两端的延迟进行对比,再去对存储性能问题进行深入分析。
1. 主机端 & 存储端延迟都很大,且主机端延迟 ≈ 存储端延迟。那瓶颈可能出现在存储端:例如磁盘性能达到上限,或带宽达到上限。
2. 主机端延迟 > 存储端延迟。可能是主机端配置不当:例如块设备并发,HBA卡并发不够等导致I/O堆积,主机CPU利用率高,带宽达到瓶颈,多路径路径选择错误。
光是对比延迟,只是有了一个大概的方向。要找到造成性能问题的根本原因,还要根据不同的硬件环境和软件环境,使用对应的工具进行深入分析。
4.1 服务器硬件
如果业务系统所使用的是物理机,在可登录ILO(HPE)或者BMC(Huawei)的情况下,可以登录服务器的带外管理页面,检查服务器的健康情况:
1. 硬件状态:RAID卡是否正常,Cache是否失效;是否有磁盘故障;是否有HBA卡或者网卡故障……
2. 硬件日志:服务器的硬件事件,有时里面还会包括了内存的ECC纠错信息。
3. 电源管理:电源是处于节能模式还是高性能模式。
在无法登录带外的情况下,此项可以先忽略。
也可以通过操作系统的ipmitool工具检查服务器的硬件状态。
4.2 Windows常用工具
Windows中与I/O相关的工具有资源监视器、性能监视器以及自带的为MPIO多路径软件。
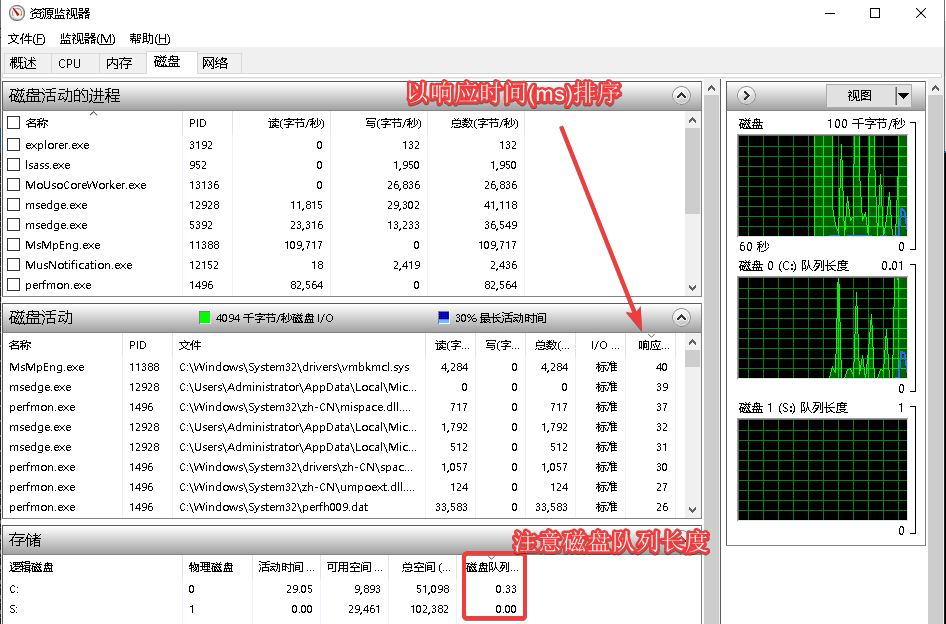
1. 资源监视器(perfmon.exe /res),在“磁盘”功能页中,可以实时监控所有消耗I/O资源的活动进程。在“磁盘活动”中,以“响应时间(ms)”排序,可以将响应时间最高的进程放在第一位。
[ ]
]
2. 性能监视器(perfmon.exe),性能监视器类似Linux上的NMON或者SAR,但分析需要导出成csv分析或者使用专用工具分析。需要关注的计数器有:
1. Avg. Disk sec/Transfer:处理的每个I/O的平均时间,单位毫秒。
2. Avg. Disk sec/Read:处理的每个读I/O的平均时间,单位毫秒。
3. Avg. Disk sec/Write:处理的每个写I/O的平均时间,单位毫秒。
可以使用自带relog命令或者到github下载[PAL](https://github.com/clinthuffman/PAL)工具分析性能监视器生成的blg文件。
3. 自带多路径MPIO,在不使用存储厂家多路径的情况下,默认多路径为MPIO。MPIO无法检查磁盘各个路径的读写性能信息,只能检查各个路径状态。
1. mpclaim -s -d,输出所有磁盘的多路径概况
[ ]
]
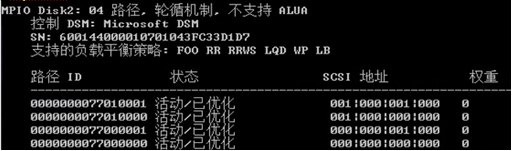
2. mpclaim -s -d [disknumber],检查指定磁盘的多路径详细信息。
n RR :轮循机制,所有的I/O请求会分布在每条路径实现负载均衡。
n 状态:在状态中确定没有Unavailable或者不可用的关键字。
n 权重:MPIO会根据权重选择相应的路径进行Failover动作。
[ ]
]
4.3 Linux常用工具
Linux中与I/O相关的工具有iostat、sar以及自带的multpath多路径软件。
1. iostat,是专用于I/O监控的工具,在sysstat软件包中(最小化安装不具备该工具)。
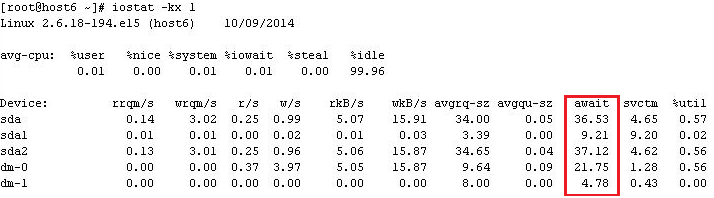
Ø iostat -kx n m
其中-k是以KB/MB显示速率,-x显示更多统计信息,n是刷新间隔,m是显示次数。
[ ]
]
n await:表示每个I/O请求处理的平均时间(单位为毫秒),即I/O的响应时间。
n svctm:表示每个I/O的平均服务时间(单位为毫秒)。新版本中会移除该指标。(但也要关注)
n avgqu-sz:新版本iostat中显示为aqu-sz,指的是该设备的I/O请求的平均队列长度,长时间10以上,说明可能由于并发限制,导致I/O堆积在主机的块设备层,并没有将主机压力传到存储端,此时可以考虑检查HBA的并发数。
2. sar,是综合性监测工具,用途比iostat更广泛,也包含在sysstat软件包中(最小化安装不具备该工具)。除了查看实时性能状态之外,还可以回溯历史性能数据,默认情况下使用sysstat服务自动收集数据,其历史性能数据保留在/var/log/sa目录下。
Ø sar -d -p n m
其中-d指监控磁盘状态,-p显示设备名,n是刷新间隔,m是显示次数。
[ ]
]
n sar显示的统计信息与iostat没有太大差异,两者可以相互借鉴。
n 如果想要获取sar与I/O相关的历史性能数据,可以切换到/var/log/sa目录下,ls查看指定日志的sa文件名,然后sar -f [sa文件名] -d |less看看历史的IO等待情况。其中-f为指定sa的历史性能数据。
3. multipath,Linux中自带的多路径软件,一般可以通过检查多路径状态,常见输出的状态如下。
Ø multipath -ll
[ ]
]
n mpathe :用户定义设备名
n 360050764008080d7780000000000001f : 唯一的WWID(LUN ID)
n dm-1 : 设备对应的sysfs文件名
n IBM,2145 : 存储厂商型号
n size=500g : DM设备大小
n features=‘1’ : DM 支持特性
n hwhandler=‘0’ : 硬件处理程序
n wp=rw : 读写权限
n policy=‘round-robin 0’:路径选择算法,在路径类别中的所有路径之间进行循环,相同的I / O数量传送至各个路径。
n prio=50或prio=10 : 计算路径组的优先级
n status=active : 路径的状态,active为接受I/O请求,enabled为备用,路径故障状态下显示为faulty。
n 1:0:0:3或2:0:0:3、2:0:1:3或1:0:1:3 : SCSI 信息: host, channel, scsi_id, and LUN
n sdg或sdj、sdt或sds : Linux设备名
n 8:96 : Major and minor numbers
n active ready running : DM 路径和物理路径状态
4.4 AIX常用工具
AIX下与I/O相关的常用工具有topas、iostat和自带的mpio多路径。
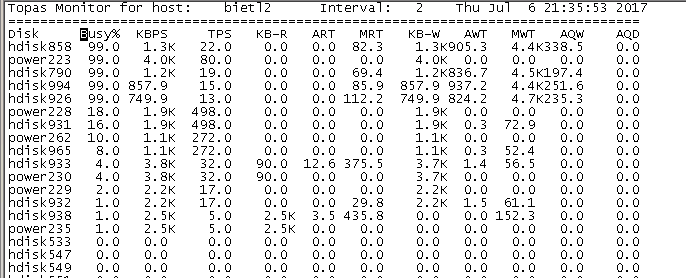
1. topas命令,比Linux下的top命令更加强大,执行topas后按D键可以进入磁盘监控页面,或者命令行执行执行topas -D直接进入该页面。
Ø topas -D
[ ]
]
n Busy%:表示磁盘的繁忙时间的活动占比(可以理解为磁盘的带宽利用率)。
n KBPS:磁盘的带宽大小,以KB为单位。
n AQW:表示每一个I/O请求处理的平均时间(单位为毫秒)。
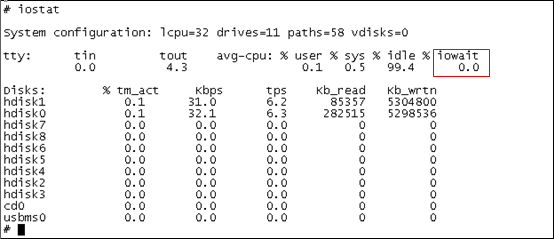
2. iostat命令,参考Linux下的iostat。
Ø iostat
[ ]
]
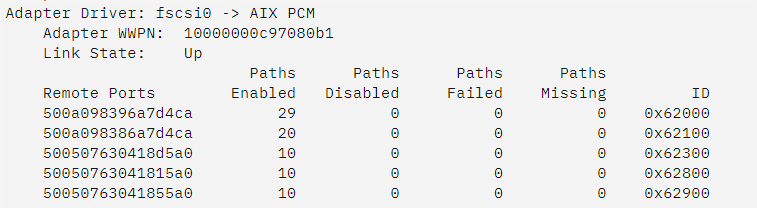
3. 自带的MPIO多路径软件, AIX中可以使用lsmpio查看多路径的运行状态,也是无法查询各个路径的读写性能信息。
1. lsmpio -ar
[ ]
]
n Link State:Up/Failed/ Degraded,Up则说明所有路径处于联机状态,Failed则说明所有路径不可用,Degraded说明部分路径不可用。
n Paths Failed:路径错误的次数。
n Paths Missing:路径丢失的次数。
4.5 虚拟化ESXi常用工具
虚拟化ESXi可以使用esxtop工具检查与I/O相关的性能问题。esxtop工具有d、u和v三个选项监控I/O相关的性能视图,d是HBA卡视角,u是LUN视角,v是虚拟机视角。esxtop在I/O性能视图中的主要列作用:
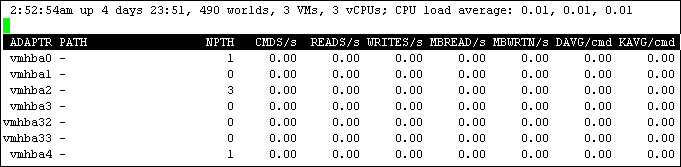
1. ****esxtop,按d,切换为hba卡的性能统计信息
[ ]
]
输入F,带星号表示已监控项,然后输入H、I选择监控HBA卡的延迟。
[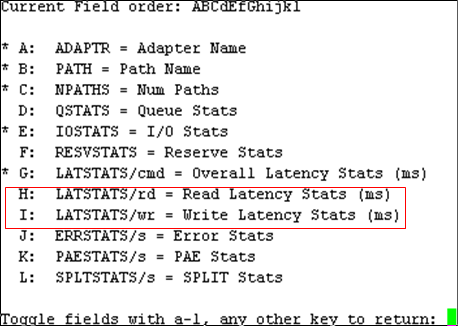 ]
]
2. ****esxtop,按u,切换为LUN的性能统计信息
[ ]
]
输入F,带星号表示已监控项,输入J、K查看LUN的延迟,按回车键返回。
[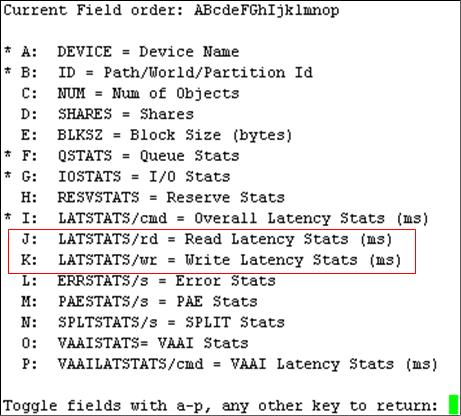 ]
]
3. ****esxtop,按v切换为虚拟机的I/O性能统计
[ ]
]
输入F,选择G、H监控虚拟机的时延。(如果虚拟机名称无法显示完整,可以按大写“L”键设置列宽度)
[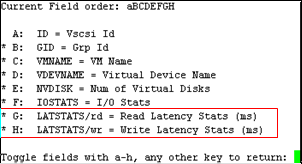 ]
]
n CMDS/s,这是指每秒命令总数,包括 IOPS(每秒输入/输出操作数)和其他 SCSI 命令,如 SCSI reservations、locks、vendor string requests、unit attention 等要发送到或发送自受监控设备或虚拟机的命令。在大多数情况下,除非有大量元数据操作(如 SCSI 预留),否则 CMDS/s = IOPS。
n DAVG/cmd,这是发送给设备的每个命令的平均响应时间(以毫秒为单位)。
n KAVG/cmd,这是命令在 VMkernel 中花费的时间。
n GAVG/cmd,是指客户机操作系统感知的响应时间。该值使用此公式计算: DAVG + KAVG = GAVG
对于性能要求高的业务系统, DAVG/cmd、KAVG/cmd 和 GAVG/cmd 不应超出 10 毫秒 (ms)。
4.6 虚拟化VCSA上监控
虚拟化上如果具备VCSA(vCenter)登录条件,可以在发生问题之前,更改vCenter的统计信息收集级别,默认级别是1,适合分析一些粗粒度的性能问题,比如整体的CPU、内存、磁盘和网络,但如果要针对性地对某个虚拟机磁盘的IOPS、响应时间和MBPS分析,则需要修改统计信息的收集级别:1. 默认的统计信息收集级别
[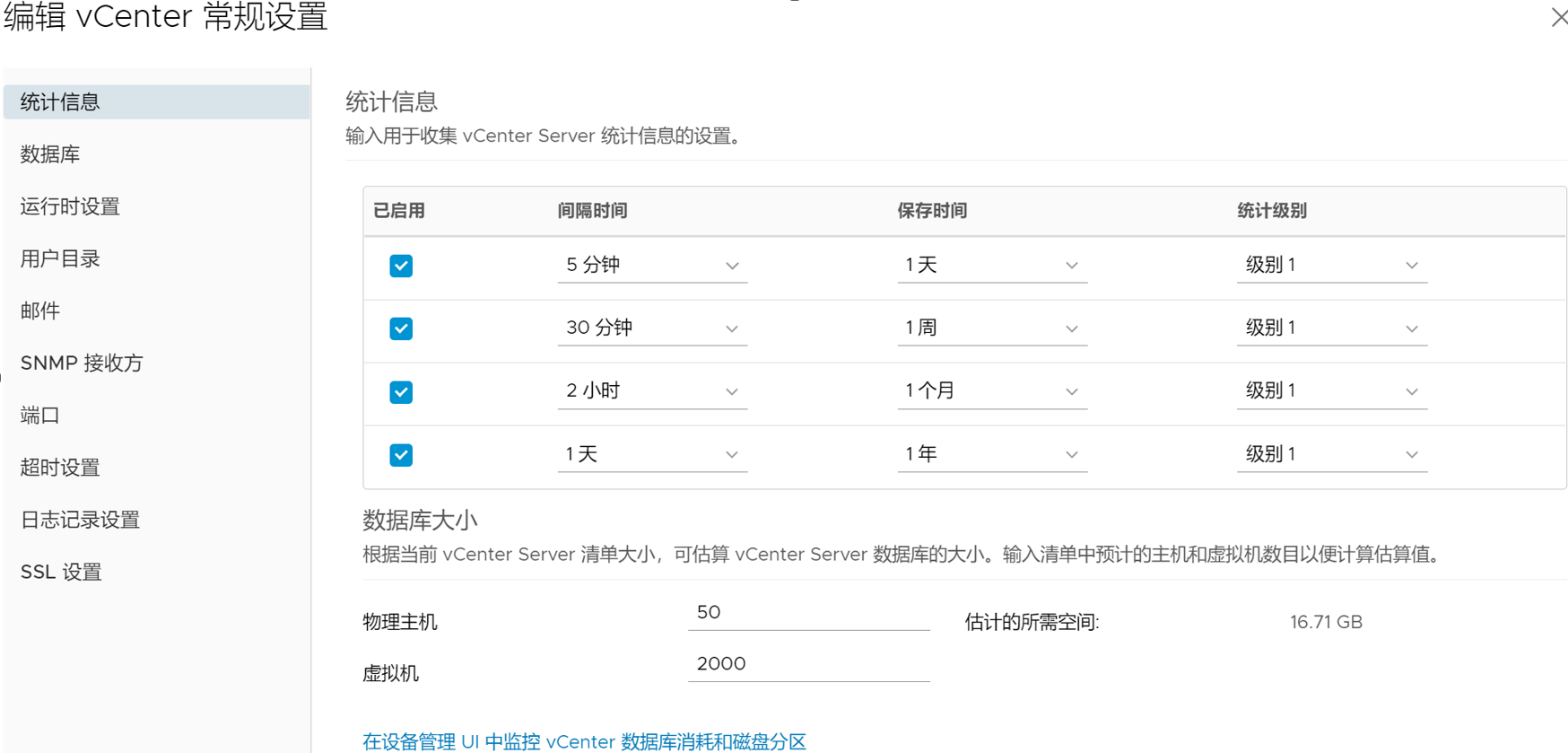 ]
]
2. 更改默认的统计信息收集级别
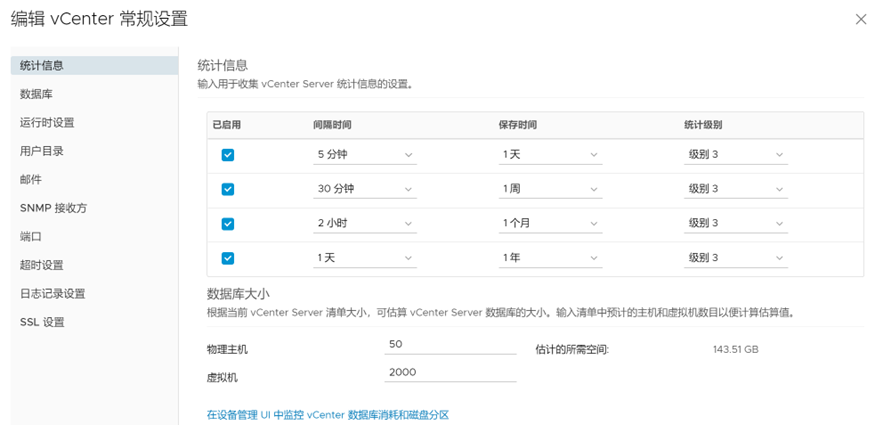
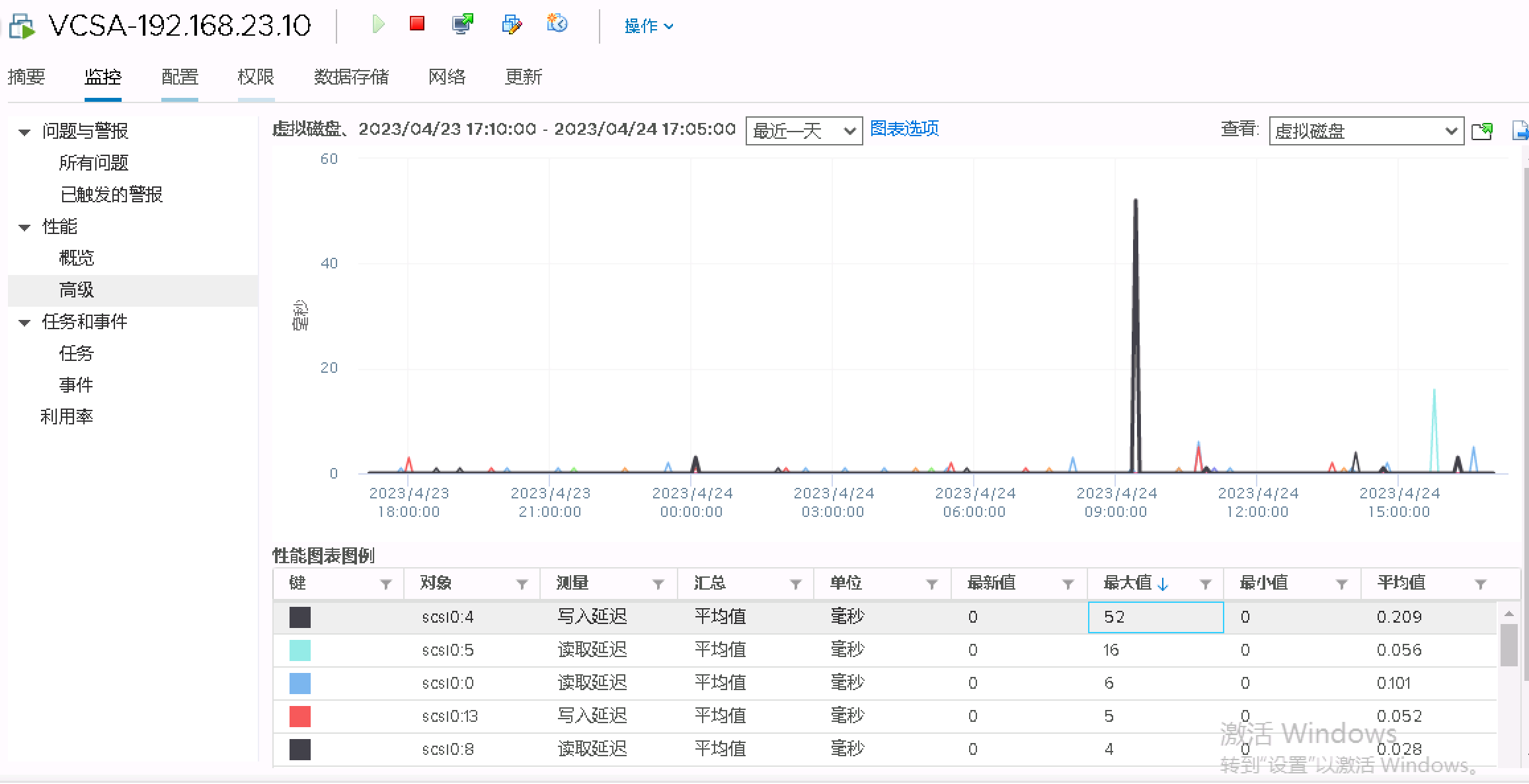
3. 查看虚拟机的磁盘响应时间
[ ]
]
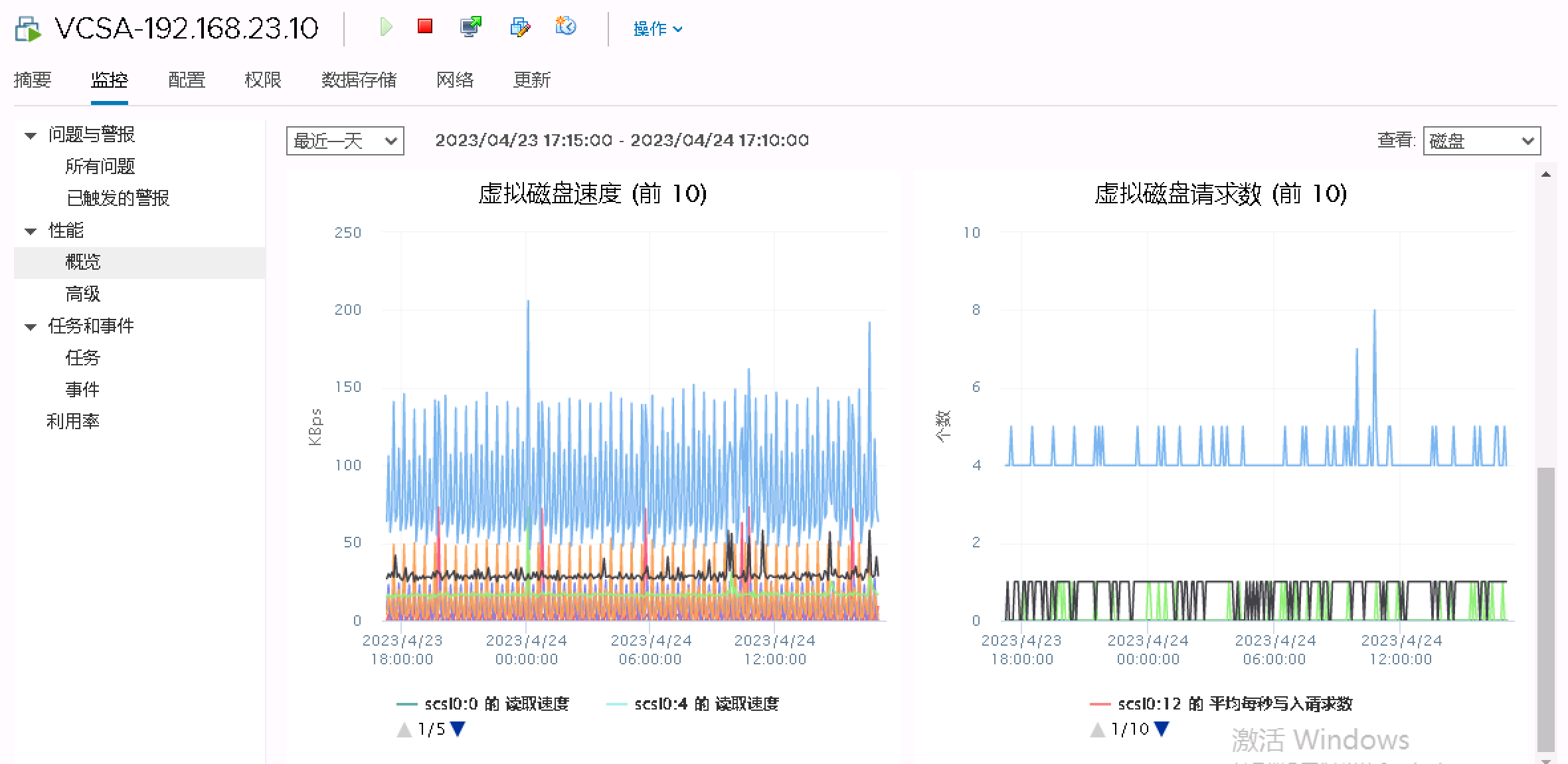
4. 查看虚拟机的磁盘IOPS和MBPS
[ ]
]
4.7 第三方厂商多路径
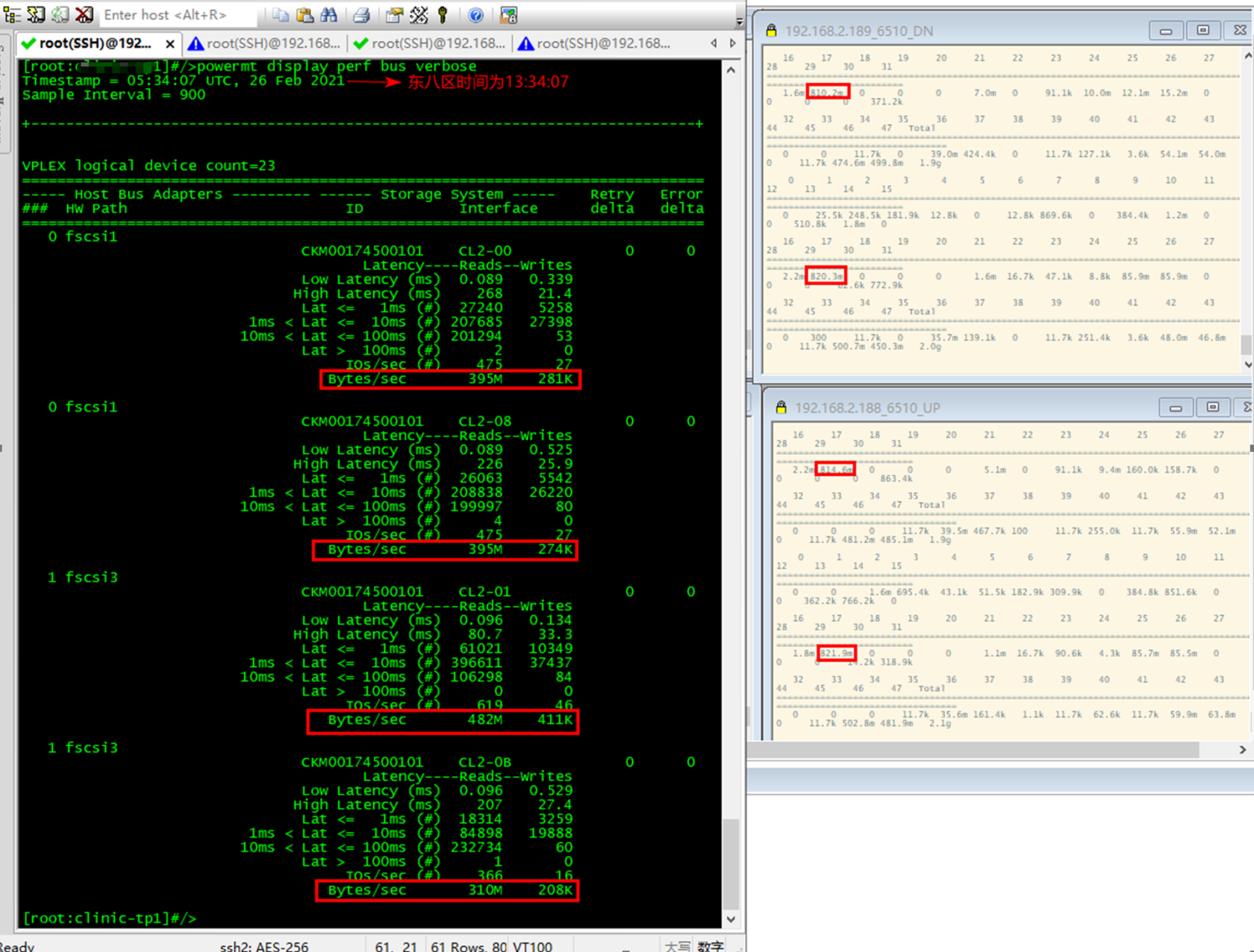
1. EMC PowerPath,可以通过powermt监控主机上所有lun或者hba卡的读写性能状态。
Ø powermt set perfmon=on,开启性能数据收集功能
Ø powermt display perf bus verbose,实时监控性能状态
[ ]
]
输出结果是一个二维表格,分别是延迟、读、写这三列:
n Latency – Low:统计时间段内I/O的最低延迟(毫秒)。
n Latency – High:统计时间段内I/O的最高延迟(毫秒)。
2. 华为 Ultrapath,可以在upadmin 中使用show iostat、show io_latency、show_io_count来监控。
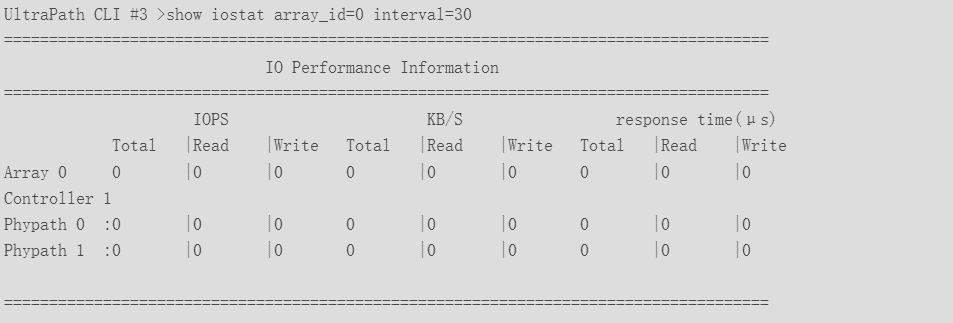
Ø show iostat array_id=0,1 interval=30 file_name=perfLogFile,监控存储0和存储1的性能状态,每30秒刷新一次,并记录到日志文件。也能以LUN为单位监控。
[ ]
]
n response time(us):响应时间,单位为微秒
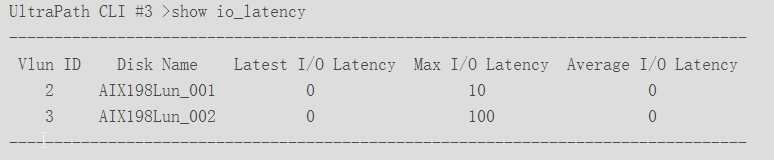
Ø show io_latency,获取所有虚拟LUN的I/O延迟信息。
[ ]
]
n 包含最新、最大和平均I/O延迟,单位为毫秒。
Ø show io_count,查看所有虚拟LUN或指定虚拟LUN逻辑路径的I/O计数信息,包括错误I/O计数、未返回I/O计数、错误命令计数和未返回命令计数。
[ ]
]
n Error I/O Count:错误的I/O数量。
n Queue I/O Count:排队(等待)的I/O数量。
n Error Command Count:错误的命令数量。
n Queue Command Count:排队(等待)的命令数量。
5 交换机端检查
交换机以FC SAN为主,在市面上基本都是各大厂商OEM博科的,底层操作系统为Brocade Fabric OS,排查命令通用。出现存储性能问题,在交换机上第一时间检查日志和端口的运行状态,常用的命令有:errdump、porterrshow、sfpshow和portperfshow。
1. errdump命令查看所有日志信息。
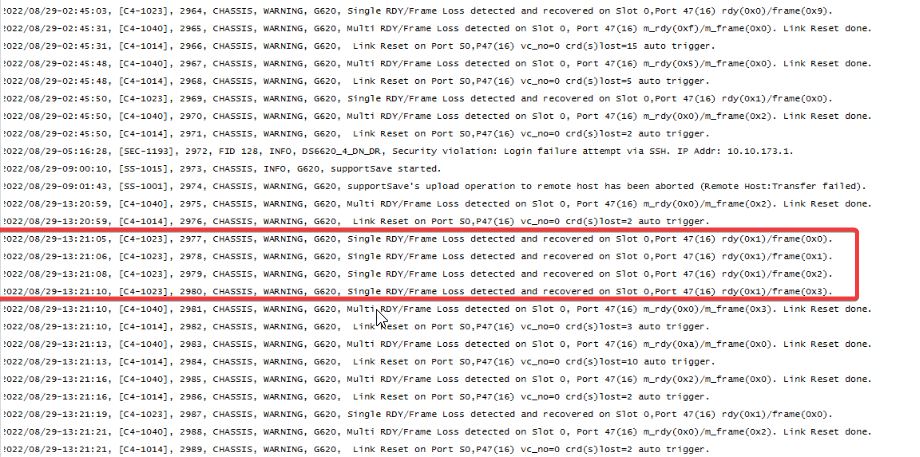
Ø errdump,查看所有日志,关于使用选项可以执行errdump --help查看命令帮助。
[ ]
]
一般可留意日志中的“Loss”和“Reset”两个关键字,意味着有端口出现问题。
2. sfpshow命令查看光模块的收发光情况。
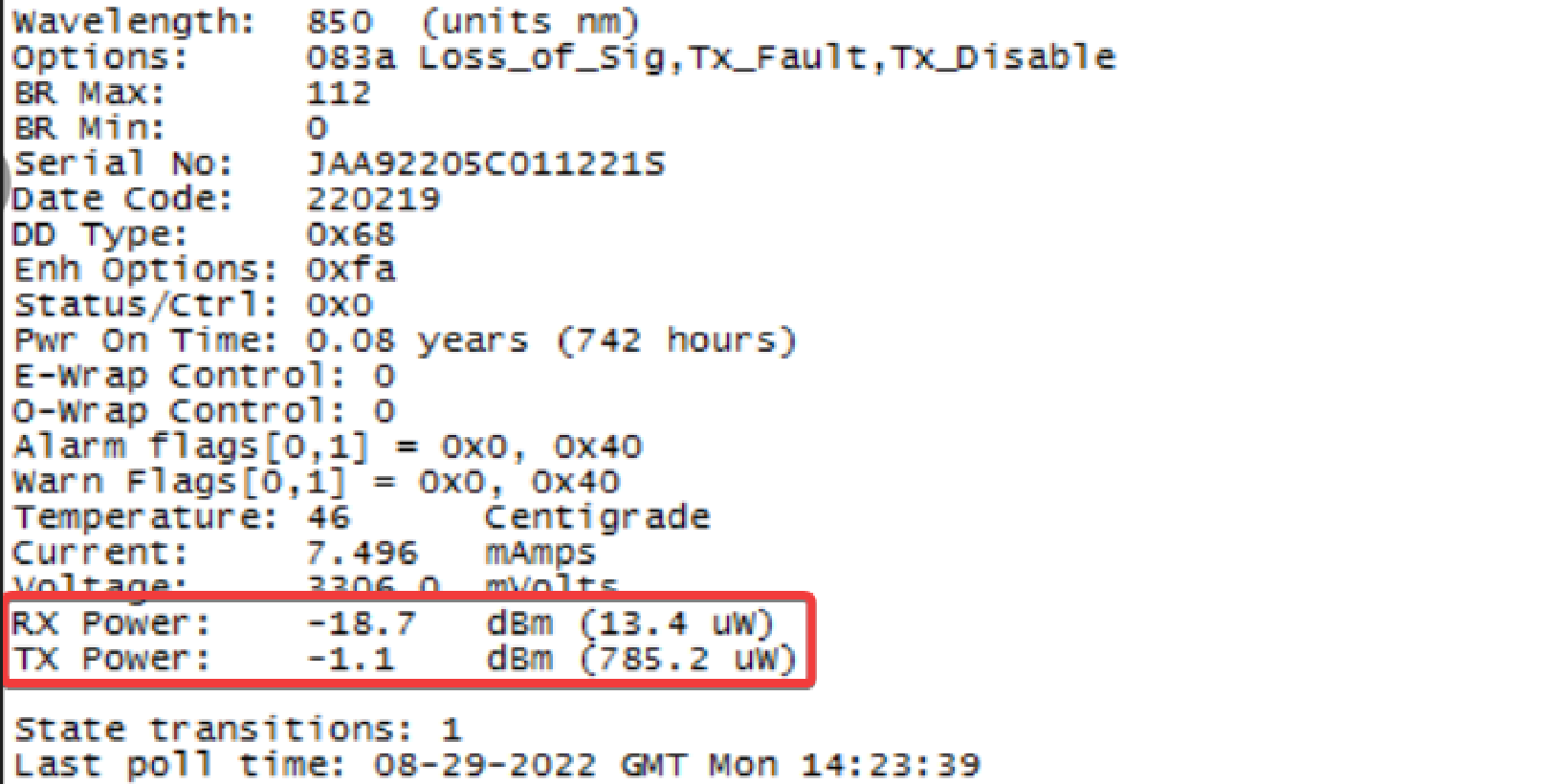
Ø sfpshow [端口号] -f,查看指定端口模块的实时收发光情况。
[ ]
]
n RX Power: 端口模块收光,信号值低于-12db (例如 -13db , -20db 等)表通常示 FC 交换机 SFP 外部存在故障。
n TX Power: 端口模块发光,TX 信号功率小于 -12dbm 表示 SFP 无法生成传输所需的光信号。
n 如果RX/TX长时间显示为-inf,意味着 SFP 发生故障,必须更换。
| **SFP 版本** | **正常值范围参考(仅供参考,一般速率越高,光功率越大)** |
| Brocade 短波 8/16/32 Gb SFP 接收功率范围 | -4.6 毫瓦( 340 瓦)~ 1.6 毫瓦( 1445 瓦) |
| Brocade 短波 8/16/32 Gb SFP 传输功率范围 | -4.6 毫瓦( 340 瓦)~ 2 毫瓦( 1584 瓦) |
| Brocade 长波8/16/32 Gb SFP接收功率范围 | 平均功率:2 dbm最大接收器敏感度小于-12dbm |
| Brocade长波8/16/32 Gb SFP传输功率范围 | 平均功率:-5.0 dbm~2.0 dbm |
3. porterrshow命令查看所有端口的统计信息日志,留意5|10分钟之后的误码增长情况。
Ø porterrshow,可以使用--help查看命令帮助。
[ ]
]
n Frame(tx/rx):tx代表端口发送的数据帧,rx代表端口收到的数据帧。
n crc err:数据帧CRC校验错误。根据实际统计,如果crc_err和 enc_out同时出现,通常代表SFP有硬件问题。
n enc out:8b/10b或者64b/66b数据帧帧外编码错误。单一的这个报错反映光纤线可能有问题;如果是Enc_out和crc_err同时报错,通常代表SFP有硬件问题。
n disc c3:被交换机丢弃的Class 3数据帧。这个参数仅仅代表有丢包发生,不能用来判定问题的具体原因。
n loss sync:位(bit)或者传输字符同步(transmission-word synchronization)失败都会产生这个错误。或者当交换机端口关闭和打开时(重新引导主机/存储、拔下 / 插入电缆或端口,禁用 /启用端口等)会新增计数。
n loss sig:zone中有一端发送了数据,但接收端没有成功收到信号时会产生这个错误。或者当交换机端口关闭和打开时(重新引导主机/存储、拔下 / 插入电缆或端口,禁用 /启用端口等)会新增计数。
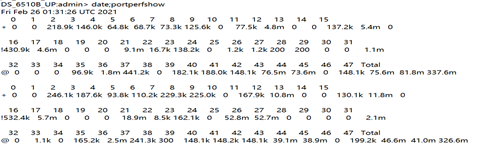
4. portperfshow命令查看所有端口的带宽使用大小。
Ø date;portperfshow -t 1,查看当前时间,并且每秒输出1次,默认对带宽大小进行换算成KB|MB|GB,No_Module、No_Light、No_SigDet、Loopback这4种状态的端口速率显示为0,可以使用--help查看命令帮助。
[ ]
]
[ ]
]
6 存储端检查
6.1 通用指标检查
检查存储端的性能不外乎以下几点:硬件状态、响应时间(延迟)、带宽使用率、IOPS 、Cache命中率。(增加双活场景的检查)在必要时刻还要收集日志分析。
1. 硬件状态:整体的硬件健康状态。特别要观察:存储端口是否发生重置(此处在SAN交换机中也能够发现,端口发生重置,则会导致性能的稳定出现抖动)、硬盘是否有故障、控制器单点、BBU(backup battery unit)或保险箱盘故障->导致LUN转写保护。(华为)
2. 响应时间(延迟):指发起I/O请求到I/O处理完成的时间间隔。检查出现业务运行缓慢的LUN响应时间,有一些存储还支持对存储的端口响应时间检查。有未配置QOS或者存储硬件配置较低的情况下,个别业务的LUN响应时间变慢,可能会导致存储的整体响应时间变慢。
3. 带宽使用率:每秒可以处理的数据量。此处一般也是存储端口的带宽使用率,带宽越大,数据的传输速度也越快。带宽在顺序大I/O的情况下会达到其极限值。而在随机小I/O的情况下,链路的最大带宽会有所降低。所以在执行数据备份或者大文件拷贝时,端口的带宽容易出现瓶颈,导致无法及时响应其他业务的I/O请求,带宽利用率在SAN交换机中也能够发现。
4. IOPS:每秒可以处理的I/O个数。对于非固态硬盘来说,其转速和寻址时间决定了最大的IOPS,如果是非固态硬盘,那需要关注在性能问题期间,硬盘的最大IOPS是否达到了极限值。以EMC Unity存储为例,硬盘的最大IOPS:
| 硬盘IOPS | 各类端口IOPS |
| SAS Flash 2 or 3 --->20,000,响应时间<1ms
SAS 15K ---> 350,响应时间5ms至6ms SAS 10K ---> 250,响应时间5ms至6ms NL-SAS(SAS接口的SATA盘) --->150,响应时间10ms | 后端12Gb SAS ---> 250,000
前端 16Gb FC ---> 45,000 前端8Gb FC ---> 45,000 前端10GbE iSCSI ---> 25,000~30,000 前端25GbE iSCSI ---> 30,000 |
5. Cache命中率:是存储的性能关键,Cache的写策略为回写(每一个写I/O到达Cache就返回给主机写入成功响应)。然后通过Cache对数据进行重新排序和合并,再统一写入到硬盘。除了加速写入操作外,还加速读取操作,在存储中以Cache命中率来衡量,如果Cache利用率过高,则命中率降低,会出现读盘操作,I/O的响应时间也会变高。
6.2 存储双活检查
存储双活架构的特殊性,在除了通用指标的检查外,还需要针对性的对其CPU利用率、端口(前端、后端)响应时间和带宽/IOPS、复制链路进行检查。以负责主机端的I/O读写角色区分,存储双活的架构可分为A/A和A/P。A/A架构比较流行(比如华为、EMC),主机可以同时读写两端存储;A/P架构较少公司采用(主流仅有3Par),主机仅可对主端存储读写,备端存储仅有复制流量。当前市面上较为流行的主要是免网关的存储双活架构,而具备存储双活网关的架构,可以让原先不支持双活技术的存储或让两个不同厂家的存储形成存储双活架构。
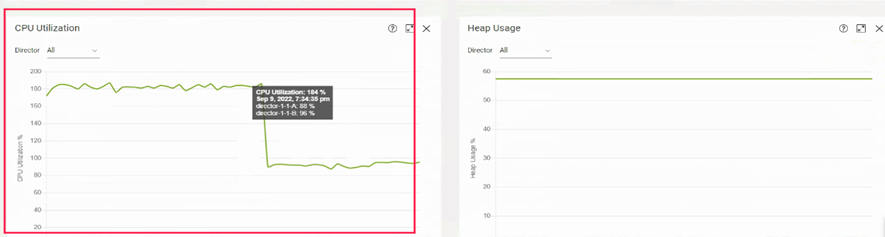
1. EMC VPLEX存储双活网关(Monitor->System Resources和Monitor->End To End):
Ø CPU 利用率,一般低于50%,CPU利用率过高,则处理和转发I/O的效率下降。
[ ]
]
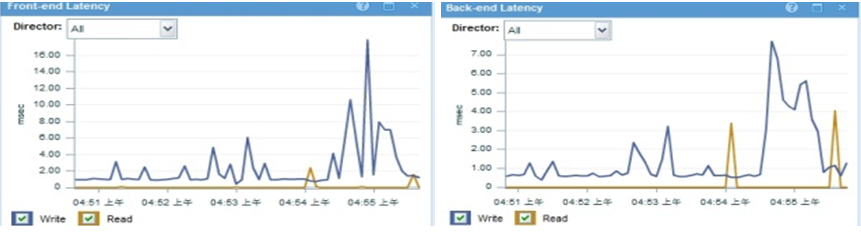
Ø 前后端端口响应时间,前端端口负责处理主机I/O,后端端口负责处理存储I/O。
[ ]
]
Ø 前后端端口的IOPS情况。
[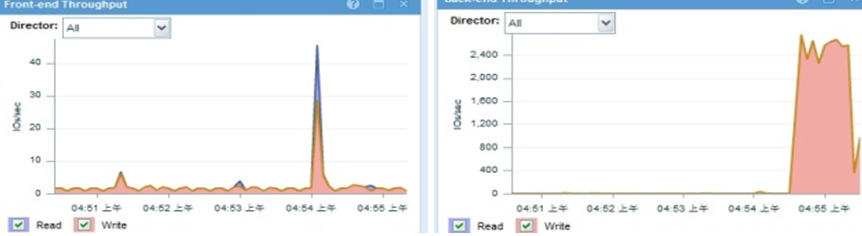 ]
]
Ø WAN口,用于VPLEX Metro的复制链路。
[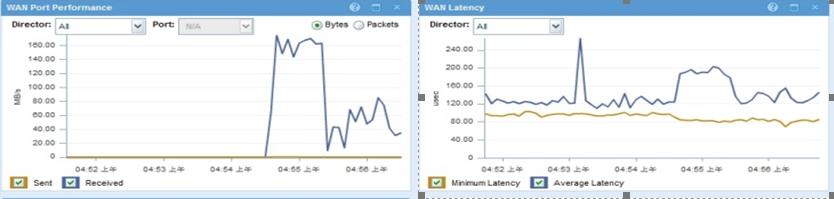 ]
]
2. 华为Dorado存储双活,有监控和分析两种功能,监控为实时监测每5秒一次,分析可以是5秒/5分钟/15分钟等,最长历史指标为1年。
Ø 监控CPU利用率和Cache利用率需要手动创建分析指标图表。
[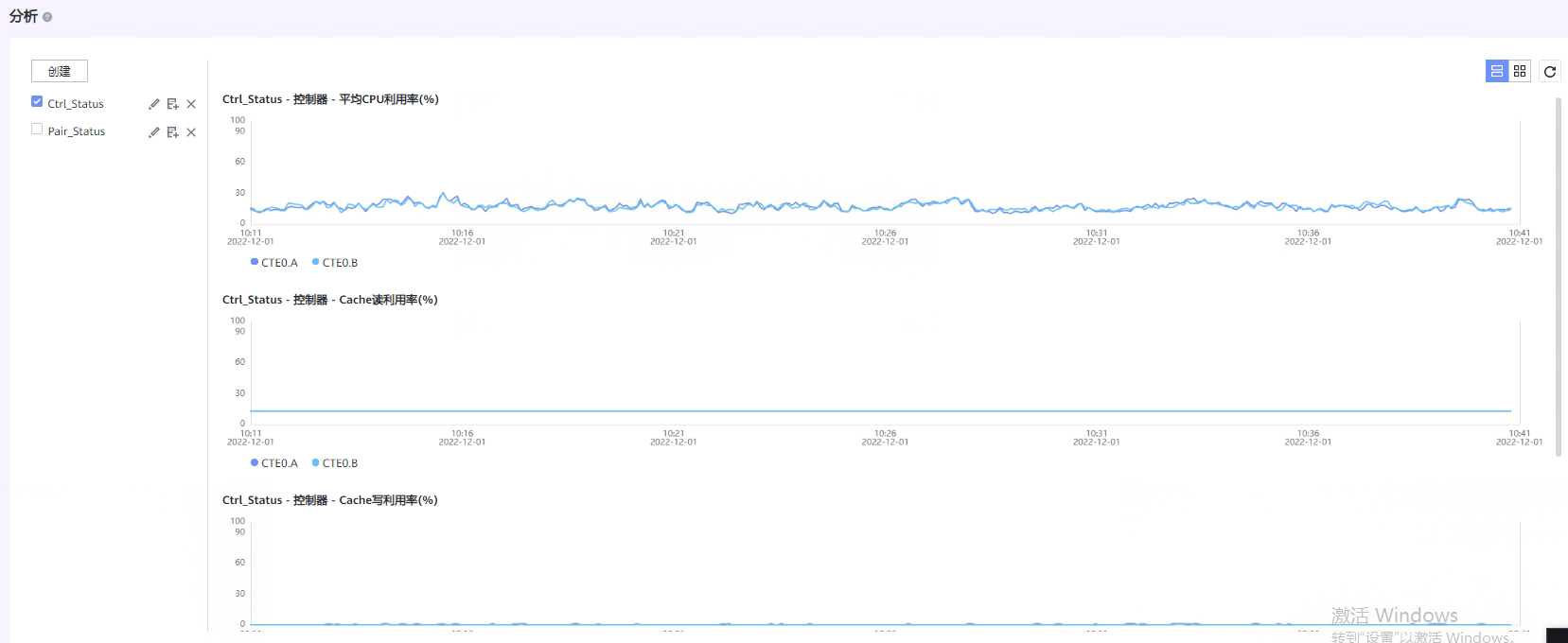 ]
]
Ø 前端端口性能表现,可以在监控中直接查看。
[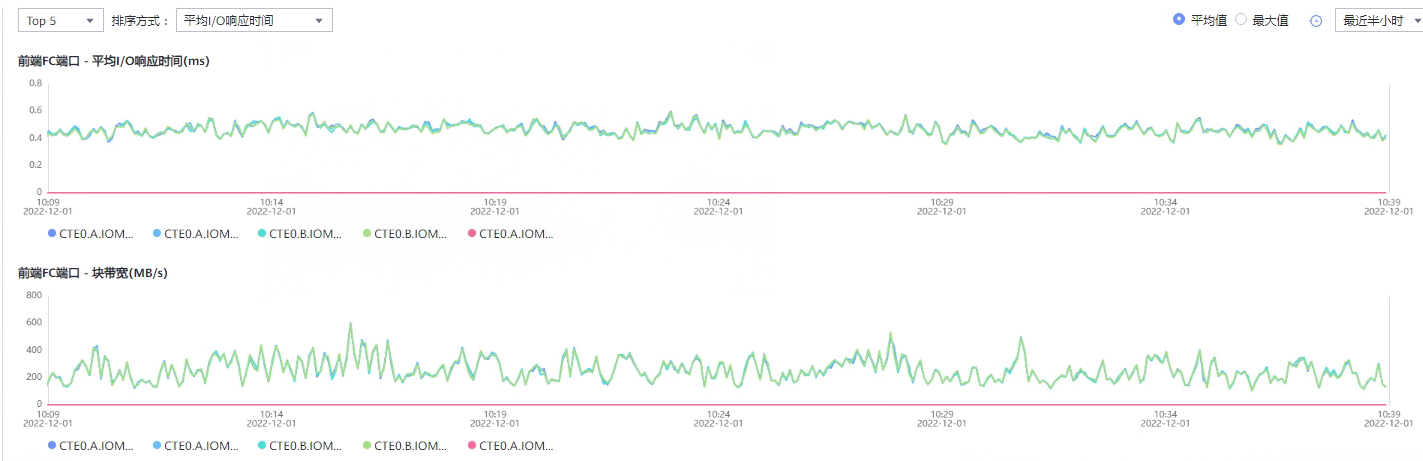 ]
]
Ø 监控复制链路性能需要手动创建分析指标图表。
[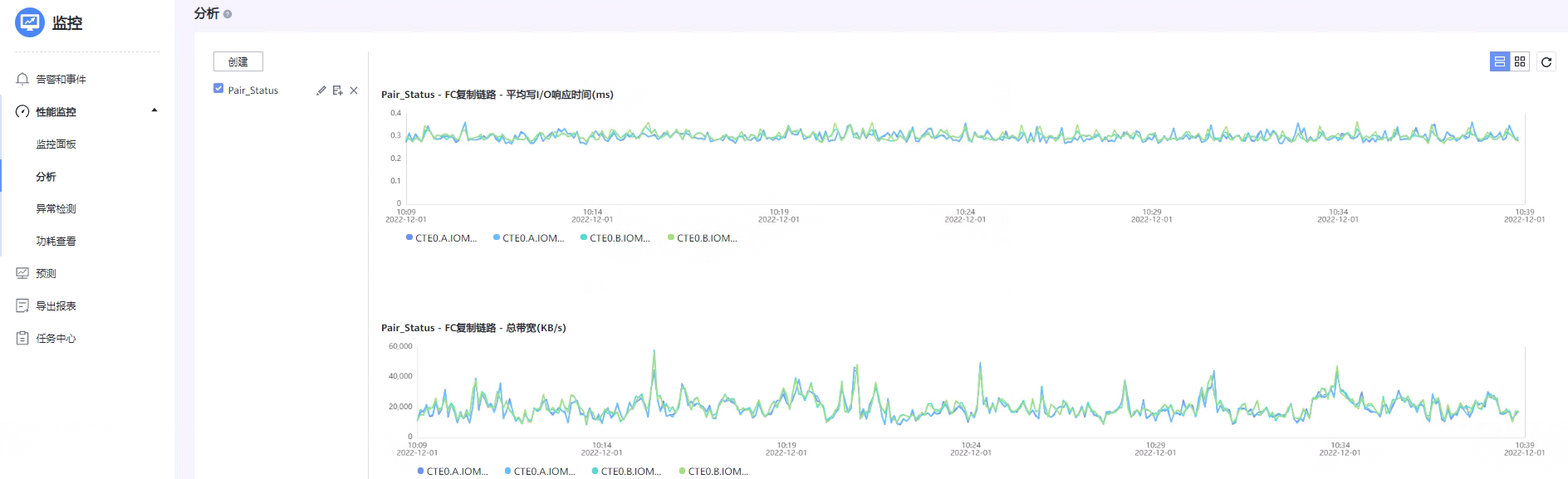 ]
]
7 结合数据库的等待事件
7.1 SQL Server与I/O相关的等待事件
SQL Server与I/O相关的等待事件有PAGEIOLATCH_SH、PAGEIOLATCH_EX、LOGBUFFER、WRITELOG、IO_COMPLETION、ASYNC_IO_COMPLETION、BACKUPIO、WRITE_COMPLETION,如果频繁出现这些等待事件,或者等待时间突然变高,那需要关注数据库的I/O情况。
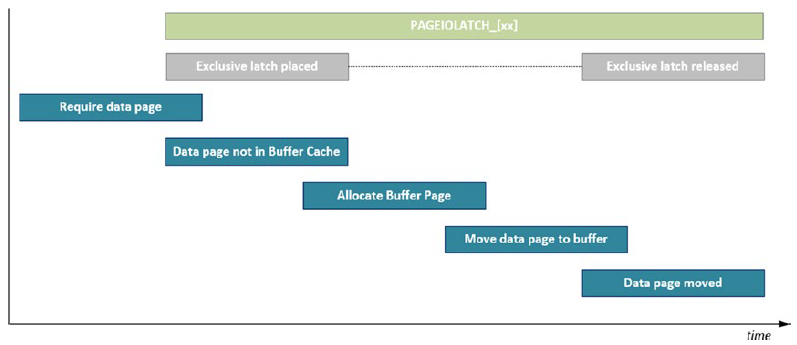
1. PAGEIOLATCH_SH、PAGEIOLATCH_EX和PAGEIOLATCH_UP,一般持续时间低于15毫秒。
PAGEIOLATCH与PAGELATCH不同,前者与I/O相关,后者与内存相关。
n PAGEIOLATCH_EX,在将缓冲区的数据写入磁盘时(例如checkpoint时),会出现独占闩锁,SQL Server在缓冲区中为数据页预留对应位置,直到数据页写入完成后释放闩锁。独占闩锁不兼容任何的闩锁模式。
n PAGEIOLATCH_SH,在从磁盘读取数据到缓冲区时,会出现共享闩锁,PAGEIOLATCH_SH会和PLE(数据页在内存中停留时间)相关,例如执行SELECT语句。
n PAGEIOLATCH_UP,如果数据页发生更改时,会出现更新闩锁或独占闩锁。
[ ]
]
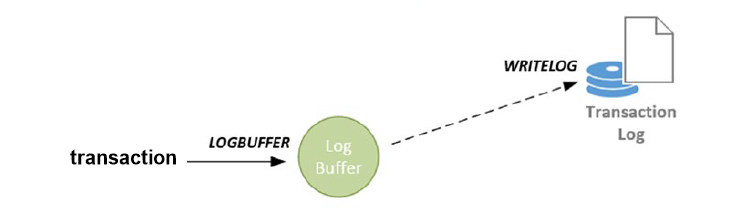
2. LOGBUFFER和WRITELOG,这两个等待事件与事务日志文件相关,数据页发生写入或修改后,会将内容写入到log buffer中,事务发生提交或者达到log buffer的固定大小60KB后,将log buffer中的日志记录写入到事务日志文件中。
n LOGBUFFER, 当事务在等待新的log buffer空间时出现。
n WRITELOG,每当log buffer中的记录写入到事务日志文件中时出现。留意VLF、小事务过多或者低版本的log write线程数量较小的问题。
[ ]
]
3. IO_COMPLETION,是一种很常见的等待事件,在涉及非数据页的I/O操作时发生,例如还原事务日志备份、分配和访问GAM页、或者使用merge join操作都会。但是当IO_COMPLETION比以往都要高时,那需要留意tempdb的性能,或者是否伴随其他的等待事件。
4. ASYNC_IO_COMPLETION,是一种很常见的等待事件,在SQL Server执行与文件相关的操作时会出现该等待事件, 出现该等待事件时,一般不用太担心,但是当ASYNC_IO_COMPLETION比以往都要高时,那需要留意是否正在执行备份或者增加数据文件,或者是否伴随其他的等待事件。开启即时文件初始化功能,可以降低该等待事件的时间。
5. BACKUPIO,在执行备份和还原操作时会出现,如果该等待时间较久,可能备份的磁盘性能较差,或者通过网络备份。BACKUPIO会伴随着ASYNC_IO_COMPLETION出现。
6. WRITE_COMPLETION,与IO_COMPLETION相关,但是WRITE_COMPLETION仅在执行dbcc 、扩容数据文件和日志文件时发生。如果出现大量的临时表创建、插入和删除的场景,导致tempdb出现PFS(Page Free Space)修改过于频繁,也有可能会出现该等待事件。
7.2 Oracle与I/O相关的等待事件
Oracle中与I/O相关的等待事件有db file sequential read、db file scattered read、direct path read和direct path read temp、db file single write、db file parallel write、direct path write and direct path write temp 、log file parallel write、log file sync,这些等待事件的出现意味着数据库正在执行与数据文件和日志文件相关的I/O操作。如果频繁出现这些等待事件的时间突然变高,那需要检查磁盘出现了I/O争用,使得数据库响应缓慢。
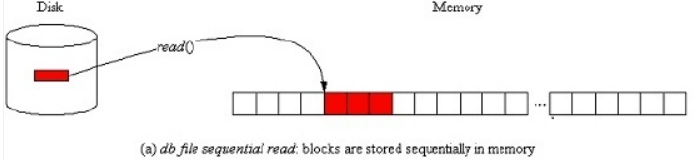
1. db file sequential read,说明会话正在从数据文件中读取单个数据块到Buffer Cache里面,通常使用索引时会读取单个数据块,sequential意思是以rowid或index的顺序进行读取。通常该等待事件是正常的,但如果单个数据块的读等待时间达到上百毫秒,那也意味着出现了I/O问题。
[ ]
]
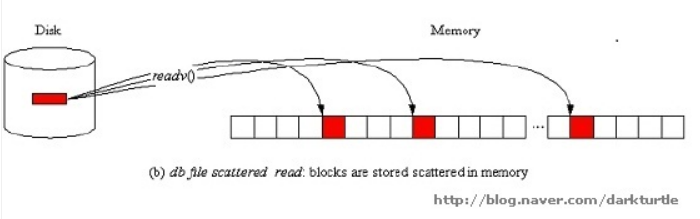
2. db file scattered read,说明会话正从数据文件中同时读取多个数据块到Buffer Cache里面,通常在全表扫描和快速扫描整个索引时会出现该等待事件。读取的数据块数量最大为db_file_multiblock_read_count参数值。
[ ]
]
3. direct path read和direct path read temp,直接从数据文件读取数据块到PGA中,并且不会共享给其他会话。全表扫描、并行查询、磁盘中排序、服务器进程处理缓冲区的速度比从磁盘中读取数据到缓冲区的速度快,都会触发direct path read等待事件,用户进程会一边处理PGA中的数据块,并且一边发出读取请求,即等待次数并不等于读取请求次数。如果底层存储不支持异步IO(LIBAIO),那每次等待都对应一次物理读请求。
[ ]
]
4. db file single write,更新数据文件头部时会出现该等待事件。数据文件头部包含了检查点信息,比如用于执行恢复操作的SCN号、还包含redo的地址信息、extent信息。
[ ]
]
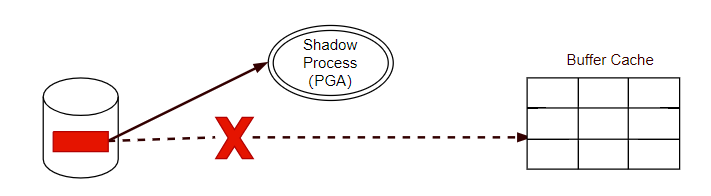
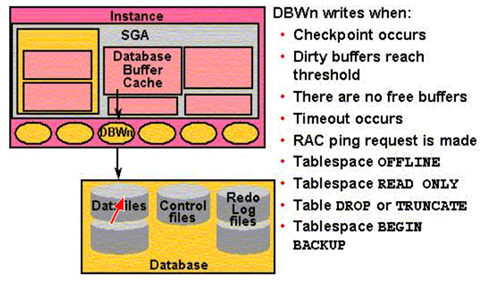
5. db file parallel write,DBWR进程在发出I/O操作时触发该等待事件,如果伴随着log file switch (checkpoint incomplete),可能是I/O出现瓶颈,或者事务日志文件太小。如果存储不支持异步I/O,DBWR的等待时间还包含等待I/O完成的时间。
[ ]
]
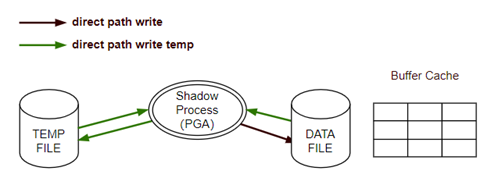
6. direct path write and direct path write temp,前者是等待进程从PGA写入数据文件时出现,例如在并行DML操作、创建索引和操作LOB数据类型等情况下出现;后者是等待进程从PGA在操作临时文件和读取数据文件时出现,例如磁盘中排序。
[ ]
]
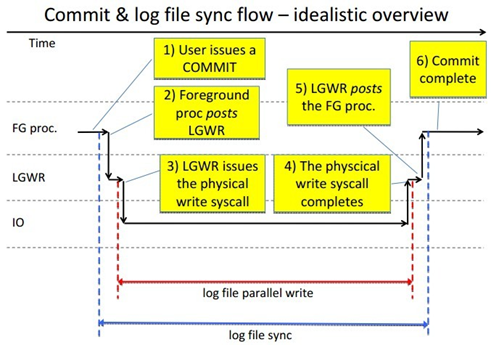
7. log file parallel write和log file sync,两个等待事件均与LGWR相关,log file sync的出现也伴随着log file parallel write。在用户执行commit操作时开始出现log file sync,随后LGWR将log buffer中的redo记录并行写入到一个redo日志文件组中的多个日志文件成员的过程中出现log file parallel write,LGWR完成后通知用户进程commit完成,此时log file sync结束。如果两个等待事件都较高,并且相差不大,那说明I/O出现了瓶颈。(log file parallel write的平均等待时间一般不超过10毫秒)
[ ]
]
8 结合虚拟化ESXi的I/O告警日志
当ESXi出现I/O性能瓶颈时,在ESXi的日志中会有相关的告警信息,分别需要留意/var/log文件夹里的vmkernel.log、hostd.log和vodb.log日志。
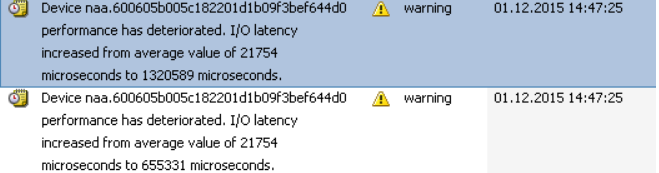
1. 检查vmkernel.log日志,搜索“performance has deteriorated”关键字,如果突然上升到很高,或者每次告警的延迟时间都在不断上升,则意味着出现的I/O性能问题,需要结合esxtop和存储端进行性能分析。
[ ]
]
2. 检查hostd.log日志,搜索“Lost access to volume”关键字,VMFS 数据存储通过检测信号进行监控,大约每 3 秒会从主机向 VMFS 卷写入检测信号。如果检测信号 I/O 的总时间超出 16 秒,则数据存储将被标记为脱机。
[ ]
]
3. 检查vobd.log日志,搜索“vob.scsi.scsipath.pathstate.dead” 关键字**,如果HBA卡的光纤线接触不良或者光功率衰弱,则会大概率触发hba卡的链路频繁重置,造成严重的存储性能问题。
[ ]
]
9 检查架构是否符合最佳实践
最佳实践对性能的发挥有关键的影响,可以根据对应存储、服务器、数据库、操作系统、虚拟化等厂家的实践指导对出现性能问题的建构进行检查,确认配置是否合理,是否要更改默认配置。
…………
10 整合分析数据
在调查清楚问题的背景后,我们根据问题的影响范围,在其涉及的组网拓扑中对受影响的业务环境进行了性能检查和分析,包括:主机端、交换机端、存储端,以及结合了一些数据库的等待事件或者虚拟化的I/O告警日志。通过整合和对比这些分析数据,基本能够确定是在硬件还是软件层面导致的存储性能问题。
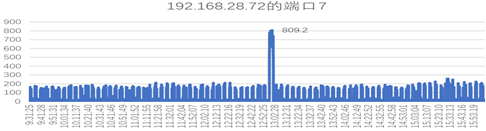
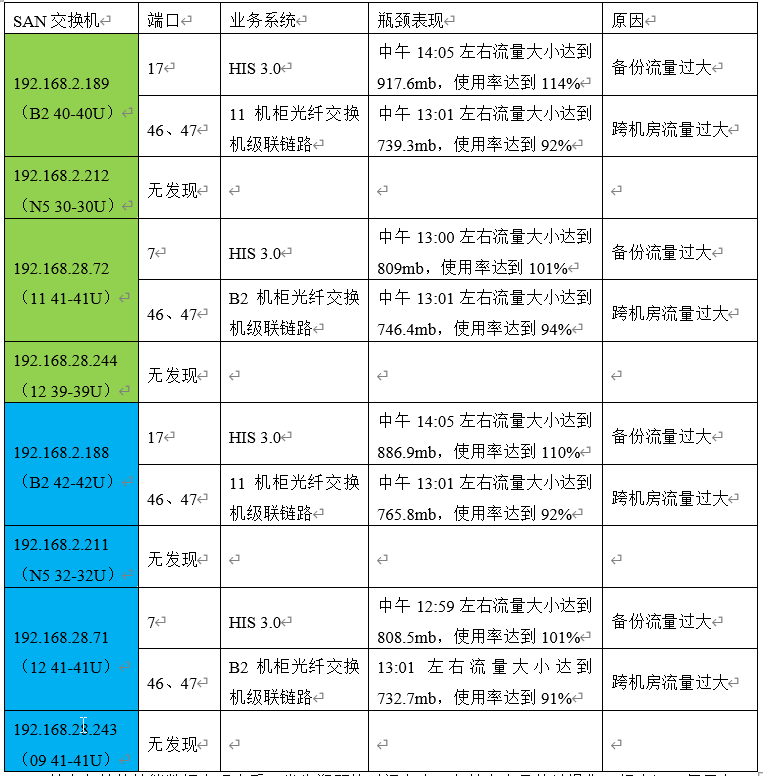
以下图为例:这是由于其数据库的存储和服务器在不同机房,在发起数据备份时,大量的读操作流量占满了主机和SAN交换机的端口,也会随之消耗级联的通道,一旦整个级联通道带宽被占满,则会使阻塞所有跨机房的流量,主机端的IO响应延迟也会随之上升,使整个业务系统产生性能问题。
[ ]
]
11 参考文档
Using esxtop to identify storage performance issues for ESX / ESXi (multiple versions) (1008205)
Dell EMC PowerPath Family CLI and System Messages Reference | Dell US
查询和导出性能统计信息 - OceanStor UltraPath for AIX 21.2.0 用户指南 04 - 华为 (huawei.com)
如何使用 Brocade 交换机的 "fpshow" 输出 确定 SFP 是否出现故障 - NetApp
Brocade 的 SFP 光功率级别的正常范围 - NetApp
dell_hdd_characteristic_and_metrics.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号